五大I/O模型全景解析:从阻塞到异步的进化之路
💡核心洞见I/O模型决定程序并发能力的天花板多路复用是当前高并发系统的黄金标准异步I/O+协程是未来发展方向io_uring代表Linux I/O的最新进化选择模型需平衡性能与开发成本思考题:为什么Redis使用单线程却能支持超高并发?评论区分享你的见解!🚀动手实验# 安装: pip install asyncio aiohttp# 同时发起100个请求理解I/O模型,你就掌握了高性能编程的核
·
当你的程序等待网络响应时,CPU是在"摸鱼"还是高效工作?为什么高并发服务器能同时处理数万连接?这一切都归功于I/O模型的巧妙设计——程序与外部世界沟通的艺术!
一、I/O模型:程序与世界的沟通策略
想象快递站取快递:
- 🧍 阻塞式:排队等待叫号(干等)
- 🔁 非阻塞式:不断询问"到了吗?"
- 📺 多路复用:一个大屏幕显示所有包裹状态
- 📢 信号驱动:短信通知取件
- 🤖 异步式:委托代取,送货上门

二、五大I/O模型详解
1. 阻塞I/O(Blocking I/O):排队等待型
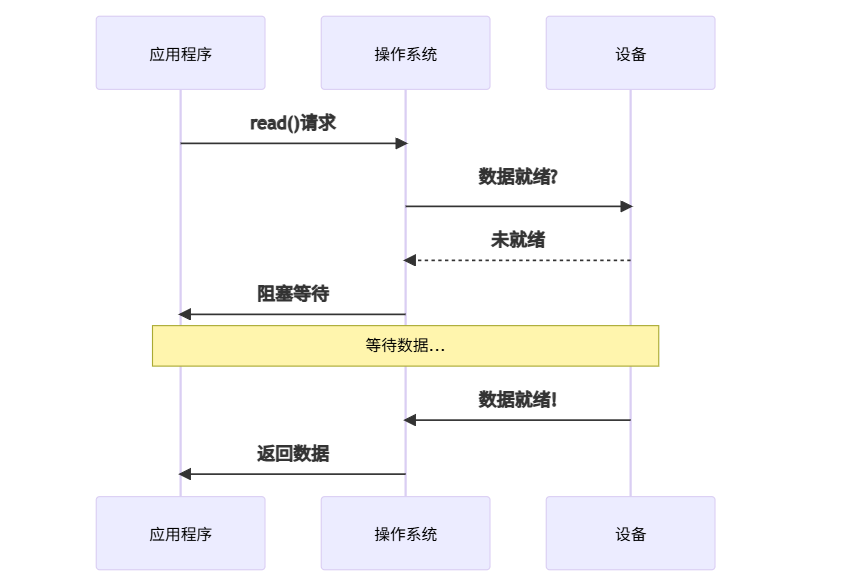
特点:
- ✅ 编程简单
- ❌ 资源利用率低
- ❌ 无法处理高并发
代码示例(C):
int sock = socket(AF_INET, SOCK_STREAM, 0);
connect(sock, &addr, sizeof(addr));
