YOLOv8提升小目标检测策略——专为微小目标检测设计的 IoU 替代方案NWD原理解析、YOLO代码集成与验证
所提出的 NWD 度量方法可轻松嵌入到任何基于锚点的检测器的分配、非极大值抑制和损失函数中,以替代常用的 IoU 度量。在用于微小目标检测的新数据集(AI-TOD)上的评估表明,采用 NWD 度量方法后,性能比标准微调基线高出 6.7 个 AP 点,比最先进的竞争对手高出 6.0 个 AP 点。
一、引言
小目标在驾驶辅助、大规模监控和海上救援等诸多现实世界应用中无处不在。尽管深度神经网络的发展使目标检测取得显著进展,但多数成果适用于正常大小目标。小目标(如AI-TOD数据集中小于特定像素的目标)外观信息极其有限,增加了识别特征的学习难度,导致检测失败案例频发。
小目标检测(TOD)的研究进展主要集中在改进特征识别方面:
- 对输入图像尺度进行归一化处理,以提高小目标及相应特征的分辨率;
- 提出生成对抗网络(GAN)直接生成小目标的超分辨表示;
- 设计特征金字塔网络(FPN)学习多尺度特征,实现尺度不变检测器。
然而,现有方法虽在一定程度上提升了TOD性能,但提高精度往往伴随额外计算成本。
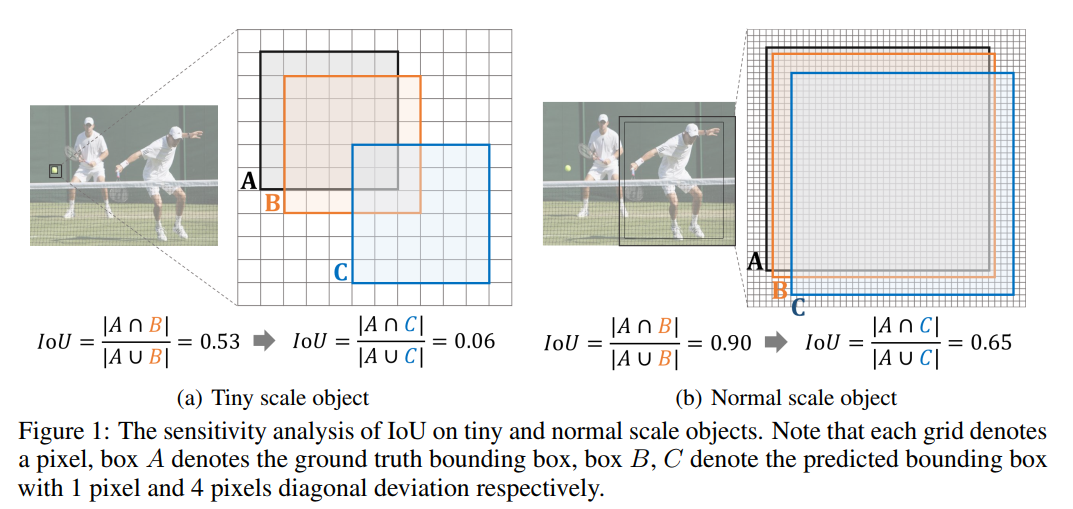
除特征学习外,训练样本选择质量对基于Anchor的小目标检测器至关重要,其中正/负标签分配是关键。但小目标的少量像素属性增加了训练样本选择难度,IoU对不同尺度物体的敏感性差异显著(如图1所示)。
具体而言,对于小目标,轻微位置偏差会导致IoU明显下降(如从0.53降至0.06),造成标签分配不准确;而对于正常目标,相同位置偏差下IoU变化较小(如从0.90降至0.65)。此外,图2中4条不同目标尺度的IoU-Deviation曲线显示,随着目标尺度减小,曲线下降速度更快,这源于BBox位置只能离散变化的特性。
这种现象导致标签分配存在以下缺陷(IoU阈值用于Anchor-Based检测器中Pos/Neg训练样本分配,RPN中常用(0.7,0.3)):
- 由于IoU对小目标的敏感性,微小位置偏差会翻转Anchor标记,导致Pos/Neg样本特征相似,网络收敛困难;
- 利用IoU度量发现,AI-TOD数据集中每个Ground-Truth(GT)分配到的平均正样本数小于1,因GT与任何Anchor的IoU低于最小正阈值,导致小目标检测的监督信息不足。
尽管ATSS等动态分配策略可根据物体统计特性自适应获取分配阈值,但IoU的敏感性使小目标检测难以找到合适阈值并获得高质量样本。
鉴于此,本文提出用Wasserstein距离度量BBox相似性以替代IoU,具体为:
- 将包围盒建模为二维高斯分布;
- 使用Normalized Wasserstein Distance(NWD)度量导出的高斯分布相似性。
Wasserstein distance的主要优点:
- 无论小目标是否重叠,均可度量分布相似性;
- 对不同尺度目标不敏感,更适合测量小目标间相似性。
NWD可应用于One-Stage和Multi-Stage Anchor-Based检测器,且能替代标签分配、非最大抑制(NMS)及回归损失函数中的IoU。在AI-TOD数据集上的实验表明,NWD可持续提升所有检测器的性能。
本文贡献:
- 分析IoU对小目标定位偏差的敏感性,提出NWD作为衡量两个BBox相似性的更优度量;
- 将NWD应用于Anchor-Based检测器的标签分配、NMS和损失函数,设计小目标检测器;
- NWD显著提升主流Anchor-Based检测器的TOD性能,在AI-TOD数据集上Faster R-CNN的性能从11.1%提升至17.6%。
二、相关研究
2.1 小目标检测
以往小目标检测方法大致分为三类:
(1)多尺度特征学习
- 简单经典方法:调整输入图像至不同尺度,训练适用于各尺度范围的检测器;
- 降低计算成本的改进:构建特征级金字塔,如SSD从不同分辨率特征图检测目标,FPN采用横向连接的自顶向下结构融合多尺度特征;
- 基于FPN的进一步优化:PANet、BiFPN、Recursive-FPN等;
- 其他结构:TridentNet构建具有不同感受野的并行多分支体系,生成特定比例特征图。
(2)更好的训练策略
- Singh等人提出SNIP和SNIPER,基于同时检测小目标和大目标的难度,在一定规模范围内选择性训练目标;
- Kim等人引入Scale-Aware网络(SAN),将不同空间提取的特征映射到尺度不变子空间,增强检测器对尺度变化的鲁棒性。
(3)基于GAN增强的检测
- Perceptual GAN:首个将GAN应用于小目标检测的算法,通过缩小小目标与大目标的表示差异改进检测;
- MT-GAN:Bai等人提出,训练图像级超分辨率模型以增强小ROI特征;
- 特征超分辨率方法:提高基于建议检测器的小目标检测性能。
2.2 目标检测中的评价指标
IoU是最广泛使用的边界框相似性度量,但仅适用于边界框有重叠的情况。为解决此问题,相关改进方法相继提出:
- Generalized IoU(GIoU):通过最小外接边界框相关惩罚项扩展,但当一个边界框包含另一个时,会降级为IoU;
- DIoU和CIoU:考虑重叠面积、中心点距离和纵横比三个几何特性,克服IoU和GIoU的局限性。
GIoU、CIoU和DIoU主要应用于NMS和损失函数以提升整体检测性能,在标签分配中的应用较少。Yang等人提出的Gaussian Wasserstein Distance(GWD)损失用于Oriented目标检测,解决边界不连续和square-like问题;而本文旨在减轻IoU对小目标位置偏差的敏感性,提出的方法可替代Anchor-Based目标检测中的IoU。
2.3 标签分配策略
将高质量Anchor分配到GT小目标Box极具挑战性:
- 简单方法:降低选择正样本时的IoU阈值,虽能增加小目标匹配的Anchor数量,但会降低训练样本整体质量;
- 自适应策略:ATSS通过一组Anchor的IoU统计值自动计算每个GT的Pos/Neg阈值;PAA假设Pos/Neg的联合损失分布服从高斯分布;OTA将标签分配视为全局最优运输问题。
但这些方法均利用IoU度量BBox相似性,聚焦标签分配中的阈值设置,不适合TOD。本文则专注于设计更优评价指标,替代小目标检测中的IoU。
三、本文方法
IoU是计算两个有限样本集相似度的Jaccard相似系数,受此启发,作者基于Wasserstein Distance设计更优的小目标度量方法,因其能一致反映分布间距离(即使无重叠),在测量小目标相似性方面性能更优。
3.1 为什么是Wasserstein Distance?
