真正懂rag的人不是只懂个流程,而是懂微观工程细节的人!大模型入门到精通,收藏这篇就足够了!
本文也算是自己对RAG的一个整体回顾了,后面的文章将逐项进行分享与大家探讨Know-How,共同进步。
做 RAG(Retrieval-Augmented Generation)系统,不是把几个组件名堆在一起,而是要把每一层的工程细节、判断标准和常见坑都讲清楚。下面按你给出的 10 个模块逐条讲清楚:原理说清、工程要点讲透、给出实操建议和可复制的小技巧,读完你能直接把这些内容交给研发去落地、交给产品去验收、交给业务去评估效果。本文也算是自己对RAG的一个整体回顾了,后面的文章将逐项进行分享与大家探讨Know-How,共同进步。
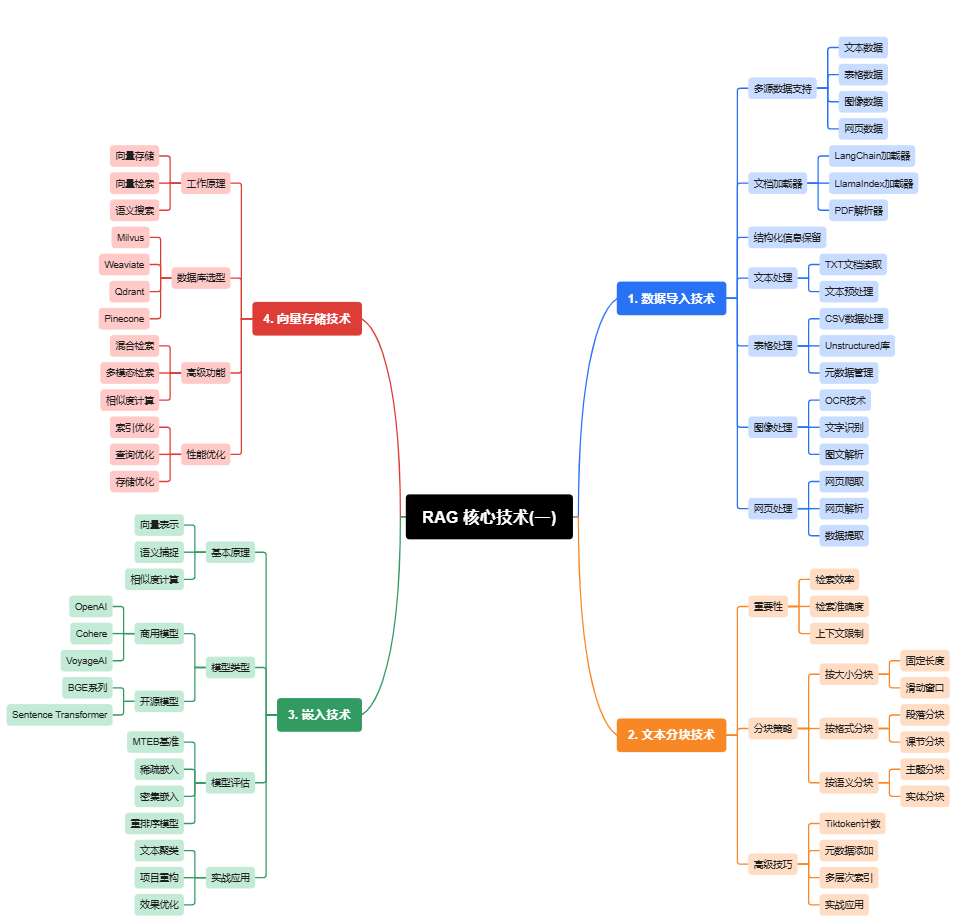
一、数据导入技术
数据质量与结构化程度决定了后续检索的下限;导入不是一次性工作,而是持续的 ETL+治理流程。
- 为什么要关注多源数据支持
- 文本:文档的段落/章节结构是语义完整性的基础,直接影响分块与检索效果。
- 表格:表格适合用结构化查询(SQL)处理,检索时应保留列名与类型。
- 图像:含文字(票据、流程图)必须先做 OCR;图中结构(表格边界、标题)很关键。
- 网页:需抓取渲染后内容并剔除噪声(广告、脚本),对时间敏感页面需记录抓取时间。
- 文档加载器实践
- 使用成熟 Loader(如 LangChain、LlamaIndex)快速接入,但不要把它当“黑盒”——检查 Loader 抽取出的段落边界与元数据。
- 复杂 PDF:优先保留页面结构(页眉/页脚/表格),否则表格会被展平成无序文本。常见做法是先做版面分析再做 OCR。
- 结构化信息保留
- 每条入库文本都应带元数据(来源、时间、作者、文档类型、页码/行号、可信度)。这些字段对路由、排序、审计非常重要。
- 具体技术要点(实操清单)
- 文本读取:统一编码、去除无关空白、保留段落分隔符。
- 表格处理:保留列名与数据类型;对数字列做单位标准化。
- 元数据管理:自动抽取 + 支持人工补充/修正(例如手工标注重要级别)。
- 图像处理:先高分辨率 OCR,再做版面分块(区分标题/正文/表格)。
- 网页处理:用 headless 浏览器抓取渲染后的 DOM,去除广告框并记录抓取快照。
- 图文解析:将图片中的结构化信息转成表格或键值对,打标签后入库。
把“可重跑、可回溯、可审计”作为数据导入的基本需求:记录数据版本、导入时间与变更记录。
二、文本分块技术
分块是平衡上下文完整性与检索效率的关键,策略要和业务查询类型绑定。
- 为什么很重要
- 粒度太大:检索时命中不精确,浪费 token。
- 粒度太小:语义被拆散、答案不完整。
- 分块策略(工程化思路)
- 按大小:固定长度(例如 400–800 token)或滑动窗口(重叠 10–30%)。对法律/白皮书类长文本效果好。
- 按格式:直接用文档的段落/章节边界分块,适合结构化文档。
