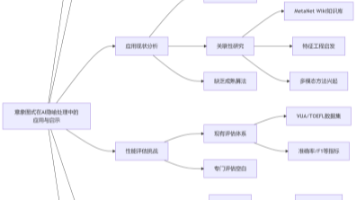
桌面级AI神器,本地大模型助手安装、配置与应用
选择时需考虑硬件配置:8GB内存可运行7B参数模型,16GB以上建议选择13B-20B参数模型。支持在Windows/macOS本地运行开源大模型(如Llama、Mistral),提供图形化界面,适合非技术用户。基于Gradio的Web界面,支持多个开源模型(如Llama、Falcon),提供模型加载、量化、LoRA微调功能。作为本地大模型助手的框架,支持多种开源模型(如 LLaMA、GPT-J
安装本地大模型助手
推荐使用 text-generation-webui 作为本地大模型助手的框架,支持多种开源模型(如 LLaMA、GPT-J 等)。以下为安装步骤:
-
克隆仓库并安装依赖
确保系统已安装 Python 3.10+ 和 Git,随后执行以下命令:git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui pip install -r requirements.txt -
下载模型权重
从 Hugging Face 下载所需模型(如TheBloke/Llama-2-7B-Chat-GGUF),保存至text-generation-webui/models目录。 -
启动 Web UI
运行以下命令启动服务:python server.py --model llama-2-7b-chat.Q4_K_M.gguf --loader llama.cpp
配置模型参数
通过修改 settings.yaml 或命令行参数优化性能:
model_args:
n_ctx: 2048 # 上下文长度
n_gpu_layers: 20 # GPU 加速层数
temperature: 0.7 # 生成温度
功能实现代码示例
1. 基础对话功能
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "models/llama-2-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
def generate_response(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
2. 文件内容处理
def process_file(file_path):
with open(file_path, "r") as f:
text = f.read()
summary_prompt = f"Summarize this text:\n{text}"
return generate_response(summary_prompt)
3. API 服务集成
from fastapi import FastAPI
app = FastAPI()
@app.post("/chat")
async def chat_endpoint(request: dict):
return {"response": generate_response(request["prompt"])}
性能优化建议
- 量化模型:使用 GGUF 格式的 4-bit 量化模型降低显存占用。
- 硬件加速:在
server.py启动时添加--auto-devices参数自动分配 GPU/CPU 资源。 - 批处理:通过
--n_batch 512参数提高吞吐量。
注意事项
- 显存需求:7B 模型约需 6GB 显存(4-bit 量化)。
- 首次运行会触发模型编译,可能耗时较长。
以下是关于桌面级AI神器、本地大模型助手安装、配置与应用的中文文献和技术资源整理,涵盖开源工具、部署指南及实践案例:
开源本地大模型工具推荐
1. LM Studio
支持在Windows/macOS本地运行开源大模型(如Llama、Mistral),提供图形化界面,适合非技术用户。支持GGUF模型量化格式,可直接下载社区预训练模型。
- 官网:https://lmstudio.ai/
- 特性:无需代码、CPU/GPU混合推理、对话历史管理。
2. Ollama
跨平台命令行工具,支持快速部署Llama 2、Gemma等模型,通过简单指令完成模型下载与交互。
- 安装命令:
curl -fsSL https://ollama.com/install.sh | sh ollama run llama2 - 扩展:可通过OpenAI兼容API对接本地应用。
3. Text Generation WebUI
基于Gradio的Web界面,支持多个开源模型(如Llama、Falcon),提供模型加载、量化、LoRA微调功能。
- GitHub仓库:https://github.com/oobabooga/text-generation-webui
- 配置要点:需安装Python依赖,建议使用NVIDIA显卡运行。
本地部署技术指南
1. 硬件要求
- 最低配置:16GB内存(7B参数模型)、NVIDIA GPU(8GB显存)。
- 推荐配置:24GB以上显存(如RTX 3090/4090)运行13B以上模型。
2. 模型量化与优化
- GGUF格式:通过
llama.cpp工具量化模型,降低硬件需求。例如将FP16模型转为4-bit量化:./quantize ./models/llama-2-7b.gguf ./models/llama-2-7b-Q4_K_M.gguf Q4_K_M - vLLM框架:针对高吞吐量场景优化,支持PagedAttention推理加速。
应用场景与案例
1. 个人知识管理
- 使用
PrivateGPT构建本地知识库,支持PDF/TXT文件检索。 - 技术栈:LangChain + Sentence Transformers嵌入模型。
2. 自动化办公
- ChatGLM3-6B:通过API集成到Excel/WPS,实现表格数据智能处理。
- 示例代码(Python调用本地模型):
from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True) model = AutoModel.from_pretrained("local_model_path", device='cuda').eval() response, history = model.chat(tokenizer, "如何总结这篇文档?", history=[])
中文技术文献与社区
-
《开源大模型本地部署实战》(电子工业出版社,2023)
- 涵盖Llama、ChatGLM的详细部署步骤与性能调优。
-
知乎专栏「本地化AI实践」
- 主题:低成本显卡推理方案、模型微调实战。
-
B站视频教程
- 搜索关键词:“RTX 4090本地大模型”、“Ollama中文教程”。
注:部分工具需自行处理网络访问限制问题。建议优先选择支持GGUF/GPTQ量化格式的模型以减少资源占用。
桌面级AI神器:本地大模型助手安装、配置与应用技术大纲
硬件与软件环境准备
- 硬件要求:明确最低配置(如CPU、GPU、内存、存储空间),推荐配置(如NVIDIA显卡型号、显存需求)。
- 操作系统兼容性:支持Windows/macOS/Linux的版本及依赖项(如CUDA、Python版本)。
- 预备工具:Git、Docker、Python虚拟环境等工具的安装与配置。
本地大模型选择与下载
- 模型选型对比:列举主流开源模型(如Llama 2、Falcon、Mistral)的特点与适用场景。
