【Agent Tool】Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning
Tool-Star: 基于强化学习的多工具协同推理框架 Tool-Star提出了一种新型强化学习框架,使大型语言模型能够自主调用多个外部工具进行渐进式推理。为解决工具使用数据稀缺问题,该研究开发了TIR数据合成管道,包含三个关键步骤:(1)通过提示采样和工具调用标记自动解析构建初始数据集;(2)实施工具调用频率控制、去重和格式规范化等质量管控措施;(3)基于难度感知将数据分为简单推理、工具集成推理
论文:https://arxiv.org/abs/2505.16410
代码:https://github.com/RUC-NLPIR/Tool-Star
简介:Tool-Star,这是一个基于RL的框架,旨在使大型语言模型能够在逐步推理过程中自主调用多个外部工具。为了解决工具使用数据的稀缺性,Tool-Star采用了可扩展的TIR数据合成管道,结合了规范化和困难感知数据分类过程。提出了一个两阶段的训练框架,以增强大型语言模型中的多工具协同推理,包括冷启动微调阶段和多工具自我批评强化学习阶段。
数据采集
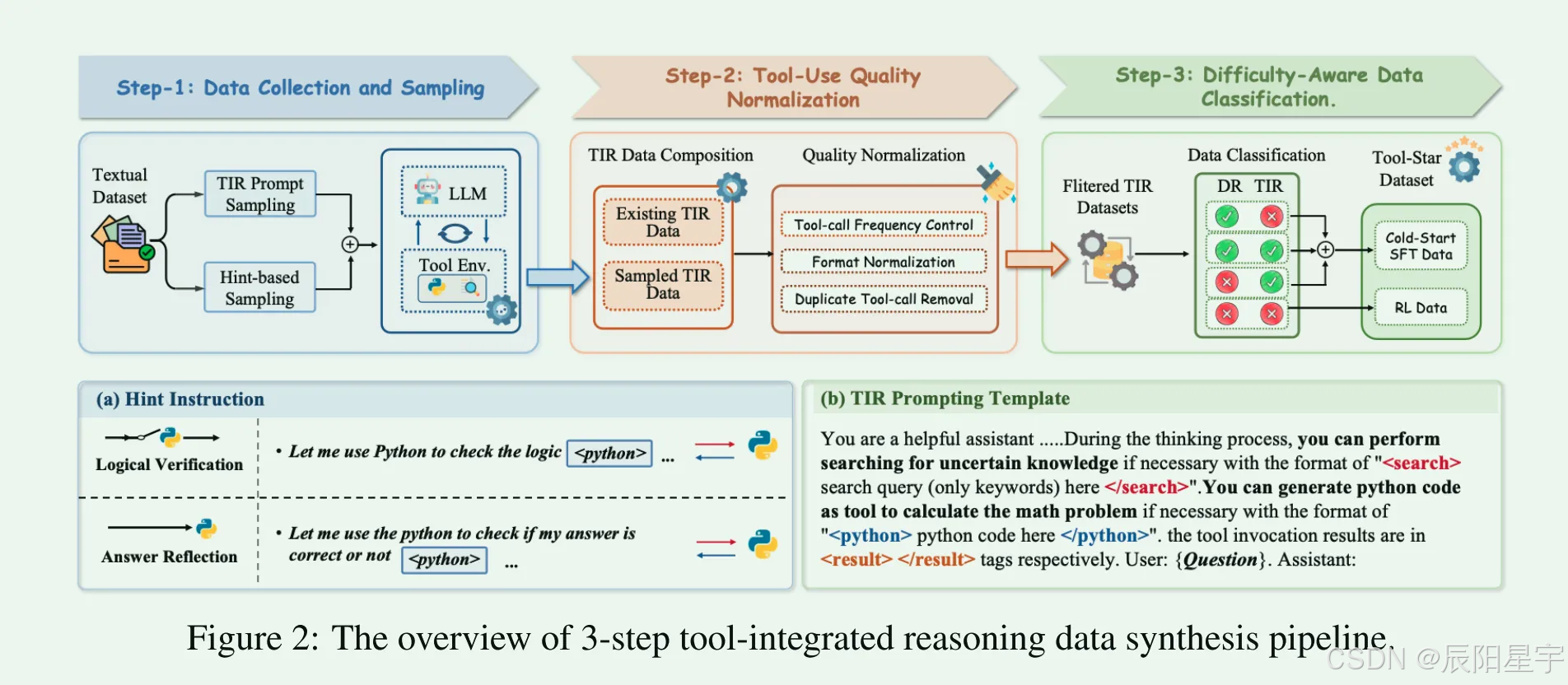
Step-1:数据收集和采样
从开源的基于知识和计算推理数据集中设计了一个高质量的训练集,包括大约90K基于文本的推理数据(Dtext)和1K现有的TIR数据集(Dtool)。
- (1)基于TIR提示的采样
