2025量化必杀技!RD-Agent-Quant深度解析:多智能体如何颠覆传统量化研发?附实战案例
R&D-Agent-Quant (RD-Agent(Q))** 是首个以数据为中心的多智能体框架,旨在通过因子-模型联合优化实现量化策略全栈研发自动化。它分解为研究和开发两个迭代阶段,包含**Specification、Synthesis、Implementation(含Co-STEER代码生成智能体)、Validation、Analysis**五个核心单元,形成假设-实现-验证-反馈闭环,并通过
R&D-Agent-Quant (RD-Agent(Q)) 是首个以数据为中心的多智能体框架,旨在通过因子-模型联合优化实现量化策略全栈研发自动化。它分解为研究和开发两个迭代阶段,包含Specification、Synthesis、Implementation(含Co-STEER代码生成智能体)、Validation、Analysis五个核心单元,形成假设-实现-验证-反馈闭环,并通过多臂老虎机调度器自适应选择优化方向。实验表明,该框架在CSI 300数据集上实现了比传统因子库高2倍的年化收益,且因子使用量减少**70%**,同时优于最先进的深度时间序列模型,在预测精度和策略稳健性间取得良好平衡。
- 研究背景与问题
金融市场因高维度、非平稳性和持续波动性,对资产收益预测构成挑战。尽管大语言模型(LLMs)和多智能体系统有所发展,当前量化研究仍存在三大局限:
- 自动化有限:假设生成、编码和调优需大量人工干预,迭代缓慢且存在偏差;
- 可解释性差:基于LLM的智能体直接生成交易信号,缺乏因子构建或模型逻辑的透明度,易产生幻觉;
- 优化碎片化:数据处理、因子挖掘、模型训练等环节缺乏系统分解与智能体协同,限制跨阶段反馈。
金融市场构成了高维度、非线性的动态系统,其收益序列呈现出厚尾分布[1]、时变波动率[2]以及复杂的横截面相关性[3]等特征。这些特性意味着资产价格同时受宏观因素、微观结构信号和行为反馈的驱动[4-6],这使得预测工作比传统时间序列预测更具挑战性。在数据爆炸式增长、计算能力与人工智能技术取得突破性进展的推动下,资产管理行业正从经验驱动向数据驱动范式转型。在这一转变中,量化投资逐渐成为主流,原因在于:(i)通过“数据-因子-模型”闭环实现高效决策;(ii)集成风险控制的可重复执行;(iii)在策略趋同加剧的背景下精准追求超额收益[7,8]。
图1展示了现代量化研究流程。微软的开源项目Qlib简化了数据处理和回测环节,减轻了大量重复性工程负担。因此,这一转变将量化研究的焦点重新导向其核心组件:因子挖掘与模型创新。因子挖掘从封闭式风险-收益模型10,11发展到进化符号回归,近年来更出现了基于强化学习的因子组合优化[15-17]。模型创新则从经典自回归模型[18,2]演进到机器学习模型[19-21]以及序列到序列的深度学习架构(如GRU[22]和LSTM[23])。更近的进展包括专门的时间序列模型——这些模型将信号分解为趋势-季节性成分[24],或改进注意力机制以适应长期预测[25]。与此同时,股票特异性模型通过图神经网络整合时序事件序列与横截面相关性,以捕捉股票间的相互作用[26-28]。最近,大语言模型(LLMs)和多智能体系统通过从新闻与社交网络中提取信号[29-31],以及模拟对冲基金和金融专家间的协作[32-34],进一步扩展了信息集。
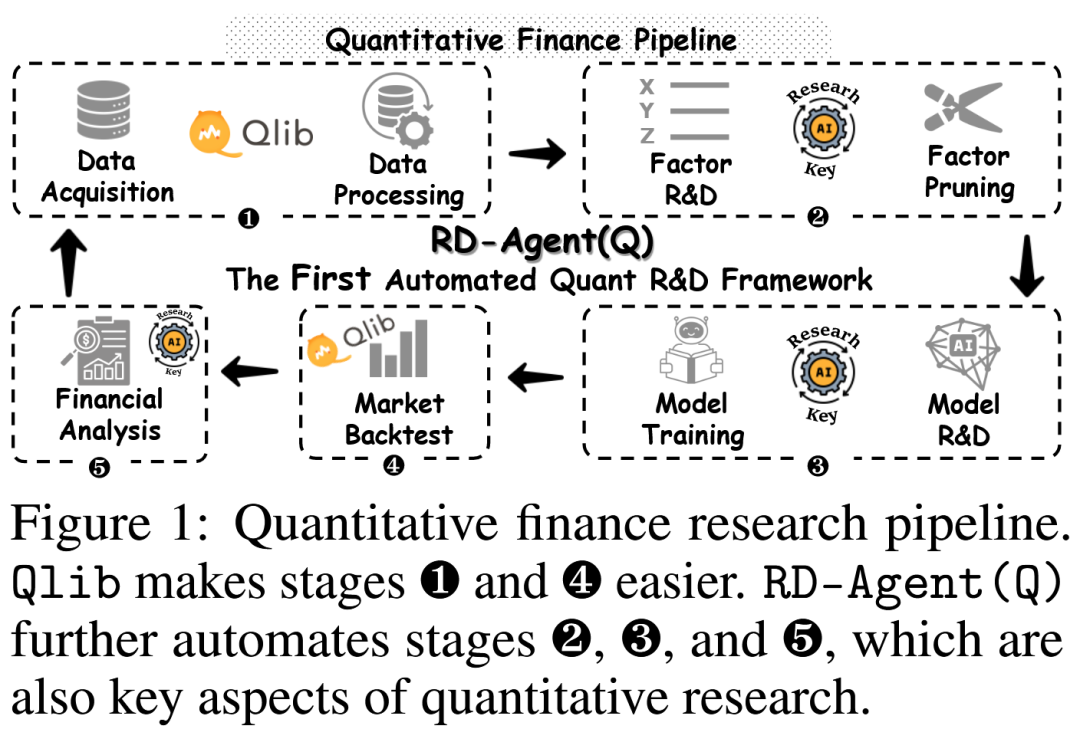
尽管取得了这些进展,量化研究仍面临三个关键局限:(i)自动化程度有限:当前工作流程在假设生成、编码和调优环节需要大量人工干预,导致迭代缓慢且存在偏差;此外,半自动化系统无法满足快速变化市场对响应速度和可扩展性的需求。(ii)可解释性差:现有基于LLM的智能体通常直接通过语言交互生成交易信号,缺乏扎实的因子构建或透明的模型逻辑,因此容易产生幻觉。这阻碍了其在实盘交易中的应用——在实盘场景中,可解释性和风险控制至关重要。(iii)优化碎片化:量化流程涵盖数据处理、因子挖掘、模型训练和评估,但现有方法缺乏系统性的任务分解或智能体层面的协同。这种孤立结构限制了跨阶段反馈和联合性能提升。
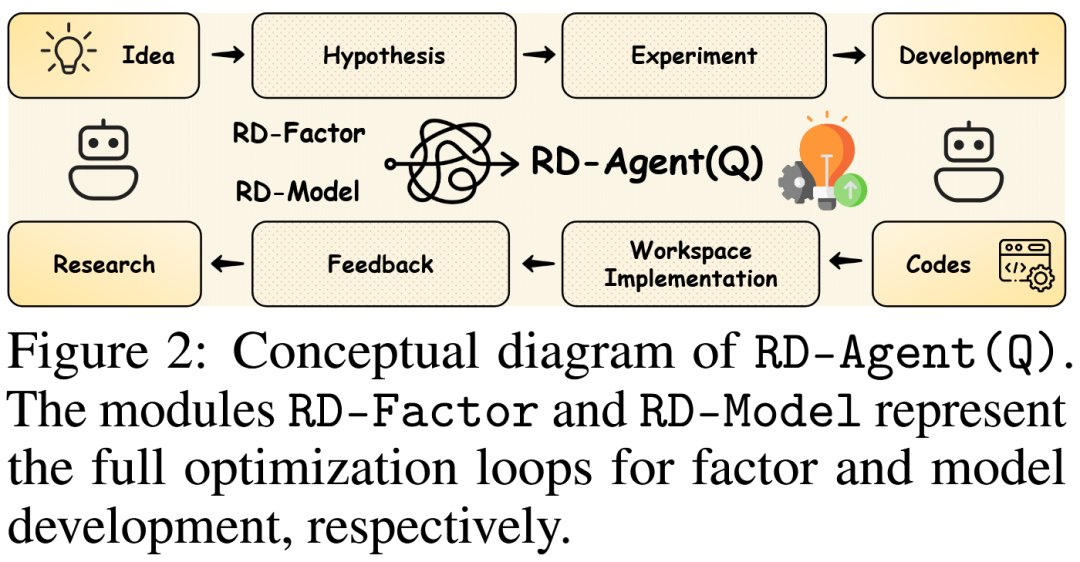
为应对这些挑战,我们提出RD-Agent(Q)——首个以数据为中心的多智能体框架,通过协同因子-模型联合优化实现量化策略全栈研发自动化(图2)。该框架将量化研究分解为跨越两个核心阶段(研究与开发)的五个环节:研究阶段中,Specification单元根据优化目标动态生成目标对齐的提示,Synthesis单元基于领域先验和历史结果构建任务特异性知识森林并生成新的因子或模型假设,再将其映射为可执行任务;开发阶段中,我们引入Co-STEER(一种利用链式推理和图基知识存储的代码生成智能体),由Implementation单元将假设转化为代码,Validation单元则执行实盘回测。两个阶段通过反馈环节连接——该环节全面评估实验结果并为后续迭代提供指导,同时采用多臂老虎机调度器自适应选择优化方向。
本文的主要贡献如下:
- 具有透明度的端到端自动化:RD-Agent(Q)是量化金融领域首个以数据为中心的多智能体框架,可自动化整个研发流程,且输出可验证,从而增强可解释性并降低幻觉风险。
- 高性能研发工具:在研究阶段,RD-Agent(Q)通过结构化知识森林模拟分析师工作流程,生成连贯、高质量的假设;在开发阶段,我们提出Co-STEER(一种为数据中心任务量身设计的知识进化智能体),提升因子和模型代码生成的准确性与效率。
- 优异的实证性能:在真实股票市场的大量实验表明,RD-Agent(Q)在成本低于10美元的情况下,年化收益率(ARR)约为基准因子库的2倍,同时使用的因子减少70%以上;在资源预算更小的情况下,其性能也超过最先进的深度时间序列模型。此外,其交替进行的因子-模型优化在预测精度和策略稳健性之间实现了出色平衡。
- RD-Agent(Q)框架设计
框架将量化研究分解为研究(Research) 和开发(Development) 两大阶段,包含五个紧密耦合的单元,形成闭环迭代:
| 单元名称 | 核心功能 |
|---|---|
| Specification | 动态配置任务上下文与约束,确保设计、实现和评估的一致性,定义为元组(背景、数据接口、输出格式、执行环境)。 |
| Synthesis | 基于历史实验生成新假设,构建任务知识森林;将假设映射为可执行任务(因子假设可分解为子任务,模型假设对应单一任务)。 |
| Implementation | 通过Co-STEER智能体将任务转化为代码:基于有向无环图(DAG)处理任务依赖,利用知识库(存储任务-代码-反馈三元组)提升代码生成效率。 |
| Validation | 评估因子/模型有效性:因子去重(计算与现有SOTA因子的相关性,IC>0.99视为冗余)、结合Qlib回测平台验证性能。 |
| Analysis | 多维度评估实验结果,更新SOTA集合;通过上下文两臂老虎机(线性汤普森采样)选择下一轮优化方向(因子或模型)。 |
基于图1和附录B中的规范化量化研究流程结构,提出了RD-Agent(Q)——一个以数据为中心的多智能体框架,用于因子-模型的迭代研发,具备自动化、可解释性和高效性。将量化过程分解为五个紧密耦合的单元:
- 规格单元(场景定义)
- 合成单元(想法生成)
- 实现单元(代码开发)
- 验证单元(回测)
- 分析单元(结果评估与任务调度)。
在统一的输入-输出约束下,这些单元以闭环循环的方式运行,模拟人类量化研究员的试错过程。与人工工作流程不同,RD-Agent(Q)能够持续自主运行,支持因子和模型组件的动态联合优化。此外,每一轮的假设、实现和结果都会被持久化存储,从而实现知识的累积增长,并随着时间的推移做出更具信息量的决策。
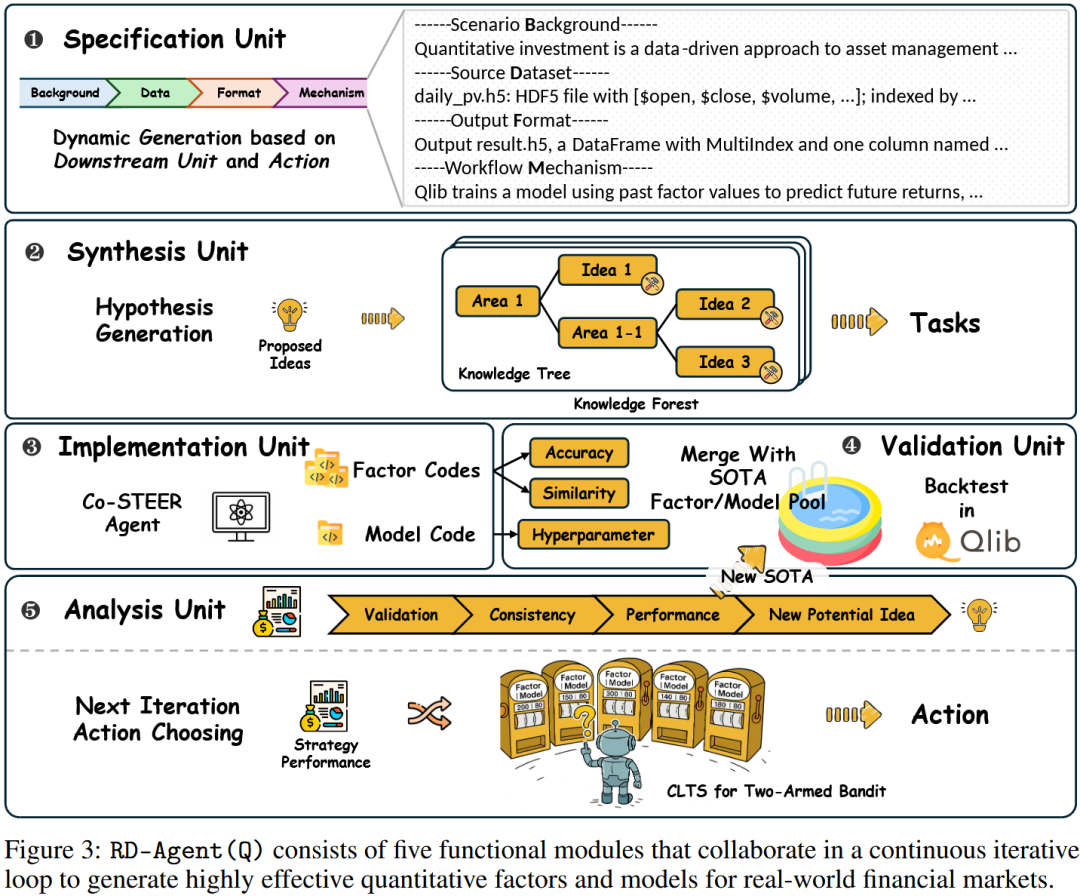
2.1 规格单元
规格单元作为RD-Agent的顶层组件,为下游模块动态配置任务上下文和约束,确保设计、实现和评估的一致性。它沿两个维度运行:
- 理论维度——将先验假设、数据模式和输出协议编码为结构化规格;
- 实证维度——建立可验证的执行环境和标准化的回测接口,使智能体无需关注底层预处理和基础设施问题。通过将形式化定义与统一接口相结合,该模块减少了歧义,提高了组件间的协同效率。
将规格单元形式化为一个元组,其中编码关于因子或模型的背景假设和先验知识;定义市场数据接口;表示预期输出格式(如因子张量或收益预测);表示外部执行环境(如基于Qlib的回测)。在这一形式化定义下,任何候选因子或模型都必须满足:对于,有,且可在中执行。这一约束确保了与标准化输入/输出结构的兼容性,并保证后续模块能在共享的操作上下文中与交互,从而支持协同工作流的一致性和可重复性。
2.2 合成单元
合成单元通过基于历史实验生成新假设来模拟类人推理。每个优化动作定义为 {因子,模型}。对于当前动作,该单元通过选择相关历史实验的子集来构建实验轨迹。第次实验表示为,其中是假设,是来自分析单元的反馈。系统会维护一组当前表现最佳的解决方案(SOTA)。基于此,历史假设集和反馈集定义为和,并按动作提取子集如公式(1)所示:
这些子集被传递给生成映射函数(作为研究阶段的核心,模拟理论先验与实证反馈的结合以生成有效且新颖的假设),从而产生下一个假设:。在实践中,该模块依赖结构化模板和标准化格式,确保假设既可执行又具有科学依据。例如,在因子生成任务中,不仅整合最新反馈,还纳入当前市场状况和特定领域的经济理论,以确保因子的有效性和可观测性。
