识场景善分析:无界智慧推出助力空间理解与推理的大模型3D-MoRe
3D-MoRe模型:突破3D场景理解瓶颈的多模态推理框架 由无界智慧联合多所高校研发的3D-MoRe模型,通过创新性"生成-融合-推理"范式,显著提升了3D场景理解能力。该模型核心突破包括: 自适应多模态数据融合:集成ScanNet等数据源,生成62,000个问答对和73,000条物体描述,通过语义过滤保证质量; 分层跨模态交互架构(CMIM):结合文本编码、视觉提示与3D场景

本文一作: 许镕涛 无界智慧联创兼CTO,Rongtao-Xu.github.io。
由无界智慧(Spatialtemporal AI)联合北京邮电大学、中科院自动化所、山东省计算中心及中山大学推出的3D-MoRe模型,是一款专注于3D场景理解与多模态推理的创新框架。该模型通过整合多模态嵌入、跨模态交互与语言模型解码器,能高效处理自然语言指令与3D场景数据,助力提升复杂三维环境中的推理能力与响应生成质量。
依托ScanNet三维场景数据,结合ScanQA的问答标注与ScanRefer的物体描述,3D-MoRe生成了62,000组问答对和73,000条物体描述,覆盖1513个室内场景;同时,通过同义词替换等数据增强技术与语义过滤策略,确保了数据的多样性与高质量。
在实际性能上,该模型在ScanQA的CIDER评分提升2.15%,在ScanRefer的CIDEr@0.5指标提升1.84%,代码已公开于https://3D-MoRe.github.io,为相关领域研究提供实用资源支持。
项目主页:https://3D-MoRe.github.io
文章目录
引言:3D场景理解面临的核心瓶颈
在3D问答和密集字幕任务中,模型需在3D环境中处理复杂的多模态推理:3D问答任务需要深度场景理解和空间推理来回答基于文本的问题,而密集字幕需要详细描述对象及其在3D空间中的关系。现有方法通常依赖语义级数据增强、空间注意和跨模态编码等多模态融合技术,以增强对象定位和场景理解。
3D-MoRe设计的“生成-融合-推理”一体化范式,突破了数据与模型的双重瓶颈,具体优势如下:
- 与专注于小型数据集的Gen3DQA不同,3D-MoRe利用多种数据增强策略拓宽数据集多样性;
- 与严重依赖空间特征的Vote2Cap-DETR++相比,3D-MoRe集成空间和语言信息,实现跨环境的稳健性能;