使用特殊的token<search></search>, <python></python>, 自动解析和提取这些请求,调用外部工具以获得反馈F,并将工具反馈(包含在<result>和</result>标记中)插入推理链中,作为后续生成步骤的附加上下文。此过程迭代直到达到工具调用的最大数量或长度,或模型生成最终答案,由指定令牌<answer>和</answer>包含。 - (2)基于提示的采样
为了进一步多样化工具调用模式,采用了基于提示的方法,该方法将提示工具调用标记插入到仅语言的推理轨迹中。首先提示大型语言模型对来自数据集的查询执行纯语言推理。提出两个提示指令——「逻辑验证」和「答案反思」—将调用工具的提示插入到原始推理链中。如图所示,逻辑验证提示随机替换链中的不确定表达式(例如,maybe、wait、not sure),而反思提示则插入在答案之后。这些不同的提示有助于模型在信息不足时或在答案生成之后调用工具,从而实现信息补全和答案验证。插入提示后,我们在提示位置截断原始推理链,提示模型根据提示进行工具增强推理,
Step-2:工具使用质量归一化
为了确保每个样本中工具使用的合理性,我们实施了以下3种TIR归一化策略来控制工具使用数据的质量:
- (1)工具调用频率控制
删除工具调用频率超过预定义阈值β的样本,以减轻过度的工具调用。 - (2)删除重复的工具调用
删除包含冗余工具调用的样本,例如在相同的响应中重复生成相同的搜索查询或代码片段。 - (3)格式规范化
通过统一调用、反馈和最终答案的特殊标记来标准化推理链中的工具调用格式,同时确保开始和结束标记的平衡使用。通过应用这些标准,我们得到一个质量过滤的数据集。
Step-3:感知困难度分类数据
