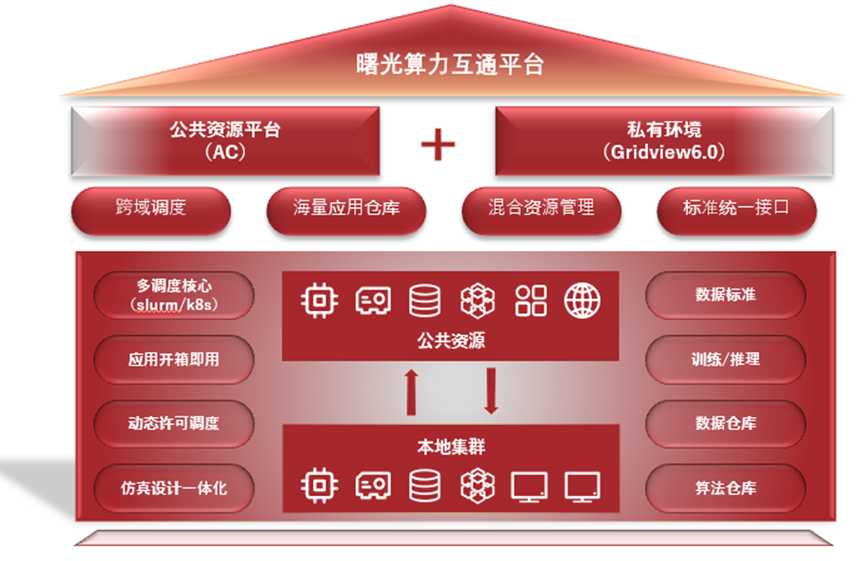
Gridview:让 HPC 作业管理真正“看得见、点得着、跑得快”
Gridview是一款面向高性能计算(HPC)的作业管理系统,通过Web界面实现算力资源的可视化管理和智能化调度。该系统将传统复杂的命令行操作简化为表单式提交,提供作业模板、实时监控、跨集群统一管理等功能,大幅降低HPC使用门槛。Gridview支持科研计算、AI训练、工业仿真等多场景应用,具备团队协作、资源配额、安全审计等企业级功能,并能量化分析作业成功率、资源利用率等关键指标。该系统旨在提升H
在高性能计算(HPC)的世界里,研究者与工程师的时间极其宝贵。每一次提交作业、每一次调度等待、每一次参数调整,背后都消耗着脑力与专注力。Gridview 的诞生,就是要把“算力使用体验”这件事重新做一遍:不用懂一堆命令行,不必频繁 SSH,不需要在多个系统来回切换,把作业提交、资源选择、运行监控和结果获取,整合到一个直观的 Web 界面中,让算力触手可及、开箱即用。
对管理者来说,Gridview 还是一个“透明的资源窗口”:集群利用率、队列健康度、作业成功率、失败原因与账目归集,都能被拆解、呈现、优化;对使用者来说,它就是一个“看得见、点得着、跑得快”的作业工作台。这不是把命令行包一层皮,而是围绕“人—任务—资源—数据”做的系统性重构。
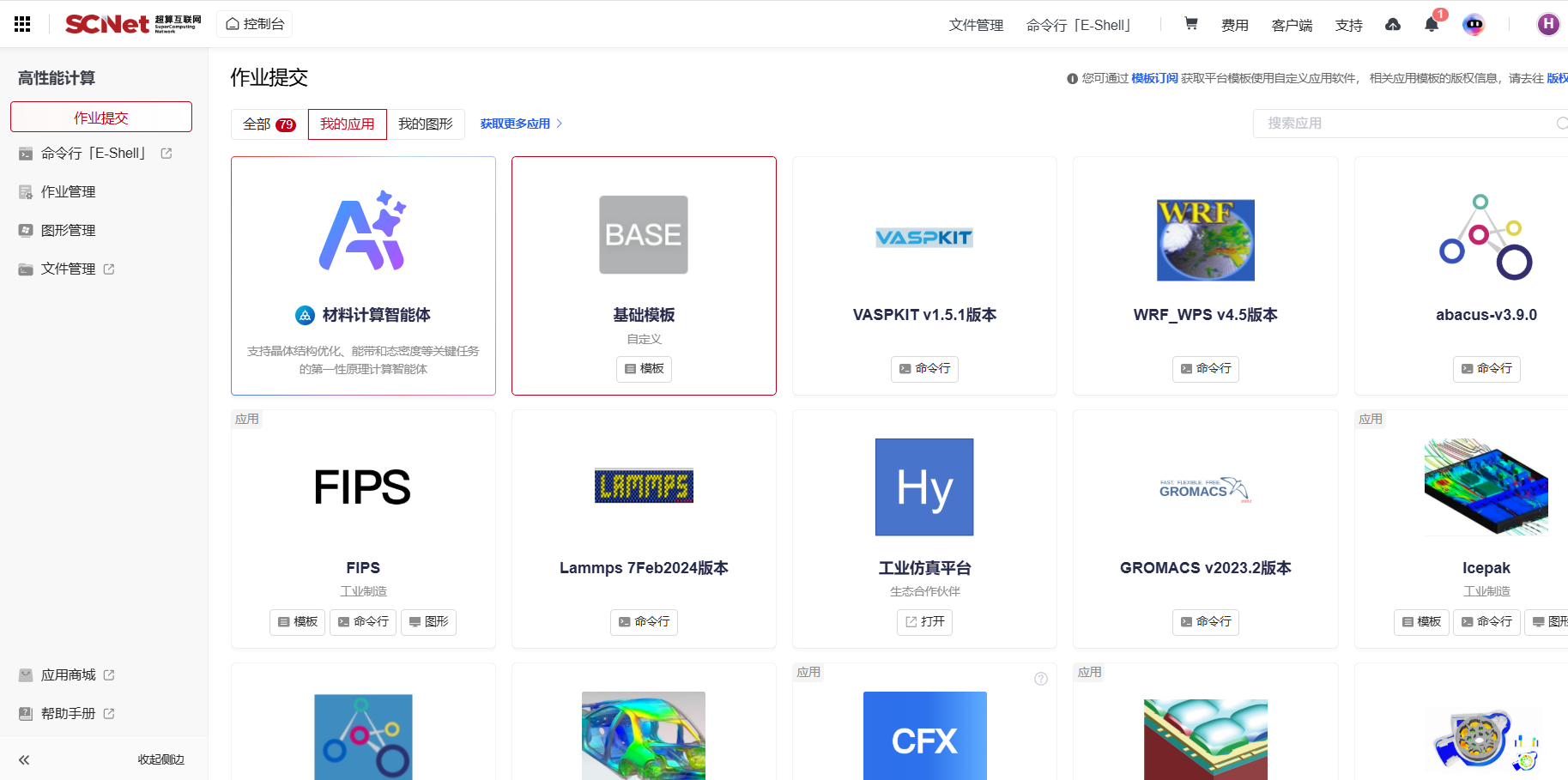
01|不是“学会 HPC”,而是“马上能用 HPC”
传统 HPC 门槛高:环境不一致、参数多、脚本复杂、队列策略难以摸清。Gridview 的第一原则很简单:第一次用也不怕。
-
可视化作业向导:像填写表单一样选择应用模板、镜像/模块、所需核数/内存/GPU、最大运行时长、输入输出路径。
-
参数检查与智能提示:表单级校验与规则引导,尽量在提交前发现问题,把“失败重提”的成本砍掉。
-
模板复用与共享:项目内可共享标准化模板,新人也能“靠模板吃饭”,把经验沉淀为组织的资产。
