四、RAG与LlamaIndex
RAG(检索增强生成)是一种结合检索和生成技术的方法,通过从文档库中检索相关信息来提升大模型回答的准确性。它解决了大模型的知识局限性、幻觉问题和数据安全等挑战。RAG分为原始、高级和模块化三个阶段,LlamaIndex作为开源框架,支持数据整合、索引构建和增强LLM推理能力,帮助开发者构建知识助手和AI代理。相比重新训练或微调模型,RAG成本更低、信息实时更新且结果更可信。LlamaCloud则提
前言
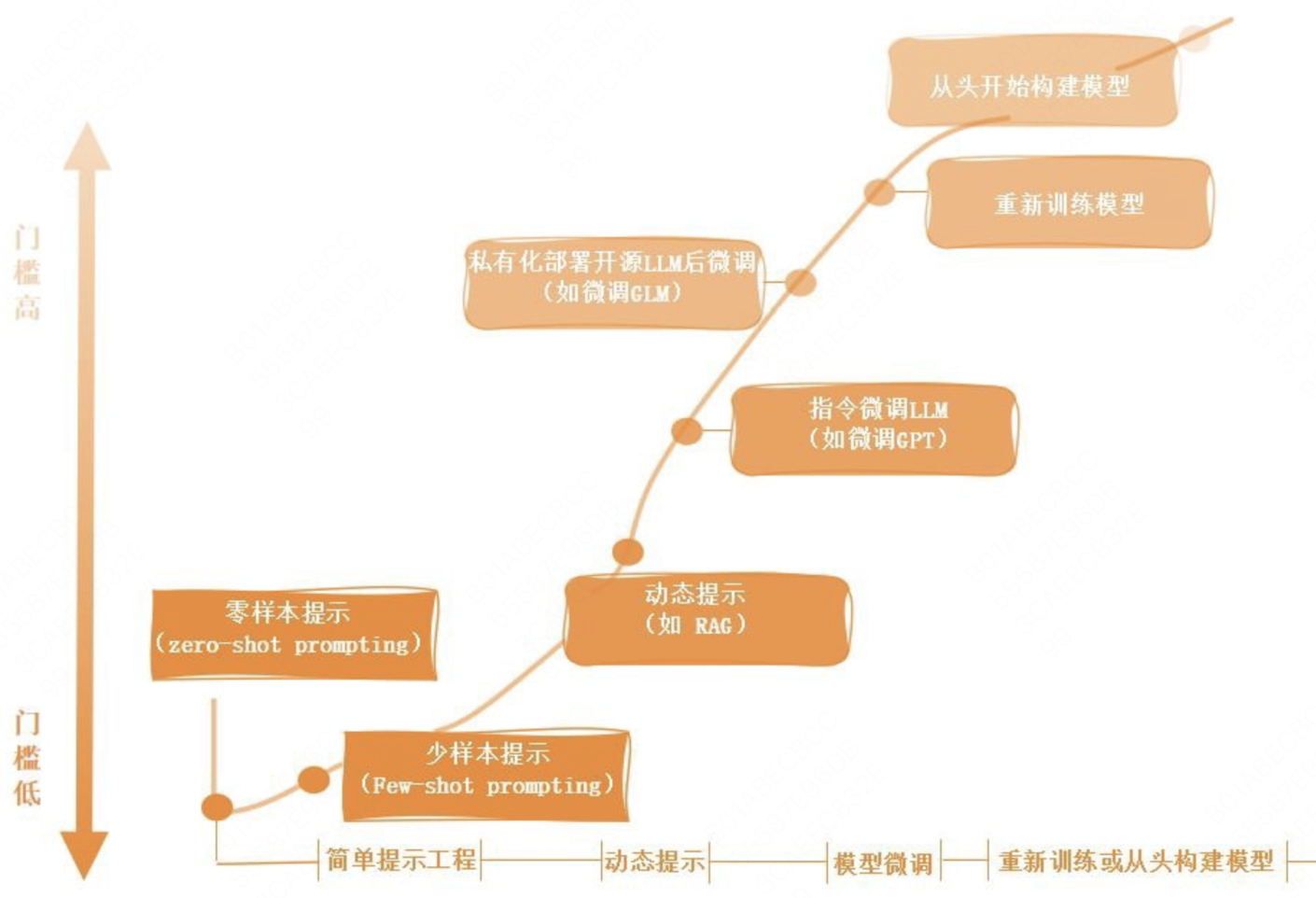
大模型要被特定行业所用,从难到易有4种方式,分别是重新训练或从头构建模型、微调模型、动态提示(RAG就是其中一种技术)和简单提示工程。RAG位于大模型应用难易链条的中部,它既不像重新训练或从头构建模型或者微调模型那么难,也不像通过简单提示工程直接向大模型提问那么容易。它克服了直接微调模型的3个缺点——成本高、信息更新困难以及缺乏可观察性。相较而言,由于RAG无须训练,因此成本较低;由于数据是实时获取的,因此始终是最新的;由于可以显示检索到的文档,因此结果更加可信。
LlamaIndex。它提供了各种框架、工具和模式,支持吞吐、结构化和访问私有或特定领域的数据,可以让RAG开发过程变得更加轻松。
RAG简介
RAG的定义
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索和生成技术的方法。2020年,Facebook AI Research(FAIR)团队发表名为《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》的论文,该篇论文首次提出了RAG概念。在2022年后,特别是ChatGPT的提出,NLP迈入大模型时代,RAG被发扬光大。在大语言模型(Large Language Models)的领域中,RAG特指一种模式:模型在回答问题或生成文本时,首先从广阔的文档库中寻找相关信息。然后,模型使用这些找到的信息来生成回答或文本,从而提高其预测的准确度。RAG的方法使得开发人员无需为每一个特定任务重新训练整个庞大的模型,他们可以简单地给模型加上一个知识库,通过这种方式增加模型的信息输入,从而提高回答的精确性。