为促进多样性和渐进式改进,生成机制会根据性能反馈调整策略:若显示成功,则下一个假设会增加复杂度或范围;否则,会进行结构调整或引入新变量,从而形成“想法森林”。这种自适应机制使智能体能够探索新方向,同时对实证结果保持敏感,支持策略的迭代高效开发。
最后,假设被实例化为具体任务,供下游实现模块进行代码级实现。因子假设由于其异质性和潜在交互性,可分解为多个子任务;相比之下,模型假设因其结构连贯性,会映射到一个负责执行整个建模和推理流程的单一任务。
2.3 实现单元
实现单元负责将合成单元生成的可执行任务转换为功能代码。它是RD-Agent(Q)中复杂开发工作的核心。为支持这一过程,我们设计了一个专门的智能体Co-STEER,专为量化研究中的因子和模型开发量身定制。如图4所示,Co-STEER整合了系统调度和代码生成策略,以确保实现过程的正确性、高效性和适应性。
在因子开发中,任务通常存在结构依赖。为此,我们引入引导式链式推理机制,促进推理的可追溯性。具体而言,智能体会构建有向无环图(DAG)来表示任务依赖,其中从任务A到任务B的边意味着A应先于B执行(基于知识流或复杂度)。随后会导出拓扑排序来指导任务执行。调度具有自适应性:来自先前执行的反馈会持续整合以改进规划——某一任务的反复失败表明其复杂度较高,此时会优先处理较简单的任务,以增强知识积累和执行成功率。
对于每个任务,实现智能体基于任务描述和当前知识库生成相应代码,即。这一过程包括任务解析、代码合成与优化、执行和验证。智能体的目标是最大化累积实现质量:,其中评估代码的正确性和性能。知识库发挥核心作用,记录成功和失败的“任务-代码-反馈”三元组:,其中表示执行任务后收到的反馈。通过知识转移机制,实现智能体还能基于当前反馈从知识库中检索相似任务的解决方案,从而提高新任务代码生成的效率和成功率:。完整的算法细节见附录A.1。
这种由反馈驱动的优化循环使实现单元能够持续提升代码质量和效率,为量化研究组件的快速稳健开发提供支持。
2.4 验证单元
验证单元评估实现单元生成的因子或模型的实际有效性。对于因子,首先执行去重过程,通过计算新因子与现有SOTA因子库的相关性来过滤冗余信号。给定拼接的因子矩阵,在每个时间片内计算所有对SOTA因子和新因子的信息系数(IC):,其中索引SOTA-新因子对,索引时间片。这些IC值在时间上取平均,对于每个新因子,其与所有SOTA因子的最大IC为。若新因子的,则视为冗余并被排除。
因子过滤后,剩余候选因子与当前SOTA模型(或基线模型,若尚无SOTA)结合,通过Qlib回测平台评估,以在真实市场条件下检验性能。对于模型,过程类似:每个候选模型与当前SOTA因子集结合,通过相同的回测流程评估。因此,验证单元提供了一个集成化的自动化流程,支持在生产级市场模拟环境中对新组件进行标准化评估。
2.5 分析单元
分析单元在RD-Agent(Q)框架中同时充当研究评估器和策略分析师。每轮实验后,它会对当前假设、具体任务和实验结果进行多维度评估。若实验在动作类型下表现优于SOTA,则其结果会被加入相应的SOTA集。该单元还会诊断失败策略,并生成针对性的改进建议。反馈被传递给合成单元,以指导未来假设的制定。
值得注意的是,分析单元仅关注当前实验的局部视角,而合成单元则维持对整个实验历史的全局视角。两者的交互形成一个闭环系统,平衡短期响应与长期探索,支持研究设计、策略实现、验证和深度分析的自动化迭代。
每轮分析后,分析单元还会决定下一轮迭代优先进行因子优化还是模型优化。为最大化性能提升,这一决策被建模为上下文两臂老虎机问题,并通过线性汤普森采样求解(详见附录A.2)。具体而言,在每轮,系统会观测一个8维性能状态向量,该向量编码当前策略的关键评估指标。动作空间为,对应两种可能的优化路径。为评估在上下文下每个动作的预期收益,我们采用线性奖励函数,其中反映每个指标的相对重要性。每个动作对应一个贝叶斯线性模型,其高斯后验编码奖励系数的不确定性。在每一步,系统从每个后验中采样奖励向量并计算相应的预期奖励,选择采样奖励最高的动作执行。观测到实际改进后,所选臂的后验会被更新。通过这种上下文汤普森采样机制,RD-Agent(Q)自适应平衡探索与利用,实现跨迭代的稳健性能提升。
关键创新组件
- **知识森林(Knowledge Forest)**:Synthesis单元通过历史实验构建结构化知识,支持连贯、高质量的假设生成;
- Co-STEER智能体:融合链式推理与图知识存储,动态调度任务优先级(基于复杂度和依赖),通过反馈迭代优化代码,提升实现准确性;
- 多臂老虎机调度器:基于8维性能状态向量(IC、ARR等),通过贝叶斯线性模型自适应选择优化方向,平衡探索与利用。
- 实验设置
- Datasets:使用沪深300(CSI 300)数据集,涵盖中国市场300只大盘A股。时间跨度分为训练期(2008年1月1日–2014年12月31日)、验证期(2015年1月1日–2016年12月31日)和测试期(2017年1月1日–2020年8月1日)。我们在三种配置下评估RD-Agent(Q):
- RD-Factor:将预测模型固定为LightGBM,从Alpha 203开始优化因子集;
- RD-Model:将输入因子集固定为Alpha 20,搜索更优模型;
- RD-Agent(Q):联合优化因子和模型组件。
- Baselines:
- 在因子层面,与Alpha 101、Alpha 158、Alpha 360和AutoAlpha进行比较。
- 在模型层面,纳入机器学习模型(线性模型、MLP、LightGBM、XGBoost、CatBoost、DoubleEnsemble)和深度学习模型(GRU、LSTM、ALSTM、Transformer、PatchTST、iTransformer、Mamba、TRA、MASTER、GATs)。更多细节见附录C.3。
- Evaluation Details:我们使用两类指标评估RD-Agent(Q):
-
因子预测指标,包括信息系数(IC)、信息系数信息比率(ICIR)、排名IC和排名ICIR;
-
策略性能指标,包括年化收益率(ARR)、信息比率(IR)、最大回撤(MDD)和卡尔玛比率(CR)。我们遵循基于预测收益排名的每日多空交易策略,包含持仓更新、持仓保留规则和真实交易成本。
-
实验分析
| 指标/模型 | RD-Factor(因子优化) | RD-Model(模型优化) | RD-Agent(Q)(联合优化) |
|---|---|---|---|
| 最高IC | 0.0497 | 0.0546 | 0.0532 |
| 最高ARR | 14.61% | 12.29% | 14.21% |
| 优势 | 优于静态因子库,用更少因子实现更高收益 | 优于ML和DL模型,回撤更低(-6.94%) | 综合性能最优,IR达1.74 |
- 成本效益:总成本低于$10,资源效率显著;
- 稳健性:在Optiver波动率预测竞赛中,通过迭代优化(如捕捉买卖价差的时间演化)取得优异成绩。
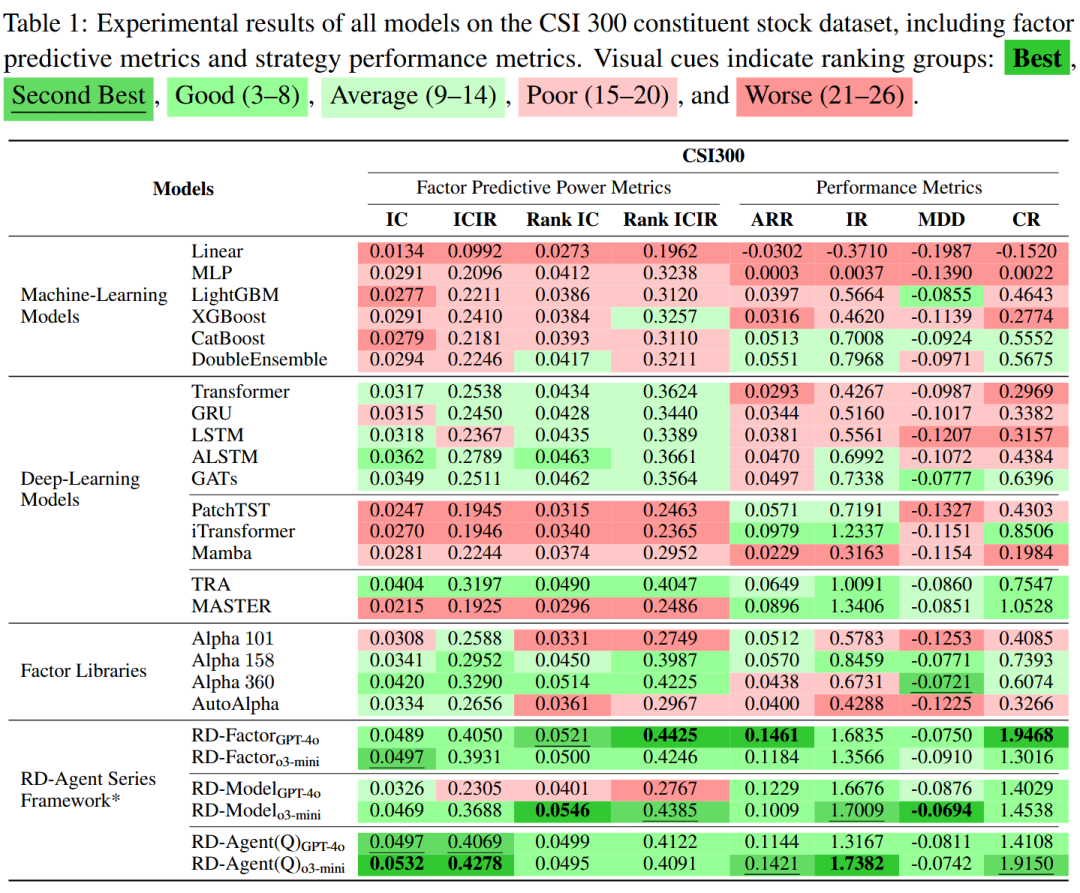
主要结果分析 表1报告了基线模型和RD-Agent框架在沪深300数据集上的性能,显示RD-Agent在预测指标和策略指标上均持续优于所有基线。
- RD-Factor(因子优化):当仅对因子空间进行自适应优化时,和均超越静态因子库(如Alpha 158/360),信息系数(IC)最高达0.0497,年化收益率(ARR)显著提升(最高达14.61%),且使用的手工因子更少。这表明RD-Agent(Q)中的动态假设优化和因子筛选能产生比固定高维因子集更具信息价值的信号。
- RD-Model(模型优化):在固定因子的模型优化中,超越所有基线,在排名IC(0.0546)和最大回撤(MDD,-6.94%)上表现最佳。机器学习模型显著落后,凸显其在捕捉金融噪声和非线性模式方面的局限性。虽然通用深度学习架构(GRU、LSTM、Transformer)的预测指标中等,但策略性能较弱,表明其在特征提取与可操作收益之间存在差距。令人惊讶的是,时间序列预测模型(如PatchTST、Mamba)在两方面均表现不佳,说明标准序列预测与股票市场动态存在根本不匹配。相比之下,专门的股票预测模型(TRA、MASTER)在策略指标上表现优异,但预测能力落后,凸显了稳健性(低MDD、高IR)与精度(高IC)之间的权衡。这些结果表明,在自动化假设评估的指导下,自适应模型配置能产生比机器学习和手工设计的深度学习架构更稳健、对风险更敏感的预测结构。
- RD-Agent(Q)(联合优化):通过联合优化因子和模型,实现了最高的整体性能:IC为0.0532,ARR为14.21%,信息比率(IR)为1.74。这些改进大幅超过最强基线方法(如Alpha 158、TRA)。这表明因子和架构的联合优化能释放互补性改进,实现可扩展且一致的阿尔法建模。
研究组件分析 为评估RD-Agent(Q)的研究动态,分析了RD-Factor中因子假设的演化,重点关注其在探索(多样化想法生成)与利用(局部优化)之间的平衡。方法包括三个步骤:
-
(i) 文本嵌入:使用Sentence-BERT[53]将迭代t时生成的假设编码为固定维度向量;
-
(ii) 相似度矩阵:计算两两余弦相似度,形成对称矩阵;
-
