综述阅读:Poisoning Attacks against Recommender Systems
本文综述了针对推荐系统的投毒攻击(PAR)研究现状,提出了一种新颖的三维分类法:组件特定攻击、目标驱动攻击和能力探测攻击。组件特定攻击针对不同推荐架构(如图结构、异构数据、强化学习系统)的固有漏洞;目标驱动攻击根据攻击者意图(如降低整体性能或操纵特定结果)进行区分;能力探测攻击则考察在有限资源和知识约束下的攻击效果。研究指出,现代推荐系统虽然准确性提升,但也引入了新的安全隐患,特别是深度学习模型对
摘要
本综述对 针对推荐系统的投毒攻击(Poisoning Attacks against Recommandation,PAR) 的研究现状进行了系统的和最新的回顾,提出了一种新颖且全面的分类法,将现有的PAR方法分为了三个不同的类别:组件特定,目标驱动,能力探测
引言
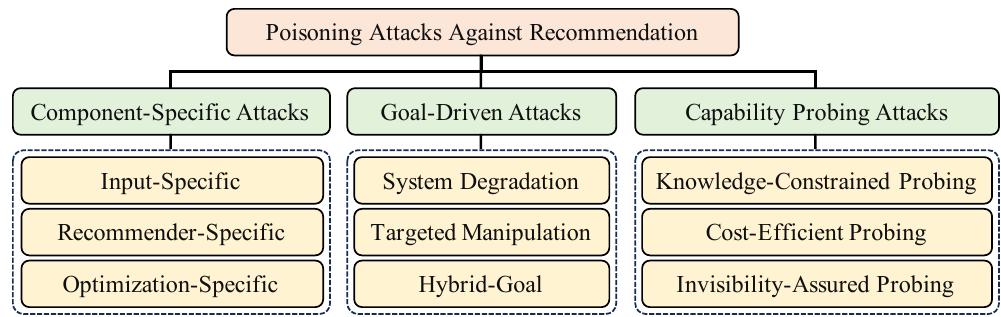
图1:针对推荐系统(Recommandation System,RS)的投毒攻击的分类
现代 RS 利用先进的深度神经架构的力量 ,帮助用户发现符合其独特偏好的物品:[Wang et al. , 2023d (Efficient Bi-Level Optimization for Recommendation Denoising)]
和[Cheng et al., 2016 (Wide & Deep Learning for Recommender Systems)]
尽管这些深度推荐系统具有前所未有的有效性 ,但越来越多的证据表明它们存在漏洞 ,容易受到恶意活动的影响 ,这种恶意活动通常被称为针对推荐系统的投毒攻击 (PAR):
[Gunes et al., 2014 (Ihsan Gunes, Cihan Kaleli, Alper Bilge, and Huseyin Polat. Shilling attacks against recommender systems: a comprehensive survey)]
和[Si and Li, 2020 (Shilling attacks against collaborative recommender systems: a review)]
和[Zhang et al., 2020b (GCN-Based User Representation Learning for Unifying Robust Recommendation and Fraudster Detection)]
通过将恶意或误导性的数据引入 RS 的训练数据中 ,会扰乱系统并操纵生成的推荐
早期对 PAR 的研究主要集中在基于启发式的方法上:
[O’Mahony et al. , 2002 (Promoting Recommendations: An Attack on Collaborative Filtering)]
和[Yu et al. , 2017 (Hybrid attacks on model-based social recommender systems )]和[Burke et al., 2005 (Limited Knowledge Shilling Attacks in Collaborative Filtering Systems)]
这些方法涉及预定义一个固定的策略用于生成恶意的用户资料并注入到系统中;但是这种固定的构造模式缺乏适应性 ,一旦模式被破译 ,就很容易被防御措施检测到:[Wang et al., 2022 (Gray-Box Shilling Attack: An Adversarial Learning Approach)]
最新的 PAR 研究方向与 RS 技术的迭代进步密切相关;
基于矩阵分解的推荐方法[Koren et al. ,2009 (Matrix factorization techniques for recommender systems)] ,
基于图的推荐方法[Fang et al. , 2018 (Poisoning Attacks to Graph-Based Recommender Systems)] ,
基于 LLM 的推荐方法[Wu et al., 2023b (A survey on large language models for recommendation.)]