概率分布间的距离有多种描述方式,KL散度虽知名但并非严格意义上的距离(不满足对称性),且不关心几何性质。例如,两个微小平移的一维高斯分布,当平移量趋于0时,KL散度会急剧增大。
Wasserstein Distance则考虑分布的几何/度量性质,定义如下:对于定义在空间上的概率分布和,
W(p,q)=infγ∈Π(p,q)∫X×Xd(x,y)γ(dx,dy)W(p,q)=\inf_{\gamma \in \Pi(p,q)} \int_{\mathcal{X} \times \mathcal{X}} d(x,y) \gamma(dx,dy)W(p,q)=γ∈Π(p,q)inf∫X×Xd(x,y)γ(dx,dy)
其中γ\gammaγ是空间上的联合分布,其边缘分布分别为ppp和qqq,ddd可以是欧式距离、L1距离等。特例中,两个delta分布间的距离等于其中心间的距离。
Wasserstein distance可定义支持集不重合(甚至无交集)的分布间距离,而KL散度在此情况下不适用。
实际应用中,Wasserstein distance的计算多依赖离散化,对任意分布可用delta分布逼近,通过组合优化求解,如下代码示例:
def Wasserstein(mu, sigma, idx1, idx2):
p1 = torch.sum(torch.pow((mu[idx1] - mu[idx2]),2),1)
p2 = torch.sum(torch.pow(torch.pow(sigma[idx1],1/2) - torch.pow(sigma[idx2], 1/2),2) , 1)
return p1+p2
3.2 BBox的高斯分布建模
小目标BBox中,前景像素集中在中心,背景像素集中在边界。为更好描述BBox中不同像素的权重,将其建模为二维高斯分布(中心像素权重最高,从中心到边界重要性递减)。
对于水平边框(xc,ycx_c, y_cxc,yc为中心坐标,www和hhh为宽度和高度),其内接椭圆方程为:
(x−xc)2(w/2)2+(y−yc)2(h/2)2=1\frac{(x - x_c)^2}{(w/2)^2} + \frac{(y - y_c)^2}{(h/2)^2} = 1(w/2)2(x−xc)2+(h/2)2(y−yc)2=1
其中(xc,yc)(x_c, y_c)(xc,yc)为椭圆中心坐标,σx\sigma_xσx、σy\sigma_yσy为沿x、y轴的半轴长度,即σx=w/2\sigma_x = w/2σx=w/2,σy=h/2\sigma_y = h/2σy=h/2。
二维高斯分布的概率密度函数为:
N(x;μ,Σ)=12πdet(Σ)exp(−12(x−μ)TΣ−1(x−μ))N(x; \mu, \Sigma) = \frac{1}{2\pi \sqrt{\det(\Sigma)}} \exp\left(-\frac{1}{2}(x - \mu)^T \Sigma^{-1} (x - \mu)\right)N(x;μ,Σ)=2πdet(Σ)1exp(−21(x−μ)TΣ−1(x−μ))
其中xxx、μ\muμ、Σ\SigmaΣ分别为坐标、均值向量和协方差矩阵。当Σ=diag(σx2,σy2)\Sigma = \text{diag}(\sigma_x^2, \sigma_y^2)Σ=diag(σx2,σy2)时,上述椭圆为二维高斯分布的密度轮廓。因此,水平边界框可建模为二维高斯分布N(μ,Σ)\mathcal{N}(\mu, \Sigma)N(μ,Σ),其中:
μ=(xc,yc)T,Σ=((w/2)200(h/2)2)\mu = (x_c, y_c)^T, \quad \Sigma = \begin{pmatrix} (w/2)^2 & 0 \\ 0 & (h/2)^2 \end{pmatrix}μ=(xc,yc)T,Σ=((w/2)200(h/2)2)
边界框A和B之间的相似性可转化为两个高斯分布之间的分布距离。
3.3 Normalized Gaussian Wasserstein Distance
使用Optimal Transport理论中的Wasserstein distance计算分布距离。对于两个二维高斯分布N(μ1,Σ1)\mathcal{N}(\mu_1, \Sigma_1)N(μ1,Σ1)和N(μ2,Σ2)\mathcal{N}(\mu_2, \Sigma_2)N(μ2,Σ2),其Wasserstein distance为:
W(N1,N2)=∥μ1−μ2∥22+tr(Σ1+Σ2−2(Σ11/2Σ2Σ11/2)1/2)W(\mathcal{N}_1, \mathcal{N}_2) = \|\mu_1 - \mu_2\|_2^2 + \text{tr}(\Sigma_1 + \Sigma_2 - 2(\Sigma_1^{1/2} \Sigma_2 \Sigma_1^{1/2})^{1/2})W(N1,N2)=∥μ1−μ2∥22+tr(Σ1+Σ2−2(Σ11/2Σ2Σ11/2)1/2)
简化为:
W(N1,N2)=∥μ1−μ2∥22+∥Σ11/2−Σ21/2∥F2W(\mathcal{N}_1, \mathcal{N}_2) = \|\mu_1 - \mu_2\|_2^2 + \|\Sigma_1^{1/2} - \Sigma_2^{1/2}\|_F^2W(N1,N2)=∥μ1−μ2∥22+∥Σ11/2−Σ21/2∥F2
其中∥⋅∥F\|\cdot\|_F∥⋅∥F是Frobenius norm。
对于由BBox建模的高斯分布,上式可进一步简化。由于Wasserstein distance是距离度量,不能直接作为0-1之间的相似性度量(如IoU),故采用指数形式归一化,得到Normalized Wasserstein Distance(NWD):
NWD(A,B)=exp(−W(NA,NB)C)\text{NWD}(A,B) = \exp\left(-\frac{W(\mathcal{N}_A, \mathcal{N}_B)}{C}\right)NWD(A,B)=exp(−CW(NA,NB))
其中CCC是与数据集相关的常数,实验中设置为AI-TOD的平均绝对大小以达到最佳性能,且在一定范围内稳健。
与IoU相比,NWD在小目标检测中的优点:
- 尺度不敏感性;
- 位置偏差平滑性;
- 可测量非重叠或相互包容的边界盒之间的相似性。
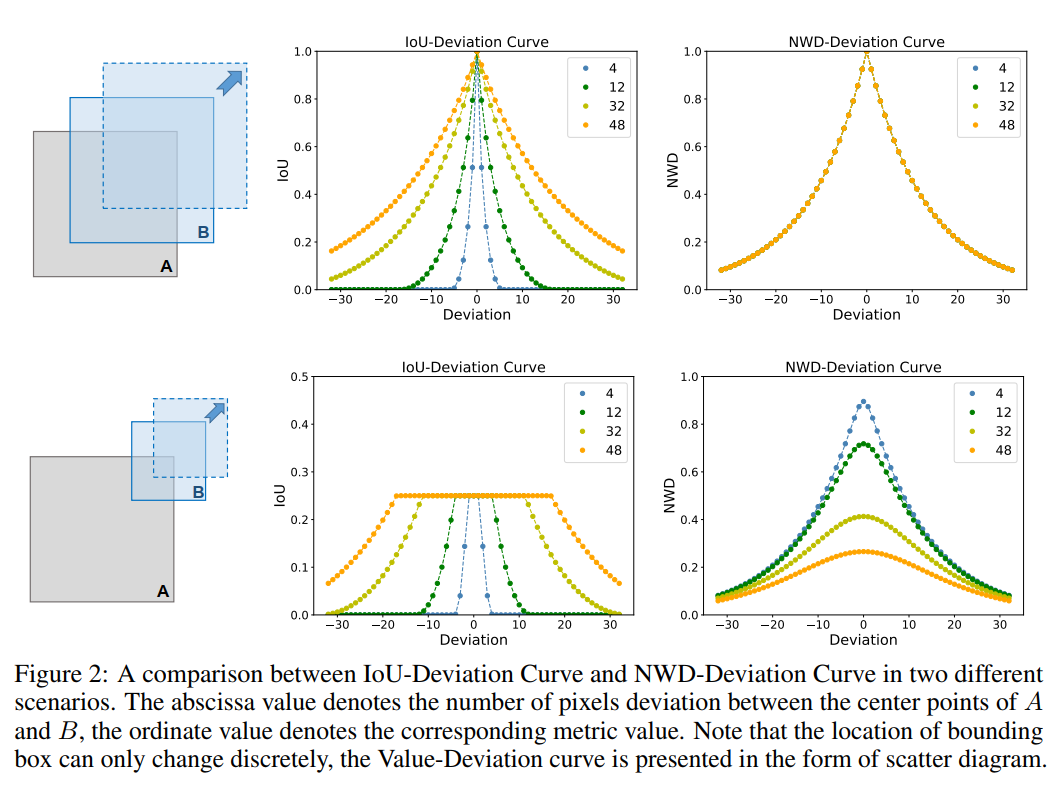
如图2所示,在两种情况下的度量值变化表明:
- 保持Box A和Box B尺度相同,Box B沿A对角线移动时,4条NWD曲线完全重合,说明NWD对Box尺度方差不敏感;NWD因位置偏差的变化更平滑,在相同阈值下Pos/Neg样本区分度可能优于IoU;
- Box B在边长一半位置沿对角线移动时,NWD曲线更平滑,能一致反映A与B之间的相似性。
3.4 NWD-based Detectors