大模型的局限
日常我们将大模型应用于实际业务场景时,会发现通用的基础大模型基本无法满足实际的业务需求,主要有以下几方面原因:
-
知识的局限性:信息滞后,大模型往往是基于某一个时间点之前的数据进行的训练,对于一些高时效的场景,如天气、新闻、政策等,只依赖大模型基本上无法得到正确的答案。私有数据匮乏,LLM的训练数据主要来源于互联网公开的数据,而垂类领域、企业内部等有很多专属知识,这部分是LLM无法直接提供的。
-
幻觉:大模型的底层生成原理是基于概率,自身并不具备任何判断回复是否符合现实世界事实的能力,所以有时候会一本正经胡说八道,即模型会出现幻觉问题。
-
token大小:目前,不同模型对token的限制也不同,token的限制会导致无法给到模型足够的外部知识。
-
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案,不得不在数据安全和效果方面进行取舍。
RAG的分类
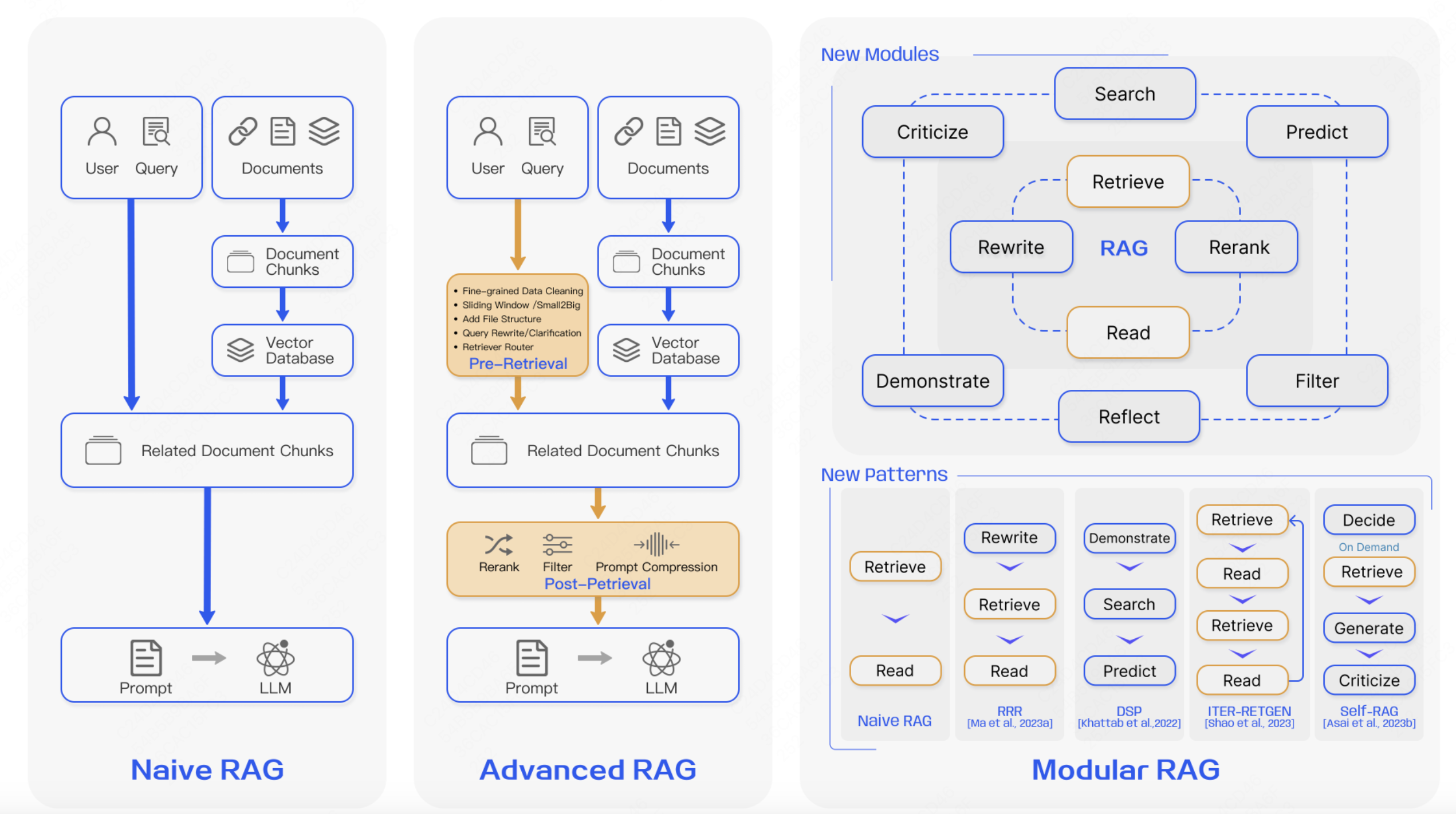
RAG作为一种工程化解决方案,能够有效解决上述问题。目前RAG已经经过一轮迭代发展,主要分三个阶段,分别是原始RAG、高级RAG、模块化RAG,三者的大致区别如下图所示。原始RAG只具备了最基础的部分:离线索引构造、在线检索以及大模型生成。高级RAG则是在这3个流程里增加更多细化的工作,用于进一步优化,例如数据预处理、滑动窗口、文章切片、用户query重写等,重点在检索层面的优化,提升检索模块的质量。而模块化RAG则是一个更为精细的系统,它是高级RAG在工程化上的改进,对RAG流程步骤和能力做模块化,供各个业务场景灵活的选择和编排。
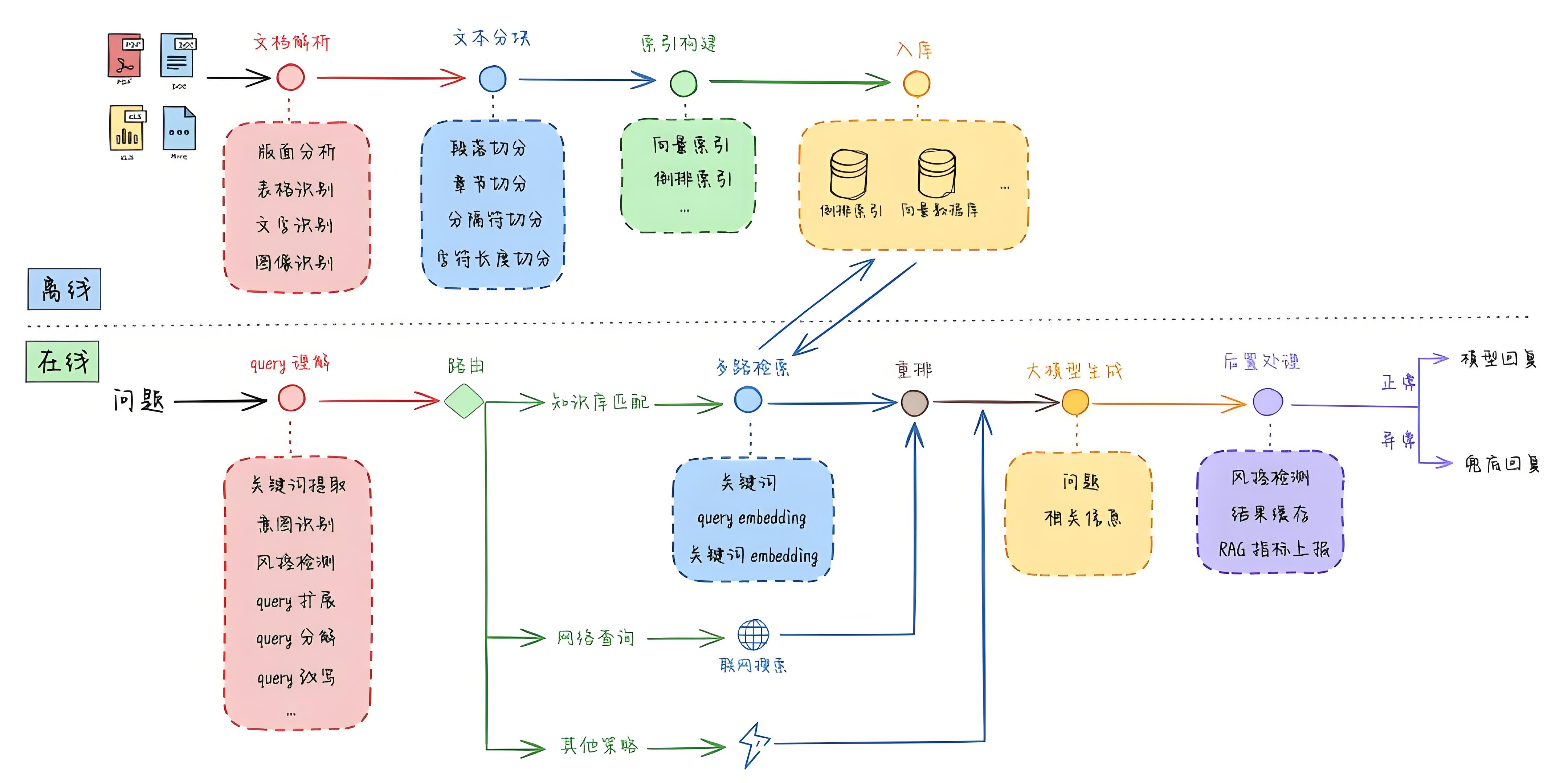
RAG的架构
如图所示,是一个RAG的基本架构,可以分为离线和在线两部分。
-
离线:对知识库文档进行解析、拆分、索引构建和入库。这部分会从用户给定的文档、图片、表格和外部URL等资源中提取内容,然后通过chunking(可以认为是将连续的文本分成一个个小块)进行合理切割,再使用Embedding模型变成向量数据存入向量数据库或elasticsearch等载体中,同时结合这些非结构化文件所附带的元数据(时间、文件名、作者、副标题、文件类型等)进行索引创建。
