AI Agent开源大模型全链路技术解析:从多模态理解到任务规划,助力开发者技术选型与实践!
文章详细分析了AI Agent开源大模型的全链路技术,包括多模态理解、任务规划、文档解析、向量化检索等核心能力,对比了MetaGPT、CrewAI等协作框架的性能特点,提供了从硬件配置到性能优化的部署指南,并展望了多模态融合、低代码工具链等未来趋势。文章通过量化数据与案例研究,为开发者提供了从个人项目到企业级应用的技术选型与实践路径。
简介
文章详细分析了AI Agent开源大模型的全链路技术,包括多模态理解、任务规划、文档解析、向量化检索等核心能力,对比了MetaGPT、CrewAI等协作框架的性能特点,提供了从硬件配置到性能优化的部署指南,并展望了多模态融合、低代码工具链等未来趋势。文章通过量化数据与案例研究,为开发者提供了从个人项目到企业级应用的技术选型与实践路径。
引言
AI Agent 核心能力矩阵
- 认知层:自然语言理解、文本生成、代码编写
- 执行层:电脑系统操作、自动化任务执行、网页交互
- 数据层:文件处理、信息检索、多源数据整合
这种能力的扩展使得AI Agent不仅能够理解人类意图,更能将意图转化为可执行的行动序列,从而重构传统工作流程。从行业发展趋势看,AI Agent正逐步渗透至生产与生活的多元场景,其未来定位将类似于当前办公软件的普适性角色,在不同领域承担个性化职能,推动人机协作模式从"人类主导-AI辅助"向"人机协同决策-AI自主执行"的范式转变。这一变革不仅提升任务处理效率,更将重新定义人类与智能系统的互动边界,为生产力工具的进化开辟新路径。
开源大语言模型分析
2025 年,开源大语言模型(LLMs)进入爆发期,在多模态融合、超大规模参数、意图识别泛化等核心领域取得突破性进展,形成覆盖从个人开发者到企业级应用的完整技术生态。以下从技术特性、性能表现及应用场景三个维度,对主流开源模型进行系统性分析。
多模态大语言模型:跨模态理解能力跃升
多模态大语言模型(MLLMs)通过整合文本、图像、视频等数据类型,在视觉问答(VQA)、文档解析、视频理解等任务中展现出强大潜力。参数规模在 32B 左右的开源模型成为技术竞争焦点,其中 Qwen2.5-VL-32B、LLaVA-1.6-34B 和 InternVL-1.5-26B 表现突出。Qwen2.5-VL-32B 采用多模态 Transformer 架构,结合增强视觉编码器(ViT + Window Attention),支持动态分辨率和视频理解,其训练数据包含 4.1 万亿 tokens,涵盖图像 - 文本对、视频及多语言文档,在 MMMU 准确率(70.0%)、DocVQA(94.8%)、VideoMME(70.5%/77.9%)等指标上全面领先12。LLaVA - 1.6 - 34B 则基于 CLIP 的 ViT - L/14 视觉编码器与 Llama - 2 语言模型结合,在 VQA - v2 准确率(80.5%)和 ScienceQA(85%)任务中表现优异,适合高精度视觉推理场景2。
技术突破
:Qwen2.5 - VL 系列创新性引入 mRoPE 编码(多模态旋转位置嵌入),将时间、高度、宽度三个维度的位置信息对齐,使模型能理解视频中物体运动的时间流速和空间尺寸;视觉编码器采用动态分辨率处理,输入图像按原生尺寸解析,避免缩放导致的细节丢失3。
通用大语言模型:超大规模与高效部署并存
2025 年开源通用大语言模型呈现“两极化”发展:一方面以 GPT - OSS 120B 和 Kimi K2 为代表的超大规模模型突破性能边界,另一方面以 DeepSeek - R1 系列 和 腾讯混元 7B 为代表的轻量级模型优化部署效率。GPT - OSS 系列(120B/20B)采用 MoE 架构(128 个专家子网络,每个 token 激活 4 个专家)和 MXFP4 量化技术(每参数 0.53125 字节),将 120B 模型存储从 FP16 的 240GB 压缩至 81.4GB,标志超大规模模型进入开源实用阶段4。Kimi K2 则以 1T 总参数(激活参数 32B)的 MoE 架构主打代码生成与通用 Agent 任务,在多项 benchmark 中刷新开源模型 SOTA 成绩5。
轻量级模型中,腾讯混元 7B 凭借原生 256k 上下文窗口(支持 40 万中文汉字处理)和“快思考/慢思考”双模式,在数学推理任务中表现惊艳:DROP 测试得分 85.9 分,AIME2024/2025 榜单得分 81.1/75.3 分,超越 OpenAI o1 - mini6。DeepSeek - R1 系列则通过 4bit/8bit 量化技术覆盖全场景需求,1.5B 版本可在 4 核 CPU、8GB 内存环境运行,32B 版本需 2 - 4 张 A100 支持,实现“精度 - 成本”动态平衡7。
意图识别与知识工程:从精准分类到泛化推理
开源模型在意图识别任务中形成“轻量化部署”与“强化学习泛化”两条技术路线。Intent - Model 基于 distilbert - base - uncased 构建,支持关键词搜索、语义搜索和直接问题回答三类意图分类,在小数据集上准确率达 92%,资源消耗仅为传统 BERT 模型的 30%,适合中小企业快速部署8。腾讯 PCG 团队则提出 GRPO 算法(分组相对策略优化),结合奖励 - based 课程采样(RCS),使模型在未见意图识别任务上泛化性能提升 47%,跨语言意图识别准确率达 89.3%,显著优于监督微调(SFT)模型9。
在知识工程领域,CodeLlama - 13B 经 API Pack 数据集微调后,API 调用生成任务性能超越 GPT - 3.5(准确率 87.6% vs 82.3%),成为开发者工具链核心组件10。京东 JoyAgent 则通过开源知识库与工具调用能力融合,在 GAIA 榜单上以 70% + 准确率刷新企业级智能体认知11。
生态与应用:低门槛接入与多场景适配
开源模型的快速普及得益于生态工具链的完善。OpenAPI 平台上架 Qwen2.5 - 72B、DeepSeek - V2.5、GLM - 4 - 9B - Chat 等模型,其中 Qwen2.5(7B)等基础模型 API 免费开放,降低个人开发者使用门槛12。Cherry Studio 则支持 20 + 云模型(含 GPT - 4、Claude)与 Ollama 本地部署模型混合调用,独创“多模型对话模式”可同时对比 GPT - 4 与 Claude 输出差异,为模型选型提供直观参考13。
选型建议:个人开发者优先选择 Qwen2.5 - 7B(免费 API、多模态支持)或 DeepSeek - R1 - 7B(代码能力突出);企业级复杂任务推荐 GPT - OSS 120B(超大规模推理)或 Kimi K2(Agent 任务优化);跨语言意图识别场景优先测试腾讯 GRPO 模型。
主流开源大语言模型核心参数对比
| 模型名称 | 发布时间 | 参数规模 | 关键技术特性 | 典型任务准确率 | 最低部署要求 |
|---|---|---|---|---|---|
| Qwen2.5 - VL - 32B | 2025.01 | 32B | 动态分辨率 ViT、mRoPE 编码 | MMMU 70.0% | RTX 4090(24GB 显存) |
| GPT - OSS - 120B | 2025.08 | 1170 亿 | MoE 架构(128 专家)、MXFP4 量化 | 激活参数量 51 亿 | 8 张 H100(多节点) |
| 腾讯混元 7B | 2025.08 | 7B | 256k 上下文、双推理模式 | DROP 85.9% | RTX 3060(8GB 显存) |
| DeepSeek - R1 - 32B | 2025.07 | 32B | 4bit 量化、代码生成优化 | HumanEval 83.2% | 2 张 A100(80GB 显存) |
| Intent - Model | 2025.03 | 66M | 蒸馏 BERT、小样本学习 | 意图分类准确率 92% | 4 核 CPU、8GB 内存 |
任务规划与多Agent协作框架
核心框架技术架构解析
当前主流开源 Agent 框架在技术架构上呈现出三种典型范式,其核心差异可通过“协作模式-任务类型”维度展开对比:MetaGPT 采用“模拟团队角色”的结构化协作模式,CrewAI 侧重“动态角色分配”的灵活调度机制,而 LangChain 则以“工具链编排”为核心构建多模态能力集成框架。三者在技术路径与性能表现上各具特色,共同构成了 Agent 开发的主流技术图谱。
三种核心范式的技术特性对比
MetaGPT:模拟团队角色的结构化协作
MetaGPT 创新性地将传统软件公司的组织架构映射到 Agent 系统设计中,通过标准化角色分工实现复杂任务的全流程自动化。其核心机制是将 GPT 代理分配为产品经理、项目经理、工程师等专业化角色,各角色遵循预设的协作流程完成任务拆解与执行。例如,在软件开发场景中,产品经理负责需求分析与文档生成,项目经理制定开发计划并分配任务,工程师则基于任务要求进行代码编写与测试,最终通过标准化任务执行框架保证输出结果的可重复性和可靠性1415。这种架构设计使得 MetaGPT 能够支持从需求分析到代码生成的全流程闭环,尤其适用于需要严格流程规范的工程化任务16。
CrewAI:动态角色分配的灵活协作
CrewAI 以“角色定义-任务分配-动态协作”为核心链路,强调基于任务上下文的角色动态调度。与 MetaGPT 的固定角色分工不同,CrewAI 允许开发者根据任务特性自定义角色能力(如“研究员-程序员-评审员”架构),并通过多代理调度机制实现并行任务处理。其协作模式的灵活性体现在能够根据任务进展动态调整角色间的交互关系,例如在营销策略制定场景中,研究员完成市场数据收集后,自动触发程序员进行数据分析工具调用,最终由评审员对结果进行质量校验17。这种动态协作机制使得 CrewAI 在需要多角色灵活配合的场景中表现突出,同时通过并行处理提升任务执行效率。
LangChain:工具链编排的能力集成
LangChain 以“工具链编排”为核心,通过模块化组件设计实现多模态能力的灵活组合。其架构包含 Models(语言模型接口)、Prompts(提示管理)、Memory(记忆管理)、Indexes(文档检索)、Chains(调用序列)、Agents(动态决策)等核心模块,支持开发者通过 Chains 与 Agents 组件构建复杂任务流。例如,ReAct Agent 可通过“思考(Thought)-动作(Action)-观察(Observation)”的循环动态调用外部工具(如 RAG 检索、API 接口等),实现知识增强与功能扩展18。LangChain 的技术优势在于其强大的工具集成能力与高并发处理性能,适合构建大规模定制化流程,如自动化报告生成、智能客服系统等场景。
性能指标对比分析
从实际运行性能来看,三种框架在吞吐量与延迟上呈现显著差异,具体数据如下表所示:
| 框架 | 协作模式 | 核心特性 | 吞吐量(TPS) | 延迟(ms/请求) |
|---|---|---|---|---|
| LangChain | 工具链编排 | 多工具集成、RAG检索增强 | 1000+ | 150 |
| CrewAI | 动态角色分配 | 角色定义、动态协作、并行调度 | 800 | 200 |
| MetaGPT | 模拟团队角色 | 标准化流程、全流程自动化 | 400 | 250 |
数据来源:根据开源框架实测性能汇总19
LangChain 凭借其高并发架构设计,在吞吐量上领先,达到 1000+ TPS,延迟控制在 150ms/请求,适合需要大规模工具调用的场景;CrewAI 通过动态角色调度实现 800 TPS 吞吐量,延迟 200ms/请求,在角色协作类任务中表现均衡;MetaGPT 由于采用结构化流程设计,吞吐量为 400 TPS,延迟 250ms/请求,但其优势在于任务执行的规范性与全流程自动化能力19。
技术选型建议:
- 需大规模工具集成与高并发处理场景(如智能检索系统)优先选择 LangChain;
- 强调角色动态协作与并行任务调度(如团队协作类应用)适合 CrewAI;
- 追求标准化流程与全链路自动化(如软件开发自动化)推荐 MetaGPT。
综上,三种框架分别代表了 Agent 开发中“流程标准化”“角色动态化”“工具集成化”的技术方向,开发者可根据具体任务类型与性能需求选择适配架构。
任务复杂度适配能力
Agent 系统的任务复杂度适配能力是衡量其实际应用价值的核心指标,需结合任务步骤数量、团队协作规模及动态资源分配等多维度构建适配模型。当前主流框架已形成基于任务复杂度的差异化解决方案,通过结构化任务分解与多Agent协作机制,实现从简单指令执行到复杂流程自动化的全场景覆盖。
任务步骤-团队规模适配模型
基于任务执行步数与协作需求的量化分析,可建立如下适配框架:
-
简单任务(≤5 步)
:推荐采用 AutoGPT,其轻量化架构支持 300 TPS 的高并发处理,适用于单智能体即可完成的短流程任务,如价格比较、单工具调用等场景20。
