大模型技术栈
主流大模型
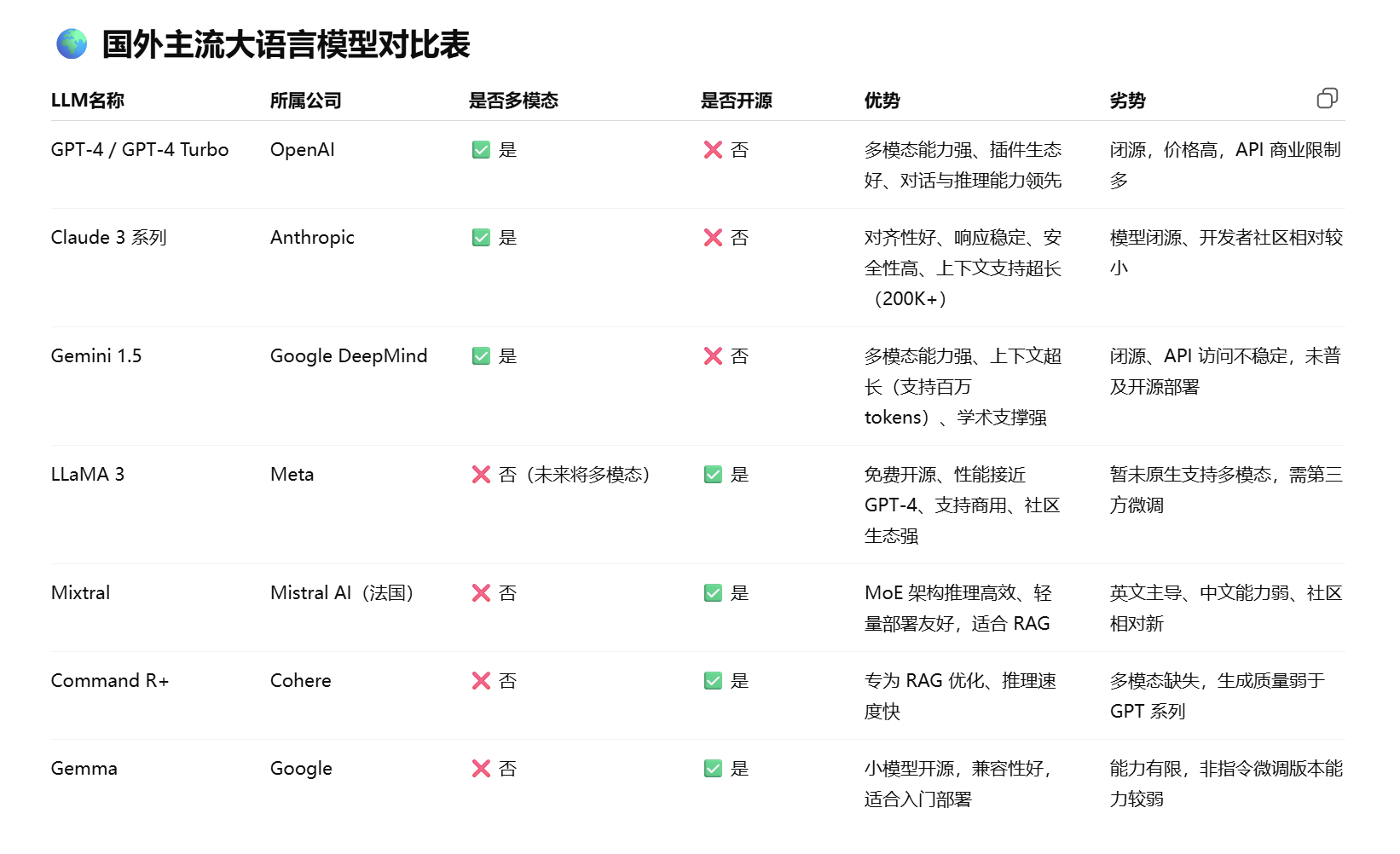
国外大模型

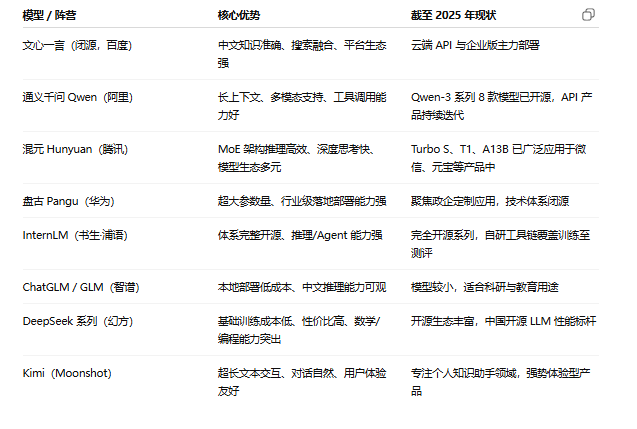
国内大模型

通用模型评估指标


训练范式
预训练

微调

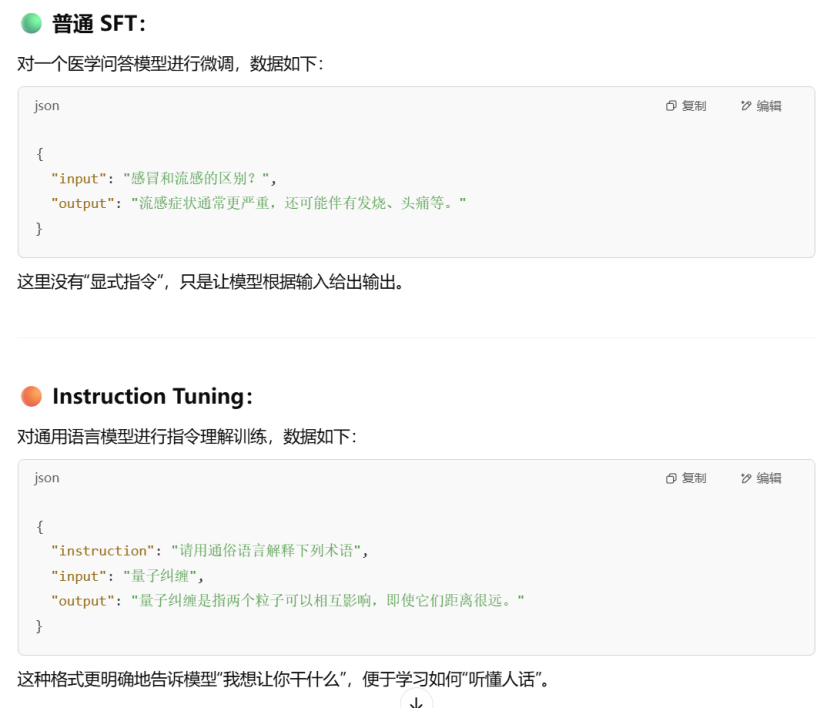
SFT(Supervised Fine-Tuning,监督微调)
下面是对 SFT(Supervised Fine-Tuning,监督微调)的详细讲解,通俗+技术兼顾,适合理解大模型在 对话能力、任务能力 上如何从“基础模型“演化为“能用模型”。

Instruction Tuning(指令微调)
Instruction Tuning(指令微调)通常就是指SFT(Supervised Fine-Tuning,监督微调)的一种具体应用形式。它们之间的关系如下:
Self-Instruct

Parameter-Efficient Tuning(参数高效微调)


