人脸识别AI项目
OpencvOpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在LinuxWindowsAndroid和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量C++类构成,同时提供了Python、RubyMATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。OpencvOPENCV的用途非常多,包括图像增强、人脸识别
1.嵌入式AI
1.1OPENCV的介绍以及用途
- Opencv的作用:

OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。 它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
- Opencv的用途:
OPENCV的用途非常多,包括图像增强、人脸识别、目标检测、图像分割、特征提取、图层叠加等等。我们能够想到的一些图像处理的功能Opencv都能够帮我们实现。后面我们的课程会详细见到OPENCV的基础功能,并和RV1126的API结合在一起进行视频图像的处理。
2.1.图像增强

图像增强指的是通过一些特殊的手段对原图像进行一些数据信息的变换或添加,并且有选择地突出图像中感兴趣区域的特征或者抑制原图像中一些不要的元素。在OPENCV中提供的丰富的API去对图像进行增强的功能,如:均值滤波、高斯滤波、伽马矫正、锐化、膨胀等等,这些功能能够成功有效对图像质量进行有效改造。如上图,OPENCV的图像增强后,右边的图像明显更加平滑了。
2.2.人脸检测

人脸识别指的是基于人的脸部特征信息来进行身份识别的一种生物识别技术,它主要是通过摄像头或者视频采集设备自动在图像中自动检测出人脸并进行识别。在OPENCV中也提供了丰富的接口对人脸进行检测,人脸检测也是OPENCV中最重要的功能点之一。如上图,经过OPENCV的人脸检测功能实时识别出图片中的人脸。
2.3.目标检测
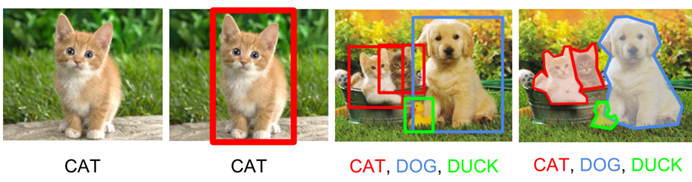
目标检测指的是根据现有的AI模型找出所有感兴趣的目标,并且确定他们的类别和位置。目标检测功能是计算机视觉最重要的功能之一,由于在目标检测中要考虑各个物体的外观、姿态等等。所以目标检测在视觉领域一直是非常具有挑战性的,OPENCV也提供了大量的API让开发者能够快速地开发目标检测的功能。如上图,经过OPENCV的目标检测后,它可以识别出目前的图片是哪种动物。
OPENCV的API效率低,一般直接用芯片自带的API开发
2.4.图层叠加