char buf[1024];
int n = read(sock, buf, sizeof(buf)); // 程序卡在这里等待
printf("收到%d字节数据\n", n);
2. 非阻塞I/O(Non-blocking I/O):轮询检查型
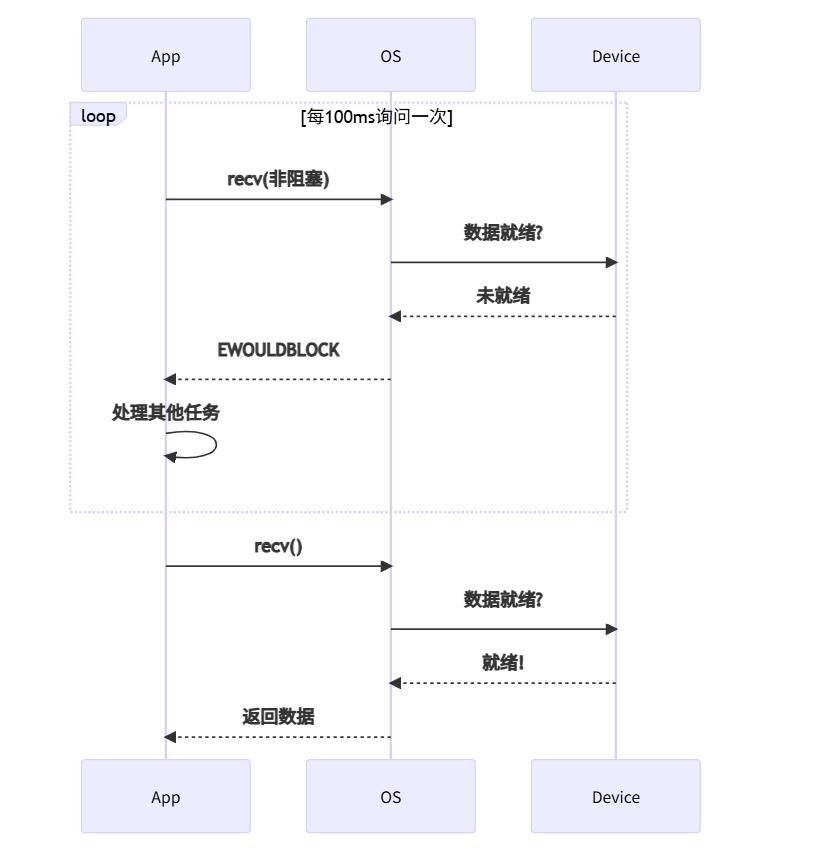
特点:
- ✅ CPU不空闲
- ❌ 轮询消耗CPU资源
- ❌ 响应延迟高
代码示例(Python):
sock.setblocking(False) # 设置为非阻塞
while True:
try:
data = sock.recv(1024)
if data:
print(f"收到数据: {data}")
break
except BlockingIOError:
print("数据未就绪,处理其他任务...")
do_other_work()
time.sleep(0.1) # 避免CPU满载
3. I/O多路复用(I/O Multiplexing):监控大屏型
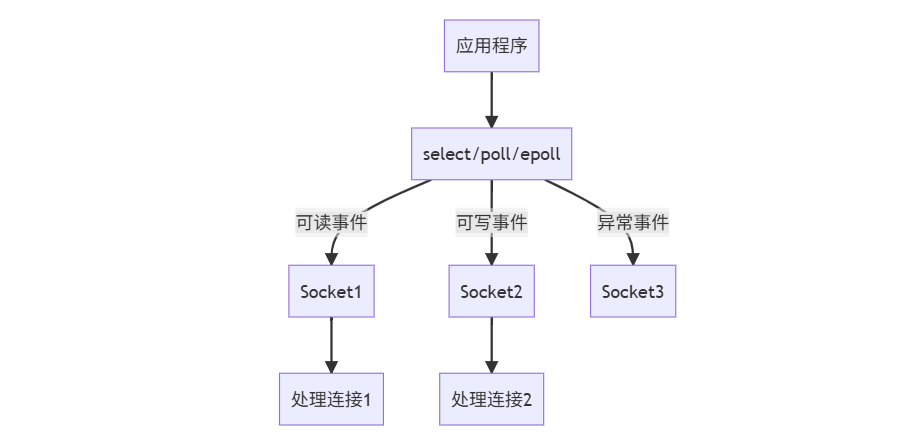
工作流程:

epoll代码示例(C):
int epfd = epoll_create1(0);
struct epoll_event ev, events[MAX_EVENTS];
ev.events = EPOLLIN;