- 按语义:先用聚类或主题模型划分语义段,适合内容混杂的知识库。
- 高级技巧
- 用 tiktoken 或等效工具估算 token 数量,按目标 LLM 窗口调整块大小。
- 每个块附带元数据(文档 ID、页码、主题标签、可信度)。
- 建多层索引:短句层(高召回)、段落层(平衡)、文档层(整体一致性)。检索流程从粗到细逐层筛选。
对金融/法律等要求精确的领域,优先按章节分块并在块内保留引用/编号;对 FAQ 类短文本采用句子/短段分块,配合重排提升准确率。
三、嵌入技术
嵌入决定了“语义能否被正确表示”,模型选型与评估要以具体业务查询为准。
- 基本原理:把文本映射为向量,向量间距离反应语义相似度。
- 模型类型:
- 商用:OpenAI、Cohere、VoyageAI——优点:效果稳、更新快;缺点:成本/合规需评估。
- 开源:BGE、Sentence-Transformers——优点:可本地化、成本可控;缺点:需要运维与评估。
- 评估与选择:
- 使用 MTEB 等通用基准做初筛,但必须用业务样本做上线前验证(离线召回/精排对比)。
- 注意稀疏嵌入(更像词表索引)和密集嵌入(向量)各自优势,混合策略常能取得更好结果。
- 在召回后使用 CrossEncoder 做精排可显著提升精度,但会增加延迟与成本。
- 实战应用:嵌入用于聚类、相似文档查找、冷启动分类等;在成本敏感的场景可以把商用嵌入用于离线 batch 更新、开源模型用于在线微调。
- 实践小贴士:做 A/B 测试时把“检索召回质量”“生成下游准确性”“资源消耗”三个维度同时考量。
四、向量存储和索引技术
合适的向量库与索引结构是保证检索速度与可扩展性的基础工程选择。
- 工作原理:向量 + 元数据存储 → ANN 索引用于快速近似检索。
- 主流选型:Milvus(企业级、分布式)、Weaviate(语义与图谱结合)、Qdrant(轻量、低延迟)。选型时关注:吞吐、复制/备份、查询延迟、过滤器支持。
- 高级应用:
- 混合检索(BM25 + ANN):先关键词召回,再语义精排。
- 多模态检索:图像/文本投影到同一空间或做跨模态匹配层。
- 性能优化:
- 调索引参数(HNSW ef、IVF nprobe 等),做离线参数扫描。
- 维度压缩(PQ/OPQ)在存储受限时降低成本,但要评估精度损失。
- 使用 metadata filters 减少 ANN 检索范围(例如按业务线/时间区间过滤)。
先在小数据集上评估索引配置与延迟曲线,再做分区/分片策略。生产环境应有索引重建与版本回滚机制。
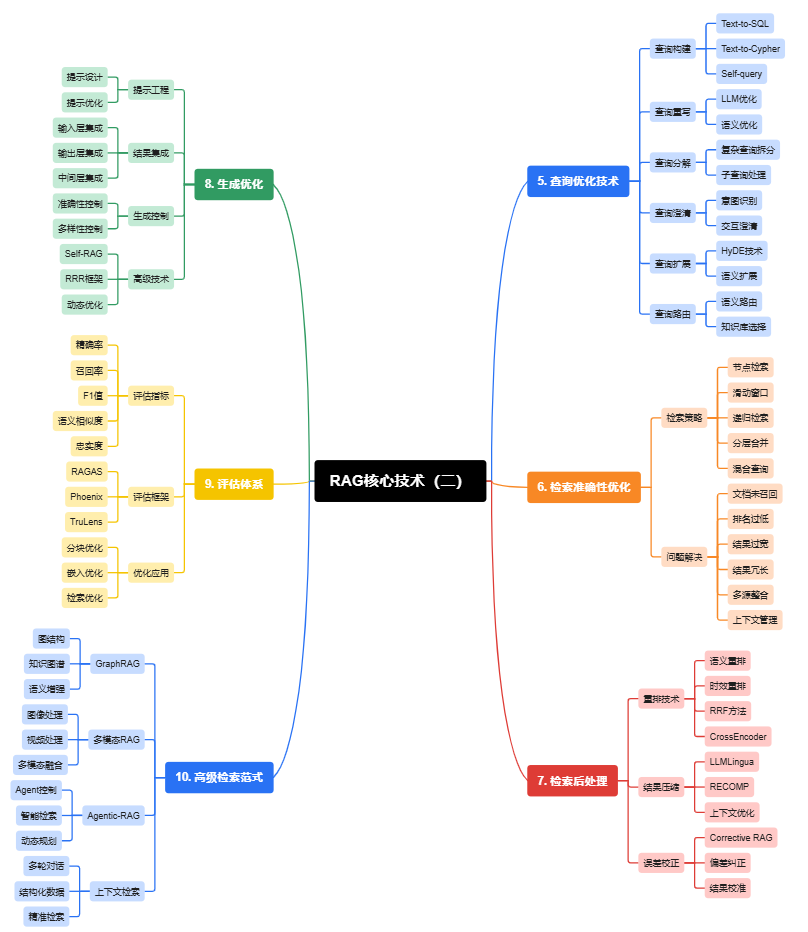
五、预检索—查询优化技术
优质查询是拿到关键证据的第一步;“翻译用户意图”比盲目检索更重要。
- 查询构建方法:
- Text-to-SQL:把自然语言转为结构化数据库查询,适合表格/报表型知识源。
- Text-to-Cypher:适合图谱查询(关系链检索)。
- Self-query Retriever:模型自己生成检索过滤器与关键词,适合复杂语义场景。