图像叠加指的是在源图像中选择一个感兴趣区域,添加自己的图片元素。图片叠加本质上是要把两个图像的像素点进行叠加,最常见的图层叠加案例是在原视频图像中添加LOGO、实时时间戳等等。如上图,原图片添加了OPENCV的图标LOGO,就可以实现在原图像中添加LOGO的功能。
1.2OPENCV的交叉编译和项目Makefile讲解
- OPENCV交叉编译的步骤
前言:在交叉编译之前需要把交叉编译工具链安装好,在我们Ubuntu里面它放在/opt目录里面,如下图:
![]()
交叉编译工具是:
/opt/rv1126_rv1109_linux_sdk_v1.8.0_20210224/prebuilts/gcc/linux-x86/arm/gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf/bin
1.1 解压并且打开opencv目录
先用unzip opencv-3.4.16.zip来解压opencv的压缩包,并且打开opencv目录(cd opencv-3.4.16)如下图
![]()
1.2 修改opencv的cmake脚本的内容
先cd platforms/linux然后修改arm-gnueabi.toolchain.cmake文件(vim arm-gnueabi.toolchain.cmake )如下图:
![]()
内容修改如下:
![]()
这里的修改关键是第二个,需要把RV1126的交叉编译工具链写上去
1.3. 在opencv-3.4.16的目录建立build
![]()
在这个目录下使用mkdir build建立编译目录
1.4. 进入build目录进行cmake配置
![]()
在build目录下使用配置命令:
cmake -DCMKAE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=../platforms/linux/arm-gnueabi.toolchain.cmake -DCMAKE_INSTALL_PREFIX=/opt/arm_opencv_source -DSOFTFP=ON -DENABLE_PROFILING=OFF -DWITH_OPENCL=OFF -DWITH_TBB=ON -DWITH_V4L=ON -DHAVE_CAMV4L2=ON -DBUILD_TESTS=OFF -DINSTALL_PYTHON_EXAMPLES=OFF -DBUILD_EXAMPLES=OFF -DWITH_FFMPEG=ON -DHAVE_FFMPEG=ON -DBUILD_opencv_js=OFF -DENABLE_NEON=OFF -DENABLE_VFPV3=OFF ../
这里配置安装的目录是/opt/arm_opencv_source,若配置成功则会有以下打印:
1.5. 编译opencv的动态库
配置完成之后则先用用make进行编译(这里用make -j8),如下图:
![]()
当make成功的话,则会出现下面的图
1.5. 安装opencv的动态库
当编译完成之后,则需要使用make install安装动态库,如下图:
最终把动态库安装到/opt/arm_opencv_source里面,如下图:
![]()