NWD可轻松集成到任何Anchor-Based Detectors以取代IoU,本文以代表性的Faster R-CNN为例说明其用法,修改集中在IoU原使用的三个部分:pos/neg label assignment、NMS和Regression loss function。
(1)NWD-based Label Assignment
Faster R-CNN由生成区域建议的RPN和基于区域建议检测目标的R-CNN组成,两者均包含标签分配过程。
基于NWD的标签分配策略中,训练RPN时,正标签分配给两种Anchor:
- 与gt box的NWD值最高且大于阈值θp\theta_pθp的Anchor;
- 与任何gt的NWD值高于正阈值θp\theta_pθp的Anchor。
若Anchor的NWD值(相对于所有gt Box)低于负阈值θn\theta_nθn,则分配负标签;未被分配正负标签的Anchor不参与训练。实验中使用原始检测器的θp\theta_pθp和θn\theta_nθn。
(2)NWD-based NMS
NMS用于抑制冗余预测边界框,基于IoU度量时,对小目标的敏感性可能导致许多预测框IoU值低于阈值,产生假阳性预测。
NWD克服了尺度敏感性问题,是小目标检测中更好的NMS标准,且基于NWD的NMS可通过少量代码灵活集成到任何小目标检测器。
(3)NWD-based Regression Loss
IoU-Loss存在无法为以下两种情况提供梯度优化网络的问题:
- 预测框与GT框无重叠(即IoU=0);
- 预测框与GT框呈现包含关系(如IoU=1)。
这两种情况在小目标中极为普遍。CIoU和DIoU虽能处理这些情况,但因基于IoU,对小目标位置偏差仍很敏感。
为此,将NWD指标设计为损失函数:
LNWD=1−NWD(p,g)L_{\text{NWD}} = 1 - \text{NWD}(p, g)LNWD=1−NWD(p,g)
其中Np\mathcal{N}_pNp为预测框p的高斯分布模型,Ng\mathcal{N}_gNg为GT Box G的高斯分布模型。该损失在IoU=0的情况下仍可提供梯度。
四、实验
4.1 与IoU度量的对比
(1)标签分配对比
表1显示,与IoU指标相比,NWD的AP最高达16.1%,比DIoU高9.6%,表明基于NWD的标签分配可为小目标提供更高质量的训练样本。
统计实验表明,相同默认阈值下,IoU、GIoU、DIoU、CIoU和NWD每个gt box匹配的正Anchor平均数量分别为0.72、0.71、0.19、0.19和1.05,仅NWD能保证足够数量的正训练样本。
此外,降低基于IoU指标的阈值虽能提供更多正Anchor,但经阈值微调后的基于IoU的小目标检测器性能仍不及基于NWD的检测器,因NWD解决了IoU对小目标位置偏差的敏感性。
(2)NMS对比
仅修改RPN的NMS模块(因其直接影响检测器训练过程),结果显示NWD的最佳AP为11.9%,比IoU提高0.8%,表明检测小目标时,NWD是过滤多余边界框的更优度量。
(3)损失函数对比
修改RPN和R-CNN的损失函数(均影响检测器收敛性),基于NWD的loss function的AP最高为12.1%。
4.2 消融实验
(1)NWD应用于单个模块
表2结果显示,与基线方法相比,RPN和R-CNN中基于NWD的分配模块AP提升最高,分别为6.2%和3.2%,说明IoU导致的小目标训练标签分配问题最明显,基于NWD的分配策略显著提高了分配质量。