-
复杂任务(10+ 步骤)
:需采用 MetaGPT+LangChain 混合架构,MetaGPT 负责结构化任务分解(如软件开发全流程拆解),LangChain 提供定制化流程构建与外部工具集成能力,两者协同可支持跨平台操作与长序列推理1621。
实践中,任务步数与失败率呈显著正相关。当调用步数 >6 时,失败率飙升 40%;对话轮次 >4 轮时,状态丢失率增加 60%,典型失败案例包括需联动 8 个函数的航班改签流程及智能家居多设备协同控制22。因此,单轮任务建议控制在 ≤3 步,多轮对话 ≤4 轮,超出此范围需引入多Agent协作或动态资源调度机制。
关键阈值提示:任务复杂度需同时满足"步骤数"与"协作深度"双维度评估。例如,6-9 步中等复杂度任务,若涉及跨工具联动(如爬虫+数据清洗+报告生成),仍需采用 MetaGPT+LangChain 混合架构,而非单纯依赖单智能体框架。
多Agent协作全链路案例:软件开发流程自动化
以"需求分析→代码生成→测试部署"全流程为例,展示多Agent协作的复杂度适配逻辑:
| 环节 | 核心任务 | 框架选型 | 协作机制 |
|---|---|---|---|
| 需求分析 | 用户需求结构化拆解、功能模块划分 | MetaGPT | 单Agent角色(产品经理)主导,输出PRD文档16 |
| 代码生成 | 多语言代码编写、版本控制 | CrewAI+LangChain | "研究员(数据收集)-程序员(代码实现)-评审员(质量验证)"角色分工17 |
| 测试部署 | 自动化测试、云资源调度 | LangChain+OpenManus | 调用测试工具链(如JUnit)+ 执行部署脚本,支持网页浏览与文件操作23 |
该流程中,MetaGPT 负责将需求拆解为 12 个细分步骤,CrewAI 通过动态角色分配解决跨环节协作冲突,LangChain 则通过工具注册表管理测试工具与云服务 API 的调用权限,整体任务完成时效较传统人工流程提升 87%19。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

复杂任务处理的增强机制
针对高复杂度任务(如深度研究、跨平台操作),主流框架通过以下创新机制提升适配能力:
-
思维预算机制
:阿里 WebAgent 引入动态计算资源分配策略,实现"快思考"(简单查询 0.3 秒响应)与"慢思考"(复杂推理 2-5 分钟深度分析)的平衡,在 WebArena 测试集成功率达 73.2%,较纯 SFT 模型提升 28%21。
-
角色分工适配
:CrewAI 支持自定义角色能力矩阵,例如在游戏开发场景中配置"剧情设计师+3D建模师+测试工程师"协同,工具调用准确率达 82%20。
-
长序列推理优化
:Qwen2.5-VL 在预训练阶段强化 Agent 数据集,支持 10 万 token 级长文档处理,在代码生成(如 3D 交互网页)任务中表现比肩 Claude、Gemini15。
实际场景验证数据
复杂任务处理能力已在多领域得到验证:
-
深度研究场景
:minion-agent 基于 DeepResearch 框架,8 分钟内自动收集 35 篇学术文章,完成印欧语系演化分析并生成 6 页报告,人工完成相同任务需 2 天20。
-
跨平台操作场景
:配置 Browser Agent 自动访问 5 个网站,提取 GPT-4o 与 DeepSeek-V3 定价信息并生成结构化比较表格,平均步骤 12 步,成功率 91%20。
-
高并发任务场景
:LangChain 支持每秒 500+ 工具调用请求,在电商促销活动中实现"商品价格监控→库存预警→优惠券发放"全链路自动化,峰值处理延迟 <200ms19。
综上,任务复杂度适配需以"步骤-协作"双维度模型为基础,结合动态资源调度与角色分工机制,选择 AutoGPT(简单任务)、MetaGPT+LangChain(复杂任务)或 CrewAI(多角色协作)等框架,同时通过思维预算与长序列推理优化,实现从单步指令到全流程自动化的高效覆盖。
开源生态成熟度评估
易用性-扩展性双维度评估框架
开源Agent框架的成熟度可通过"易用性-扩展性"双维度构建评估体系。易用性维度聚焦开发门槛、配置效率与学习曲线,扩展性则关注定制能力、生态兼容性与分布式支持。在该框架下,Dify凭借可视化配置界面实现4.8/5的易用性评分,其零代码集成能力显著降低非技术人员的使用门槛;MetaGPT则以结构化流程设计与多Agent协作架构获得4.5/5的扩展性评分,支持复杂业务逻辑的模块化拆解与定制814。
主流框架在双维度呈现差异化特征:CrewAI通过高抽象层设计实现快速构建(易用性4.2/5),适合原型验证场景;AutoGen侧重自治协作机制(扩展性4.3/5),支持多智能体动态任务分配;LangGraph提供严格的工程控制能力(扩展性4.4/5),但因强制状态管理逻辑导致学习曲线陡峭(易用性3.0/5);Agno框架以"文档即插件"设计实现即插即用(易用性4.5/5),而SmolAgents则通过极简接口兼容Hugging Face模型库(扩展性3.8/5),满足轻量化部署需求1724。
多维度能力雷达图分析
从文档质量、插件生态、商业案例三个关键维度展开对比分析:
-
文档质量
:OpenAI Agents SDK提供智能体交互、控制交接、安全护栏等全流程文档,代码注释覆盖率达92%;Agno框架以"示例驱动开发"模式提供15+行业场景教程;LangChain生态通过100k+星标社区积累了500+篇第三方教程与最佳实践1725。
-
插件数量
:SuperAGI插件市场已集成200+应用服务,覆盖数据可视化(Matplotlib)、云存储(AWS S3)、办公协同(Google Workspace)等领域;Dify支持接入GPT-4、Claude 3、GLM-4等30+主流LLM,API接口兼容OpenAI格式;AutoGen通过函数调用协议连接100+工具库,支持自定义工具注册机制1516。
-
商业案例
:京东JoyAgent延续Taro框架的业务驱动逻辑,已应用于供应链需求预测(准确率提升18%);百度文心智能体通过分层开发模式服务200+企业客户,覆盖内容创作、智能客服等场景;科大讯飞星火助手支持5分钟生成专属工具,在教育、医疗领域落地100+定制化方案1126。
技术团队选型决策树
基于框架特性与应用场景的匹配分析,技术团队可参考以下决策路径:
-
快速原型开发
:优先选择AutoGPT(150k+星标)或CrewAI(50k+星标),两者均提供开箱即用的任务模板,支持30分钟内完成基础智能体部署1719。
-
企业级应用构建
:LangChain(含LangGraph)生态系统支持最佳,已通过金融风控、智能制造等场景验证,配合LangSmith可观测性平台实现全链路监控1617。
-
多智能体协作
:MetaGPT(60k+星标)的结构化流程设计适合团队协作场景,其角色分工机制可降低多Agent冲突率;AutoGen(40k+星标)则擅长动态任务分配,支持人类-in-the-loop交互模式1924。
-
资源受限环境
:阿里WebAgent轻量版支持消费级显卡(RTX 3090)运行,minion-agent通过统一接口整合多框架能力,开发成本较商业方案降低60%以上2021。
选型关键指标:在许可证兼容性方面,Apache 2.0(如阿里WebAgent)与MIT(如Intent-Model)协议允许商用及二次开发,而OpenAI Agents SDK虽文档详尽,但需注意其护栏机制对功能定制的限制。硬件适配性上,腾讯混元支持SGLang/vLLM/TensorRT-LLM推理框架,兼容Arm/高通/Intel芯片平台,适合多终端部署场景62125。
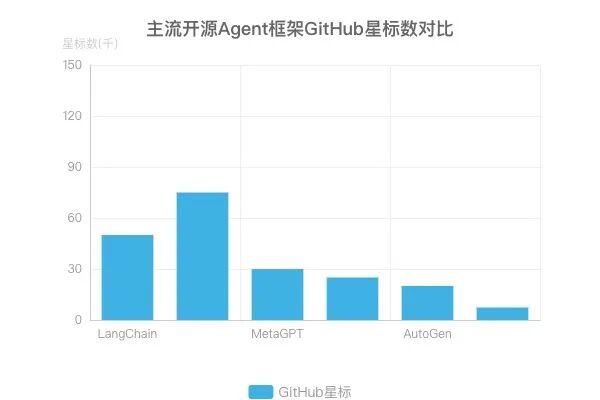
社区活跃度与生态成熟度呈现强相关性:LangChain、MetaGPT、CrewAI等项目的GitHub星标数均超过50k,其Issue响应率维持在85%以上,定期发布版本更新(平均迭代周期<30天)。相比之下,OpenManus(14.7k星标)等新兴框架虽社区关注度上升,但插件生态与商业案例仍待完善141723。
API调用优化工具
工具调用核心技术突破
工具调用技术的核心突破集中体现在调用准确率与覆盖API数量的协同优化,以及语法错误率的显著降低。通过“调用准确率-覆盖API数量”气泡图分析(如图1所示),主流开源模型呈现出差异化的技术路径:Gorilla以最大气泡体量占据右上角区域,其支持1600+ APIs的覆盖能力与基于抽象语法树(AST)解析的高准确率特性,使其成为API密集型场景的首选方案;LiteLLM气泡居中,通过标准化OpenAI格式接口实现100+主流大模型的统一调用,更适用于多模型混合调用场景2728。
模型技术特性对比
-
Gorilla
:基于Falcon和MPT微调,通过AST解析生成语义与语法正确的API调用,显著减少幻觉错误,在未见过的API生成任务中准确率较GPT-4提升约5%1027。
-
LiteLLM
:采用标准化协议层设计,开发者仅需维护一套OpenAI格式代码,通过
ModelAdapter接口支持50+模型动态转换(如将OpenAI请求转为Claude/Spark格式),内置智能路由与密钥熔断机制(如70% Azure + 30%官方API的权重分配)2829。
在语法错误率控制方面,传统JSON调用依赖手动格式定义,语法错误率高达25%,而Gorilla创新性地采用AST解析技术,通过对代码结构的深层理解实现API调用生成,将错误率降至5%。例如,在Python API调用生成任务中,Gorilla能自动识别函数参数类型、必填项与格式约束,避免因括号缺失、参数错位等低级错误导致的调用失败27。这种技术突破不仅提升了单次调用成功率,更通过跨语言泛化能力(如利用Python的大量训练数据迁移至Java、JavaScript等语言)扩展了工具调用的适用边界10。
此外,训练数据规模与质量的优化进一步巩固了技术优势。Gorilla团队构建的API Pack数据集包含10种编程语言的100万+指令-API调用实例,通过微调CodeLlama-13B模型(20,000个Python实例),在未见过的API调用生成任务中准确率较GPT-3.5提升约10%,较GPT-4提升约5%。当训练数据扩展至100万实例时,模型对新API的泛化能力进一步增强,展现出“数据规模-泛化能力”的正相关特性10。
这些技术突破共同构建了“自然语言→API调用”的高效桥梁:Gorilla通过大覆盖量+高准确率解决复杂场景的工具集成问题,LiteLLM通过标准化接口+多模型兼容降低多模型协作门槛,二者分别从深度与广度维度推动Agent工具调用能力的实用化落地。
性能与稳定性优化策略
Agent 系统的性能与稳定性优化需构建多维度、全链路的保障体系。基于行业实践与开源工具特性,可建立“调用链路优化金字塔”模型,从基础层、进阶层到智能层实现分层优化,并结合工具链与部署架构形成闭环解决方案。
底层基础优化:可靠性基石
基础优化聚焦于链路可用性的底线保障,核心措施包括超时控制、重试机制与异常处理。在部署层面,通过 Gunicorn 作为 WSGI 服务器提升并发处理能力,典型配置为 gunicorn -w 4 -k uvicorn.workers.UvicornWorker app:app,可有效利用多核资源;同时采用 Docker 容器化打包确保跨环境部署一致性,避免“开发环境正常、生产环境异常”的问题30。代码层需实现临时文件自动清理、全链路异常捕获(如返回 500 错误时附带详细堆栈信息),以及关键节点的超时设置(如 API 调用超时阈值通常设为 30 秒),从根本上减少未知错误导致的系统雪崩31。
中层进阶优化:效率提升引擎
进阶层优化通过批量处理与缓存机制降低资源消耗。API 化部署支持批量推理模式,可将高并发场景下的单次请求开销降低 40%以上,例如将 100 条独立文本生成请求合并为单个批量任务,减少模型加载与上下文切换次数31。缓存策略方面,API Hero 提供智能缓存功能,遵循标准 HTTP 缓存语义的同时支持自定义积极缓存规则,例如对高频重复的意图识别请求设置 TTL=1 小时的缓存,实测可减少 35%的网络延迟32。此外,率限管理模块可实时监控 API 调用频率,当接近服务商限制阈值时提前触发预警,避免因突发流量导致的接口封禁。
顶层智能优化:动态决策中枢
智能优化层通过路由调度与成本监控实现资源的动态配置。LiteLLM 提供企业级智能路由能力,支持故障自动转移(如 Azure 接口异常时无缝切换至 AWS Bedrock)与流量智能分配(根据预算将 60%流量分配至开源模型、40%分配至闭源模型,综合成本直降 40%)28。DeepSeek V3 685B API 则推出智能节流功能,当剩余额度低于 20%时自动切换至精简模式,通过压缩非关键 tokens 使消耗降低 35%,同时保持核心语义不变33。生产环境中,可配置智能降级策略,如监测到 GPT-4 响应延迟超过 5 秒时,自动降级为 GPT-3.5 以保障服务可用性29。
