EasyCopilot之数据质量规则智能推荐——数据治理,快马加鞭
数据质量中心作为EasyData中的数据治理模块产品之一,通过事前定义监控规则、事中监控数据的生产过程、事后评估和问题追溯,实现数据质量问题发现的“全面化、自动化、在线化”,从而将业务规范落实到数据开发的每一环节,围绕DAMA理论的完整性、一致性、准确性、有效性、唯一性和及时性六大维度监控数据质量问题,为企业提供数据全生命周期的监控能力。当我们未手动输入补充监控要求时,点击开始生成,大模型将直接根

在数据驱动决策成为企业核心竞争力的当下,数据质量的精准管控直接影响业务判断的有效性。随着数据体量呈指数级增长、来源渠道日趋多元,传统依赖人工制定监控规则的模式已凸显效率瓶颈——不仅需投入大量人力成本进行规则编写与维护,更易因人为疏漏导致规则覆盖不全、业务适配性不足等问题。
为此,EasyData推出质量规则AI智能推荐功能,通过AI技术赋能数据治理,实现监控规则的自动化生成与精准适配。

数据质量中心作为EasyData中的数据治理模块产品之一,通过事前定义监控规则、事中监控数据的生产过程、事后评估和问题追溯,实现数据质量问题发现的“全面化、自动化