RAG神技实战:小白秒变SQL大神!AI自动翻译人话成查询,从入门到精通一篇搞定!
在我们之前的文章中我们已经了解了两种预检索的优化策略。比如怎么“翻译”用户那七零八落的问题,还有怎么做一个聪明的“导航员”,把问题带到正确的数据源。
在我们之前的文章中我们已经了解了两种预检索的优化策略。比如怎么“翻译”用户那七零八落的问题,还有怎么做一个聪明的“导航员”,把问题带到正确的数据源。
那么,现在问题来了,我们知道去哪里找数据了,那我们如何查不同类型的数据呢?
这就是我们今天想聊的另一种预检索优化策略:查询构建(Query Construction)。
在本文中,我们将聚焦于如何将用户的自然语言问题,翻译成数据源能理解的那套"行话"。比如SQL语言,或者Cypher查询语句。
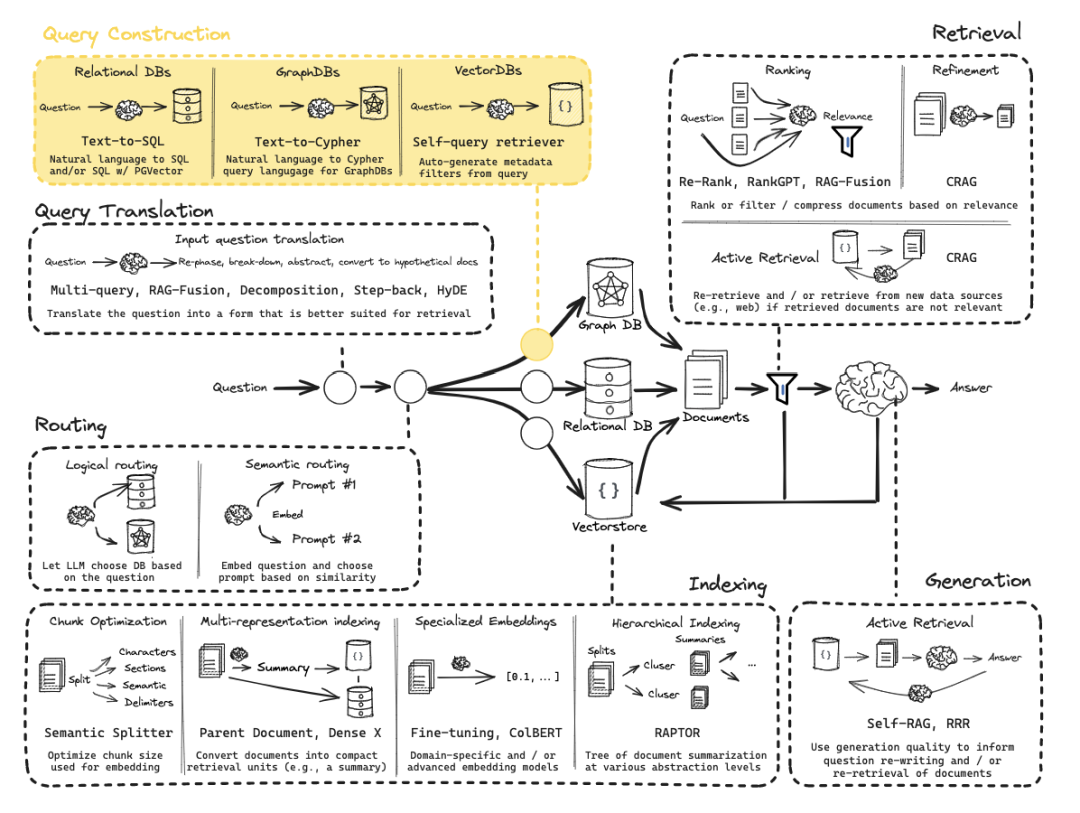
什么是查询构建?
