Meta如何给RAG做Context Engineering,让模型上下文增加16倍
最近一段时间,Context Engineering(上下文工程)的热度已无需多言,而 Meta 超级智能实验室发布的首篇论文,便聚焦于该领域的核心议题——模型上下文智能压缩,展开了深度研究。相信在开发 RAG与 Agent时,上下文太长导致输出效果崩掉,几乎做AI 应用人的家常便饭。
最近一段时间,Context Engineering(上下文工程)的热度已无需多言,而 Meta 超级智能实验室发布的首篇论文,便聚焦于该领域的核心议题——模型上下文智能压缩,展开了深度研究。
相信在开发 RAG与 Agent时,上下文太长导致输出效果崩掉,几乎做AI 应用人的家常便饭。
其具体体现有二:
长上下文导致了更高内存成本,模型的首 token 生成时间(TTFT)会随之呈二次方增加。
冗余计算严重:RAG 与 Agent 的上下文一般是多个检索段落的组合,段落间的关联几乎为零。但大模型的注意力机制会对所有token 间的关联做计算,导致了大量冗余计算。
在此背景下,Meta团队提出了REFRAG 框架,在仅保留核心内容的原始token情况下,对RAG提供的低相关chunk内容做智能压缩,从而在不损失性能的前提下,实现 30.85 倍 TTFT 加速、将 LLMs 上下文处理长度扩展 16 倍。
经过实测,该方案在 RAG、多轮对话、智能体及 Web 级检索等 高吞吐量、低延迟场景中表现尤为突出 。
01
如何智能压缩上下文
以下是整个策略的核心流程图演示,整体可以分为三部分:
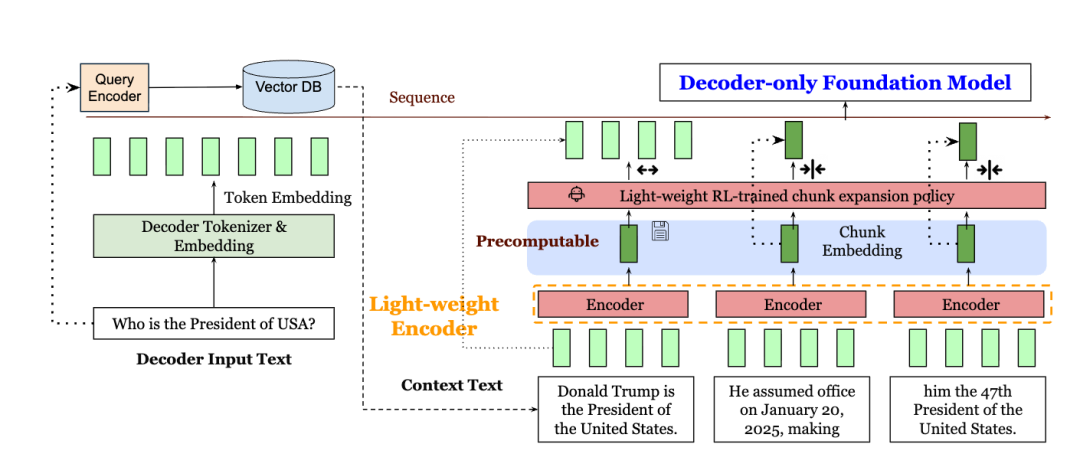
第一步:上下文分块与压缩
RAG 检索到的长文档,通常动辄几千上万 token,直接丢进 LLM 会让显存和计算成本爆炸。 REFRAG 的做法是:
- 先把文档切成固定大小的 块(chunk)。
- 每个块经过一个轻量级编码器(比如 RoBERTa)得到 块嵌入(chunk embedding)。
- 再用一个投影层,把这些嵌入映射到与解码器 token embedding 相同的维度。
这样做的好处是:LLM 不再处理每个原始 token,而是处理“压缩后的一整个块”。如果一个块里原来有 k 个 token,现在只用一个 embedding 来表示,那么输入长度就缩短了约 k倍,显著减少注意力计算量和显存占用。

第二步:选择性扩展与自回归保留