不仅产生了更精确的推荐结果 ,还引入了一系列新的漏洞
对 PAR 的研究还包括检查这些攻击背后的目标 ,例如降低整体推荐性能以及影响特定项目或用户.鉴于与不同预期目标相关的各种攻击措施和形式 ,认识和理解这些差异对于制定有效的防御措施以应对此类攻击至关重要.最后 ,了解攻击者的能力非常重要
在现实场景中,攻击者通常难以获取关于 RS 的详细信息;资源限制进一步阻碍了他们在不被发现的情况下发起有效攻击的能力
[Lin et al. , 2020 , (Attacking Recommender Systems with Augmented User Profiles)]
和[Zeng et al., 2023 (Practical Cross-system Shilling Attacks with Limited Access to Data)]
PAR分类
前置知识
受害者RS:
设 U \mathcal{U} U 和 I \mathcal{I} I 分别为RS中的用户和物品集合, D \mathcal{D} D 表示原始用户/物品数据,包含交互信息(点击,收藏,喜欢等)和特征(例如文本和图像)
PAR中的受害者模型指的是一个推荐器 f \mathcal{f} f ,旨在学习一个低维表示集合用于预测用户 u ∈ U u \in \mathcal{U} u∈U 对物品 i ∈ I i \in \mathcal{I} i∈I 的偏好
将受害者(推荐)任务公式化为:
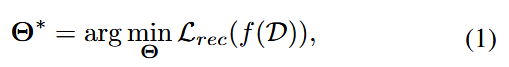
其中, Θ ∗ \Theta^* Θ∗ 代表最优模型参数,包括用户和物品表征, L r e c L_{rec} Lrec 是推荐目标函数,比如交叉熵
PAR:
在PAR的场景中,攻击者可以操控一组恶意用户集合 U M \mathcal{U}_{M} UM ,这些用户与各类物品做交互,有时还会对部分物品的特征进行修改
由此产生的恶意数据 D M \mathcal{D}_{M} DM 随后被注入到RS的训练数据中,此类攻击的目的在于操纵推荐模型的学习过程,并最终实现特定攻击目标。在此背景下,我们将推荐系统投毒攻击任务表述为一个双层优化问题: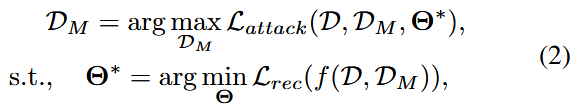
其中 L a t t a c k \mathcal{L}_{attack} Lattack 用于评估攻击效用的投毒攻击损失函数,通常包括诸如推荐准确率降低和特定目标物品排名的混乱程度等指标
恶意数据 D M \mathcal{D}_{M} DM 通过交替执行 受害者模型训练的内层优化 与 恶意数据优化的外层优化 生成。具体而言,内层优化的核心是结合原始数据与恶意数据对受害者模型进行训练;与此同时,外层优化的任务是对恶意数据进行优化调整,以实现预期的攻击目标
提出的分类法
根据投毒攻击的模式和意图将其分为3个类别:组件特定攻击、目标驱动攻击、能力探测攻击
组件特定攻击:
由于深度学习技术的快速发展,RS领域现在包含各种各样的输入数据类型(图、文本、图像等)、推荐架构(基于矩阵分解、基于图、基于LLM等)以及优化函数(交叉熵、softmax、Triplet损失等);这些基本组件的独特特征可能会导致各种形式的投毒攻击
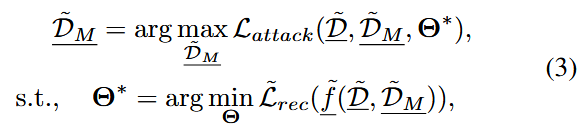
其中, D ~ \tilde{\mathcal{D}} D~ 和 D ~ M \tilde{\mathcal{D}}_{M} D~M 表示包含特定类型数据的数据集, f ~ \tilde{\mathcal{f}} f~ 表示具有特定推荐器架构的受害者模型,而 L ~ r e c \tilde{\mathcal{L}}_{rec} L~rec 指的是特定的目标函数
目标驱动攻击
该类攻击依据攻击者在攻击策略中追求的不同目标进行划分
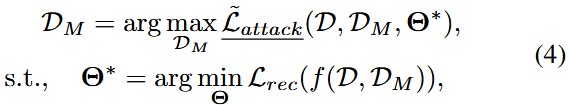
能力探测攻击
在实际场景中,攻击者常常受到各种限制,通常,它们无法完全访问推荐系统的数据和模型细节,同时,经济和资源成本也阻止他们注入过多的用户和交互
因此,研究人员积极研究在不同等级的攻击者能力下,PAR的效果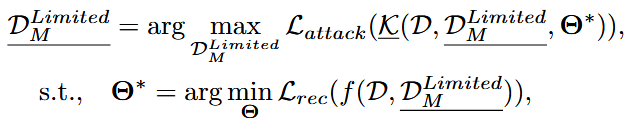
其中, D M L i m i t e d \mathcal{D}_{M}^{Limited} DMLimited 是符合特定限制的恶意数据集,而 K \mathcal{K} K 代表数据和模型细节知识相关的约束
三种类别的联系:互相关联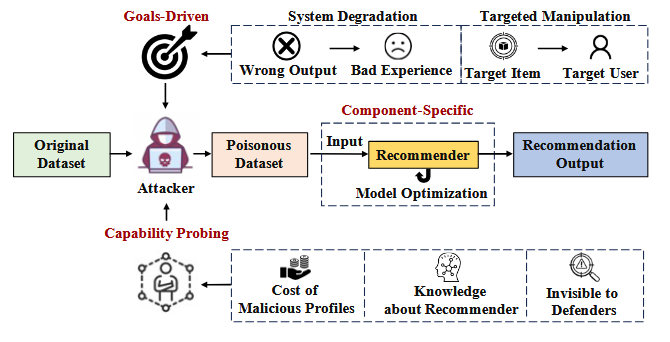
组件特定攻击
输入特定攻击
基于图结构的推荐系统的攻击:
用户和物品作为节点,通过交互作为边连接
GraphAttack [Fang et al., 2018 (Poisoning Attacks to Graph-Based Recommender Systems)]