ev.data.fd = sockfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &ev);
while(1) {
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
for(int i = 0; i < nfds; i++) {
if(events[i].data.fd == sockfd) {
handle_connection(); // 处理I/O
}
}
}
4. 信号驱动I/O(Signal-driven I/O):通知提醒型
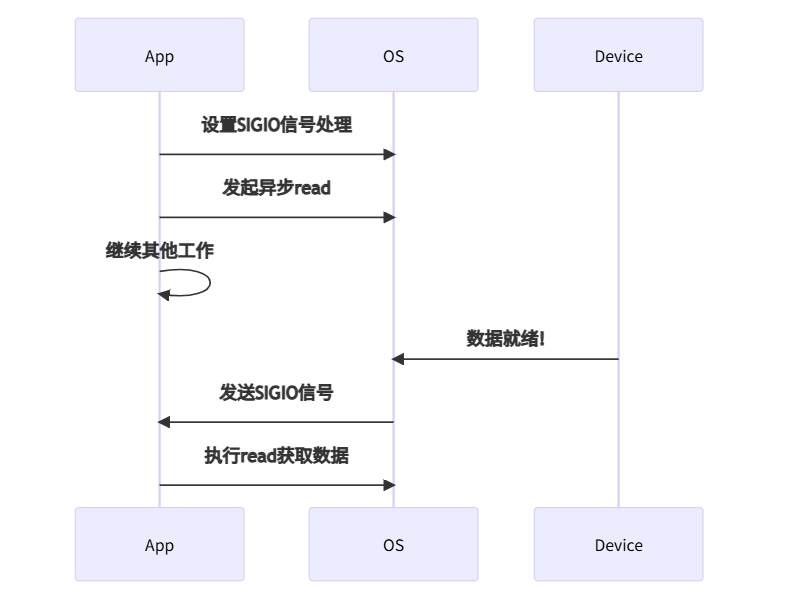
特点:
- ✅ 无轮询开销
- ❌ 信号处理复杂
- ❌ 兼容性问题
代码示例:
void handler(int sig) {
// 信号处理函数中读取数据
char buf[1024];
read(sockfd, buf, sizeof(buf));
}
int main() {
signal(SIGIO, handler); // 注册信号处理
fcntl(sockfd, F_SETOWN, getpid());
fcntl(sockfd, F_SETFL, FASYNC); // 启用信号驱动
while(1); // 主循环
}
5. 异步I/O(Asynchronous I/O):委托代理型
