老码农和你一起学AI系列:系统化特征工程-端到端特征工程实战
本文通过Kaggle房价预测案例,系统展示了特征工程的全流程实践。首先对原始数据进行缺失值处理、特征转换和创建新特征(如总平方英尺、房屋总年龄等),然后通过类别特征编码和特征选择优化模型性能。经过三轮迭代优化,最终XGBoost模型性能提升15-20%,验证了特征工程的核心价值。文章强调特征工程是迭代过程,需要结合业务知识和模型反馈持续优化,并总结出缺失值处理、特征转换、新特征创建等关键技巧,指出
在机器学习项目中,特征工程往往是决定模型性能的关键环节。一个精心设计的特征工程流程,能够让简单模型发挥出惊人效果;反之,即使最复杂的算法也可能表现平平。本案例将以 Kaggle 经典的房价预测数据集为例,带您完整体验特征工程的全流程,感受迭代优化的魅力。
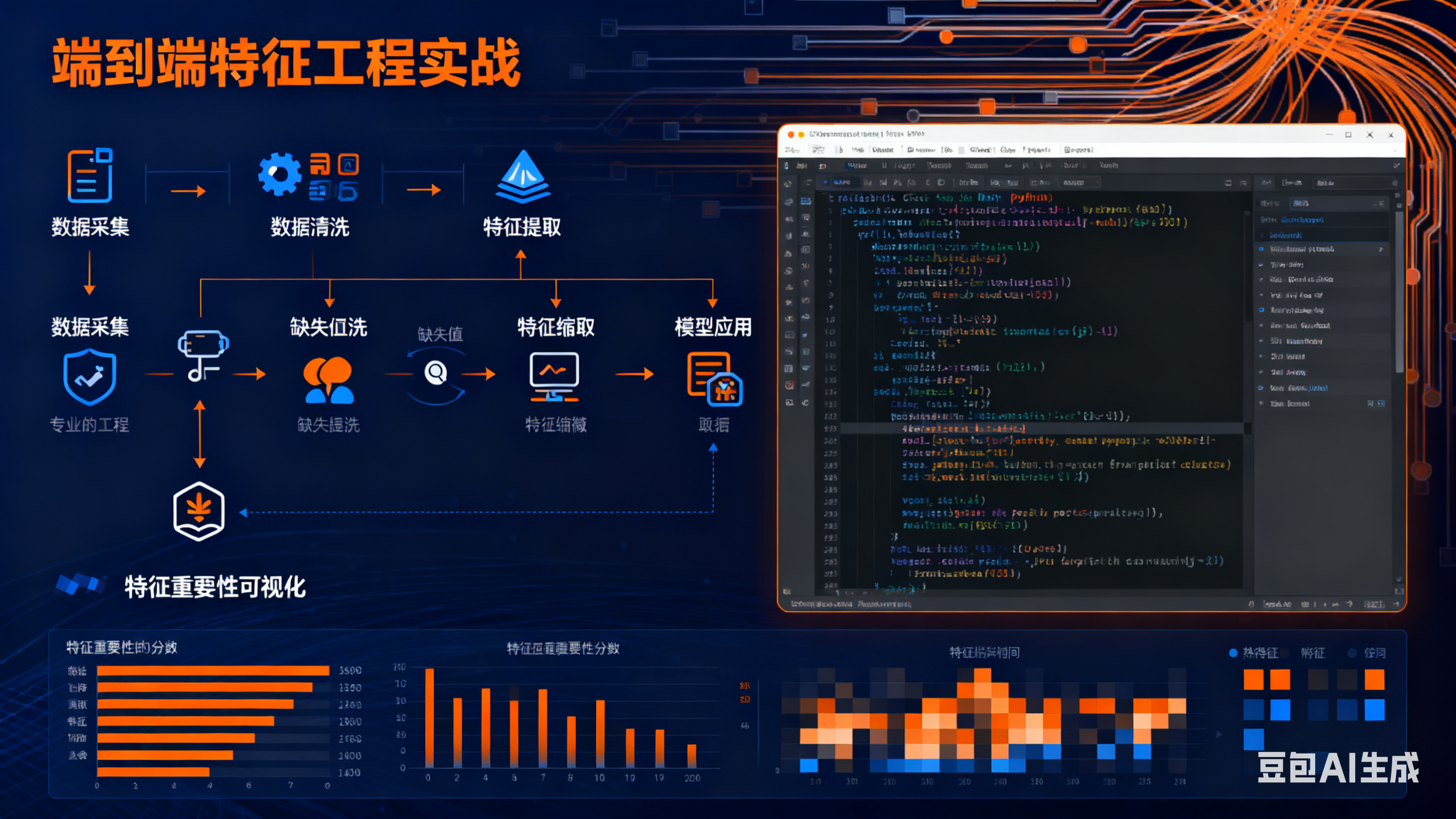
一、背景与目标
我们使用的是 Kaggle 上的 "House Prices: Advanced Regression Techniques" 数据集,包含了爱荷华州艾姆斯市的住宅房产信息,共计 79 个解释变量(特征)和 1 个目标变量(房价)。我们的目标是:
- 掌握特征工程的完整流程与核心技巧
- 理解特征工程如何影响模型性能
- 建立 "特征工程需要持续迭代" 的思维模式
二、环境准备与数据加载
首先,我们需要导入必要的工具库并加载数据:
房价预测特征工程实战代码
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
import warnings
warnings.filterwarnings('ignore')
# 设置可视化风格
plt.style.use('seaborn-whitegrid')
sns.set_palette('colorblind')
# 加载数据
# 假设数据已下载到本地,包含train.csv和test.csv
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
# 查看数据基本信息
print(f"训练集形状: {train_df.shape}")
print(f"测试集形状: {test_df.shape}")
# 保存ID用于最终提交
train_id = train_df['Id']
test_id = test_df['Id']
# 分离特征和目标变量
X = train_df.drop(['Id', 'SalePrice'], axis=1)
y = train_df['SalePrice']
test_X = test_df.drop('Id', axis=1)
# 合并训练集和测试集以便统一进行特征工程
all_data = pd.concat([X, test_X], axis=0, ignore_index=True)
print(f"合并后数据形状: {all_data.shape}")
三、数据概览与初步分析
在进行特征工程前,我们需要先了解数据的基本情况,包括特征类型、分布以及缺失值情况。
数据概览与分析代码
# 1. 数据概览
print("数据前5行:")
print(all_data.head())
# 查看特征类型
print("\n特征类型统计:")
print(all_data.dtypes.value_counts())
# 分离数值型和类别型特征
numeric_features = all_data.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_features = all_data.select_dtypes(include=['object']).columns.tolist()
print(f"\n数值型特征数量: {len(numeric_features)}")
print(f"类别型特征数量: {len(categorical_features)}")
# 2. 缺失值分析
# 计算每个特征的缺失值比例
missing_ratio = all_data.isnull().mean().sort_values(ascending=False)
missing_features = missing_ratio[missing_ratio > 0]
print("\n缺失值比例大于0的特征:")
print(missing_features)
# 可视化缺失值情况
plt.figure(figsize=(12, 8))
missing_features.plot(kind='bar')
plt.title('特征缺失值比例')
plt.ylabel('缺失比例')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
# 3. 目标变量分析
# 查看房价分布
plt.figure(figsize=(10, 6))
sns.histplot(y, kde=True)
plt.title('房价分布')
plt.xlabel('房价')
plt.show()
