dinov3 笔记2 架构
特征推论深度:24 层属于“大模型”级别(类似 ViT-Large)隐藏维度:1024高维特征表示,强大表达能力MLP 扩展比:4×标准设计使用 RoPE支持灵活分辨率,可能是 DINOv2 或后续改进版本LayerScale现代化训练技巧,提高收敛性和性能无分类头(Identity head)主要用于特征提取或下游任务微调特性说明类型自监督学习方法目标训练强大的视觉表示(无需标签)核心机制自蒸馏
https://www.bilibili.com/video/BV1sAamzBE9k
# examples of available DINOv3 models:
MODEL_DINOV3_VITS = "dinov3_vits16"
MODEL_DINOV3_VITSP = "dinov3_vits16plus"
MODEL_DINOV3_VITB = "dinov3_vitb16"
MODEL_DINOV3_VITL = "dinov3_vitl16"
MODEL_DINOV3_VITHP = "dinov3_vith16plus"
MODEL_DINOV3_VIT7B = "dinov3_vit7b16"
MODEL_NAME = "dinov3-vitl16-pretrain-lvd1689m"
from transformers import AutoImageProcessor, AutoModel
from transformers.image_utils import load_image
pretrained_model_name =os.path.abspath("E:\dinov3\model\dinov3-vitl16-pretrain-lvd1689m")
processor = AutoImageProcessor.from_pretrained(pretrained_model_name)
model = AutoModel.from_pretrained(pretrained_model_name, device_map="auto")
model.cuda()DinoVisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1024, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(rope_embed): RopePositionEmbedding()
(blocks): ModuleList(
(0-23): 24 x SelfAttentionBlock(
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attn): SelfAttention(
(qkv): LinearKMaskedBias(in_features=1024, out_features=3072, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(ls1): LayerScale()
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
(ls2): LayerScale()
)
)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(head): Identity()
)
这是一个 DinoVisionTransformer 模型的结构,看起来是基于 ViT (Vision Transformer) 架构,并结合了 DINO 自监督学习方法 的变体。它被设计用于视觉任务(如图像分类、特征提取等),特别是可能用于自监督学习或作为目标检测/分割模型的主干网络。
下面我们逐层分析这个模型的结构和功能:
1. patch_embed: Patch Embedding
python
深色版本
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1024, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)- 作用:将输入图像分割成固定大小的 patch,并将其映射到高维向量空间。
- 细节:
- 使用一个卷积层
Conv2d(3, 1024, kernel_size=16, stride=16)来实现 patch 到 embedding 的转换。- 输入通道为 3(RGB 图像)
- 输出维度为 1024(即每个 patch 被编码为 1024 维向量)
- 每个 patch 大小是 16×16 像素
- 这相当于标准 ViT 中的“线性投影”操作,只不过用卷积高效实现。
- 使用一个卷积层
norm: Identity()表示没有使用额外的归一化(可能是为了简化或配合后续归一化)。
✅ 输出:形状为
(B, N, 1024)的 token 序列,其中 B 是 batch size,N 是 patch 数量(例如 224×224 图像 → (224/16)² = 196 个 patches)
2. rope_embed: RopePositionEmbedding()
- Rope = Rotary Position Embedding
- 这不是传统的可学习位置编码(learned positional embedding),而是近年来在语言模型中流行的 旋转式位置编码(RoPE),现在也被引入视觉 Transformer。
- 优点:
- 更好的外推能力(对更大分辨率图像更鲁棒)
- 相比绝对位置编码,能更好地建模相对位置关系
- 在这里用于给 patch tokens 添加位置信息。
⚠️ 注意:这表明该模型可能支持动态分辨率输入,或者是为了提升泛化性而采用先进位置编码机制。
3. blocks: ModuleList(24 × SelfAttentionBlock)
这是模型的核心部分 —— 由 24 层堆叠的 Transformer 编码器块组成。
每一层都是如下结构:
python
深色版本
SelfAttentionBlock(
(norm1): LayerNorm(...)
(attn): SelfAttention(...)
(ls1): LayerScale()
(norm2): LayerNorm(...)
(mlp): Mlp(...)