bin:可执行文件文件
include:Opencv的头文件
lib:opencv的交叉编译动态库
share:一些共享的数据,通常无需关注
1.6. 把交叉编译的动态库拷贝到RV1126的板子里面
![]()
(图一)
![]()
(图二)
最后把Ubuntu交叉编译的动态库(图一)拷贝到板子的/usr/lib目录里面(图二),此时RV1126的板子就可以直接使用OPENCV功能了
- Makefile的讲解
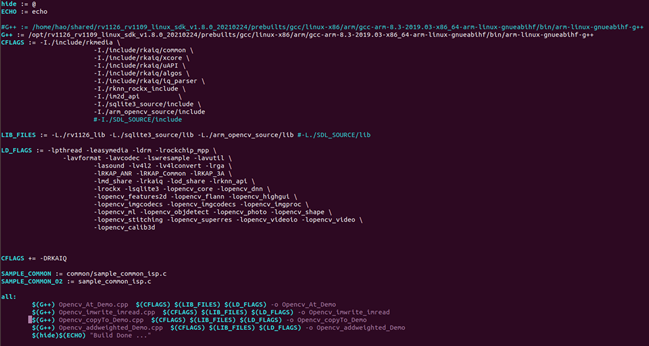
上图是Makefile的具体内容,后面OPENCV都是参照这个语法去进行编译。它的基本语法是:
$(G++) xxx.cpp $(CFLAGS) $(LIB_FILES) $(LIB_FLAGS) -o xxx
$(G++):RV1126的交叉编译工具链,这里是:
/opt/rv1126_rv1109_linux_sdk_v1.8.0_20210224/prebuilts/gcc/linux-x86/arm/gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf/bin/arm-linux-gnueabihf-g++
$(CFLAGS):项目包含的头文件,最主要的包括rkmedia的头文件(-I./include/rkmedia) 、rknn的头文件(-I./rknn_rocx_include)、OPENCV的头文件(-I./arm_opencv_source/include), 其他的include没怎么用到。
$(LIBS_FILES): 项目包含的库目录,包括了RV1126的库(-L./rv1126_lib)、sqlite3的库(-L./sqlite3_source/lib)、opencv的动态库(-L./arm_opencv_source/lib)
$(LD_FLAGS):动态库的链接,这里包括了Opencv的链接(-lopencv_开头的库)、rkmedia的动态库链接(-ldrm、 -leasymedia、-lrockchip_mpp)等等。
-o:输出的可执行文件
1.3OPENCV重点结构体Mat的讲解
- 什么是Mat
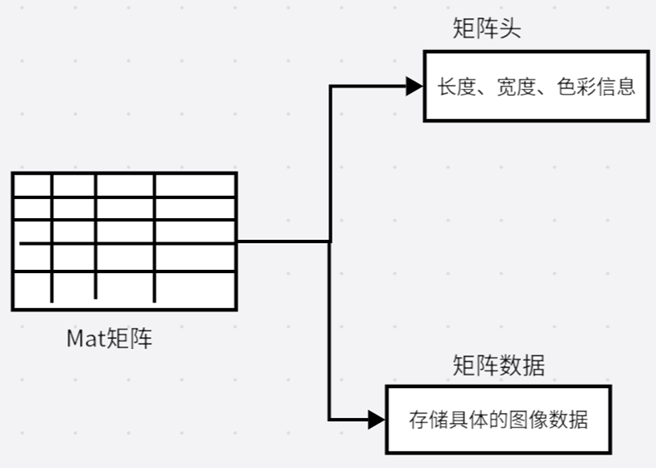
在OPENCV中,Mat是整个图像存储的核心也是所有图像处理的最基础的类。Mat主要存储图像的矩阵类型,包括向量、矩阵、灰度或者彩色图像等等。Mat的对象可以分成矩阵头和矩阵数据两个大部分,矩阵头是存储图像的长度、宽度、色彩信息等头部信息;矩阵数据则是存储具体的图像数据。若开发者想对OPENCV的Mat中的信息进行修改,则是改变像素信息的数据部分。
Mat的输出一般包含图像的宽度、高度、通道数量、通道深度、字节类
- Mat的深度和字节类型
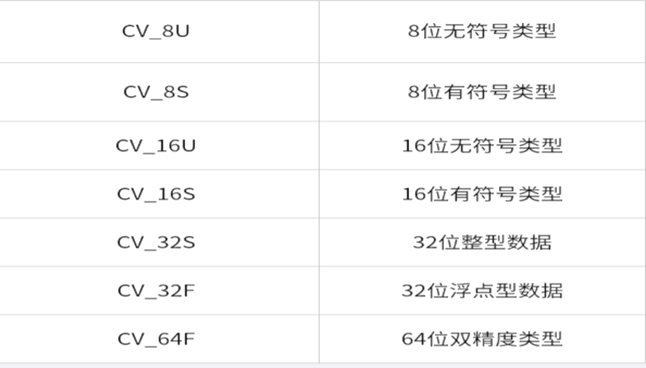
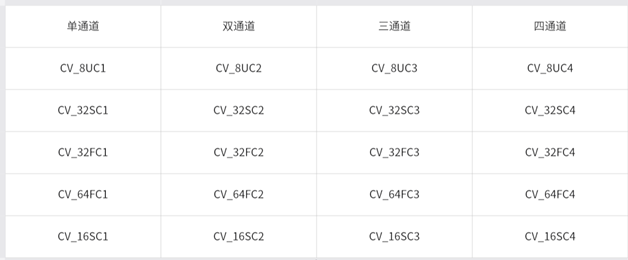
上面是Opencv的字节类型和通道数的定义,在OPENCV中通常分为四个通道和8种数据类型。分别是单通道(灰度图)、双通道(二值图像)、三通道(RGB彩色图像)、四通道(带Alpha的四通道图像)。
灰度图:

灰度图又称之为灰阶图,颜色介于白色和黑色之间按对数关系分为若干等级,这种图像称之为灰度。灰度分为256个阶
二值图像:

二值图像中的图像中每一个像素只有两个值分别是0和1,其中0表示黑色、1表示白色
三通道图像:

三通道(RGB)图像也就是我们所说的RGB图像,所以三通道图像可以用来彩色图像。
四通道图像:

四通道(ARGB)也就是在彩色图像中
2.1.单通道分类:
CV_8UC1:指的是一个8位无符号整型单通道矩阵
CV_32SC1:指的是一个32位整型单通道矩阵
CV_32FC1:指的是一个32位浮点型单通道矩阵
CV_64FC1:指的是一个64位浮点型单通道矩阵
CV_16SC1:指的是一个16位整型单通道矩阵
2.2.双通道分类:
CV_8UC2:指的是一个8位无符号整型双通道矩阵
CV_32SC2:指的是一个32位整型双通道矩阵
CV_32FC2:指的是一个32位浮点型双通道矩阵
CV_64FC2:指的是一个64位浮点型双通道矩阵
CV_16SC2:指的是一个16位整型双通道矩
2.3.三通道分类:
CV_8UC3:指的是一个8位无符号整型三通道矩阵
CV_32SC3:指的是一个32位整型三通道矩阵
CV_32FC3:指的是一个32位浮点型三通道矩阵
CV_64FC3:指的是一个64位浮点型三通道矩阵
CV_16SC3:指的是一个16位整型三通道矩阵
2.4.四通道分类:
CV_8UC4:指的是一个8位无符号整型四通道矩阵
CV_32SC4:指的是一个32位整型四通道矩阵
CV_32FC4:指的是一个32位浮点型四通道矩阵
CV_64FC4:指的是一个64位浮点型四通道矩阵
CV_16SC4:指的是一个16位整型四通道矩阵
- Mat的创建和构造方法
Mat的创建一般分为五种方式,分别是Mat(int rows, int cols, int type)、Mat(Size size, int type)、Mat::zeros(Size(width,height),type),下面我将把三种构造的方式都详细说一遍。
3.1.Mat(int rows, int cols, int type);
重载的构造函数,这个构造函数在创建的时候,提供矩阵的大小,分别是rows、cols以及存储类型type
rows:行数,也指的是图像的高度,height。
cols:列数,也指的是图像的宽度,width。
type:通道类型,具体的看上面的图
示例:Mat t1 = Mat(300,300,CV_8UC1),这指的是创建一个width:300,height:300,单通道的灰度图像.
3.2.Mat(Size size, int type);
重载的构造函数,这个构造函数在创建的时候,需要传入Size类和类型。
第一个传参:Size结构体,Size(width,height)
第二个传参:type通道类型,具体的看上面的图
示例:Mat t2 = Mat(Size(300,300),CV_8SC3),这指的是创建一个width:300,height:300,三通道的灰度图像
3.3.Mat(int rows, int cols, int type, const Scalar& s);
重载的构造函数,这个构造函数在创建的时候,提供矩阵的大小,分别是rows、cols、存储类型type、还有Scalar颜色标量。
第一个传参:rows行数,也指的是图像的高度,height。
第二个传参:cols列数,也指的是图像的宽度,width。
第三个传参:type通道类型,具体的看上面的图
第四个传参:Scalar颜色标量,Scalar(v0,v1,v2,v3),v0,v1,v2,v3分别对应OPENCV颜色分量的四个值
示例: Mat mat = Mat(300,300,CV_8UC3,Scalar(255,255,255));表示的是创建一个cols:300,rows:300,三通道的灰度,颜色标量为白色的图像
3.4.Mat::zeros(rows,cols,type);
重载的构造函数,这个构造函数在创建的时候,提供矩阵的大小,分别是rows、cols以及存储类型type。ZROS相当于创建一张黑色的图片,每个像素通道为0,并且Scalar(0,0,0)。
第一个传参:rows行数,也指的是图像的高度,height。
第二个传参:cols列数,也指的是图像的宽度,width。
第三个传参:type通道类型,具体的看上面的图
示例: Mat::zeros(300,300,CV_8SC3);,这指的是创建一个width:300,height:300,三通道的彩色图像,Scalar(0,0,0),相当于
Mat mat = Mat(300,300,CV_8SC3,Scalar(0,0,0));
3.5.Mat::ones(rows,cols,type);
重载的构造函数,这个构造函数在创建的时候,提供矩阵的大小,分别是rows、cols以及存储类型type。ONES相当于每个像素第一个通道为1,后面两个通道为0。
第一个传参:rows行数,也指的是图像的高度,height。
第二个传参:cols列数,也指的是图像的宽度,width。
第三个传参:type通道类型,具体的看上面的图
示例: Mat::ones(300,300,CV_8SC3),这指的是创建一个width:300,height:300, 三通道的彩色图像,Scalar(1,0,0),
这等同于Mat mat = Mat(300,300,CV_8SC3,Scalar(1,0,0));
- 代码实现OPENCV创建Mat
4.1. 实现Mat构造,并保存到本地