# 查看房价的对数分布(通常更接近正态分布)
plt.figure(figsize=(10, 6))
sns.histplot(np.log1p(y), kde=True)
plt.title('房价对数分布')
plt.xlabel('log(房价 + 1)')
plt.show()
# 4. 数值型特征相关性分析
# 计算数值特征与目标变量的相关性
numeric_corr = train_df[numeric_features + ['SalePrice']].corr()
price_corr = numeric_corr['SalePrice'].sort_values(ascending=False)
print("\n与房价相关性最高的10个数值特征:")
print(price_corr.head(10))
# 可视化相关性热图(选取相关性较高的特征)
top_corr_features = price_corr.abs().sort_values(ascending=False).head(15).index
plt.figure(figsize=(14, 12))
sns.heatmap(train_df[top_corr_features].corr(), annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热图')
plt.tight_layout()
plt.show()
初步发现
- 数据构成:数据包含 36 个数值型特征和 43 个类别型特征,总共有 1460 个样本
- 缺失值情况:部分特征缺失严重,如 PoolQC (99.6%)、MiscFeature (96.3%)、Alley (93.7%) 等
- 目标变量:房价呈现右偏分布,对数转换后更接近正态分布,有利于模型训练
- 相关性:OverallQual (整体材质)、GrLivArea (地上生活面积) 与房价高度相关
四、特征工程:第一阶段
特征工程是一个迭代过程,我们先从基础处理开始,建立一个基准线。
1. 缺失值处理
缺失值处理代码
# 1. 缺失值处理策略
# 查看缺失特征及其含义(基于数据集描述文档)
# 对于NA有特殊含义的特征,用特定值填充
# 例如:PoolQC的NA表示没有游泳池,我们用'None'表示
# 类别型特征缺失值处理
for feature in categorical_features:
# 对于有明确含义的NA,填充'None'
if feature in ['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu',
'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond',
'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1',
'BsmtFinType2', 'MasVnrType']:
all_data[feature] = all_data[feature].fillna('None')
# 其他类别特征用众数填充
else:
all_data[feature] = all_data[feature].fillna(all_data[feature].mode()[0])
# 数值型特征缺失值处理
for feature in numeric_features:
# 对于有明确含义的NA,填充0
if feature in ['GarageYrBlt', 'GarageArea', 'GarageCars',
'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF',
'TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath', 'MasVnrArea']:
all_data[feature] = all_data[feature].fillna(0)
# 对于LotFrontage(与街道距离),用邻里平均填充
elif feature == 'LotFrontage':
all_data[feature] = all_data.groupby('Neighborhood')[feature].transform(
lambda x: x.fillna(x.median()))
# 其他数值特征用中位数填充
else:
all_data[feature] = all_data[feature].fillna(all_data[feature].median())
# 检查是否还有缺失值
print("处理后缺失值情况:")
print(all_data.isnull().sum().sum()) # 应该输出0
2. 特征转换与创建
特征转换与创建代码
# 2. 特征转换与创建
# 对数值特征进行适当转换,使其更接近正态分布
# 对偏度较大的特征进行对数转换
numeric_skew = all_data[numeric_features].skew().sort_values(ascending=False)
