Spring AI+RAG架构在社交媒体营销中的实战应用——Java技术面试深度解析
本文通过一场生动的Java技术面试,深入探讨Spring AI和RAG架构在社交媒体营销场景中的应用,包含完整的技术解析和代码示例,帮助开发者掌握AI技术在营销领域的实战技能。
Spring AI+RAG架构在社交媒体营销中的实战应用——Java技术面试深度解析
📋 面试背景
某互联网大厂正在招聘Java开发工程师,专注于AI技术在社交媒体营销领域的应用。岗位要求熟练掌握Spring AI、RAG架构、向量数据库等技术,能够构建智能化的营销系统。
🎭 面试实录
第一轮:基础概念考查
面试官:小润龙,你好。首先请你简单介绍一下Spring AI的核心功能和在社交媒体营销中的应用场景。
小润龙:Spring AI啊,这个我知道!它就像是给Spring框架装上了AI大脑,可以很方便地集成各种AI模型。在社交媒体营销中,可以用来做智能客服、内容推荐什么的...(声音逐渐变小)
面试官:具体一点,Spring AI提供了哪些核心组件?
小润龙:呃...有ChatClient、EmbeddingClient,还有PromptTemplate之类的吧?主要是让调用AI API变得更简单。
面试官:那RAG架构呢?它在营销场景中有什么价值?
小润龙:RAG就是检索增强生成嘛!比如用户问营销活动的问题,我们可以从知识库检索相关信息,再让AI生成回答,这样更准确!
面试官:很好。最后一个基础问题:为什么在AI项目中构建工具的选择很重要?
小润龙:因为AI项目依赖很多啊!Maven或Gradle能帮我们管理这些复杂的依赖,不然手动管理会疯掉的!
第二轮:实际应用场景
面试官:现在假设要为一个社交媒体平台构建智能客服系统,你会如何设计技术架构?
小润龙:这个...我会用Spring Boot做后端,集成Spring AI,然后用Redis或者Milvus做向量数据库存储知识库,前端用Vue...
面试官:具体到RAG的实现,文档加载和向量化的流程是怎样的?
小润龙:(擦汗)文档加载就是读取PDF、Word这些文件,然后拆分成chunk,再用Embedding模型转换成向量,存到向量数据库里...
面试官:那用户提问时,具体的检索和生成流程呢?
小润龙:用户问题也转换成向量,在向量数据库里做相似度搜索,找到最相关的文档片段,把这些上下文和问题一起给AI模型生成回答。
第三轮:性能优化与架构设计
面试官:如果智能客服系统并发量很大,你会如何优化性能?
小润龙:这个...可以用缓存?Redis缓存热点问题答案,还有...异步处理?
面试官:向量数据库的索引选择有什么考虑?HNSW和IVF-PQ有什么区别?
小润龙:(紧张)HNSW好像是基于图的算法,适合高召回率;IVF-PQ是量化之类的...具体区别我记不太清了。
面试官:最后,如何用Maven或Gradle管理AI项目的多环境配置?
小润龙:可以用Profiles!不同环境用不同的配置,比如开发环境用测试API key,生产环境用正式的...
