球场比赛中足球识别探讨
展示了探讨这个AI跟踪运动足球的一些思路与实践
一、 出发点
1)最先是觉得使用手机拍摄足球场上的比赛一些精彩片段不好把握时间,位置与效果也不好,就萌生了搞台无人机来试试。
2)使用无人机拍摄足球赛觉得太累了,不停的控制飞机转来转去,想通过大疆的一个开放的SDK去做这方面的开发,让无人机智能的跟踪足球运动,移动镜头和飞行位置去拍摄。出现了些问题。a、电池的续航时间也只有20分钟,准备了三个电池都不够换的。b、手机做视频目标追踪速度很慢,除非你用性能很好的手机,而且延时比较严重。(这里延时包括数据传送延时和推理延时的,没有过多深究)。
3)就萌生了做个足球比赛自动云台的项目自娱自乐一下;发现在淘宝上还有一种Xbotgo的手机云台,想买一台试试的,发现囊中羞涩,暂时搁置,初步估计就是手机的ai估算球或人物的动作轨迹把方向发送给给云台,云台带动手机镜头移动跟踪目标。
另外这家公司还新出了一个自带摄像头的云台,使用遥控器做拍摄操作。不知道那个广角摄像头是做什么用的,可能要买一个回来才能确认。是否用这个自带摄像头来做初步目标识别大概位置发送给手机,手机根据位置裁剪拍摄的图片(1080p以上)的图像到四分之一,这样再进行跟踪处理。这样会不会把手机算力不足或能耗的问题解决。
(莫名其妙,发张图片都说广告)
好吧,淘宝只有你想不到,没有找不到的产品。还是回到我的自娱自乐环节。如果我买一台手机放在哪里,再做一个云台,确实比自己做一个边缘算力机器(例如jetson orin系列)做足球识别控制云台更加的方便和简单,说不定成本会更加可控。(在两个方案间的选择是比较艰难的,选定后如果走不动就意味着巨大的工作量随时间消逝,哈)
4)从手机拍摄的情况看,一些图片效果并不理想,不知道加上一个微单镜头怎么样?现有各种监控的的智能目标识别做的挺好的,我以为使用jetson做这个应该也没有问题。所以无知的认为jetson orin nx做这个应该是很轻松的。具体折腾了一个星期,发现在现有设备上是识别球场上的足球,不尽人意啊。(使用的是yolov8s的模型,首先是在屏幕上屏幕很小,不好识别,只能使用1080p像素输入才能勉强过关,当然还做了些训练,这样导致每秒才能跑12帧左右,不能实时推断,如果加上追踪,就成了10帧了),如何解决小类(小分辨率)高速物体识别率的问题。才是最需要解决的问题。两条思路,a、手机的推理运算速度能够跟得上(看xbotgo品牌的机器倒是可以做到),如果可以,手机如何解决画质问题。b、使用jetson 如何解决实时追踪的问题。或许使用在1080p图片中预测出球的位置,然后以这个位置裁剪640*640图片才能以呢?)