Adapter Tuning
原理:在 Transformer 每层中插入小的“瓶颈网络”(通常是先降维再升维的 MLP),主模型参数冻结,只训练 Adapter。
优点:参数开销小,适用于多任务。
代表作:Houlsby Adapter(ICML 2019)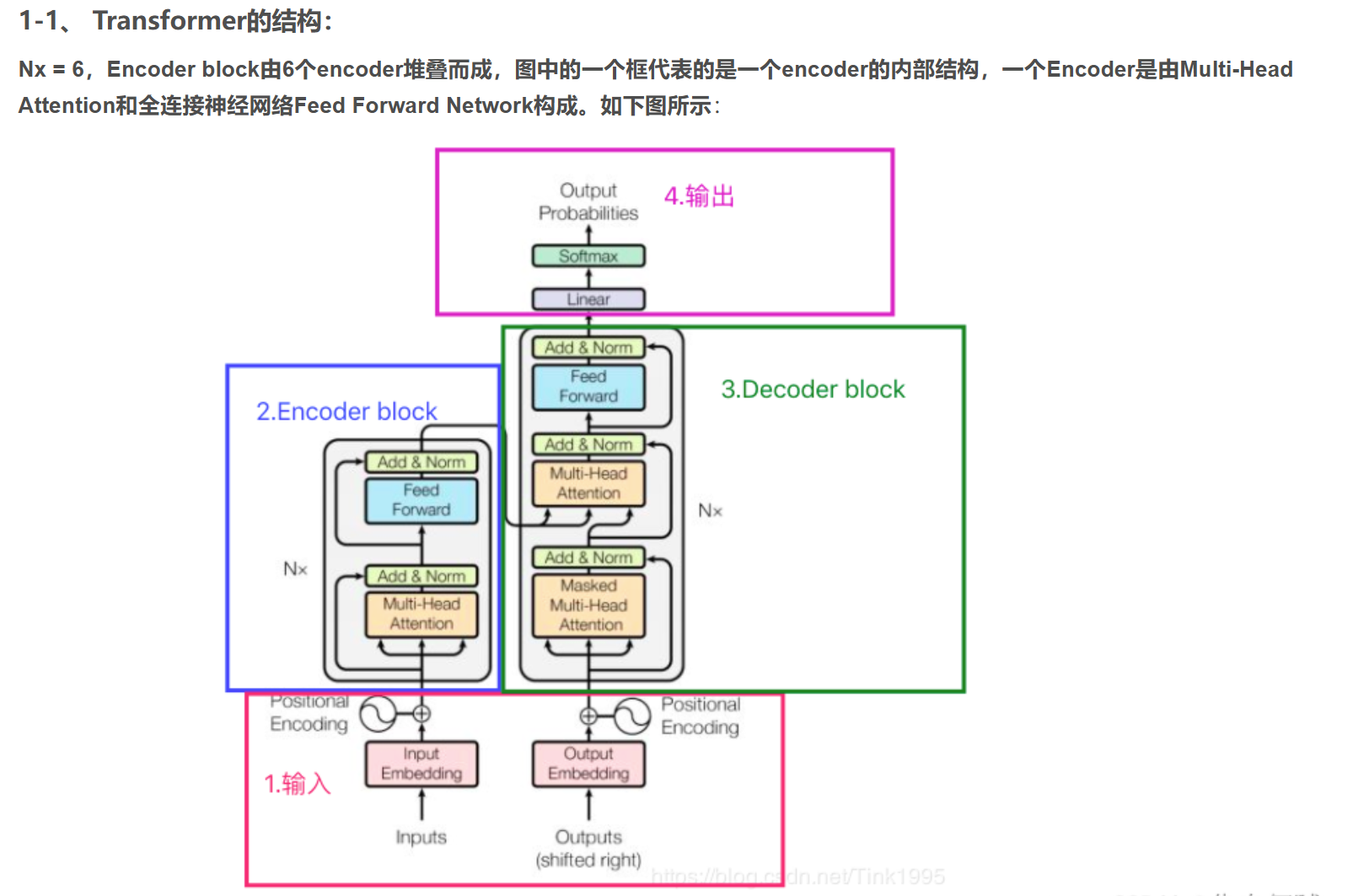
LoRA(Low-Rank Adaptation)
原理:将线性层权重变化表示为两个低秩矩阵相乘(ΔW ≈ A × B),主模型参数冻结,只训练 A 和 B。
优点:不改动原始模型结构,训练效率高,参数量极小。
代表作:LoRA(ICLR 2021)
QLoRA(Quantized LoRA)
在 LoRA 的基础上,把大模型权重 量化(通常为4位),进一步压缩显存占用,使得消费级GPU也能训练百亿参数模型。
1.将原始大模型量化为4-bit整数(NF4格式)
2.使用 double quantization 技术减少存储误差
3.在此基础上加上 LoRA模块进行训练
4.推理时也可以保持低比特推理(部署成本低)
4bit NormalFloat(NF4):对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比 4 bit整数和 4bit 浮点数更好的实证结果。
双量化(double quantization):对第一次量化后的那些常量再进行一次量化,减少存储空间。
分页优化器:使用NVIDIA统一内存特性,该特性可以在在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
Prefix Tuning
原理:在每一层注意力机制前加入可训练的“前缀向量”,这些前缀参与注意力计算,但主模型不变。
优点:参数少,适合生成类任务。
代表作:Prefix Tuning(ACL 2021)
Prompt Tuning
原理:在输入文本前添加若干可学习的“伪 token”(Prompt Embedding),主模型参数不动。(加在输入处)
优点:极低参数量,适用于冻结大模型进行下游任务适配。
代表作:Prompt Tuning(ICML 2021)
BitFit
原理:只训练 Transformer 层中的 bias 参数(偏置项),其余全部冻结。
优点:实现极其简单,参数量极少。
代表作:Ben Zaken et al. (2021)
Selective Layer Tuning
原理:仅微调模型中的某几层(如最后几层),其余层保持冻结。
优点:参数比全量训练少,效果保持较好。
Sparse Fine-Tuning
原理:只对模型中部分参数(如梯度较大者)进行微调,其余不动。
优点:进一步压缩参数变化空间,节省显存。
对齐