、在线化”,从而将业务规范落实到数据开发的每一环节,围绕DAMA理论的完整性、一致性、准确性、有效性、唯一性和及时性六大维度监控数据质量问题,为企业提供数据全生命周期的监控能力。
而智能推荐质量规则正是数据质量中心为提升数据治理效率、推动数据质量提升而推出的全新功能。其入口位于数据质量中心-监控任务详情页中的规则列表顶部,目前仅支持针对Hive数据源进行智能推荐质量规则,生成智能推荐质量规则需要有监控任务的编辑权限。

点击“AI推荐规则”,进入到推荐规则页面。页面顶部支持用户额外输入监控要求,也可默认不输入内容,点击“开始生成”按钮后,系统将根据表信息、字段信息、监控模板、监控要求等生成推荐规则。
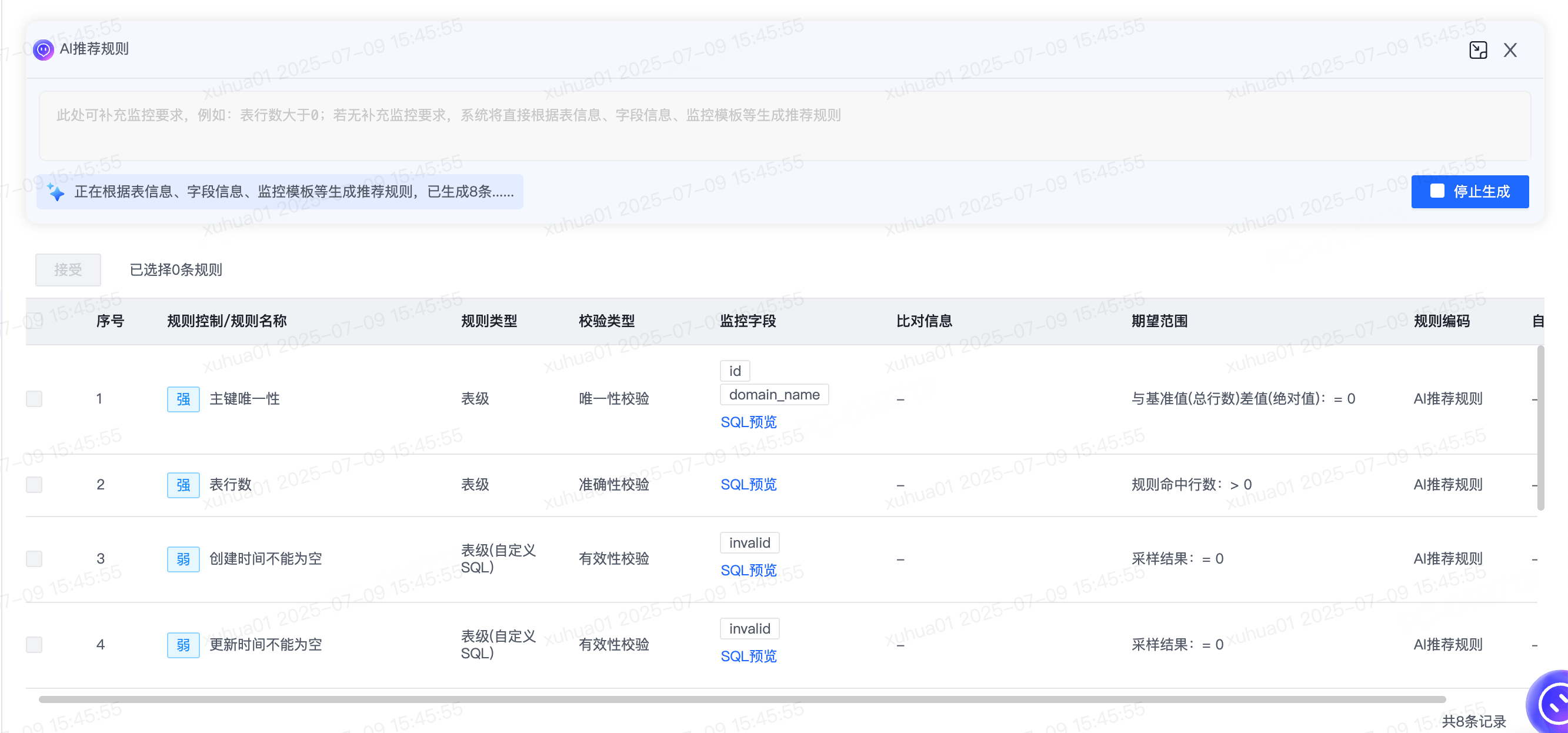
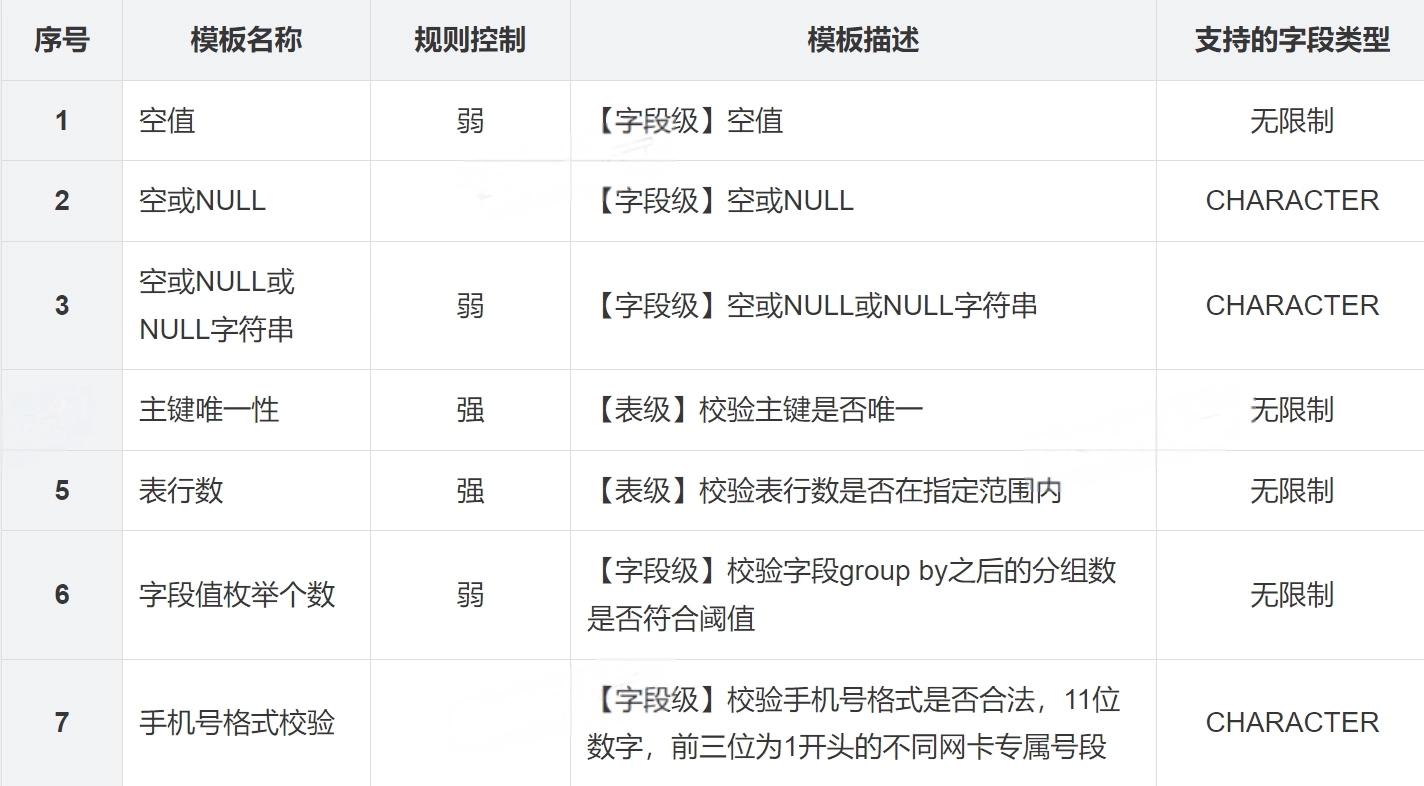
目前支持的AI推荐规则主要有两类,包括模板规则和自定义规则。针对模板规则,为提高模型生成质量规则的准确性,我们目前限制了能推荐出来的模板规则类型,以下都是我们经过验证,推荐效果表现良好的模板,具体包括:


假设我们有一张银行流水记录表,用于记录每日新增支付流水数据,建表语句如下:
CREATE TABLE IF NOT EXISTS dwd_trade_payment_increment_di (
payment_id STRING COMMENT '主键,支付流水ID,格式:PAYYYYYMMDDHHMMSS+6位随机数',
order_id STRING COMMENT '订单ID,关联订单主表',
user_id STRING COMMENT '用户ID,用户唯一标识',
payment_amount DECIMAL(10,2) COMMENT '支付金额,单位:元,保留2位小数',
payment_method STRING COMMENT '支付方式,枚举值:ALIPAY/WECHATPAY/CARD/APPLEPAY',
payment_time TIMESTAMP COMMENT '支付时间,精确到毫秒',
payment_status STRING COMMENT '支付状态,枚举值:SUCCESS/FAIL/PROCESSING/REFUNDING/REFUNDED',
currency STRING COMMENT '货币类型,ISO 4217标准代码,如CNY/USD/EUR',
channel_fee DECIMAL(8,4) COMMENT '支付渠道手续费,单位:元,保留4位小数',
transaction_id STRING COMMENT '第三方支付交易ID,如支付宝交易号、微信支付单号',
device_info STRING COMMENT '支付设备信息,包含设备类型、操作系统、浏览器信息',
ip_address STRING COMMENT '支付IP地址,用户支付时的IP地址',
risk_score INT COMMENT '支付风险评分,0-100分,分数越高风险越大',
create_time TIMESTAMP COMMENT '记录创建时间,数据进入本系统的时间'
)
PARTITIONED BY (
dt STRING COMMENT '分区日期,格式:YYYY-MM-DD'
);根据表的元数据,我们预期的数据质量规则如下:
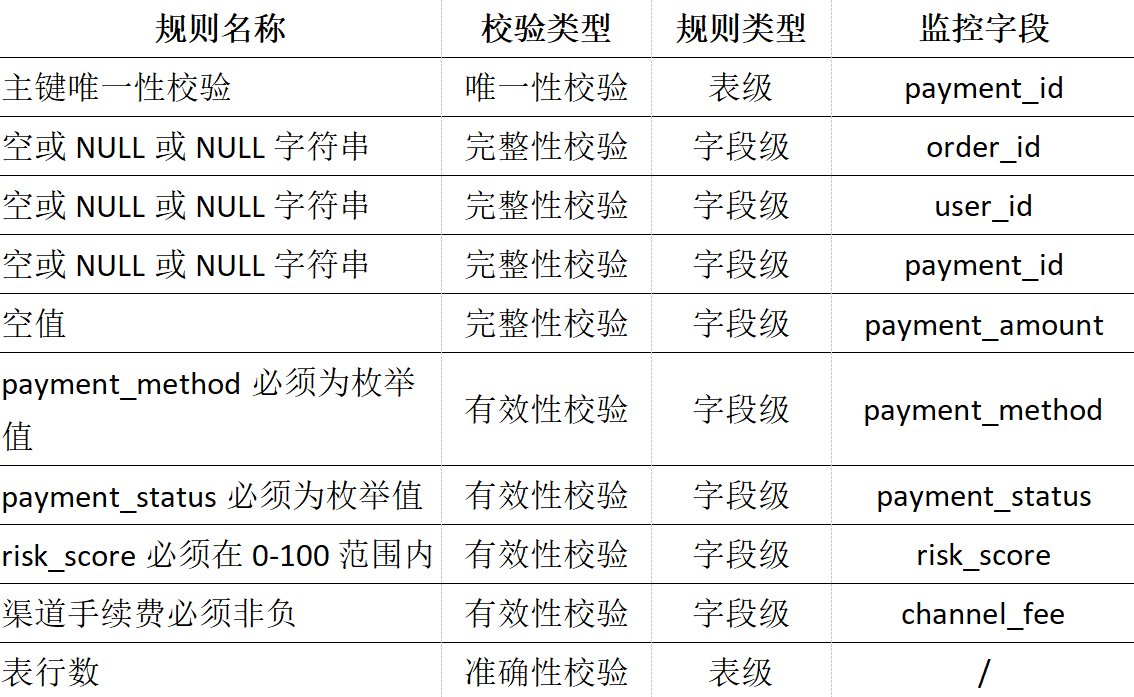
那么接下来,我们来检验看AI能否把我们期望的这些规则推荐出来。
首先,来到数据质量中心,对这张表新建监控任务:
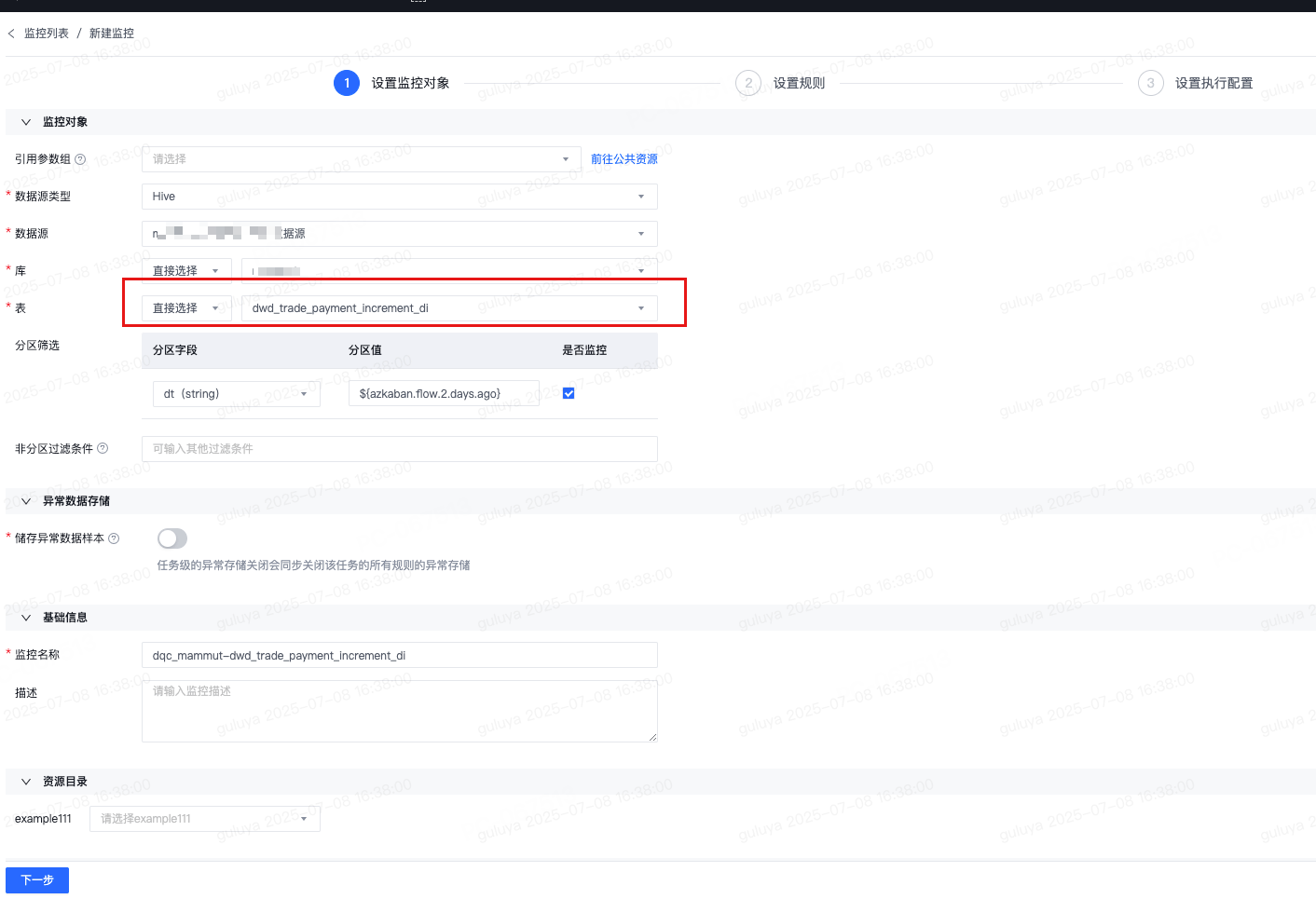
然后点击下一步,进入规则创建页面:
点击“AI推荐规则”,进入AI推荐规则页面,并点击“开始生成”:
当我们未手动输入补充监控要求时,点击开始生成,大模型将直接根据表的元数据,包括表信息、字段信息、规则模板等,开始解析并生成对应规则,推荐的规则会尽量覆盖每一个字段。
推荐结果:
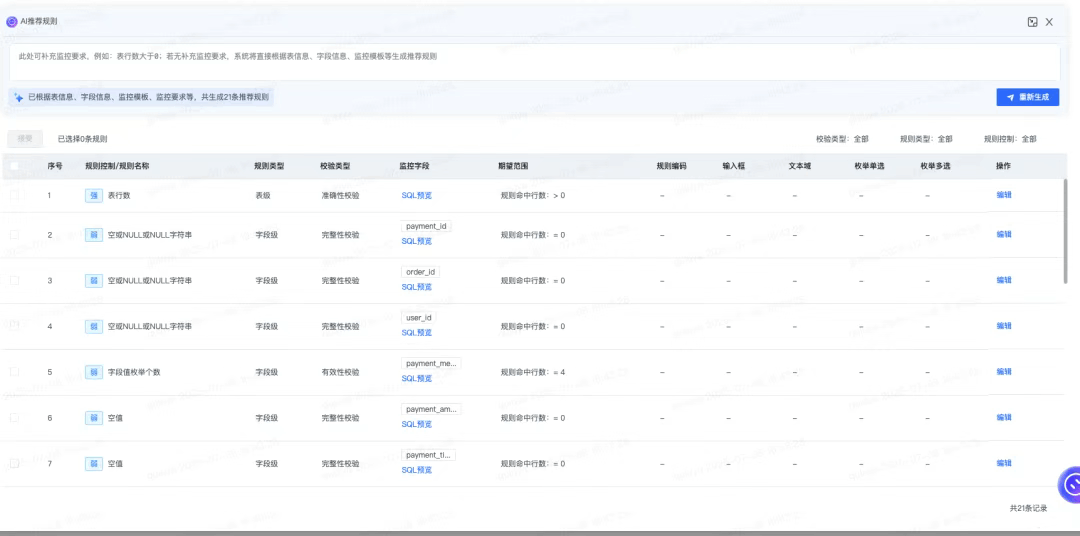
本案例下,系统共智能推荐了21条规则。接着,配置者基于开发经验,逐条进行判断,采纳汇总详情如下:
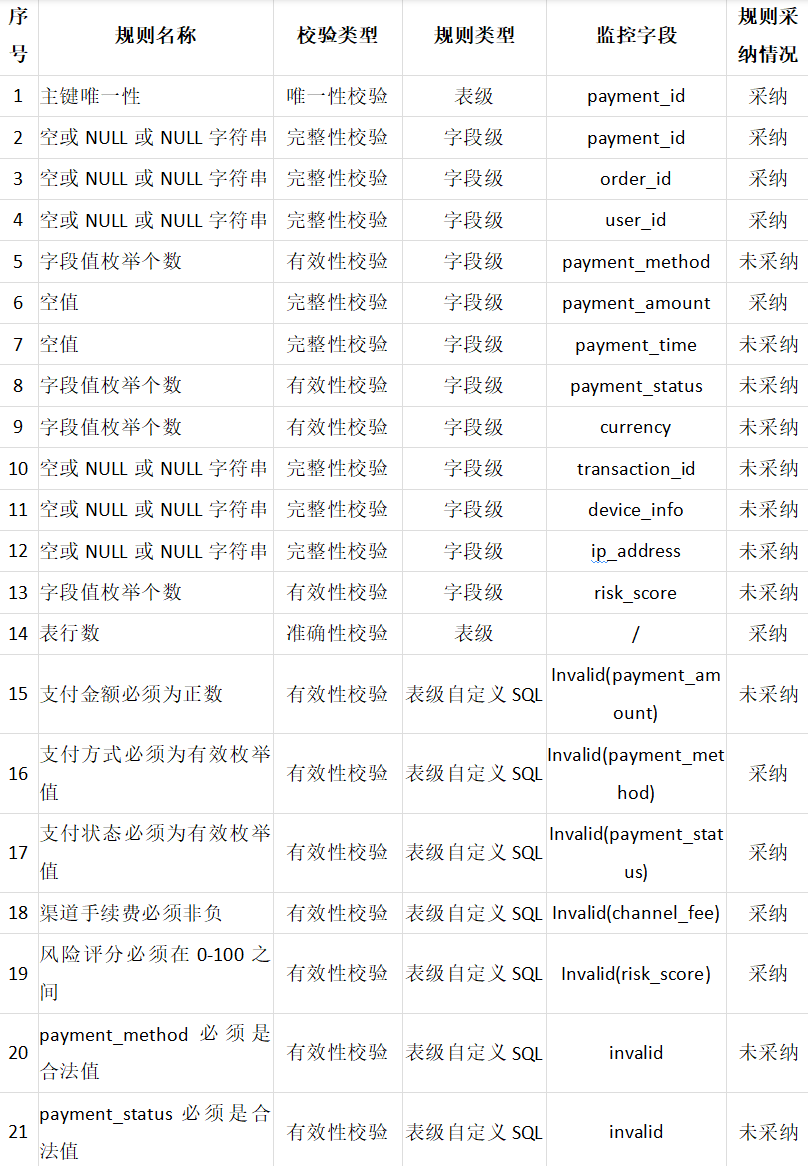
具体被采纳规则的详细情况如下:

主键字段 payment_id,推荐出来主键唯一性和非空校验规则,确保主键唯一且不能为空,基于经验判断,采纳该规则。
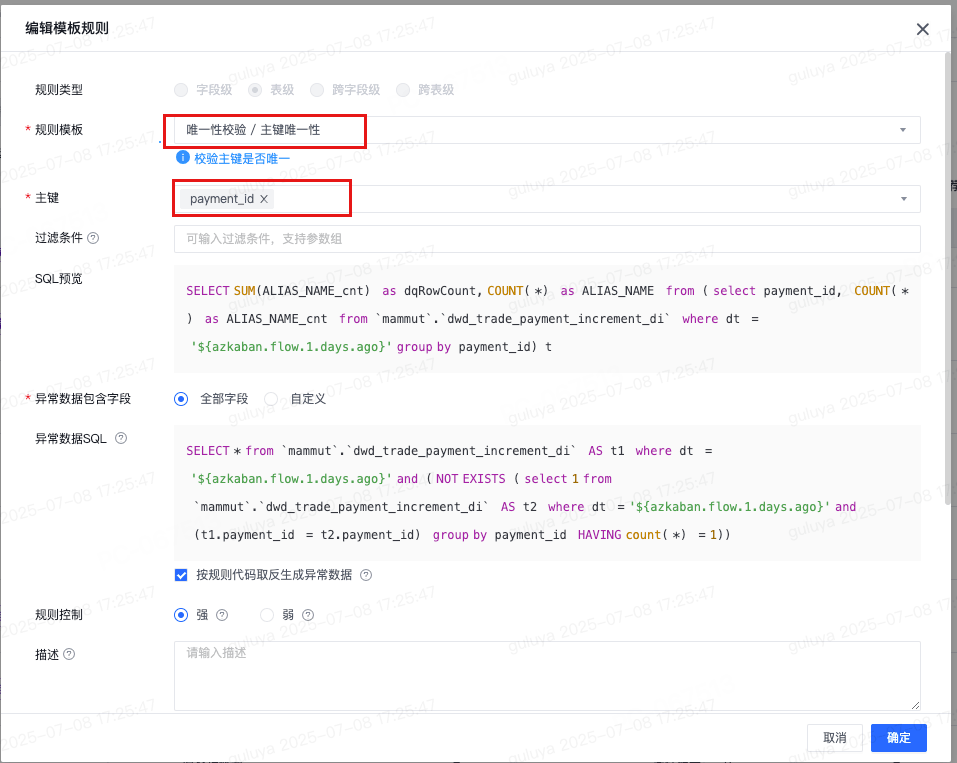

针对于order_id,user_id,transaction_id,payment_time等字段,推荐出来空值校验,由于这些字段比较核心,确保其不能为空,基于经验判断,采纳该规则。