和
GSPAttack [Nguyen et al., 2022 (Poisoning GNN-based Recommender Systems with Generative Surrogate-based Attacks)]
等特定于图的PAR,展示了图结构固有的漏洞:利用物品推荐率作为其目标函数,通过利用图传播动态过程中产生的梯度,对恶意用户档案进行优化
加入了异构数据和知识图谱的攻击
随着异构数据和知识图谱(KG) [Ji et al., 2021 (A Survey on Knowledge Graphs: Representation, Acquisition, and Applications)]的加入,复杂度进一步升级。这些元素添加了多样化的信息,例如社会关系和详细的实体属性
例如
MSOPDS [Yeh et al., 2023 (Planning Data Poisoning Attacks on Heterogeneous Recommender Systems in a Multiplayer Setting)]
多个攻击者共同进攻(攻击者实施投毒时,需要考虑其他对手的后续攻击行为)融合了用户社交网络,物品关联图等多源异构数据的推荐系统,每个攻击者都有独特的社会联系
KGAttack [Chen et al., 2022 (Knowledge-enhanced Black-box Attacks for Recommendations)]
和
KG-RLattack [Wu et al., 2022b (Poisoning attacks against knowledge graph-based recommendation systems using deep reinforcement learning)]
利用KG中广泛的信息来创建既真实又可信的合成用户资料
基于强化学习的攻击
时序数据在序列推荐系统中至关重要,同时也为PAR提供了一个可行的攻击目标
PoisonRec [Song et al., 2021 (PoisonRec: An Adaptive Data Poisoning Framework for Attacking Black-box Recommender Systems)]
采用RL从历史序列中分析用户偏好,并将此过程概念化为一个马尔可夫决策过程(MDP)
LOKI [Zhang et al., 2020a (Practical Data Poisoning Attack against Next-Item Recommendation)]
使用RL训练一个代理模型,以便为 特定攻击目的(推广、贬低、干扰系统等) 生成用户行为样本
CopyAttack [Fan et al., 2021 (Attacking Black-box Recommendations via Copying Cross-domain User Profiles)]
应用RL来识别和复制来自源域的真实用户资料到目标域,旨在利用真实用户数据的真实性和特征,从而在目标域中推广特定的物品子集
推荐器特定攻击
随着RS不断发展,PAR领域的研究方向之一已经越来越多地转向利用各类推荐系统架构与范式中存在的特定漏洞
对传统的RS的攻击
TNA [Fang et al., 2020 (Influence Function based Data Poisoning Attacks to Top-N Recommender Systems)]
探索了基于矩阵分解的RS漏洞
UNAttack [Chen et al., 2021 (Data poisoning attacks on neighborhood‐based recommender systems)]
深入研究了基于邻域(基于用户邻域User-based,基于物品邻域Item-based)的RS,攻击场景聚焦于通过投毒操纵该类系统的推荐结果
对基于深度学习的RS的攻击
DLAttack [Huang et al., 2021 (Data Poisoning Attacks to Deep Learning Based Recommender Systems)]
专注于纯粹的基于深度学习的推荐系统,首次系统探索了DL架构在投毒攻击下的共性脆弱性(梯度更新机制和特征嵌入学习,如果扭曲了梯度方向与嵌入向量分布,就可能使模型推荐结果偏离预期),为后续深度RS的安全研究奠定基础
NCFAttack [Zhang et al., 2020c (Towards Poisoning the Neural Collaborative Filtering-Based Recommender Systems)]
针对基于 神经协同过滤(neural collaborative filtering) 的RS展开研究