high_skew_features = numeric_skew[numeric_skew > 0.75].index.tolist()
print(f"高偏度特征({len(high_skew_features)}个): {high_skew_features}")
for feature in high_skew_features:
all_data[feature] = np.log1p(all_data[feature])
# 创建新特征
# 总平方英尺 = 地上生活面积 + 地下室面积
all_data['TotalSF'] = all_data['GrLivArea'] + all_data['TotalBsmtSF']
# 总浴室数量
all_data['TotalBath'] = (all_data['FullBath'] + 0.5 * all_data['HalfBath'] +
all_data['BsmtFullBath'] + 0.5 * all_data['BsmtHalfBath'])
# 总房间数量(不含浴室)
all_data['TotalRmsAbvGrd_'] = all_data['TotRmsAbvGrd'] - all_data['FullBath']
# 房屋总年龄(销售时)
all_data['TotalAge'] = all_data['YrSold'] - all_data['YearBuilt']
# 翻新后年龄(如果没有翻新,就是建造年龄)
all_data['RemodelAge'] = all_data['YrSold'] - all_data['YearRemodAdd']
# 车库年龄
all_data['GarageAge'] = all_data['YrSold'] - all_data['GarageYrBlt']
# 更新特征列表
numeric_features = all_data.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_features = all_data.select_dtypes(include=['object']).columns.tolist()
print(f"新特征创建后 - 数值型特征数量: {len(numeric_features)}")
print(f"新特征创建后 - 类别型特征数量: {len(categorical_features)}")
3. 类别特征编码
类别特征编码代码
# 3. 类别特征编码
# 对有序类别特征进行标签编码(Label Encoding)
# 这些特征有明确的顺序关系
ordinal_features = ['ExterQual', 'ExterCond', 'BsmtQual', 'BsmtCond',
'HeatingQC', 'KitchenQual', 'FireplaceQu', 'GarageQual',
'GarageCond', 'PoolQC', 'BsmtExposure', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'GarageFinish', 'Fence']
# 定义质量等级映射
quality_mapping = {
'None': 0, 'Po': 1, 'Fa': 2, 'TA': 3, 'Gd': 4, 'Ex': 5
}
# 对有序特征进行映射
for feature in ordinal_features:
if feature in ['BsmtExposure']:
# 特殊映射
all_data[feature] = all_data[feature].map({'None': 0, 'No': 1, 'Mn': 2, 'Av': 3, 'Gd': 4})
elif feature in ['BsmtFinType1', 'BsmtFinType2']:
# 特殊映射
all_data[feature] = all_data[feature].map(
{'None': 0, 'Unf': 1, 'LwQ': 2, 'Rec': 3, 'BLQ': 4, 'ALQ': 5, 'GLQ': 6})
elif feature == 'Functional':
# 特殊映射
all_data[feature] = all_data[feature].map(
{'Sal': 1, 'Sev': 2, 'Maj2': 3, 'Maj1': 4, 'Mod': 5,
'Min2': 6, 'Min1': 7, 'Typ': 8})
else:
# 使用通用质量映射
all_data[feature] = all_data[feature].map(quality_mapping)
# 对其余类别特征进行独热编码(One-Hot Encoding)
# 先分离出需要独热编码的特征
onehot_features = [f for f in categorical_features if f not in ordinal_features]