-
在线:当用户输入问题之后,我们会对query进行分析,如关键词提取、意图识别等,然后再根据路由条件进行知识库的多种召回检索或者联网搜索等。如果是做向量数据库的检索,会先将查询内容通过Embedding模型转化为向量数据,接着在向量数据库中进行相似度匹配,比如从百万的数据块中找出匹配度较高的100个,然后再将这100个数据块进行更精准的重排序,将最相关的top k结果找到,最后将用户问题,经过处理的top k数据块,还有prompt一起提交给LLM,让它生成最终可靠的答案。
LlamaIndex简介
LlamaIndex开放于2022年11月,和ChatGPT同时诞生,距离LangChain问世也仅有一月之隔。这两个库都受到ChatGPT的强烈影响和催化,并得到广泛应用和认可。
LlamaIndex项目由Jerry Liu创建,在2023年6月获得850万美元的种子资金。由于这个项目解决了大模型训练时只具有数据知识的局限性,因此它在AI社区广受欢迎。
和LangChain的策略略有不同,LlamaIndex并不是那么“大”而“全”,而是特别关注如何开发先进的基于AI的RAG技术,以及多租户RAG系统的建立。基于LlamaIndex的企业解决方案旨在消除技术和安全壁垒,增强企业的数据使用和服务能力。LlamaIndex的相关工作不仅关注技术开发,还涉及将这些技术应用于实际场景,以提高业务效率和用户体验。
LlamaIndex用于帮助开发者将大语言模型(LLM)与各种数据源连接起来,构建知识助手和 AI 代理,主要功能是将私有或特定领域的数据注入、结构化,并使其能够被访问。通俗来说,它就像是给大语言模型(LLM)配备了一个“智能数据管家”,帮助 LLM 理解和处理各种数据。
核心功能
-
数据连接与整合
LlamaIndex 提供了统一的接口,支持接入多种数据源:- 结构化数据(SQL 数据库、Excel、CSV 等)
- 非结构化数据(PDF、Word、Markdown、网页等)
- API 接口(第三方服务、内部系统数据)
通过数据加载器(Reader)将不同格式的数据转换为标准化的文档对象,简化数据预处理流程。
-