- 高级语义过滤确保高质量数据,显著提高上下文准确率。

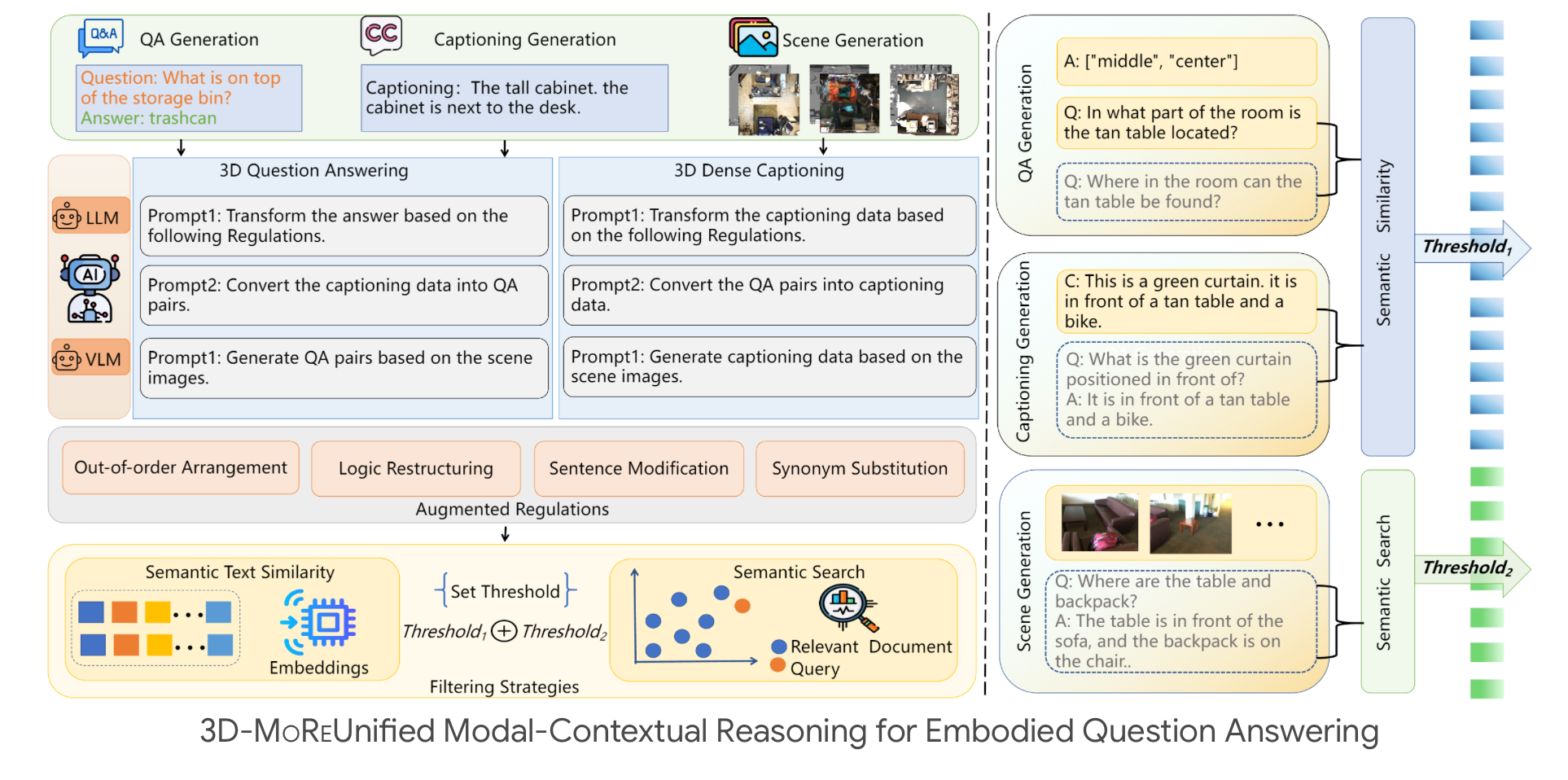
生成大规模数据集面临提示构建、准确注释提取、数据质量过滤等挑战。为解决这些问题,3D-MoRe提出自适应多模态融合范式,包含三种生成方法(问答对生成、字幕生成、场景生成)与两种数据筛选技术(语义相似度、语义搜索)。通过上述方法,为3D问答任务生成62,000个三元组,为字幕任务生成73,000个三元组(如图1所示)。
同时,3D-MoRe微调训练了一个3D大语言模型,通过多模态编码、交互对齐模式、LLM解码响应,实现显著性能改进,接近人类水平的熟练程度。
主要贡献
- 设计3D-MoRe框架:利用基础模型生成大规模3D语言数据集,集成多模态嵌入、跨模态交互和语言模型解码器,增强复杂3D环境中的推理能力;
- 构建高质量数据集:从ScanNet数据集中合成62,000个问答对和73,000个对象描述,显著增加数据多样性,提升3D问答和3D密集字幕任务性能;
- 提出高效数据增强技术:通过同义词置换、语句重排、语义过滤等先进技术,在ScanQA上实现2.15%的CIDER提升,在ScanRefer上实现1.84%的CIDEr@0.5提升,有效提高了模型回答理解准确率。
3D-MoRe模型的核心突破
自适应多模态数据融合范式

如图2所示,3D-MoRe框架通过度量引导的转换实现质量控制的数据增强:集成来自ScanNet、ScanQA和ScanRefer的多源输入 D = { D sccnc , D Q A , D cap } {D}=\left\{D_{\text {sccnc }}, D_{\mathrm{QA}}, D_{\text {cap }}\right\} D={Dsccnc ,DQA,Dcap },增强管道先应用任务特定转换 Φ k \Phi_{ \tiny{{}_{k}}} Φk,再通过基于度量的过滤 Ψ k \Psi_{ \tiny{{}_{k}}} Ψk,最终生成高质量数据集 D f i n a l = ⋃ k = 1 3 Φ k ∘ Ψ k ( D k ) D_{ final}=\bigcup_{k=1}^{3}\Phi_{ \tiny{{}_{k}}} \circ\Psi_{ \tiny{{}_{k}}}(D_{ \tiny{k}}) Dfinal=⋃k=13Φk∘Ψk(Dk)。