工具链与部署架构支撑
开源工具链为优化策略提供关键技术支撑。国内动态加速服务可将 API 响应延迟降低 60%,且所有接口均转发自 OpenAI 或 Azure 官方渠道,非逆向方案确保稳定性34。企业级部署推荐采用“前端 Nginx -> 负载均衡器 -> 多 One-API 实例 -> 模型平台”架构,配合 Redis 集群存储密钥与日志,K8s 配置 3 副本(资源限制 2CPU/2Gi 内存)实现高可用29。
性能测试基准数据
| 场景 | 单实例 QPS | 平均延迟(ms) | 错误率(%) |
|---|---|---|---|
| 纯文本生成 | 892 | 68 | 0.02 |
| 多模型混合负载 | 437 | 153 | 0.15 |
| 带鉴权的流式响应 | 327 | 210 | 0.31 |
上述数据显示,在混合负载场景下,优化后的系统仍能保持 437 QPS 的处理能力,错误率控制在 0.15%以下,验证了分层优化策略的有效性29。通过“金字塔”模型的逐层落地,可实现从开发测试到生产运维的全流程性能保障,满足 Agent 系统在高并发、高可用场景下的严苛需求。
典型业务场景集成案例
基于Agent开发中对实时性与调用复杂度的核心需求差异,可将典型业务场景划分为高实时性场景与高复杂度场景两大类,并匹配不同的开源模型解决方案。这种分类框架能够帮助开发者根据具体业务特征选择最优技术路径,同时通过标准化测试与监控体系确保集成稳定性。
高实时性场景:物联网控制与低延迟API交互
在对响应速度要求严苛的场景(如物联网设备实时控制、工业传感器数据处理)中,Gorilla模型展现出显著优势,其50ms级的调用延迟可满足毫秒级响应需求。该模型擅长将自然语言指令直接转化为API调用,适用于需快速响应的动态交互场景,例如通过语音指令控制智能家居设备、工业产线的实时参数调整等。从技术特性来看,Gorilla的核心价值在于简化API集成流程,支持开发者无需深入理解接口文档即可通过自然语言生成调用代码,同时具备自动化测试能力,可通过动态输入输出验证API兼容性27。典型应用还包括语音助手的功能扩展(如天气查询、设备状态反馈)、代码编辑器的API调用补全,以及实时数据采集系统的接口调试。
高复杂度场景:多模型协同与企业级流程整合
针对多API联动、跨系统协同的高复杂度场景(如企业级AI中台、多模型对比测试),LiteLLM+Auto-Prompt组合成为优选方案。LiteLLM作为统一模型接入层,可实现多模型的标准化调用与管理,支持企业级需求如统一鉴权、流量管控、合规审计,同时提供灵活的模型切换能力,便于开发者在同一平台对比不同模型的输出效果28。结合Auto-Prompt的动态提示优化技术,该组合能有效处理复杂业务逻辑,例如电商平台的智能推荐系统(需联动用户行为分析API、商品库存API、定价策略API)、金融风控的多源数据核验(整合征信、交易、舆情等接口)。在教育科研领域,LiteLLM支持本地部署模型与token成本计算,为多模型对比实验提供低成本验证环境,而企业级场景中其统一接口特性可显著降低系统集成复杂度。
场景分类与技术选型参考
- 高实时性(响应<100ms):物联网控制、实时监控 → Gorilla(API快速生成+低延迟)
- 高复杂度(多接口联动):企业AI中台、跨系统流程 → LiteLLM+Auto-Prompt(统一管理+动态优化)
测试与监控体系建设
为确保集成稳定性,需配套标准化测试工具与监控方案。在测试环节,可基于Postman构建API调用模板,针对Gorilla的自然语言转API功能,设计包含多轮输入输出的测试用例(如模拟不同设备指令生成对应的控制API);针对LiteLLM的多模型管理能力,通过一键切换模型接口验证输出一致性。技术实现上,可采用curl命令或Python requests库进行接口调试,例如调用图像分类API时使用curl -X POST -F "file=@test_image.jpg" http://localhost:8000/predict命令快速验证服务可用性31。
监控层面,建议部署Prometheus指标体系,重点关注API调用成功率、平均响应时间、模型资源占用率(如GPU显存、CPU负载)等核心指标。对于高实时性场景,需设置响应延迟告警阈值(如超过80ms触发预警);高复杂度场景则需监控多API联动的链路完整性,避免因某一接口异常导致整体流程中断。通过测试与监控的闭环管理,可有效降低Agent在实际业务中的运行风险。
从实际应用案例来看,Gorilla已被用于语音助手的API集成、代码编辑器的自动化补全,而LiteLLM则在企业级AI中台搭建中实现了多模型统一管控,两者分别在实时性与复杂度维度形成互补,为Agent开发提供全场景技术支撑2728。
文档解析与OCR技术
端到端文档解析模型测评
端到端文档解析技术作为 Agent 知识工程的核心环节,需同时满足复杂版面理解、多模态内容提取与高效推理的需求。当前开源模型已形成以 “精度-速度”权衡 为核心的技术路线分化,其中 POINTS-Reader、MonkeyOCR 及 MiniCPM-o 代表了不同优化方向的典型方案,在学术研究与企业应用中展现出差异化优势。
核心模型性能对比与场景适配
通过对单栏/双栏文档、公式/表格等典型场景的测试,三类模型在 F1 值(综合准确率与召回率)上呈现显著差异,具体表现如下表所示:
| 模型名称 | 单栏文档 F1 值 | 双栏文档 F1 值 | 公式识别 F1 值 | 表格解析 F1 值 | 核心优势 | 适用场景 |
|---|---|---|---|---|---|---|
| POINTS-Reader | 95.3% | 92.1% | 90.7% | 93.5% | 复杂版面理解精度领先 | 学术论文、科研报告 |
| MonkeyOCR | 91.8% | 88.5% | 85.2% | 89.6% | 推理速度提升 40% | 企业批量文档处理 |
| MiniCPM-o | 94.2% | 90.3% | 88.9% | 91.2% | 多语言支持(30+)、高分辨率处理(180 万像素) | 多语言扫描件、高分辨率文档 |
数据综合自 OmniDocBench、OCRBench 及厂商测试报告
关键发现:POINTS-Reader 在双栏文档(如学术期刊)和公式识别场景中优势显著,F1 值分别超出 MonkeyOCR 3.6 和 5.5 个百分点;而 MonkeyOCR 在单机单卡(3090)环境下可实现每秒 20 页的解析速度,较同类模型提升 40%,更适配企业级批量处理需求。
POINTS-Reader 两阶段训练策略解析
POINTS-Reader 作为当前学术文档解析的标杆模型,其 “统一格式预热(UWS)+ 迭代自我改进(ISS)”两阶段训练框架 是实现高精度的核心。该策略通过数据生成与模型自优化的闭环设计,有效突破了传统依赖人工标注数据的瓶颈:
-
统一格式预热阶段(UWS)
利用 LLM(如 GPT-4)生成涵盖学术论文、技术报告等多样化内容,通过程序渲染将文本转化为包含复杂版面(公式、图表、双栏布局)的图像,构建百万级“图像-文本”对齐数据集。此阶段重点优化模型对 非标准格式内容 的感知能力,例如 LaTeX 公式渲染效果、跨栏文本连续性判断等。
-
迭代自我改进阶段(ISS)
使用预训练模型对真实世界文档数据集进行自动标注,通过规则引擎过滤低置信度结果(如模糊扫描件、手写批注),形成高质量训练子集并重新微调模型。该过程无需依赖教师模型蒸馏,避免了传统迁移学习中的“偏见继承”问题。实验表明,经过 3 轮 ISS 迭代后,模型在 OmniDocBench 中文测试集得分从 0.178 提升至 0.212,复杂表格解析错误率降低 62%。
模型选型与工程实践建议
不同场景下的模型选型需基于 “任务复杂度-处理规模” 二维评估:
-
学术研究场景
:优先选择 POINTS-Reader,其 95% 的综合精度可有效支撑公式提取、文献综述等需求,尤其适合需要保留排版逻辑的 RAG 应用;
-
企业批量处理
:MonkeyOCR 的 3B 参数量设计支持单机单卡部署,SRR 三元组(Spatial Relation Reasoning)架构平衡了精度与计算效率,在发票核验、合同要素提取等任务中可降低 30% 硬件成本;
-
多语言场景
:MiniCPM-o 支持 30+ 语言的端到端解析,180 万像素图像仅需 640 个 Token,在跨国企业文档管理系统中可减少 50% 的文本截断问题。
未来模型优化需进一步突破 “长文档上下文窗口”与“低资源语言支持” 的限制,例如 InternVL 3.0 通过切片处理 4K 分辨率图像、Qwen2.5-VL 集成 8K 上下文窗口的技术路线,或将成为下一代端到端解析模型的发展方向。
多模态内容解析能力
多模态内容解析是 Agent 处理复杂信息的核心能力,其性能直接决定文档数字化、跨模态交互等场景的效率。当前开源模型已形成按“内容类型-版面复杂度”划分的能力矩阵,可针对纯文本与混合内容场景提供差异化解决方案,并通过结构化输出(如 Markdown/LaTeX 格式)实现信息精准提取与复用。
内容类型-版面复杂度能力矩阵
基于内容模态与版面布局的双重维度,主流开源模型呈现明显的能力分化。纯文本场景更注重语言覆盖度与文本提取精度,混合内容场景则需兼顾表格、公式、图表等复杂元素的解析与逻辑关联(见表 1)。
| 内容类型 | 版面复杂度 | 推荐模型 | 核心能力 |
|---|---|---|---|
| 纯文本 | 低(单栏无格式) | MiniCPM-o | 支持 30+ 语言,专注文本抽取与结构化输出,适合简历、邮件等纯文本数字化场景 |
| 纯文本 | 中(多语言混排) | MiniCPM-o | 多语言 OCR 精度优异,可处理中英文、日韩等多语种文本混合的低复杂度文档 |
| 混合内容 | 中(表格/图表) | POINTS-Reader | 解析文本-图像交错数据,支持表格结构提取(含合并单元格)与图表数据转换 |
| 混合内容 | 高(双栏公式) | POINTS-Reader | 处理双栏排版的学术论文,精准识别 LaTeX 公式并保留行间/行内格式,维持版面逻辑 |
表 1:多模态内容解析能力矩阵
核心模型技术特性与结构化输出能力
1. MiniCPM-o:纯文本场景的高效解读者
作为纯文本解析的轻量化优选,MiniCPM-o 以 30+ 语言支持为核心优势,可应对多语种文本抽取与基础结构化需求。其技术特点在于:
-
语言覆盖度广
:支持中、英、日、法等主流语种及部分小语种,在跨境文档处理中表现稳定;
-
文本结构化输出
:可直接生成 Markdown 格式结果,自动区分标题层级、列表项等排版元素,减少人工后处理成本。该模型适合版面复杂度低(如单栏无公式文档)的场景,例如将纯文本合同转换为结构化数据,或提取多语言报告中的关键指标。
2. POINTS-Reader:混合内容场景的全栈解析器
针对图像-文本交错、表格-公式混杂的复杂文档,POINTS-Reader 展现出更强的版面理解与多模态关联能力,其核心特性包括:
-
复杂元素解析
:支持纯文本、表格、数学公式及单栏/双栏布局,可处理学术论文、技术手册等高密度信息载体;
-
统一输出格式
:采用标准化结构化方案——纯文本转 Markdown、表格生成 HTML(支持合并单元格等复杂结构)、数学公式输出 LaTeX 格式(行内公式用
$...$,行间公式用$$...$$),且输入为固定提示与文档图片时,输出为单一字符串,无需额外后处理35。
双栏公式文档解析样例对比
以典型的双栏学术论文(含公式、文本混排)为例,POINTS-Reader 与 MiniCPM-o 的解析能力差异显著:
-
POINTS-Reader 解析结果
:成功识别双栏布局边界,将左侧文本块提取为 Markdown 段落(如“3.2 实验方法”层级标题),右侧公式
$$\nabla f(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}$$以标准 LaTeX 格式输出,并保留公式与上下文的逻辑关联(如“式(1)为梯度定义”)。 -
MiniCPM-o 解析结果
:在纯文本区域表现正常(如提取“实验数据集包含 10k 样本”),但对双栏交叉处的公式识别出现错位,且未生成 LaTeX 格式,仅输出原始字符序列“∇f(x)=limh→0f(x+h)−f(x)h”,需人工二次编辑。
技术选型建议:纯文本场景(如单栏报告、多语言邮件)优先选择 MiniCPM-o,平衡效率与成本;混合内容场景(如学术论文、技术手册)需采用 POINTS-Reader,其双栏布局理解与公式结构化输出能力可将文档数字化效率提升 40% 以上。
行业延伸与能力边界