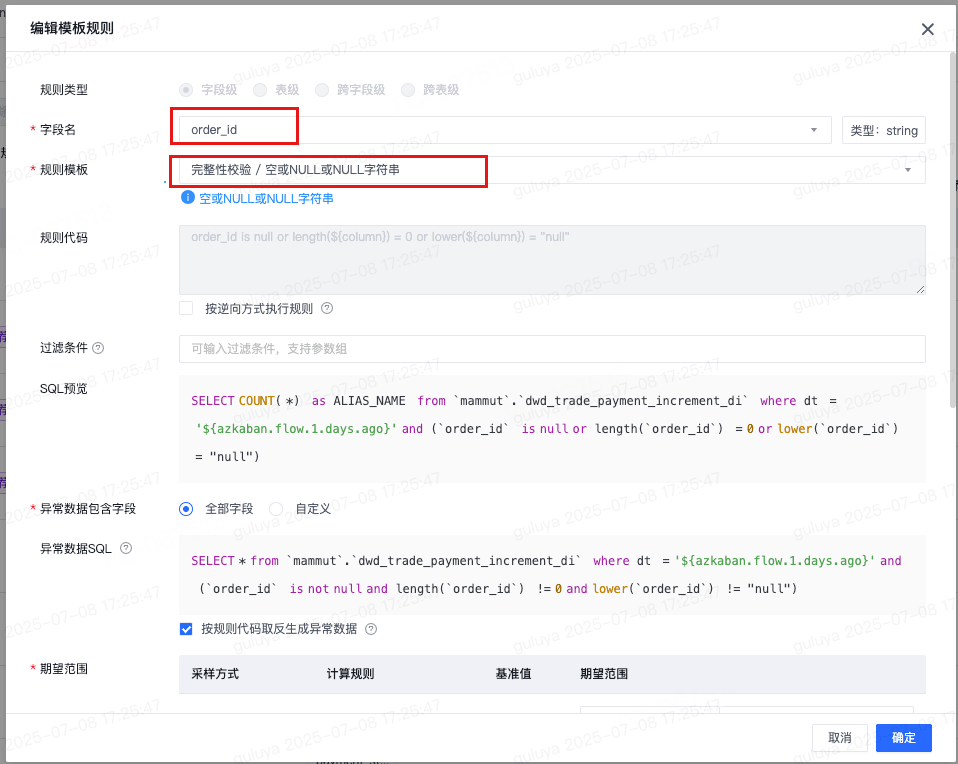

针对于payment_status,payment_method字段,作为枚举字段,推荐出来枚举值个数以及有效枚举值规则,确保其枚举值的有效性,基于经验判断,采纳该规则。
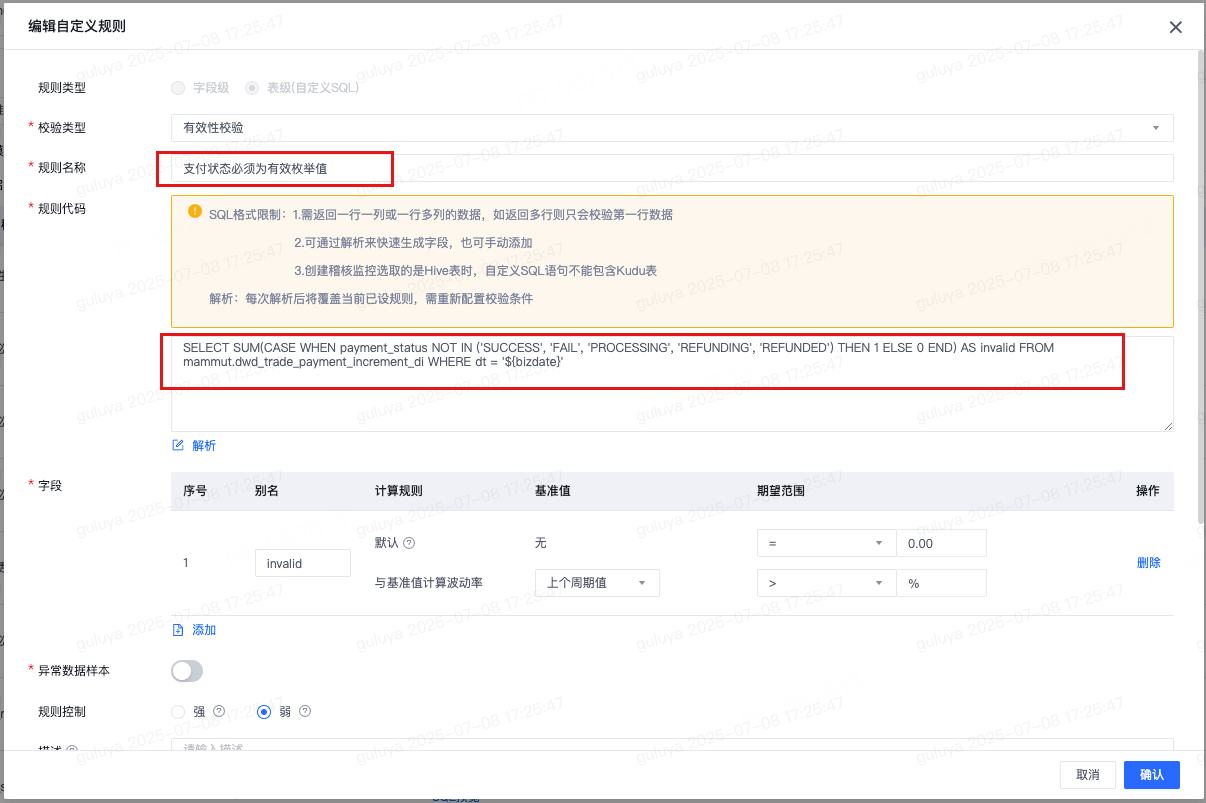

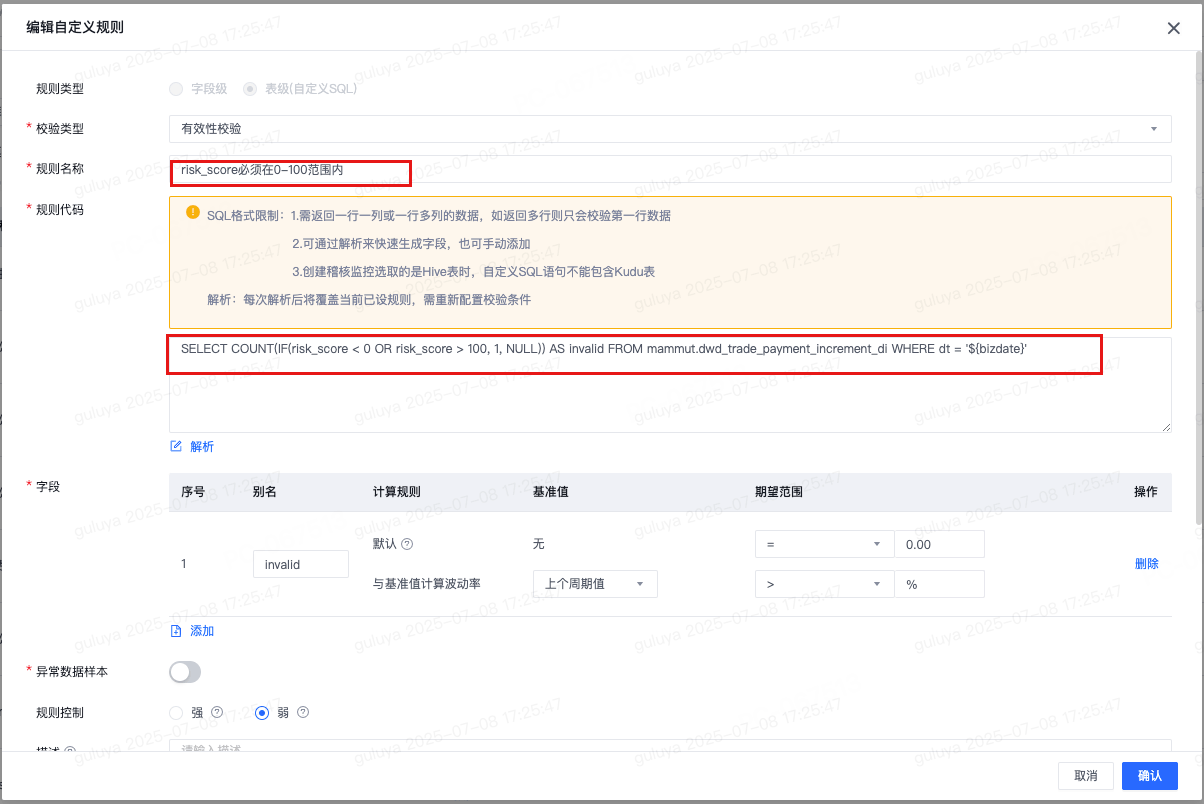
对于payment_amount,channel_fee,risk_score等数值字段,推荐出来相应的数据格式校验规则,确保其数值的有效性,基于经验判断,采纳该规则。
在本次案例中,我们从推荐的21条规则中,采纳了10条完全匹配我们预期的监控规则。在实际应用中,使用者需要根据业务需要,结合自己的专家经验,按需采纳。
使用者选择对应的规则并点击“接受”,规则就会被正式添加到当前监控任务的规则列表。

上面我们介绍了数据质量中心基于表的元数据所生成的智能推荐规则,但是在实际场景中,由于种种原因,元数据并不能像上述案例一样完备详细。