(iii) 层次聚类:应用凝聚聚类对相似假设分组,并重新排序S以呈现块结构。
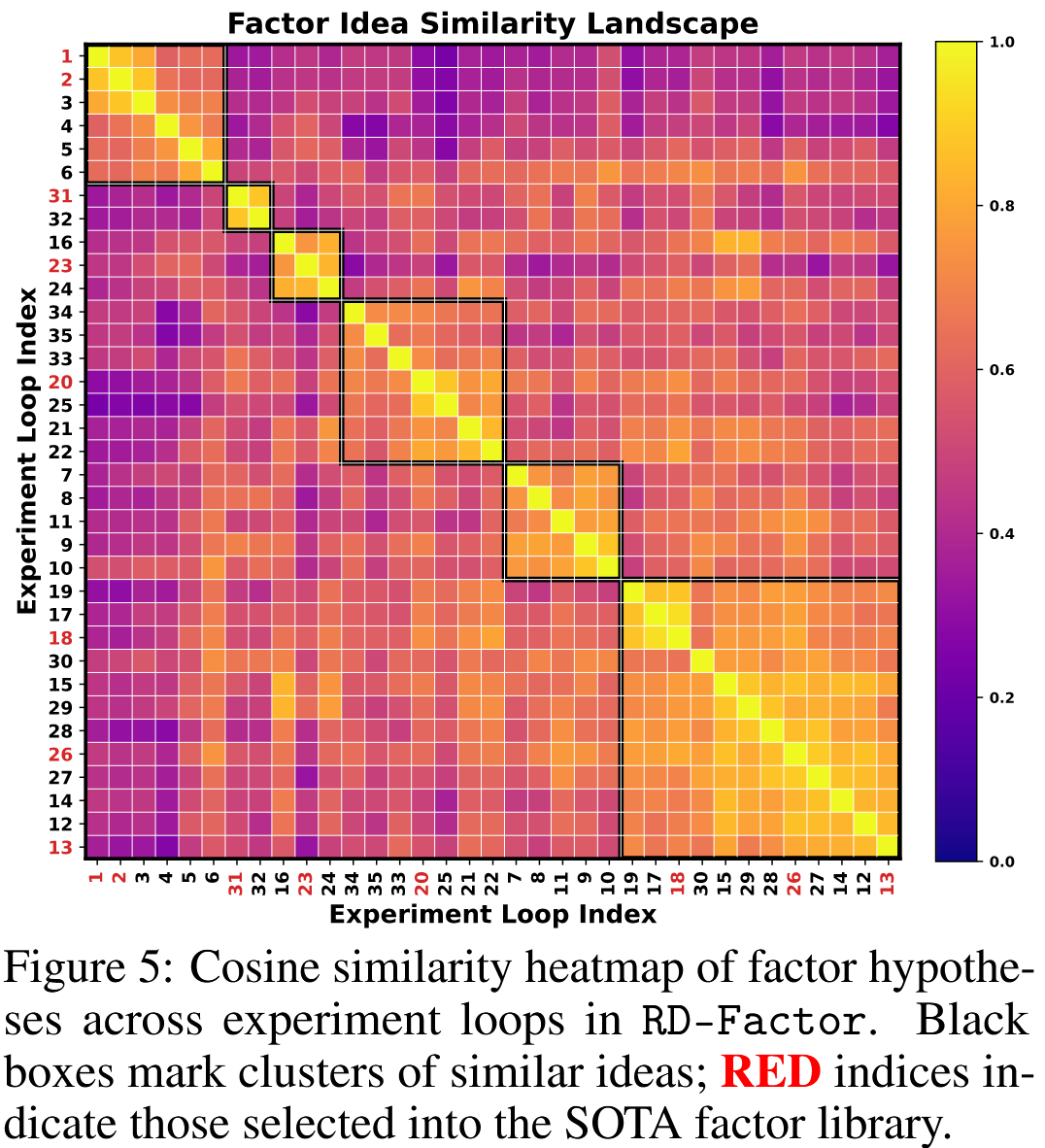
图5揭示了三种探索模式:
- 局部优化后转向新方向:对角块(如试验1-6、7-11)显示,RD-Factor在某一概念线索内进行多步优化后转向新方向,平衡了深度与新颖性;
- 策略性重访:试验26与早期试验12-14聚类,表明智能体能够重访并增量优化早期有潜力的假设;
- 多样化路径产生协同效应:36次试验中有8次被选入最终SOTA集,分布在6个聚类中的5个。这表明探索多个方向能产生互补信号,共同强化最终因子库。这种“优化-转向-复用”模式支撑了高效的深度搜索和广泛的概念覆盖,使构建紧凑、多样且高性能的因子库成为可能。
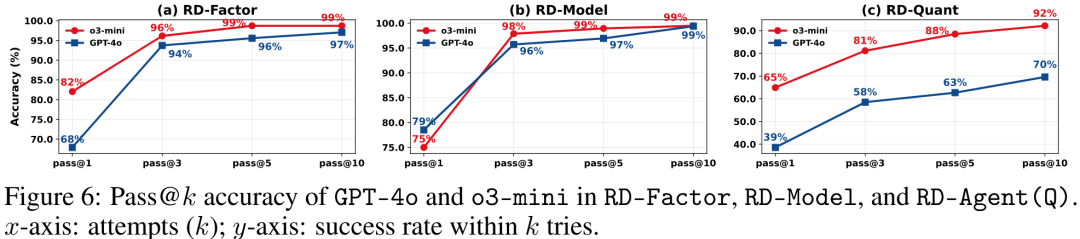
开发组件分析 为评估开发组件的代码生成能力,使用pass@k准确率指标分析了Co-STEER在RD-Agent(Q)各框架中的性能(图6)。在因子和模型任务中,成功率均在几次迭代内快速收敛,表明Co-STEER能通过反馈有效修复初始错误。在全栈任务(RD-Agent(Q))中,由于复杂度更高,差异更显著,迭代优化变得至关重要。其中,o3-mini始终实现更高的修复率,反映其更强的链式推理能力——这在结构化、高依赖的编码场景中是明显优势。总体而言,pass@k轨迹表明Co-STEER能在结构化金融编码中通过迭代优化实现渐进式自我修正。更多关于Co-STEER的实验见附录D.3。
因子效果分析。 图7中,我们将RD-Factor生成的因子库与基线比较,评估因子生成效果。子图(a)和(b)显示,即使从Alpha 20初始化,RD-Factor也能快速达到与Alpha 158和Alpha 360相当的IC水平,同时仅使用22%的因子。2017年后,它持续优于Alpha 20,并在2019-2020年基线性能下降时保持稳定的IC。从Alpha 158初始化时,RD-Factor进一步提升,尤其是o3-mini版本,2020年IC>0.07,超越所有基线。这表明迭代因子优化有助于消除对市场状态敏感或冗余的信号,提高整体预测稳定性。更多相关结果见附录D.2。
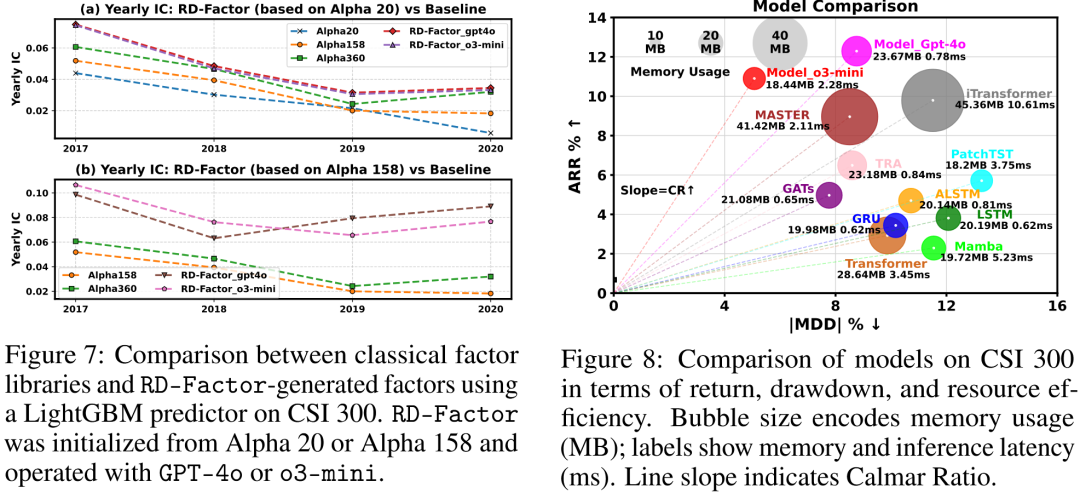
模型效果分析 图8从年化收益率、最大回撤和资源使用三个维度比较了RD-Model与基线深度学习模型。两种RD-Model变体均显著向理想的左上区域移动。实现12%的ARR和8%的|MDD|,达到最高的收益-风险斜率。的回撤更低,ARR为11%,在更严格的风险约束下表现强劲。
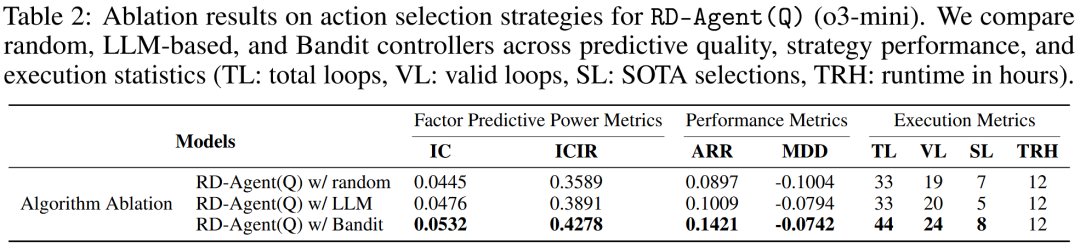
消融研究 为评估不同动作选择策略的影响,我们进行了如表2所示的消融研究。老虎机调度器实现了最佳整体性能,在IC、ARR和SOTA选择数量上均最高,证实其在有限计算预算下优先选择最有潜力优化目标的能力。基于LLM的策略表现中等,但由于额外的模型调用,每步开销更高,导致迭代次数更少。随机调度表现最差,凸显了明智决策在驱动有效优化中的重要性。完整消融结果见附录D.1。
后端比较 为评估RD-Agent(Q)对LLM后端的敏感性,我们在研究和策略指标上评估了六种API变体(图9)。尽管循环统计中等,但o1通过几次有影响力的试验实现了顶级性能,取得显著的策略突破。最新发布的GPT-4.1在大多数指标上排名第二。其他变体(除推理能力有限的GPT-4o-mini表现较弱外)结果相当,表明我们的框架在不同LLM后端上具有稳健性。
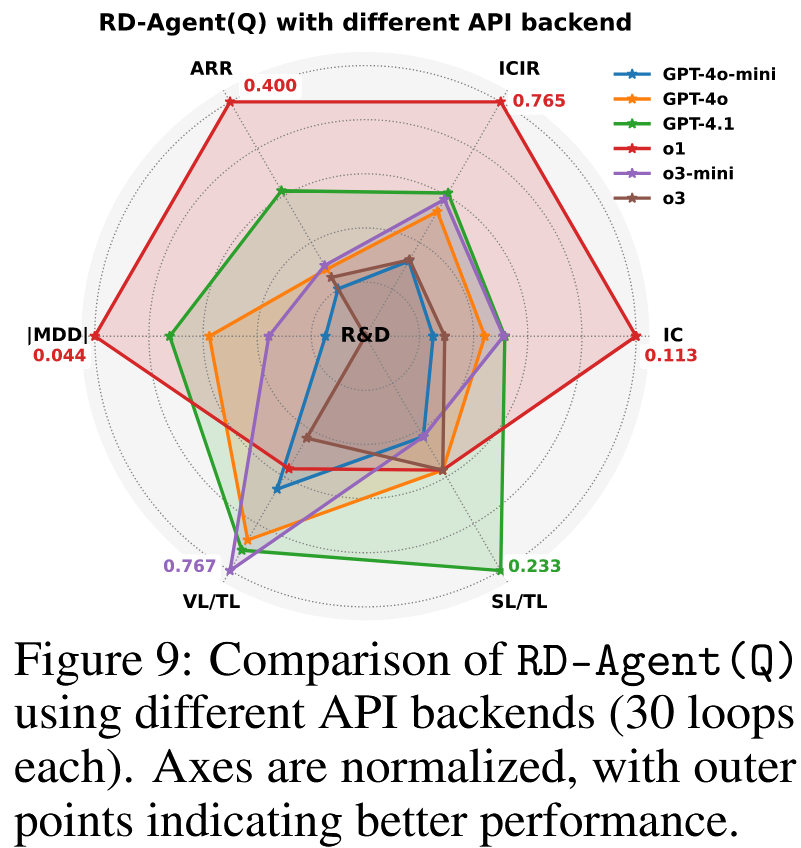
扩展研究 附录D.4进一步显示,在本文设置中,RD-Agent(Q)的成本低于10美元,证实其具有成本效益和可扩展性。附录D.5验证了其在真实世界量化场景中的稳健性。
5 相关工作
量化研究中的传统方法:量化策略传统上依赖于基于资产定价理论的人工构建因子,例如价值因子和动量因子。这些固定信号虽然具有可解释性,但在适应不断变化的市场状态方面往往缺乏灵活性。为克服这些局限性,符号回归和遗传编程(GP)方法通过演化复杂的非线性表达式来实现因子挖掘的自动化。诸如滞后算子和带剪枝的算子变异等改进方法产生了更多样化且有效的信号。强化学习(RL)方法将因子分配重新定义为序贯决策问题,直接优化夏普比率或卡尔玛比率。Andre等人通过带有KL正则化的狄利克雷策略对因子权重进行建模,实现了稀疏且自适应的策略。然而,强化学习方法在市场状态变化下(如2020年熔断)往往缺乏稳健性,且难以解释。
在模型方面,早期方法如ARIMA和指数平滑难以处理高维噪声数据。经典机器学习方法(如支持向量机、随机森林)提高了稳健性,但仍需要人工特征工程。此后,LSTM和Transformer等深度学习模型被应用于捕捉长期和横截面依赖关系。在此基础上,专门的时间序列神经网络应运而生。PatchTST将输入分割为局部补丁,而iTransformer通过重新映射变量-令牌关系来建模多变量结构。MASTER等领域特定模型进一步整合了市场层面的动态,以改进金融预测。然而,因子和模型的研发流程仍然相互孤立、依赖专家经验且缺乏灵活性,限制了其在波动市场中的可扩展性。
金融领域中由大语言模型驱动的智能体:大语言模型(LLMs)凭借其强大的推理和抽象能力,为自动化金融研究提供了新机遇。近期研究探索了将其用于从金融文本中提取预测信号、生成因子解释以及实现多模态市场分析。与此同时,基于大语言模型的多智能体系统(如AutoGen、AutoGPT)的相关进展为复杂决策提供了协同框架。在金融领域,FinAgent和TradingAgents 等系统采用基于角色的智能体来处理事件提取或组合更新等子任务。然而,大多数现有研究聚焦于狭窄的子任务,且严重依赖语义信号,导致其容易产生幻觉、可解释性差且难以复现。此外,这些研究缺乏因子-模型联合优化机制或工作流整合,限制了其在真实世界量化系统中的有效性。
6 结论
提出了RD-Agent(Q)大语言模型驱动的框架,用于量化金融领域的协同因子-模型研发。通过将研究分解为模块化组件并整合基于老虎机的调度器,该框架能够在固定计算预算下支持高效、自适应的迭代。实证结果表明,RD-Agent在信号质量和策略性能上均优于基线模型,且具有较强的成本效益和通用性。其模块化设计还使其能够适应真实世界场景。然而,当前框架仅依赖大语言模型内置的金融知识。未来的工作可能会增强数据多样性、融入领域先验知识,并实现对不断变化的市场状态的在线适应。
- 结论与局限
RD-Agent(Q)实现了量化策略研发的端到端自动化,在收益和效率上优于传统方法。局限性包括:依赖LLM内置金融知识、未整合多模态数据(如新闻、宏观指标)、实时适应性不足。未来可通过检索增强生成(RAG)整合领域知识,提升实时市场适应能力。
7 免责声明
RD-Agent(Q)框架及相关代码的用户应自行准备金融数据,并在自身场景中独立评估和测试生成的因子及模型的风险。使用智能体生成的代码、数据和模型时,必须谨慎行事并进行彻底检查。RD-Agent(Q)框架不提供金融意见,其设计目的也并非取代合格金融专业人士在制定、评估和审批金融产品方面的作用。RD-Agent(Q)框架的输出不代表微软的观点。
关键问题
- RD-Agent(Q)如何解决传统量化研究的三大局限?
答案:针对自动化有限,框架通过五个单元形成闭环,实现假设生成、代码实现、回测评估的全流程自动化,减少人工干预;针对可解释性差,通过因子构建和模型逻辑的透明化实现(如知识森林记录假设来源、Co-STEER生成可验证代码),降低幻觉风险;针对优化碎片化,通过多智能体协同(如Synthesis与Analysis的反馈交互)和联合优化机制,打破阶段壁垒,提升跨环节协同效率。 - Co-STEER智能体在代码生成中的核心优势是什么?
答案:Co-STEER的优势体现在三方面:①任务调度:基于DAG处理任务依赖,动态调整优先级(如优先执行简单任务积累知识);②知识复用:通过知识库存储任务-代码-反馈三元组,检索相似任务的解决方案,提升新任务代码生成效率;③迭代优化:结合链式推理和反馈,实现代码自我修正,在因子和模型任务中快速收敛(pass@k准确率高),尤其在高复杂度全栈任务中表现突出。 - RD-Agent(Q)在实验中表现出的性能优势有哪些具体数据支撑?
答案:在CSI 300数据集上,①与传统因子库相比,RD-Factor实现最高14.61%的年化收益(ARR),是Alpha 158等基线的2倍,且因子使用量减少70%;②与SOTA深度模型相比,RD-Agent(Q)的IC达0.0532,ARR达14.21%,信息比率(IR)1.74,均优于GRU、Transformer等模型;③成本效益显著,总运行成本低于$10,且在Optiver竞赛中通过优化买卖价差特征,实现低波动率预测误差(RMSPE)。
A Algorithmic Details
A.1 Co-STEER Implementation Logic
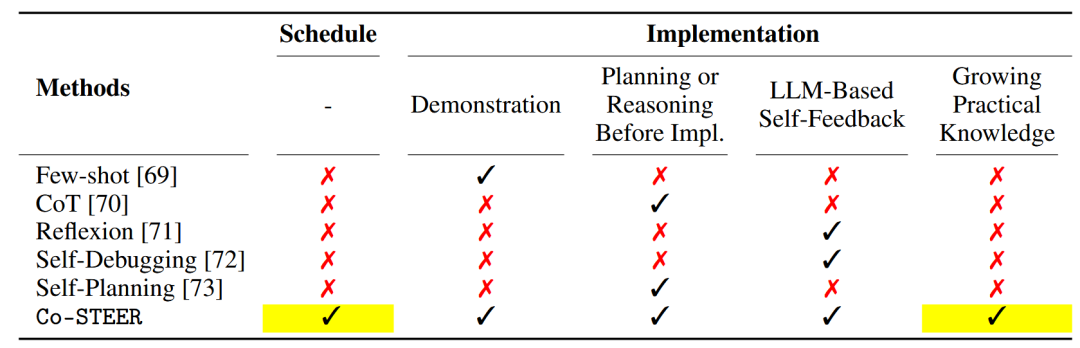
为进一步阐明Co-STEER智能体的内部机制,我们同时提供了形式化的算法流程(算法1)和比较方法分析(表3)。
现有的自然语言到代码的方法主要关注孤立的能力。少样本学习利用上下文示例来指导模型输出。链式思维(CoT)通过逐步提示提高推理连贯性。Reflexion和自我调试强调通过反馈进行迭代修正,而自我规划支持自动任务分解。