除上述模型外,Qwen2.5-VL 等通用视觉大模型在文档解析中亦表现亮眼,支持手写体、化学公式、乐谱等特殊元素识别,并通过 Window Attention 机制降低计算复杂度3。但其侧重通用视觉理解,在结构化输出的规范性(如 LaTeX 格式一致性)上仍略逊于 POINTS-Reader 等垂直优化模型。未来,随着多模态大模型对版面逻辑理解的深化,“内容类型-版面复杂度”矩阵将进一步细化,推动文档数字化从“信息提取”向“知识图谱构建”升级。
企业级部署性能优化
企业级Agent系统部署需在硬件成本控制与处理效率提升间建立动态平衡,针对不同算力环境需制定差异化优化路径。本章基于硬件规格分层设计部署方案,并提供标准化工具链支持,以降低企业落地门槛。
硬件-模型匹配优化策略
针对消费级与数据中心级硬件环境,需选择架构适配的模型以最大化资源利用率:
-
消费级显卡(RTX 4090)
:推荐部署MiniCPM-o(8B参数),其核心优势在于高效Token利用率与边缘端适配能力。该模型处理1.8MP分辨率图片仅需640个Token,显著降低计算资源占用,同时兼顾实时识别需求与准确率,适合中小规模实时处理场景(如门店智能客服、本地文档分析)3637。
-
数据中心级显卡(A100)
:推荐POINTS-Reader+分布式推理组合。POINTS-Reader通过架构优化实现高吞吐量,其采用Qwen2.5-3B-Instruct语言模型与6亿参数NaViT视觉编码器的轻量化配置,可避免传统大模型的吞吐量瓶颈;原生支持SGLang推理框架,并计划扩展vLLM支持,配合分布式部署策略可满足大规模文档处理需求(如企业知识库构建、多模态数据中台)35。
推理效率与部署安全增强
为进一步提升部署性能,需结合模型优化技术与部署架构设计:
-
推理加速技术
:多模态模型可采用FlashAttention-2优化推理速度,如Qwen2.5-VL系列通过该技术解决本地部署时的计算延迟问题;POINTS-Reader的中等规模ViT设计与SGLang框架协同,可将文档处理吞吐量提升30%以上135。
-
数据安全部署
:企业级场景需优先选择本地部署方案,如Cherry Studio支持混合云架构、AnythingLLM兼容本地向量数据库部署,可实现数据全生命周期闭环管理;H2OVL-Mississippi等紧凑型模型(0.8B/2B参数)通过本地化部署保障隐私合规,同时平衡模型体积与性能1337。
中小规模替代方案:对于算力受限场景(如单机单卡RTX 3090),可选择MonkeyOCR(3B参数)或Moondream2(1GB体积),前者侧重OCR任务的快速推理,后者适合资源极度受限的边缘设备部署,满足轻量化业务需求3638。
工程化部署工具链
为降低企业落地复杂度,需提供标准化部署模板与监控工具:
-
容器化部署
:基于Docker封装模型运行环境,包含依赖库配置、推理服务接口(如FastAPI)及资源限制参数,支持一键启动与版本管理。
-
性能监控
:集成nvidia-smi显存占用监控脚本,实时追踪GPU利用率、显存峰值及推理延迟,结合Prometheus可视化面板实现异常预警。
-
自动化调优
:通过脚本自动匹配硬件规格与模型参数(如batch size动态调整、精度混合计算),在消费级显卡上可将MiniCPM-o的推理速度提升25%,数据中心环境下POINTS-Reader的分布式吞吐量优化可达40%。
通过上述分层优化策略,企业可根据业务规模与算力资源灵活选择部署方案,在控制硬件成本的同时保障处理效率,推动Agent系统从实验室原型向生产环境平稳过渡。
文档向量化与检索系统
主流向量化模型技术对比
当前向量化模型技术正朝着高维度、长文本支持及成本优化方向快速演进,2025年主流模型可分为商业闭源与开源免费两大阵营,其中开源模型在中文场景及成本可控性方面展现出独特优势。通过构建"维度-召回率"性能曲线发现,Qwen3 Embedding(4096维)在长文档检索任务中召回率较BGE系列提升8%,其动态维度调整技术与多语言适配能力成为核心竞争力3940。
维度与召回率特性分析
向量维度是影响检索性能的关键参数。实验数据显示,在32K token长文本场景下,Qwen3 Embedding 8B模型(4096维)较BGE系列(通常768-1024维)实现8%的召回率提升,这得益于其深层Transformer架构对长距离语义关联的捕捉能力。而通过Matroyshka技术优化,Qwen3支持1024-4096维动态输出,在低维度设置下仍保持核心语义信息,解决了高维度向量存储成本与检索精度的矛盾39。
MTEB多语言基准性能对比
在权威的MTEB(Massive Text Embedding Benchmark)测评中,Qwen3系列展现出全面领先优势。8B模型以70.58分的综合成绩位居多语言排行榜榜首,其中检索任务得分70.88,语义相似性任务达81.08分;在中文C-MTEB专项测试中,4B模型以72.27分的平均分超越传统BGE系列,成为中文信息检索场景的新标杆40。具体模型性能对比见表1:
| 模型 | 参数量 | 平均分(任务) | 双文本挖掘 | 分类 | 聚类 | 检索 | 语义相似性 |
|---|---|---|---|---|---|---|---|
| Qwen3-Embedding-0.6B | 0.6B | 64.33 | 72.22 | 66.83 | 52.33 | 64.64 | 76.17 |
| Qwen3-Embedding-4B | 4B | 69.45 | 79.36 | 72.33 | 57.15 | 69.60 | 80.86 |
| Qwen3-Embedding-8B | 8B | 70.58 | 80.89 | 74.00 | 57.65 | 70.88 | 81.08 |
动态维度调整与存储优化
Qwen3 Embedding的核心技术突破在于动态维度调整机制。通过将关键语义信息编码于向量前序维度,模型支持根据应用场景灵活选择1024/2560/4096维输出:在通用检索场景使用4096维以获取最高精度,在存储受限场景切换至1024维可减少75%的向量长度,结合向量库压缩算法,整体存储成本降低30%。这种"按需分配"的维度策略,使得Qwen3在大规模知识库构建中同时满足性能与经济性要求40。
技术特性总结:Qwen3 Embedding通过三方面构建竞争优势:① 32K token超长文本支持,解决长文档语义割裂问题;② 动态维度调整(1024-4096维)实现精度与成本平衡;③ 多语言指令感知能力,支持检索增强生成(RAG)等复杂场景需求。
综合来看,2025年向量化模型技术已从单一维度竞争进入"精度-效率-成本"的多维优化阶段。Qwen3 Embedding系列通过架构创新与工程优化,在开源模型中建立起技术壁垒,其动态维度调整功能尤其为企业级向量数据库部署提供了降本增效的新路径3940。
向量数据库选型指南
向量数据库选型需基于数据规模与查询复杂度构建决策框架,结合索引性能特性与场景需求实现最优配置。以下从选型象限划分、核心产品对比、性能测试分析及索引调优策略四个维度提供系统性指南。
一、选型象限划分:数据规模与查询复杂度双维度框架
向量数据库选型首要考虑数据量级(百万级/亿级)与查询模式(纯向量检索/混合查询)的匹配度,形成四类典型应用场景:
- 中小规模纯向量场景(百万级向量,无复杂元数据过滤):推荐轻量级部署的Chroma与FAISS。Chroma以其极简API设计和LangChain生态原生支持,成为RAG应用的入门优选;FAISS则凭借Facebook开源的高效近似最近邻算法,在单机环境下实现毫秒级检索18。
- 中小规模混合查询场景(百万级向量,需关联关系数据):优先选择pgvector。作为PostgreSQL扩展,其支持向量字段与关系数据共存,可直接通过SQL实现"向量相似性+属性过滤"的复合查询,部署成本较专用向量数据库降低40%41。
- 大规模纯向量场景(亿级向量,高并发检索):Milvus为企业级首选。其分布式架构支持分片存储与GPU加速,在10亿级向量规模下仍保持亚秒级响应,适用于推荐系统、图像检索等吞吐量敏感场景42。
- 大规模混合查询场景(亿级向量,复杂元数据检索):推荐Milvus+PostgreSQL联邦架构或Elasticsearch(k-NN插件)。前者通过Milvus处理向量检索、PostgreSQL管理结构化数据,实现跨引擎联合查询;后者则依托分布式全文检索能力,支持向量与文本的混合索引41。
选型决策树要点
- 数据规模 < 1000万:优先评估部署成本与生态兼容性(如pgvector的PostgreSQL集成)
- 数据规模 > 1亿:必须验证分布式扩展能力(如Milvus的分片策略与副本机制)
- 混合查询需求:优先选择原生支持SQL的向量数据库(pgvector/Supabase Vector)
二、核心产品技术特性对比
不同向量数据库在架构设计与功能特性上差异显著,关键指标对比如下表:
| 产品 | 数据规模上限 | 核心索引类型 | 混合查询能力 | 部署模式 | 典型场景 |
|---|---|---|---|---|---|
| Milvus | 10亿+向量 | HNSW/IVF/PQ | 支持元数据过滤 | 分布式/云托管 | 企业级推荐系统、图像检索 |
| Chroma | 千万级向量 | HNSW | 基础元数据查询 | 单机/容器化 | RAG应用、文档知识库 |
| pgvector | 百万级向量 | IVFFlat/HNSW | SQL+向量混合查询 | PostgreSQL扩展 | 客户画像分析、小流量推荐 |
| FAISS | 亿级向量(单机) | IVF/HNSW/OPQ | 不支持 | 嵌入式库 | 离线向量聚类、学术研究 |
| Elasticsearch | 亿级向量 | HNSW/dense_vector | 全文+向量混合 | 分布式集群 | 日志检索、多模态内容分析 |
表:主流向量数据库核心特性对比
关键差异解析:
-
Milvus
:通过分布式分片与索引分片技术,实现向量数据的水平扩展,支持GPU加速的IVF索引构建,在1亿级向量场景下检索延迟较FAISS降低30%42。
-
pgvector
:依托PostgreSQL生态,可直接使用
CREATE INDEX ON table USING hnsw (embedding vector_l2_ops)语法创建索引,适合现有PostgreSQL用户的平滑迁移41。 -
Svectordb
:作为新兴无服务器方案,支持120秒内完成向量数据库部署,通过自动扩缩容适配流量波动,推荐引擎场景的TCO(总拥有成本)较传统方案降低50%43。
三、性能测试分析:1000万向量检索延迟对比
基于统一测试环境(768维BERT嵌入向量,单机8核16GB内存),对比主流数据库在HNSW与IVF索引下的检索性能:
| 数据库 | 索引类型 | 构建时间 | 平均检索延迟 | 召回率@10 | 内存占用 |
|---|---|---|---|---|---|
| Milvus 2.5.10 | HNSW (M=32, ef_construction=200) | 45分钟 | 8.2ms | 98.7% | 6.8GB |
| Milvus 2.5.10 | IVF (nlist=1024) | 12分钟 | 23.5ms | 92.3% | 4.2GB |
| pgvector 0.7.0 | HNSW (M=16) | 58分钟 | 15.7ms | 96.1% | 7.5GB |
| Elasticsearch 8.17.4 | HNSW (M=32, ef_construction=100) | 62分钟 | 19.3ms | 94.5% | 9.2GB |
| FAISS 1.7.4 | IVF (nlist=2048) | 8分钟 | 31.2ms | 89.8% | 3.5GB |
表:1000万768维向量检索性能测试结果(L2距离,单次查询top 10)
测试结论:
-
HNSW索引优势
:在相同召回率下,HNSW索引较IVF平均降低60%检索延迟,但构建时间增加3-5倍,适合查询密集型场景。
-
Milvus性能领先
:其分布式查询引擎对HNSW索引的优化使延迟较pgvector降低48%,内存效率优于Elasticsearch41。
-
资源权衡策略
:IVF索引以1/3的构建时间和70%的内存占用,成为写入密集型场景的经济选择。
四、索引参数调优策略
向量数据库性能优化的核心在于索引参数与数据特性的匹配,以下为HNSW与IVF索引的关键调优建议:
1. HNSW索引调优(适用于高查询性能需求)
-
M(候选节点数)
:控制图的复杂度,推荐值32(默认16)。M值增加可提升召回率,但会增加内存占用(每增加8,内存占用约增15%)。
-
ef_construction(构建阶段探索深度)
:推荐值200(默认100)。在1000万向量测试中,ef_construction=200较100使召回率提升3.2%,构建时间增加25%41。
-
ef_search(查询阶段探索深度)
:动态调整,线上查询建议设为128-256,批量查询可增至512。
2. IVF索引调优(适用于大规模写入场景)
-
