my-neuro rag 向量数据库部分 笔记 sklearn.metrics.pairwise.cosine_similarity watchdog 召回
my-neuro/run_rag.py at main · morettt/my-neuro
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from typing import List, Dict, Any
import torch
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import uvicorn
import time
import os
import sys
import re
import threading
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
# 保存原始stdout和stderr
original_stdout = sys.stdout
original_stderr = sys.stderr
# 创建双重输出类
class TeeOutput:
def __init__(self, file1, file2):
self.file1 = file1
self.file2 = file2
self.ansi_escape = re.compile(r'\x1B(?:[@-Z\\-_]|\[[0-?]*[ -/]*[@-~])')
def write(self, data):
self.file1.write(data)
clean_data = self.ansi_escape.sub('', data)
self.file2.write(clean_data)
self.file1.flush()
self.file2.flush()
def flush(self):
self.file1.flush()
self.file2.flush()
def isatty(self):
return self.file1.isatty()
def fileno(self):
return self.file1.fileno()
# 设置日志
LOGS_DIR = "logs"
if not os.path.exists(LOGS_DIR):
os.makedirs(LOGS_DIR)
log_file = open(os.path.join(LOGS_DIR, 'rag.log'), 'w', encoding='utf-8')
sys.stdout = TeeOutput(original_stdout, log_file)
sys.stderr = TeeOutput(original_stderr, log_file)
# 全局变量
model = None
knowledge_base = []
knowledge_embeddings = None
reload_lock = threading.Lock()
class KnowledgeBaseHandler(FileSystemEventHandler):
"""监控记忆库文件变化"""
def on_modified(self, event):
if not event.is_directory and event.src_path.endswith("记忆库.txt"):
time.sleep(0.5) # 等待文件写入完成
reload_knowledge_base()
def load_knowledge_base(file_path="./live-2d/AI记录室/记忆库.txt"):
"""加载知识库文件 - 使用连续横线分割段落"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
paragraphs = []
# 使用正则表达式匹配10个以上连续的横线
# 匹配10个或更多连续的横线(可能前后有空格)
separator_pattern = r'\s*-{10,}\s*'
# 按分隔符分割内容
sections = re.split(separator_pattern, content)
for section in sections:
section = section.strip()
# 过滤掉空内容和过短的内容
if section and len(section) > 10:
paragraphs.append(section)
print(f"知识库加载完成,共 {len(paragraphs)} 个段落")
return paragraphs
except Exception as e:
print(f"加载知识库失败: {e}")
return []
def reload_knowledge_base():
"""重新加载知识库"""
global knowledge_base, knowledge_embeddings
with reload_lock:
print("检测到文件变化,重新加载知识库...")
new_knowledge_base = load_knowledge_base()
if new_knowledge_base and model is not None:
knowledge_base = new_knowledge_base
knowledge_embeddings = model.encode(knowledge_base)
print("知识库更新完成!")
# 创建FastAPI应用
app = FastAPI(title="BGE API", version="1.0.0")
@app.on_event("startup")
async def startup_event():
global model, knowledge_base, knowledge_embeddings
print("启动BGE API服务...")
print("加载模型...")
# 加载模型
model = SentenceTransformer("./RAG-model")
model = model.to('cuda')
print("模型加载完成,使用GPU")
# 加载知识库
knowledge_base = load_knowledge_base()
if knowledge_base:
print("生成知识库嵌入...")
knowledge_embeddings = model.encode(knowledge_base)
print("知识库嵌入完成")
# 启动文件监控
event_handler = KnowledgeBaseHandler()
observer = Observer()
observer.schedule(event_handler, "./live-2d", recursive=False)
observer.start()
print("文件监控启动完成")
print("API服务启动完成!")