除R-CNN的NMS性能下降(可能因默认阈值非最优,需微调)外,本文方法在其余5个模块中均提升性能,验证了其有效性。
(2)NWD应用于多个模块
表3结果显示,训练12个Epoch时,在RPN、R-CNN或所有模块中使用NWD,检测性能均显著提升。将NWD应用于RPN的3个模块时,获得最佳17.8%的性能;而在所有6个模块中使用NWD时,AP比仅在RPN中使用下降2.6%。
增加训练至24个Epoch的实验显示,性能差距从2.6%减小到0.9%,表明在R-CNN中使用NWD时,网络收敛需要更多时间。因此,后续实验仅在RPN中使用NWD,以更少时间获得显著性能提升。
4.3 主要结果
(1)AI-TOD数据集
(结果如图表所示)
(2)Visdrone 数据集
(结果如图表所示)
4.4 可视化小目标检测结果
AI-TOD数据集上基于IoU的检测器(第1行)和基于NWD的检测器(第2行)的可视化结果显示,与IoU相比,NWD可显著降低假阴性(FN)。
4.5 与现有方法的比较
在AI-TOD和VisDrone数据集上,将基于NWD的Faster R-CNN与其他先进的小目标检测方法进行了比较。
在AI-TOD数据集上,如表4所示,基于NWD的Faster R-CNN在AP上达到17.6%,显著优于其他方法。例如,相比FPN,AP提升了6.5%;相比SNIPER,AP提升了4.2%。这表明NWD能够有效提升小目标检测性能。
在VisDrone数据集上,如表5所示,基于NWD的方法同样表现出色。与基线方法相比,AP提升明显,验证了NWD在不同小目标数据集上的通用性。
4.6 关于常数C的分析
常数C的设置对NWD的性能有一定影响。实验中测试了不同C值对检测结果的影响,发现当C在AI-TOD数据集的平均目标大小附近一定范围内变化时,NWD的性能保持稳定。这说明NWD对C的取值具有一定的鲁棒性,在实际应用中便于设置。
五、YOLOv8改进
5.1 下载YoloV8代码
直接下载
git clone https://github.com/ultralytics/ultralytics
安装环境
进入代码根目录并安装依赖。在最新版本中,官方已废弃requirements.txt文件,转而将所有必要代码和依赖整合进ultralytics包中。因此,用户只需安装该库:
pip install ultralytics
5.2 引入代码
将下面代码加入ultralytics/utils/loss.py文件:
def Wasserstein(box1, box2, xywh=True):
box2 = box2.T
if xywh:
b1_cx, b1_cy = (box1[0] + box1[2]) / 2, (box1[1] + box1[3]) / 2
b1_w, b1_h = box1[2] - box1[0], box1[3] - box1[1]
b2_cx, b2_cy = (box2[0] + box2[0]) / 2, (box2[1] + box2[3]) / 2
b1_w, b1_h = box2[2] - box2[0], box2[3] - box2[1]
else:
b1_cx, b1_cy, b1_w, b1_h = box1[0], box1[1], box1[2], box1[3]
b2_cx, b2_cy, b2_w, b2_h = box2[0], box2[1], box2[2], box2[3]