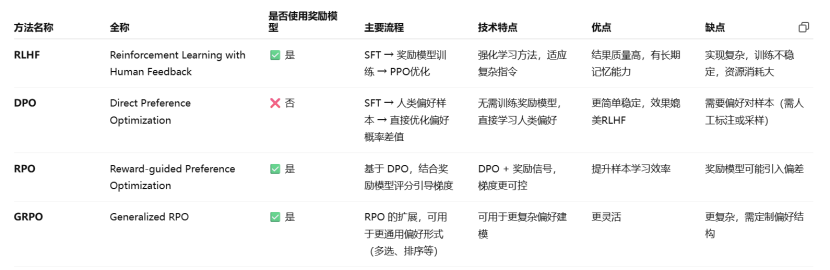
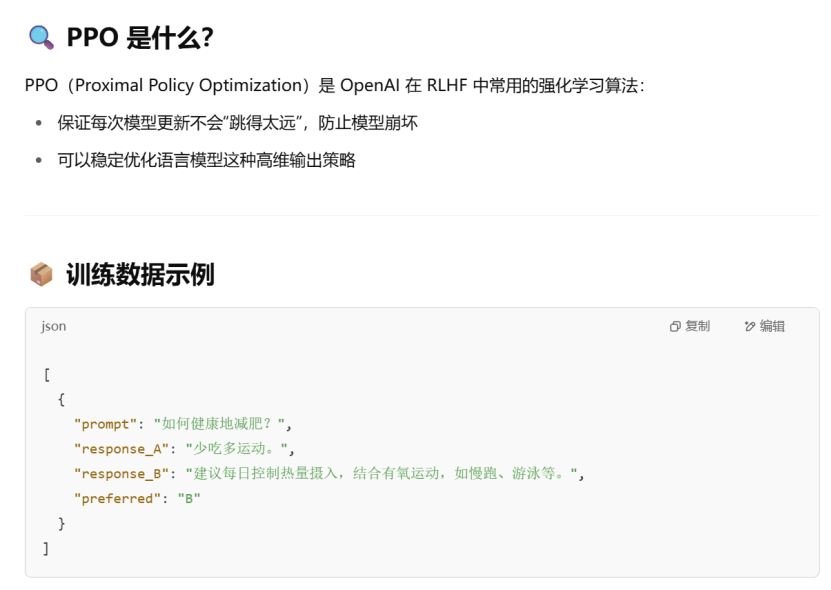
RLHF(Reinforcement Learning with Human Feedback)


DPO:Direct Preference Optimization(直接偏好优化)

RPO(Reward-weighted Preference Optimization)

GRPO

分布式训练
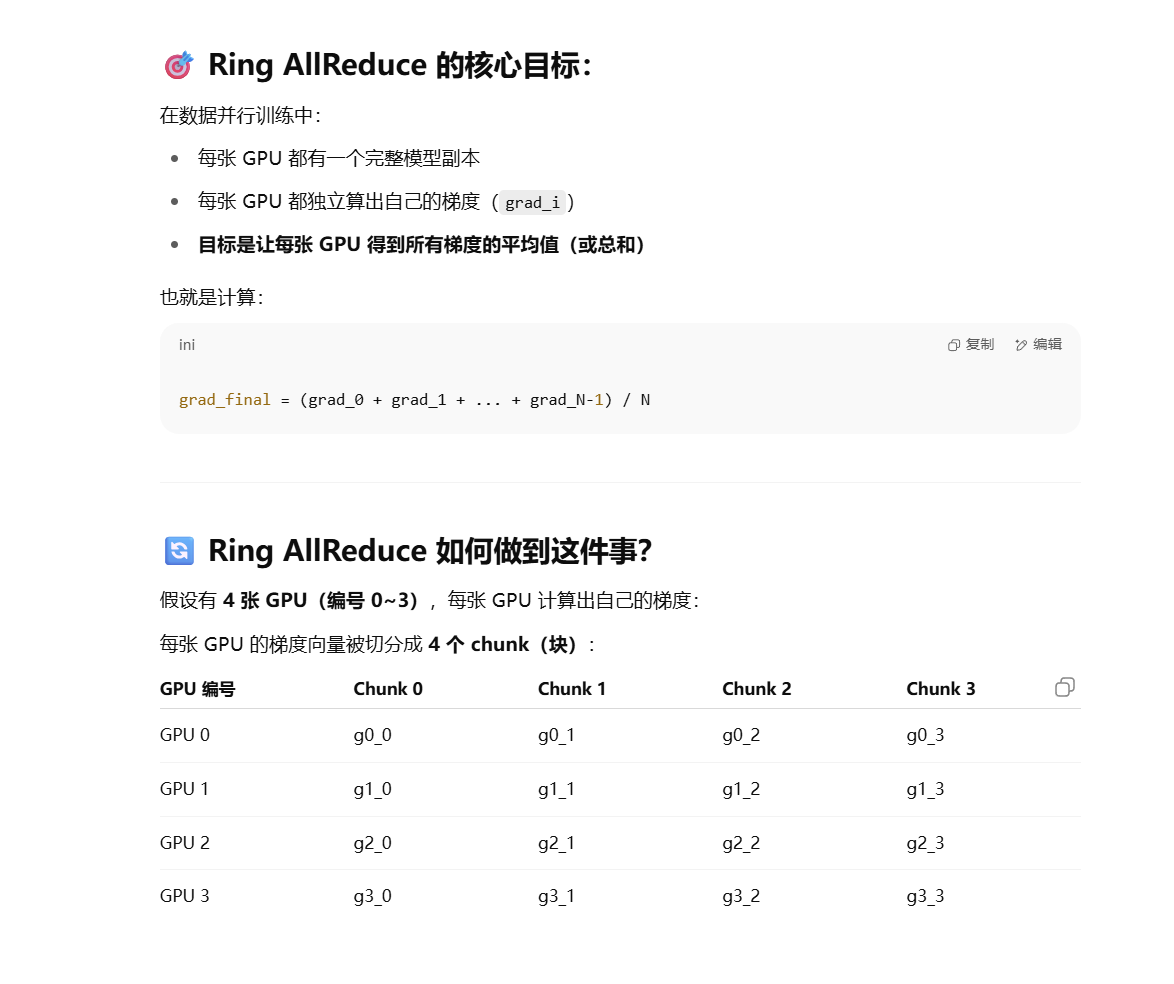
比如四个GPU卡,所有数据被分成四份,四个卡分别计算自己那一部分数据,最后汇总求梯度平均。
对于传统方法(PS 和 Ring AllReduce ),每张卡都会保存:
模型参数的完整副本 + 梯度副本 + 优化器状态(如使用 Adam)。
parameter server