对基于图的RS的攻击
GOAT [Wu et al., 2021c (Ready for Emerging Threats to Recommender Systems? A Graph Convolution-based Generative Shilling Attack)]
和
GSPAttack [Nguyen et al., 2022 (Poisoning GNN-based Recommender Systems with Generative Surrogate-based Attacks)]
专门在架构中结合了GNN的RS上执行PAR,揭示了图嵌入的邻居依赖性带来的漏洞(信息汇聚与信息传递机制将恶意节点的特征汇聚,扭曲最终的节点嵌入)
上述研究揭示了基于深度学习的系统的梯度更新机制中的漏洞
针对自监督学习(SSL)的攻击
SSLAttack [Wang et al., 2023b (Poisoning Self-supervised Learning Based Sequential Recommendations)]
将PAR的重点转移到最初的预训练阶段;这种方法强调在预训练期间注入对抗性影响,这些影响随后在微调阶段传播到下游推荐模型
PromptAttack [Wu et al., 2023c (Poisoning Self-supervised Learning Based Sequential Recommendations)]
探索了 自监督预训练+提示学习微调 模型漏洞,这是一种与传统微调相比更为细致的方法,从而暴露了各种下游推荐模型中的弱点
针对去中心化的联邦推荐系统(decentralized Federated RS)的攻击
联邦推荐系统的核心思想是:数据不动,模型动
即用户的原始行为数据(购买,浏览历史等)永远保留在个人设备或者本地服务器上,不上传至中央服务器;推荐模型的一部分(或全部)训练过程在用户的本地设备上进行。设备利用本地的私有数据计算模型的更新(如梯度或权重更新),而不是原始数据
FedRecAttack [Rong et al., 2022b (FedRecAttack: Model Poisoning Attack to Federated Recommendation)]
证明了在保护隐私的去中心化架构下,仍可利用公共交互来近似用户特征并操纵恶意用户,从而优化PAR过程
A-ra [Rong et al., 2022a (Poisoning Deep Learning based Recommender Model in Federated Learning Scenarios)]
进一步聚焦于识别目标物品的 “难影响用户(hard users)”—— 这类用户因具有独特的交互模式,难以被投毒攻击所影响
可解释推荐系统:通过逻辑化建模用户交互与推荐结果的关联,实现推荐透明化:
- 交互-推荐逻辑建模
将用户的历史交互转换为逻辑规则;比如:用户u交互过物品b,a与b同属一个类别,那么系统生成规则u交互b->推荐a,并将该规则作为推荐a的解释 - 反事实解释生成
回答"若交互条件改变,推荐结果会如何变化"
H-CARS [Chen et al., 2023b (The Dark Side of Explanations: Poisoning Recommender Systems with Counterfactual Examples)]
利用了反事实解释;攻击者构造满足反事实条件的恶意交互(比如为了让系统推荐目标物品T,故意注入用户交互物品C(T的同类物品)的虚假数据),即可触发系统生成 “交互 C→推荐 T” 的规则;揭示了新的漏洞
优化特定攻击
PipAttack [Zhang et al., 2022a (PipAttack: Poisoning Federated Recommender Systems forManipulating Item Promotion)]
利用了广泛使用的贝叶斯个性化排序(Bayesian Personalized Ranking, BPR)损失函数中 “热门物品聚合” 的独特特性。该方法在嵌入空间中调整目标物品,使其特征与热门物品的特征相似,从而提高用户与该目标物品发生交互的概率。
CLeaR [Wang et al., 2023e (Poisoning Attacks Against Contrastive Recommender Systems)]
指出,在RS中增强对比学习(Contrastive Learning)损失,可能导致特征表示呈现均匀分布。这种均匀分布被认定为一种漏洞,会加剧推荐系统在推荐系统投毒攻击(PAR)面前的脆弱性。
目标驱动攻击
PAR中,恶意数据的性质高度依赖于攻击者的目标。因此该攻击类别可被细分为三类:系统降级攻击、定向操纵攻击、混合目标攻击
系统降级攻击 - System Degradation Attacks