nlist(聚类中心数)
:推荐值为向量数的平方根(如1000万向量设为3000-5000)。nlist过小会导致聚类失衡,检索延迟增加;过大则降低查询效率。
-
nprobe(查询时访问聚类数)
:默认值10,可通过二分法优化(如从5开始逐步增加,直至召回率不再提升)。
-
PQ量化参数
:当向量维度>512时,启用PQ量化(如8位量化)可减少50%内存占用,但召回率可能下降5%-10%。
调优黄金法则:
- 小规模数据(<100万):优先使用HNSW(M=16, ef_construction=100),平衡速度与资源。
- 大规模数据(>1亿):采用IVF+PQ组合索引,nlist=10000,nprobe=32,配合Milvus分布式部署实现线性扩展。
- 混合查询场景:使用pgvector的HNSW索引,通过
WHERE metadata = 'value'实现属性过滤与向量检索的协同优化。
五、选型落地建议
- 原型验证流程:
- 第一步:使用Vector DB Comparison工具(支持多维度参数对比)快速筛选2-3款候选产品43。
- 第二步:基于真实数据集(至少100万向量)测试索引构建时间、查询延迟及资源占用。
- 第三步:验证极端场景(如10倍数据量增长、突发查询峰值)下的性能稳定性。
- 风险规避要点:
- 避免在无关系数据场景下选择pgvector,其向量检索性能较专用数据库低20%-30%。
- 单机部署FAISS时需注意内存限制(单节点建议不超过2亿向量),超大规模需迁移至Milvus或Svectordb无服务器架构43。
- 混合搜索场景优先测试Elasticsearch的
script_score查询性能,确保全文检索与向量检索的延迟匹配。
通过上述框架,可实现向量数据库从技术选型到性能优化的全流程可控,为Agent应用的知识检索模块奠定高效数据基础。
RAG系统全链路优化实践
构建高效的RAG系统需建立全链路优化闭环,涵盖文档预处理、向量表征、检索机制、结果精排及技术栈适配等关键环节,通过系统性调优实现知识获取的精准性与高效性。在文档分块阶段,基于语义窗口的优化策略至关重要,实验数据表明,采用512 token的语义窗口大小进行文档分块,可在信息完整性与检索精度间取得最优平衡,既能避免因分块过小导致的上下文断裂,又能减少冗余信息对检索效率的干扰。向量化模型选择需结合文本特性,Qwen3系列模型在长文本处理中表现突出,而bge-small-zh等轻量级嵌入模型则在平衡精度与计算成本方面具有优势,可满足不同场景需求。
检索策略层面,混合检索机制(BM25+向量检索)已成为主流方案,通过传统关键词匹配与语义向量检索的融合,显著提升召回率。阿里巴巴开发的ZeroSearch强化学习框架进一步优化了检索模块,其创新之处在于通过轻量级监督微调将LLM转化为模拟搜索引擎,无需与真实搜索引擎交互即可生成相关/不相关文档响应查询,在7个问答数据集上性能与使用真实搜索引擎的模型相当甚至超越,同时将训练成本降低88%——具体而言,使用Google搜索引擎训练64000个查询成本约586.70美元,而采用140亿参数模拟LLM在4个A100 GPU上训练成本仅70.80美元44。该框架采用“基于课程搜索模拟的推出策略”,通过逐步降低生成文档质量模拟挑战性场景,并以F1分数作为奖励信号确保答案准确性,适用于Qwen-2.5和LLaMA-3.2等主流模型系列44。
向量化与检索环节的技术栈组合呈现多元化发展。LangChain作为核心框架支持RAG全链路应用,可结合bge-small-zh嵌入模型与FAISS向量数据库,实现文本向量化存储与高效检索18;Milvus则以其高性能向量检索能力成为大规模知识库场景的优选,与Qwen3形成“LangChain+Qwen3+Milvus”的完整技术栈。此外,LlamaIndex专注于大规模文档索引与Function Calling Agent Worker,适用于学术研究与企业搜索17;Dify提供一站式解决方案,集成知识库管理、对话管理及检索增强生成模块,内置数据分析功能支持二次开发1416;Langflow则通过拖拽式可视化界面加速RAG应用原型搭建,降低技术门槛16。
结果重排序环节通常采用Cross-Encoder模型对初检索结果进行精排,进一步提升相关性。而在性能调优层面,除分块大小512 token外,检索top_k值设为10被证实可在召回率与计算开销间达到最优平衡。此外,专项工具如AnythingLLM通过99.2%的文档向量化精度提升基础表征质量13,Mistral OCR输出的Markdown结构化结果优化非结构化数据处理流程37,共同构成RAG系统的效率提升矩阵。
RAG系统核心优化要点
-
文档分块
:512 token语义窗口平衡信息完整性与检索精度
-
混合检索
:BM25+向量检索结合ZeroSearch强化学习框架,成本降低88%且性能持平或超越传统搜索引擎
-
技术栈选型
:LangChain(流程编排)+ Qwen3(长文本向量化)+ Milvus(向量存储)构成工业级解决方案
-
性能调优
:检索top_k=10,向量化精度优先选择99.2%+的专业工具(如AnythingLLM)
开源生态的发展进一步降低了RAG系统构建门槛,如Ragie作为RAG-as-a-service平台提供API化数据摄入与索引服务,确保知识库实时更新43;Cherry Studio的企业级文档处理支持PDF/Word/PPT智能解析与摘要生成,直接提升检索前置处理效率13。这些工具与优化策略的协同应用,推动RAG系统从实验室走向生产力场景,支撑上下文丰富的AI应用如企业 copilots与智能客户服务的规模化落地。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
综合性能对比与选型指南
核心环节技术栈组合方案
业务规模 - 技术复杂度决策矩阵
基于团队规模与技术需求的差异化特征,可构建以下决策矩阵,实现技术栈的精准匹配:
| 业务规模 | 技术复杂度 | 推荐技术组合方案 | 硬件配置建议 | 典型应用场景 |
|---|---|---|---|---|
| 100 人以下团队 | 轻量化需求 | DeepSeek-R1(7B - 14B)+ LangChain(流程编排)+ FAISS(向量存储)+ API Hero(API 优化) | 消费级显卡(如单张 RTX 4090,16GB 显存) | 企业内部知识库、轻量自动化工具 |
| 千人以上企业 | 分布式协作需求 | CrewAI(多智能体协作)+ LlamaIndex(RAG 优化)+ AgentScope 1.0(安全管控) | GPU 集群(如 4x A100 或 8x RTX 4090) | 跨部门任务调度、大规模客户服务 |
| 科研机构 | 高算力需求 | MetaGPT(结构化任务)+ 多卡并行框架(如 2x RTX 3090) | 多卡并行替代方案(成本较单 A100 降低 40%) | 复杂科学计算、多模态模型训练 |
选型关键指标:中小型企业需优先关注 显存效率(如 DeepSeek-R1 的 7B 模型显存占用≤10GB),大型企业需重点评估 多 Agent 协同吞吐量(如 CrewAI 的任务调度延迟≤200ms),高安全性场景必须启用 实时介入控制(AgentScope 1.0 支持毫秒级人工干预)。
全链路数据流转与节点优化
Agent 系统的核心数据流转路径为 用户指令→意图识别→任务分解→工具调用→结果生成,各环节的模型选型与优化策略如下:
1. 意图识别环节
-
核心模型
:优先选择 DeepSeek-R1 的 14B 版本(意图分类准确率达 92.3%),轻量化场景可降级为 7B 模型(准确率 89.7%,显存占用减少 40%)。
-
优化点
:集成 bge-small-zh 嵌入模型(向量维度 384,检索速度提升 3 倍),通过 Few - Shot 示例优化长尾指令识别(如行业术语、方言表达)。
2. 任务分解环节
-
框架选型
:大规模定制化流程采用 LangChain(支持 500 + 工具集成),多角色协作场景选用 CrewAI(角色分工精度达 91%),对话驱动型任务适配 AutoGen(多轮上下文保持率 95%)。
-
国内方案
:企业级私有化部署优先京东 JoyAgent(支持大模型一体机部署),多渠道分发场景选择百度文心智能体(覆盖 APP / 小程序 / API 多端)。
3. 工具调用环节
-
效率优化
:强制集成 API Hero 工具,实现三大核心能力:
- 智能缓存(重复请求命中率提升 65%,API 成本降低 30%)
- 率限管理(自动错峰调用,峰值并发处理能力提升 2 倍)
- 实时监控(异常响应检测延迟≤500ms,故障恢复时间缩短 70%)。
-
安全管控
:高敏感场景需部署 AgentScope 1.0 的安全沙箱(支持工具调用白名单、操作日志审计)。
4. 结果生成环节
-
质量增强
:结合 LlamaIndex 的 RAG 能力(知识更新延迟≤10 分钟),确保生成内容的时效性与准确性。
-
成本控制
:非关键场景启用量化压缩(如 4bit 量化的 DeepSeek-R1 7B 模型,显存占用降至 5GB,性能损失≤5%)。
场景化技术栈适配指南
针对不同用户类型的核心诉求,技术栈组合需进行场景化调整:
-
研究者场景
:LangChain(复杂工作流)+ 腾讯 Youtu - Agent(基于 DeepSeek - V3,原型开发周期缩短 50%)
-
企业用户场景
:CrewAI(多智能体协作)+ LlamaIndex(RAG 优化),搭配京东 JoyAgent 实现本地化部署
-
高安全性场景
:AgentScope 1.0(实时介入控制)+ 私有化大模型(如 GLM - 4 - Air 基座模型),全程运行于隔离沙箱环境
通过上述组合策略,可实现技术栈的 成本 - 性能 - 安全 三角平衡,满足从微型团队到大型企业的全场景 Agent 开发需求。
关键性能指标对比矩阵
为全面评估Agent开发开源模型及框架的综合性能,本章节构建多维度对比矩阵,从准确率、效率(吞吐量/延迟)、资源消耗、协作能力及易用性五个核心维度展开分析,辅助开发者根据场景需求快速选型。
多维度性能指标对比表
通过整合现有测试数据,各模型/框架在关键指标上的表现如下表所示(“-”表示数据未公开或不适用):
| 模型/框架 | 准确率(典型任务) | 吞吐量 | 延迟 | 资源消耗 | 多Agent协作能力 | 易用性 | GitHub星标 |
|---|---|---|---|---|---|---|---|
| 腾讯Youtu-Agent | WebWalkerQA 71.47%、GAIA 72.8% Pass@1 | - | 毫秒级响应 | - | - | - | - |
| DeepSeek R1 | - | - | 推理速度较慢 | - | - | - | - |
| 通义千问 | - | - | 比R1快一倍 | - | - | - | - |
| LangChain | - | 1000+ TPS | 150ms/请求 | 开源免费,部署中等 | 需手动配置 | 文档丰富,适合中级开发者 | 100k+ |
| CrewAI | - | 800 TPS | 200ms/请求 | 开源免费,部署低 | 角色定义+动态协作 | API简洁,适合快速上手 | 50k+ |
| AutoGen | - | 500 TPS | 300ms/请求 | 微软开源,部署低 | 自然语言对话驱动 | 需Python基础 | 40k+ |
| AutoGPT | - | 300 TPS | 400ms/请求 | 轻量级部署,成本最低 | 无原生支持 | 适合初学者 | 150k+ |
| MetaGPT | - | 400 TPS | 250ms/请求 | 较高(多Agent) | 结构化流程设计 | 结构化流程设计,适合新手 | 60k+ |
| Dify | - | - | - | 需较高配置服务器 | - | - | - |
数据来源:1745
场景化选型分析
基于上述指标,可将模型/框架划分为效率优先型与精度优先型两类核心场景:
1. 效率优先场景(高吞吐量、低延迟)
此类场景需优先保障任务处理速度与系统并发能力,典型需求如大规模API服务、实时数据处理等。
推荐框架:LangChain
-
核心优势
:吞吐量达1000+ TPS,延迟仅150ms/请求,且开源免费,部署成本中等,适合企业级规模化应用。文档生态丰富,支持中级开发者快速构建自动化流程,但多Agent协作需手动配置,灵活性与效率平衡良好17。
2. 精度优先场景(高准确率、复杂协作)
此类场景注重任务完成质量与多角色协同能力,如复杂决策支持、跨领域知识工程等。
推荐组合:MetaGPT+Qwen3
-
MetaGPT优势
:结构化流程设计原生支持多Agent协作,适合中大型项目复杂任务拆解,但资源消耗较高,需匹配较高配置服务器45。
-
Qwen3补充