传统那套RAG,把问题变成一串向量数字,再去另一堆向量数字里找最相似的。这招在处理非结构化的文字,比如博客、文章时,确实管用。我得承认,这很巧妙。
但世界不是只有文字啊。
要是我们面对的是一张冷冰冰的Excel表,或是一座结构严密、壁垒分明的关系型数据库呢?我第一次遇到这个问题时,真的有点懵。你总不能跟一张员工薪资表谈“语义相似”吧?它有它的脾气,有行有列,有不容置疑的数据类型。跟它打交道,你得说它的“方言”——那些结构化的查询语言。
这感觉,就像从一个诗人,突然要转变成一个会计。
查询构建技术流派
1. Text-to-SQL – 从自然语言到SQL转换
企业里最常见的就是这种“会计式”的数据了。MySQL、PostgreSQL… 它们就像一个个巨大的账本,记录着一切。
一个真正好用的RAG系统,我觉得它不应该偏科,不能只会读诗(非结构化文档),也得会算账(结构化数据)。
如果能让系统自己学会把我们的日常白话,转换成SQL,那该多好。用户只管提问,系统默默地把查询、整合、生成答案这些脏活累活全干了。这听起来才够智能,不是吗?
要做到这一点,其实没那么玄乎。关键就两步:
- 数据库描述: 你得先让大模型看明白数据库长什么样,有哪些表,表里有哪些字段。
- 少量示例: 在提示词里给它几个标准提问的例子,它就能有样学样。
用一个简单的实现流程代码来理解:
- 创建一个
SQLite数据库,并创建一个包含一些示例数据的sales_database表。import sqlite3 def__init__(self, db_path="sales_database.db"): """ 初始化转换器 Args: db_path (str): SQLite数据库文件路径 """ self.db_path = db_path self.conn = None self.cursor = None defconnect_database(self): """连接数据库""" try: self.conn = sqlite3.connect(self.db_path) self.cursor = self.conn.cursor() print(f"✅ 成功连接数据库: {self.db_path}") except Exception as e: print(f"❌ 数据库连接失败: {e}") raise defcreate_sample_database(self): """创建示例数据库和数据""" try: # 创建销售数据表 self.cursor.execute(''' CREATE TABLE IF NOT EXISTS sales_data ( id INTEGER PRIMARY KEY AUTOINCREMENT, product_name TEXT NOT NULL, quantity INTEGER NOT NULL, sale_date TEXT NOT NULL, revenue REAL NOT NULL, region TEXT NOT NULL, customer_type TEXT NOT NULL ) ''') # 清空现有数据 self.cursor.execute('DELETE FROM sales_data') # 插入示例数据 sample_data = [ ('iPhone 15', 10, '2023-07-15', 15000.0, '北京', '个人'), ('iPhone 15', 5, '2023-08-10', 7500.0, '上海', '个人'), ('MacBook Pro', 20, '2023-07-20', 40000.0, '广州', '企业'), ('iPhone 15', 15, '2023-09-01', 22500.0, '深圳', '个人'), ('iPad Air', 7, '2023-09-15', 3500.0, '北京', '个人'), ('MacBook Air', 12, '2023-08-25', 12000.0, '上海', '企业'), ('iPhone 14', 8, '2023-07-30', 8000.0, '成都', '个人'), ('iPad Pro', 6, '2023-09-10', 7200.0, '杭州', '企业'), ('MacBook Pro', 3, '2023-08-05', 6000.0, '武汉', '个人'), ('iPhone 15 Pro', 25, '2023-09-20', 37500.0, '北京', '企业'), ] self.cursor.executemany(''' INSERT INTO sales_data (product_name, quantity, sale_date, revenue, region, customer_type) VALUES (?, ?, ?, ?, ?, ?) ''', sample_data) self.conn.commit() print("✅ 示例数据库和数据创建成功") # 显示数据统计 self.cursor.execute('SELECT COUNT(*) FROM sales_data') count = self.cursor.fetchone()[0] print(f"📊 数据库中共有 {count} 条销售记录") except Exception as e: print(f"❌ 数据库创建失败: {e}") raise - 使用LLM生成查询
import os
from dotenv import load_dotenv
from langchain_deepseek import ChatDeepSeek
from langchain_core.prompts import ChatPromptTemplate
defgenerate_sql(self, natural_query):
"""
使用DeepSeek模型生成SQL查询
将所有SQL生成相关的初始化和配置集中在此函数中,便于理解整个生成流程
Args:
natural_query (str): 自然语言查询
Returns:
str: 生成的SQL语句
"""
try:
print("🔧 步骤1: 初始化DeepSeek模型...")
# 初始化DeepSeek模型
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.1, # 设置较低温度确保SQL生成的准确性
max_tokens=1024,
api_key=os.getenv("DEEPSEEK_API_KEY"),
)
print("📋 步骤2: 准备数据库Schema信息...")
