【每天一个知识点】RAG 中的增强生成(Augmented Generation)
摘要:RAG中的增强生成(Augmented Generation)通过将检索到的外部知识注入生成过程,显著提升大模型输出的准确性和可信度。其核心流程包括文档裁剪拼接、Prompt构建和基于知识的答案生成,能有效减少幻觉、增强时效性并实现领域适配。相比传统生成方式,增强生成支持知识溯源,并可通过片段拼接、知识图谱、工具调用等多种方式实现,是RAG区别于普通大模型的关键技术环节。(149字)
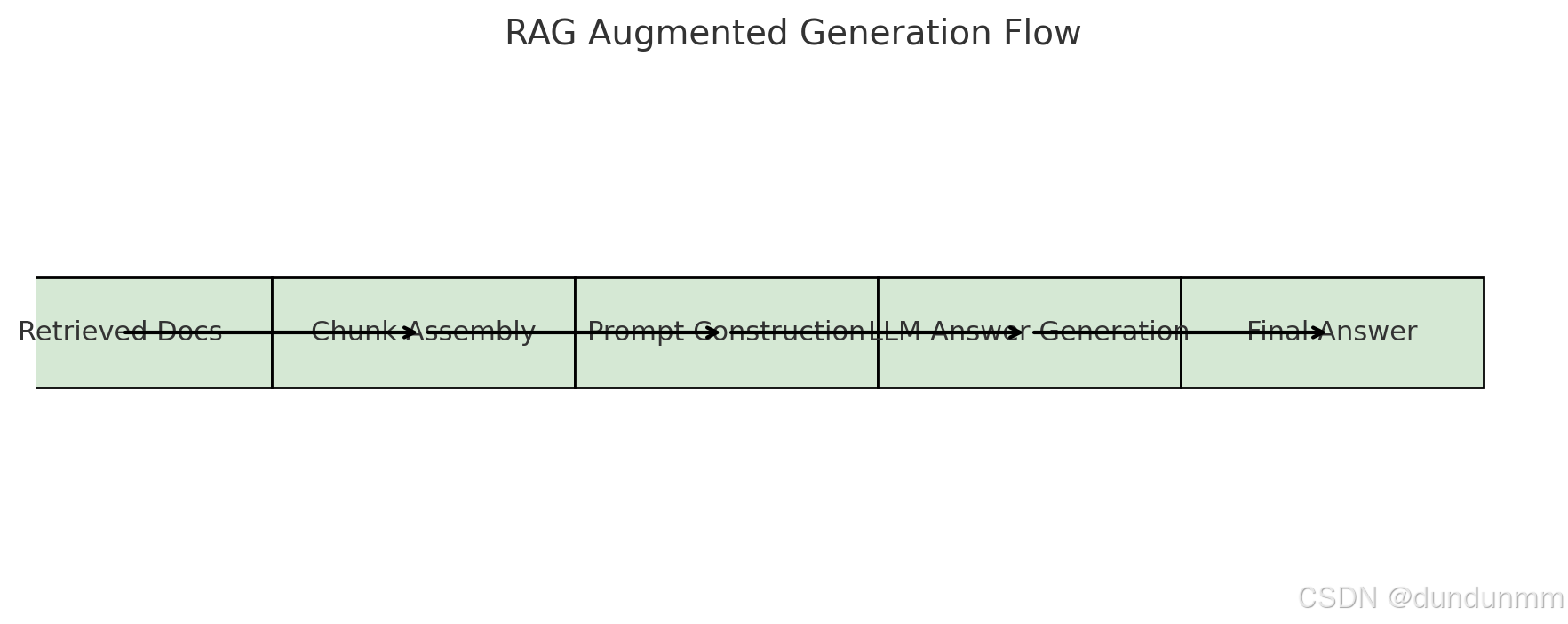
好的,我们前面讲了 RAG 中的检索(Retrieval),现在来看另一半:增强生成(Augmented Generation)。这是 RAG 与普通大模型生成的最大区别。
1. 增强生成的核心思想
在传统的生成式大模型(如 GPT、LLaMA)中,回答完全依赖模型参数内部存储的知识,这些知识有时过时、片面或不足。
而 增强生成(Augmented Generation) 的关键在于:
-
把检索到的外部知识注入到生成过程,让模型在回答时“既有记忆,也有参考”。
-
这样生成结果 更准确、更可信、更可控,还能附带引用来源。
2. 增强生成的流程
增强生成通常包含以下几个步骤:
-
文档裁剪与拼接(Chunk Assembly)
-
将检索到的文档片段压缩/改写为合适的上下文,拼接到 Prompt 中。
-
常用方法:Top-k 片段拼接、窗口拼接、动态摘要。
-
-
Prompt 构建(Prompt Engineering)
-
把用户问题 + 相关文档组织成结构化的提示词。
-
例如:
给定以下文档片段,请基于其中信息回答用户问题: [片段1] ... [片段2] ... 用户问题:... -
这样能引导模型尽量“引用事实”,而不是“凭空生成”。
-
-
大模型回答生成(LLM Answering)
-
模型根据 Prompt 中的外部知识和自身语义能力,生成答案。
-
输出可包含:
-
回答内容
-
引用文档编号
-
不确定性提示(如“未找到相关信息”)
-
-
3. 增强生成的优势
-
减少幻觉:模型更少编造信息。
-
提升可信度:答案可回溯来源。
-
增强时效性:知识库可随时更新,突破模型训练数据的时效限制。
-
领域适配:通过注入行业文档(法律、医学、能源等),实现行业大模型。
4. 典型增强方式
-
片段拼接增强(Context Augmentation):最常见方式,把检索内容直接拼到输入里。
-
知识图谱增强(Knowledge Graph Augmentation):结合实体、关系、推理路径。
-
工具增强(Tool-Augmented Generation):在生成过程中调用外部 API 或计算工具。
-
动态聚类增强(您正在研究的方向):通过动态聚类和语义组织,把相似或相关的知识点自动组合成“知识块”,再注入模型。
5. RAG 全流程位置
用户问题 → 检索 (Retrieval) → 外部知识
↓
增强生成 (Augmented Generation)
↓
模型回答 (Answer)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)