1. 语义质量控制
为了确保高质量的数据生成,我们依赖两个关键指标。首先,语义相似度衡量为 S Q ( Q o r i g , Q g e n ) = cos ( f B E R T ( Q o r i g ) , f B E R T ( Q g e n ) ) S_{Q} \left( Q_{orig},Q_{gen} \right)= \cos \left( f_{BERT} \left( Q_{orig} \right),f_{BERT} \left( Q_{gen} \right) \right) SQ(Qorig,Qgen)=cos(fBERT(Qorig),fBERT(Qgen)),其中BERT嵌入量化原始问题和生成问题之间的对齐。其次,我们通过语义搜索方法评估语义一致性,定义为 S c a p ( C o r i g , C g e n ) = 1 n ∑ i = 1 n N L I ( C o r i g , C g e n ( i ) ) S_{cap} \left( C_{orig},C_{gen} \right)= \frac{1}{n} \sum_{i=1}^{n}NLI \left( C_{orig},C_{gen}^{ \left( i \right)} \right) Scap(Corig,Cgen)=n1∑i=1nNLI(Corig,Cgen(i)),该方法利用RoBERTa推断来评估字幕派生问答对的正确性。根据人工注释的统计数据确定的任务特定阈值为 τ k = μ k + 1.96 σ k \tau_{k}= \mu_{k}+1.96 \sigma_{k} τk=μk+1.96σk,问答任务设置为 τ Q A = 0.82 \tau_{QA}=0.82 τQA=0.82,字幕设置为 τ c a p = 0.77 \tau_{cap}=0.77 τcap=0.77。
2. 增强架构
对于QA生成,应用同义词替换、逻辑反转和顺序重排等转换,相关评分计算为 r e l ( A , Q ) = σ ( W r [ f B E R T ( A ) : f B E R T ( Q ) ] ) rel \left( A,Q \right)= \sigma \left( W_{r} \left[ f_{BERT} \left( A \right):f_{BERT} \left( Q \right) \right] \right) rel(A,Q)=σ(Wr[fBERT(A):fBERT(Q)]),其中 σ \sigma σ代表 S i g m o i d Sigmoid Sigmoid函数。