这指的是创建一个width:300,height:300,三通道的灰度图像, 粉色的图像
4.2. 利用Mat(Size size, int type)构造生成矩阵数据,并保存到本地
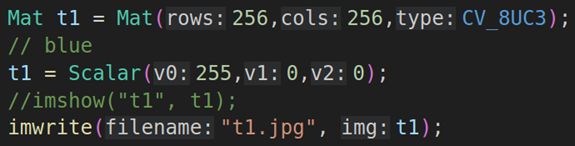
这指的是创建一个width:256,height:256,三通道的图像。
然后再用t1 = Scalar(255,0,0);把矩阵变成蓝色
最后把矩阵保存到本地
4.3. 利用Mat::zeros(rows,cols,type)构造生成矩阵数据,并保存到本地
![]()
利用zeros去创建矩阵,ZROS相当于创建一张黑色的图片,每个像素通道为0,并且Scalar(0,0,0)。
然后把图片保存到本地
4.4. 利用Mat::ones(rows,cols,type)构造生成矩阵数据,并保存到本地

利用ones去创建矩阵,ONES相当于每个像素第一个通道为1,后面两个通道为0,相当于Scalar(1,0,0))
然后把图片保存到本地
实际操作:Opencv_Mat_Demo_Project文件夹放入share ,在linux中复制到douyin_project的地方,vscode打开。
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv; //Must Need Write cv
using namespace std;
int main()
{
Mat t0 = Mat(300, 300, CV_8UC3, Scalar(218,112,214));
imwrite("t0.jpg", t0);
Mat t1 = Mat(300, 300, CV_8UC3);
t1 = Scalar(255,0,0);
imwrite("t1.jpg", t1);
Mat t2 = Mat::zeros(300,300,CV_8UC3);
imwrite("t2.jpg", t2);
Mat t3 = Mat::ones(300,300,CV_8UC3);
imwrite("t3.jpg", t3);
Mat t4 = Mat(Size(300,300), CV_8UC3);
imwrite("t4.jpg", t4);
return 0;
}编译,复制到share。拷贝到桌面,放入板子/tmp/,
cd /userdata/
cp /tmp/Opencv_Mat_Demo .
chmod 777 ....
执行
生成了t0.jpg t1.jpg t2.jpg t3.jpg t4.jpg
cp t*.jpg /tmp/
在/tmp/打开图片
1.4利用opencv的imread读取图片信息和imwrite写入数据
imread读取图片: mat imread(const string& filename, int flags=IMREAD_COLOR);
flag有三种,灰度图,彩色图,原图。
mat img_mat=imread("frame1.jpg");
printf("%d %d %d",img_mat.cols,img_mat.rows,img_mat.channels());
imwrite保存图片
bool imwrite(const string& filename, inputarray image,const std::vector<int>¶ms);
保存的文件名,保存的数据,保存的可选参数:有很多。
mat mat = mat(300,300,CV_8UC3,Scaler(218,112,214));
imwrite("mat_demo.jpg",mat);
带参数方式的保存:
Mat quality_frame1_mat=imread(filename:"frame1.jpg");
std::vector<int> params = {[0]=cv::IMWRITE_JPGE_QUALITY,[1]=40};
imwrite(filename:" quality_mat_demo.jpg",img:quality_frame1_mat,params);
编码质量关乎文件大小和画面质量。
1.5opencv的at函数遍历图像像素
mat矩阵里就是一个一个的像素点的值,at去获取值,去修改图像。很多功能都用at去实现的,我们开发时,一般都用功能的API。