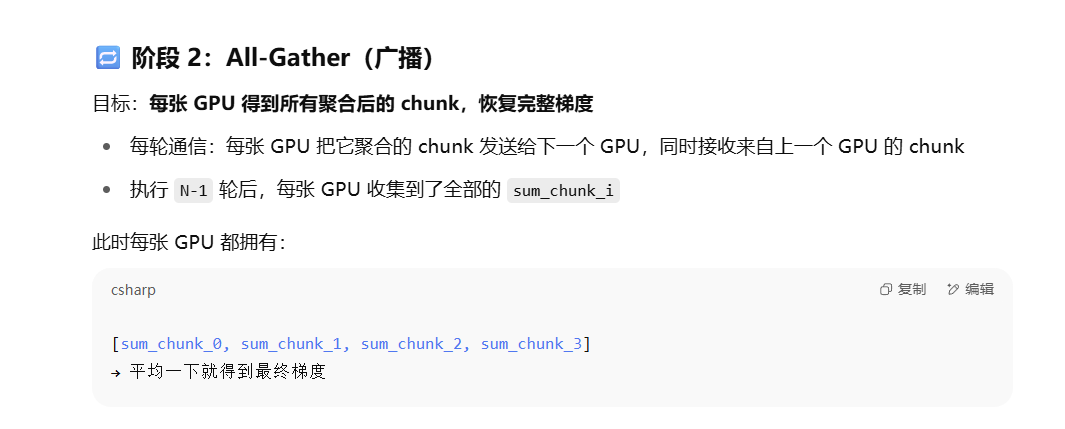
Ring All Reduce



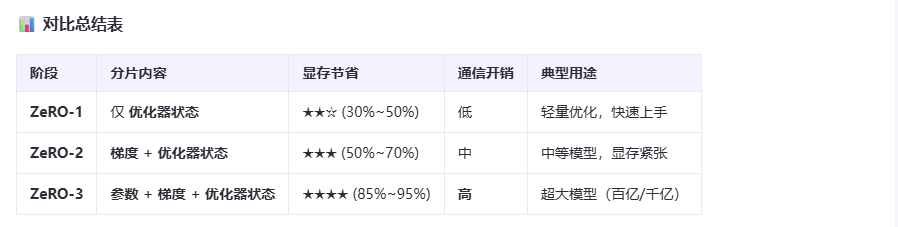
ZeRO-1/2/3 (三种递进的配置方案)