二、硬件情况
在刚开始阶段(啥都不清楚的情况下)实际上硬件选择不多,两种方案,手机方案和边缘智能芯片之间的选择;手机方案有高通骁龙4代和天玑9400。
骁龙8至尊版(四代)搭载了高通迄今为止最快的Hexagon NPU,拥有80TOPS的AI算力,性能提升46%,能效提升45%,配合CPU、GPU、内存等全面提升也让平台AI性能更上一层楼,其综合AI性能增强达到45%。(有点疑惑,这个算力到底是用在哪里的?如果使用高分辨率屏幕,需要用到30%左右的GPU;那实际上剩下50TOPS算力。刚觉应该是够的)加上强劲的CPU,应该很好用才对。手机芯片对标的是天玑9400;
高通8 四代是现在能够用的最新芯片,查了一下型号与具体特点如下:
在淘宝搜。。。,8750的开发板没有找到,8650的开发板需要3500大元以上,发现成本还不如去买台手机。手机如何更换摄像头呢,(我需要一个专业的摄像头)。明年换台手机就买一台测试一下。
边缘智能芯片就有很多,我对这方面比较了解,英伟达的jetson orin系列,个人觉得把性价比做到最好的。还有寒武纪的MLU220,地平线的RDK Ultra和RDK S100,当然还有瑞芯微的RK3588和全志的消费类平板芯片。
瑞芯微和全志的芯片算力不够,pass了,寒武纪的MLU220,我个人用过算力应该够的但是发热量较大和没有外接mipi接口。地平线的RDK系列在淘宝上看到很多,就是最离奇的是我找了半个小时都找不到这家公司的网站。仔细观察后发现在这家公司的网站产品变成两种,一种是征程芯片做智能驾驶,提供的硬件软件一体化解决方案,网站是https://www.horizon.auto/ 。一种做智能芯片的,网站找到的是https://developer.d-robotics.cc/ , 是不是这个网站真不清楚,但是这个国有品牌怎么搞成这样?心里不禁纳闷。后续的软件支持怎么搞?看来在探索阶段还是先用成熟的吧。那就选了jetson orin系列的,软件支持与教程都很好获得,在咸鱼上费尽周折掏了一个二手jetson orin nx 8G的板子。终究是花了钱的,把特征放出来亮一亮,:-)
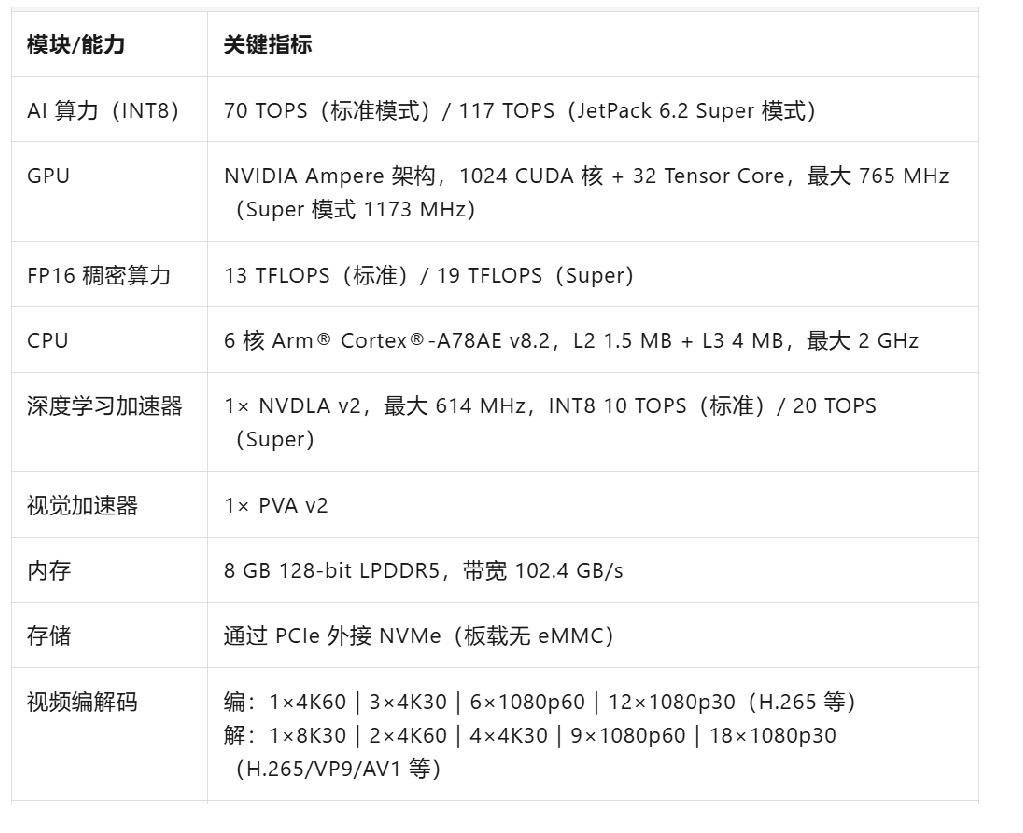 当然有了核心板还不行,开发底板是必不可少的的,配套拿下:
当然有了核心板还不行,开发底板是必不可少的的,配套拿下:

硬件定下来后,自己尝试安装jetpack6.2的系统,发现使用虚拟机安装真是一言难尽,奉劝大家还是直接搞台linux的机器安装。我是被虚拟usb接口搞了两个小时,实在不想继续了。
三、 系统安装与模型选择
正常的安装是去https://www.nvidia.cn/官网,寻找安装教程,其中主要是英伟达的资源需要账号,而且不同的资源需要不同的账号,反正我都有点懵为啥要不同网站不同账号。找到安装教程直接安装,安装后使用jtop命令,查看安装情况。
提示:做嵌入式边缘设备的系统linux一定要格外关注软件版本号,虽然现在软件做的原来越灵活,但是嵌入式设备的软件版本一定要对应,例如CPU架构,例如接口定义;以前的芯片供应商就直接给你全套的芯片和软件,要是修改的话只能在这些代码里面改,不能安装软件,现在可以安装软件,但有些还是有些错误的,(例如数据类型,安装labelimg的时候就需要修改数据类型才能跑起来)
需要说明的是系统安装的是作为边缘智能设备使用的,使用yolov做训练还有一些软件库需要额外安装,因为版本原因,所有的软件版本都必须对应硬件能够使用的版本(jetson orin nx的jetpack6.2系统版本是需要跟一些库配套的),具体配套版本,需要到这个网站Jetson Zoo - eLinux.org去对应下载和安装(eLinux.org这个网站非常好,涉及的嵌入式linux软件基本都能找到对应版本的)。系统方面安装后,因为人工智能这块一般用的是python,所有我安装了一些与jetson 对应的版本的pithon库(如果不对应版本,可能出错或调用不了硬件加速)。我在这个网站https://pypi.jetson-ai-lab.io/里面找到所需的软件库(要按照自己对应的硬件和软件版本下载)。
