【自然语言处理与大模型】大模型应用开发四个场景
大模型应用开发的4个场景:纯大模型对话、RAG、Agent、微调。
大模型应用技术有个特点,就是门槛低但天花板高。一方面,预训练模型直接把技术门槛拉低了,API接口开箱就能用,还有好多开源社区资源能帮忙,prompt工程方法也特别直观,上手快。另一方面,天花板又特别高,想深度定制的话能通过模型微调来搞,还能处理多模态任务,如果你有持续学习和迭代的本事,甚至能整合起来构建复杂的业务系统。而且用起来优势很明显,想快速验证基础功能完全没问题,也能一步步慢慢深化技术。
一、基于RAG架构的开发
(1)背景
- 大模型的知识冻结
- 大模型幻觉
而RAG就可以非常精准的解决这两个问题
举例:
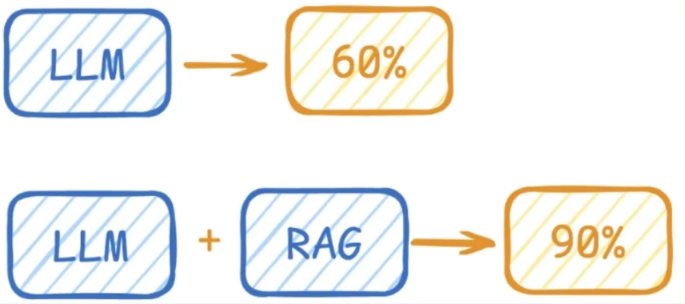
LLM在考试的时候面对陌生的领域,答复能力有限。然后就准备放飞自我了。而此时RAG给了一些提示和思路,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%提升到了90%。
