ReAct:赋予大模型“思考”与“行动”的协同之力,告别一本正经的胡说八道
摘要:ReAct模式通过将推理(Reasoning)与行动(Acting)相结合,有效提升了大型语言模型(LLM)的可靠性和准确性。与单纯推理的CoT方法相比,ReAct通过外部交互获取实时信息,显著减少了"事实幻觉"问题;而与纯行动方法相比,其推理能力在复杂任务中表现更优。实验显示,在HotpotQA和Fever任务上,ReAct与CoT的组合策略取得了最佳效果,分别通过&q
参考文献:《ReAct: Synergizing Reasoning and Acting in Language Models》
引言:当LLM学会“谋定而后动”
近年来,大型语言模型(LLM)以其惊人的语言能力席卷了整个科技界。然而,当我们惊叹于其对答如流的背后,一个棘手的问题也逐渐浮出水面——事实幻觉(Fact Hallucination)。模型可能会“一本正经地胡说八道”,编造出看似合理却完全错误的信息。
为了解决这个问题,研究者们提出了“思维链”(Chain-of-Thought, CoT)技术,通过引导模型模拟人类的思考过程,一步步推导出答案,从而提高推理的准确性。但这依然不够,CoT本质上是一个封闭的“思想者”,它在自己的知识库里打转,无法与外部世界交互来验证事实、获取新知。
这引出了一个核心问题:我们能否让模型既会“思考”,又会“行动”?能否让它像一个真正的专家那样,在遇到知识盲区时,会主动去查阅资料,然后基于新的信息来调整思路,最终给出可靠的答案?
答案是肯定的。今天,我们将深入探讨一种开创性的模式——ReAct(Reasoning + Acting),它通过将“推理”和“行动”这两种能力无缝结合,为我们揭示了构建更强大、更可靠的AI智能体的未来方向。
什么是ReAct?思考与行动的动态循环
ReAct模式的核心思想非常直观:它引导LLM以一种交错的方式,生成推理轨迹(Reasoning Traces)和任务特定动作(Actions)。
这两者相互协同,形成了一个强大的动态循环:
- 推理(谋定而后动):推理轨迹帮助模型梳理逻辑、制定行动计划、跟踪任务进度,甚至在遇到意外时调整策略。
- 行动(行以思):动作使得模型能够与外部环境(如维基百科、搜索引擎API等)进行交互,从而获取额外信息,并将这些一手资料整合到后续的推理中。
简单来说,CoT像一个闭门造车的思想家,而ReAct则像一个边思考边动手做实验的科学家。它不仅能规划“我要做什么”,还能执行“我做了”,并根据“我看到了什么”来调整下一步的“我应该怎么想”。
对照实验:推理与行动,谁更重要?
为了验证ReAct的真正实力,研究者们设计了一场精彩的“对照实验”,在两个经典的知识密集型任务上,对比了多种提示方法的效果。
- HotpotQA:一个“多跳问答”任务,需要模型结合多个信息源才能回答问题,考验的是复杂推理能力。
- Fever:一个“事实核查”任务,需要模型判断一个陈述的真伪,考验的是事实准确性。
下面是各路选手的表现:
| Prompt Method | HotpotQA (EM) | Fever (Acc) | 核心思想 |
|---|---|---|---|
| Standard (仅提问) | 28.7 | 57.1 | 基准线,直接回答 |