- 模型下载渠道:Hugging Face、官方GitHub仓库的下载步骤与权限申请(如需)。
- 权重文件管理:模型文件的存储路径与版本控制建议。
安装与依赖配置
- 框架部署:Ollama、Text-generation-webui或本地化Hugging Face环境的安装命令。
- 依赖库安装:通过
pip或conda安装PyTorch、Transformers等关键库的代码示例。 - 环境变量设置:配置GPU加速(如CUDA_HOME)与模型路径的注意事项。
模型初始化与参数调优
- 启动脚本编写:加载模型的Python示例代码(如
AutoModelForCausalLM.from_pretrained)。 - 关键参数调整:温度(temperature)、top-p采样、最大生成长度的作用与推荐值。
- 性能优化:量化(4-bit/8-bit)、LoRA微调等技术的应用场景与实现方法。
应用场景与实战案例
- 交互式对话:通过命令行或Web界面(如Gradio)实现问答与文本生成。
- 自动化任务集成:调用API处理文档摘要、代码生成等任务的代码片段。
- 插件扩展:支持LangChain、AutoGPT等工具的插件配置与案例演示。
常见问题排查
- 显存不足处理:降低批次大小(batch size)或启用内存交换的解决方案。
- 依赖冲突修复:虚拟环境重建与版本回退的具体操作。
- 模型兼容性错误:检查架构(如GGML与GPTQ格式)匹配性的调试步骤。
进阶优化与安全建议
- 持续学习:本地数据微调(Fine-tuning)的流程与数据准备建议。
- 隐私保护:离线运行的隐私优势与敏感数据过滤方案。
- 性能监控:使用
nvidia-smi或日志分析工具跟踪资源占用情况。
(注:大纲可根据具体模型或工具链调整细节,如侧重CPU推理或多模态扩展。)
本地大模型助手的选择
目前主流的桌面级AI工具包括Llama 3、Mistral、Gemini Nano等开源模型。Llama 3由Meta推出,提供8B和70B参数版本;Mistral 7B以高效著称;Gemini Nano是谷歌推出的轻量级模型。选择时需考虑硬件配置:8GB内存可运行7B参数模型,16GB以上建议选择13B-20B参数模型。
硬件要求与优化
最低配置需要4核CPU、8GB内存和NVIDIA GTX 1060显卡。推荐配置为6核CPU、32GB内存及RTX 3060以上显卡。使用量化技术可将模型内存占用降低4-8倍,例如GGUF格式的4-bit量化模型。Mac用户可通过Metal加速,AMD显卡需使用ROCm框架。
安装部署流程
Windows用户推荐使用Ollama或LM Studio一键安装。Linux环境下可通过Text Generation Webui部署:
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt
下载模型权重后放入指定文件夹,例如Llama 3的8B模型约需15GB存储空间。启动命令:
python server.py --model llama-3-8b --load-in-4bit
参数配置技巧
关键启动参数包括:
--max_seq_len 2048控制上下文长度--temperature 0.7调节输出随机性--gpu-memory 12为显卡分配显存
配置文件launch-config.json示例:
{
"model": "mistral-7b-instruct",
"quant": "q4_k_m",
"ctx_len": 4096,
"n_gpu_layers": 32
}
应用场景实践
文档处理可使用RAG架构:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("report.pdf")
docs = loader.load_and_split()
代码辅助开发配置:
// VS Code设置
"ai.codeCompletion": {
"modelPath": "./models/codellama-13b",
"temperature": 0.2,
"maxTokens": 128
}
性能监控与调优
使用nvidia-smi监控显存占用,Windows任务管理器可观察CPU负载。当响应延迟过高时,可尝试:
- 启用
--batch-size 8提高吞吐量 - 使用
--threads 4增加CPU解码线程 - 添加
--flash-attention优化注意力机制
日志文件中OOM错误通常需要降低--gpu-memory值或改用更低量化级别的模型。
https://www.jianshu.com/p/f73f7aad0ece
https://www.jianshu.com/p/69554d44795e
https://www.jianshu.com/p/3e4d5af23854
https://www.jianshu.com/p/3e328617891c
https://www.jianshu.com/p/de3d4f225aee
https://www.jianshu.com/p/e122265162b9
https://www.jianshu.com/p/fe049dfe4d09
https://www.jianshu.com/p/ba00cdfbdb59
https://www.jianshu.com/p/91f05ecd2c9c
https://www.jianshu.com/p/d5172a4896c7
https://www.jianshu.com/p/79e649732dec
https://www.jianshu.com/p/df9fa18477f7
https://www.jianshu.com/p/8c195e739636?v=1758028874057
https://www.jianshu.com/p/9cad4290b879?v=1758028940696
https://www.jianshu.com/p/a9636a1e24a0?v=1758029659652
https://www.jianshu.com/p/e51944b96f94?v=1758030025271
https://www.jianshu.com/p/69b29a1f7649?v=1758030329807
https://www.jianshu.com/p/b2eca80a88ff?v=1758030226998
https://www.jianshu.com/p/ff4f3ce523bf?v=1758030845128
https://www.jianshu.com/p/44dbc20f5d40?v=1758030775938
https://www.jianshu.com/p/8c195e739636
https://www.jianshu.com/p/9cad4290b879
https://www.jianshu.com/p/a9636a1e24a0
https://www.jianshu.com/p/e51944b96f94
https://www.jianshu.com/p/69b29a1f7649
https://www.jianshu.com/p/b2eca80a88ff
https://www.jianshu.com/p/ff4f3ce523bf
https://www.jianshu.com/p/44dbc20f5d40

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)