解决大模型幻觉全攻略:理论、技术与落地实践
大模型幻觉问题是指AI生成与事实不符或虚构信息的现象,在医疗、金融等高敏场景可能造成严重后果。文章分析其四大成因:数据噪声、微调过拟合、奖励设计缺陷及推理缺陷,并分类为事实冲突、虚构内容等类型。提出检索增强生成(RAG)和黑白盒检测两大解决方案,通过外部知识库和概率分析等技术降低42%幻觉风险。建议企业全生命周期防控,结合数据清洗、诚实样本和多模态检测等措施。该问题是大模型本质特性衍生的核心挑战,
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI算法学习视频及资料,尽在 聚客AI学院。
随着大模型迅猛发展的浪潮中,幻觉(Hallucination)问题逐渐成为业界和学术界关注的焦点。所谓模型幻觉,指的是模型在生成内容时产生与事实不符、虚构或误导性的信息。因此,如何识别、抑制甚至消除幻觉,已经成为亟待解决的重要课题。今天我们就来深入解析探讨大模型为什么出现幻觉?从成因到缓解方案。欢迎交流指正。
一、幻觉问题定义与影响
定义:大模型生成与事实不符、虚构或误导性信息。
典型案例:
- 事实冲突:称“亚马逊河位于非洲”(实际在南美洲)
- 无中生有:虚构房源楼层信息(如“4楼,共7层”)