- 查询优化技巧:
- 查询重写:用 LLM 将口语查询转换为清晰的检索语句(消歧、补全实体)。
- 查询分解:把复杂问题拆成多个子问题分别检索然后合并答案。
- 查询澄清:对歧义问题进行简短交互式澄清,避免错误检索。
- 查询扩展(增强召回):HyDE(用 LLM 生成“假设文档”并嵌入到索引)能扩展语义覆盖。
- 查询路由:根据问题主题或元数据把检索请求路由到最可能命中的知识库(例如把合同类问题路由到法律知识库)。
- 工程化建议:对高频问题预设 Query Template;对低命中率问题启用交互式澄清或查询分解流程。
六、提升检索准确性方法
准确率来自多层策略的组合,而不是单一模型的提升。
- 检索策略组合:
- 从小到大:先在短句级别检索,再扩展到段落、文档。
- 滑动窗口:对长文档使用重叠窗口保证上下文连续。
- RecursiveRetriever:粗检索→在候选中精检索。
- 分层合并:把相关短片段合并为更完整的“证据段”供生成模型用。
- 混合查询:并行关键词与语义检索后合并结果。
- 常见问题与解决路径:
- 关键文档没检索到:检查分块规则、metadata filter、索引是否包含该文档。
- 文档排名低:引入时效性/来源可信度权重,或用 CrossEncoder 重排。
- 结果过于宽泛或冗长:用摘要/压缩策略,或拆解查询以缩小范围。
- 多源知识冲突:在结果中标注来源并在生成端做冲突检测与回溯。
把检索策略参数化(例如召回阈值、合并策略),在不同场景按策略开关调优。
七、检索后处理技术
检索只是第一步,后处理(重排、压缩、校正)决定最终给用户的质量。
- 重排(提高相关性):
- 用 RRF(Reciprocal Rank Fusion)合并不同检索器结果。
- 在召回集合上使用 CrossEncoder 做精排,优化最终段落的相关性。
- 压缩(控制上下文成本):
- 把多文档压缩为关键句或条目式摘要,减少 token 占用。
- 可以用 LLM 做抽取或用专门的压缩模型(如 RECOMP 思路)。
- 校正(提高可信度):
- 对关键事实做知识库反查或二次验证,检测并标注冲突或低可信答案。
- Corrective RAG:生成后回检并在必要时触发二次检索或澄清。
输出中附带证据引用(source、snippet、可信度),便于用户核验并减少误导。
八、生成过程技术
生成要有“可控的流程”——提示、结构化输出、验证回路三管齐下。
- 提示设计:
- 明确回答角色、格式与限制(长度、是否引用、是否给出建议)。
- 在 prompt 中加入“检验步骤”或“核事实”要求,降低幻觉概率。
- 结果规范化:
- 强制输出结构(JSON schema、字段约束),便于自动化解析与后续校验。
- 内容控制:
- 关键场景(合规/财务/法律)使用低 temperature 并启用事实校验环节。
- 检索结果集成方式:
- 输入层集成:把检索片段拼接到 prompt(简单但 token 占用大)。