结果是显而易见的:减少学习成本、提高提交流畅度、降低失败率。Gridview 让“用不起来的算力”变成“顺手就能用的生产力”。
02|实时可见:从排队到结果,每一步都在眼前
作业提交出去了,接下来呢?以往我们靠轮询日志与命令行查询,效率低且焦虑感强。Gridview 提供端到端的可视化监控:
-
状态流转:等待、调度中、运行、完成/失败,一目了然;
-
关键指标:CPU/GPU/内存利用率、I/O 概况、排队时长、剩余预估时间;
-
异常提醒:资源不足、时间配额将耗尽、作业异常退出等触发通知(站内/邮件/IM 可选);
-
日志即点即看:标准输出/错误输出与关键阶段日志就地预览,无需再切换终端抓日志。
可见性不是为了“好看”,而是为了更快定位、更少反复。当你知道排队为何久、瓶颈在何处、错误在哪一环,决策就更快,迭代也更短。

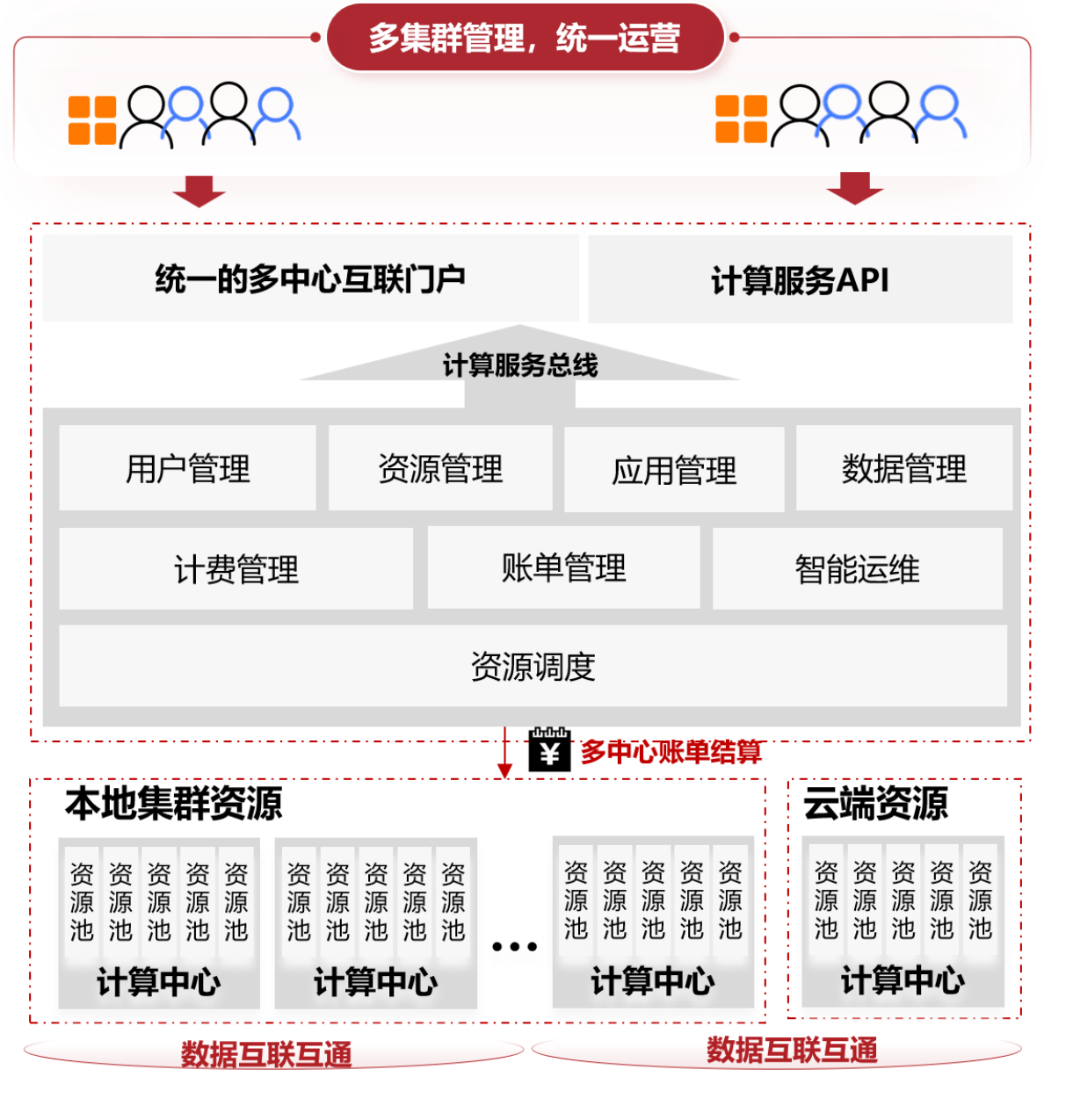
03|跨集群一站式:统一入口、统一体验、统一治理
如今的算力往往分布在多地多中心:本地超算中心、合作高校节点、云上 GPU 集群,甚至异构架构(CPU/GPU/DCU)混用。Gridview 提供跨集群统一接入与调度视图:
-
在一个控制台查看各集群队列健康度与资源余量;
-
跨地域按策略路由作业,择优提交,减少排队;
-
权限、配额、审计“统一口径”,不再各自为政。
这让管理从“分散 + 手工统计”进化为“集中 + 自动量化”。跨集群不是复杂的代名词,而是更高可用、更高效率的保障。
04|把调度做“聪明”:资源匹配与等待优化
排队是 HPC 的常态,但漫长与不确定不该是常态。Gridview 将“用户诉求—资源画像—队列策略”结合起来:
-
资源画像匹配:基于历史数据为作业推荐合适的队列与节点类型(例如内存型/计算型/GPU 型);
-
等待时间预估:参考队列长度与运行时长分布,给出“预计开始/结束时间”区间;
-
策略加速:对短作业或交互式任务提供“快速道/短作业队列”,尽力降低长队中的“短任务被淹没”问题。