考虑到工具使用的计算开销和TIR训练的多阶段性质,我们认为一个高质量的工具使用数据集应该满足以下标准:(1)仅在必要时调用工具:当模型能够通过直接推理解决问题时,应避免调用工具。(2)从易到难组织样本:正如之前强化学习工具学习中所强调的,基于样本难度的分阶段训练对于有效学习至关重要。
基于上述标准,将数据集划分成两类,一类是直接推理(DR),另一类是工具集成推理(TIR)。我们从第一类和第二类中,抽取困难的问题,作为一个数据子集。
为了支持从简单到困难的课程学习范式,将前两类数据集构建一个成冷启动微调数据集SFT工具。对于DR和TIR都具有挑战性的第三个样本数据,我们将其作为硬例并保留用于强化学习,形成RL数据集。这种设计使LLM能够通过冷启动微调获得基本的工具使用能力,并随后在RL阶段推广到更复杂的场景(例如多工具协作),从而促进渐进式学习轨迹。
两阶段训练
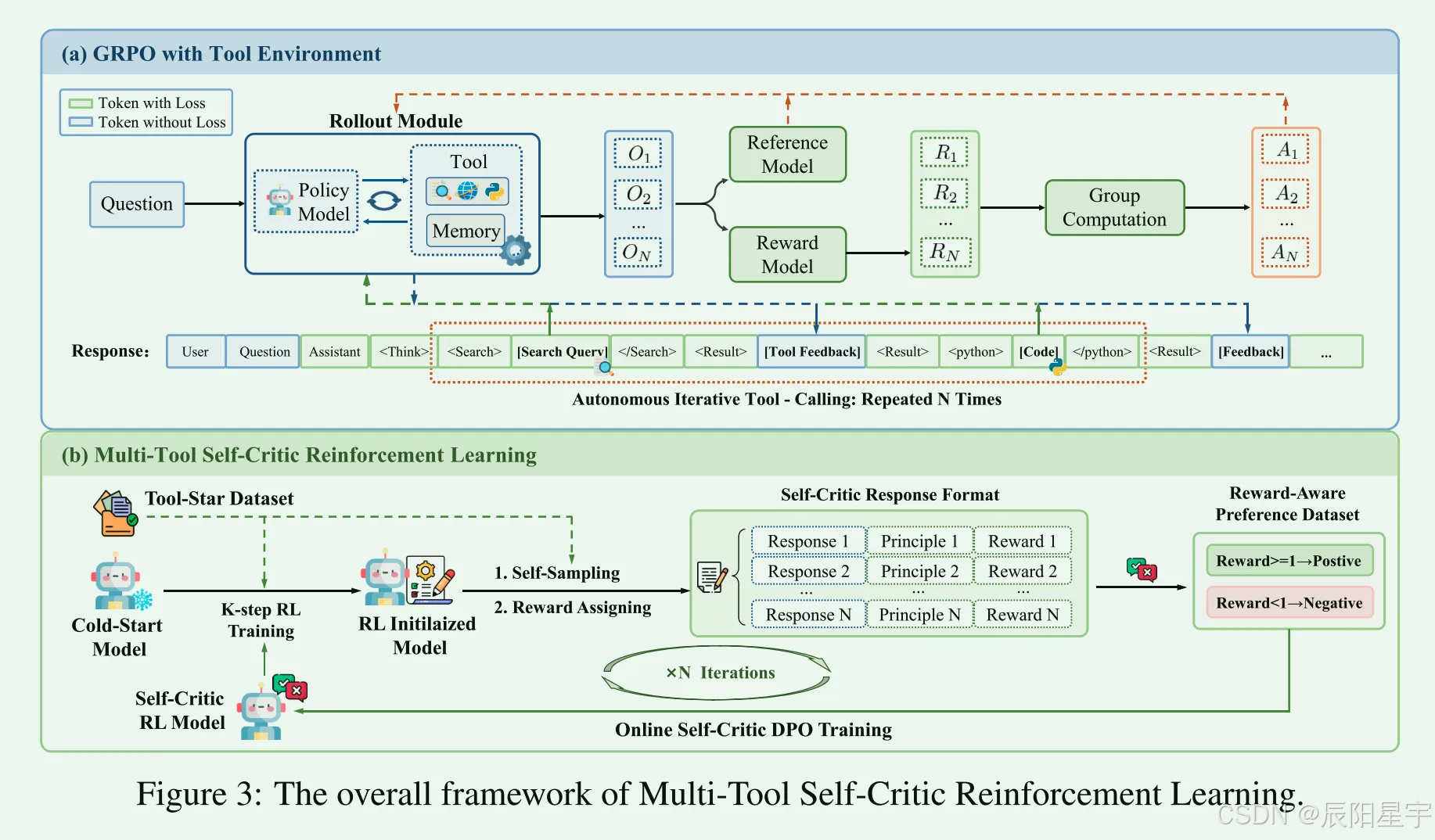
- 用上述数据进行SFT冷启动
- RL训练增强泛化性
- 使用工具进行基于内存的Rollout:使用多工具调用指令来指导模型在转出过程中将工具使用请求解码为特殊令牌(例如,)。检测到这些令牌后,将自动调用相应的工具,并将结果反馈集成回推理链中。为了减少由频繁的工具调用引起的延迟,我们合并了一个内存机制来缓存每个工具请求和它的输出之间的映射。这允许模型直接从内存中检索重复请求的响应,从而提高效率。
- 层次化奖励设计:我们不仅为大型语言模型设计了正确性和格式奖励,还引入了多工具协作奖励。这种设计旨在鼓励多种工具的使用,同时保持大型语言模型的正确性。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)