应用层组件与技术
RAG
数据结构化


向量检索


检索增强生成
RAG

KAG

Graph RAG

本地大模型推理部署框架

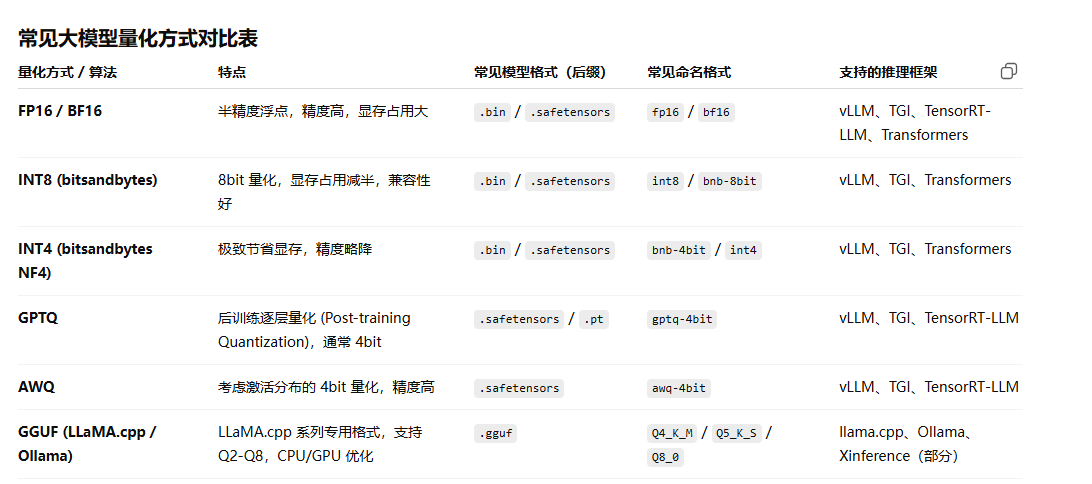
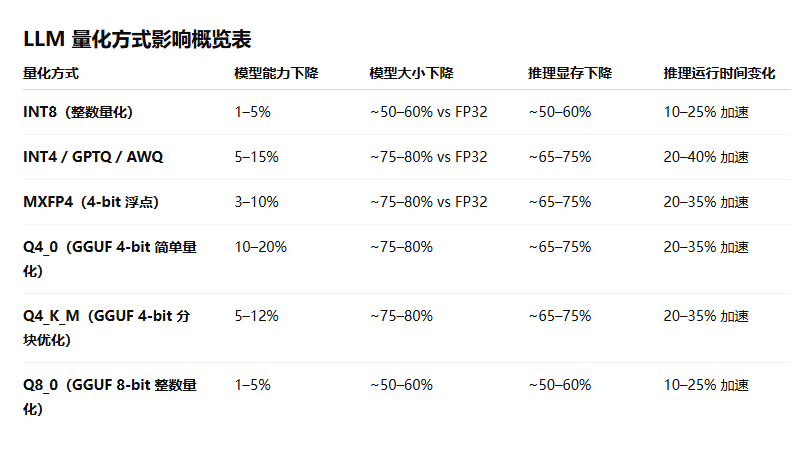
大模型微调主流框架