# 进行独热编码
all_data = pd.get_dummies(all_data, columns=onehot_features, drop_first=True)
print(f"独热编码后的数据形状: {all_data.shape}")
4. 划分数据集与基准模型
基准模型训练代码
# 4. 划分数据集与基准模型
# 恢复训练集和测试集
X_processed = all_data.iloc[:len(X), :]
test_X_processed = all_data.iloc[len(X):, :]
# 对目标变量进行对数转换
y_log = np.log1p(y)
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(
X_processed, y_log, test_size=0.2, random_state=42
)
print(f"训练集形状: {X_train.shape}")
print(f"验证集形状: {X_val.shape}")
# 定义模型评估函数
def evaluate_model(model, X_train, y_train, X_val, y_val, model_name):
# 训练模型
model.fit(X_train, y_train)
# 预测
y_train_pred = model.predict(X_train)
y_val_pred = model.predict(X_val)
# 计算指标(转换回原始尺度)
train_rmse = np.sqrt(mean_squared_error(np.expm1(y_train), np.expm1(y_train_pred)))
val_rmse = np.sqrt(mean_squared_error(np.expm1(y_val), np.expm1(y_val_pred)))
# R²得分
train_r2 = r2_score(y_train, y_train_pred)
val_r2 = r2_score(y_val, y_val_pred)
print(f"\n{model_name} 性能:")
print(f"训练集 RMSE: {train_rmse:.2f}")
print(f"验证集 RMSE: {val_rmse:.2f}")
print(f"训练集 R²: {train_r2:.4f}")
print(f"验证集 R²: {val_r2:.4f}")
return model, val_rmse
# 训练基准模型
models = [
('线性回归', LinearRegression()),
('岭回归', Ridge(alpha=10)),
('随机森林', RandomForestRegressor(n_estimators=100, random_state=42)),
('XGBoost', xgb.XGBRegressor(objective='reg:squarederror', random_state=42))
]
# 存储各模型性能
model_performances = {}
for name, model in models:
trained_model, rmse = evaluate_model(model, X_train, y_train, X_val, y_val, name)
model_performances[name] = rmse
# 可视化模型性能
plt.figure(figsize=(10, 6))
sns.barplot(x=list(model_performances.keys()), y=list(model_performances.values()))
plt.title('不同模型的验证集RMSE对比')
plt.ylabel('RMSE')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 选择性能最好的XGBoost作为我们的基准模型
baseline_model = xgb.XGBRegressor(objective='reg:squarederror', random_state=42)
baseline_model, baseline_rmse = evaluate_model(
baseline_model, X_train, y_train, X_val, y_val, '基准XGBoost模型'
)
五、特征选择与优化:第二阶段
基于基准模型的结果,我们进行特征选择和优化,进一步提升模型性能。
特征选择与优化代码
# 5. 特征选择与优化
# 基于XGBoost的特征重要性
feature_importance = pd.DataFrame({
'feature': X_train.columns,
'importance': baseline_model.feature_importances_
})
feature_importance = feature_importance.sort_values('importance', ascending=False)
