具身智能还有哪些适合研究生的方向?
具身智能是一个广阔且充满活力的交叉学科领域。它不仅是算法的竞技场,也是系统工程、硬件设计与认知科学的交汇点。VLA和RL/IL是两个核心切入点,前者更前沿,后者更扎实。最重要的是,具身智能的研究并非必须依赖昂贵的硬件。利用开源的仿真环境、公开数据集和代码框架,在纯软件层面同样可以开展极具深度的研究。希望这份梳理能帮助你拨开迷雾,找到属于自己的那条研究路径,共同见证这场AI与物理世界融合的浪潮。

从春晚舞台上的惊艳亮相,到马拉松赛道上的稳健步伐,再到科幻电影中才有的高难度动作化为现实,具身智能(Embodied AI)正以一种前所未有的速度,从学术界的象牙塔冲入公众视野。这股浪潮不仅体现在顶会顶刊上逐年攀升的论文数量,更体现在无数研究生和工程师涌入这个赛道的决心。
然而,热情背后是普遍的迷茫。面对庞大而交叉的知识体系,许多初学者都面临着同一个问题:“我该从哪里开始?” 在“视觉语言导航”与“策略学习”、“仿真平台”与“机器触觉”之间徘徊不定,是许多新人共同的困境。
本文旨在系统性梳理当前具身智能领域的主流研究方向,剖析其核心问题、代表性工作与所需技能,为希望投身于此的你,提供一份清晰的入门地图,帮助你找到最适合自身背景与兴趣的切入点。
第一步:建立全局视野——从高质量综述开始
在深入任何细分领域之前,我们强烈建议通过高质量的综述文章建立对具身智能的宏观认知。这远比零散地阅读论文或浏览论坛帖子更高效。一篇好的综述能让你快速把握领域的核心脉络、关键挑战和未来趋势,并提供丰富的参考文献,为后续研究指明方向。
这里精选两篇代表性综述,作为你的起点:
-
英文首选:《Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI》
- 由鹏城实验室与中山大学联合发表,调研了近400篇文献,内容详尽,覆盖面广,适合希望深入了解国际前沿的读者。
-
中文入门:《基于大模型的具身智能系统综述》
- 由中山大学与清华大学合作发表于《自动化学报》,条理清晰,语言流畅,非常适合中文读者快速构建对该领域的整体理解。
具身智能研究方向深度盘点
具身智能的研究方向其实主要就分为这两大类:
方向一:视觉-语言-动作模型 (VLA, Vision-Language-Action)
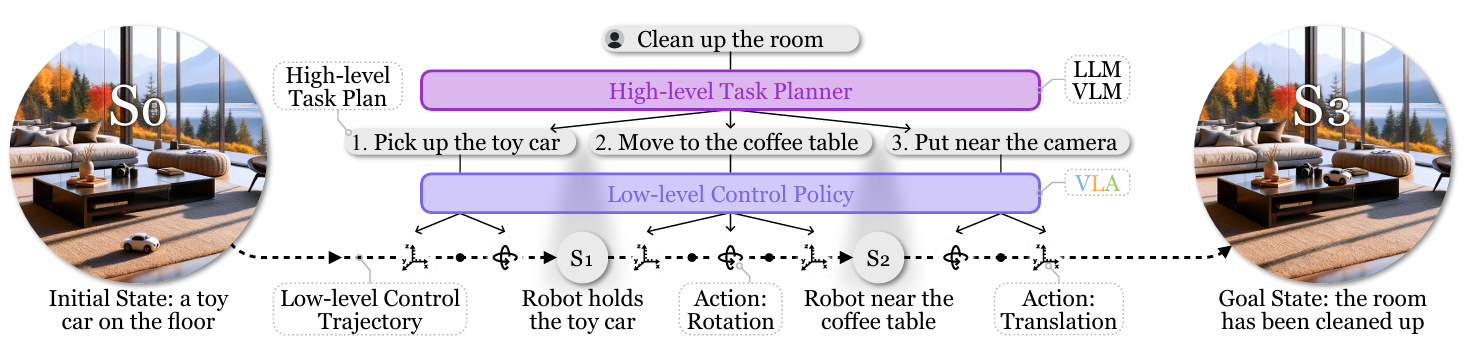
VLA是当前具身智能领域最炙手可热的方向之一,其目标是构建一个端到端的智能系统,实现从“理解世界”到“与之交互”的直接映射。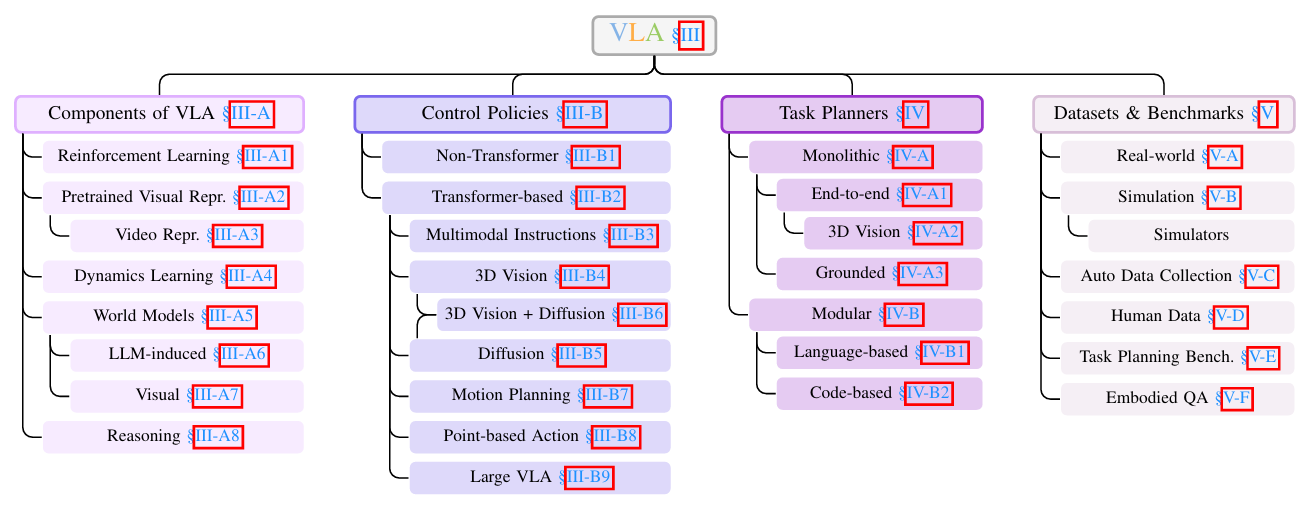
-
核心理念:VLA模型接收多模态输入(如摄像头捕捉的视觉图像和人类下达的语言指令),并直接输出机器人的动作指令(如关节角度、末端速度等)。它试图打破传统机器人“感知-规划-控制”的模块化框架,用一个统一的模型来处理复杂的现实世界任务。
-
研究价值:其核心价值在于追求“通用性”。一个强大的VLA模型理论上可以让机器人在不同场景下执行多样化任务,例如,用同一个模型控制机械臂完成“把桌上的红苹果递给我”,或指挥四足机器人“去客厅然后绕着沙发走一圈”。
-
关键资源:
- 经典论文:Google的 RT-2 和斯坦福等机构联合推出的 OpenVLA 是该领域的里程碑式工作,值得精读。这是我整理的 VLA论文合集。
- 推荐综述:《A Survey on Vision-Language-Action Models for Embodied AI》⁵,这篇新近的综述对VLA模型进行了系统梳理。