知识结构化与存储
对于海量或复杂数据,LlamaIndex 提供了灵活的知识组织方式:- 文档拆分:将长文本按语义或固定长度拆分为 “节点”(Node),避免超出 LLM 上下文限制。
- 索引构建:通过向量索引(Vector Index)、列表索引(List Index)、树索引(Tree Index)等结构,优化数据检索效率。其中,向量索引(基于嵌入模型将文本转为向量)是最常用的方式,支持快速语义匹配。
- 存储集成:可对接向量数据库(如 Pinecone、Milvus、Chroma)或本地文件系统,实现知识的持久化管理。
-
增强 LLM 推理能力
LlamaIndex 解决了 LLM 原生的 “知识滞后” 和 “缺乏私有数据” 问题:- 检索增强生成(RAG):在生成回答前,自动从索引中检索与问题相关的上下文数据,让 LLM 基于最新 / 私有信息生成答案,减少幻觉。
- 多步推理:支持复杂问题的拆解(如 “先检索 A,再基于 A 的结果检索 B”),通过 “查询引擎”(Query Engine)或 “聊天引擎”(Chat Engine)实现多轮对话与逻辑推理。
- 自定义提示词(Prompt):允许开发者根据场景定制提示词模板,优化 LLM 的输出格式和质量。
优势
-
数据整合与索引构建
-
打破数据孤岛:LlamaIndex 支持从 PDF、数据库、API 等 100 多种数据源提取信息,将分散在不同地方的数据整合起来,构建统一的索引。比如企业内部的文档、医疗报告等私有数据,都可以通过 LlamaIndex 被 LLM 所利用。
-
多种索引类型:它提供了多种索引结构,如向量存储索引、总结索引和知识图谱索引等。这些不同类型的索引可以根据应用场景和查询策略进行选择,以达到最优的检索效果。
-
-
提升检索效率与问答能力
-
动态知识更新:借助语义分块与向量化技术,LlamaIndex 能突破 LLM 的上下文长度限制,实现 TB 级数据的高效检索。这意味着即使数据量非常庞大,也能快速找到与问题最相关的部分。
-
智能问答增强:结合混合检索(语义 + 关键词)与响应合成引擎,LlamaIndex 能生成带溯源的可信回答,解决了传统 LLM 的“知识滞后”问题。它让 LLM 在回答问题时能够提供更准确、更相关的内容。