mat.at<i,j>[0];第i行第j列的第一个通道

单通道修改
实际操作:Opencv_At_Demo_Project文件夹放入share ,在linux中复制到douyin_project的地方,vscode打开。
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main()
{
Mat mat = imread("frame1.jpg");
//循环cols
for (int i = 0; i < mat.rows; i++)
{
//循环rows
for (int j = 0; j < mat.cols; j++)
{
mat.at<Vec3b>(i,j)[0] = (int)mat.at<Vec3b>(i,j)[0] - 10; //R Channel
mat.at<Vec3b>(i,j)[1] = (int)mat.at<Vec3b>(i,j)[1] - 50; //G Channel
mat.at<Vec3b>(i,j)[2] = (int)mat.at<Vec3b>(i,j)[2] - 10; //B Channel
}
}
imwrite("frame1_process.jpg", mat);
//single channels
Mat before_process_gray_Image;
Mat process_gray_Image;
cvtColor(mat, before_process_gray_Image, COLOR_RGB2GRAY); //RGB图像转换成GRAY灰度,保存没有进行操作的灰度图
cvtColor(mat, process_gray_Image, COLOR_RGB2GRAY); //RGB图像转换成GRAY灰度,保存进行操作的灰度图
for (int i = 0; i < process_gray_Image.rows; i++)
{
for (int j = 0; j < process_gray_Image.cols; j++)
{
process_gray_Image.at<uchar>(i,j) = 50 - process_gray_Image.at<uchar>(i,j); //对灰度像素进行相减操作
}
}
imwrite("gray_frame1.jpg", before_process_gray_Image);
imwrite("gray_frame1_process.jpg", process_gray_Image);
return 0;
}编译,复制到share。程序和frame1.jpg拷贝到桌面,放入板子/tmp/,
chmod 777 ....
执行
生成图片
在/tmp/打开图片


1.6opencv的图像叠加功能

在原图上面,把logo添加上去,要在原图上用矩形确定一个区域(rect可感兴趣区域,长宽和logo的长宽一样),把logo的数据复制到这个区域。
Opencv_addImage_Demo文件夹放到share里,linux里复制到project下面,vscode打开
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Mat src_image_pic = imread("frame1.jpg"); //src_image_pic是原图像数据
Mat logo_image_pic = imread("jaychou.png");//logo_image_pic是LOGO图像的数据
Mat logo_image_roi = src_image_pic(Rect(0,0,logo_image_pic.cols, logo_image_pic.rows)); //在src_image_pic截取可感兴趣区域roi
logo_image_pic.copyTo(logo_image_roi);//把LOGO图像copyTo到可感兴趣区域
imwrite("copyImage_output.jpg", src_image_pic);//imwrite写入数据
return 0;
}编译完,程序和原图,logo图放到板子上,改权限,运行

可以把logo和原图加权融合,谁的加权值大,谁就更清晰。
两个融合图像尺寸不一样大时:要在大图上给一个感兴趣区域,对该区域加权,对logo图像加权,然后区域和logo融合到一块。最后输出大图。
两个融合图像尺寸一致时:直接加权,然后两张图融合就行,不用给感兴趣区域。最后输出一个全新的图。
Opencv_addImage_Demo文件夹放到share里,linux里复制到project下面,vscode打开
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main(int argc, char * argv[])
{
Mat src1 = imread(argv[1]); //src1原图像的数据
Mat src2 = imread(argv[2]); //src2是LOGO图像的数据
//判断src1长度和src2是否相同,若不同则进行以下操作
if(src1.size != src2.size)
{
Mat image_roi = src1(Rect(20 , 20, src2.cols, src2.rows)); //在原图像中截取一个可感兴趣区域,感兴趣区域
double alpha = 0.4; //alpha第一个图像的权重值,这里是0.4
double beta = 1 - alpha;//beta是第二个图像权重值,1- alpha = 0.6,第二个图像的清晰度较高
int gamma = 0; //gamma默认为0
addWeighted(image_roi, alpha , src2, beta, gamma, image_roi);//调用addWeighted对src1和src2进行图像融合
imwrite("addweighted_norsamesize.jpg", src1);
}
else
{
double alpha = 0.4;//alpha第一个图像的权重值,这里是0.4
double beta = 1 - alpha;//beta是第二个图像权重值,1- alpha = 0.6,第二个图像的清晰度较高
int gamma = 0;
Mat dst;
addWeighted(src1, alpha , src2, beta, gamma, dst); //调用addWeighted对src1和src2进行图像融合
imwrite("addweighted_samesize.jpg", dst);
}
return 0;
}
编译,复制到share,从share复制到桌面,把可执行文件,两张图片加入板子。修改权限,执行程序(记得加参数:两张图像不一样大)。
执行程序(记得加参数:两张图像一样大)。
1.7OPENCV查找图形轮廓重要API讲解
图像形状查找在OPENCV里面是非常常见的功能,它常用于视觉任务、目标检测、图像分割等等。在OPENCV中通常使用Canny函数、findContours函数、drawContours函数结合在一起去做轮廓的形检测。
一.重要的函数讲解:
-
- findContours函数的简介以及定义