| CoT (仅思考) | 29.4 | 56.3 | 纯内部推理,易产生幻觉 |
| CoT-SC (多路径思考) | 33.4 | 60.4 | 内部推理的鲁棒增强版 |
| Act (仅行动) | 25.7 | 58.9 | 纯外部交互,缺乏规划 |
| ReAct (思考+行动) | 27.4 | 60.9 | 推理与行动结合 |
| CoT-SC → ReAct | 34.2 | 64.6 | 内部思考碰壁后,求助外部行动 |
| ReAct → CoT-SC | 35.1 | 62.0 | 外部行动受阻后,求助内部思考 |
| Supervised SoTA | 67.5 | 89.5 | 传统监督学习的最佳模型 |
从数据中我们可以清晰地看到几个关键结论:
- 纯思考(CoT)与纯行动(Act)各有缺陷:CoT在事实核查(Fever)上表现不佳,因为它无法验证事实,容易产生幻 giác。而Act在复杂推理(HotpotQA)上表现最差,说明没有“思考”指导的“行动”是盲目的,容易在复杂任务中迷失方向。
- ReAct在事实核查中表现出色:通过与外部环境交互,ReAct有效克服了CoT的幻觉问题,在Fever任务上取得了独立方法中的最高分。
- 组合策略效果最佳:
ReAct → CoT-SC和CoT-SC → ReAct这两种“混合双打”策略,在两个任务上分别取得了冠军。这有力地证明了,让模型根据任务情况,智能地在“内部思考”和“外部行动”之间切换,是通往更高性能的钥匙。
深入剖析:ReAct与CoT的成败归因
为了更深层次地理解两者的差异,研究者们对它们在HotpotQA任务中的成功与失败案例进行了归因分析。
| 模式 | 类别 | ReAct | CoT | 解读 |
|---|---|---|---|---|
| 成功 (Success) | 真阳性 (推理事实全对) | 94% | 86% | ReAct的成功更“脚踏实地”,有事实依据。 |
| 假阳性 (碰巧答对) | 6% | 14% | CoT有更多“蒙对”的情况,过程可能包含幻觉。 | |
| 失败 (Failure) | 推理错误 (陷入循环等) | 47% | 16% | ReAct的主要弱点:思考-行动的结构可能限制推理灵活性。 |
| 搜索结果错误 | 23% | 0% | ReAct特有问题,依赖外部工具的质量。 | |
| 幻觉 (编造事实) | 0% | 56% | CoT的致命弱点:超过一半的失败源于此。 | |
| 标签歧义 | 29% | 28% | 普遍存在的小问题,影响不大。 |
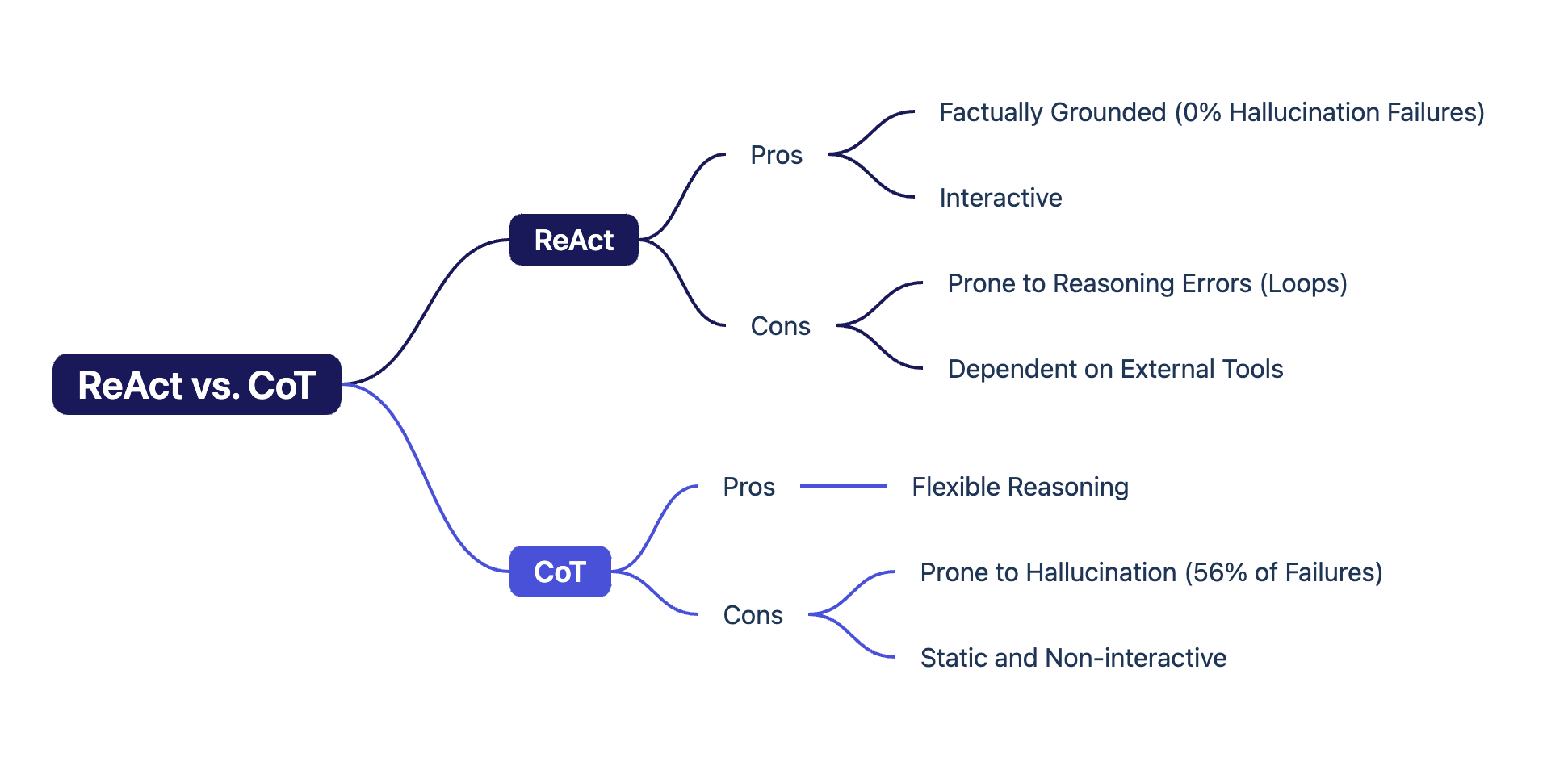
这个表格揭示了惊人的真相:
- ReAct彻底消灭了幻觉:失败案例中,因幻觉导致的错误占比为0%!这是ReAct最核心的优势,它通过“行动”来锚定“思考”,确保了推理的真实性。
- CoT深受幻觉之苦:CoT的失败案例中,超过一半(56%)都是因为它在推理过程中编造了不存在的事实。
- ReAct的代价是推理灵活性:ReAct最大的失败原因是“推理错误”(47%),其交错执行的模式有时会陷入重复的循环,不如纯内部思考的CoT灵活。
这完美解释了为什么ReAct和CoT的组合策略如此强大——它们恰好可以取长补短。
最佳拍档:详解两种黄金组合策略
1. CoT-SC → ReAct:当“智囊团”也拿不准时,派“调查员”去现场