-
-
开发者友好与灵活性
-
模块化设计:LlamaIndex 的组件设计非常灵活,开发者可以根据自己的需求自定义数据处理管道、索引构建流程等。比如可以自由选择不同的索引类型、查询引擎和数据加载器。
-
灵活易用:仅需几行代码即可实现基本功能,支持多种数据源和格式,提供从基础到高级的完整工具链,支持创建复杂的 LLM 工作流程。
-
开源与社区支持:作为一个开源项目,LlamaIndex 拥有活跃的社区和不断更新的文档,开发者可以轻松获取帮助和资源。
-
LlamaCloud
LlamaCloud 是基于 LlamaIndex 的托管服务,为企业提供了一个全托管的平台,用于数据解析、摄取和检索。LlamaCloud 是一个云服务,旨在为基于大语言模型(LLM)和检索增强生成(RAG)的应用程序提供生产级别的上下文增。LlamaCloud提供文档上传、解析、索引及搜索服务。它可以帮助企业 AI 工程师专注于编写业务逻辑,而无需处理数据。LlamaParse 。LlamaExtract(beta 版)用于从未结构化的文档和文本中提取结构化数据,同样可通过 web UI、Python 包或 REST API 使用。
LlamaIndex VS LlamaCloud
|
LlamaIndex |
LlamaCloud |
|
|---|---|---|
|
功能定位 |
是一个开源框架,侧重于提供灵活的数据处理和索引构建工具,让开发者能够自定义数据处理管道、索引类型和查询策略。 |
是一个托管服务,专注于提供生产级别的数据解析、摄取和检索功能,减少企业开发者的数据管理负担,让他们更专注于业务逻辑。 |
|
使用方式 |
需要开发者自行部署和管理,适合有一定技术能力的团队,可以根据具体需求进行高度定制。 |
提供托管的 API 和界面,用户可以通过简单的配置和调用快速使用其功能,无需担心底层的基础设施。 |
|
适用场景 |
适用于需要高度定制化和灵活性的开发场景,适合中小型企业或有特定需求的项目。 |
更适合企业级应用,尤其是那些需要处理大量生产数据、对数据安全和合规性有严格要求的场景。 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)