(2)什么是RAG?
Rerieval-Augmented Generation (检索增强生成)
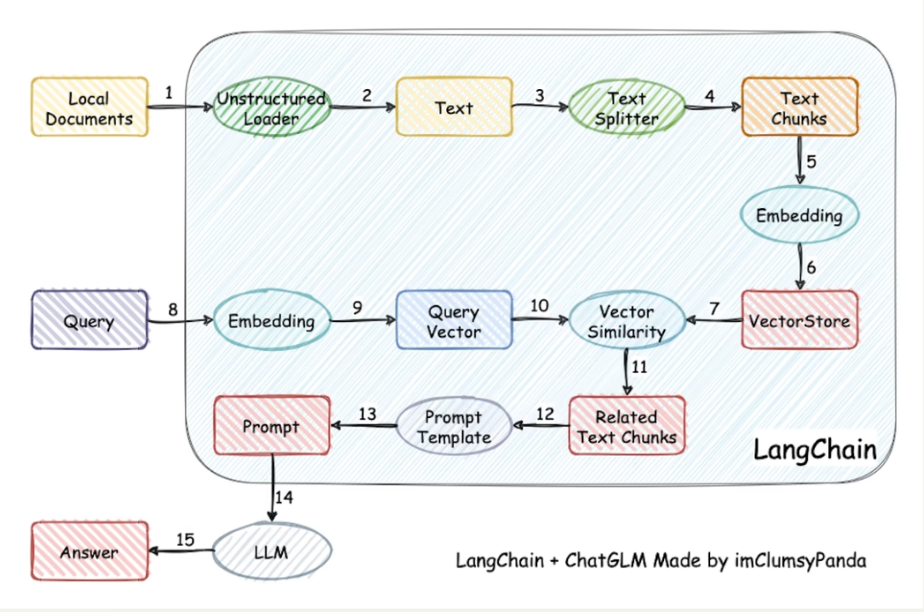
检索-增强-生成的过程:检索可以理解为第10步。增强理解为第12步(这里的提示词包含检索到的数据),生成理解为第15步。
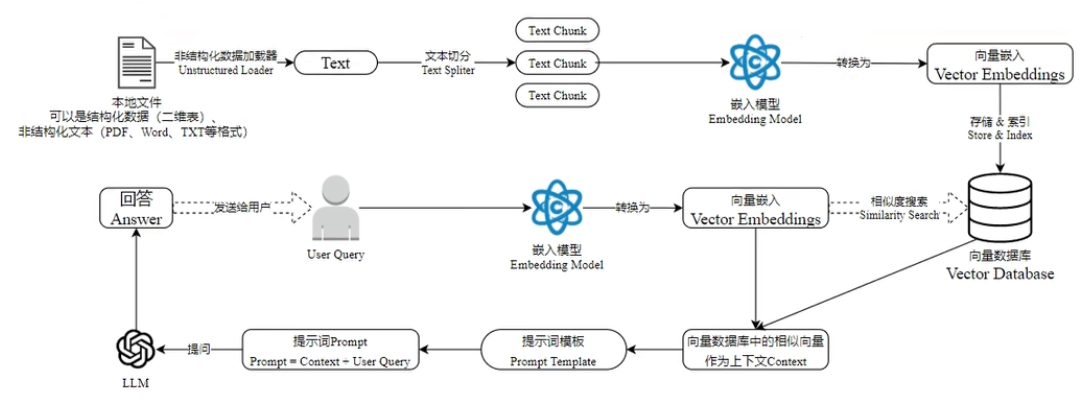
类似的细节图:
强调RAG的难点步骤:
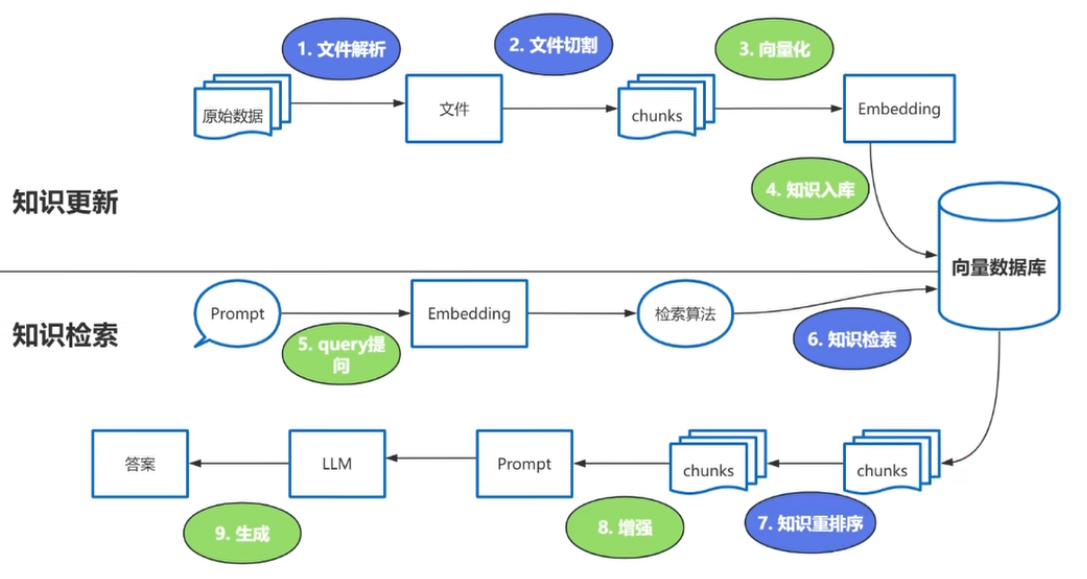
这些过程中的难点:1、文档解析 2、文档切割 3、知识检索 4、知识重排序
(3)Reranker的使用场景
- 适合:追求`回答高精准度`和`高相关性`的场景中特别适合使用reranker,例如专业知识库或者客服系统应用。
- 不适合:引入reranker会增加召回时间,增加检索延迟。服务对`响应时间要求高`,使用reranker不太合适。
这里有三个地方涉及到大模型的使用:
- 第3步向量化时,需要使用Embedding models