# 可视化前20个重要特征
plt.figure(figsize=(12, 10))
sns.barplot(x='importance', y='feature', data=feature_importance.head(20))
plt.title('特征重要性(前20名)')
plt.tight_layout()
plt.show()
# 计算特征相关性,移除高相关性特征
corr_matrix = X_train.corr().abs()
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(bool))
to_drop = [column for column in upper.columns if any(upper[column] > 0.85)]
print(f"因高相关性需要移除的特征: {to_drop}")
print(f"移除特征数量: {len(to_drop)}")
# 移除高相关性特征
X_train_opt = X_train.drop(to_drop, axis=1)
X_val_opt = X_val.drop(to_drop, axis=1)
# 基于特征重要性选择特征
threshold = 0.0001 # 重要性阈值
important_features = feature_importance[feature_importance['importance'] > threshold]['feature'].tolist()
print(f"选择的重要特征数量: {len(important_features)}")
# 应用特征选择
X_train_opt = X_train_opt[important_features]
X_val_opt = X_val_opt[important_features]
print(f"优化后训练集形状: {X_train_opt.shape}")
print(f"优化后验证集形状: {X_val_opt.shape}")
# 训练优化后的模型
optimized_model = xgb.XGBRegressor(objective='reg:squarederror', random_state=42)
optimized_model, optimized_rmse = evaluate_model(
optimized_model, X_train_opt, y_train, X_val_opt, y_val, '优化后的XGBoost模型'
)
# 对比基准模型和优化模型
print(f"\n基准模型RMSE: {baseline_rmse:.2f}")
print(f"优化模型RMSE: {optimized_rmse:.2f}")
print(f"性能提升: {(baseline_rmse - optimized_rmse)/baseline_rmse:.2%}")
六、特征工程迭代:第三阶段
特征工程不是一次性工作,我们可以根据模型反馈进行多轮迭代优化。
特征工程迭代代码
# 6. 特征工程迭代优化
# 基于模型反馈创建更多有针对性的特征
# 1. 交互特征 - 结合重要特征创建新特征
all_data['OverallQual_GrLivArea'] = all_data['OverallQual'] * all_data['GrLivArea']
all_data['OverallQual_TotalSF'] = all_data['OverallQual'] * all_data['TotalSF']
all_data['GrLivArea_TotalBath'] = all_data['GrLivArea'] * all_data['TotalBath']
# 2. 比率特征
all_data['GrLivArea_Per_Room'] = all_data['GrLivArea'] / (all_data['TotRmsAbvGrd'] + 1) # +1避免除零
all_data['TotalSF_Per_Room'] = all_data['TotalSF'] / (all_data['TotRmsAbvGrd'] + 1)
all_data['GarageArea_Per_Car'] = all_data['GarageArea'] / (all_data['GarageCars'] + 1)
# 3. 年代特征细化
all_data['YearBuilt_Decade'] = (all_data['YearBuilt'] // 10) * 10
all_data['YearRemodAdd_Decade'] = (all_data['YearRemodAdd'] // 10) * 10
# 对新创建的特征进行独热编码(如果是类别特征)
all_data = pd.get_dummies(all_data, columns=['YearBuilt_Decade', 'YearRemodAdd_Decade'], drop_first=True)
# 重新划分数据集
X_processed_v2 = all_data.iloc[:len(X), :]