当策略与数据结合,调度不只是“公平”,还能“合适”。少等、少挤,效率自然高。
05|面向多样场景:科研、AI、工业仿真都好用
Gridview 不为某一学科定制,但为常见场景准备了“最佳实践剧本”:
科研计算(材料、化学、生物、气象、天文)
-
大规模并行模板、MPI/OMP 参数引导;
-
典型输入/输出目录结构参考;
-
长/短任务混部策略建议(避免长队“吞没”短任务)。
AI 训练/推理
-
多 GPU 配置面板(数据并行/模型并行、梯度累积、混合精度开关);
-
与常用框架(PyTorch/TensorFlow)容器镜像模板;
-
训练日志/可视化指标接入(如对接 TensorBoard/MLFlow 等)。
工业仿真(CFD/FEA 等)
-
许可证位检查与排队提醒;
-
I/O 热点处理与批量编队作业提交;
-
常见商业软件模板与环境变量预置。
复杂藏在模板里,用户只需改参数,不必“重造轮子”。
06|团队协作:权限、配额、共享,让组织有序高效
算力是组织级的资源,协作能力至关重要。Gridview 提供基于成员/项目/部门的多维治理:
-
角色与权限:区分团队管理员、普通成员的操作边界;
-
预算与配额:按项目或成员设置使用上限,防止资源失控;
-
模板与结果共享:沉淀经验、共享成果,减少“重复踩坑”。
这既保护了资源的可持续性,也保护了团队的工作秩序。好的治理,才能放大个体效率。
07|体验至上:友好界面 + 细节打磨
Gridview 的界面并不追求炫技,而是追求“高密度信息的可读性”。
-
信息分层:重要状态在上、一眼能懂;
-
术语贴合:HPC 术语保留但有解释,不强行改名;
-
高频操作就近:模板、重试、终止、克隆新作业都在“手边”。
体验不是装饰,而是效率本身。越懂用户的“下一步”,越能少走弯路。
08|稳定与安全:从工程底层守护任务成功率
HPC 的稳定性和安全性没有“玄学”。Gridview 从工程角度夯实基础:
-
作业级隔离与限额:避免单个任务拖垮节点;
-
数据访问控制与审计:最小权限原则,关键操作可追溯;