- 第7步重排序时,需要使用rerank models
- 第9步生成答案时,需要使用LLM
二、基于Agent架构的开发
充分利用LLM的推理决策能力,通过增加`规划`、`记忆`和`工具调用`的能力,构造一个能够独立思考、逐步完成给定目标的智能体。
举例:传统的程序vsAgent
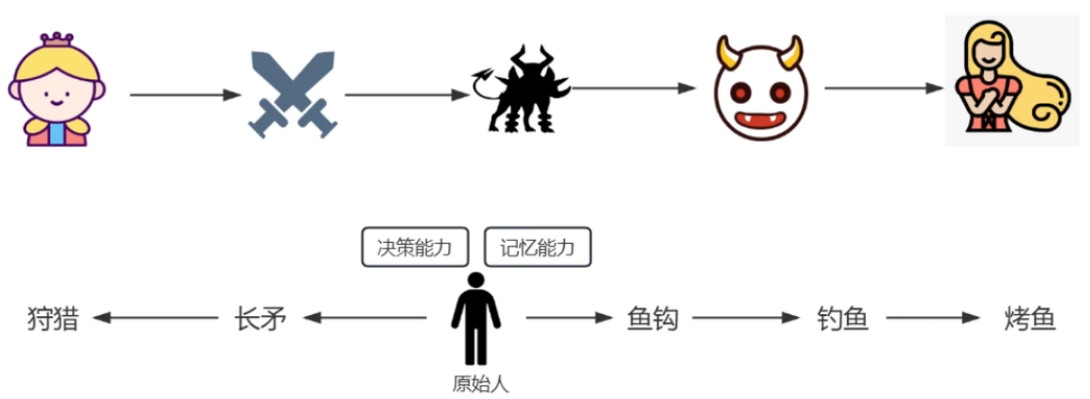
现代AI Agent架构:
一个数学公式来表示:
Agent = LLM + Memory + Tools + Planning + Action
比如,打车到西藏玩。
• 大脑中枢:规划行程的你
• 规划:步骤1:规划打车路线,步骤2:定饭店、酒店,。。。
• 调用工具:调用MCP或FunctionCalling等API,滴滴打车、携程、美团订酒店饭店
• 记忆能力:沟通时,要知道上下文。比如定酒店得知道是西藏路上的酒店,不能聊着聊着忘了最初的目的。
• 能够执行上述操作。说走就走,不能纸上谈兵。
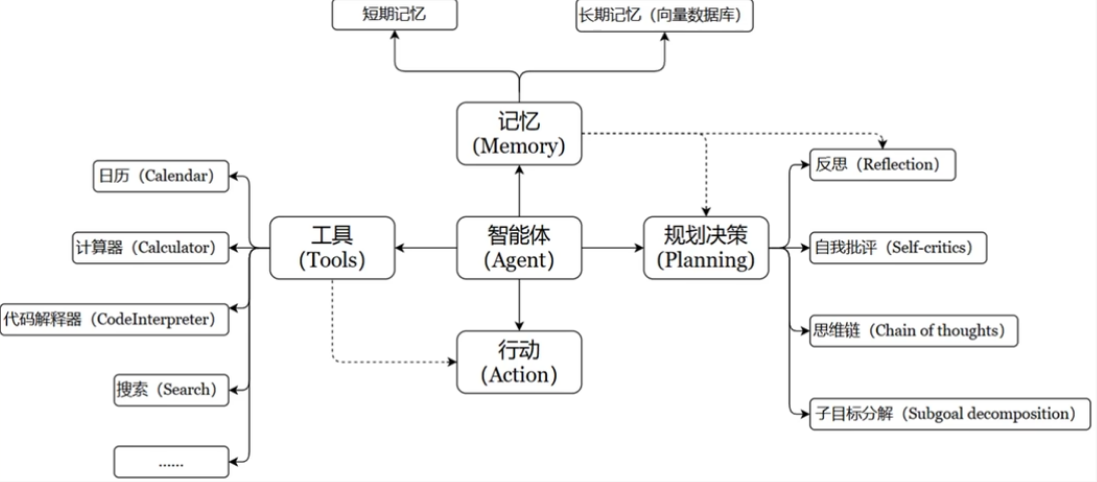
