LangChain + MCP + vLLM + Qwen3-32B 构建本地私有化智能体应用,大模型入门到精通,收藏这篇就足够了!
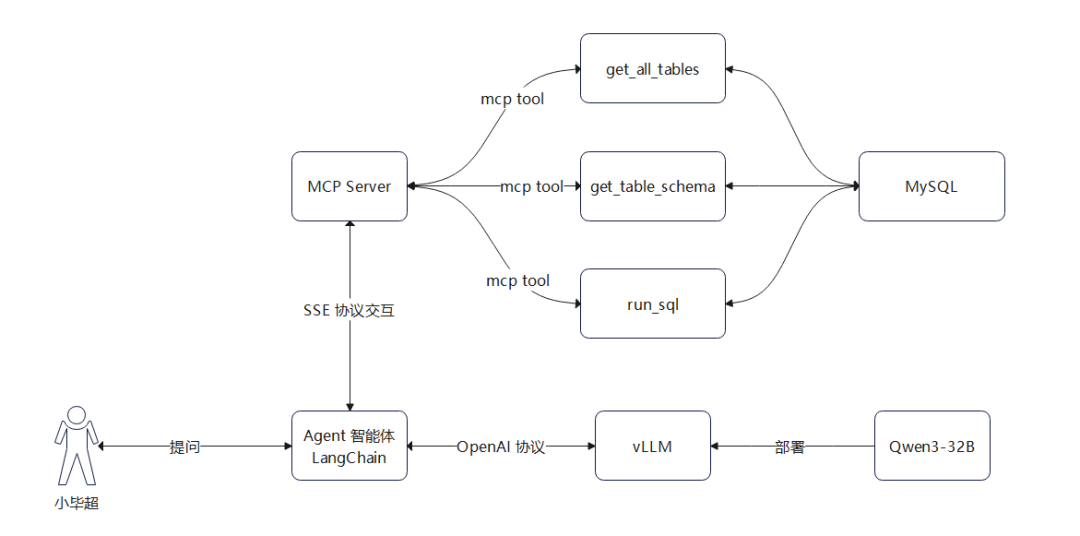
在本专栏的前面文章基于Spring AI MCP实现了本地 ChatBI 问答应用,本文还是依据该场景,采用 LangChain + vLLM + Qwen3-32B + MCP 技术栈构建该流程
一、私有化智能体应用
在本专栏的前面文章基于Spring AI MCP实现了本地 ChatBI 问答应用,本文还是依据该场景,采用 LangChain + vLLM + Qwen3-32B + MCP 技术栈构建该流程,整体过程如下图所示:
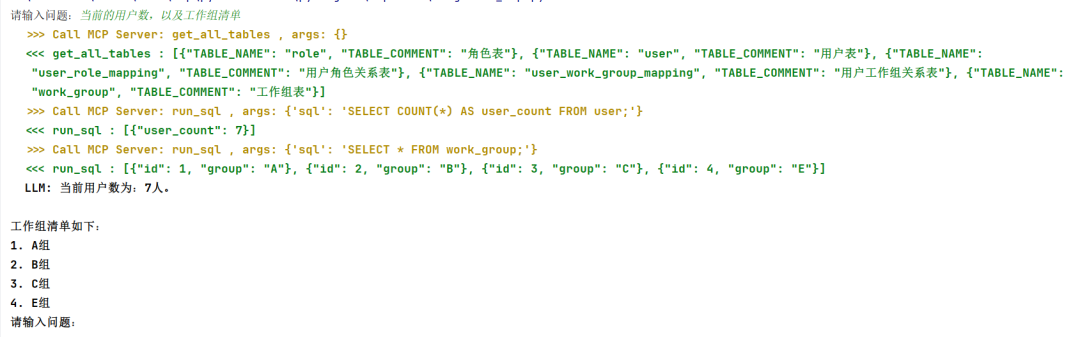
实现效果如下所示:
关于 MySQL 表结构的创建,可以参考下面这篇文章:
Spring AI MCP Server + Cline 快速搭建一个数据库 ChatBi 助手
小毕超,公众号:狂热JAVA小毕超Spring AI MCP Server + Cline 快速搭建一个数据库 ChatBi 助手
实验所使用依赖的版本如下:
torch==2.6.0
transformers==4.51.3
modelscope==1.23.1
vllm==0.8.4
mcp==1.9.2
openai==1.75.0
langchain==0.3.25
langchain-openai==0.3.18
langgraph==0.4.7
pymysql==1.0.3
二、vLLM 部署 Qwen3-32B
使用 modelscope 下载 Qwen3-32B 模型到本地:
modelscope download --model="Qwen/Qwen3-32B" --local_dir Qwen3-32B
vLLM 读取模型启动API服务。
export CUDA_VISIBLE_DEVICES=0,1
vllm serve "Qwen3-32B" \
--host 0.0.0.0 \
--port 8060 \
--dtype bfloat16 \
--tensor-parallel-size 2 \
--cpu-offload-gb 0 \
--gpu-memory-utilization 0.8 \
--max-model-len 8126 \
--api-key token-abc123 \
--enable-prefix-caching \
--enable-reasoning \
--reasoning-parser deepseek_r1\
--enable-auto-tool-choice \
--tool-call-parser hermes \
--trust-remote-code
关键参数说明:
- •
export CUDA_VISIBLE_DEVICES=0,1:指定所使用的GPU。 - •
dtype: 数据类型,其中bfloat16,16位浮点数,适合NVIDIA A100等设备。 - •
tensor-parallel-size:Tensor并行的数量,当多GPU分布式推理时使用,建议和GPU的数量一致。 - •
cpu-offload-gb:允许将部分模型权重或中间结果卸载到CPU的内存中,单位为GB。,模拟GPU内存扩展,如果部署的模型大于了显存大小可以设置该参数,但是推理速度会大大下降。 - •
gpu-memory-utilization:设置GPU内存利用率的上限。 - •
max-model-len:允许模型最大处理的Token数,该参数越大占用显存越大。 - •
enable-prefix-caching:启用前缀缓存减少重复计算。 - •
enable-reasoning:启用思考推理能力。 - •
reasoning-parser deepseek_r1:指定推理解析器。 - •
enable-auto-tool-choice:启用 function call 模式。 - •
tool-call-parser hermes:设置 function call 的解析器。
显存占用情况:
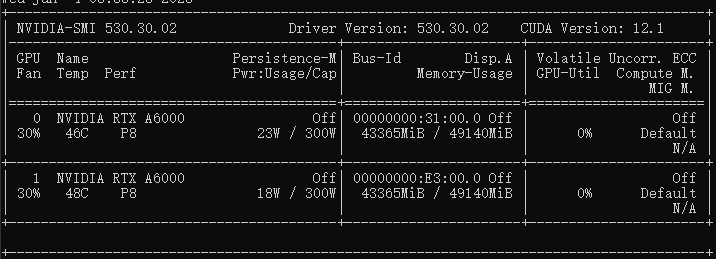
如果启动显存不足,可适当调整 gpu-memory-utilization 和 max-model-len 参数,或通过 cpu-offload-gb 将部分模型权重卸载到内存中。
启动成功后,可通过 /v1/models 接口可查看模型列表:
curl http://127.0.0.1:8060/v1/models -H "Authorization: Bearer token-abc123"

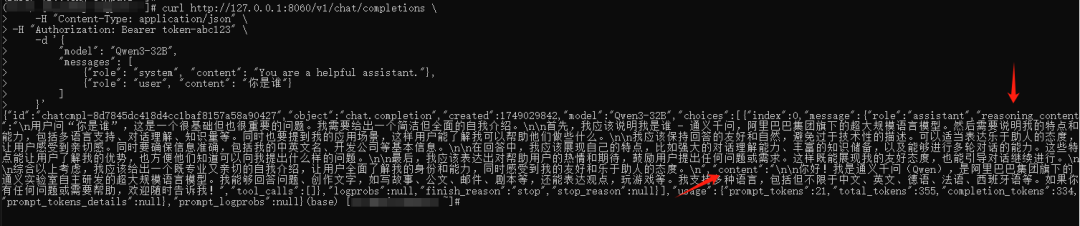
测试API交互,思考模式:
curl http://127.0.0.1:8060/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "Qwen3-32B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁"}
]
}'
非思考模式测试:
curl http://127.0.0.1:8060/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "Qwen3-32B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁/no_think"}
]
}'

三、构建DB MCP Server
在 MCP Server 端,依据上面图片的规划,包括三个 MCP Tool ,分别是 获取所有可用的表名:get_all_tables、根据表名获取:Schema get_table_schema、执行SQL:run_sql ,交互协议选择 SSE 模式。
首先实现数据库操作,这里仅仅做了数据库的交互,实际使用你应考虑很多性能细节的优化:
utils_db.py
import pymysql
defget_conn():
return pymysql.connect(
host="127.0.0.1",
port=3306,
database="langchain",
user="root",
password="root",
autocommit=True
)
defquery(sql):
conn = get_conn()
cursor = conn.cursor()
cursor.execute(sql)
columns = [column[0] for column in cursor.description]
res = list()
for row in cursor.fetchall():
res.append(dict(zip(columns, row)))
cursor.close()
conn.close()
return res
db_mcp_server.py
import json
from mcp.server.fastmcp import FastMCP
import utils_db
mcp = FastMCP("DB Mcp Server")
all_tables_sql = "SELECT TABLE_NAME, TABLE_COMMENT FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'langchain'"
schema_sql = """
SELECT COLUMN_NAME, DATA_TYPE, COLUMN_COMMENT FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'langchain' AND TABLE_NAME = '{table}'
"""
@mcp.tool()
defget_all_tables() -> str:
"""获取所有可用的表名"""
return json.dumps(utils_db.query(all_tables_sql), ensure_ascii=False)
@mcp.tool()
defget_table_schema(table_names: list[str]) -> str:
"""根据表名获取Schema"""
table_schema = []
for table in table_names:
schemas = utils_db.query(schema_sql.format(table=table))
schemas = ", \n".join([f"{s['COLUMN_NAME']}{s['DATA_TYPE']} COMMENT {s['COLUMN_COMMENT']}"for s in schemas])
table_schema.append(f"{table} ({schemas})")
return"\n\n".join(table_schema)
@mcp.tool()
defrun_sql(sql: str) -> str:
"""执行SQL查询数据,一次仅能执行一句SQL!"""