- 指令误解:将翻译指令误答为事实提问
- 逻辑错误:解方程
2x+3=11时得出错误结果x=3
风险:在医疗、金融、法律等高敏场景中,幻觉可能导致决策错误、法律纠纷及品牌声誉损害。
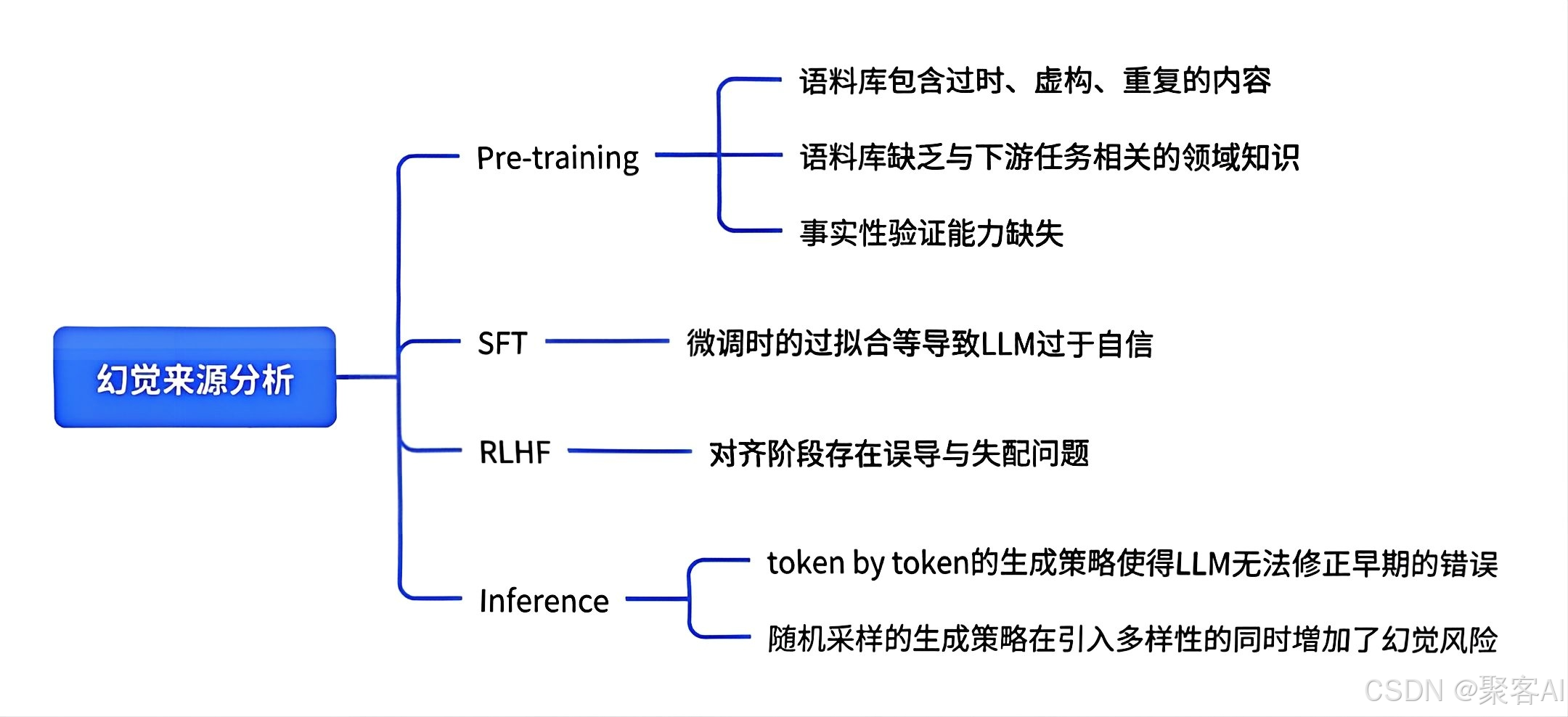
二、幻觉成因与分类
2.1成因分析
| 阶段 | 核心问题 |
|---|---|
| 预训练 | 数据噪声、领域知识稀疏、事实性验证能力缺失 |
| 有监督微调(SFT) | 标注错误、过拟合导致对错误知识过度自信 |
| RLHF对齐 | 奖励设计缺陷使模型为迎合目标牺牲真实性 |
| 推理部署 | Token级生成无法修正早期错误;随机采样增加风险 |
2.2分类体系
| 类型 | 特征 | 示例 |
|---|---|---|
| 事实冲突 | 与客观知识矛盾 | “亚马逊河位于非洲” |
| 无中生有 | 虚构无法验证的内容 | 补充未提供的房源楼层信息 |
| 指令误解 | 偏离用户意图 | 将翻译指令回答为事实陈述 |
| 逻辑错误 | 推理过程漏洞 | 解方程步骤正确但结果错误 |
三、企业级解决方案
1. 检索增强生成(RAG)