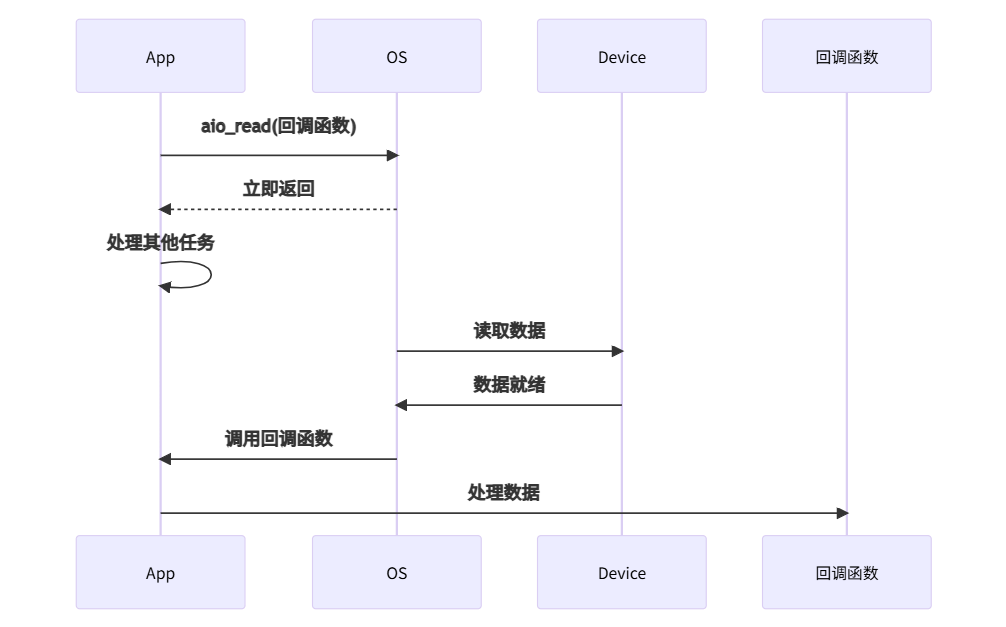
特点:
- ✅ 真正的异步
- ✅ 资源利用率最高
- ❌ 编程复杂度高
代码示例(Python asyncio):
import asyncio
async def fetch_data():
reader, writer = await asyncio.open_connection('example.com', 80)
writer.write(b'GET / HTTP/1.1\r\nHost: example.com\r\n\r\n')
await writer.drain() # 异步等待发送完成
data = await reader.read(1024) # 异步等待数据
print(f"收到数据: {data[:100]}")
writer.close()
asyncio.run(fetch_data())
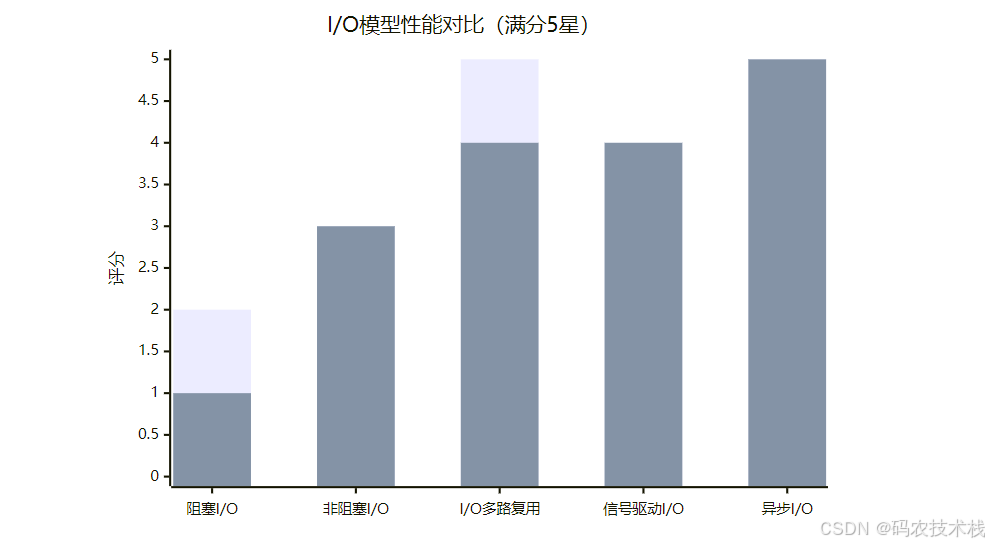
三、五大模型性能对比
| 模型 | 响应速度 | CPU利用率 | 编程复杂度 | 适用场景 |
|---|---|---|---|---|
| 阻塞I/O | ⭐ | ⭐ | ⭐ | 低并发简单应用 |
| 非阻塞I/O | ⭐⭐ | ⭐⭐ | ⭐⭐ | 中并发实时系统 |