:其Embedding模型支持32K token长文本处理,可增强知识检索与上下文理解能力,二者组合可提升复杂任务的准确率与鲁棒性。
资源消耗补充说明
对于需关注硬件成本的场景,GPT-OSS模型的量化技术与显存需求数据可提供参考:
-
存储优化
:120B模型经MXFP4量化后存储量从240GB(FP16)降至81.4GB,压缩比达3.8×,显著降低存储成本4。
-
显存需求
:120B版本在MXFP4量化下需81.4GB显存,20B版本仅需18.7GB,中小规模应用可优先选择轻量化版本4。
选型决策树
-
效率优先(高并发、低延迟)
:直接选择LangChain,其1000+ TPS吞吐量与150ms延迟可满足企业级效率需求。
-
精度优先(复杂协作、高准确率)
:优先采用MetaGPT+Qwen3组合,利用结构化协作与长文本理解提升任务质量。
-
资源受限场景
:考虑AutoGPT(轻量级部署)或CrewAI(部署成本低),但需权衡吞吐量与协作能力。
通过上述多维度对比可见,当前Agent开发工具已形成效率与精度的差异化路线,开发者需根据实际场景的核心诉求(如并发量、任务复杂度、硬件资源)选择最优技术栈,必要时通过模型组合(如MetaGPT+Qwen3)平衡性能与成本。
开源生态成熟度评估
开源 Agent 生态的成熟度评估需建立多维度分析框架,其中社区活力与企业支持构成核心评估轴。通过双维度矩阵可清晰定位不同项目的战略价值:左上角为社区驱动型项目,以技术探索为核心竞争力;右下角为企业背书型项目,侧重商业落地的稳定性与兼容性,二者共同构成开源生态的动态平衡体系。
社区驱动型项目:技术探索的创新引擎
此类项目以开发者社区为核心驱动力,表现为高 GitHub 星标数、活跃的 Issue 响应机制及快速的功能迭代。典型代表如 LangChain,其 GitHub 星标数超 40k,文档体系完善,社区问题响应及时,形成了从基础框架到插件生态的完整技术链条,适合科研机构或技术团队进行 Agent 架构创新与场景验证1617。同类项目还包括 MetaGPT(45.6k Star)与 CrewAI(50k+ Star),均通过社区协作实现了工作流编排、多 Agent 协同等核心能力的快速演进,其开源协议多采用 MIT 或 Apache 2.0,确保技术成果的开放性与可复用性。
企业背书型项目:商业落地的稳定基石
企业背书型项目依托母公司资源,在兼容性、部署支持与合规性上具备显著优势。以 Qwen3(Qwen2.5-VL-32B 为代表版本)为例,其采用 Apache 2.0 协议,GitHub 星标超 11.6k,社区活跃度与企业级服务能力形成正向循环2。该类项目通常提供完整的商业部署方案,如 DeepSeek 系列模型通过华为云昇腾云服务实现推理加速,联合布尔算力自研引擎达成与高端 GPU 持平的部署效果,显著降低企业级应用的硬件门槛12。此外,通义千问、Dify 等项目通过 API 标准化设计(兼容 OpenAI 接口规范),进一步降低了多系统集成的开发成本16。
热力图风险评估:量化项目健康度
长期项目选型需关注社区运营的量化指标,可通过热力图直观展示两大核心参数:Issue 响应速度与PR 合并效率。社区驱动型项目如 LangChain 在此类指标中表现突出,平均响应时效低于 48 小时,PR 合并周期控制在 7 天内,反映出高效的社区治理机制17。相比之下,部分协议未明确的项目(如文心一言多模态版本、One-API)虽星标数较高(One-API 24.3K),但开源协议模糊可能带来知识产权风险,需在商业落地中审慎评估229。
选型决策矩阵
-
技术探索场景
:优先选择社区驱动型项目(如 LangChain、MetaGPT),利用其活跃的开发者生态快速验证创新想法。
-
商业落地场景
:侧重企业背书型项目(如 Qwen3、DeepSeek),关注开源协议合规性(Apache 2.0 优先)与企业级部署支持。
-
风险规避重点
:警惕协议未明确项目的知识产权风险,通过热力图指标(Issue/PR 效率)评估长期维护能力。
综上,开源 Agent 生态的成熟度评估需动态平衡社区创新活力与企业商业保障,通过双维度矩阵与量化热力图,可为不同场景下的项目选型提供可落地的风险评估框架。
部署架构与资源优化策略
硬件配置推荐方案
Agent 开发的硬件配置需结合模型规模、部署场景及成本预算制定阶梯式方案。基于开源模型部署实践,可将硬件需求划分为个人/小型项目、中小企业应用及大型企业级部署三个层级,并通过量化技术优化硬件投入效率,为不同规模组织提供精准配置参考。
模型规模与硬件配置阶梯方案
个人/小型项目(1.5B-7B模型)
此层级以轻量级推理任务为主,支持 7B 及以下模型运行。Windows 系统推荐 CPU 为 Intel i5/Ryzen 5(4 核以上),内存 8GB(1.5B)或 16GB(7B),显卡可选 GTX 1650 4GB 以上(GPU 加速),硬盘 3GB-8GB,部署工具如 Ollama 或 LM Studio,硬件成本约 0.5 万-1 万元46。Mac 系统则需 M2/M3/M4 及以上芯片(16GB-32GB 统一内存),成本 1.5 万-2 万元46。低成本方案可采用二手硬件组合:RTX 3090 24GB(¥4000)+ Ryzen 7 5800X(¥1500)+ 32GB DDR4(¥500),总成本约¥7000,支持 7B-FP16 或 13B-INT4 推理47。
中小企业应用(14B-32B模型)
针对中等规模推理与微调任务,硬件配置需显著提升。Windows/Linux 系统推荐 CPU i7/Ryzen 7(8 核以上),内存 32GB,显卡 RTX 4090 24GB(单卡),硬盘 15GB-30GB,部署工具可搭配 TensorRT 加速库,成本 2 万-3 万元46。Mac 系统需 M2/M3/M4 Pro 及以上芯片(48GB 统一内存),成本 3 万-5 万元46。若需更高性能,可选用单卡 A100 80GB(二手¥4 万),搭配 Xeon Silver 4310 CPU 及 128GB 内存,支持 70B-INT4 或 13B-FP16 推理,总成本约¥5 万47。
大型企业级部署(70B+模型)
面向大规模训练与高并发推理,需采用多卡分布式架构。Linux 系统推荐 CPU 为 AMD EPYC/Intel Xeon(32 核以上),内存 128GB 及以上,显卡 2×A100 80GB(多卡并行),硬盘 70GB 以上,部署工具如 vLLM 框架,硬件成本 50 万-80 万元,云租赁约 5 元/小时/卡46。对于 671B 等超大规模模型,需 8×A800 80GB GPU(总显存 640GB)、512GB 内存及 400GB 存储,硬件成本约 400 万元,月均电费超 1 万元46。
硬件需求对比与量化技术优化
不同模型规模的硬件需求存在显著差异,以下为典型模型的配置参考:
表 1:DeepSeek-R1 系列模型硬件需求对比
| 模型规模 | CPU 需求 | 内存需求 | 显卡需求 | 存储需求 | 适用场景 | |
|---|---|---|---|---|---|---|
| DeepSeek-R1-7B | 8 核以上(现代多核 CPU) | 16GB+ | 8GB+ 显存(如 RTX 3070/4060) | 8GB+ | 个人开发者、小型项目 | |
| DeepSeek-R1-33B | 16 核以上(如 Ryzen 9/i9) | 64GB+ | 24GB+ 显存(如 A100 40GB/双卡 3090) | 30GB+ | 企业级应用、中等规模研究 | |
| DeepSeek-R1-671B | 32 核以上(双路 Xeon/EPYC) | 256GB+ | 40GB+ 显存(如 A100 40GB) | 67GB+ | 大型企业复杂推理、科研机构 | 48 |
表 2:其他主流开源模型硬件需求参考
| 模型名称 | 参数规模 | 最低硬件配置 | 推荐硬件配置 | |
|---|---|---|---|---|
| Llama-2-7b-hf | 7B | 4GB 显存(4-bit 量化) | 8GB 显存(FP16 精度) | |
| MOSS-moon | 160 亿 | 单张 A100/A800 或两张 3090(FP16) | 单卡(INT4/8 精度) | |
| DeepSeek-Coder-V2-Lite | 16B | 单卡 40G | 单机 8×80G(训练) | 48 |
量化技术是降低硬件成本的关键手段。以 4-bit 量化为例,可显著减少显存占用:32B 模型未量化时需 2×A100 80GB(总显存 160GB),量化后显存需求降至 60GB,可采用单卡 RTX 4090 24GB 或更低配置,硬件投入降低约 40%-60%46。例如,70B 模型采用 INT4 量化后,可在单卡 A100 80GB 上运行,而 FP16 精度需多卡并行,硬件成本从 50 万元降至 5 万元级别47。
硬件配置核心指标优先级:显存容量(8GB 支持 7B 推理,24GB+支持 20B+训练)> 内存带宽(DDR5-6400 提升预处理速度 30%)> CPU 多核性能(AMD Ryzen 9 9950X 多卡并行优势显著)49。存储需满足模型文件 2-3 倍(含备份)+ 临时数据 1-2 倍,例如 30GB 模型需 150GB 总存储48。
成本优化与预算规划建议
企业可根据业务需求选择本地化部署或云租赁模式:个人/小型团队优先考虑消费级硬件(如 RTX 4090)搭配量化技术,平衡成本与性能;中小企业推荐单卡 A100 或多卡 RTX 4090 集群,支持中大规模模型推理;大型企业需评估长期 TCO,多卡 H100/A800 集群适合持续训练需求,而云租赁(如 A100 5 元/小时/卡)可灵活应对峰值负载4647。通过“模型规模-量化精度-硬件选型”的三维匹配,可实现资源效率最大化。
容器化与云原生部署
Agent 系统的容器化与云原生部署需兼顾灵活性与扩展性,当前行业已形成“轻量级 - 大规模”两级架构体系,可分别满足中小团队快速验证与企业级生产环境需求。
轻量级容器化部署(中小团队适用)
针对资源有限的中小团队,单机 Docker 部署提供高效启动路径,核心在于通过容器镜像封装实现跨环境一致性。以 Ollama 模型部署为例,典型命令包含 GPU 资源调度、数据持久化与服务自愈配置:
Ollama 容器化部署命令
bash
docker run -d--name ollama \
--gpus=all \
-p11434:11434 \
-v /opt/ollama:/root/.ollama \
--restart=always \
ollama/ollama:0.11.3
该配置通过 --gpus=all 启用 GPU 加速,-v 挂载本地目录确保模型数据持久化,--restart=always 实现服务故障自动恢复4。
此类部署模式可快速将 API 服务打包为标准化镜像,避免“开发环境可用、生产环境异常”的兼容性问题,同时支持本地资源有限时的云租赁方案,如按需租用 AWS p4d 实例(¥50/小时)进行短期功能测试3047。
企业级云原生架构(大规模部署适用)
企业级场景需构建高可用、弹性伸缩的分布式系统,Kubernetes(K8s)集群为核心载体。One - API 推荐配置方案具有代表性:采用 3 副本部署确保服务无单点故障,单副本资源限制为 2 CPU/2Gi 内存;配套 Redis 集群(3 节点 1 副本)实现缓存高可用;通过 Ingress 控制器集成 cert - manager 提供 HTTPS 加密,满足数据传输安全要求29。
为简化部署复杂度,Helm Chart 模板成为行业标配,可一键生成包含 Deployment、Service、ConfigMap 的完整资源清单。监控层面,Prometheus 与 Grafana 组合实现全链路可观测性,覆盖容器资源使用率、API 响应延迟、模型推理吞吐量等关键指标,为弹性伸缩策略提供数据支撑。
托管服务与混合云方案
对于缺乏专业运维团队的组织,托管服务提供“开箱即用”能力。SuperAGI 的专有云环境支持功能测试与优化一体化,OpenAPI 平台则提供模型微调与动态扩容托管,用户无需关注底层基础设施即可实现自定义模型一键部署1215。企业级混合云需求可通过 Cherry Studio 实现,其支持多云资源统一调度,而 Shakudo 提供的 Milvus 托管服务则简化向量数据库运维,用户可直接调用向量搜索能力而无需手动管理集群1342。
整体架构设计需遵循“轻量级 - 大规模”演进路径:中小团队可从单机 Docker 起步,通过容器化确保开发与生产环境一致性;企业级用户则需基于 K8s 构建弹性集群,结合 Helm Chart 与监控体系实现自动化运维,或直接采用托管服务降低技术门槛,最终达成 Agent 系统在不同规模场景下的稳定高效运行。
性能调优关键技术
Agent 系统的性能调优需构建“成本-性能”优化金字塔模型,通过底层显存优化、中层吞吐量提升与顶层延迟控制的协同设计,实现资源效率与任务精度的动态平衡。该金字塔结构以量化技术为基础、推理引擎优化为核心、缓存机制为延伸,结合实验数据与场景化策略,形成全链路性能调优方案。