光压缩可能会丢失信息,尤其是对关键块(比如问题答案所在段落)。REFRAG 引入了一个 RL(强化学习)策略,用来动态决定:哪些块必须保留原始 token(不压缩),以保证信息完整。哪些块可以用压缩的embedding代替。
这样就能 兼顾准确性和效率。同时,因为 LLM 是自回归生成的(依赖前文 token),REFRAG 的方法保证了原始 token 仍能参与生成,不破坏上下文连续性。这对多轮对话等场景尤其重要。
第三步:高效推理与上下文扩展
REFRAG 还有两点优化:
- 复用检索阶段的块嵌入:RAG 在检索时已经算过一次 chunk embedding,推理时直接拿来用,省掉冗余计算。
- 注意力复杂度下降:普通注意力是和 token 数量成平方增长的。如果每个 chunk 代表一组 token,复杂度就变成和 chunk 数量平方关系,大幅降低。
整体结果来看,该方案在短上下文下,可以实现 k 倍的首 token 延迟(TTFT)加速;在长上下文下,加速比最高可达 k的平方 倍。同时,该方案还能把 LLM 的上下文长度扩展到 16 倍 以上。
02
关键技术细节
REFRAG 的方法体系围绕 “让编码器与解码器高效协同处理长上下文” 展开,核心流程分为三个阶段:
1.编码器 - 解码器对齐
持续预训练(CPT) 以 “下一段预测任务” 为核心:每个训练样本含 s 个前序 token 和 o 个后续 token(共 T 个),将前 s 个输入编码器,其输出用于辅助解码器预测后 o 个 token。
目标是让解码器基于压缩上下文(编码器输出)的生成结果,尽可能接近基于完整上下文的结果,为下游任务(如 RAG)奠定基础。
2.CPT 的关键训练方案(保障对齐效果)
(1)重建任务:先冻结解码器,仅训练编码器和投影层 —— 让编码器输入 s 个 token 后,能生成让解码器准确重建出这 s 个 token 的嵌入。目的是确保编码器压缩信息损失最小、投影层能将嵌入转换为解码器可理解的格式,同时迫使解码器依赖输入的上下文记忆(而非自身参数)。完成后解冻解码器,正式启动 CPT。
(2)课程学习:因直接训练难度大(块长度 k 增加会导致 token 组合呈指数级增长),采用 “从简到难” 的训练策略:先让模型用单个块嵌入重建 k 个 token,再逐步增加块数量和重建长度;训练数据也从以简单任务为主,逐渐过渡到以复杂任务为主,帮助模型循序渐进掌握能力。
3.性能增强:选择性压缩与下游适配