相比之下,Co-STEER提供了一个统一的解决方案,整合了调度、推理、反馈驱动的优化和长期知识积累。它维护一个不断增长的先前尝试的知识库,从而能够检索和调整先前成功的解决方案。此外,其调度智能体通过基于复杂度和反馈动态确定任务优先级(早期优先处理更简单、更基础的任务,为后续代码生成提供信息丰富的框架),支持多任务代码生成(如量化研究中的因子实现)。
表3:量化研究中代码生成方法的比较。Co-STEER是唯一支持从任务调度到实现的端到端开发的方法,其通过结构化推理和终身知识复用得到增强。这使其特别适用于多步骤、以数据为中心的金融工作流。
A.2 Bandit Scheduling Logic
给出用于因子实现任务的 Co-STEER 工作流的完整伪代码。
A.2 老虎机调度逻辑
如2.5节所述,我们基于当前策略性能,应用上下文汤普森采样(contextual Thompson Sampling)来自适应选择两个优化方向——因子优化和模型优化。该问题被表述为具有线性奖励函数的两臂上下文老虎机(two-armed contextual bandit)。每个臂(arm)维护其自身的贝叶斯线性回归模型,其 posterior 在每次交互后更新。
在每一轮中,系统使用以下8维性能向量总结策略质量:
每个组件都与理想的策略结果正相关;最大回撤(MDD)取负值以与该方向保持一致。
给定先验、,该算法从每个动作的 posterior 中采样奖励系数向量,估计当前上下文下的奖励,并选择具有最高采样值的动作。随后,使用标准的贝叶斯线性回归更新来更新 posterior。


B 量化研究流程的正式定义
基于量化金融领域的几项经典研究,我们将原始数据集定义为具有双重时间索引的三维张量,记为 。该数据集以股票为基础资产类别,每个资产都关联一组因子维度。如公式(2)所正式定义,该张量包含个资产在观测期内的数据:行索引对应时间,列索引对应资产,通道索引对应个因子维度中的一个。每个元素表示资产在时间的第个因子值。
新因子通过解析方法或机器学习方法基于原始因子特征构建。给定长度为的滑动窗口,如公式(3)所定义的映射会生成新因子,其中表示资产最近天的张量切片,是第个衍生因子。新因子张量由原始因子和生成因子拼接而成,如公式(4)所示,其中表示在处的拼接向量。
鉴于金融数据的噪声性和不完整性,采用两阶段预处理流程来抑制异常值的影响。首先,对每个特征应用横截面稳健z分数归一化,如公式(5)所示,其中MAD是中位数绝对偏差,是数值稳定性常数。其次,采用“前向填充+横截面均值”策略填充缺失值,如公式(6)所正式定义。
资产收益被定义为训练和验证的预测目标,记为,本文中个交易日,如公式(7)所示。与因子预处理类似,缺失标签会被移除,并且每个交易日会对收益进行横截面分数归一化,得到有监督样本对。
是资产在时间的收盘价
为更好地封装因子与模型之间的交互接口,预测值由预测器统一生成,如公式(9)所定义,其中表示可学习参数。该预测器同时支持表格模型(以为输入)和时间序列模型(以张量切片为输入以捕捉时间结构)。
模型训练遵循滚动验证流程,通过梯度下降最小化均方误差损失(公式(10)),以将参数优化至。
该流程涵盖四个基本组件——数据表示、特征工程、样本构建和模型训练,为RD-Agent(Q)框架中的因子-模型双循环优化机制提供了标准化输入接口。
C 实验细节
C.1 实现设置
硬件设置:所有实验均在专用服务器上进行,该服务器配备双Intel Xeon Gold 6348 CPU(共112线程)和四块NVIDIA RTX A6000 GPU(每块显存48 GiB,总显存192 GiB)。
评估协议:所有模型在一致的数据集划分上进行训练和验证,以确保公平比较。对于每个基线模型,进行了广泛的超参数调优,并使用五个不同的随机种子进行独立运行以评估稳健性。我们报告这些运行的年化收益率(ARR)中位数,而非标准误差棒或置信区间。这符合量化金融实践——在该领域,持续跑赢基准比单点方差更受重视。使用中位数还能减少异常值的影响。
框架配置:实验基于RD-Agent框架进行。RD-Factor自动化因子设计和评估,RD-Model优化预测模型。每个模块每次实验运行6小时。联合框架RD-Agent(Q)在两者间交替运行,总时长12小时。全程启用持久缓存,以加速对中间输出(包括每轮循环中参考的SOTA因子库)的重复访问。
参数配置:实验中使用了多种LLM API后端。对于GPT-4o和GPT-4o-mini,启用流式传输,温度设置为0.8,tokens使用上限为4096。对于o3-mini、o3和GPT-4.1,禁用流式传输,温度为1.0,允许最多10,000个令牌。所有API交互均使用来自用户角色的统一系统提示,并根据后端能力进行调整。在Co-STEER模块(实现单元)中,我们使用text-embedding-ada-002 计算代码、假设和日志分析的语义嵌入。为确保细粒度调试的效率,Co-STEER中的内部优化循环在因子和模型工作流中每任务上限为10次迭代。对于每个任务,实现单元的最大运行时间设置为600秒,验证单元为3600秒。
C.2 数据集
本文不提出新数据集。基线因子库Alpha 20如表4所示。用于因子挖掘的原始金融数据可分为两类:市场数据 和 基本面数据。
- 市场数据可使用以下脚本生成:https://github.com/microsoft/RD-Agent/blob/main/rdagent/scenarios/qlib/experiment/factor_data_template/generate.py;
- 基本面数据包括盈利能力、估值和增长指标等标准财务指标,如表5所示。
表5:RD-Agent(Q)中用于因子挖掘的基本面数据字段。这些字段可通过在Wind终端(https://www.wind.com.cn/mobile/WFT/en.html)中搜索其名称获取。
| 类别 | 描述 |
|---|---|
| 盈利能力 | |
| ROE_TTM | 净资产收益率(Return on Equit,TTM) |
| ROA_TTM | 资产收益率(Return on Assets,TTM) |
| ROIC | 投入资本回报率(Return on Invested Capital) |
| EBIT_EV | 息税前利润/企业价值(EBIT / Enterprise Value) |
| EBITDA_EV | 息税折旧摊销前利润/企业价值(EBITDA / Enterprise Value) |
| NET_PROFIT_YOY | 净利润同比增长率(Net Income Year-over-Year Growth) |
| NET_PROFIT_YOY_Q | 净利润季度同比增长率(Net Income YoY Growth (Quarterly)) |
| NET_PROFIT_MARGIN | 净利润率(Net Profit Margin) |
| NET_PROFIT_MARGIN_TTM | 净利润率(Net Profit Margin,TTM) |
| GROSS_PROFIT_MARGIN_TTM | 毛利率(Gross Profit Margin,TTM) |
| 增长能力 | |
| NET_PROFIT_YOY_TTM | 净利润增长率(Net Profit Growth,TTM) |
| OPER_REV_YOY_TTM | 营业收入增长率(Revenue Growth,TTM) |
| OPER_REV_YOY | 营业收入同比增长率(Revenue Year-over-Year Growth) |
| OPER_PROFIT_YOY | 营业利润同比增长率(Operating Profit Year-over-Year Growth) |
| OPER_REV_YOY_Q | 营业收入季度同比增长率(Revenue YoY Growth (Quarterly)) |
| OPER_REV_QOQ | 营业收入季度环比增长率(Revenue Quarter-over-Quarter Growth) |
| OPER_PROFIT_QOQ | 营业利润季度环比增长率(Operating Profit QoQ Growth) |
| NET_PROFIT_QOQ | 净利润季度环比增长率(Net Profit QoQ Growth) |
| EST_OPER_REV_CHANGE_1M | 预测营业收入变化(Forecast Revenue Change (1M),1个月) |
| EST_OPER_REV_CHANGE_3M | 预测营业收入变化(Forecast Revenue Change (3M),3个月) |
| 估值指标 | |
| EP_TTM | 市盈率(Earnings-to-Price Ratio,TTM,盈利/价格) |
| BP | 账面价格比(Book-to-Price Ratio,账面/价格) |
| EP_FY1 | 远期市盈率(Forward Earnings-to-Price Ratio,盈利/价格) |
| BP_FY1 | 远期账面价格比(Forward Book-to-Price Ratio,账面/价格) |
| CFO_TO_PRICE_TTM | 现金流/价格(Cash Flow-to-Price Ratio,TTM) |
| OCF_TO_MKT_CAP | 经营现金流/市值(Operating Cash Flow / Market Cap) |