这类PAR也称为非目标攻击(Untargeted Attacks),因为它们在策略上旨在破坏RS的整体功能,从而影响所有推荐结果。最终目的是降低用户体验,并可能给服务提供商造成巨大的经济损失
Infmix [Wu et al., 2023a (Influence-Driven Data Poisoning for Robust Recommender Systems); Wu et al., 2021b (Fight Fire with Fire: Towards Robust Recommender Systems via Adversarial Poisoning Training)]
专注于识别恶意用户中的"有影响力用户",这些用户可以对系统产生更显著的影响;该方法的核心是优先为这些有影响力用户创建交互,以扩大攻击的影响
FedAttack [Wu et al., 2022a (FedAttack: Effective and Covert Poisoning Attack on Federated Recommendation via Hard Sampling)]
采用全局范围内的"最难样本物品"来破坏模型训练。它分别选择与用户嵌入向量关联性最强和最弱的物品,将其作为最难正样本和最难负样本。对这些最难样本物品的交互记录进行操纵,能显著影响系统的推荐结果
ClusterAttack [Yu et al., 2023b (Untargeted Attack against Federated Recommendation Systems via Poisonous Item Embeddings and the Defense)]
通过控制恶意用户档案,将物品嵌入向量聚类成密集的群组。这种聚类会导致推荐系统对同一群组内的物品给出相近的评分,进而打乱正常的推荐排名顺序。
UA-FedRec [Yi et al., 2023 (UA-FedRec: Untargeted Attack on Federated News Recommendation)]
则聚焦于用户与物品的建模过程,通过调整特征表示,增大相似样本之间的距离,同时缩小不相似样本之间的距离,从而影响整个推荐流程。
定向操纵攻击 - Targeted Manipulation Attacks
与系统降级攻击相反,这种类型的PAR通常被称为目标攻击。这些攻击经过精心设计,旨在向特定用户群体或所有用户推广特定物品,或降低特定物品在这些用户群体中的推荐优先级
PoisonRec [Song et al., 2021 (PoisonRec: An Adaptive Data Poisoning Framework for Attacking Black-box Recommender Systems)]
KGAttack [Chen et al., 2022 (Knowledge-enhanced Black-box Attacks for Recommendations)]
ModelExtractionAttack [Yue et al., 2021 (Black-Box Attacks on Sequential Recommenders via Data-Free Model Extraction)]
聚焦于最大化目标物品在Top-K列表中的出现频率
A-ra [Rong et al., 2022a (Poisoning Deep Learning based Recommender Model in Federated Learning Scenarios)]
旨在直接最大化每个目标物品被推荐的预测概率
RAPU [Zhang et al., 2021a (Data Poisoning Attack against Recommender System Using Incomplete and Perturbed Data)]
致力于确保目标物品的预测概率高于其他所有物品
GTA [Wang et al., 2023c (Revisiting Data Poisoning Attacks on Deep Learning Based Recommender Systems)]
该方法首先通过预测每位用户最偏好的物品来评估用户意图,随后调整目标物品的特征,使其与这些用户偏好物品高度相似。这一操作能更新目标物品的属性,使其与用户偏好物品保持一致,从而巧妙地影响推荐结果。
AutoAttack [Guo et al., 2023 (Targeted shilling attacks on gnn-based recommender systems)]
它同时从目标物品与目标用户两个视角出发,构建与特定用户群体的属性和交互模式高度相似的恶意用户档案。这种策略不仅能有效影响目标用户群体,还能将对其他用户的非预期影响降至最低。
混合目标攻击 - Hybrid-Goal Attacks