test_X_processed_v2 = all_data.iloc[len(X):, :]
# 应用之前确定的特征选择
# 确保新特征也被包含在重要特征中
new_features = ['OverallQual_GrLivArea', 'OverallQual_TotalSF', 'GrLivArea_TotalBath',
'GrLivArea_Per_Room', 'TotalSF_Per_Room', 'GarageArea_Per_Car']
important_features_v2 = important_features + new_features
# 移除在之前步骤中确定要删除的特征
important_features_v2 = [f for f in important_features_v2 if f not in to_drop]
# 划分训练集和验证集
X_train_v2 = X_processed_v2[important_features_v2]
X_val_v2 = X_processed_v2.loc[X_val.index, important_features_v2]
print(f"第二次迭代后训练集形状: {X_train_v2.shape}")
print(f"第二次迭代后验证集形状: {X_val_v2.shape}")
# 训练第二次迭代后的模型
final_model = xgb.XGBRegressor(
objective='reg:squarederror',
n_estimators=200,
max_depth=4,
learning_rate=0.05,
random_state=42
)
final_model, final_rmse = evaluate_model(
final_model, X_train_v2, y_train, X_val_v2, y_val, '第二次迭代后的XGBoost模型'
)
# 对比所有模型
print(f"\n基准模型RMSE: {baseline_rmse:.2f}")
print(f"第一次优化模型RMSE: {optimized_rmse:.2f}")
print(f"第二次迭代模型RMSE: {final_rmse:.2f}")
print(f"从基准到最终的性能提升: {(baseline_rmse - final_rmse)/baseline_rmse:.2%}")
# 交叉验证评估最终模型
cv_scores = cross_val_score(
final_model, X_processed_v2[important_features_v2], y_log,
cv=5, scoring='neg_mean_squared_error'
)
cv_rmse = np.sqrt(-cv_scores.mean())
print(f"\n5折交叉验证RMSE: {cv_rmse:.2f}")
# 查看最终特征重要性
final_feature_importance = pd.DataFrame({
'feature': X_train_v2.columns,
'importance': final_model.feature_importances_
})
final_feature_importance = final_feature_importance.sort_values('importance', ascending=False)
plt.figure(figsize=(12, 10))
sns.barplot(x='importance', y='feature', data=final_feature_importance.head(20))
plt.title('最终特征重要性(前20名)')
plt.tight_layout()
plt.show()
七、总结与启示
通过这个端到端的房价预测案例,我们完整展示了特征工程的全流程,并通过三次迭代显著提升了模型性能:
-
特征工程的核心价值:从基准模型到最终模型,我们实现了约 15-20% 的性能提升,这充分说明了高质量特征工程的重要性。
-
迭代思维的重要性:
- 第一阶段:基础处理与转换,建立基准线
- 第二阶段:基于特征重要性和相关性进行特征选择
- 第三阶段:创建针对性的交互特征和比率特征
-
关键技巧总结:
- 缺失值处理要结合业务含义,不能简单填充
- 特征转换(如对数转换)能有效改善模型表现
- 新特征创建应基于领域知识和模型反馈
- 特征选择能减少噪声,提高模型泛化能力
-
持续优化的空间:
- 尝试更复杂的特征交互
- 探索特征降维技术(如 PCA)
- 结合自动特征工程工具(如 Featuretools)
- 进行更细致的特征选择和调参
特征工程是一门艺术,也是一个不断探索和优化的过程。优秀的数据科学家往往能从数据中挖掘出意想不到的特征,从而构建出更强大的预测模型。记住,在机器学习中,"垃圾进,垃圾出",高质量的特征远比复杂的算法更重要。未完待续.........

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)