| OCF_TO_PRICE_TTM | 经营现金流/价格(Operating Cash Flow-to-Price Ratio,TTM) |
| 风险与波动率 | |
| VOLATILITY_1M | 1个月波动率(1-Month Volatility) |
| VOLATILITY_3M | 3个月波动率(3-Month Volatility) |
| VOLATILITY_1Y | 12个月波动率(12-Month Volatility) |
| BETA_1Y | 市场贝塔(Market Beta (12-Month),12个月) |
| IDIOSYNCRATIC_VOLATILITY | 特质波动率(Idiosyncratic Volatility) |
| 质量指标 | |
| INTEREST_COVERAGE | 利息覆盖率(Interest Coverage Ratio) |
| CFO_TTM | 经营现金流(Cash Flow from Operations (TTM)) |
| CFO_Q | 经营现金流(Cash Flow from Operations (Quarterly)) |
| CFO_TO_OPER_REV_TTM | 经营现金流/营业收入(Operating Cash Flow / Revenue (TTM)) |
| NET_PROFIT_MARGIN | 净利润率(Net Profit Margin) |
| ASSET_TURNOVER_TTM | 资产周转率(Asset Turnover (TTM)) |
| FIXED_ASSET_TURNOVER_TTM | 固定资产周转率(Fixed Asset Turnover (TTM)) |
| 情绪与资金流 | |
| MID_ORDER_BUY_AMT | 中等订单主动买入金额(Medium Order Active Buy Amount) |
| MID_ORDER_SELL_AMT | 中等订单主动卖出金额(Medium Order Active Sell Amount) |
| RATING_UPGRADE | 分析师评级上调(Analyst Rating Upgrade) |
| RATING_DOWNGRADE | 分析师评级下调(Analyst Rating Downgrade) |
| ANALYST_MOMENTUM_SCORE | 分析师动量得分(Analyst Momentum Score) |
| 动量指标 | |
| RETURN_1M | 30天收益率(30-Day Return) |
| RETURN_2M | 60天收益率(60-Day Return) |
| RETURN_3M | 90天收益率(90-Day Return) |
| RETURN_6M | 182天收益率(182-Day Return) |
| RETURN_1Y | 365天收益率(365-Day Return) |
C.3 Baselines
在基准实验中,基于因子的实验使用LightGBM模型,基于模型的实验使用Alpha 20因子库。
机器学习模型:
- 线性模型(Linear Model):最基础的线性回归模型,用于建模特征与目标变量之间的线性关系。可解释性强,复杂度低,作为模型预测性能的下界基准。
- 多层感知器(MLP):前馈神经网络架构,包含一个或多个非线性隐藏层,适用于建模特征间的非线性关系。
- LightGBM[39]:基于梯度提升框架的树模型。采用基于直方图的分裂方法和叶节点优先生长策略,训练速度快,内存占用低。源代码见:https://github.com/microsoft/LightGBM。
- XGBoost[44]:增强树模型,利用二阶梯度优化、剪枝和正则化策略提高泛化能力和稳健性。源代码见:https://github.com/dmlc/xgboost。
- CatBoost[45]:针对分类特征优化的提升树模型。采用有序提升策略减少预测偏差,适用于多种结构化数据建模任务。源代码见:https://github.com/catboost/catboost。
- DoubleEnsemble[46]:整合多个异质模型,结合样本重加权和特征选择机制以提高准确性和稳健性。源代码见:https://github.com/microsoft/qlib/tree/main/examples/benchmarks/DoubleEnsemble。
深度学习模型:
- 通用深度学习模型
- Transformer[48]:利用多头自注意力机制捕捉时间序列数据中的长程依赖。并行处理整个序列,比循环结构更具可扩展性。
- GRU[22]:门控循环单元,通过引入更新门和重置门简化传统循环神经网络,提高训练效率并缓解梯度消失问题。
- LSTM[23]:长短期记忆网络,循环神经网络的一种变体,包含记忆单元和门控机制,能有效建模长期依赖关系。是时间序列建模的标准方法之一。
- ALSTM[47]:LSTM模型的增强版本,整合注意力机制,使模型能聚焦关键时间步并选择性地建模序列特征。
- GATs[52]:图注意力网络,将注意力机制扩展到图结构,能建模非欧几里得空间中节点间的关系。
- 时间序列预测模型
- PatchTST[49]:基于Transformer的时间序列模型,采用分块和通道独立技术。支持跨数据集的有效预训练和迁移学习。源代码见:https://github.com/yuqinie98/PatchTST。
- iTransformer[50]:基于Transformer的时间序列模型,将每个时间序列嵌入为变量令牌,提高参数效率和建模精度。适用于长序列建模任务。源代码见:https://github.com/thuml/iTransformer。
- Mamba[51]:基于状态空间模型的下一代长序列模型,支持并行计算和线性时空复杂度。
- 股票预测模型
- TRA[37]:在Transformer架构中引入新颖的动态路由机制,使模型能自适应学习股票价格的时间模式,提高对多样市场趋势的捕捉能力。源代码见:https://github.com/TongjiFinLab/THGNN。
- MASTER[38]:以市场为中心的Transformer模型,旨在动态建模股票间的瞬时和跨时间相关性,从而提高趋势预测准确性。源代码见:https://github.com/SJTU-DMTai/MASTER。
- 因子库:
- Alpha 101:WorldQuant团队2015年提出的101个公式化交易阿尔法因子集合。基于每日价量数据构建,是量化金融领域早期公开的结构化阿尔法因子基准。
- Alpha 158:微软Qlib团队提出的因子库,包含158个传统技术指标(如MA、RSI),通过不同时间窗口(如5、10、20天)的组合构建。
- Alpha 360:微软Qlib提供的更全面的因子库,包含360个因子,通过对历史价格序列的归一化处理(如收盘价和成交量的多周期相对值)构建。
- AutoAlpha:由大语言模型驱动的动态结构化因子库,整合文本、数值和图像等多模态数据。

C.4 评估细节
C.4.1 指标
我们采用两类指标:因子层面的预测性能和策略层面的组合收益。
信息系数(Information Coefficient,IC):IC衡量预测排名与实际收益排名之间的横截面相关性。在量化金融中广泛使用,定义为:
其中和分别表示预测排名和实际排名;为期望,为标准差。在实践中,IC按日计算,并以其时间均值报告。
信息系数信息比率(Information Coefficient Information Ratio,ICIR):ICIR评估IC随时间的稳定性,定义为每日IC值的均值与标准差之比:
ICIR越高,表明交易日间的预测排名一致性越强。
排名IC(Rank IC):排名IC指预测收益排名与实际收益排名之间的斯皮尔曼等级相关系数。对异常值稳健,特别适用于具有厚尾或极端值的分布。
排名ICIR(Rank ICIR):与ICIR类似,排名ICIR衡量排名IC的时间稳定性:
是评估基于因子的排名模型长期一致性的关键指标。
年化收益率(Annual Return Ratio,ARR):ARR反映组合的复合年增长率:
其中表示每日收益率,为总交易日数。
信息比率(Information Ratio,IR):IR通过比较基准之上的年化收益均值与标准差来评估风险调整后的超额收益:
其中表示基准收益率,通常为无风险利率或市场收益率。
最大回撤(Maximum Drawdown,MDD):MDD衡量评估期内从峰值到谷值的最大损失,捕捉下行风险:
其中为第天的组合价值,为评估周期。
卡尔玛比率(Calmar Ratio):卡尔玛比率量化相对于下行风险的收益,定义为:
卡尔玛比率越高,表明单位最大损失对应的收益越好,适用于评估强调回撤控制的策略。
C.4.2 交易策略
完整交易策略模拟如下:
- 在交易日收盘时,模型基于预测收益为每只股票生成排名分数。
- 在交易日开盘时,交易者卖出日的所有持仓,根据预测收益选择排名前50的股票构建新组合。排除表现最差的5只股票。
- 持续排名靠前的股票保留在组合中,以支持优质资产的长期持有。
- 交易执行时,价格限制阈值为0.095。交易以收盘价执行,买入成本0.05%,卖出成本0.15%,每笔交易最低手续费5元。
D 补充实验
D.1 消融分析