-
日志与指标留存:便于事后分析与问题复盘;
-
高可用部署:控制面与执行面解耦,避免单点。
稳定与安全守住底线,才能放心“把重活交给平台”。
09|量化价值:把“感觉快”变成“看得见的提升”
Gridview 鼓励用数据说话:
-
作业成功率:提交成功率、一次通过率、失败原因分布;
-
资源利用率:CPU/GPU/内存利用效率、空转占比;
-
队列等待:平均等待时长、P95/P99 指标、跨队列差异;
-
成本与预算:按项目/成员/应用归集,支持核算与管控。
当你能看见这些指标,优化就有方向:比如模板化把“重复失败”清零;用短作业队列让交互式任务平均等待下降;给数据密集型任务匹配更合适的节点与存储。一切改进,都能量化呈现。
10|现在开始:用 Gridview,把算力变成生产力
如果你正在评估新的作业平台,或者正被多系统割裂、提交体验欠佳、作业失败率高、队列不可预期等问题困扰,给 Gridview 一个项目周期:
-
先把团队最高频的 2–3 类任务模板化;
-
用统一入口替代分散脚本,减少“环境漂移”;
-
打通监控与告警,让问题暴露在第一时间;
-
建立“指标看板”,将体验与效率转化为数据。
你会发现,算力不是难事,难的是把算力用好。Gridview 想做的正是这件事:把复杂收起来,把效率释放出来,把团队的时间还给研究与工程。
结语与行动引导
今天的高性能计算,正在从“拼资源”走向“拼效率”。Gridview 用清晰的可视化、聪明的调度、扎实的治理与稳定的工程,实现“让 HPC 真正服务于成果”的承诺。 现在就行动:把你的第一批作业迁到 Gridview,用一次提交,见一次效率。如果你需要更细的场景配置建议、模板设计方法或迁移清单,我可以基于你的实际工作负载,给出一份“一周落地实施方案”,让团队快速起跑。
Gridview — 让 HPC 作业管理更简单、更高效、更可见!
如果您对Gridview感兴趣,请您联系我!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)