智能体系统
推理与规划
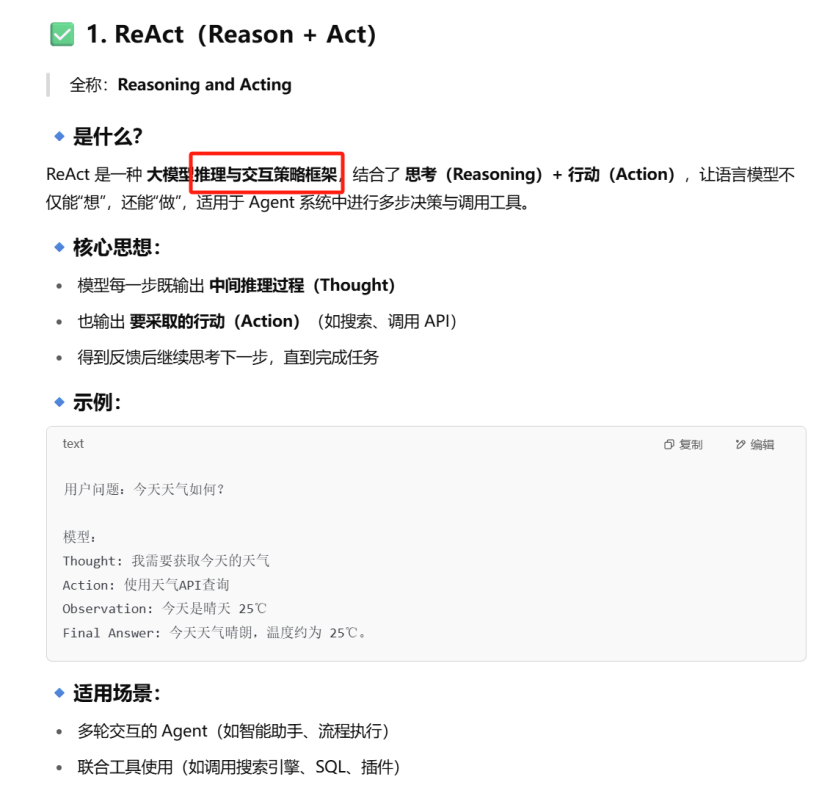
ReACT