# 数据库schema信息
schema_info = """
数据库Schema信息:
表名: sales_data
字段说明:
- id: INTEGER PRIMARY KEY (主键,自增)
- product_name: TEXT (产品名称)
- quantity: INTEGER (销售数量)
- sale_date: TEXT (销售日期,格式:YYYY-MM-DD)
- revenue: REAL (销售收入)
- region: TEXT (销售区域)
- customer_type: TEXT (客户类型:个人/企业)
"""
print("📝 步骤3: 创建SQL生成提示模板...")
# 创建SQL生成提示模板
sql_prompt = ChatPromptTemplate.from_template(
"""
你是一个专业的SQL查询生成专家。基于以下数据库schema,将用户的自然语言查询转换为准确的SQL语句。
{schema}
规则要求:
1. 只生成SQL语句,不要包含任何解释文字
2. 确保SQL语法正确且符合SQLite标准
3. 使用适当的聚合函数、WHERE条件、GROUP BY、ORDER BY等
4. 日期比较请使用字符串比较(如:sale_date >= '2023-07-01')
5. 产品名称匹配请使用LIKE操作符支持模糊查询
6. 如果查询涉及时间范围,请合理解释季度、月份等时间概念
用户查询: {query}
SQL语句:"""
)
print("⚙️ 步骤4: 格式化提示词...")
# 格式化提示词
formatted_prompt = sql_prompt.format(
schema=schema_info, query=natural_query
)
print("🤖 步骤5: 调用DeepSeek模型生成SQL...")
# 调用DeepSeek模型生成SQL
response = llm.invoke(formatted_prompt)
sql_query = response.content.strip()
print("✨ 步骤6: 清理和格式化SQL语句...")
# 清理SQL语句(移除可能的markdown格式)
if sql_query.startswith("```sql"):
sql_query = sql_query.replace("```sql", "").replace("```", "").strip()
elif sql_query.startswith("```"):
sql_query = sql_query.replace("```", "").strip()
print("✅ SQL生成完成!")
return sql_query
except Exception as e:
print(f"❌ SQL生成失败: {e}")
returnNone
- 执行生成的 SQL 查询
defexecute_sql(self, sql_query): """ 执行SQL查询 Args: sql_query (str): SQL查询语句 Returns: list: 查询结果 """ try: self.cursor.execute(sql_query) results = self.cursor.fetchall() # 获取列名 column_names = [description[0] for description inself.cursor.description] return results, column_names except Exception as e: print(f"❌ SQL执行失败: {e}") returnNone, None - 示例输出
📝 用户查询: 2023年第三季度iPhone 15的总销售收入是多少?
--------------------------------------------------------------------------------
🔄 正在生成SQL查询...
🔧 步骤1: 初始化DeepSeek模型...
📋 步骤2: 准备数据库Schema信息...
📝 步骤3: 创建SQL生成提示模板...
⚙️ 步骤4: 格式化提示词...
🤖 步骤5: 调用DeepSeek模型生成SQL...
✨ 步骤6: 清理和格式化SQL语句...
✅ SQL生成完成!
🔍 生成的SQL: SELECT SUM(revenue) AS total_revenue
FROM sales_data
WHERE product_name LIKE '%iPhone 15%'
AND sale_date >= '2023-07-01'
AND sale_date <= '2023-09-30';
--------------------------------------------------------------------------------
⚡ 正在执行查询...