# 请求模型
class TextRequest(BaseModel):
text: str
class QuestionRequest(BaseModel):
question: str
top_k: int = 3
class SimilarityRequest(BaseModel):
text1: str
text2: str
# 响应模型
class EmbeddingResponse(BaseModel):
embedding: List[float]
dimension: int
processing_time: float
class AnswerResponse(BaseModel):
question: str
relevant_passages: List[Dict[str, Any]]
processing_time: float
class SimilarityResponse(BaseModel):
similarity: float
processing_time: float
@app.get("/")
async def root():
return {
"message": "BGE API服务运行中",
"model_loaded": model is not None,
"knowledge_base_size": len(knowledge_base)
}
@app.post("/encode", response_model=EmbeddingResponse)
async def encode_text(request: TextRequest):
if model is None:
raise HTTPException(status_code=500, detail="模型未加载")
start_time = time.time()
embedding = model.encode([request.text])[0]
processing_time = time.time() - start_time
return EmbeddingResponse(
embedding=embedding.tolist(),
dimension=len(embedding),
processing_time=processing_time
)
@app.post("/similarity", response_model=SimilarityResponse)
async def calculate_similarity(request: SimilarityRequest):
if model is None:
raise HTTPException(status_code=500, detail="模型未加载")
start_time = time.time()
embeddings = model.encode([request.text1, request.text2])
similarity = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
processing_time = time.time() - start_time
return SimilarityResponse(
similarity=float(similarity),
processing_time=processing_time
)
@app.post("/ask", response_model=AnswerResponse)
async def ask_question(request: QuestionRequest):
if model is None:
raise HTTPException(status_code=500, detail="模型未加载")
if not knowledge_base:
raise HTTPException(status_code=404, detail="知识库未加载")
with reload_lock: # 确保查询时数据不会被更新
start_time = time.time()
question_embedding = model.encode([request.question])
similarities = cosine_similarity(question_embedding, knowledge_embeddings)[0]
top_indices = np.argsort(similarities)[::-1][:request.top_k]
relevant_passages = []
for i, idx in enumerate(top_indices):
relevant_passages.append({
"rank": i + 1,
"similarity": float(similarities[idx]),
"content": knowledge_base[idx]
})
processing_time = time.time() - start_time
return AnswerResponse(
question=request.question,
relevant_passages=relevant_passages,
processing_time=processing_time
)
@app.get("/health")
async def health_check():
return {
"status": "healthy",
"model_loaded": model is not None,
"knowledge_base_loaded": len(knowledge_base) > 0
}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8002)同意前文这样看
你贴的这段代码是一个 基于 FastAPI 的本地 RAG(检索增强生成)服务后端,它结合了语义搜索、知识库实时监控和日志记录功能。我们来一步步拆解它到底“是什么玩意”:
🌟 总体功能一句话总结:
这是一个运行在本地的 语义搜索引擎 + 知识库问答 API 服务,能根据用户提问从“记忆库.txt”中找出最相关的段落,并通过横线分隔管理知识片段。
🔧 技术栈组成
| 组件 | 作用 |
|---|---|
FastAPI |
提供 RESTful API 接口 |
SentenceTransformer |
使用 BGE 模型对文本进行向量化(编码成 embedding) |
cosine_similarity |
计算语义相似度 |
Uvicorn |
ASGI 服务器,启动服务 |
watchdog |
监控文件变化,自动重载知识库 |
Pydantic |
数据校验模型 |
📁 文件结构依赖(关键路径)
bash
深色版本
.