密集字幕形式文本到问答对转换采用T5模型,其中生成的问题 Q g e n = T 5 ( C ⊕ P t e m p l a t e ) Q_{gen}=T5 \left( C \oplus P_{template} \right) Qgen=T5(C⊕Ptemplate),使用多个手工模板 P t e m p l a t e P_{template} Ptemplate,答案通过 W ans ∈ R d × ∣ V ∣ \mathbf{W}_{\text{\tiny{ans}}}\in\mathbb{R}^{ d\times|\mathcal{V}|} Wans∈Rd×∣V∣投射。
3. 多模态集成
对于场景到QA的生成,我们采用CogVLM,其中问答对似然通过3D文本交叉关注计算 p ( Q , A ∣ S ) = s o f t m a x ( C r o s s A t t ( E 3 D , E t e x t ) ) p \left( Q,A|S \right)=softmax \left( CrossAtt \left( E_{3D},E_{text} \right) \right) p(Q,A∣S)=softmax(CrossAtt(E3D,Etext))。最终数据集 D F i n a l D_{Final} DFinal集成了62,000多个问答对和73,000个标题注释,超过原始ScanQA和ScanRefer数据集。
分层跨模态交互推理架构 (CMIM)
3D-MoRe提出的CMIM架构为具身推理建立分层融合框架,包含三个核心组件:多模态嵌入模块、交叉注意力融合模块、LLM解码器。如图3所示,处理管道 R = L L M d e c ( F f u s i o n ( E t ( T ) ∥ E v ( V ) ∥ E s ( S ) ) ) R=LLM_{dec} \left( F_{fusion} \left( E_{t} \left( T \right) \parallel \mathcal{E}_{v} \left( V \right) \parallel \mathcal{E}_{s} \left( S \right) \right) \right) R=LLMdec(Ffusion(Et(T)∥Ev(V)∥Es(S)))通过张量连接集成文本、视觉提示和3D场景数据,实现端到端的3D多模态推理。