| I/O多路复用 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 高并发网络服务 |
| 信号驱动I/O | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 专业嵌入式系统 |
| 异步I/O | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 超高并发云服务 |
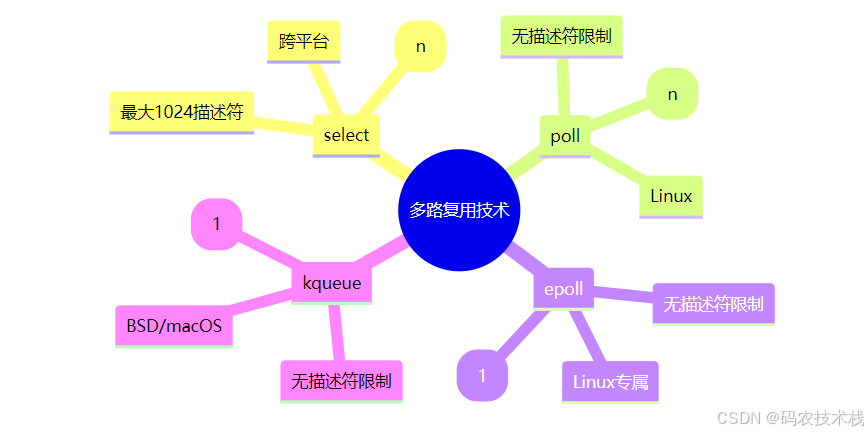
四、I/O多路复用技术详解
1. select/poll vs epoll/kqueue
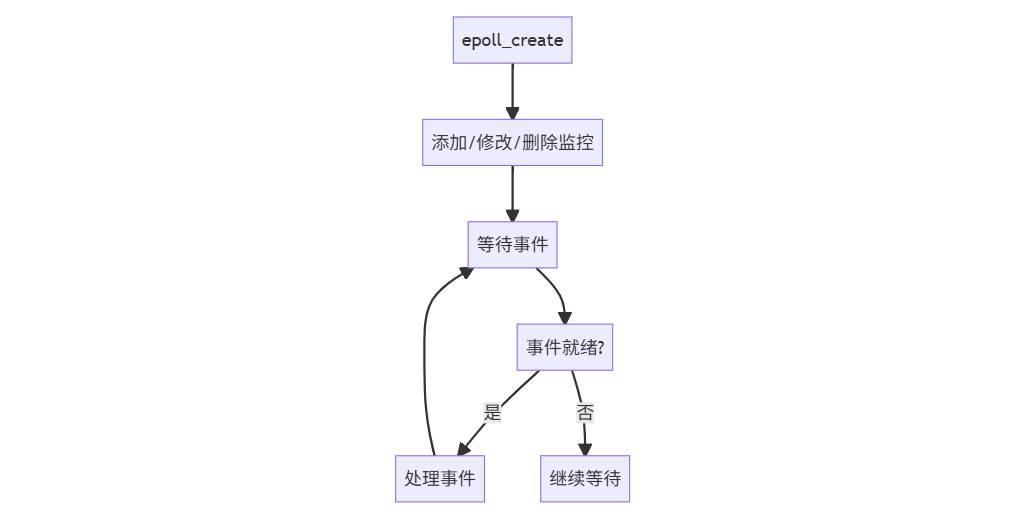
2. epoll工作流程
3. epoll的两种触发模式
| 模式 | 特点 | 适用场景 |
|---|---|---|
| 水平触发 | 数据未处理会重复通知 | 编程简单 |
| 边缘触发 | 只在状态变化时通知一次 | 高性能场景 |
五、现代I/O模型应用
1. 主流语言实现对比
| 语言 | 阻塞I/O | 非阻塞I/O | 多路复用 | 异步I/O |
|---|---|---|---|---|
| C/C++ | ✓ | ✓ | epoll/kqueue | libaio/io_uring |
| Java | ✓ | ✓ | NIO Selector | NIO.2 |