├── live-2d/AI记录室/记忆库.txt ← 主要的知识源文件
├── RAG-model/ ← 下载好的 BGE 中文嵌入模型
├── logs/rag.log ← 自动记录运行日志
└── your_script.py ← 当前这个脚本🧠 核心功能详解
✅ 1. 加载知识库
- 读取
记忆库.txt - 用 连续10个以上横线
----------分割不同段落 - 过滤空或太短的内容
- 示例格式:
深色版本
今天我和小明去了公园。 我们玩得很开心。 ------------------------- 昨天我吃了火锅,辣得不行。 -------------------------
✅ 2. 启动时加载模型与向量化
- 加载本地 Sentence-BERT 类型的中文嵌入模型(如 BAAI/bge-small-zh-v1.5)
- 将所有知识段落转为向量(embedding),存入内存
- 使用 GPU (
model.to('cuda')) 提升速度
✅ 3. 自动热更新知识库
- 启动一个后台线程,监听
./live-2d目录下的记忆库.txt - 一旦文件被修改,延迟0.5秒后重新加载并重建 embeddings
- 多线程安全锁保护数据一致性
✅ 4. 提供的 API 接口
| 路由 | 方法 | 功能 |
|---|---|---|
GET / |
查看服务状态 | 返回模型是否加载、知识库大小等 |
POST /encode |
输入文本 → 输出其 embedding 向量 | |
POST /similarity |
比较两段文本的语义相似度(0~1) | |
POST /ask |
提问 → 返回 top-k 最相关知识段落 | |
GET /health |
健康检查接口 |
示例:调用 /ask 接口
json
深色版本
{
"question": "你喜欢吃什么?",
"top_k": 2
}返回:
json
深色版本
{
"question": "你喜欢吃什么?",
"relevant_passages": [
{
"rank": 1,
"similarity": 0.87,
"content": "我最喜欢吃火锅,尤其是麻辣锅底..."
}
],
"processing_time": 0.021
}📝 日志系统(高级细节)
- 所有
print()和错误输出都会同时显示在终端 和 写入logs/rag.log - 清理 ANSI 颜色码(避免日志乱码)
- 使用
TeeOutput实现类似 Linux 的tee命令效果
💡 它可能是谁写的?用来干嘛?
很像是某个 虚拟主播 / Live2D 角色 AI 对话系统的一部分!
比如:
- 用户和桌面萌娘聊天
- 萌娘的回答需要参考“记忆库”
- 每次你说过的话、事件都被写进
记忆库.txt - AI 通过
/ask查询历史记忆,做出更个性化回应
所以这其实是给 角色赋予“长期记忆”的中间层服务。
⚠️ 可能的问题 & 改进建议
| 问题 | 建议 |
|---|---|
强依赖 CUDA,没GPU会报错 |
加上 CPU 回退机制:<br>device = 'cuda' if torch.cuda.is_available() else 'cpu' |
on_modified 可能触发多次 |
加去重 debounce 机制 |
| 所有知识一次性加载到内存 | 大知识库应考虑分块索引(如 FAISS、Chroma) |
| 没有身份区分 | 多用户场景下需加 user_id 区分记忆 |
✅ 如何运行它?
确保你有:
-
安装依赖:
bash深色版本
pip install fastapi uvicorn torch sentence-transformers scikit-learn watchdog numpy -
准备模型目录:
- 下载 BAAI/bge-small-zh-v1.5
- 放入项目根目录下的
RAG-model/
-
创建知识库文件:
text深色版本
我叫小美,是个可爱的AI助手。 ------------------------- 我喜欢吃苹果和香蕉。 ------------------------- 我讨厌下雨天。 -
启动服务:
bash深色版本
python your_script.py -
测试接口:
bash深色版本
curl http://localhost:8002/ curl -X POST http://localhost:8002/ask \ -H "Content-Type: application/json" \ -d '{"question": "你讨厌什么天气?", "top_k": 1}'
🎯 总结:这是什么玩意?