1. 多模态嵌入模块
(1)文本编码
对于输入标记 T = { w i } i = 1 L T= \left \{ w_{i} \right \}_{i=1}^{L} T={wi}i=1L,标准Transformer编码生成嵌入 E t = Transformer enc ( Embed ( T ) + P t ) ∈ R L × d \mathbf{E}_{t} = \text{Transformer}_{\text{\tiny{enc}}} \left(\text{Embed} \left(T\right) +\mathbf{P}_{t} \right)\in\mathbb{R}^{L\times d} Et=Transformerenc(Embed(T)+Pt)∈RL×d,位置编码 P t P_t Pt。
(2)视觉提示编码
空间制导信号 V = { v j } j = 1 N v V= \left \{ v_{j} \right \}_{j=1}^{N_{v}} V={vj}j=1Nv(3D边界框 v j = ( c j , d d j ) ∈ R 6 v_{j}= \left( c_{j},dd_{j} \right) \in R^{6} vj=(cj,ddj)∈R6)通过两种方式获取:
- 用户手动注释的3D边界框;
- Mask3D检测器自动输出的边界框。
通过 E v = M L P ( F l a t t e n ( V ) ) ∈ R N v × d \mathbf{E}_{v}= \mathrm{MLP} \left( Flatten \left( V \right) \right) \in \mathbb{R}^{N_{v} \times d} Ev=MLP(Flatten(V))∈RNv×d编码以建立空间先验。
(3)3D场景编码