智能体核心要素被细化为一下几个模块:
1、大模型作为大脑(LLM)
提供推理、规划和知识理解能力,是AI Agent的决策中枢
2、记忆(Memory)
记忆机制让智能体处理重复工作时调用以前的经验,从而避免用户进行大量重复交互。
短期记忆:存储单词对话周期的上下文信息,属于临时信息存储机制。受限于模型的上下文窗口长度。
ChatGPT:支持约8k token的上下文
GPT4:支持约32k token的上下文
最新的很多大模型:都支持100万、1000万token的上下文(相当于2000万字文本或20小时视频)
一般情况下模型中token和字数的换算比例大约如下:
◦ 1个英文字符 ≈ 0.3个token。
◦ 1个中文字符 ≈ 0.6个token。
长期记忆:可以横跨多个任务或时间周期,可存储并调用核心知识,非即时任务。长期记忆可以通过模型参数微调(固化知识)、知识图谱(结构化语义网络)或向量数据库(相似度检索)方式来实现。
3、工具调用(Tool Use)
调用外部工具(比如:API、知识库)扩展能力边界。

4、规划决策(Planning)
通过任务分解、反思与自省框架实现复杂任务处理。例如,利用思维链(COT)将目标拆解为子任务,并通过反馈来优化策略。
5、行动(Action)
实际执行决策的模块,涵盖软件接口操作(如自动订票)和物理交互(如机器人执行搬运)。比如:检索、推理、编程等。
三、大模型应用开发的4个场景
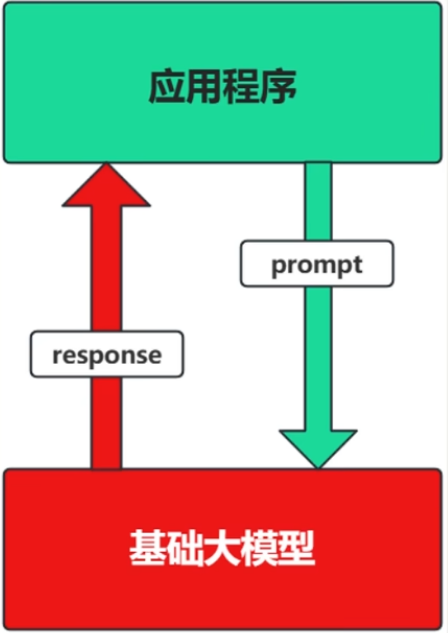
(1)场景1:Prompt
- Prompt是操作大模型的唯一接口
- 把大模型当做是一个人:你说一句,它回复一句...
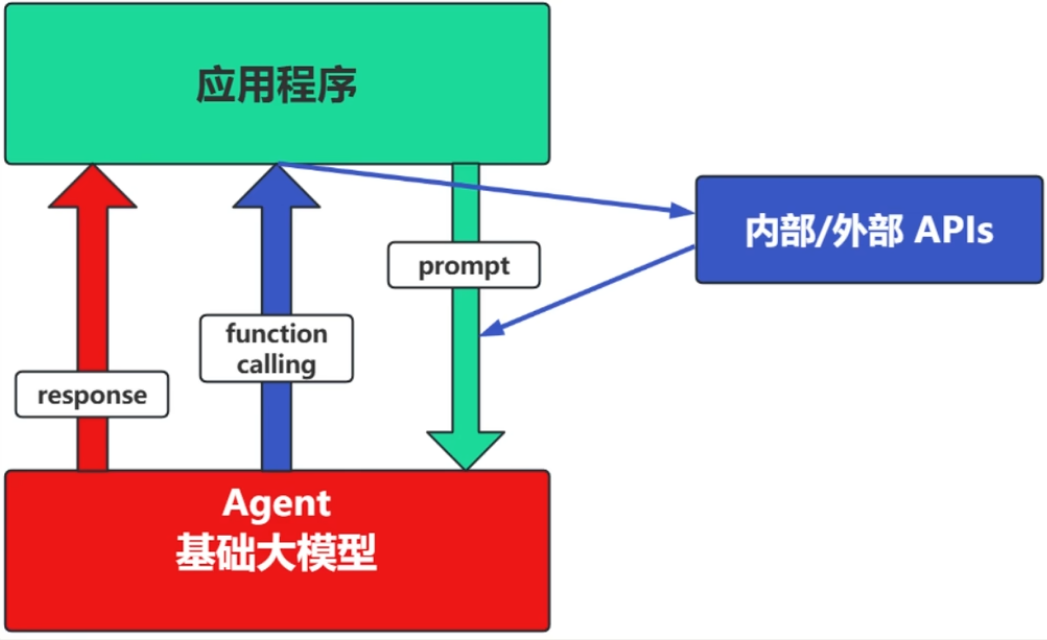
(2)场景2:Agent + Function Calling
- Agent:AI 主动提出要求
- Function Calling:需要对外部系统时,AI需要执行某个函数
- 把Agent当做人:你问它`我明天去杭州出差,要带雨伞吗?`,它会先去看天气预报,看了之后它再回复你要不要带伞。