这种情况下如果直接让模型生成质量规则,则推荐效果势必不尽如人意。基于此,我们提供了“补充监控要求”功能,用户可以在生成质量规则之前,使用自然语言将所需要的稽核要求告诉模型,基于用户补充的监控要求,就可以生成对应的质量规则,免去人工编辑SQL创建规则的时间,提高规则配置效率。
例如,我们输入以下两条补充监控要求:支付宝支付手续费比例不超过 0.6%, 风险评分在 81-100 区间(高风险)的分组中,支付成功状态(SUCCESS)的记录数占该区间总记录数的比例应低于一定阈值(如 10%),对应生成的质量规则:
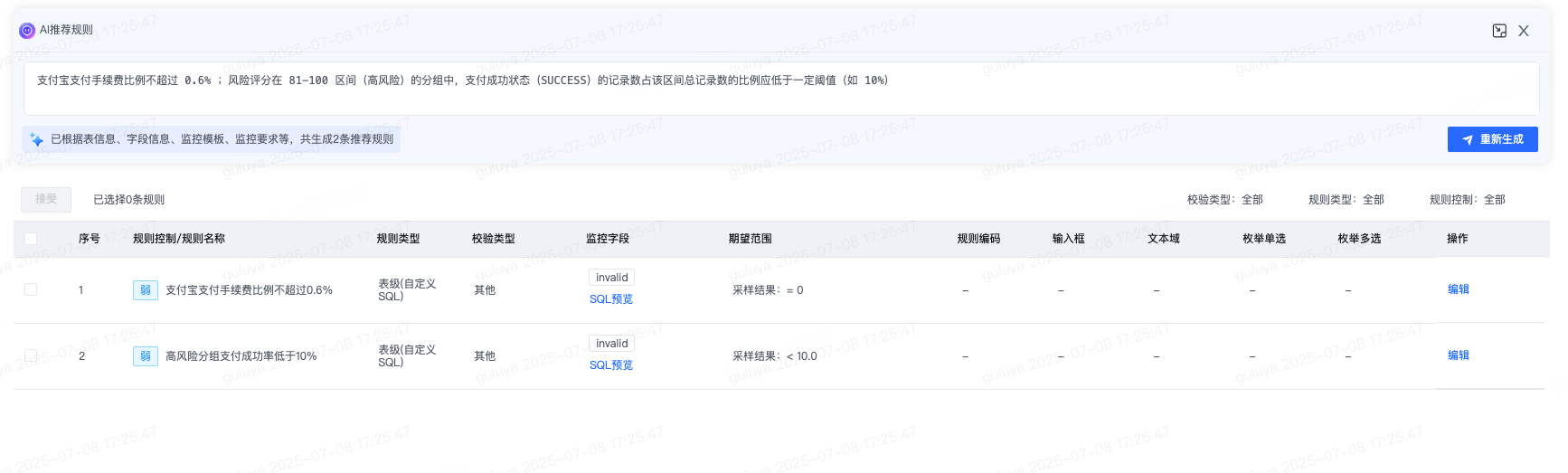
我们来看具体的SQL规则:

这段SQL通过统计指定日期(dt = '${bizdate}')支付宝支付(payment_method = 'ALIPAY')记录中,手续费比例超标的异常记录数量,反映当天支付宝支付中手续费比例超标的数据质量问题规模,监控支付宝支付手续费比例不超过 0.6%。

这段SQL通过计算指定日期(dt = '${bizdate}')内,风险评分在 81 - 100 分(高风险区间)的支付记录中,支付成功的记录所占的比例,以此来判断高风险支付的合理性,监控风险评分在 81-100 区间(高风险)的分组中,支付成功状态(SUCCESS)的记录数占该区间总记录数的比例应低于10%的阈值。

我们可以看到,智能规则推荐依赖于输入,不管是元数据还是补充监控要求,都是依赖模型对文本的理解能力,所以我们建议用户能够遵循一定的规范、将元数据信息尽可能详细地补充完整,最终推荐的效果也将更为理想。

以上就是质量规则智能推荐的相关介绍。未来我们将进一步打通EasyData数据资产,包括将表的产出信息、安全分类分级等内容均作为大模型的分析输入,同时将海量数据开发、数据分析的数据经验,转换为专项垂直大模型的训练数据和经验录入,扩充行业模板库、增强跨表规则推荐能力等方向持续迭代,进一步提升规则生成的精准度与业务适配性,助力企业构建更高效的数据治理体系。
数据质量管控的智能化转型,不仅是技术升级,更是数据治理理念的革新——让数据规则从“人工定义”走向“智能适配”,释放数据价值的同时,降低治理成本,为业务决策提供更可靠的质量保障。
DEMO环境现已开放试用,欢迎联系试用!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)