采用Vote2Cap-DETR++模型处理3D点云 S ∈ R N p × 3 S\in\mathbb{R}^{ N_{\text{\tiny{p}}}\times 3} S∈RNp×3,提取场景全局特征: E s = Vote2Cap − DETR + + (S) ∈ R N s × d \mathbf{E}_{\text{s}} = \text{Vote2Cap}-\text{DETR}++\text{ (S)}\in\mathbb{R}^{N_{\text{s}} \times d} Es=Vote2Cap−DETR++ (S)∈RNs×d
2. 跨注意力融合模块
融合模块通过三阶段特征集成,实现多模态数据的深度对齐:
(1)跨模态对齐
通过交叉注意力机制,让文本嵌入与视觉-场景嵌入交互:
E f 1 = softmax ( E t W q ( Concat ( E v , E s ) W k ⊤ ) d ) ⋅ ( E v ∥ E s ) W v \mathbf{E}_{f1} = \text{softmax} \left( \frac{\mathbf{E}_{t} \mathbf{W}_{q} \left( \text{Concat} \left( \mathbf{E}_{v}, \mathbf{E}_{s} \right) \mathbf{W}_{k}^{\top} \right)}{\sqrt{d}} \right) \cdot \left( \mathbf{E}_{v} \parallel \mathbf{E}_{s} \right) \mathbf{W}_{v} Ef1=softmax(dEtWq(Concat(Ev,Es)Wk⊤))⋅(Ev∥Es)Wv
(2)上下文保持
自我注意过程 [ E f 1 ; E t ] [E_{f1};E_t] [Ef1;Et]通过Transformer层来保持语言一致性,同时启用自适应融合控制。
(3)残差融合
通过残差连接保留视觉-场景引导细节,生成最终融合特征:
E f = L a y e r N o r m ( T r a n s f o r m e r L a y e r ( E f 1 ∣ ∣ E t ) + E t ) E_{f}=LayerNorm \left( TransformerLayer \left( E_{f1}||E_{t} \right)+E_{t} \right) Ef=LayerNorm(TransformerLayer(Ef1∣∣Et)+Et)
3. LLM解码器