我对图像识别基本门外汉,找了几本书算是浏览吧,觉得使用yolo这个模型挺牛的,就用这个吧,让后有朋友介绍supervision在图象识别和追踪上特别好,我又参考了一部分资料;下载了一些github上的项目来看代码。使用了yolov8s这个模型,使用predict()和track()最足球识别和目标跟踪。代码跑起来后,发现识别率太低了。就用yolov8s+supervison的追踪试了一下,也是这样的效果。知道这个还是需要自己训练模型参数来做。
小知识:模型,权重,交换文件,部署文件,分别是model ,.pt , .onnx , .engine 文件;我们训练出来的权重文件.pt .pt文件可以使用yovo export命令转换成onnx文件或.engine文件。
下面是很多ai说要使用把.pt的export 成engine文件的速度会快一点,以下是命令,实际上转换成.onnx文件也是用这个命令;
yolo task=detect export model=football_01_train.pt format=engine device=0 half=True但在实际使用用,我觉得使用.pt文件,然后直接在代码中增加以下代码:
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = YOLO(MODEL_PT).to(device)上面两种方法,第一个是把.pt权重文件被转换成.engine文件,可被tensor或模型识别的部署文件,直接放进GPU按文件的要求运行。第二个是把带.pt文件的模型直接放进GPU,GPU 根据实际情况来部署和运行。
在实际中,我肉眼观察到的结果发现速度没啥区别,那个人更倾向第二种方法,也不知道还有什么区别没有。主要是这个转换耗时间啊。
四、 标识软件
鉴于直接使用yolov8的sports ball(原.pt文件的标签一定要跟原有uyil文档相适配,包括格式,外面教程和AI出来的不知道是哪个版本的,会有稍微误差,踩坑。。。,请注意规避),直接使用一个循环代码识别一个带足球的MP4文件,发现速度很慢,识别率?嗯,基本约等于零。
根据AI的意见:-),需要重新训练一下权重,那首先需要大量的足球视频,我去拍了一些,麻烦的是拍了一小时,标注才是大活:-( ,实在是受不了手工标注,例如labelimg,就搜索了自动标注软件;选了一个比较适合我的,x-anylabeling,下载网站是CVHub520/X-AnyLabeling: Effortless data labeling with AI support from Segment Anything and other awesome models.;因为也是初学,在jetson 上训练(就是需要安装一堆软件,后来才发现其实不需要的),在windows训练,最后发现流程应该如下:
1、 采集素材
也就是去组球场拍了一个小时,最好是角度相同的,还有图片尺寸最好一致(不一样也可以)。
2、预处理
在windows上,把图片使用x-anylabeling的工具预处理,直接在网页的release下载Windows的cpu版本就能使用,如果有gpu的应该需要下载源码自己编译。打开软件后是主界面(不同版本可能略有不同)
点击右下角的(AI)自动标注按钮,就会出现选用识别模型,如果是自己设定的模型,当然一定要有一个yaml文件,指定模型与标签(标签一定要跟模型对应,后面的过滤也一定要按下面的格式,否则就会出错。(都是格式的坑,ai这个大坑),我这里只识别足球。
type: yolov8
name: yolov8_persion_ball
display_name: yolov8_persion_ball
model_path: model_yolov8s/yolov8s.onnx
input_width: 1280
input_height: 1280
nms_threshold: 0.45
confidence_threshold: 0.25
# COCO 80 类,与官方模型完全一致
classes:
- person
- bicycle
- car
- motorcycle
- airplane
- bus
- train
- truck
- boat