原理:将“闭卷考试”转为“开卷考试”,通过外部知识库(数据库/文档)提供实时依据。
价值:
- 突破模型参数化知识边界
- 提升时效性与领域适应性(如企业内部政策库)
局限:知识冲突、信息缺失时仍可能产生幻觉。
ps:关于RAG检索增强生成的相关优化技术,我之前也讲了很多,这里由于文章篇幅有限,建议粉丝朋友自行查阅:《检索增强生成(RAG)》
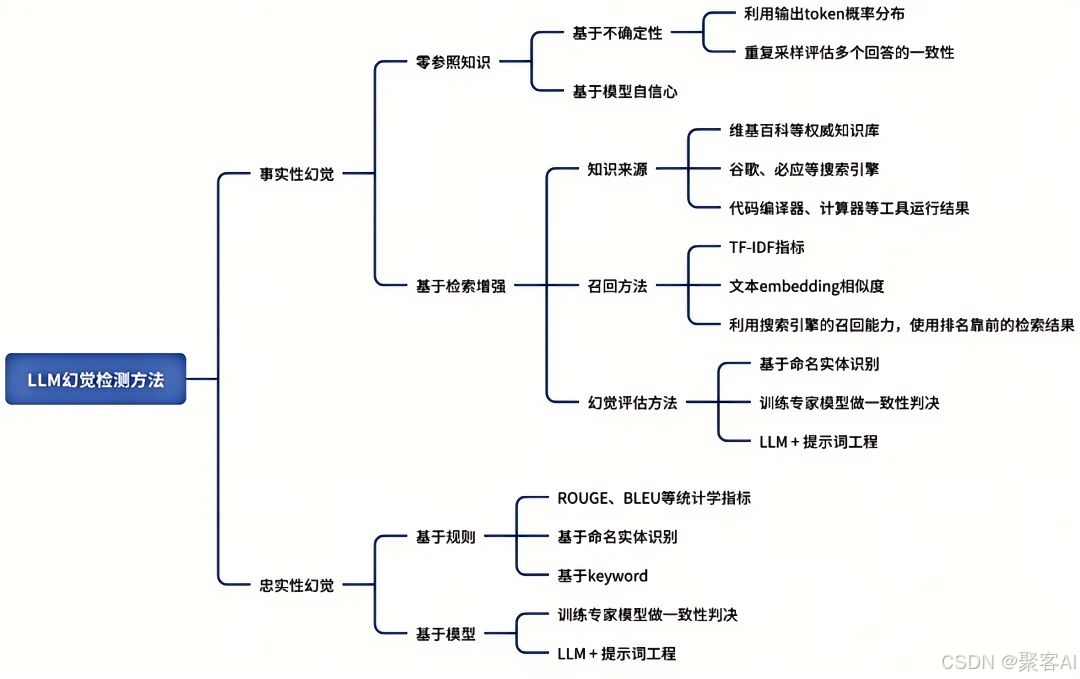
2. 后验幻觉检测
(1)白盒方案(需模型访问权限)
- 不确定性度量:提取生成内容关键概念,计算token概率(概率越低风险越高)
- 注意力机制分析: Lookback Ratio=对新生成内容的注意力对上下文的注意力
比值越低表明幻觉风险越高
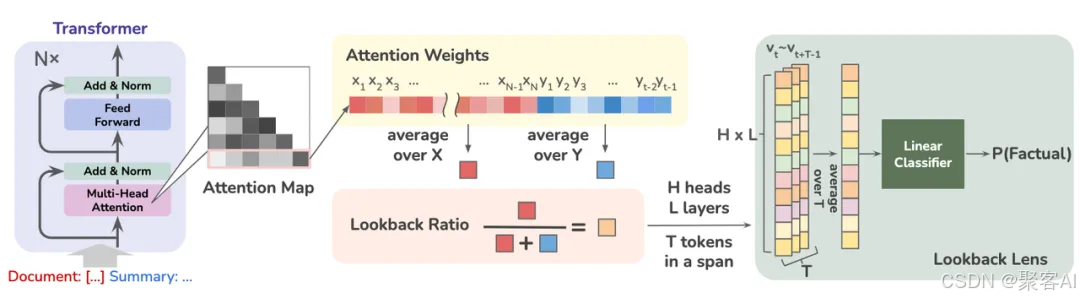
图示:Lookback Ratio: 基于上下文与生成内容注意力分配比例的白盒检测方案
- 隐藏状态分析:正确内容对应低熵值激活模式,错误内容呈现高熵值模糊模式
(2)黑盒方案(仅API调用)
采样一致性检测:同一问题多次生成,输出不一致则标识幻觉风险
规则引擎:
-
- ROUGE/BLEU指标对比生成内容与知识源重叠度
- 命名实体验证(未出现在知识源中的实体视为风险)