解码器通过动态前缀投影实现基于视觉的生成: h t = LLM ( p 1:t ; LinearProj ( E f ) ) \mathbf{h}_{\textit{t}}=\text{LLM}\left(\mathbf{p}_{\textit{1:t}};\text{LinearProj} \left(\mathbf{E}_{\textit{f}}\right)\right) ht=LLM(p1:t;LinearProj(Ef))
其中视觉空间上下文通过嵌入条件令牌概率的投影前缀流动 p ( w t + 1 ) = s o f t m a x ( h t W v o c a b ) p \left( w_{t+1} \right)=softmax \left( h_{t}W_{vocab} \right) p(wt+1)=softmax(htWvocab)
实验结果:性能显著超越现有方法
1. 与领先方法的比较
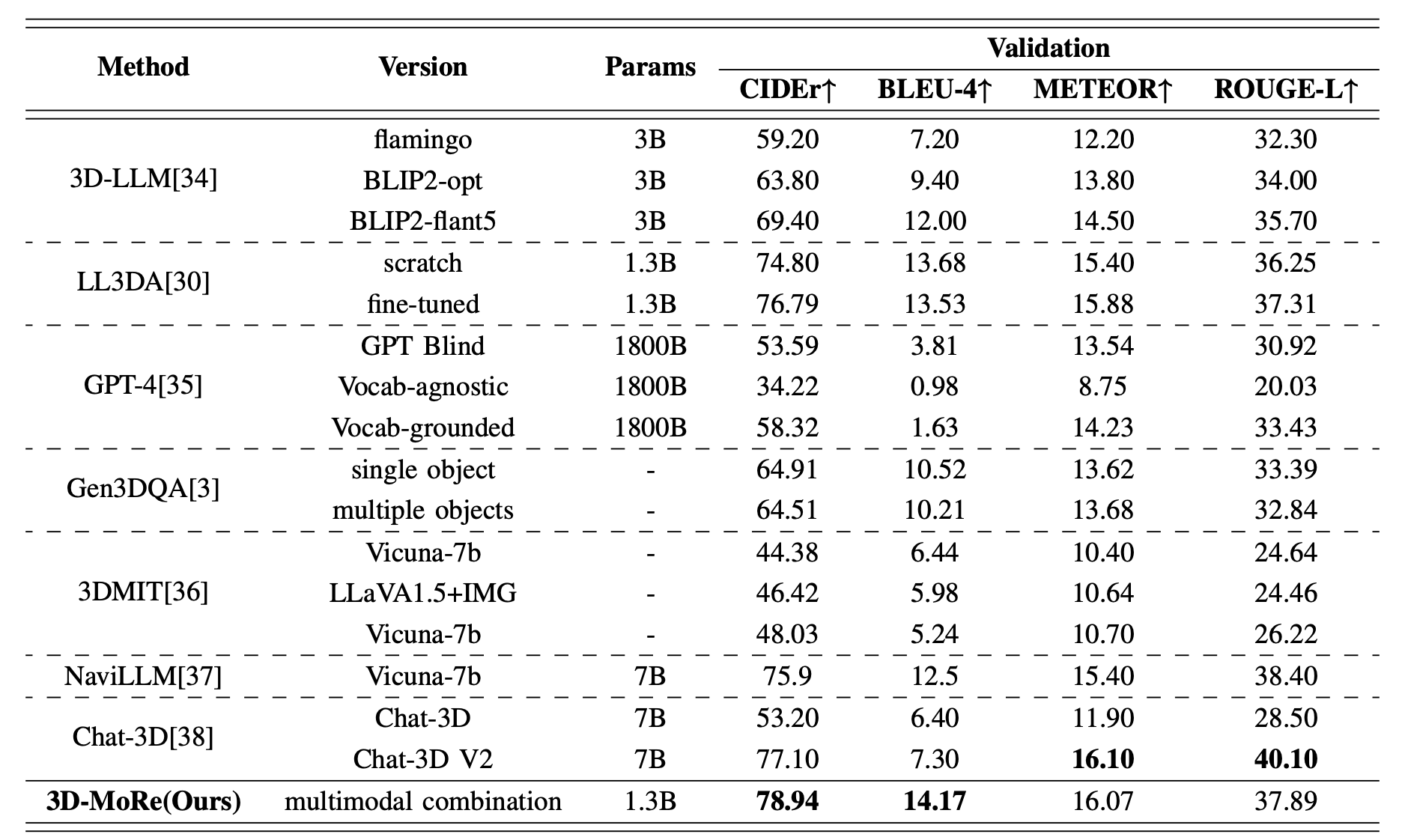
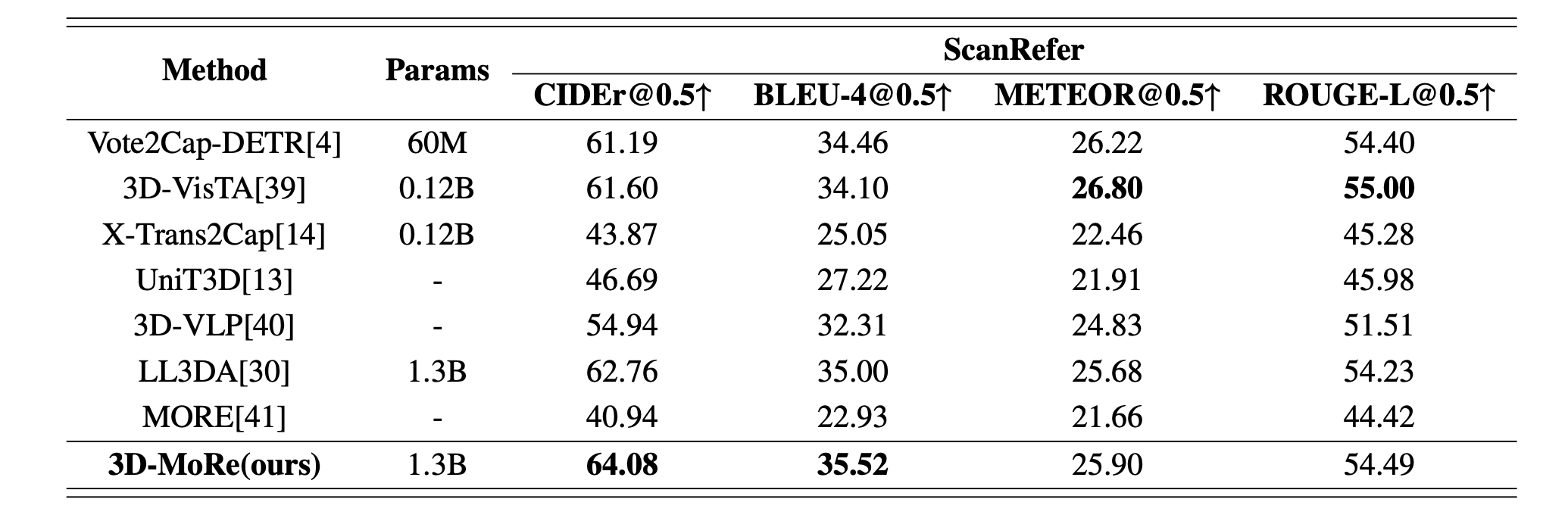
在权威基准 ScanQA 和 ScanRefer 上进行严格评测,使用 BLEU, ROUGE, METEOR, CIDEr 指标。表1和表2展示了我们的方法与现有方法的性能。在这里,“版本”指的是不同的模型架构或实验技术。我们的模型始终优于以前的方法,尤其是在验证集上,使用CIDER指标作为主要指标。值得注意的是,我们的方法超过了基于生成的Chat-3D V2模型,将CIDEr@0.5分数提高了1.84%。此外,在ScanRefer数据集的比较中,我们的模型优于其他先前的方法,显示在低参数LLM上CIDER性能提高了2.15%。
关键结论:
- 在ScanRefer数据集上,3D-MoRe(1.3B参数量)的CIDER@0.5分数达到64.08,超过基于生成的Chat-3D V2模型1.84%;
- 在低参数LLM(如1.3B)设置下,3D-MoRe在ScanQA的CIDER指标上比现有方法提升2.15%。
2. 消融实验
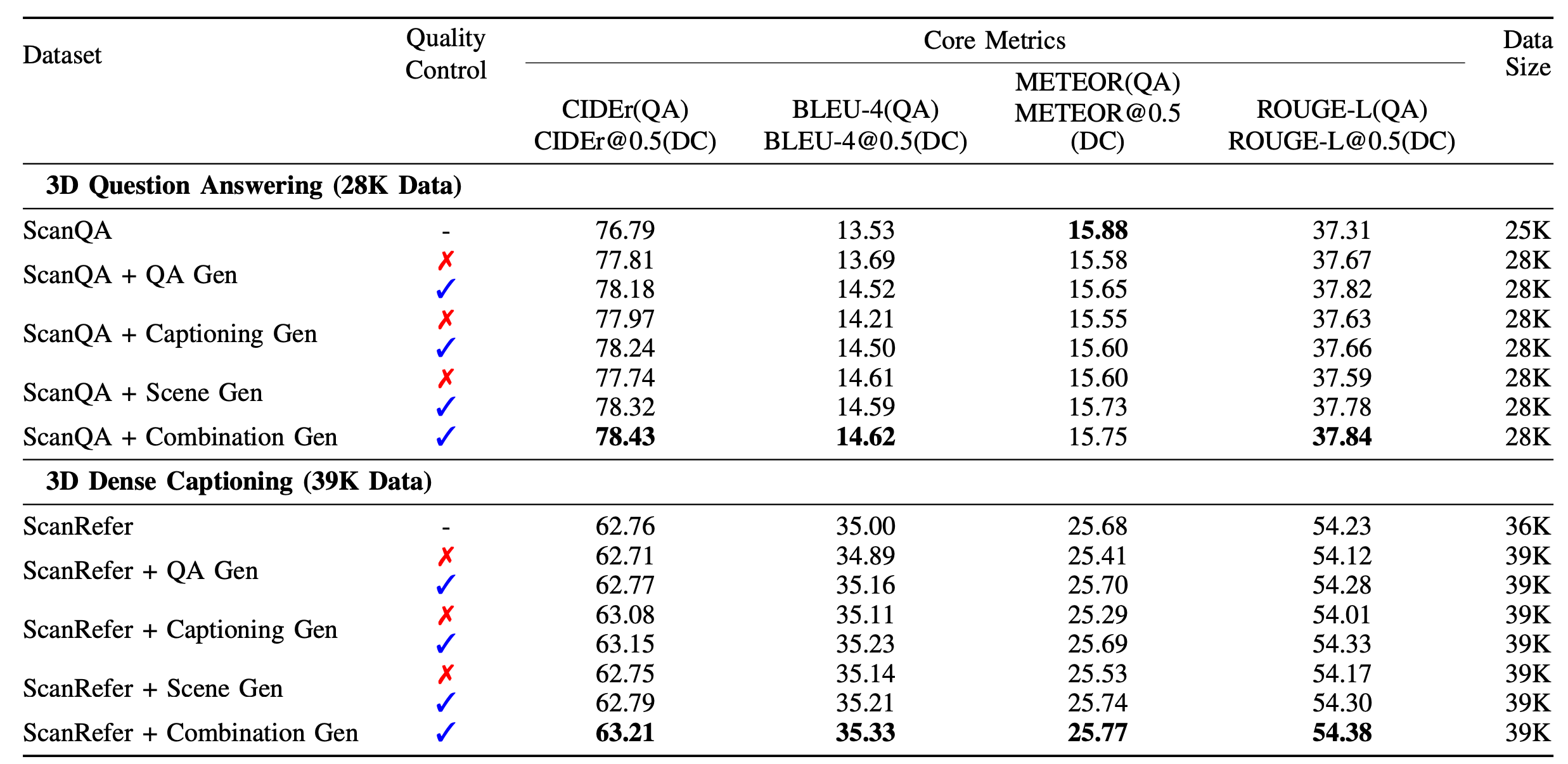
为验证数据增强与过滤方法的有效性,该研究采用自适应多模态融合范式扩展3D问答和3D密集字幕任务数据集。实验设置:
- 统一采样3,000个实例,对比三种生成方法(问答对生成、字幕生成、场景生成);