(1)选择性压缩:引入 RL 策略,以 “下一段预测困惑度” 为负奖励(困惑度越高说明块越重要),决定保留哪些上下文块的原始形式(不压缩),仅压缩次要块;同时微调编码器和解码器,使其适配 “压缩 + 未压缩” 混合输入,兼顾效率与性能。
(2)下游适配:完成 CPT 和选择性压缩优化后,通过有监督微调(SFT)让模型适配具体下游任务(如 RAG、多轮对话)。
03
关键效果与核心场景解读
Meta 团队在 Slimpajama(书籍、arXiv 领域)、PG19、Proof-Pile 等主流数据集,以及 RAG、多轮对话、长文档摘要等任务中对 REFRAG 进行了全面验证,其优势主要体现在效率提升、上下文扩展、场景适配三个维度。
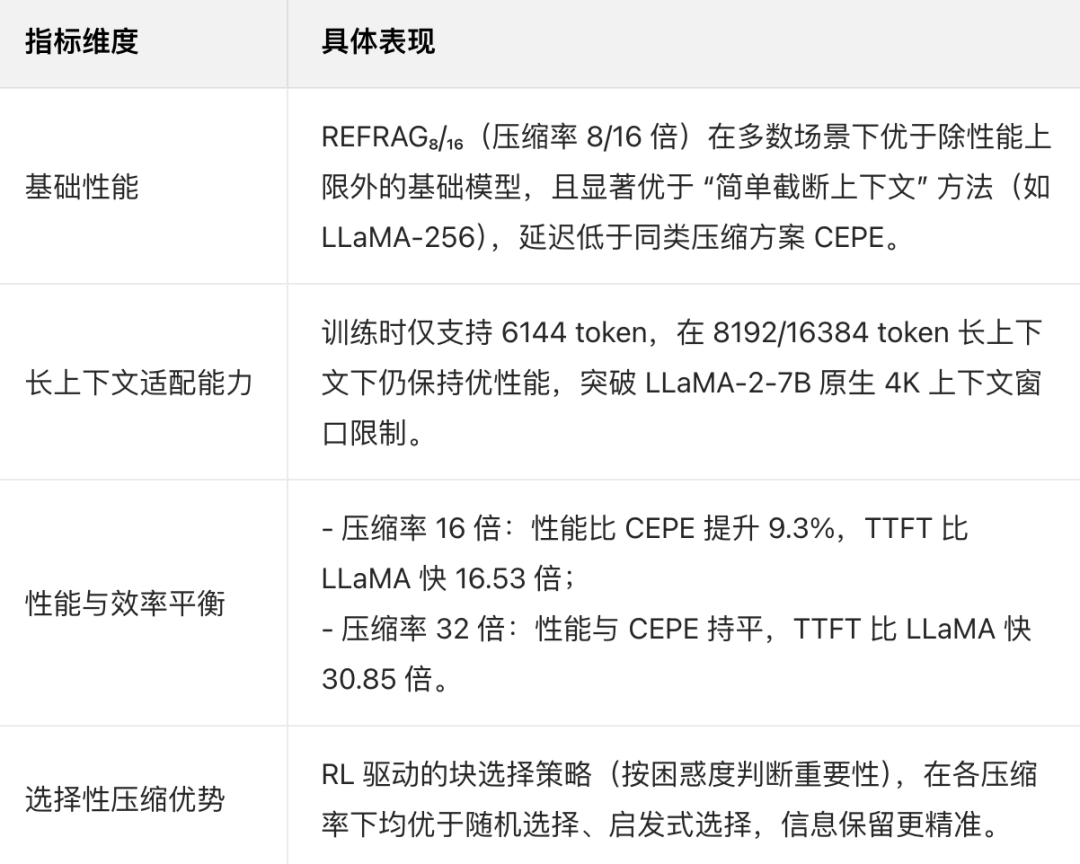
基于以上能力, REFRAG 的核心落地场景主要有三:
(1)增强版 RAG:支持 Web 级高效检索
在 Web 级搜索等需处理大量检索结果的场景中,REFRAG 可 “以更低延迟纳入更多有效信息”:
延迟持平情况下:REFRAG 可处理 8 个检索段落(LLaMA 仅能处理 1 个),在 MMLU、BoolQ 等知识密集型任务中精度提升 1.5% 以上。
多段落处理场景中:处理 10 个检索段落时,TTFT 加速 5.26 倍,且在弱检索器(模拟真实场景中检索误差)下优势更明显。
(2)多轮对话:突破上下文窗口限制
传统 LLaMA 因 4K 上下文窗口限制,多轮对话中需截断历史信息,导致回答连贯性下降;REFRAG 无需扩展位置编码,通过压缩机制实现长对话记忆:
在 TopiOCQA、ORConvQA 等知识密集型多轮对话数据集上,面对 10 个检索段落 + 6 轮对话的长上下文,性能全面优于 LLaMA 微调模型,其中 ORConvQA 任务精度提升超 30%。
(3)长文档摘要:提升科学性文献处理能力
在 arXiv、PubMed 等长 scientific 文献摘要任务中,REFRAG 可通过高压缩率纳入全文档信息,生成摘要的完整性与准确性更优:
相同延迟下(解码器生成 token 数量一致),Rouge-1 指标较 LLaMA 提升 15%-20%,尤其在医学、物理等需精准提炼核心结论的领域表现突出。
尾声
模型上下文长度管理,只是Context Engineering 的议题之一,未来围绕提示工程、动态上下文生成、多模态上下文整合等重点话题,我们还将为大家带来更多更专业的解读。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)