这是一套 轻量级本地知识库语义检索引擎,专为中文设计,支持热更新、日志记录、GPU加速,适用于构建带有“记忆能力”的对话机器人、个人AI助理、游戏NPC记忆系统等。
你可以把它理解为:
🔹 “我的AI大脑的记忆模块”
🔹 “让AI记得你说过啥的小助手”
ask部分

你贴出的代码片段:
python
深色版本
question_embedding = model.encode([request.question])
similarities = cosine_similarity(question_embedding, knowledge_embeddings)[0]
top_indices = np.argsort(similarities)[::-1][:request.top_k]这是整个 RAG(检索增强生成)系统中最关键的 语义检索核心逻辑。我们来逐行详细解释它在做什么、为什么这么做,以及背后的原理。
🔍 代码逐行解析
1. question_embedding = model.encode([request.question])
- 作用:将用户的提问(文本)转换为一个语义向量(embedding)
- 输入:一个字符串,比如
"你喜欢吃什么?" - 输出:一个高维向量(例如 512 维或 768 维的浮点数列表),表示这句话的“语义特征”
- 说明:
[request.question]是一个单元素列表,因为model.encode()通常接受文本列表。- 使用的是像 BGE 这样的 Sentence-BERT 模型,能捕捉中文语义。
- 向量的每个维度代表某种抽象语义特征(比如情感、主题、动词类型等)。
✅ 举例:
“我喜欢吃火锅” 和 “我爱吃麻辣烫” 的 embedding 向量会很接近;
而 “我喜欢打篮球” 的向量就会远一些。
2. similarities = cosine_similarity(question_embedding, knowledge_embeddings)[0]
-
作用:计算提问与知识库中每一段落的语义相似度
-
输入:
question_embedding: 形状(1, d)—— 1 条问题,d 维向量knowledge_embeddings: 形状(N, d)—— N 个知识段落,每个都是 d 维向量
-
输出:一个长度为
N的数组,每个值是[0,1]区间内的相似度分数 -
原理:
- 使用 余弦相似度(Cosine Similarity),衡量两个向量方向的夹角。
- 相似度 = 1:完全同方向(语义高度相关)
- 相似度 = 0:正交(无关)
- (通常不会出现负值,因为 embeddings 被归一化了)
- 使用 余弦相似度(Cosine Similarity),衡量两个向量方向的夹角。
-
[0]的含义:cosine_similarity(A, B)返回一个(len(A), len(B))的矩阵- 这里
A只有 1 个问题,所以结果是(1, N),取[0]就是取出第一行 → 得到(N,)的一维数组
📌 举例输出:
[0.32, 0.95, 0.12, 0.87, ...]表示第2段最相似,其次是第4段。
3. top_indices = np.argsort(similarities)[::-1][:request.top_k]
这行是“找最相关段落”的关键操作,拆解如下:
✅ np.argsort(similarities)
- 返回相似度数组中元素从小到大排序的索引位置
- 比如
similarities = [0.32, 0.95, 0.12, 0.87] np.argsort(...)→[2, 0, 3, 1](即最小的是第2个,然后是第0个……)
✅ [::-1]
- Python 切片语法,表示反转数组
- 上面的结果反转后 →
[1, 3, 0, 2] - 这就是从最大到最小的排序索引
✅ [:request.top_k]
- 取前
top_k个索引 - 比如
top_k=2→[1, 3] - 表示:最相关的两个段落是知识库中的第1个和第3个
🎯 最终结果:
top_indices是最相关知识段落在原始knowledge_base列表中的位置索引。
🧠 总结:这三行干了什么?
| 步骤 | 干了啥 | 类比 |
|---|---|---|
| 1️⃣ encode | 把“问题”变成数字向量 | 把一句话翻译成“数学语言” |
| 2️⃣ cosine_similarity | 对比问题和每段知识的相似度 | 在大脑里快速回忆:“哪段记忆最像这个问题?” |
| 3️⃣ argsort + slice | 找出最相似的前 K 段 | “我想起来了!首先是XX,其次是XX” |
🎯 目的:实现语义搜索,而不是关键词匹配。
比如你问:“你觉得辣的食物怎么样?”