- traffic light
- fire hydrant
- stop sign
- parking meter
- bench
- bird
- cat
- dog
- horse
- sheep
- cow
- elephant
- bear
- zebra
- giraffe
- backpack
- umbrella
- handbag
- tie
- suitcase
- frisbee
- skis
- snowboard
- sports ball
- kite
- baseball bat
- baseball glove
- skateboard
- surfboard
- tennis racket
- bottle
- wine glass
- cup
- fork
- knife
- spoon
- bowl
- banana
- apple
- sandwich
- orange
- broccoli
- carrot
- hot dog
- pizza
- donut
- cake
- chair
- couch
- potted plant
- bed
- dining table
- toilet
- tv
- laptop
- mouse
- remote
- keyboard
- cell phone
- microwave
- oven
- toaster
- sink
- refrigerator
- book
- clock
- vase
- scissors
- teddy bear
- hair drier
- toothbrush
# 在原有 yaml 末尾追加
filter_classes:
# - person
- sports ball
选用了自定义模型后,就可以按右下角的(一次运行)按钮,软件就会按照模型的识别给你标注标签。然后检查每张图片标注是否正确,错了的就删掉,漏检测到的就手动加上去。视频的检测其实也是图片检测,你选择打开视频的时候,会出现让你选择序列长度和每秒多少帧,这里序列长度是指文件名的位数,默认把视频可以分割成是5位数图片,每秒帧的字面意思应该是错的的,实际是原视频多少帧就是多少帧,如果原视频是30帧/s,那么你填30就是1秒1帧。
思考:其实这里可以自由的选用模型(主要是看识别准确度),我选的这个模型yolov8是跟我jetson的设备相配合,其实.pt文件与设备无关,所以应该可以选用其他更好的模型。但是这样标签的导出不知道会不会有问题。
识别后,x-anlabeling只会生成json文件,但这个还是不能被yolov8的训练工具识别,需要导出,点击(导出)(导出YOLO水平框标签),先要输入一个txt文件,这个txt文件应该是记录标签意义的,好像没有啥用。随便放一个txt文件,你有多少个标签就写多少行的标签名称。继续后就会出现一个label文件夹,文件夹里就是yovo能够辨认的txt文件,(这个txt应该是位置文件,点位置、长、宽)。把这个图片和txt分别放在两个文件夹中,需要再做一些处理;运行代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
一键生成 YOLOv8 标准数据集目录
python make_yolo_set.py
yolo task=detect mode=train data=dataset/data.yaml model=yolov8s.pt \
epochs=100 imgsz=1280 name=football_1280s
yolo task=detect mode=train data=dataset\data_yolov8s\data.yaml model=data_tools\model_yolov8s\yolov8s.pt epochs=100 imgsz=320
"""
import os
import shutil
import random
from pathlib import Path
# ========== 用户只需要改这里 ==========
IMAGE_DIR = r'../data_src/data_src/' # 原始图片目录(jpg/png/...)