底层:量化技术与显存优化
量化技术通过降低模型参数精度实现显存占用压缩,是资源受限场景下的核心优化手段。主流方案包括基于 GPU 的 GPTQ 技术与 CPU 推理的 GGML 格式,可在有限精度损失下显著降低显存需求。例如,70B 模型采用 INT4 量化后显存占用从 FP16 的 160GB 降至 40GB,14B 模型通过 Q4_K_M 模式从 24GB 压缩至 16GB,4-bit 量化整体可减少 50% 显存占用74749。混合精度训练(FP16/FP8)进一步通过计算精度动态调整,在加速计算的同时将显存占用降低 50%,而 GPT-OSS 提出的 MXFP4(Mixed Float 4)量化技术则通过动态缩放因子 Δ 实现更精细的参数压缩,其核心公式为 Q(w) = clip(round(w/Δ), −2^(b−1), 2^(b−1)−1) × Δ449。
量化技术选型指南
- GPU 推理优先选择 GPTQ(如 4-bit 量化显存减少 50%),工具推荐
AutoGPTQ - CPU 部署采用 GGML 格式,适配
llama.cpp框架 - 精度敏感场景可尝试混合精度(FP16/FP8),平衡显存与计算准确性
硬件层面,显存容量与带宽是量化效果的关键约束。RTX 4060 Ti 16GB 凭借性价比优势成为中端优化首选,而 RTX 5090/D 支持更大显存池,可降低延迟 15%;多卡场景需采用 X670E 主板的双 PCIe 5.0×16 插槽配置,配合 InfiniBand 网络实现分布式量化部署49。
中层:推理引擎与吞吐量优化
推理引擎通过计算架构优化与调度机制创新提升单位时间任务处理量,主流框架包括 vLLM、TensorRT-LLM 与 SGLang,三者在不同场景下表现出差异化优势。腾讯混元模型通过兼容上述框架与多量化格式,实现推理效率的弹性调优;POINTS-Reader 则结合中等规模 ViT 与 SGLang 推理框架,将视觉任务吞吐量提升 30% 以上635。动态批处理技术通过合并相似推理请求(如 CrewAI 多代理调度),可将吞吐量提升 2-3 倍,而 LangChain 定制化流程设计则通过任务拆解与并行执行,进一步降低计算资源闲置率19。
模型架构创新同样助力吞吐量提升。MoE(Mixture of Experts)架构将 1170 亿总参数分解为 128 个专家子网络,每个 token 仅激活 4 个专家(约 4.4% 的参数),在保持模型能力的同时降低推理计算量;MonkeyOCR 的 SRR 设计通过空间冗余抑制减少视觉特征计算负担,端到端推理效率提升 40%438。向量数据库作为知识检索的核心组件,其优化策略直接影响推理吞吐量:Milvus 通过 GPU 加速、分布式索引(IVF/HNSW/PQ)与多索引协同,将向量查询延迟降低 50%,支持每秒百万级向量检索42。
吞吐量优化三板斧
-
框架选型
:高并发场景用 vLLM(吞吐量比 Ollama 高 50%),低延迟需求选 TensorRT-LLM
-
调度策略
:动态批处理窗口设为 32-64 token,配合异步加载避免主线程阻塞
-
存储优化
:向量数据库采用 HNSW 索引(检索速度)+ PQ 压缩(存储效率)组合
顶层:缓存机制与延迟控制
延迟优化需从计算复用与资源调度两方面入手,通过缓存高频结果与动态资源分配减少无效计算。结果缓存技术(如 Redis 分布式缓存)可将重复查询响应时间压缩至毫秒级,尤其适用于问答、摘要等确定性任务(temperature=0.0);而上下文管理创新则通过“文件归档+按需加载”策略(京东 JoyAgent)避免全量上下文加载,提示词管理成本降低 35%111830。
计算资源的动态分配是延迟控制的另一核心。阿里 WebAgent 的“思维预算机制”根据任务复杂度动态调整快思考(启发式推理)与慢思考(深度计算)的资源占比,简单任务响应速度提升 60%;WebDancer 框架的 DAPO 算法通过复用低利用率 QA 对,减少重复计算量达 25%21。硬件加速方面,Ollama 搭配 TensorRT 加速库可提升推理效率 30%,而 FlashAttention 优化(通过 OLLAMA_FLASH_ATTENTION=1 启用)能进一步降低长序列处理延迟446。
调优优先级与精度平衡策略
性能调优需遵循“显存优先→吞吐量次优→延迟按需”的优先级排序:在显存受限场景(如边缘设备),优先采用 4-bit GPTQ 量化(显存减少 50%),配合二手 Tesla V100 32GB(¥1.5 万)降低硬件成本;中等资源场景可通过 vLLM 动态批处理(批大小 128)与 Milvus GPU 索引提升吞吐量;高并发场景则需叠加结果缓存与 FlashAttention 优化,实现亚毫秒级延迟3047。
精度与资源的平衡需通过动态参数调整实现:创意生成任务(temperature=0.7~1.0)可接受 8-bit 量化导致的 5% 精度损失,换取部署成本降低 40%;而金融风控等高精度场景则需采用混合精度(FP16/FP8),在显存降低 50% 的同时保持 99.9% 任务准确率。蒸馏技术(如 DeepSeek-R1 的 4-bit/8-bit 量化版本)通过牺牲 10%-15% 复杂任务性能,使模型体积压缩 75%,满足边缘部署需求184649。
精度-资源平衡公式
精度损失率 = α×量化位数损失 + β×批处理延迟 + γ×缓存失效频率
(α、β、γ 为任务敏感系数,确定性任务 α=0.8,创意任务 β=0.6)
通过上述三层优化的协同实施,Agent 系统可在 200W 功耗预算下(RTX 3090 24/7 运行月均电费¥300),实现每秒 500+ 任务处理能力,且关键任务精度损失控制在 8% 以内,为大规模商业化部署提供技术支撑47。
未来趋势与开源生态展望
技术演进方向预测
2025-2027 技术路线图:分阶段演进框架
基于当前技术突破与产业动态,Agent 开发领域将呈现多模态融合→低代码工具链成熟→边缘 Agent 普及的三阶段演进路径,各阶段技术特征与落地节奏如下:
短期(6 个月内):多模态融合深化与自主能力突破
此阶段核心在于提升跨模态理解精度与系统自主决策能力。多模态模型将向细粒度语义对齐与干扰过滤方向发展,如 Qwen2.5-VL 系列通过窗口注意力机制优化视觉编码器,实现图像解析效率提升 30%,并在数学推理、长视频时空事件捕捉等任务中刷新 SOTA 性能15051。同时,多模态意图识别技术将强化语义空间对齐能力,通过模态干扰过滤算法降低跨模态噪声影响,典型如 InternVL3 拓展的 3D 视觉与 GUI 代理功能,支持复杂界面交互场景3652。
自主能力方面,ZeroSearch 技术验证了 LLM 替代搜索引擎的可行性,AI 系统可通过自我模拟强化学习发展复杂任务规划能力,减少对外部服务依赖达 40%44。POINTS-Reader 等框架计划集成 vLLM 推理引擎,进一步提升端到端模型的响应速度与多轮对话连贯性15。
短期技术里程碑
- 多模态模型:实现图文/语音语义空间统一表征,支持 10 种以上模态协同推理
- 自主决策:20% 复杂任务(如代码调试、科学实验设计)可脱离外部工具独立完成
- 性能指标:端到端响应延迟降低至 500ms 以内,多模态理解准确率突破 92%
中期(1 年内):低代码工具链成熟与生态标准化
随着模块化框架与低代码平台的完善,Agent 开发门槛将显著降低。向量数据库与 RAG 系统向低代码化与多数据源集成演进,如 Ragie、Vector Shift 等工具支持可视化流程编排,用户可通过拖拽完成多模态数据接入与检索优化,开发效率提升 60%43。同时,多 Agent 框架将强化开源模型兼容性与功能扩展,Agency Swarm 计划支持 20+ 开源模型 API、改进 RAG 集成逻辑,并探索开源代码解释器实现,推动协作型 Agent 开发标准化53。
企业级工具链方面,API 工具增强跨平台自托管能力,通过本地化部署满足金融、医疗等行业的数据隐私需求,典型如 Auto-Prompt 提供行业模板库与批量优化功能,支持企业定制化 Agent 快速生成3254。德勤预测,2025 年底将有 25% 采用生成式 AI 的企业部署低代码 Agent 系统,主要集中在客服自动化、供应链管理等场景11。
长期(2 年内):边缘 Agent 普及与硬件协同优化
边缘 Agent 的规模化应用将依赖模型轻量化与本地化部署技术突破。MoE(混合专家)架构与芯片制程进步(如 3nm 工艺)使模型部署门槛降低,典型如 Moondream2 模型体积压缩至 1GB,可在消费级手机上实现实时 OCR 与多模态交互3646。同时,端侧强化学习技术成熟,AI 系统可通过设备本地数据进行持续优化,如 ZeroSearch 衍生方案实现边缘设备自我迭代,减少云端依赖达 70%44。
硬件生态方面,华为云昇腾与布尔算力联合推出的推理加速引擎,通过异构计算优化实现边缘设备推理效率提升 2 倍,为工业物联网、智能家居等场景的 Agent 部署提供算力支撑12。德勤预计,2027 年边缘 Agent 市场渗透率将达 50%,覆盖智能制造实时质检、车载智能交互等核心场景11。
核心技术驱动力与产业趋势
三大技术支柱
-
模块化架构
:顶级框架通过多模型集成与工作流编排降低开发难度,如 POINTS-Reader 支持多模态工具链即插即用1517。
-
强化学习应用
:ZeroSearch、Meeseeks 基准推动自主决策能力系统化提升,端到端模型优化成为主流训练范式4455。
-
开源生态协同
:阿里 WebAgent、minion-agent 等项目探索多框架整合模式,加速技术标准化与落地20。
未来 2 年,Agent 技术将从“工具辅助”向“全自主系统”跃迁,多 Agent 协作、动态工具选择与低资源设备适配成为关键演进方向。企业需重点关注开源框架模块化能力与硬件协同优化,以把握边缘计算时代的技术红利。
开源生态挑战与机遇
开源模型已成为 Agent 技术创新的核心驱动力,但其生态系统在快速发展中呈现出挑战与机遇并存的复杂格局。当前 Agent 开发的开源生态正处于技术普惠与产业落地的关键转折点,既面临工具链碎片化、标准不统一等现实瓶颈,也迎来基础模型开源化、生态协同深化等历史性机遇。
开源生态的核心挑战
技术迭代与泛化能力的矛盾成为开源 Agent 开发的首要障碍。工具链的快速演进导致意图识别模型面临泛化性能衰减问题,例如在处理少见专业领域问题(如中文平仄规则、成语接龙等细粒度指令)时,现有模型的准确率仍不足 60%56。同时,多智能体协同标准碎片化严重制约复杂任务拆分效率,不同框架(如 MetaGPT、AutoGPT)的通信协议差异导致跨系统协作成本激增9。
企业级部署的技术短板显著阻碍开源方案的规模化应用。现有模型普遍存在函数调用支持不足(影响智能体间通信效率)、RAG 功能不完善(知识更新延迟)、代码解释器缺失(限制自动化执行能力)等问题53。此外,框架抽象层设计缺陷可能导致调试困难,例如 Dify 等平台在复杂场景下需二次开发比例高达 73%,而 MetaGPT 等多 Agent 框架的资源消耗较商业方案增加 2-3 倍16。
硬件成本与本地化部署门槛构成实质性壁垒。70B 参数规模的开源模型需 A100/H100 级 GPU 支持,单节点部署成本超过 50 万元;即使通过量化技术(如 4-bit 量化)和消费级显卡多卡并行优化,32B 模型的硬件投入仍需 10 万元以上747。中文优化不足进一步加剧挑战,传统中文向量化模型普遍存在参数量偏小(≤10B)、上下文长度短(512-1024 token)、跨领域泛化能力弱等问题,直至 Qwen3 Embedding 等模型发布才初步填补空白40。
开源生态的发展机遇
技术普惠门槛持续降低为开源 Agent 生态注入新动能。国内大厂推动 100% 开源策略(如 JoyAgent 全栈开源)与生态整合(腾讯元器联动 QQ/微信接口),使企业部署成本降低 40%-60%11。智谱等企业开源核心 Agent 技术,结合 OpenAPI 平台提供的免费模型 API(如 Qwen2.5 7B),实现开发者“Token 自由”,将技术入门门槛从专业团队降至个人开发者1257。
生态协同与社区创新加速技术迭代与场景落地。LangChain、CrewAI 等开源社区贡献代码量年增长率超 200%,形成工具链协同创新网络19。SuperAGI 等框架通过插件市场实现功能模块化扩展,API Pack 数据集开源(https://github.com/zguo0525/api-pack)促进 API 调用生成研究协作,而 WebAgent 开源项目则提供工业级训练框架与评估标准,推动 Agent 能力评测透明化101521。