即使知识库里没有“辣”字,但只要有“我爱吃火锅”的段落,也能被匹配上。
💡 可视化流程
深色版本
用户提问
↓
[模型编码] → question_embedding (向量)
↓
[与所有知识段落对比]
↓
相似度数组: [0.1, 0.93, 0.4, 0.78, 0.2]
↓
排序索引: [1, 3, 2, 4, 0]
↓
取 top_k=2 → [1, 3]
↓
返回 knowledge_base[1], knowledge_base[3]✅ 常见优化建议
| 问题 | 建议 |
|---|---|
| 每次都重新计算相似度 | 改用 FAISS / Chroma 等向量数据库加速 |
| 大知识库慢 | 分块索引、加缓存 |
| 相似度阈值太低也返回 | 加判断:if similarities[idx] > 0.6: 才返回 |
| 多轮对话无上下文 | 把历史对话拼接进 question 一起 encode |
如果你想,我可以帮你:
- 加上相似度阈值过滤
- 输出时带上段落编号或标签
- 支持模糊搜索 fallback
- 把这部分封装成函数
需要吗?🙂
这里的【0】是啥
你问得非常好!这里的 [0] 是一个 NumPy 数组的索引操作,它的存在是因为 sklearn.metrics.pairwise.cosine_similarity 函数的返回值是一个二维数组(矩阵)。
我们来彻底讲清楚它到底是什么、为什么要有 [0]。
📌 举个例子说明
假设:
- 你的问题是:
"你喜欢吃什么?" - 知识库里有 4 个段落
那么:
python
深色版本
question_embedding = model.encode(["你喜欢吃什么?"]) # shape: (1, 768)
knowledge_embeddings = model.encode(knowledge_base) # shape: (4, 768)调用:
python
深色版本
similarities = cosine_similarity(question_embedding, knowledge_embeddings)❓ cosine_similarity 返回什么?
它返回一个 形状为 (1, 4) 的二维数组(矩阵),长这样:
python
深色版本
[[0.32, 0.95, 0.12, 0.87]]🔍 解释:这是一个矩阵,表示 1 个问题 对 4 个知识段落 的相似度。
虽然我们只问了一个问题,但 cosine_similarity 设计上是支持批量计算的,比如你可以同时问 5 个问题,就会返回 (5, 4) 的矩阵。
🤔 那我只需要第一个(也是唯一一个)问题的结果怎么办?
你就得取这个矩阵的第 0 行:
python
深色版本
similarities[0]结果就是:
python
深色版本
[0.32, 0.95, 0.12, 0.87] # 这是一个一维数组,长度为 4这才是我们可以用来排序的“相似度列表”。
✅ 所以 [0] 的含义是:
“取第一个(也是唯一一个)查询语句与所有知识段落的相似度得分”
即:把[[s1, s2, s3, ...]]变成[s1, s2, s3, ...]
🧠 类比理解
想象你在查成绩单:
| 学生 | 数学 | 英语 | 语文 | 物理 |
|---|---|---|---|---|
| 张三 | 85 | 90 | 78 | 88 |
如果你用代码表示这张表,就是一个二维数组:
python
深色版本
scores = [[85, 90, 78, 88]]你想看“张三各科成绩”,就要写:
python
深色版本
scores[0] # → [85, 90, 78, 88]这里的 similarities[0] 就和 scores[0] 是一样的道理!
✅ 总结
| 表达式 | 类型 | 形状 | 含义 |
|---|---|---|---|
cosine_similarity(...) |
二维数组 | (1, N) |
所有问题对所有知识的相似度矩阵 |
cosine_similarity(...)[0] |
一维数组 | (N,) |
第一个问题对所有知识的相似度列表 ✅ 我们要的 |
💡 小贴士:如果你一次性问多个问题
比如:
python
深色版本
questions = ["你喜欢吃什么?", "你讨厌什么?"]
embeddings = model.encode(questions) # shape (2, 768)
similarities = cosine_similarity(embeddings, knowledge_embeddings) # shape (2, 4)返回:
python
深色版本
[
[0.32, 0.95, 0.12, 0.87], # 第一个问题的相似度
[0.77, 0.21, 0.93, 0.15] # 第二个问题的相似度
]那你就可以:
similarities[0]→ 第一个问题的结果similarities[1]→ 第二个问题的结果
✅ 所以 [0] 不是魔法,只是一个普通的数组索引:取第一个问题的相似度列表。
watchdog是什么库
watchdog 是一个 Python 的文件系统监控库,它的作用是:实时监听文件或目录的变化(比如文件被创建、修改、删除、重命名等),并在变化发生时自动执行你指定的代码。
🌟 一句话解释:
watchdog就像是你电脑里的“保安摄像头”,专门盯着某个文件夹看有没有人动了里面的文件。
🔍 在你的代码中它是怎么用的?