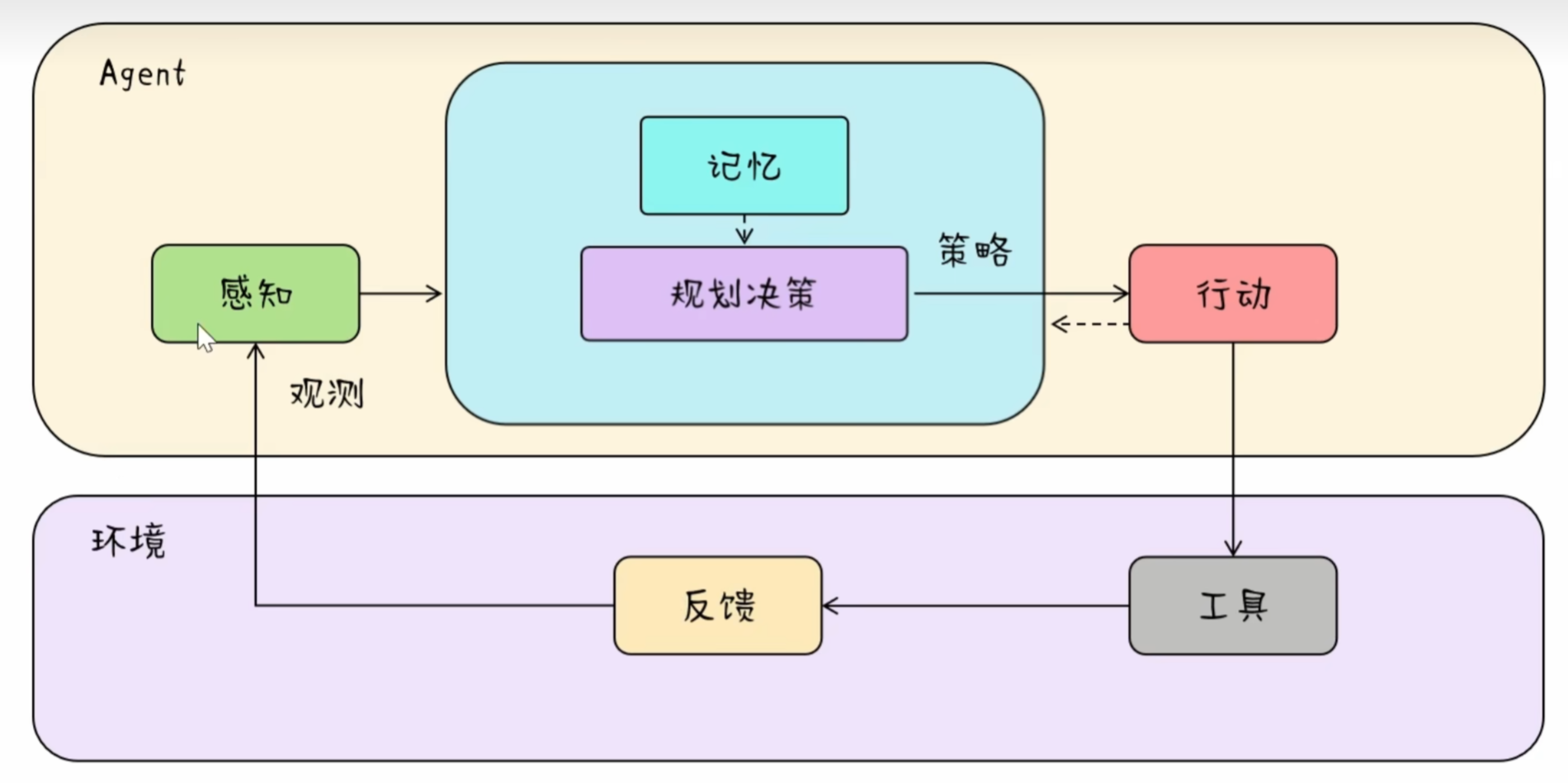
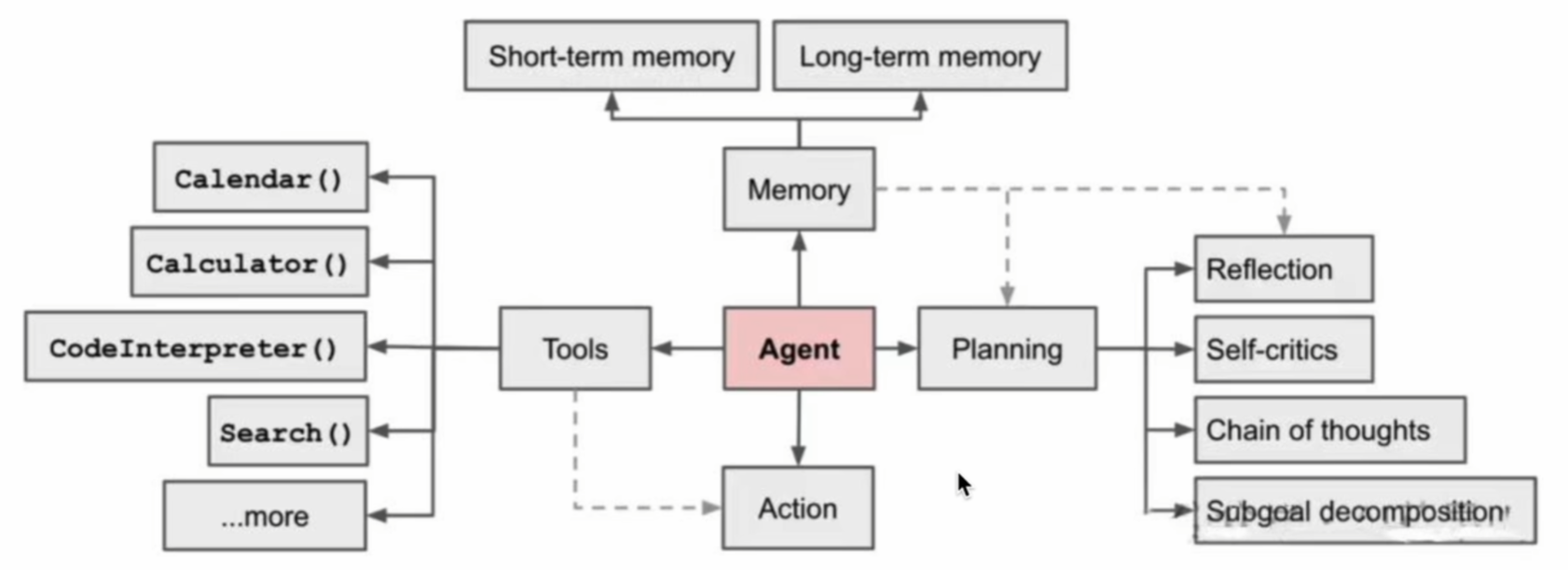
CoT