- 中间层集成:先让模型把片段摘要化,再用摘要生成最终答案(兼顾准确与成本)。
- 输出层集成:生成后再用检索结果做一致性验证与修正。
- 高级模式:Self-RAG(循环式自检)、RRR(反复优化检索与提示)在高可靠场景非常有效。
- 实施建议:对高风险回复采用“中间层+验证回路”,并在输出中附带“证据片段 + 置信度”。
九、评估检索结果技术
没有评估就没有改进;评估要覆盖检索、生成和用户价值三层。
- 评估指标:
- 检索层:Precision、Recall、MRR(平均排名)。
- 生成层:语义相似度、faithfulness(忠实度)、用户解决率(是否解决问题)。
- 评估框架与工具:RAGAS、Phoenix、TruLens 等可以做端到端评估与监控。
- 结果用法:把评估结果用来优化分块、替换嵌入模型、调整索引参数和优化重排策略。
- 实践技巧:建立回归测试集(真实用户问题+人工标注答案),每次改动必跑回归并记录变更影响。
线上引入小比例 A/B 测试并结合离线评测,关注回归风险和边缘场景失败率。
十、复杂检索策略和范式
核心结论:面对复杂业务需求,单一检索模式不足,需组合图谱、多模态、Agent 等能力。
- 高级检索技术:
- GraphRAG:把实体关系图与向量检索结合,用实体路径增强上下文。
- Contextual Retrieval:检索时考虑会话上下文、用户画像、历史交互。
- 前沿方向:
- 多模态 RAG:把图像、视频和文本统一检索/生成,关键是跨模态对齐和时间同步。
- Agentic-RAG:用 agent 寻找最优检索路径(例如跨多个知识库调度检索并做策略选择)。
- 动态检索路径规划:基于查询难度动态决定检索深度、是否分解、何时做澄清。
先做单模态或混合小规模 PoC(例如把图像 OCR+文本索引打通),验证跨模态召回与精排策略,再逐步引入图谱与 agent 路由。
十一、总结
不要把 RAG 当成“黑盒白盒”的魔法组合。把上面的每一项做成独立可观测的模块,每个模块都有清晰的输入/输出/监控/回滚点。给你一份最小可交付(MVP)清单,便于快速上线并可持续迭代:
- 明确数据源与元数据规范并实现可回溯的导入流水线。
- 建分块策略(章节优先 + 滑动窗口),并记录 token 估算规则。
- 选定并 benchmark 嵌入模型(离线与在线样本)。
- 选向量库并验证索引延迟/召回质量与过滤支持。
- 设计 Query 构建与澄清流程(模板化并可交互)。
- 实装检索后重排(CrossEncoder/RRF)与压缩策略。
- 对生成动作强制输出 schema 并加入事实验证回路。
- 建评估体系(回归集 + 在线 A/B + 指标监控)。
- 在关键场景显示证据并标注可信度。
- 先做单模态稳定,再逐步引入图谱/多模态/Agent 能力。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献298条内容
已为社区贡献298条内容

所有评论(0)