你贴的代码里有这么一段:
python
深色版本
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class KnowledgeBaseHandler(FileSystemEventHandler):
def on_modified(self, event):
if not event.is_directory and event.src_path.endswith("记忆库.txt"):
time.sleep(0.5) # 等待文件写入完成
reload_knowledge_base()
# 启动监控
event_handler = KnowledgeBaseHandler()
observer = Observer()
observer.schedule(event_handler, "./live-2d", recursive=False)
observer.start()它在做什么?
- 监控
./live-2d这个目录 - 一旦发现
记忆库.txt被修改了 - 就自动调用
reload_knowledge_base()函数,重新加载知识库 - 实现了“改完文件,AI 立刻知道”的热更新效果 ✅
🧰 核心组件说明
| 组件 | 作用 |
|---|---|
FileSystemEventHandler |
你可以继承它,定义“当文件发生某种变化时要做什么” |
.on_modified() |
文件被修改时触发 |
.on_created() |
文件被创建时触发 |
.on_deleted() |
文件被删除时触发 |
.on_moved() |
文件被移动/重命名时触发 |
Observer |
真正的“监控器”,负责启动监听循环 |
🧪 简单例子:打印所有文件变化
python
深色版本
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
class MyHandler(FileSystemEventHandler):
def on_modified(self, event):
if not event.is_directory:
print(f"文件被修改: {event.src_path}")
def on_created(self, event):
if not event.is_directory:
print(f"新文件被创建: {event.src_path}")
# 开始监控当前目录
event_handler = MyHandler()
observer = Observer()
observer.schedule(event_handler, path=".", recursive=False)
observer.start()
print("开始监控当前目录... 按 Ctrl+C 停止")
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()运行后,你随便新建或修改一个文件,就会看到提示!
💡 为什么需要 watchdog?
在你的 RAG 服务中,watchdog 解决了一个关键问题:
❌ 如果不监控文件:你改了
记忆库.txt,AI 还是用旧的知识,必须重启服务才能生效
✅ 有了watchdog:改完保存,AI 自动 reload,无需重启,体验丝滑
📦 安装方法
bash
深色版本
pip install watchdog⚠️ 注意:在 Windows 上它是原生支持的,在 Linux/macOS 上可能依赖
inotify或kqueue,但一般都能正常工作。
✅ 适用场景(除了你的 RAG)
| 场景 | 用途 |
|---|---|
| 自动重启服务 | 类似 nodemon,文件改了自动重启 Flask/FastAPI |
| 日志监控 | 日志文件更新时触发告警 |
| 同步工具 | 文件变了就上传到云端 |
| 编译器 | 源码改了就自动编译 |
| AI 记忆系统 | 如你代码中所示,动态更新知识库 |
🧩 小知识:recursive=False 是啥意思?