MCP




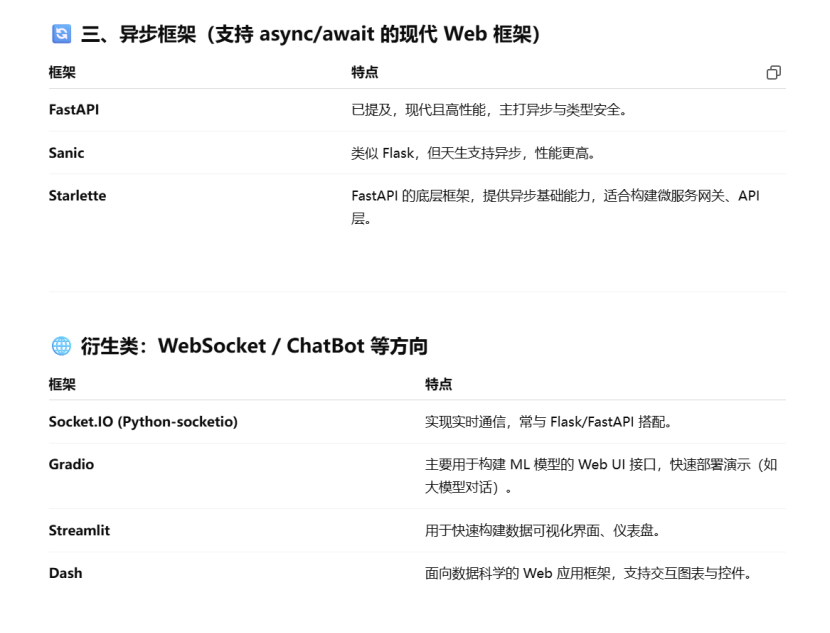
Python Web框架


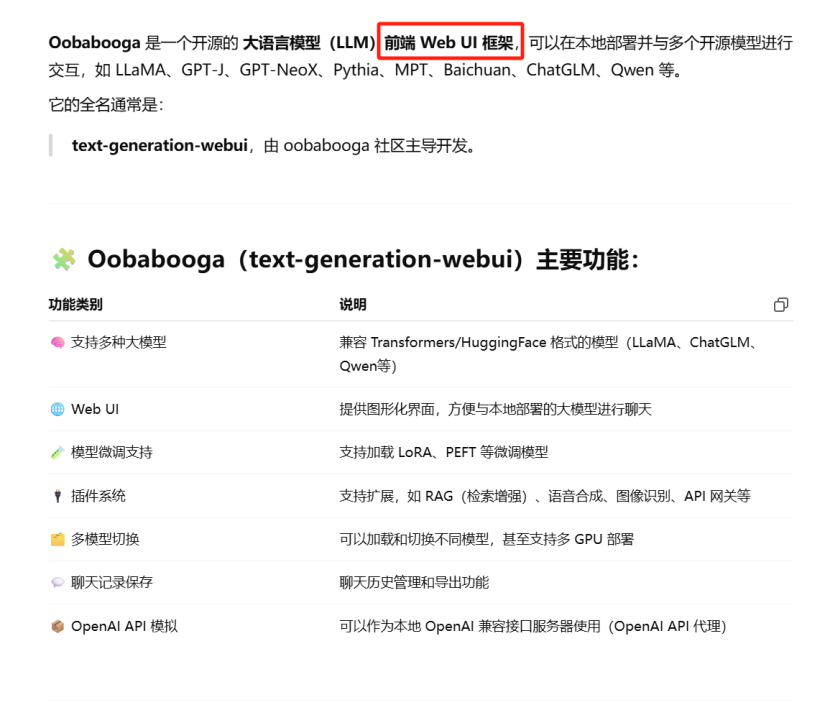

可视化平台
.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)