📊 查询结果:
total_revenue
---------------
82500.0
2. Text-to-Cypher – 从自然语言到图数据库查询
图数据库是一种基于图结构进行数据存储的形式。这东西跟关系型数据库给人的感觉完全不一样。如果说SQL是精准、严谨的法律条文,那Cypher(图数据库的查询语言)就像是在描绘一张复杂的人际关系网。
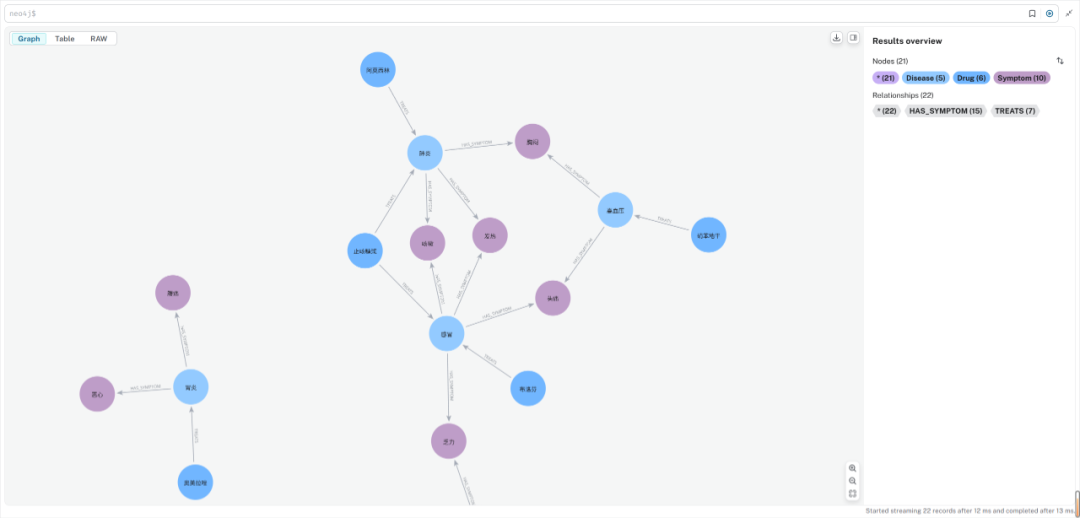
它不关心一行行的数据,它关心的是实体(节点)和它们之间千丝万缕的联系(关系)。
- 一个“糖尿病”是个节点。
- 一个“头痛”症状也是个节点。
- “糖尿病”会有“头痛”这个症状,这个“会有”就是一条关系。
这种结构,简直是为了回答那些“打破砂锅问到底”的复杂问题而生的。
比如,你问:“什么药能治那些既会引起头痛、又会引起发烧的病?”
传统的RAG可能会被问傻,因为它很难找到一篇文章正好把这几样东西都凑在一起说。但对图数据库来说,这太自然了。它会沿着“关系”的藤蔓,一步步帮你把答案“摸”出来。
用它的语言Cypher写出来,大概是这个感觉:
// 寻找同时拥有'头痛'和'发烧'两种症状的疾病
MATCH (s1:Symptom {name: '头痛'}), (s2:Symptom {name: '发烧'})
MATCH (disease:Disease)-[:HAS_SYMPTOM]->(s1)
MATCH (disease)-[:HAS_SYMPTOM]->(s2)
// 寻找能够治疗这些疾病的药物
MATCH (drug:Drug)-[:TREATS]->(disease)
// 返回药物和对应治疗的疾病名称
RETURN drug.name, disease.name
你看,它思考的方式,是不是更像人脑的联想?把自然语言翻译成Cypher的过程,和翻译成SQL大同小异,都是让大模型去理解、匹配、然后生成。
Text-to-Cypher的实现主要流程是:
- 自然语言理解:你先得让它听懂你的“人话”,明白你到底想干嘛。