为了获得更多利益,攻击者可能会设计更灵活的攻击策略,同时实现系统降级与定向操纵
SGLD [Li et al., 2016 (Data Poisoning Attacks on Factorization-Based Collaborative Filtering)]
是具有开创性的双目标攻击方法,能够同时实现两类攻击目标
核心技术在于:一方面最大化投毒攻击前后系统所有预测结果的偏差(以达成系统降级目的),另一方面提升每个用户对目标物品的预测推荐概率(以达成定向操纵目的)。该方法通过权重系数,在这两个目标之间实现了平衡
CD-Attack [Chen and Li, 2019 (Data Poisoning Attacks on Cross-domain Recommendation)]
以攻击效果为优化目标,证明了基于双重目标框架开发的恶意用户资料在不同领域上表现出良好的可迁移性
NCFAttack [Zhang et al., 2020c (Towards Poisoning the Neural Collaborative Filtering-Based Recommender Systems)]
会根据模型的优化策略生成特定的对抗性梯度,从而实现更精准的攻击
能力探测攻击
在现实场景中,执行PAR的攻击者往往会收到一系列约束条件(对推荐系统了解程度,资源成本等)的限制,这些约束必然会影响其攻击效果
将这类基于约束条件的PAR分为三类:知识约束探测攻击、经济高效的探测攻击、隐身性保证的探测攻击
知识约束探测攻击 - Knowledge-Constrained Probing Attacks
攻击者对于受害者RS的了解程度可以分为三种:白盒(white-box),灰盒(gray-box),黑盒(black-box),
分别代表完全访问RS,部分访问RS,再到攻击者只有有限的交互信息且没有关于RS先验知识的情况
CovisitationAttack [Yang et al., 2017 (Fake Co-visitation Injection Attacks to Recommender Systems)]
从理论上评估了攻击者关于受害者模型可能掌握的三个知识层级(黑/白/灰盒),并针对每个知识层级设计了不同的PAR策略
A-ra [Rong et al., 2022a (Poisoning Deep Learning based Recommender Model in Federated Learning Scenarios)]
更聚焦于攻击者"知识有限"的场景。特别是攻击者仅了解目标系统的物品表示建模方式,却不掌握用户表示建模的相关信息
AIA [Tang et al., 2020 (Revisiting Adversarially Learned Injection Attacks Against Recommender Systems)]
和
ReverseAttack [Zhang et al., 2021b (Reverse Attack: Black-box Attacks on Collaborative Recommendation)]
则针对攻击者无法完全获取目标数据集的场景。它们的核心思路是从社交网络平台收集数据,以此逼近RS所学习到的用户与物品表示,进而将这些逼近得到的表示迁移应用于真实的推荐系统
RAPU [Zhang et al., 2021a (Data Poisoning Attack against Recommender System Using Incomplete and Perturbed Data)]
致力于应对数据模糊性的挑战(如数据噪声);采用了融合概率生成模型的双层优化框架。这种组合能有效处理数据不完整与数据扰动问题,更精准地估计用户与物品的特征,从而提升攻击效果
经济高效的探测攻击 - Cost-Efficient Probing Attacks
每一条被篡改或注入的恶意数据都伴随着特定成本。这种开销本质上会受到攻击者经济资源等因素的限制。因此对PAR进行优化,以在最大限度降低相关成本的同时实现攻击效果最大化,是攻击者的核心目标
注入恶意用户预算有限
SUI-Attack [Huang and Li, 2023 (Single-User Injection for Invisible Shilling Attack against Recommender Systems)]
解决了注入恶意用户预算有限的约束。它探讨了一种攻击者只能注入单个用户的场景。尽管存在这种限制,但通过仔细选择注入用户进行交互的合适项目,这种方法仍然有效,从而展示了在严格约束下执行 PAR 的潜力
系统输出查询预算有限
ModelExtractionAttack [Yue et al., 2021 (Black-Box Attacks on Sequential Recommenders via Data-Free Model Extraction)]