面试结果
面试官:小润龙,你的基础概念掌握得不错,但在深度技术和架构设计方面还需要加强。建议你多实践一些完整的AI项目,特别是性能优化和系统架构方面。本次面试评级为B+,进入下一轮需要在这些方面进一步提升。
📚 技术知识点详解
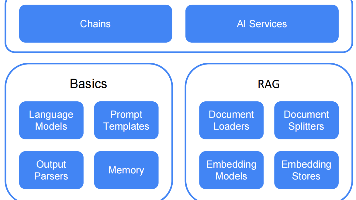
Spring AI核心组件详解
Spring AI提供了统一的AI应用开发接口,主要组件包括:
// ChatClient示例
@Bean
public ChatClient chatClient(@Value("${spring.ai.openai.api-key}") String apiKey) {
return OpenAiChatClient.builder()
.apiKey(apiKey)
.build();
}
// EmbeddingClient示例
@Bean
public EmbeddingClient embeddingClient(@Value("${spring.ai.openai.api-key}") String apiKey) {
return OpenAiEmbeddingClient.builder()
.apiKey(apiKey)
.build();
}
在社交媒体营销中,可以用ChatClient处理用户咨询,用EmbeddingClient构建内容推荐系统。
RAG架构完整实现
RAG(Retrieval Augmented Generation)架构包含四个核心步骤:
- 文档加载与分割
public List<Document> loadAndSplitDocuments(String filePath) {
// 加载文档
DocumentLoader loader = new FileDocumentLoader();
Document document = loader.load(filePath);
// 文本分割
TextSplitter splitter = new RecursiveCharacterTextSplitter(
1000, 200, true, 100
);
return splitter.split(document);
}
- 向量化与存储
public void vectorizeAndStore(List<Document> chunks) {
EmbeddingClient embeddingClient = context.getBean(EmbeddingClient.class);
VectorStore vectorStore = context.getBean(VectorStore.class);
for (Document chunk : chunks) {
float[] embedding = embeddingClient.embed(chunk.getContent());
vectorStore.addEmbedding(embedding, chunk);
}
}
- 语义检索
public List<Document> retrieveRelevantDocuments(String query, int topK) {
EmbeddingClient embeddingClient = context.getBean(EmbeddingClient.class);
VectorStore vectorStore = context.getBean(VectorStore.class);
float[] queryEmbedding = embeddingClient.embed(query);
return vectorStore.similaritySearch(queryEmbedding, topK);
}
- 增强生成
public String generateAnswer(String query, List<Document> contextDocs) {
ChatClient chatClient = context.getBean(ChatClient.class);
String context = contextDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
String prompt = String.format("""
基于以下上下文信息回答问题:
%s
问题:%s
回答:
""", context, query);
return chatClient.generate(prompt);
}
向量数据库选型与优化
在社交媒体营销场景中,向量数据库的选择至关重要:
Milvus:
- 优点:高性能、支持多种索引算法、云原生
- 适用场景:大规模向量检索、高并发查询
Redis:
- 优点:部署简单、内存存储、低延迟
- 适用场景:中小规模应用、实时性要求高
索引算法选择:
- HNSW:高召回率,适合精度要求高的场景
- IVF-PQ:高吞吐量,适合大规模数据
Maven多环境配置最佳实践
<profiles>
<profile>
<id>dev</id>
<properties>
<spring.ai.openai.api-key>dev-key-123</spring.ai.openai.api-key>
<vectorstore.type>redis</vectorstore.type>
</properties>
</profile>
<profile>
<id>prod</id>
<properties>
<spring.ai.openai.api-key>prod-key-456</spring.ai.openai.api-key>
<vectorstore.type>milvus</vectorstore.type>
</properties>
</profile>
</profiles>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<!-- 条件依赖 -->
<dependency>
<groupId>com.redis</groupId>
<artifactId>spring-ai-redis-vector-store</artifactId>
<version>1.0.0</version>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
</dependencies>
智能客服系统架构设计
┌─────────────────┐ ┌──────────────────┐ ┌────────────────┐
│ Web前端 │───▶│ Spring Boot │───▶│ Spring AI │
│ (Vue/React) │ │ 应用层 │ │ AI层 │
└─────────────────┘ └──────────────────┘ └────────────────┘
│ │
│ │
▼ ▼
┌─────────────────┐ ┌──────────────────┐ ┌────────────────┐
│ 缓存层 │◀──▶│ 向量数据库 │◀──▶│ 知识库管理 │
│ (Redis) │ │ (Milvus/Redis) │ │ 系统 │
└─────────────────┘ └──────────────────┘ └────────────────┘
💡 总结与建议
通过这次面试对话,我们可以看到Spring AI和RAG架构在社交媒体营销中的巨大价值:
学习建议:
- 夯实基础:深入理解Spring AI核心组件和RAG架构原理
- 实践项目:从简单的智能客服开始,逐步构建复杂的营销系统
- 性能优化:学习向量数据库索引算法和系统架构优化
- 工具熟练:掌握Maven/Gradle在多环境下的最佳实践
- 业务理解:深入了解社交媒体营销的业务流程和需求
技术成长路径:
- 初级阶段:掌握Spring AI基本使用和简单RAG实现
- 中级阶段:优化系统性能,处理高并发场景
- 高级阶段:设计复杂AI工作流,集成多模态能力
- 专家阶段:领导AI项目架构,创新业务应用场景
Spring AI和RAG技术正在重塑社交媒体营销的智能化未来,掌握这些技术将为你在大厂面试和实际工作中带来显著优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)