- Schema匹配:你给它一张家族图谱(数据库的schema),让它把你话里提到的人和事在图谱上对号入座。
- Cypher生成:等它都搞清楚了,它就会学着用图谱的“官方语言”,写出一句像模像样的查询。
- 查询验证与执行:它还会自己检查一下语法,确认无误后才把问题真正递出去。
由于篇幅原因,详细的可运行示例代码,请访问我的GitHub仓库,仓库链接见文章底部。
3. Self-Query Retriever – 通过自然语言生成元数据过滤器
在向量数据库这边,我们虽然可以直接用自然语言去查,但也不是没有优化的空间。在该环节中也有一些预检索优化技巧,Self-Query Retriever就是其中一种。
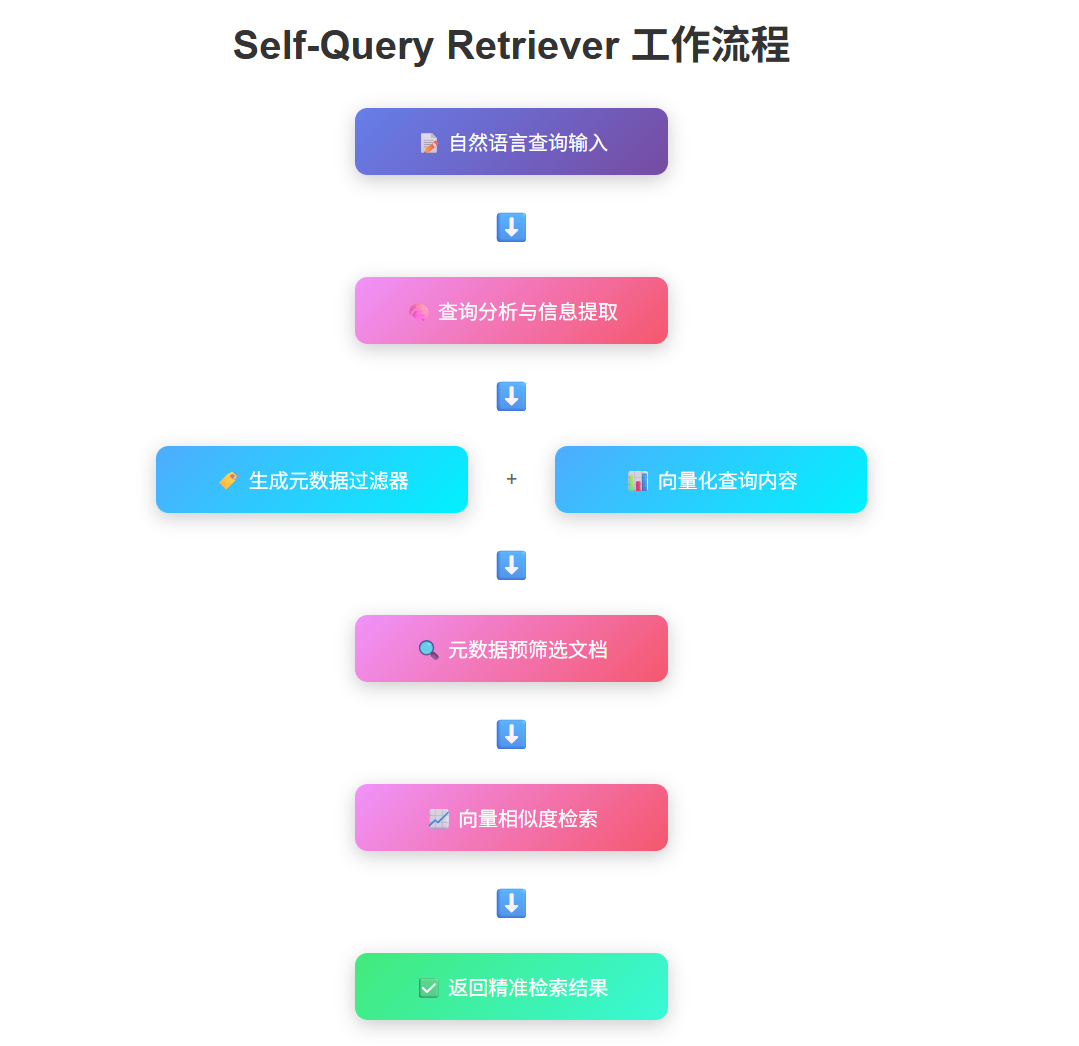
它的想法是:为什么不让用户的提问“自己告诉自己”该怎么查?
它会自动从你的问题里,抠出一些关键词作为“元数据”过滤条件。比如你问“给我找找2023年关于AI的论文”,它会先用“2023”和“AI”这两个硬性条件,把海量的文档筛掉一大批,再在剩下的小范围里去做向量相似度计算。
这不就是我们人脑处理信息的方式吗?先分类,再细看。简单,但极其有效。
同样,这个的完整代码我也放在GitHub上了,有兴趣可以去看看,仓库链接见文章底部。
总结
从SQL的严谨,到Cypher的关联,再到Self-Query的小巧思,我们其实一直在做一件事:努力让机器放下身段,来迁就我们的思考方式。
这不只是个“翻译”工作,我觉得这更像是在驯兽,或者说,是在和一个异类寻找沟通的桥梁。我们希望它能突破那些冷冰冰的数据结构,真正理解我们字里行间那些模糊、跳跃、甚至充满情感的意图。
这个过程还在继续,远没到画上句号的时候。或许,下一代智能应用,真的能像个老朋友一样,听懂我们所有的言外之意吧。谁知道呢。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献256条内容
已为社区贡献256条内容

所有评论(0)