-
研究条件:
- 硬件:虽然许多算法可以在仿真环境中进行验证,但拥有物理机器人(真机)进行实验会是巨大的优势。
- 算力:如果研究不涉及大型语言模型(LLM)的训练,一块NVIDIA 4090级别的GPU基本够用。但VLA模型通常数据维度高,对显存(VRAM)需求较大,建议配置32GB或更高显存的显卡。
-
前景与挑战 (评价):VLA是目前最具潜力的方向之一,吸引了大量研究者。但它仍处于相对初级的阶段,模型的泛化能力和鲁棒性是亟待解决的核心难题。换言之,机遇与挑战并存。
方向二:以模仿学习(IL)为辅助的强化学习(RL)
如果说VLA追求的是“一步到位”的端到端学习,那么模仿学习与强化学习的结合则提供了一条更具实践性的策略学习路径。这也是机器人学习领域一个经典且持续活跃的方向。
-
核心理念:
- 模仿学习 (Imitation Learning, IL):简单直接,让机器人像学生“抄作业”一样,通过学习人类专家提供的示范数据(Expert Demonstrations)来掌握技能。优点是学习效率高,能快速达到一个不错的初始水平。缺点是模型的上限受限于示范数据的质量和多样性,泛化能力较差,遇到新情况容易“不知所措”。
- 强化学习 (Reinforcement Learning, RL):鼓励机器人“自主探索”,在与环境的持续交互中,通过试错(Trial-and-Error)和奖励机制来学习最优策略。RL的泛化能力强,理论上可以发现超越人类示范的最优解。但其挑战在于奖励函数(Reward Function)的设计极为困难,且在真实物理世界中训练成本高昂、风险大。
因此,“IL + RL”的模式应运而生:先通过模仿学习让机器人快速掌握基础能力,再利用强化学习在安全的环境(如仿真器)或有限的真实交互中进行微调和优化,从而兼顾效率与性能。

-
研究现状:在运动控制(如行走、奔跑)领域,RL已有相对成熟的解决方案,例如波士顿动力的机器人就大量应用了相关技术。但在需要精细操作的灵巧手(Dexterous Manipulation)领域,RL仍处于探索阶段。
-
关键资源:
- 经典论文:该领域研究众多,建议从近几年顶会(如CoRL, RSS, ICRA)的相关论文入手,我帮大家整理了 RL & IL for Robotics论文合集。
-
研究条件:
- 硬件:RL研究,尤其是涉及Sim2Real(从仿真到现实)的工作,强烈推荐使用物理机器人。幸运的是,市面上有几百元到数千元不等的小型机械臂或移动平台可供入门研究。
- 算力:一块拥有24GB显存的NVIDIA 4090基本可以满足大部分RL算法的训练需求。
-
前景与挑战 (评价):相比VLA,RL在机器人领域的应用历史更长,理论基础更扎实。当前竞争激烈程度略低于VLA,对于希望在传统机器人控制上结合AI方法的同学来说,是一个更容易发表成果、做出扎实贡献的方向。
总结
具身智能是一个广阔且充满活力的交叉学科领域。它不仅是算法的竞技场,也是系统工程、硬件设计与认知科学的交汇点。
VLA 和 RL/IL 是两个核心切入点,前者更前沿,后者更扎实。
最重要的是,具身智能的研究并非必须依赖昂贵的硬件。利用开源的仿真环境、公开数据集和代码框架,在纯软件层面同样可以开展极具深度的研究。希望这份梳理能帮助你拨开迷雾,找到属于自己的那条研究路径,共同见证这场AI与物理世界融合的浪潮。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)