- 运作模式:优先使用CoT-SC(多路径自洽思维链),让模型像一个智囊团,从多个角度进行内部推理并投票。
- 触发条件:如果智囊团内部意见不一,无法形成明确的多数票(意味着内部知识不足以自信地回答),则“求助”ReAct。
- ReAct接管:ReAct作为“调查员”出动,通过与外部环境交互来获取关键事实,为最终决策提供依据。
- 优势:完美弥补了CoT无法核实事实的短板。因此,它在事实核查(Fever)任务上表现最佳。
2. ReAct → CoT-SC:当“调查员”陷入僵局时,请“思想家”来破局
- 运作模式:优先使用ReAct,让模型扮演“调查员”,通过“思考-行动”循环来解决问题。
- 触发条件:如果调查员在限定步数内无法找到答案,或者陷入了行动的死循环(即ReAct的“推理错误”模式),则“求助”CoT-SC。
- CoT-SC接管:CoT-SC这位“思想家”登场,利用其强大的多路径内部推理能力,尝试在现有信息的基础上,从逻辑层面找到突破口。
- 优势:完美弥补了ReAct推理灵活性不足、可能陷入僵局的弱点。因此,它在复杂推理(HotpotQA)任务上表现最佳。
更广阔的舞台:决策任务中的ReAct
ReAct的价值远不止于问答。在更复杂的“决策任务”中,它的能力得到了进一步的体现。
研究者们在ALFWorld(一个模拟家庭环境的文本交互游戏)中进行了实验。这类任务具有**“奖励稀疏”(Sparse Rewards)**的特点——智能体只有在最终完成任务时才能获得奖励,中间步骤没有任何反馈。这就像在黑暗中走迷宫,只有走到出口才知道自己走对了。
在这种场景下,纯粹的“行动派”(Act-Only)智能体表现很差,因为它无法进行长期规划。而ReAct智能体则表现优异,成功率远超传统方法。因为它能够:
- 分解复杂目标:将“拿一个苹果去桌子”分解为“找到苹果”、“拿起苹果”、“找到桌子”、“放下苹果”等步骤。
- 跟踪任务进度:知道自己完成了哪一步,下一步该做什么。
- 处理异常:如果发现门是关着的,会生成“打开门”的新动作。
- 进行有效探索:而不是无头苍蝇一样乱撞。
这表明,“推理”能力为智能体在复杂环境中进行长期规划和自主决策提供了核心动力。
总结与展望
ReAct模式通过将推理与行动相结合,为我们展示了如何构建更可靠、更能干的LLM智能体。它不仅是一种有效的技术,更是一种重要的思想转变——从构建一个封闭的“语言大脑”,转向构建一个能与世界互动的“智能实体”。
核心要点回顾:
- 协同作用:推理指导行动,行动反哺推理,形成强大的动态循环。
- 事实为基:通过与外部世界交互,ReAct有效克服了LLM的“幻觉”问题,大大提高了答案的可靠性。
- 取长补短:与CoT等纯推理方法结合,可以实现“内部知识”与“外部信息”的完美协同,达到1+1>2的效果。
- 未来可期:在问答、事实核查、乃至需要长期规划的复杂决策任务中,ReAct都展现了巨大的潜力。
当然,ReAct也并非银弹,它对外部工具的依赖、以及在推理灵活性上的牺牲,都为未来的研究指明了方向。但无论如何,ReAct已经为我们推开了一扇门,门后是一个AI能够“知行合一”、更深度地理解并与我们这个复杂世界互动的未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)