recursive=True:监控该目录 及其所有子目录recursive=False:只监控当前目录,不进子文件夹
你在代码中设为 False,表示只关注 ./live-2d 下的文件,不管它的子文件夹。
✅ 总结
| 问题 | 回答 |
|---|---|
watchdog 是什么? |
一个监听文件变化的 Python 库 |
| 能干什么? | 文件一改、一删、一建,你就知道 |
| 在你的代码里起什么作用? | 实现知识库热更新,改完 .txt 不用重启服务 |
| 值不值得学? | ✅ 只要你做自动化、后台服务、AI 工具,它非常有用 |
向量数据库查询方法
https://www.bilibili.com/video/BV1JLN2z4EZQ
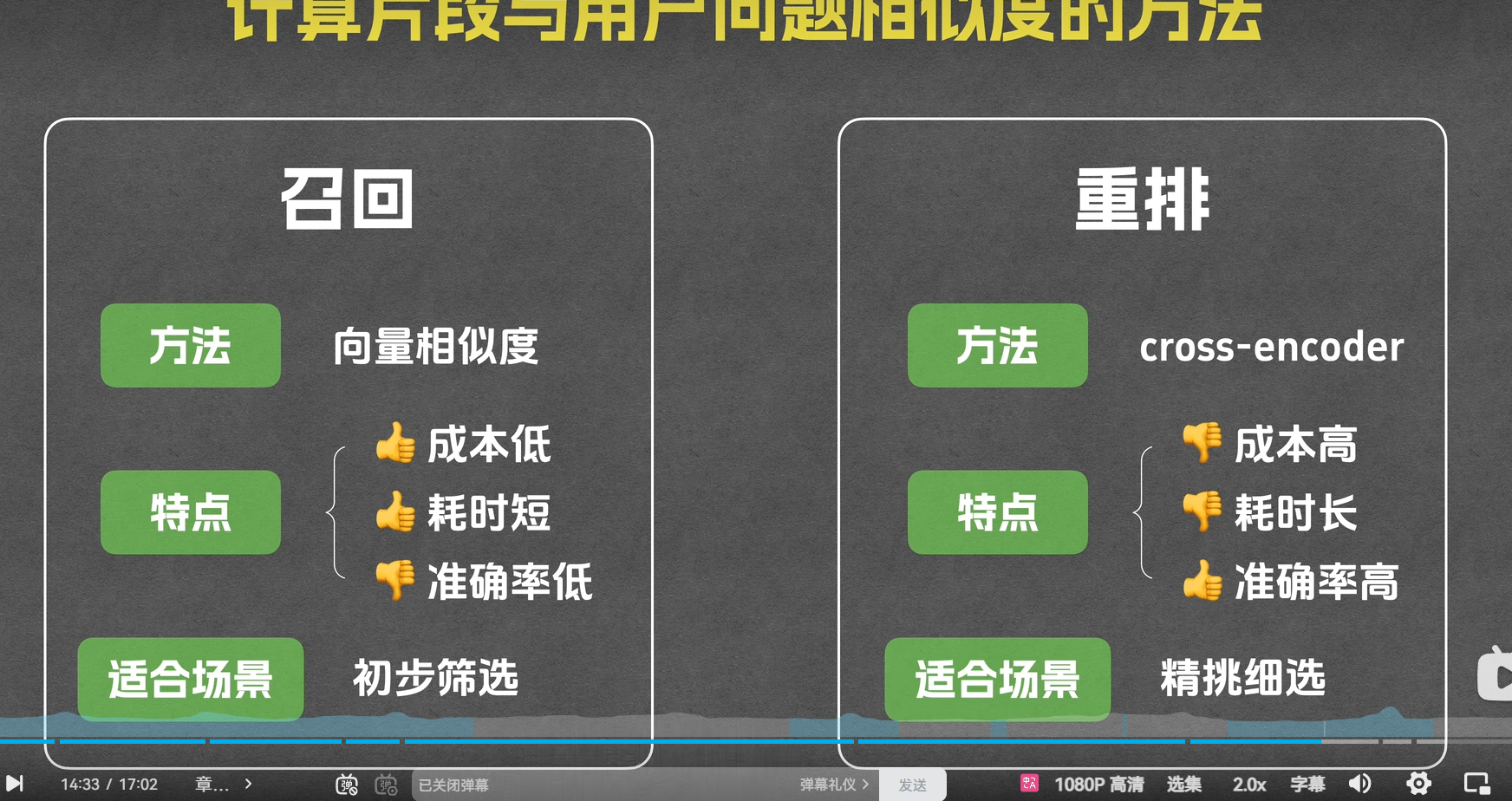
重排阶段
在重排阶段,系统的目标是对召回阶段得到的候选文档或片段进行更精细的排序,以确保最相关的文档或片段排在前面。这个阶段通常使用更复杂的模型,如 cross-encoder。cross-encoder 是一种深度学习模型,它可以对问题和文档进行联合编码,并输出一个表示它们相关性的分数。这种方法的优点是准确率高,能够更好地捕捉问题和文档之间的复杂关系,但缺点是计算成本高、耗时长。
知识图谱相关
知识图谱(Knowledge Graph, KG)和 RAG(Retrieval-Augmented Generation)都是现代人工智能,特别是自然语言处理领域的重要技术,它们在信息检索和知识利用方面有互补性,可以结合使用以提升系统性能。它们之间的关系可以从以下几个方面来理解:
1. 核心功能不同,但目标互补
- 知识图谱:是一种结构化的知识表示形式,以“实体-关系-实体”三元组(如
<北京, 是首都, 中国>)的形式组织知识。它擅长表示结构化、语义明确的关联知识,便于进行逻辑推理、关系查询和知识推理。 - RAG:是一种生成模型架构,其核心思想是在生成答案之前,先从外部知识库中检索相关信息,然后将检索到的内容作为上下文输入给语言模型,以生成更准确、更可信的回答。它主要解决大语言模型(LLM)的知识局限、幻觉和时效性问题。
👉 关系:知识图谱可以作为 RAG 框架中的外部知识源之一。RAG 负责“检索+生成”,而知识图谱则提供高质量、结构化的知识内容。
2. 知识图谱可以增强 RAG 的检索能力