cx_L2Norm = torch.pow((b1_cx - b2_cx), 2)
cy_L2Norm = torch.pow((b1_cy - b2_cy), 2)
p1 = cx_L2Norm + cy_L2Norm
w_FroNorm = torch.pow((b1_w - b2_w)/2, 2)
h_FroNorm = torch.pow((b1_h - b2_h)/2, 2)
p2 = w_FroNorm + h_FroNorm
return p1 + p2
5.3 更换损失函数
修改ultralytics/utils/loss.py文件的class BboxLoss(nn.Module):函数:
步骤1:
将:
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
修改为:
# NWD - start
loss_iou = 0
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
nwd = torch.exp(
-torch.pow(Wasserstein(pred_bboxes[fg_mask].T, target_bboxes[fg_mask], xywh=False), 1 / 2) / 1.0)
loss_iou1 = ((1.0 - iou).mean()) * 0.5 + ((1.0 - nwd).mean()) * 0.5
loss_iou = loss_iou + loss_iou1
# NWD - end
5.4 验证
执行下面脚本,若代码可正常运行,则说明更换成功:
import os
from ultralytics import YOLO
# Define the configuration options directly
yaml = 'ultralytics/cfg/models/v8/yolov8n.yaml'
# Initialize the YOLO model with the specified YAML file
model = YOLO(yaml)
# Print model information
model.info()
if __name__ == "__main__":
# Train the model with the specified parameters
results = model.train(**{'cfg':'ultralytics/cfg/default.yaml'})
结论
本文针对小目标检测中IoU度量对位置偏差敏感、导致训练样本分配不合理等问题,提出了一种基于Normalized Wasserstein Distance(NWD)的新度量方法。
NWD通过将边界框建模为二维高斯分布,利用Wasserstein距离度量分布相似性,具有尺度不敏感性和对位置偏差的平滑性,能够更好地衡量小目标边界框之间的相似性。
将NWD应用于Anchor-Based检测器的标签分配、NMS和回归损失函数中,在AI-TOD和VisDrone等小目标数据集上的实验表明,该方法能显著提升检测性能,例如在AI-TOD数据集上,Faster R-CNN的AP从11.1%提升到17.6%。
未来工作可探索将NWD应用于Anchor-Free检测器,以及进一步优化NWD在不同场景下的适应性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)