try:
return json.dumps(utils_db.query(sql), ensure_ascii=False)
except Exception as e:
returnf"执行SQL错误:{str(e)} ,请修正后重新发起。"
if __name__ == "__main__":
mcp.settings.port = 6030
mcp.run("sse")
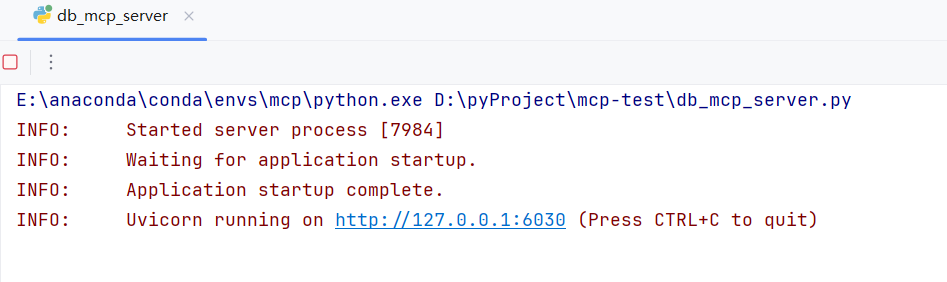
启动 MCP Server 服务:
四、Langchain 构建 MCP Client Agent 智能体
官方关于 MCP 的集成介绍文档:
https://langchain-ai.github.io/langgraph/agents/mcp/
实现过程:
import os, config
os.environ["OPENAI_BASE_URL"] = "http://127.0.0.1:8060/v1"
os.environ["OPENAI_API_KEY"] = "token-abc123"
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
import asyncio
from colorama import Fore, Style, init
asyncdefmain():
client = MultiServerMCPClient(
{
"db": {
"url": "http://127.0.0.1:6030/sse",
"transport": "sse",
}
}
)
tools = await client.get_tools()
checkpointer = InMemorySaver()
agent = create_react_agent(
"openai:Qwen3-32B",
tools,
checkpointer=checkpointer
)
config = {
"configurable": {
"thread_id": "1"
}
}
whileTrue:
question = input("请输入问题:")
ifnot question:
continue
if question == "q":
break
asyncfor chunk in agent.astream(
{
"messages": [
{
"role": "user",
"content": question
}
]
},
config=config,
stream_mode="updates"
):
if"agent"in chunk:
content = chunk["agent"]["messages"][0].content
tool_calls = chunk["agent"]["messages"][0].tool_calls
if tool_calls:
for tool in tool_calls:
print(Fore.YELLOW, Style.BRIGHT, f">>> Call MCP Server: {tool['name']} , args: {tool['args']}")
else:
print(Fore.BLACK, Style.BRIGHT, f"LLM: {content}")
elif"tools"in chunk:
content = chunk["tools"]["messages"][0].content
name = chunk["tools"]["messages"][0].name
print(Fore.GREEN, Style.BRIGHT, f"<<< {name} : {content}")
if __name__ == '__main__':
asyncio.run(main())
运行智能体,开始测试。
四、智能体问答测试
提问:当前的用户数,以及工作组清单
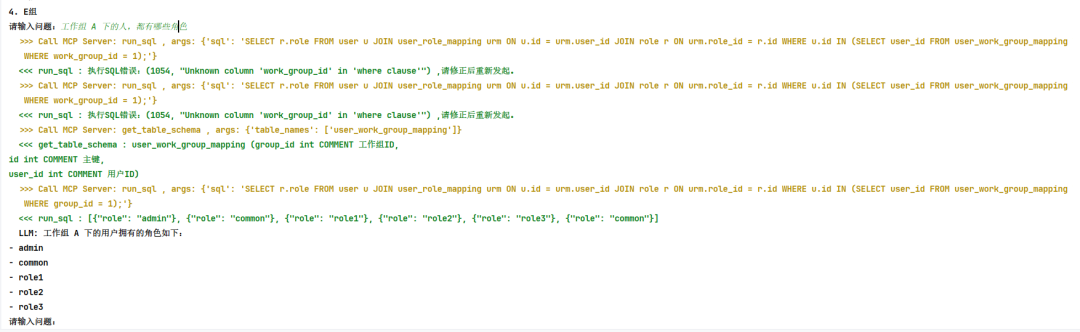
提问:工作组 A 下的人,都有哪些角色
可以看到执行过程,当发现错误后,能够及时的纠正,进而得到正确的结果:
提问:role1 下的有哪些人

想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献314条内容
已为社区贡献314条内容

所有评论(0)