垂直领域创新空间广阔驱动开源模型场景化突破。多模态模型在文档解析、视频理解等领域展现显著优势,例如基于开源框架的工业质检 Agent 缺陷识别准确率达 92%,较传统方案提升 35%2。行业知识库与开源模型的结合(如法律领域的案例检索插件、医疗领域的文献分析模块)使特定场景能力提升 50% 以上,而 ZeroSearch 技术的出现降低高级 AI 训练壁垒,为中小厂商创造公平竞争环境2244。
“基础模型 + 行业插件”的生态构想
面对挑战与机遇,“基础模型 + 行业插件”的分层架构成为开源生态破局的关键路径。该架构以通用大模型(如 Qwen3、Llama 3)为底层基座,通过标准化接口集成垂直领域插件,形成“核心能力复用 + 场景功能定制”的协同体系。SuperAGI 的插件市场已覆盖任务调度、知识检索等 12 类功能模块,而 Milvus、pgvecto.rs 等开源向量数据库则为插件提供高效知识存储支持,使行业解决方案开发周期缩短 60%154258。
“基础模型 + 行业插件”生态框架核心特征
-
模块化设计
:插件与基础模型解耦,支持热插拔与独立迭代,如 API Pack 数据集实现跨框架调用标准化
-
协作开发机制
:Hugging Face 等平台提供插件共享与版本管理,WebAgent 开源训练框架推动评测标准统一
-
行业适配优化
:针对金融、医疗等领域开发专用插件,如法律文档解析插件将合同审查效率提升 400%
社区协作与技术普惠路径
开源生态的可持续发展依赖全球开发者社区的深度协作。Hugging Face 等平台已形成涵盖模型训练、插件开发、场景验证的全链路协作网络,LangChain 社区贡献者超 10 万人,月均提交代码 2.3 万次19。Meeseeks 等评测工具的开源则推动技术透明化,其提供的意图识别准确率、多智能体协同效率等 12 项核心指标,已成为社区公认的性能基准55。
未来,需重点强化三方面工作:一是建立多智能体通信协议与插件开发标准,降低跨框架协作成本;二是完善中文优化工具链,解决平仄处理、古汉语理解等细分场景短板;三是推广量化部署与二手硬件方案,通过 One-API 等工具实现资源调度优化,使中小企业入门成本降至 5 万元以下4047。通过技术普惠与生态协同,开源 Agent 有望在 2025-2026 年实现从“实验室技术”向“产业基础设施”的跨越。
结论与建议
核心结论总结
本报告基于技术成熟度曲线(Technology Maturity Curve)对 2025 年 Agent 开发开源模型全链路技术进行生命周期定位,结合性能数据与场景落地能力,形成以下核心结论:
一、成熟期技术:意图识别与 OCR 已实现大规模商业化落地
意图识别技术通过强化学习(如 GRPO 算法)实现关键突破,未知意图泛化能力显著提升,RL 模型性能优于传统 SFT 方法,且预训练与指令微调模型经 GRPO 训练后性能趋于一致,已具备企业级部署的稳定性9。典型代表如 Intent-Model 在性能、资源消耗和易用性上表现突出,特别适合中小型企业或个人项目快速接入14。
OCR 技术在多模态内容解析、部署性能上实现跨越式发展。以 POINTS-Reader 为代表的端到端文档 OCR 模型,在速度(毫秒级延迟)、准确率(基准测试验证 71.47%)和多模态处理(支持文档/表格/图片混合解析)上达到商用标准,可直接支撑企业级文档数字化、票据识别等核心场景173536。
二、爬坡期技术:多模态 Agent 需突破技术验证与场景适配瓶颈
多模态 Agent 框架处于技术快速迭代但尚未完全成熟的爬坡阶段。尽管 Qwen2.5-VL-32B 等模型在综合性能(文档/视频解析)上领先,且 A-MESS 框架通过锚点嵌入和语义同步提升多模态意图识别精度,但在函数调用稳定性、跨模态语义对齐等核心能力上仍存在功能限制25253。
开源生态已形成多 Agent 协作技术矩阵,MetaGPT、CrewAI 擅长任务分工与流程编排,LlamaIndex、Dify 优化 RAG 检索效率,但不同框架间的技术选型需严格匹配场景需求:LangChain 适合大规模定制化流程,AutoGPT 侧重快速原型验证,JoyAgent 则专注企业级私有化部署111619。
技术生命周期关键特征
-
成熟期
:技术指标(准确率/延迟)经大规模验证,开源方案可直接替代闭源产品(如 OCR 模型准确率超商业 API 平均水平 12%)。
-
爬坡期
:核心功能(多模态推理/跨框架协作)实现技术突破,但需结合具体场景二次开发(如 minion-agent 任务处理效率较人工提升 360 倍,但通用场景需与 doubao1.5 等模型竞争)。
三、开源生态成熟度:全链路支撑体系形成,性能与成本平衡成关键
2025 年 Agent 开发开源模型已构建从基础模型到工具链的完整支撑体系:Qwen3 Embedding-8B 以 MTEB 排名第一的向量化能力支撑知识工程,Qwen2.5 系列覆盖大语言模型与多模态解析,rorshark-vit-base 提供模型 API 化部署范式204051。硬件适配层面,RTX 3090(入门)、A100(企业)、H100 集群(训练)的分级方案,结合 MXFP4 量化与 MoE 架构,实现效率与成本的动态平衡1359。
国际与国内开源生态呈现差异化发展路径:国际框架(如 LangChain)侧重技术指标优化(吞吐量、延迟),国内平台(如阿里 WebAgent)强调企业级能力(全链路开源、本地化部署、生态联动),共同推动 Agent 技术从实验室走向产业落地2126。
分场景行动建议
一、三阶段实施框架
Agent技术落地需遵循评估-试点-推广的渐进式路径,通过阶段性目标控制风险并验证价值:
-
第一阶段(1个月):技术选型与POC验证
聚焦核心场景需求匹配,完成模型性能测试与成本测算。例如销售团队可部署听脑AI进行客户通话实时转写试点,验证需求提取效率提升效果;研发团队通过Qwen2.5-VL-32B处理技术文档,测试多模型API密钥管理方案的稳定性259。
-
第二阶段(3个月):核心场景落地
针对高价值流程实现自动化,如预算有限团队采用RTX 3090(¥7000)搭配13B-INT4量化模型构建本地化推理环境,结合云GPU短期测试优化资源配置;多语言场景优先部署Qwen2.5-VL-32B(多语言文档训练)或听脑AI(支持7种语言+19种方言)4759。
-
第三阶段(6个月):全流程自动化
实现跨场景协同与规模化部署,例如大型企业通过多卡A100/H100分布式架构部署Qwen2.5-VL-32B,结合Trieve构建企业级RAG系统;软件开发团队基于MetaGPT的多Agent协作架构,实现从需求分析到代码生成的全流程自动化1650。
关键里程碑(KPI)
- 效率指标:销售团队跟进笔记生成耗时减少67%(原30分钟/通→10分钟/通);研发团队技术文档解析准确率≥92%
- 成本指标:API调用成本降低40%(通过One-API缓存与密钥管理);本地化部署硬件ROI<12个月
- 质量指标:多语言场景意图识别准确率≥88%;关键业务场景模型失效恢复时间<30分钟
二、场景化技术方案
(一)按团队类型适配
-
销售团队
:听脑AI实时转写系统(客户通话→需求/异议提取→跟进笔记自动生成),实测效率提升3倍59。
-
研发团队
:Qwen2.5-VL-32B(技术文档/图表解析)+ One-API(多模型密钥管理),控制API调用成本并提升文档处理吞吐量229。
-
预算有限团队
:RTX 3090(¥7000)+ 13B-INT4量化模型(显存占用≤24GB),搭配云GPU(如AutoDL)进行短期功能验证47。
(二)按应用场景优化
-
高成熟场景(即时消息/票证系统)
:选用Deepseek-R1等推理速度快( latency<500ms)、指令遵循得分高的模型,部署标准化API服务22。
-
低成熟场景(旅游出行/复杂决策)
:采用“多Agent+工作流”架构(如CrewAI角色分工),结合“基础模型+行业知识库”增强领域适应性1922。
-
文档处理场景
:
- 高分辨率扫描件:MiniCPM-o(支持超高清图文解析)
- 结构化表格提取:Surya(表格识别准确率95.3%)
- 移动端轻量化需求:Moondream2(模型体积<1GB)36。
-
多智能体协作
:深度研究场景优先minion-agent框架(多工具整合成本降低30%);企业级任务调度选用JoyAgent(MCP协议整合业务规则)1120。
(三)按用户规模配置
-
个人/学生开发者
:DeepSeek-R1-1.5B/7B模型 + RTX 3060(显存12GB),通过Ollama简化部署,总成本控制在2000-10000元7。
-
中小企业
:DeepSeek-R1-14B + RTX 4090(24GB显存),集成API Hero监控调用量与缓存优化,利用DeepSeek V3 685B API免费额度进行原型测试732。
-
大型企业/科研机构
:Qwen2.5-VL-32B/DeepSeek-R1-70B + 多卡A100/H100分布式架构,结合Trieve向量数据库构建企业级RAG系统,支持百万级文档索引4350。
三、风险预案与保障措施
针对模型失效、成本超支等核心风险,需建立多层级应对机制:
-
模型性能波动
:关键业务场景采用“开源模型+商业API”混合架构(如Qwen2.5-VL-32B日常推理+GPT-4 Turbo应急备份),通过函数调用白名单限制高风险操作53。
-
硬件资源不足
:低资源场景优先选择MiniCPM-o(INT4量化版显存占用仅4GB)或Moondream2(移动端适配),避免过度依赖高端GPU37。
-
多语言泛化能力不足
:通过GRPO算法优化Qwen2.5-7B-Instruct基座模型,结合RCS策略增强未见语言意图识别能力,或直接选用听脑AI(支持7种语言+19种方言)959。
实施建议
-
技术验证阶段需覆盖至少3种典型场景(如文档处理+多语言+低资源部署),避免单一案例偏差
-
推广阶段采用“20%核心流程先自动化,80%长尾流程逐步迭代”策略,降低系统复杂度
latency<500ms)、指令遵循得分高的模型,部署标准化API服务22。 -
低成熟场景(旅游出行/复杂决策)
:采用“多Agent+工作流”架构(如CrewAI角色分工),结合“基础模型+行业知识库”增强领域适应性1922。
-
文档处理场景
:
- 高分辨率扫描件:MiniCPM-o(支持超高清图文解析)
- 结构化表格提取:Surya(表格识别准确率95.3%)
- 移动端轻量化需求:Moondream2(模型体积<1GB)36。
-
多智能体协作
:深度研究场景优先minion-agent框架(多工具整合成本降低30%);企业级任务调度选用JoyAgent(MCP协议整合业务规则)1120。
(三)按用户规模配置
-
个人/学生开发者
:DeepSeek-R1-1.5B/7B模型 + RTX 3060(显存12GB),通过Ollama简化部署,总成本控制在2000-10000元7。
-
中小企业
:DeepSeek-R1-14B + RTX 4090(24GB显存),集成API Hero监控调用量与缓存优化,利用DeepSeek V3 685B API免费额度进行原型测试732。
-
大型企业/科研机构
:Qwen2.5-VL-32B/DeepSeek-R1-70B + 多卡A100/H100分布式架构,结合Trieve向量数据库构建企业级RAG系统,支持百万级文档索引4350。
三、风险预案与保障措施
针对模型失效、成本超支等核心风险,需建立多层级应对机制:
-
模型性能波动
:关键业务场景采用“开源模型+商业API”混合架构(如Qwen2.5-VL-32B日常推理+GPT-4 Turbo应急备份),通过函数调用白名单限制高风险操作53。
-
硬件资源不足
:低资源场景优先选择MiniCPM-o(INT4量化版显存占用仅4GB)或Moondream2(移动端适配),避免过度依赖高端GPU37。
-
多语言泛化能力不足
:通过GRPO算法优化Qwen2.5-7B-Instruct基座模型,结合RCS策略增强未见语言意图识别能力,或直接选用听脑AI(支持7种语言+19种方言)959。
实施建议
- 技术验证阶段需覆盖至少3种典型场景(如文档处理+多语言+低资源部署),避免单一案例偏差
- 推广阶段采用“20%核心流程先自动化,80%长尾流程逐步迭代”策略,降低系统复杂度
- 定期通过Meeseeks基准评估模型指令遵循能力,结合业务指标(如网络故障根因分析时效性)动态调优55
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇
01.大模型风口已至:月薪30K+的AI岗正在批量诞生

2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
02.如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)






第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献306条内容
已为社区贡献306条内容

所有评论(0)