考虑了"系统输出查询预算有限"的场景;它采用知识蒸馏(knowledge distillation)技术,将不透明的黑盒目标模型(victim models)转化为透明、更易操纵的白盒代理模型(surrogate models)。这种转化使得攻击者能在预算约束内,用代理模型替代目标模型完成查询任务(无需频繁调用真实目标系统,减少查询成本)
使用其他平台数据训练代理模型
CopyAttack [Fan et al., 2021(Attacking Black-box Recommendations via Copying Cross-domain User Profiles); Fan et al., 2023 (Adversarial Attacks for Black-Box Recommender Systems via Copying Transferable Cross-Domain User Profiles)]
和
PC-Attack [Zeng et al., 2023 (Practical Cross-system Shilling Attacks with Limited Access to Data)]
利用来自多个其他平台的交互数据预训练一个代理模型(surrogate model),其目的是识别在不同平台间兼具"固有性"和"可迁移性"的特征属性;随后,用部分目标数据集对该代理模型进行微调,使其适配特定的攻击目标
LOKI [Zhang et al., 2020a (Practical Data Poisoning Attack against Next-Item Recommendation)]
使用代理模型,避免和目标RS直接交互;核心创新点在于引入了直接评估攻击影响力的方法:该方法无需重新训练代理模型,就能高效评估注入样本对推荐结果的影响
KG-RLattack [Wu et al., 2022b (Poisoning attacks against knowledge graph-based recommendation systems using deep reinforcement learning)]
使用代理模型,避免和目标RS直接交互;将知识图谱(KGs)中丰富的物品属性信息融入攻击策略 — 它利用公开可获取的知识图谱,借助其海量辅助知识,显著提升 “与正常用户档案无差别的恶意用户档案” 的构建质量
隐蔽性保障探测攻击 - Invisibility-Assured Probing Attacks
为保护RS免受PAR的影响,大多数商业RS都配备了PAR检测机制。因此要有效实施PAR,就必须审慎考虑恶意用户档案的隐蔽性
基于对抗性学习的隐蔽性攻击
其核心实现方式是让 “对抗性虚假用户” 的分布与真实用户交互数据的分布保持一致
AdvAttack [Christakopoulou et al., 2019 (Adversarial attacks on an oblivious recommender)]
攻击目标为 “无感知推荐器”(不具备攻击检测功能,仅基于用户交互数据进行推荐决策的传统RS);通过对抗优化生成虚假用户档案,确保虚假用户同时满足隐蔽性与攻击性,最终生成与真实用户分布高度一致的虚假用户档案;是将对抗学习整合到 PAR 中的开创性研究
基于GANs的隐蔽性攻击
在此基础上,后续研究采用了更高级的生成对抗网络框架(GANs),该框架包含生成器(generative component)与判别器(discriminative component)两个核心模块,通过二者的对抗交互,提升生成的用户档案与真实用户档案的相似度
AUSH [Lin et al., 2020 (Attacking Recommender Systems with Augmented User Profiles)]
LegUP [Lin et al., 2022 (Shilling Black-Box Recommender Systems by Learning to Generate Fake User Profiles)]
GOAT [Wu et al., 2021c (Ready for Emerging Threats to Recommender Systems? A Graph Convolution-based Generative Shilling Attack)]
和
GSPAttack [Nguyen et al., 2022 (Poisoning GNN-based Recommender Systems with Generative Surrogate-based Attacks)]
侧重于改进生成器以提高其有效性
TrialAttack [Wu et al., 2021a (Triple Adversarial Learning for Influence based Poisoning Attack in Recommender Systems)]