(ls2): LayerScale()
)a. norm1 和 norm2
- 两个 LayerNorm 分别在注意力和 MLP 前进行归一化(Pre-LN 结构),有助于训练稳定性。
b. attn: SelfAttention
python
深色版本
(qkv): LinearKMaskedBias(in_features=1024, out_features=3072, bias=True)
(proj): Linear(1024 -> 1024)
(attn_drop, proj_drop): Dropout(p=0.0)- QKV 投影:将输入分解为 query, key, value,总维度 3×1024 = 3072。
- 多头注意力机制(具体头数未显示,但通常 1024 维会用 16 或 32 头)。
LinearKMaskedBias可能表示带有特殊初始化或掩码偏置处理(常见于 DINOv2 等改进模型中)。- Dropout 关闭(p=0.0),说明推理或轻量设置。
c. mlp: Feed-Forward Network
python
深色版本
(fc1): Linear(1024 → 4096)
(act): GELU
(fc2): Linear(4096 → 1024)
(drop): Dropout(p=0.0)- 标准两层 MLP,中间扩展到 4096 维(4× hidden dim),GELU 激活函数。
d. ls1, ls2: LayerScale
- LayerScale 是一种可学习参数,乘在残差路径上,形式为
gamma * f(x),其中 gamma 初始化很小(如 1e-6),帮助稳定深层 Transformer 训练。 - 出现在注意力输出和 MLP 输出之后:
python
深色版本
x = x + ls1(attn(norm1(x))) x = x + ls2(mlp(norm2(x))) - 这是 ConvNeXt / DeiT-III 等现代架构的关键组件,允许早期层几乎“跳过”信息传递,提升训练稳定性。
4. norm: Final LayerNorm
python
深色版本
LayerNorm((1024,), eps=1e-05)- 整个 Transformer 块输出后的最终归一化。
- 通常用于提取 [CLS] token 或所有 tokens 的特征表示。
5. head: Identity()
python
深色版本
(Head): Identity()- 这意味着模型 不包含分类头(classifier head)。
- 输出就是最后一个 block 后的特征本身。
- 常见于 基础模型(foundation model) 或 特征提取器 场景,比如:
- DINO 自监督预训练模型
- 用作目标检测器(如 DETR、DINO)的 backbone
- 提取图像嵌入用于检索、聚类等
总结与推断
| 特征 | 推论 |
|---|---|
| 深度:24 层 | 属于“大模型”级别(类似 ViT-Large) |
| 隐藏维度:1024 | 高维特征表示,强大表达能力 |
| MLP 扩展比:4× | 标准设计 |
| 使用 RoPE | 支持灵活分辨率,可能是 DINOv2 或后续改进版本 |
| LayerScale | 现代化训练技巧,提高收敛性和性能 |
| 无分类头(Identity head) | 主要用于特征提取或下游任务微调 |
🧩 很可能这是:
👉 DINOv2 的主干网络(Backbone),例如 dinov2_vitl14(ViT-Large, patch14),尽管这里是 patch16。
- DINOv2 模型常用这种结构:24 层、1024 dim、LayerScale、RoPE、无 head。
- 适用于:
- 自监督特征提取
- 迁移学习
- 视觉生成模型的 encoder
- 开放世界识别系统
🔍 典型用途示例
python
深色版本
# 输入图像 (B, 3, H, W),如 (1, 3, 224, 224)
x = model.patch_embed(img) # -> (1, 196, 1024)
x = x + model.rope_embed(x) # 加上旋转位置编码
for block in model.blocks:
x = block(x)
x = model.norm(x) # 最终归一化
# 输出:patch tokens,可用于池化得到全局特征
feat = x.mean(dim=1) # 或取 cls token(如果有)✅ 建议应用场景
- 图像检索
- 医学图像分析
- 目标检测 / 实例分割(作为 backbone)
- 少样本学习
- 无监督/自监督学习研究
如果你有具体的使用场景(比如想做分类、迁移学习、可视化 attention map),可以进一步讨论如何利用这个模型。
分界线
DINO(DIstilled NOise-contrastive estimation,但官方更倾向于视为无缩写)是一种由 Meta AI(原 Facebook AI) 在 2021 年提出的 自监督学习(Self-Supervised Learning, SSL) 方法,主要用于训练 视觉 Transformer(Vision Transformers, ViT) 模型,无需人工标注标签。
它的核心思想是:通过对比两个不同增强视图之间的特征,让模型学会提取有意义的、结构化的图像表示。
🌟 DINO 的核心思想
DINO 利用 “在线网络”(online network) 和 “目标网络”(target network)” 之间的一致性学习(类似知识蒸馏),但没有真实标签,而是用自身作为老师。
🔁 基本流程:
-
对同一张图像进行 两种不同的数据增强(例如:不同裁剪、旋转、颜色抖动等),得到两个视图:
- 全局视图 A(通常为全图或大裁剪)