表6展示了RD-Agent(Q)框架在两种LLM后端(GPT-4o和o3-mini)上的扩展消融研究。我们评估了组件级别的贡献,并比较了三种用于动作选择的调度策略:随机调度、基于LLM的调度和上下文老虎机调度。
表6:RD-Agent(Q)框架的消融研究。上方行展示了通过禁用因子生成或模型生成进行的组件级消融。下方行比较了RD-Agent(Q)中的动作选择策略:随机、基于LLM和老虎机。指标包括因子预测能力(IC、ICIR)、策略性能(ARR、MDD)和执行统计(TL:总循环数;VL:有效循环数;SL:SOTA选择数;TRH:总运行时间(小时))。
| 模型 | 因子预测能力指标 | 策略性能指标 | 执行指标 |
|---|---|---|---|
| IC | ICIR | ARR | |
| GPT-4o | |||
| 组件消融 | RD-Factor | 0.0489 | 0.4050 |
| RD-Model | 0.0326 | 0.2305 | |
| 算法消融 | RD-Agent(Q)(随机) | 0.0318 | 0.2431 |
| RD-Agent(Q)(LLM) | 0.0523 | 0.4172 | |
| RD-Agent(Q)(老虎机) | 0.0497 | 0.4069 | |
| o3-mini | |||
| 组件消融 | RD-Factor | 0.0497 | 0.3931 |
| RD-Model | 0.0469 | 0.3688 | |
| 算法消融 | RD-Agent(Q)(随机) | 0.0445 | 0.3589 |
| RD-Agent(Q)(LLM) | 0.0476 | 0.3891 | |
| RD-Agent(Q)(老虎机) | 0.0532 | 0.4278 |
组件消融结果显示:移除模型分支(即RD-Factor)在IC、ICIR和ARR上的表现始终优于移除因子分支(即RD-Model)。这反映了两方面影响:(i)在严格的运行时间限制下,因子优化能实现更快的迭代和更丰富的信号发现;(ii)在流程早期,改进特征比调优模型的影响更大。尽管如此,RD-Model仍有助于组合层面的风险平滑(例如,在o3-mini下实现更低的MDD)。
算法消融结果显示:对于调度策略,随机选择在两种模型上的性能均最低。基于LLM的决策提升了预测质量,但存在规划不稳定性。老虎机调度器在IC、ARR和有效循环数上始终优于其他方案,表明其通过适应不断变化的性能信号,能实现更高效的资源分配。
总体而言,结果凸显了因子分支是信号质量的主要驱动因素,模型分支是风险稳定器,而老虎机调度器是在有限时间和计算预算下平衡权衡的高效机制。
D.2 因子库分析
图10展示了因子效果评估实验的完整结果。除信息系数(IC,子图(a)和(c))外,子图(b)和(d)显示排名IC(Rank IC)也有持续提升,证实RD-Factor不仅提高了绝对预测精度,还改善了股票收益的相对排名。特别是在基于Alpha 158初始化的情况下,o3-mini版本的排名IC在2020年保持在0.07以上,而传统因子库则大幅下降。这支持了迭代优化能同时提升信号强度和跨市场状态排名一致性的观点。
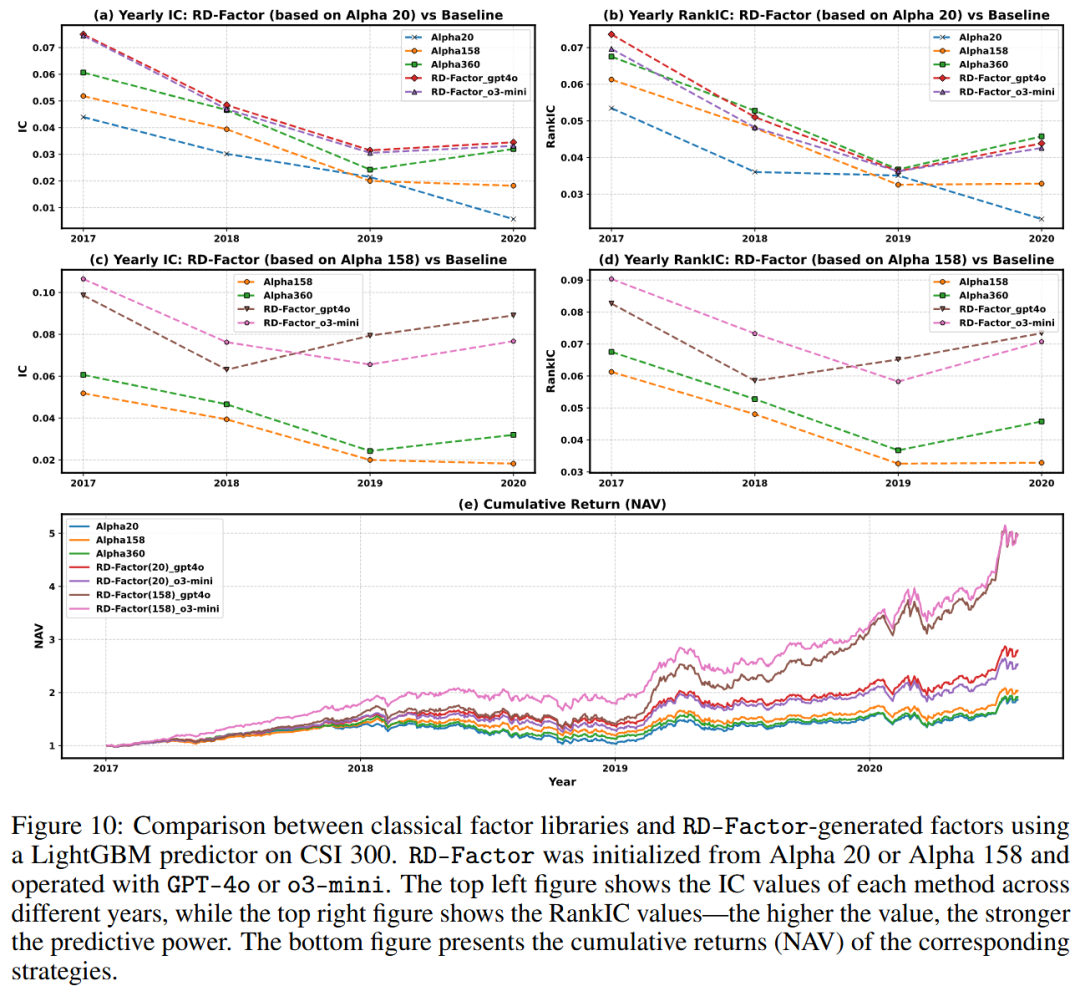
图10:在沪深300数据集上,使用LightGBM预测器比较传统因子库与RD-Factor生成的因子。RD-Factor从Alpha 20或Alpha 158初始化,并使用GPT-4o或o3-mini运行。左上子图显示各方法在不同年份的IC值,右上子图显示排名IC值——值越高,预测能力越强。下方子图展示了相应策略的累计收益(净值)。
在累计收益(子图(e))方面,2018年初开始出现性能分化。RD-Factor(158)生成的因子集始终优于其他因子库,到2020年第三季度净值超过5.1。即使是RD-Factor(20)配置也超过了Alpha 360,表明因子数量多并不一定带来更高收益。传统因子库因因子冗余导致波动性增加。相比之下,RD-Factor通过动态筛选缓解了这一问题,实现了更稳定且资本效率更高的表现。
这些结果凸显了RD-Factor在信息效率(用更少因子实现更高IC/排名IC)和资本效率(实现更优净值)方面的双重优势。无论从紧凑还是高维的基础因子库开始,其迭代优化流程都能可靠地发现有效信号并去除冗余,为后续模型优化和RD-Quant中的全栈协同进化奠定坚实基础。
D.3 Co-STEER有效性分析
作为RD-Agent(Q)开发阶段的关键组件,除第4节描述的Co-STEER在RD-Agent(Q)框架内的直接实现外,我们还进行了进一步实验以验证Co-STEER的能力。具体而言,我们希望回答以下研究问题:
- RQ1:与最新的代码生成基线相比,Co-STEER在为金融任务生成可执行且语义正确的代码方面表现如何?
- RQ2:在受限计算预算下,其进化调度器能否提高实现效率和输出质量?
数据集:我们在RD2Bench上评估Co-STEER,这是一个面向金融领域数据中心智能体系统的综合基准。该基准包含27个可实现因子和13个不可实现因子,涵盖基本面、价量和高频类别。每个因子都面临独特挑战,需要对异构金融数据源进行复杂推理,并在严格约束下生成可执行的Python代码。
基线:我们采用少样本[69]、CoT[70]、Reflexion[71]、自我调试[73]和自我规划[72]作为基线。详见A.1节。
指标:我们引入四个评估指标:平均执行率、平均格式正确率、平均相关性和最大相关性。平均执行率衡量代码执行的平均成功率;执行过程中遇到的任何错误都计为0。平均格式正确率衡量生成代码符合正确格式的程度(例如列名是否符合预期)。平均相关性反映模型生成的代码输出序列与真实结果之间的平均相关性——例如,在相同输入特征下,评估大语言模型生成的因子与实际实现生成的因子之间的相关性。最大相关性表示模型生成的代码输出序列与真实结果之间的最高相关性。
方法实现结果(RQ1):
表7的实验结果表明,在27个测试案例中,Co-STEER在所有评估指标上的实现能力均优于其他方法。这一性能优势源于两个关键创新:动态知识扩展和上下文检索。尽管Reflexion和自我调试都利用环境反馈(表3),但Co-STEER独特地积累和检索跨实现的实践经验。与仅考虑即时反馈的现有方法不同,Co-STEER通过持续实践构建全面的知识库,有效弥合初级工程师与高级工程师之间的专业差距。这种系统化的知识积累和检索机制使Co-STEER在各种实现场景中都能实现显著的性能提升。
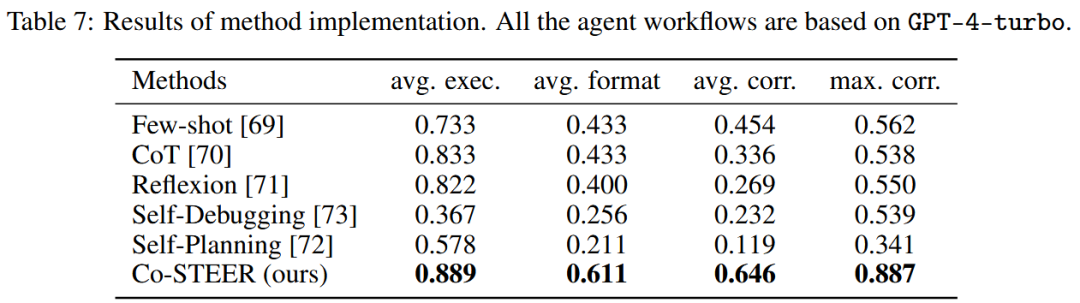
表7:方法实现结果。所有智能体工作流均基于GPT-4-turbo。
整体性能分析(RQ2):我们在资源受限环境中评估Co-STEER的有效性——在该环境中,智能体必须在有限的实现尝试下优化40个候选方法(27个可实现,13个不可实现)的性能。这种设置模拟了现实世界的计算约束,并测试了调度与实现能力之间的协同作用。表8呈现了比较结果,揭示了实际约束下系统性能的几个关键见解。
①进化调度提高任务有效性:表8显示,在所有top-k阈值下,进化调度器的表现始终优于随机基线。这凸显了其通过识别任务复杂度和依赖关系来学习有效执行顺序的能力。通过随时间积累经验,系统建立了一种工程直觉,使其能够优先处理更简单或更基础的任务,为后续代码生成提供信息丰富的框架。
②更多资源带来更强泛化能力:随着预算增加,两种调度器都能受益,但进化策略的增益更大。与早期就趋于稳定的自我修正方法不同,进化过程通过检索和优化过去的尝试(无论初始试验是否成功)持续改进。这种调度器与实现之间的协同进化使系统能在实际约束下高效适应。
表8:在top-k评估(k=5,10,15,20)下Co-STEER与随机调度器和进化调度器的比较。指标包括执行成功率(exec.)、格式正确率、与真实结果的相关性(平均和最大)。
D.4 成本效率分析
图11比较了在固定运行时间设置下GPT-4o和o3-mini的令牌支出。因子任务每循环的成本更高,因其具有多阶段结构——涵盖多个候选的假设生成、实现和分析;而模型任务更简单且成本更低,因为每个循环仅生成一个模型。GPT-4o和o3-mini在模型和量化设置中的每循环成本相近。因子任务中的较大差距源于o3-mini每循环生成更复杂的假设(产生更多样化的因子类型并处理更困难的实现),导致成本更高。尽管存在这些差异,两种后端在所有RD-Agent(Q)工作流中的总成本均保持在10美元以下(见附录C.1),证实了该框架在可扩展、自动化量化研究中的成本效益。
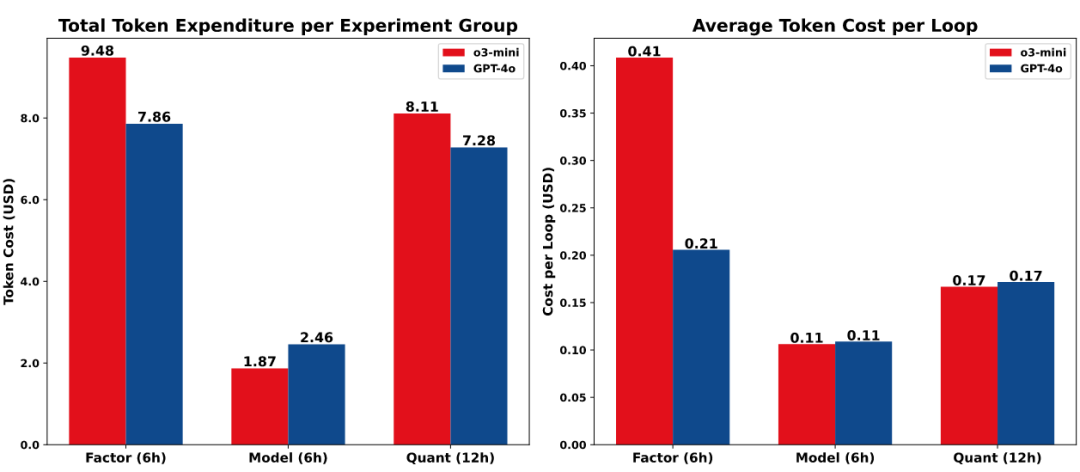
图11:不同大语言模型后端的令牌成本(5次试验的平均值)。左:对应运行时间的总成本(RD-Factor/RD-Model为6小时,RD-Agent(Q)为12小时);右:每循环的平均成本。所有成本单位为美元。
D.5 真实世界量化竞赛分析
为进一步探索RD-Agent(Q)框架的潜力,我们将其用于Kaggle上的Optiver实际波动率预测[76]竞赛。这是一项预测竞赛,重点是使用高粒度金融数据预测数百只股票的短期波动率。竞赛要求参与者使用10分钟时间窗口内收集的信息预测一组股票的实际波动率,涉及处理经典的表格时间序列数据并优化均方根百分比误差(RMSPE)指标。