| Python | ✓ | ✓ | selectors | asyncio |
| Go | netpoll | goroutine | ||
| Node.js | libuv | Promise |
2. 高并发服务器架构演进
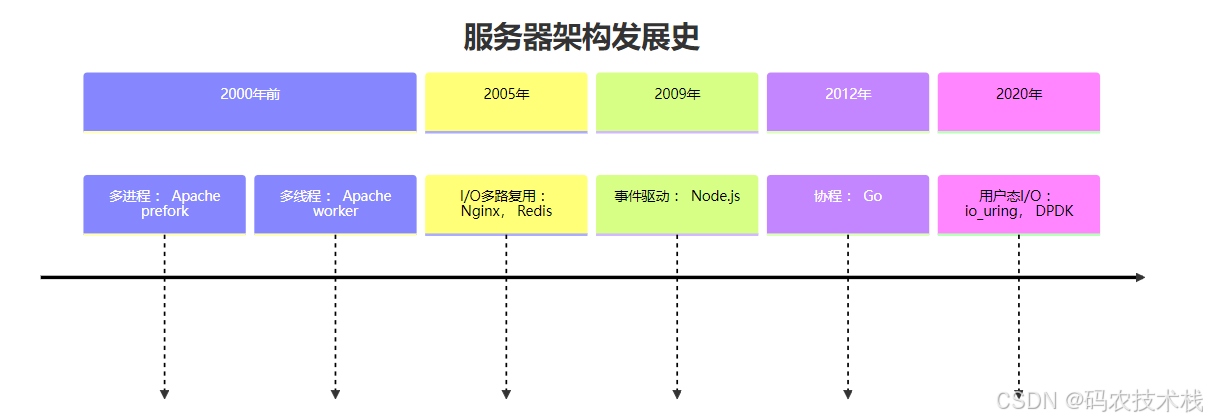
六、终极解决方案:io_uring
io_uring架构
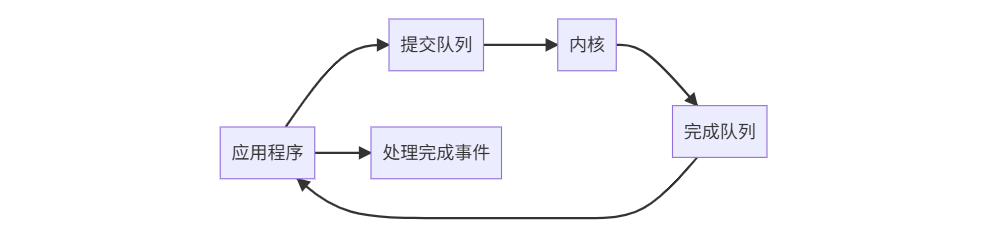
创新特性:
- ⚡ 零拷贝数据传输
- 🚀 批量提交操作
- 💡 无系统调用开销
- 🔧 支持所有I/O类型
性能对比:
+----------------+------------+
| 模型 | 每秒请求 |
+----------------+------------+
| 阻塞I/O | 5,000 |
| epoll | 200,000 |
| io_uring | 1,500,000+ |
+----------------+------------+
七、I/O模型选择指南
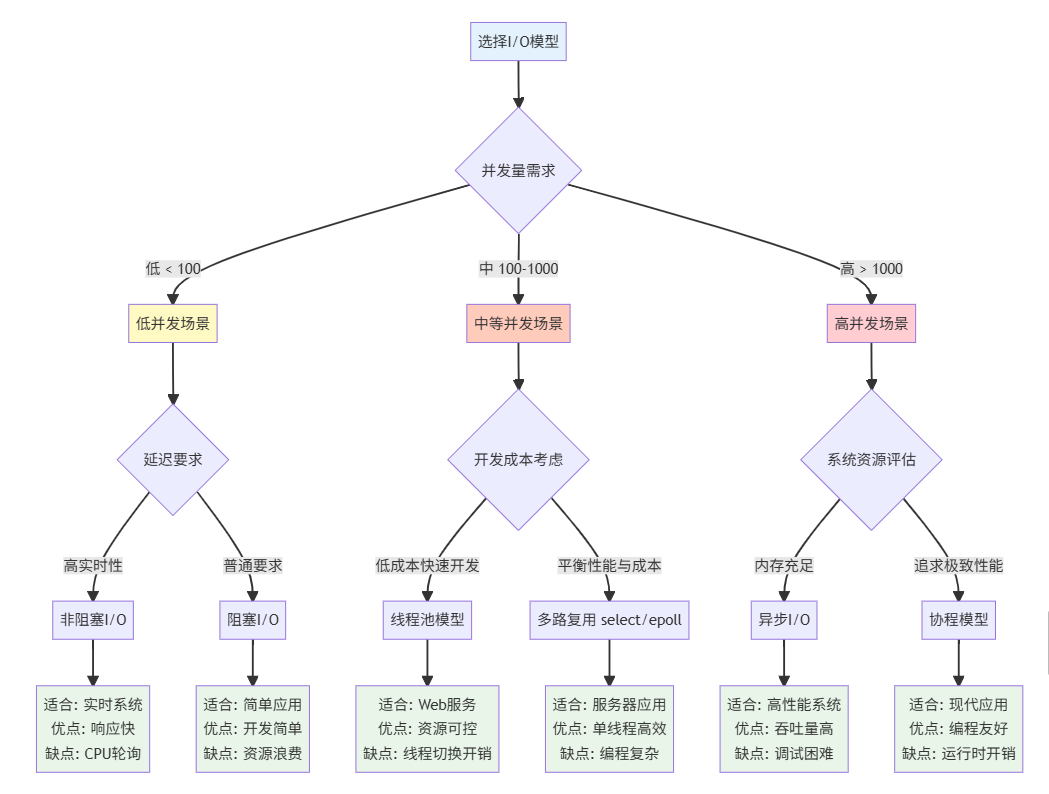
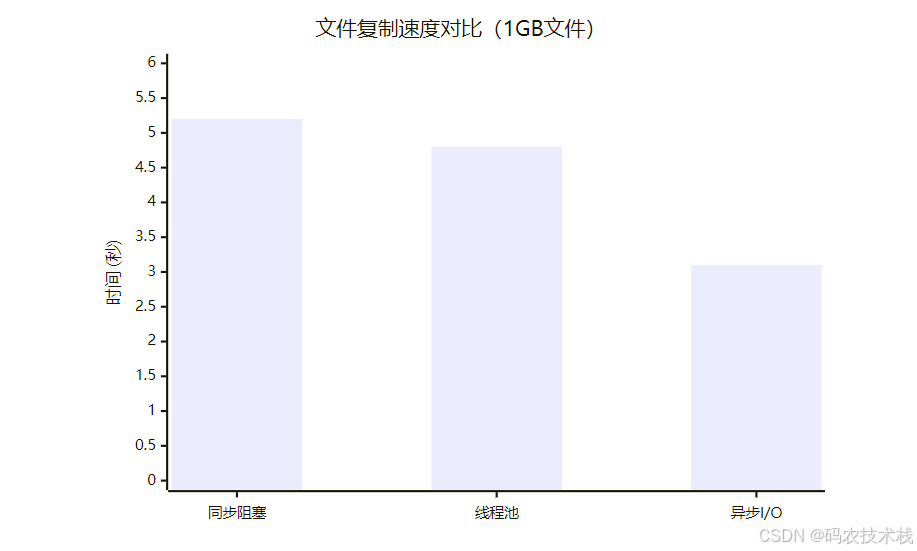
八、实战:文件I/O模型对比
同步 vs 异步文件复制
# 同步阻塞复制
def sync_copy(src, dst):