- 局部视图 B(小裁剪或随机裁剪)
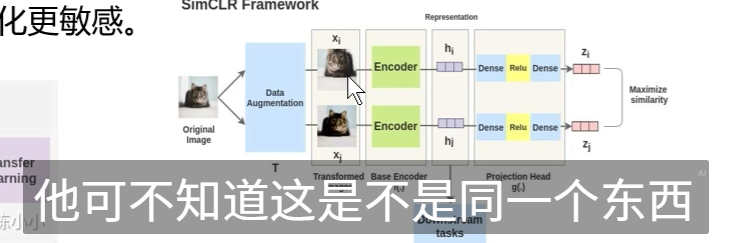
-
将这两个视图分别输入 同一个 ViT 模型的两个分支:
- Online 网络:接收局部视图 B,正常前向+反向传播。
- Target 网络:接收全局视图 A,不计算梯度,其参数是 online 网络的 指数移动平均(EMA)。
-
Online 网络预测的特征应尽可能 匹配 Target 网络生成的“目标”分布(即“老师”指导“学生”)。
-
使用 交叉熵损失(或 KL 散度)来最小化两者输出之间的差异。
💡 目标网络就像是一个“缓慢更新的老师”,教“快速学习的学生”(online 网络)如何理解图像。
🧠 DINO 的关键技术亮点
1. 没有负样本(No Negative Samples)
- 与 MoCo、SimCLR 等对比学习方法不同,DINO 不需要显式构造负样本对。
- 它使用 “自蒸馏” + 锐化(sharpening) 的方式,让模型自己生成“伪标签”。
✅ 优势:避免了负样本选择的复杂性,训练更稳定。
2. 教师网络参数是学生网络的 EMA
- 目标(教师)网络的权重不是随机初始化,也不是复制一次就固定,而是:
θtarget←τ⋅θtarget+(1−τ)⋅θonlineθtarget←τ⋅θtarget+(1−τ)⋅θonline
其中 ττ 接近 1(如 0.996),表示缓慢更新。
✅ 作用:提供稳定的学习目标,防止模型崩溃(collapse)。
3. 使用中心化和锐化(Centering & Sharpening)
- 输出分布会减去一个可学习的“中心向量”(防止所有输出趋同)
- 使用 温度系数(temperature)和锐化(如 sinkhorn 或 softmax with low temp)让目标分布更尖锐(one-hot-like)
✅ 防止模型输出恒定值(collapse problem),鼓励多样性。
4. 适用于 Vision Transformers
- DINO 特别适合 ViT,因为:
- ViT 的 patch 结构天然支持局部/全局建模
- 注意力机制可以学习出语义分割级的注意力图(即使没标注!)
🔍 惊人现象:DINO 训练出的 ViT,其 [CLS] token 的注意力图能自动聚焦在物体主体上,接近语义分割效果!
🎯 DINO 能做什么?(无需标注!)
| 应用 | 说明 |
|---|---|
| 图像分类 | 提取特征后接线性分类器(linear probe),性能接近监督学习 |
| 目标检测 / 分割 | 作为 backbone(如 DINO DETR) |
| 图像检索 | 高质量嵌入向量 |
| 无监督分割 | 利用注意力图或特征聚类 |
| 迁移学习 | 在小数据集上微调表现优异 |
📈 DINO 的演进:DINO → DINOv2
- DINO(2021):初代,使用 ViT-B/L,在 ImageNet-1k 上预训练。
- DINOv2(2023):重大升级:
- 使用 更大规模、无标注图像数据集
- 引入 RegNet 作为教师网络 进行多阶段训练
- 支持 更强的骨干网络(如 ViT-Huge)
- 输出特征可直接用于密集任务(如分割、深度估计)
- 开源高质量模型(
dinov2_vitb14,vitl14,vith14)
✅ DINOv2 被广泛认为是当前最强的通用视觉基础模型之一。
🧪 简单代码示意(概念级)
python
深色版本
# 伪代码
online_network = ViT() # 学生网络
target_network = ViT() # 老师网络,参数为 EMA
target_network.load_state_dict(online_network.state_dict())
target_network.requires_grad_(False)
for image in dataloader:
# 两种增强
global_view = augment(image, large_crop=True)
local_view = augment(image, small_crop=True)
# 学生预测(局部视图)
pred = online_network(local_view) # (B, D)
# 老师生成目标(全局视图)
with torch.no_grad():
target = target_network(global_view)
target = sharpen(centralize(target))
# 自蒸馏损失
loss = - (target * log_softmax(pred)).sum(dim=1).mean()
loss.backward()
update(online_network)
update_ema(target_network, online_network) # EMA 更新✅ 总结:DINO 是什么?
| 特性 | 说明 |
|---|---|
| 类型 | 自监督学习方法 |
| 目标 | 训练强大的视觉表示(无需标签) |
| 核心机制 | 自蒸馏 + EMA 目标网络 + 多视图一致性 |
| 优势 | 无需负样本、训练稳定、注意力有语义 |
| 应用 | 分类、检测、分割、检索、基础模型 |
| 代表模型 | DINO, DINOv2 |
如果你正在使用你之前提到的那个 DinoVisionTransformer 模型,极大概率它就是通过 DINO 或 DINOv2 方法在大规模无标签图像上预训练得到的,因此可以直接用于各种视觉任务的特征提取,而无需从头训练。
如果你想进一步了解如何使用 DINO 提取特征、可视化注意力图或进行微调,我可以提供具体代码示例。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)