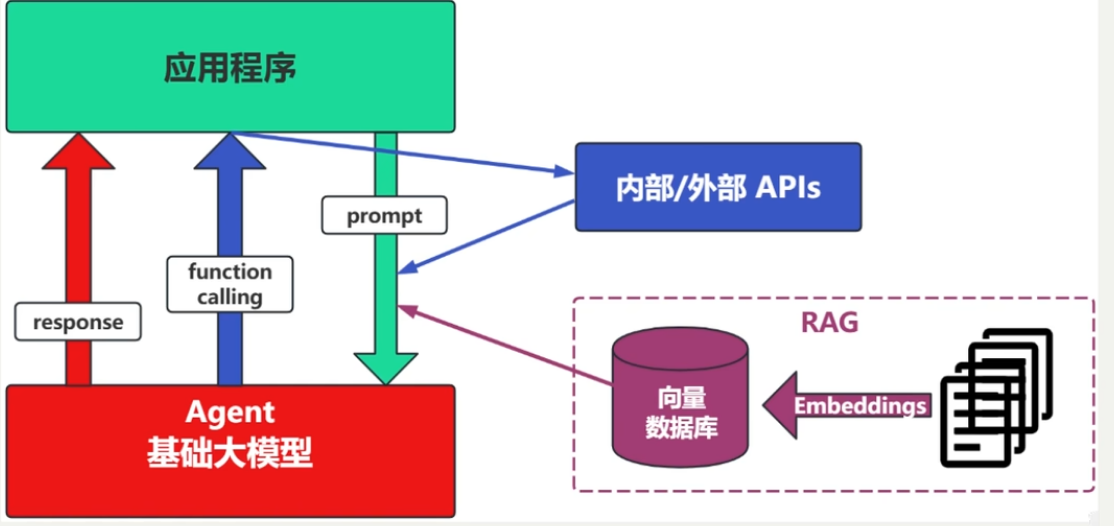
(3)场景3:RAG
RAG需要补充领域知识时使用
- Embedding:把文字转换成向量。便于计算相似度。
- 向量数据库:把向量存起来,方便查找。
- 向量搜索:根据输入向量,找到最相似的向量
举例:考试答题的时候,去书上找相关内容,再结合题目组成答案。
(4)场景4:Fine-tuning
举例:努力学习考试内容,将知识内化成自己的,做到活学活用。
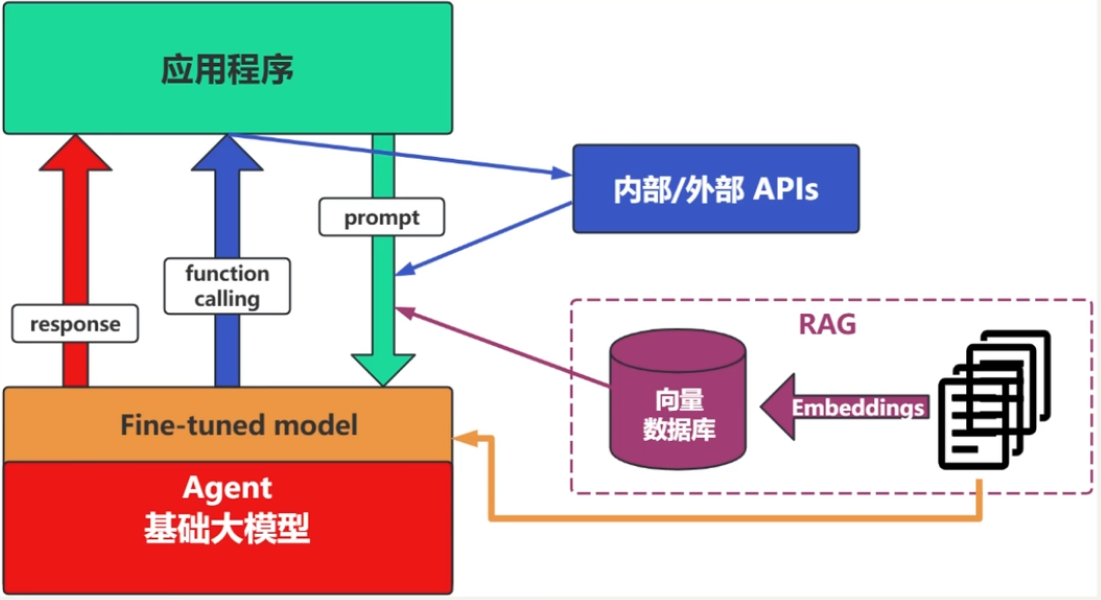
特点:成本高,在前面的方式解决不了问题的情况下再使用。
(5)如何选择?
面对一个需求,如何开始,如何选择技术方案?下面是常用思路:
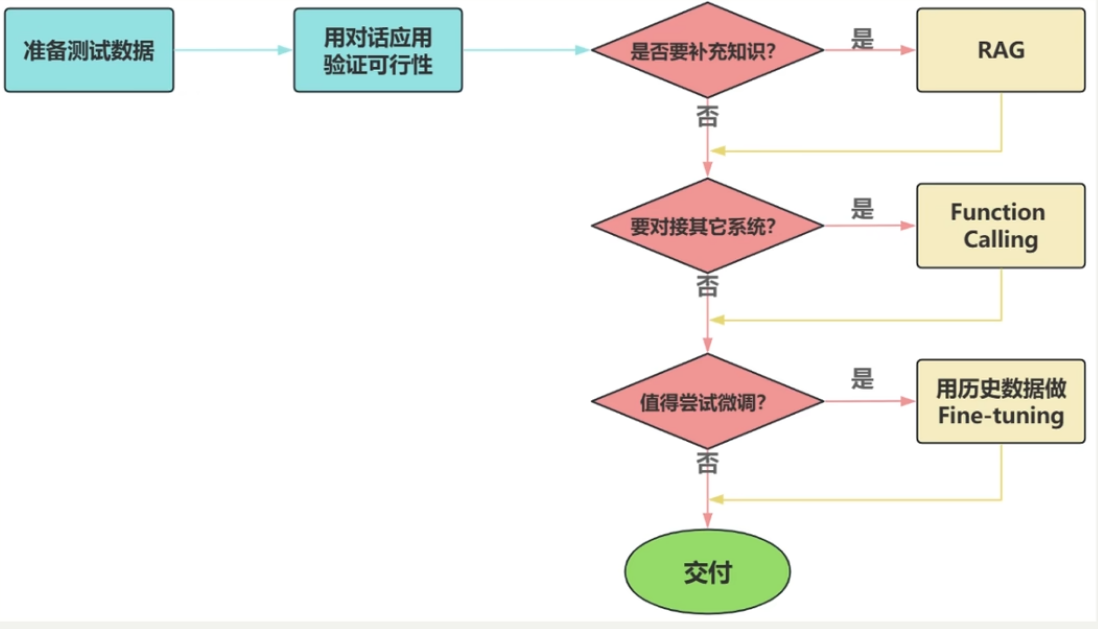
注意:其中最容易被忽略的是准备测试数据。
另外有关RAG和微调的对比可查看我之前的文章:【自然语言处理与大模型】微调与RAG的区别

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)