工具增强验证:
- 拆解回答为原子陈述
- 调用搜索引擎/知识库验证
- 集成计算器、代码执行器等工具实现多模态校验[12-14]
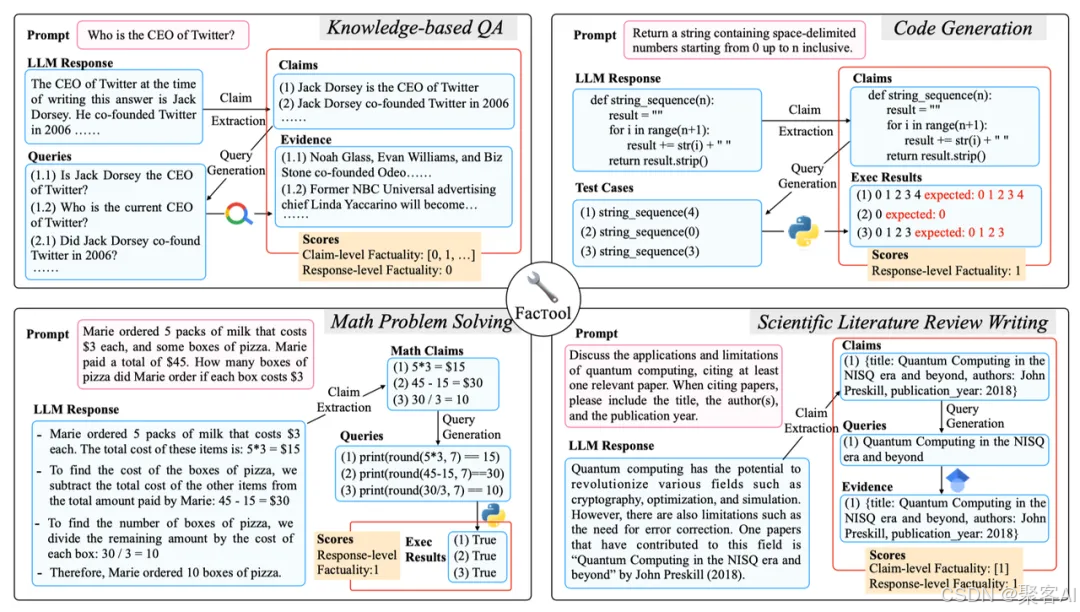
图示:基于外部知识/工具增强的黑盒检测方案
专家模型检测:
- 训练AlignScore模型评估生成内容与知识源对齐度
- 幻觉批判模型(Critique Model)提供可解释性证据
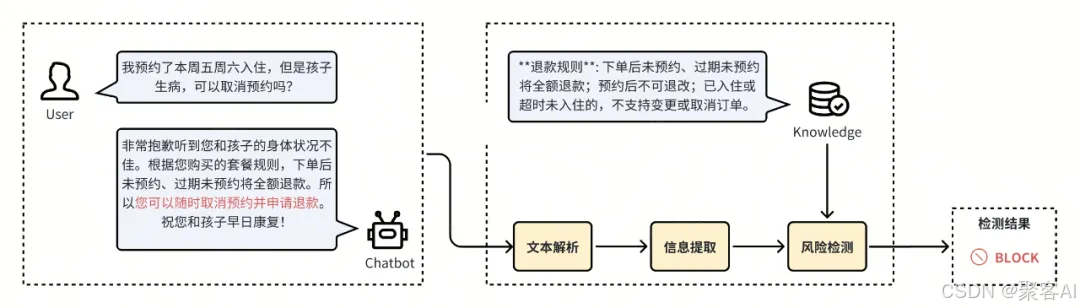
四、客服、广告等多个业务场景实践
方案架构:
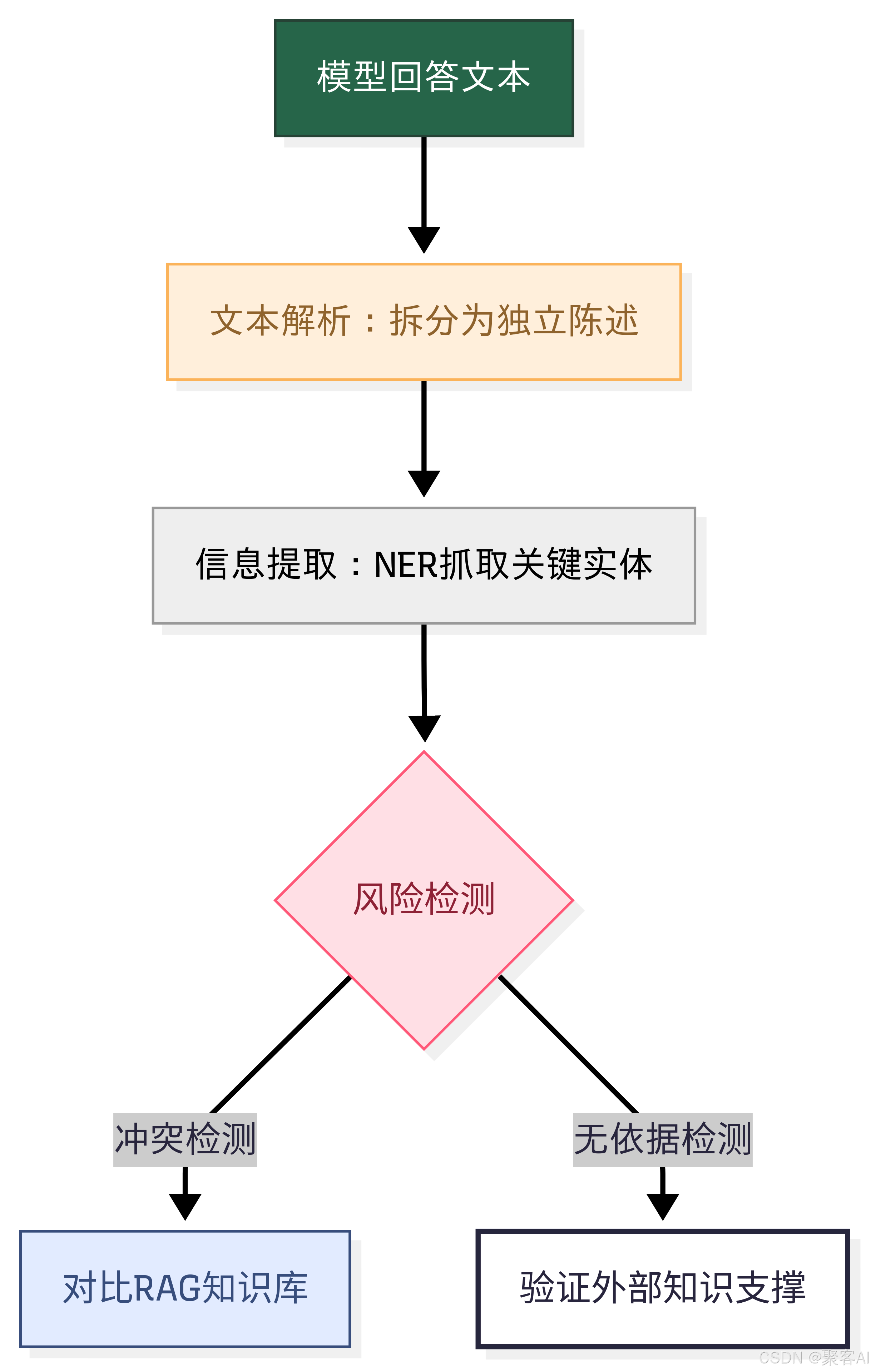
落地效果:在客服、广告场景中降低幻觉风险率42%,误报率<8%。
五、笔者总结
核心认知:幻觉是LLM本质特性(概率生成模型)的衍生问题,需贯穿全生命周期防控。
企业行动建议:
- 预训练阶段强化数据清洗与去重
- 微调引入“诚实样本”增强不确定性表达
- 部署阶段结合RAG+多模态检测流水线
好了,今天的分享就到这里,点个小红心,我们下期见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)