with open(src, 'rb') as s, open(dst, 'wb') as d:
while chunk := s.read(4096):
d.write(chunk) # 阻塞直到写入完成
# 异步复制 (Python aiofiles)
async def async_copy(src, dst):
async with aiofiles.open(src, 'rb') as s, \
aiofiles.open(dst, 'wb') as d:
while chunk := await s.read(4096):
await d.write(chunk) # 异步等待
性能对比测试结果
九、未来趋势:下一代I/O技术
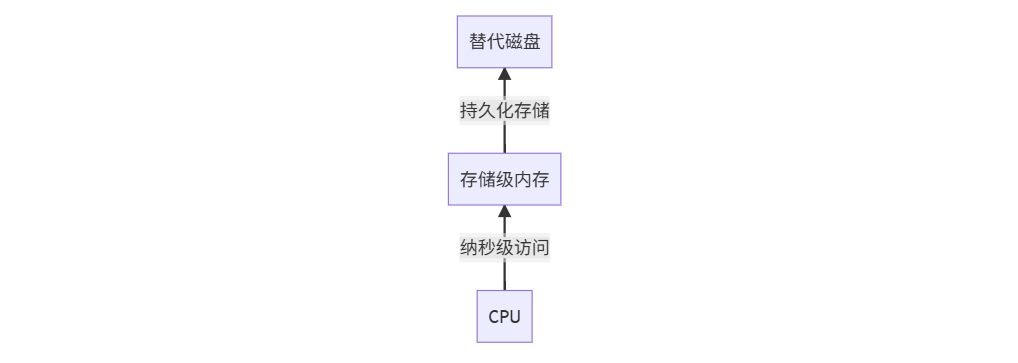
1. 存储级内存(SCM)
2. 可编程网络接口卡(SmartNIC)
+---------------------+
| SmartNIC |
| 处理TCP/IP协议栈 |
| 执行加密/解密 |
| 过滤DDoS攻击 |
+---------------------+
3. 光子I/O互连
电信号 --> 光子信号
优势:
- 速度提高1000倍
- 能耗降低90%
- 无电磁干扰
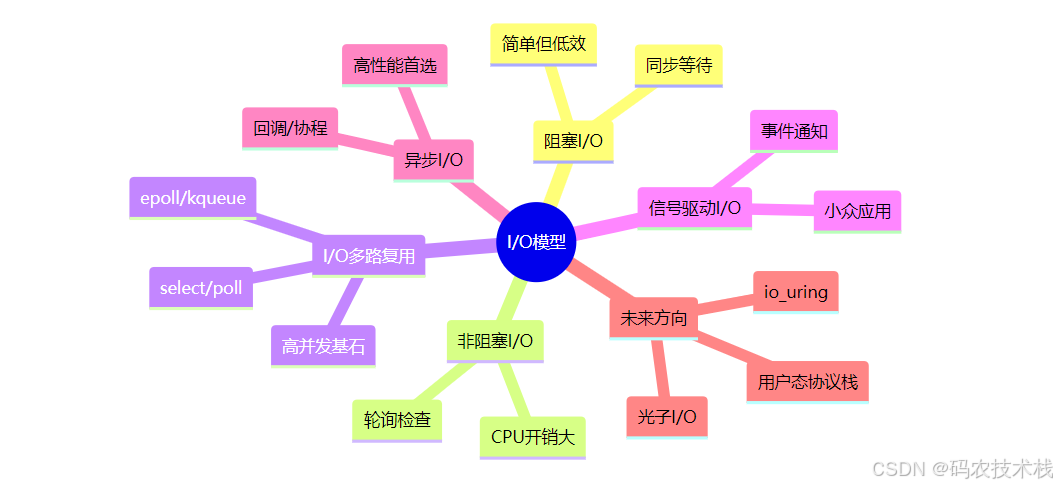
十、总结:I/O模型知识图谱
💡 核心洞见:
- I/O模型决定程序并发能力的天花板
- 多路复用是当前高并发系统的黄金标准
- 异步I/O+协程是未来发展方向
- io_uring代表Linux I/O的最新进化
- 选择模型需平衡性能与开发成本
思考题:为什么Redis使用单线程却能支持超高并发?评论区分享你的见解!
🚀 动手实验:用Python测试不同I/O模型性能:
# 安装: pip install asyncio aiohttp import asyncio import aiohttp async def async_fetch(url): async with aiohttp.ClientSession() as session: async with session.get(url) as response: return await response.text() # 同时发起100个请求 urls = ["http://example.com"] * 100 asyncio.run(asyncio.gather(*[async_fetch(url) for url in urls]))
理解I/O模型,你就掌握了高性能编程的核心密码!现在就开始升级你的I/O策略吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 42
42 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)