传统的 RAG 通常基于向量数据库(如使用 Embedding 模型)进行语义检索,这种方式对“语义相似”的文本检索效果好,但对精确的关系推理和多跳查询(multi-hop reasoning)能力较弱。
- 优势结合:将知识图谱引入 RAG,可以在检索阶段利用图结构进行关系推理和路径查询。例如,当用户问“《红楼梦》的作者的出生地是哪里?”,RAG 可以先在知识图谱中通过“《红楼梦》→作者→曹雪芹→出生地”这样的路径进行精确检索,而不是依赖模糊的文本匹配。
- 结果更精准:这种基于图的检索能提供更准确、结构化的上下文,从而让 LLM 生成更可靠的答案。
3. RAG 可以弥补知识图谱的“非结构化知识”短板
- 知识图谱虽然结构清晰,但构建成本高,覆盖范围有限,难以包含所有非结构化信息(如新闻、文章、论坛讨论等)。
- RAG 可以从大规模非结构化文本中检索信息,补充知识图谱未覆盖的知识,实现更全面的知识利用。
4. 融合架构:KG-RAG
近年来,研究者提出了 KG-RAG(Knowledge Graph-enhanced RAG)等融合架构,将两者深度结合:
- 检索阶段:同时从知识图谱和文本语料库中检索信息。
- 融合阶段:将结构化的图信息(如三元组、子图)与非结构化的文本片段进行融合,形成丰富的上下文。
- 生成阶段:语言模型基于融合后的上下文生成最终回答。
这种架构兼具精确推理能力(来自 KG)和广泛知识覆盖(来自 RAG 的文本检索)。
总结
| 维度 | 知识图谱 (KG) | RAG | 关系总结 |
|---|---|---|---|
| 本质 | 结构化知识表示 | 生成模型架构 | 不同技术,可互补 |
| 知识形式 | 结构化(三元组、图) | 非结构化(文本段落) | KG 提供结构,RAG 处理非结构 |
| 检索方式 | 图遍历、关系查询 | 向量相似度、关键词匹配 | KG 支持精确推理,RAG 支持语义匹配 |
| 结合方式 | —— | —— | KG 可作为 RAG 的高质量知识源,提升检索精度 |
| 趋势 | —— | —— | 融合架构(KG-RAG)是提升问答系统性能的重要方向 |
简单来说:知识图谱像是一个高度组织化、逻辑清晰的“专家数据库”,而 RAG 是一个“善于查找和总结信息的助手”。当这个助手能访问专家数据库时,它的回答会更加准确、有据可依。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)