LABEL_DIR = r'../data_src/labels/' # 原始 txt 标注目录
DATASET_ROOT = r'../dataset/data_yolov8s' # 想要生成的数据集根目录
SPLIT = (0.8, 0.1, 0.1) # train/val/test 比例,和须为 1
CLASS_NAMES = ['football'] # 与标注 id 顺序一致
SEED = 42
# =====================================
random.seed(SEED)
def make_yolo_set():
img_paths = sorted([p for p in Path(IMAGE_DIR).glob('*')
if p.suffix.lower() in {'.jpg','.jpeg','.png','.bmp','.tif'}])
assert img_paths, f'没有在 {IMAGE_DIR} 找到图片!'
# 过滤:只保留“图片+标签”同时存在的
pairs = []
for img_p in img_paths:
txt_p = Path(LABEL_DIR) / f'{img_p.stem}.txt'
if txt_p.exists():
pairs.append((img_p, txt_p))
assert pairs, '图片和 txt 标注没有完全匹配,请检查文件名!'
random.shuffle(pairs)
n = len(pairs)
n_train = int(n * SPLIT[0])
n_val = int(n * SPLIT[1])
# 其余归 test
splits = {
'train': pairs[:n_train],
'val' : pairs[n_train:n_train+n_val],
'test' : pairs[n_train+n_val:]
}
# 创建目录
for split in splits:
(Path(DATASET_ROOT)/'images'/split).mkdir(parents=True, exist_ok=True)
(Path(DATASET_ROOT)/'labels'/split).mkdir(parents=True, exist_ok=True)
# 拷贝文件
for split, items in splits.items():
for img_p, txt_p in items:
shutil.copy2(img_p, Path(DATASET_ROOT)/'images'/split/img_p.name)
shutil.copy2(txt_p, Path(DATASET_ROOT)/'labels'/split/txt_p.name)
print(f'{split}: {len(items)} 张')
# 生成 data.yaml
yaml_path = Path(DATASET_ROOT) / 'data.yaml'
with yaml_path.open('w', encoding='utf-8') as f:
f.write(f'train: {Path(DATASET_ROOT).absolute()}/images/train\n')
f.write(f'val: {Path(DATASET_ROOT).absolute()}/images/val\n')
if splits['test']:
f.write(f'test: {Path(DATASET_ROOT).absolute()}/images/test\n')
f.write(f'\nnc: {len(CLASS_NAMES)}\n')
f.write(f'names: {CLASS_NAMES}\n')
print(f'\n已生成 {yaml_path},可直接 yolo train data={yaml_path}')
if __name__ == '__main__':
make_yolo_set()运行上面代码后,就可以得到训练所需的文件目录;
3、训练
在终端输入命令就可以训练,训练时间跟你的设备与数据大小有关。使用以下明以下命令:
yolo task=detect mode=train data=..\database\data_yolov8s\data.yaml model=..\database\model\model_yolov8s\football_01_train.pt epochs=100 imgsz=1280
一些参数自己去设置,我也刚学很多参数都不明白效果如何。基本都是默认的。
4、执行识别效果
准确度:还没有定量的识别到的准确度,只是看着视频跑,看看能识别到多少个足球,和什么时候看到足球。结果很不好,识别率很低。
速度(实时性):这个用来做功能性的代码实时性肯定差的,不过imgsz=1280 在jetson orin nx 8G设备上跑起来也需要做处理,不过我觉得这台设备的性能,这是可以解决的。
功耗:主芯片20W的功耗,基本没有别的芯片能够达到这个水平了。
五、 后续学习研究
1、软件开发
不知道是否Python的效率比较低,我是觉得比起以前用qt c++写的代码要慢点。但是设备进化了好多啊。第一版软件开发肯定做到功能如下
1)控制云台让镜头对着足球跑;(防抖和坐标变换)
2)能够根据需求显示;
3)能够保存图像;
2、图像识别的优化
这个刚刚开始学习,想到的做法有可能是下面的:
1)分割训练 (imgsz=1280的实时性估计很难办到),然后使用分割训练配合分割图像识别,估计会好很多。
2)图片的要求,是否预处理有很多花样的?我如果拍的照片的角度和大小是否需要一致或做一些处理。(学习ing)
3、硬件开发
1) 云台,二维云台,精度需要。。。
2)摄像头, 考虑中。。。
3)结构, 考虑中。。。
以此文希望对足球感兴趣的朋友一起交流。;-)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)