- 3D问答任务:额外生成问答对,通过语义搜索过滤低质量数据;
- 3D密集字幕任务:通过语义相似度度量选择高质量字幕。
关键结论:
- 组合数据增强(QA生成+字幕生成+场景生成)与多维度质量控制(语义相似度+语义搜索)的结合效果最佳;
- 在3D问答任务中,组合方法的CIDER(QA)达到78.43%,比基础ScanQA(28K)提升0.62%;
- 在3D密集字幕任务中,组合方法的CIDER@0.5(DC)达到63.21%,比基础ScanRefer(39K)提升0.5%。
应用前景与未来方向
1. 赋能研究领域
生成的大规模高质量数据集(62K问答对 + 73K对象描述)解决了3D-语言领域的数据瓶颈,为模型训练、评测提供坚实基础,可支持3D问答、密集字幕、视觉定位等多任务研究。
2. 降低技术门槛
3D-MoRe提供完整的训练、推理与数据生成流程(代码已开源),研究者可直接复用框架:
- 数据生成:通过自适应多模态融合范式快速扩展数据集;
- 模型训练:基于CMIM架构实现端到端多模态推理;
- 推理部署:支持自然语言指令输入与3D场景数据处理。
3. 扩展通用场景
其统一模态交互推理架构(CMIM)具备良好扩展性,可迁移至其他3D多模态任务:
- 视觉定位:结合3D场景特征与文本指令,实现对象精准定位;
- 具身导航:引导机器人在3D环境中根据自然语言指令规划路径;
- 人机交互:支持机器人理解复杂场景中的自然语言需求(如“拿取桌子上的水杯”)。
无界智慧团队介绍
无界智慧(Spatialtemporal AI)是一家专注于基于时空智能的跨场景具身Agent的AI公司,致力于打造具备自主感知、理解、决策与执行能力的服务机器人系统。我们当前面向“陪护场景”构建具备真实任务执行能力的智能康养陪护机器人,部署于养老院、康养社区、家庭养老、示范样板间等场景。
无界智慧团队成员由来自CMU、MBZUAI、清华、北大、中山大学、南方科技大学的研究人员组成。团队在机器人和人工智能领域具有深厚的学术造诣,已在T-PAMI、CVPR、ICCV、ICML、NeurIPS、ICLR、ICRA、RSS等国际顶级会议和期刊上发表数百篇高水平学术论文。
关注微信公众号:无界时空,了解具身领域最新资讯吧~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)