如图12所示,RD-Agent(Q)在第12次实验中取得最佳性能。根据实验总结,该实验基于以下假设:通过捕捉不同时间窗口内买卖价差的时间演化,可增强模型预测股票短期波动率的能力。具体实现包括计算多个时间窗口(5秒、10秒和30秒)内买卖价差的滚动均值和标准差,以有效捕捉市场微观结构的动态特征。总体而言,从第3轮的模型优化到第8轮和第12轮的因子调优,RD-Agent(Q)通过持续实验和探索发现,捕捉买卖价差动态的时间特征对该金融任务最有效。这也表明,RD-Agent(Q)能在多种可能的建模方法中探索,并通过实证评估(而非仅依赖直觉或预设策略)合理识别最有前景的方向。此外,RD-Agent(Q)框架能适应各种量化金融任务,并表现出较好的性能。
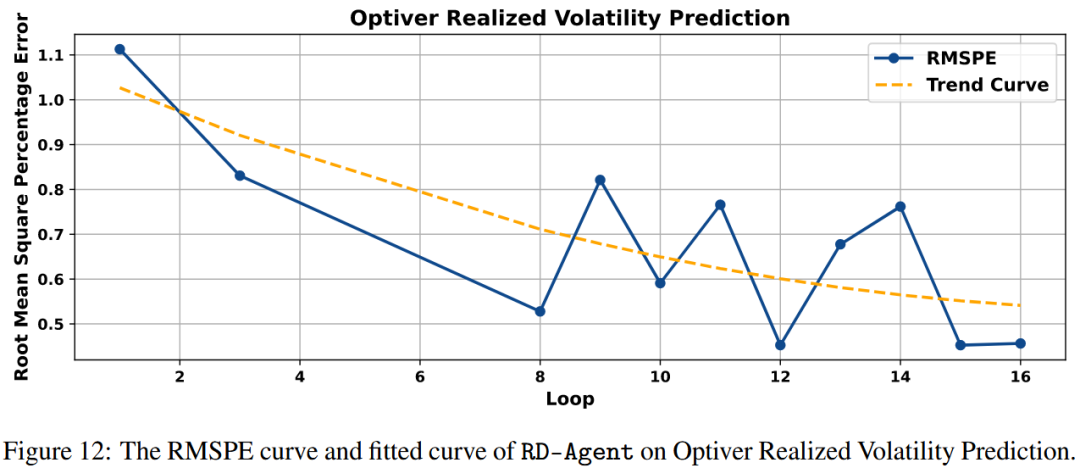
图12:RD-Agent在Optiver实际波动率预测中的RMSPE曲线和拟合曲线。
RD-Agent在Optiver实际波动率预测竞赛中生成的假设
实验循环索引1
动作:构建流程
假设:/
结论:/
实验循环索引2
动作:模型
假设:引入梯度提升模型(如LightGBM)并优化超参数,将优于当前的线性回归模型和集成策略。
结论:失败。
实验循环索引3
动作:模型
假设:用LightGBM模型替代线性回归模型并使用早停策略,通过更好地捕捉复杂模式来提升性能。
结论:成功。
...
实验循环索引8
动作:因子
假设:纳入捕捉买卖价格相互作用的特征(如买卖价差和订单失衡),将增强模型预测股票短期波动率的能力。
结论:成功。
...
实验循环索引12
动作:因子
假设:纳入捕捉不同时间窗口内买卖价差时间演化的特征,将增强模型预测股票短期波动率的能力。
结论:成功。
E 提示词设计
E.1 规格单元
如2.1节所述,规格单元负责基于当前优化目标动态生成元组。下游单元根据其功能角色选择性访问的组件——例如,合成单元和分析单元通常使用、和,而实现单元依赖、和。
下面,我们提供因子优化和模型优化两种设置下的完整规格元组。
规格提示——因子导向
你是华尔街顶级对冲基金中最权威的量化研究员之一。我需要你的专业知识来设计和实现新的因子或模型,以提高投资回报。
这次,我需要你协助因子的研发工作。
**场景背景**
- 名称:因子名称。
- 描述:因子逻辑说明。
- 公式:数学表达式。
- 变量:所有使用的变量或中间函数。
请清晰列出所有超参数,如回溯期、窗口大小等。每个因子必须使用静态数据源生成一个输出。不同的参数设置视为不同的因子。
**源数据集**
daily_pv.h5
- 类型:HDF5
- 索引:多层索引 [datetime, instrument]
- 列:$open、$high、$low、$close、$volume、$factor...
**输出格式**
- 可通过以下命令执行的Python文件:python {your_file_name}.py
- 包含:导入部分、函数部分和一个名为calculate_{function_name}的主函数。
- 在以下条件下调用:if __name__ == "__main__"
- 不要使用try-except语句。
输出:将计算得到的因子保存为result.h5,格式为pandas DataFrame,索引为[datetime, instrument],包含一列以因子命名的列。
**工作流机制**
1. Qlib根据因子值生成特征表。
2. 训练模型(如LightGBM、LSTM、GRU)以预测未来收益。
3. 根据预测收益构建投资组合。
4. 评估性能(收益、夏普比率、最大回撤等)。
规格提示——模型导向
你是华尔街顶级对冲基金中最权威的量化研究员之一。我需要你的专业知识来设计和实现新的模型,以提高投资回报。
这次,我需要你协助模型的研发工作。
**场景背景**
模型是量化投资中使用的机器学习或深度学习结构,用于预测投资组合或单个资产的收益和风险。模型基于历史数据和提取的因子生成预测,是许多量化投资策略的核心。
每个模型以因子值为输入,预测未来收益。模型通过固定的架构和超参数定义,以确保可复现性和一致性。
每个模型应包含以下组件:
- 名称:模型名称。
- 描述:模型逻辑和用途说明。
- 架构:模型的内部结构(如LSTM层、MLP、决策树)。
- 超参数:与模型结构相关的所有超参数。
- 训练超参数:训练中使用的超参数(如学习率、批大小)。
- 模型类型:“Tabular”(表格)或“TimeSeries”(时间序列)之一,用于指示输入格式。
模型必须输出一个预测收益值。不同的超参数集定义不同的模型。
**源数据集**
daily_pv.h5
- 类型:HDF5
- 索引:多层索引 [datetime, instrument]
- 列:$open、$high、$low、$close、$volume、$factor...
**输出格式**
- 名为model.py的Python文件,包含PyTorch模型定义。
- 包含以下部分:
- 导入部分:仅导入必要的库(如torch、torch.nn)。
- 模型类:torch.nn.Module的子类,实现__init__和forward方法。
- 模型接口:必须将名为model_cls的变量赋值给定义的模型类。
- 模型必须遵循以下接口约束:
- 对于表格输入:输入形状 = (batch_size, num_features)。
- 对于时间序列输入:输入形状 = (batch_size, num_timesteps, num_features)。
- 输出形状必须为(batch_size, 1)。
- 模型必须仅使用当前输入张量,不进行外部数据加载或保存。
- 不传递其他参数;模型必须接受以下参数之一:(num_features)或(num_features, num_timesteps)。
- 不包含任何try-except块。
- 不包含任何训练、推理或保存逻辑。
- 用户将通过以下方式导入模型类:from model import model_cls
**工作流机制**
1. Qlib根据因子值生成特征表。
2. 训练模型(如LightGBM、LSTM、GRU)以预测未来收益。
3. 根据预测收益构建投资组合。
4. 评估性能(收益、夏普比率、最大回撤等)。
E.2 合成单元
在收到规格单元动态组装的规格元组后,合成单元利用其不断演化的知识森林提出新假设,然后将其分解为可执行的研究任务。
以下是优化目标为因子时使用的提示词:
假设合成提示——因子导向
System prompt:
背景信息……(来自规格单元)
用户提出了几个假设并进行了评估。你的任务是分析这些试验,找出那些标记为“成功”的假设为何成功,以及标记为“失败”的假设为何失败。然后提出改进方法——要么优化现有方法,要么探索新方法。
如果反馈中已提供新假设且你同意,可直接复用。否则,生成一个改进的假设。
**假设生成指南**
1. 每次生成应产生1-5个因子。平衡简单性和复杂性;利用所有可用的金融数据。
2. 从简单、易于实现的因子开始。初期避免复杂或组合因子。清晰解释其原理。
3. 逐步增加复杂性。仅在简单因子得到验证后,再引入高级或组合因子。
4. 如果多次迭代未能超越SOTA,从新方向重新开始,从简单因子逐步优化。
5. 记录超越SOTA的因子,避免重复实现。
**输出格式(JSON Schema)**:
\```json
{
"action": "factor",
"hypothesis": "基于提供的信息生成的新假设。",
"reason": "对新假设的详细解释。"
}
\```
User Prompt
以往的假设及相应反馈如下:
**试验1**
动作:factor
假设:使用每日价格和成交量数据开发简单的动量因子和价量因子。
理由:动量因子和价量因子在量化投资中简单且有效。它们捕捉潜在趋势和交易活动,可能预示未来收益。测试这些简单因子将提供性能基准,并有助于在后续迭代中发现更复杂因子开发的潜在机会。
具体因子:
factor_name: 10_day_momentum
factor_description: [动量因子] 动量因子捕捉近期表现良好的股票在短期内继续表现良好的趋势。具体而言,该因子计算过去10天的收益。
factor_formulation: MOM10 = (Pt / Pt−10) − 1
factor_name: 10_day_volatility
factor_description: [价量因子] 平均成交量因子计算过去10天的平均成交量,反映交易活动水平。较高的成交量可能预示更强的价格波动。
factor_formulation: VOL10 = std(Rt−i),i = 0...9
...
观察:在给定假设下,新开发的动量因子和价量因子显示出良好结果。所有已实现的因子持续带来超越先前SOTA的性能。具体而言,信息系数(IC)和年化收益均有改善,这是评估预测模型有效性的关键指标。但需注意,最大回撤较SOTA基准有所恶化。
评估:结果支持“简单的动量因子和价量因子可提升量化投资模型性能”这一假设。IC和年化收益的显著改善表明,这些因子有效捕捉了股票表现的潜在模式和趋势。
决策:成功
**试验2**
SOTA假设及相应反馈如下:
- 动作:factor
- 假设:...
- 理由:...
- 具体因子:...
- 观察:...
- 评估:...
- 决策:成功
上一个假设及相应反馈如下:
- 动作:factor
- 假设:...
- 理由:...
- 具体因子:...
- 观察:...
- 评估:...
- 决策:...
新假设(来自分析单元,供参考):...
- 理由:...