引入了一个额外的判别器来评估 合成用户档案(生成器生成的恶意用户档案) 对推荐系统的影响,从而能更细致地衡量攻击在系统内部产生的作用。
其他方法考虑恶意档案的隐蔽性
PipAttack [Zhang et al., 2022a (PipAttack: Poisoning Federated Recommender Systems forManipulating Item Promotion)]
实施定向操纵攻击时,要求将对系统整体推荐性能的影响降至最低;避免了推荐性能出现明显异常波动导致管理员或用户警觉
FedRecAttack [Rong et al., 2022b (FedRecAttack: Model Poisoning Attack to Federated Recommendation)]
限制了攻击后目标物品的最大梯度扰动,因为显著的扰动可能会提醒防御者
RecUP [Zhang et al., 2022c (Attacking Recommender Systems With Plausible Profile)]
和
GSA-GANs [Wang et al., 2022 (Gray-Box Shilling Attack: An Adversarial Learning Approach)]
采用最先进的恶意用户检测方法来评估生成的虚假用户是否可以逃避检测机制
挑战与未来方向
对新型受害者情境的探索
创新技术的出现催生了大量的推荐场景,从而扩大了潜在威胁的范围
多模态推荐[Yuan et al., 2023b (Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited)]
基于LLM的推荐[Wu et al., 2023b (A survey on large language models for recommendation)]
基于自监督学习(SSL)的推荐[Yu et al., 2023a (Self-Supervised Learning for Recommender Systems: A Survey)]
等显著进展为推荐领域引入了独特的复杂性。虽然这些进展正在迅速推进,但深入研究这些新场景的研究仍处于早期阶段。每种新型受害者情境都引入了独特的特征和脆弱性,这些特征和脆弱性与传统RS中的不同,揭示了未被探索的威胁和挑战
复杂恶意意图探究
攻击者可能会试图通过在另一个平台上采取行动来操纵一个平台的推荐,尤其是在用户数据跨平台共享的情况下
文化攻击旨在利用多语言RS中语言或文化差异来影响结果
鉴于潜在的现实攻击范围广泛,全面理解这些不同的动机并揭示各种PAR方法对于增强推荐系统的安全性和完整性至关重要。
PAR的理论基础
虽然各种PAR方法已证明RS的脆弱性,但对PAR的潜在原理缺乏深入研究(注入的恶意数据量收到经济因素制约,攻击的有效性也往往带有经济目标,但攻击成本与其带来的经济影响之间的关联规律仍不明确);PAR需要解决此类问题的坚实理论基础,以减少对繁琐试错法的依赖
PAR的长期影响
目前关于PAR的研究倾向于关注其直接影响,例如基于当前数据和模型配置快速注入中毒数据。然而,这种视角可能无法完全捕捉到RS的动态。随着RS通过累积数据和持续的模型更新而演变,注入的中毒数据的初始影响可能会随着时间的推移而减弱或被稀释。理解投毒数据如何在较长时间内与RS交互并影响RS,可以更深入地了解RS的持续脆弱性和抗干扰能力
PAR的高效中和策略
一个正在探索的有趣想法是将对抗性数据注入RS以抵消投毒数据的负面影响
这种策略在其他领域被提出[Chan and Ong, 2019 (Poison as a Cure: Detecting & Neutralizing Variable-Sized Backdoor Attacks in Deep Neural Networks)]
但在PAR的背景下相对未被探索。实施中和策略的主要挑战在于:
如何有效且高效地实现这种中和,且不给系统带来额外的负担或者损害用户体验
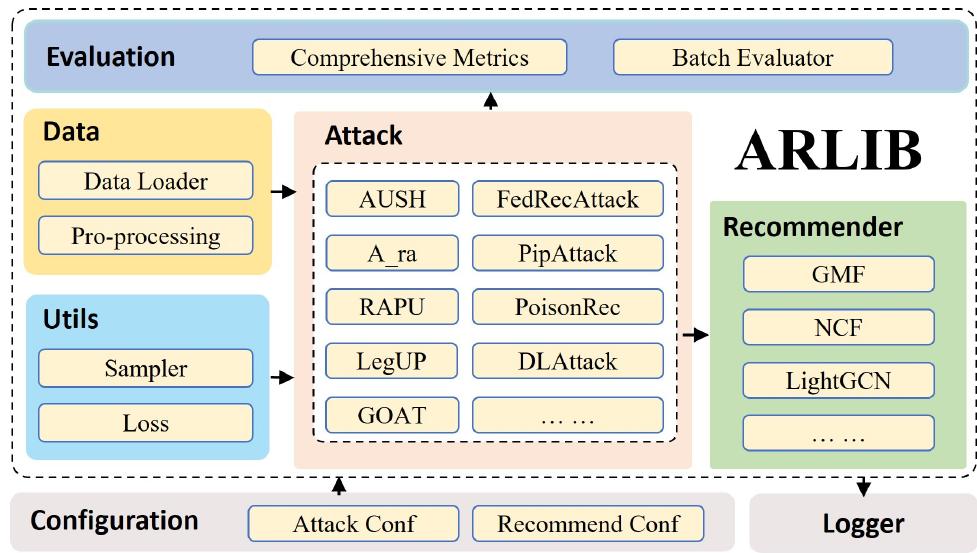
ARLib:一个用于推荐系统攻击的库
为了促进和标准化PAR的实证比较,作者引入了一个开源库ARLib,其中包含PAR模型和数据集的全面集合
代码地址: https://github.com/CoderWZW/ARLib
这是一个旨在促进 PAR 实现的开源库。ARLib 集成了超过 15 种不同的 PAR 模型。此外,它还整合了 PAR 中各种广泛使用的数据集,以满足各种研究需求
ARLib 致力于适应 PAR 模型中的最新进展,将自身定位为学术界全面且不断发展的资源

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)