**示例输出**:
\```json
{
"action": "factor",
"hypothesis": "整合现有动量因子、价量因子和波动率因子的高级变体及组合。引入累积收益、换手率或波动率聚类指标等因子,以进一步优化性能,同时可能减少回撤。",
"reason": "先前试验成功证明,基本的动量因子和价量因子可改善IC和年化收益等性能指标。但回撤增加表明可能需要更复杂的风险控制。通过使用高级变体(如因子组合和新风险指标),我们可优化收益并解决波动性问题。这与“更复杂的因子公式可增强预测性和收益稳定性”的反馈一致。"
}
\```
任务合成提示——因子导向
System Prompt
用户正基于上一步生成的假设生成新因子。这些因子用于特定场景,场景如下:
背景信息……(来自规格单元)
用户将使用生成的因子进行实验。用户将向你提供以下信息:
1. 你需要为其生成因子的目标假设。
2. 上一步生成的假设及其相应反馈。
3. 基于类似假设的先前提出的因子。
4. 帮助你生成新因子的其他信息。
**输出格式(JSON Schema)**:
\```json
{
"factor name 1": {
"description": "因子1的描述,以其类型开头,例如[动量因子]",
"formulation": "因子1的Latex公式",
"variables": {
"variable or function name 1": "变量或函数1的描述",
"variable or function name 2": "变量或函数2的描述"
}
},
"factor name 2": {
"description": "因子2的描述,以其类型开头,例如[基于机器学习的因子]",
"formulation": "因子2的Latex公式",
"variables": {
"variable or function name 1": "变量或函数1的描述",
"variable or function name 2": "变量或函数2的描述"
}
}
}
\```
User Prompt:
用户已针对该场景提出多个假设,并对其进行了多次评估。你需要为其生成因子的目标假设如下:
选择的动作:factor
假设:使用可用的每日价格和成交量数据开发简单的动量因子和价量因子。
理由:动量因子和价量因子在量化投资中简单且有效。它们捕捉潜在趋势和交易活动,可能预示未来收益。测试这些简单因子将提供性能基准,并有助于在后续迭代中发现更复杂因子开发的潜在机会。
先前的假设及相应反馈如下:
**示例输出**:
\```json
{
"cumulative_return_30_days": {
"description": "[动量因子] 该因子衡量股票过去30天的累积收益。它通过捕捉更长期的价格趋势,扩展了先前的动量因子。",
"formulation": "CR_{30} = \\prod_{i=0}^{29} (1 + R_{t-i}) - 1",
"variables": {
"R_{t-i}": "t-i时刻的日收益,定义为(P_{t-i} - P_{t-i-1}) / P_{t-i-1}"
}
},
"turnover_ratio_20_days": {
"description": "[价量因子] 该因子计算过去20天的平均日换手率,反映股票的流动性和交易活动。",
"formulation": "TR_{20} = \\frac{1}{20} \\sum_{i=0}^{19} \\frac{V_{t-i}}{\\text{Shares Outstanding}}",
"variables": {
"V_{t-i}": "t-i时刻的成交量",
"Shares Outstanding": "股票的总流通股数"
}
}
}
\```
E.3 实现单元
实现单元使用Co-STEER框架执行合成单元提出的任务,通过迭代优化将高层描述转换为可执行代码。这一过程涉及三个关键提示阶段:(i)代码合成:基于任务描述生成初始代码;(ii)日志分析:解析错误轨迹或输出以诊断问题;(iii)正确性验证:判断当前代码是否符合规格;若不符合,提示修改。
每个阶段都为自修正循环做出贡献,即使初始合成不完美,也能实现稳健执行。
实现提示——因子导向——代码实现
系统提示:
用户正尝试在以下场景中实现一些因子:
背景信息……(来自规格单元)
你的代码应以任何形式与场景对齐,这意味着用户需要通过你的代码获得预期的精确因子值。
为帮助你编写正确的代码,用户可能会提供多种信息:
1. 用户可能会提供类似因子的正确代码。你应借鉴这些代码编写正确的代码。
2. 用户可能会提供失败的先前代码及相应反馈。反馈包含执行情况、代码和因子值。你应分析反馈并尝试修正最新代码。
3. 用户可能会提供对最新失败代码的建议,以及一些类似的“失败-修正”对。每个对包含有类似错误的失败代码及相应的修正版本。你应借鉴这些建议编写正确的代码。
你必须基于下方你先前的最新尝试(包含你先前的代码和代码反馈)编写代码。你应仔细阅读先前尝试,且不得修改先前代码中正确的部分。
**输出格式(JSON Schema)**:
\```json
{
"code": "作为字符串的Python代码。"
}
\```
用户提示:
——目标因子信息:——
factor_name: ...
factor_description: ...
factor_formulation: ...
[注意]
1. 确保计算高效。尽可能优先使用向量运算;必要时,可考虑通过numba进行JIT编译以处理递归计算。
2. 若能提升性能,允许使用并行化技术(如Joblib、Dask)。
以下是一些类似组件任务的成功实现,供参考:
=====因子1:=====
factor_name: ...
factor_description: ...
factor_formulation: ...
=====代码:=====
# 文件路径:factor.py
<code>
=====因子2:=====
...
以下是一些类似组件任务的错误实现,供参考:
=====因子1:=====
factor_name: ...
factor_description: ...
factor_formulation: ...
=====代码:=====
# 文件路径:factor.py
<code>
=====因子2:=====
...
**示例输出**:
\```json
{
"code": "import pandas as pd\nimport numpy as np\n\ndef cumulative_return_30_days():\n..."
}
\```
系统提示:
用户将向你提供因子的信息。
你的工作是检查用户的代码是否与因子和场景对齐。
用户将提供Python源代码和执行错误信息(若执行失败)。
用户可能会提供真实代码供你提出批评。你不得以任何形式向用户泄露真实代码,但可使用它提供批评。
用户还比较了用户代码计算的因子值与真实代码计算的因子值。用户将向你提供一些比较两个输出的分析结果。你可能会发现代码中导致两个输出差异的错误。
若提供了真实代码,你的批评应仅考虑用户代码是否与真实代码对齐,因为真实代码肯定是正确的。若未提供真实代码,你的批评应考虑用户代码是否合理且正确。
请注意,你的批评不是供用户调试代码的。它们将发送给编码智能体以修正代码。因此,不要给出任何让用户检查的内容,如“请检查代码第XXX行”。
你的建议不应包含任何代码,只需清晰简洁的建议。请在回复中指出非常关键的问题,忽略不重要的问题以避免混淆。若代码中未发现重大问题,可回复“未发现批评点。”
你应对每个批评点提供改进建议,以帮助用户完善代码。
请按以下格式回复批评。输出示例结构如下:
批评1:针对批评点1的信息
批评2:针对批评点2的信息
用户提示:
=====因子信息:=====
factor_name: ...
factor_description: ...
factor_formulation: ...
=====Python代码:=====
# 文件路径:factor.py
<code>
=====执行反馈:=====
执行成功,无错误。
找到预期的输出文件。
=====因子值反馈:=====
源数据框仅包含一列,正确。
源数据框没有任何无穷值。
输出格式正确。数据框具有“datetime”和“instrument”的多层索引,包含一列因子名称,因子值为float32类型,可接受。结果符合要求。
生成的数据框为每日数据。
**示例输出1**:
未发现批评点。
**示例输出2**:
批评1:主要错误源于对分组数据应用滚动函数时的索引处理不正确。具体而言,...
批评2:处理成交量总和为空或为零的逻辑存在,但滚动应用中的逻辑需要与函数预期一致的索引。
系统提示:
用户已完成评估,并从评估器处获得一些反馈。
评估器运行了代码,获得了因子值数据框,并提供了关于用户代码和输出的多项反馈。你应分析反馈,并结合场景和因子描述,对评估结果做出最终决策。最终决策应说明因子是否实现正确;若决策为“否”,需包含详细反馈,说明原因和建议。
实现的最终决策基于以下逻辑:
1. 若数值与真实值在小公差范围内完全一致,则认为实现正确。
2. 若数值与真实值在IC或排名IC上具有高相关性,则认为实现正确。
3. 若未提供真实值,若代码执行成功(假设提供的数据正确),则认为实现正确。任何异常(包括主动抛出的异常)均视为代码缺陷。此外,代码反馈必须与场景和因子描述一致。
**输出格式(JSON Schema)**:
\```json
{
"final_decision": true,
"final_feedback": "最终反馈信息"
}
\```
用户提示:
=====因子信息:=====
factor_name: ...
factor_description: ...
factor_formulation: ...
=====Python代码:=====
# 文件路径:factor.py
<code>
=====执行反馈:=====
执行成功,无错误。
找到预期的输出文件。
=====因子值反馈:=====
源数据框仅包含一列,正确。
源数据框没有任何无穷值。
输出格式正确。数据框具有“datetime”和“instrument”的多层索引,包含一列因子名称,因子值为float32类型,可接受。结果符合要求。
生成的数据框为每日数据。
**示例输出**:
\```json
{
"final_decision": "True",
"final_feedback": "因子'10_day_momentum'已成功实现。代码执行无错误,生成的数据框符合指定要求。因子值以正确格式存储,鉴于动量因子的性质,其值看起来准确。"
}
\```
E.4 验证单元
验证单元不涉及任何提示词。
E.5 分析单元
如2.5节所述,分析单元不仅评估实验结果,还生成基于提示词的反馈以进行局部优化。每轮之后,它使用结构化提示词解释结果三元组,识别潜在失败原因,并生成针对特定弱点(如过拟合、泛化能力差、特征不稳定性)的短期假设。
这些优化后的假设作为上下文传递给合成单元,用于下一轮生成。分析单元基于局部、近期证据运作,而合成单元将这些建议与全局搜索记忆整合——在短期适应和长期发现之间实现互补平衡。
分析提示——因子导向
系统提示:
你将收到一个假设、多个带因子的任务、它们的结果以及SOTA结果。你的反馈应说明当前结果是否支持或反驳该假设,将其与先前SOTA(最先进水平)结果比较,并提出改进建议或新方向。
请理解以下操作逻辑,然后提供适合该场景的反馈:
1. 逻辑说明:
a) 所有在先前尝试中超越SOTA的因子都将纳入SOTA因子库。
b) 新实验将生成新因子,这些因子将与SOTA库中的因子组合。
c) 这些组合的因子将进行回测,并与当前SOTA比较,以实现持续迭代。
2. 发展方向:
a) 新方向:提出新的因子探索和开发方向。
b) 现有方向的优化:
- 建议对该因子进行进一步改进(可包括因子的进一步优化或提出与其更好组合的方向)。
- 避免重新实现先前的因子,因为那些超越SOTA的因子已纳入因子库,并将在每次运行中使用。
3. 最终目标:不断积累在每次迭代中超越SOTA的因子,以保持最佳SOTA。
请为未来的探索提供详细且有建设性的反馈。
**输出格式(JSON Schema)**:
\```json
{
"Observations": "你的总体观察结果",
"Feedback for Hypothesis": "与假设相关的观察结果",
"New Hypothesis": "你的新假设",
"Reasoning": "新假设的推理过程",
"Replace Best Result": "yes或no"
}
\```
用户提示:
目标假设:
整合现有动量因子、价量因子和波动率因子的高级变体及组合。引入累积收益、换手率或波动率聚类指标等因子,以进一步优化性能,同时可能减少回撤。
任务和因子:
cumulative_return_30_days:[动量因子] 该因子衡量股票过去30天的累积收益。它通过捕捉更长期的价格趋势,扩展了先前的动量因子。已实现。
turnover_ratio_20_days:[价量因子] 该因子计算过去20天的平均日换手率,反映股票的流动性和交易活动。未实现。
组合结果:
- IC:0.033412 vs SOTA IC:0.027691
- 年化收益:0.097140 vs SOTA:0.076871
- 最大回撤:-0.133149 vs SOTA:-0.075444
**示例输出**:
\```json
{
"Observations": "当前结果显示,与SOTA结果相比,信息系数(IC)和年化收益均有轻微改善。然而,最大回撤有所增加,表明风险可能上升。",
"Feedback for Hypothesis": "假设部分得到支持,因为引入因子的高级变体和组合确实使性能指标(特别是IC和年化收益)略有改善。但假设还旨在潜在减少回撤,而实际最大回撤增加,因此这一目标未实现。",
"New Hypothesis": "在因子组合的同时引入风险缓解技术,可改善收益指标,同时有效减少回撤。",
"Reasoning": "尽管高级组合在某些性能方面有所改善,但回撤增加表明需要更有效地平衡风险。考虑风险调整因子或纳入方差减少或分散化等策略,可进一步优化改进,同时维持或减少回撤。",
"Replace Best Result": "yes"
}
\```
因子已纳入因子库,并将在每次运行中使用。
3. 最终目标:不断积累在每次迭代中超越SOTA的因子,以保持最佳SOTA。
请为未来的探索提供详细且有建设性的反馈。
**输出格式(JSON Schema)**:
\```json
{
"Observations": "你的总体观察结果",
"Feedback for Hypothesis": "与假设相关的观察结果",
"New Hypothesis": "你的新假设",
"Reasoning": "新假设的推理过程",
"Replace Best Result": "yes或no"
}
\```
用户提示:
目标假设:
整合现有动量因子、价量因子和波动率因子的高级变体及组合。引入累积收益、换手率或波动率聚类指标等因子,以进一步优化性能,同时可能减少回撤。
任务和因子:
cumulative_return_30_days:[动量因子] 该因子衡量股票过去30天的累积收益。它通过捕捉更长期的价格趋势,扩展了先前的动量因子。已实现。
turnover_ratio_20_days:[价量因子] 该因子计算过去20天的平均日换手率,反映股票的流动性和交易活动。未实现。
组合结果:
- IC:0.033412 vs SOTA IC:0.027691
- 年化收益:0.097140 vs SOTA:0.076871
- 最大回撤:-0.133149 vs SOTA:-0.075444
**示例输出**:
\```json
{
"Observations": "当前结果显示,与SOTA结果相比,信息系数(IC)和年化收益均有轻微改善。然而,最大回撤有所增加,表明风险可能上升。",
"Feedback for Hypothesis": "假设部分得到支持,因为引入因子的高级变体和组合确实使性能指标(特别是IC和年化收益)略有改善。但假设还旨在潜在减少回撤,而实际最大回撤增加,因此这一目标未实现。",
"New Hypothesis": "在因子组合的同时引入风险缓解技术,可改善收益指标,同时有效减少回撤。",
"Reasoning": "尽管高级组合在某些性能方面有所改善,但回撤增加表明需要更有效地平衡风险。考虑风险调整因子或纳入方差减少或分散化等策略,可进一步优化改进,同时维持或减少回撤。",
"Replace Best Result": "yes"
}
\```
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献216条内容
已为社区贡献216条内容

所有评论(0)