在OPENCV中通常使用findContours函数去寻找图片的轮廓,也是OPENCV中处理轮廓最重要的函数之一,它常用于找到二值图像中所有物体的轮廓。它的实现原理是通过扫描一张二值图像,然后找到所有的轮廓,并把所有的数据存储在向量里面。下面我们来看看findContours的函数定义
CV_EXPORTS_W void findContours( InputOutputArray image, OutputArrayOfArrays contours,
OutputArray hierarchy, int mode,
int method, Point offset = Point());
第一个参数:image输入的二值图像,这个图像通常是用在边缘检测、阈值处理等等
第二个参数:contours输出的轮廓集合,每一个轮廓都是由点组成,通常用vector<vector<Point>>来表示
第三个参数:hierarchy输出的轮廓层次结构,这通常表示轮廓之间的父子关系,这个是可选参数,通常用vector<Vec4i> hierarchy来表示。比方说,第i个轮廓,hierarchy[i][0]、hierarchy[i][1]、hierarchy[i][2]、hierarchy[i][3], 依次为第i个轮廓[Next、Pervious、First_Child,Parent], 这表示的是相同等级下种下一轮廓、前一轮廓,第一个子轮廓和父轮廓的索引号。若轮廓i没有下一个,前一个或者父级轮廓,则层次相应的元素是负数。如下图:
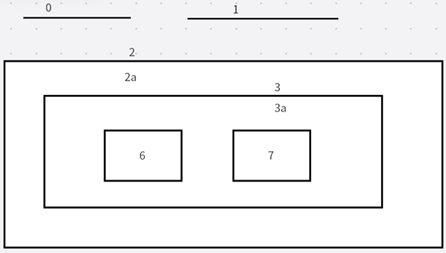
Next:表示同一级别的下一个轮廓索引,若我们图片中取出轮廓0,同一水平的下一个是轮廓1。所以说当轮廓 == 0的时候,NEXT就是轮廓1。
Previous:表示同一级别的上一个轮廓索引,如轮廓1的同一级别的上一个是轮廓0。以此类推,轮廓2的上一个轮廓是轮廓1。
First_Child:表示的是当前轮廓的第一个子轮廓的索引。比方说,对于轮廓2,子轮廓是2a,所以轮廓2的First_Child是轮廓2a相对应的索引值。而对于3a来说,它有两个轮廓分别是6,7, 但这里只能取第一个轮廓,所以这里是6。
Parent:表示的是当前轮廓的父轮廓索引,比方说对于轮廓6和轮廓7来说,它们的父轮廓都是3a。
第四个参数:mode轮廓检索模式,通常有以下选项,分别是:RETR_EXTERNAL(只检测最外层轮廓)、RETR_LIST(检测所有轮廓,包括内围、外围轮廓,但是检测到的轮廓不建立等级关系,都是独立的)、RETR_CCOMP(检测所有轮廓,但是所有的轮廓只建立两个等级关系,也就是外围是顶层,而外围内的内部轮廓都属于顶层)、RETR_TREE(检测所有轮廓并建立轮廓树,这个模式下外围轮廓包含内层轮廓,内层还可以继续嵌套)。
第五个参数:method轮廓近似方法,通常有以下的几种方法,分别是CHAIN_APPROX_NONE(存储所有顶点)(图像原封不动的还原)、CHAIN_APPROX_SIMPLE(仅存储轮廓的拐点信息,并把所有轮廓拐点处的点保存到向量里面)(不画线,只保留重要的拐点信息,其他忽略)、CHAIN_APPROX_TC89_L1(使用TEH_CHAIN近似算法)。
第六个参数:offset轮廓点偏移量,默认(0,0)
-
- drawContours函数的简介以及定义

在OPENCV中drawContours常用于绘制图像的轮廓,如上图,我们来看看这个函数的API定义:
CV_EXPORTS_W void drawContours( InputOutputArray image, InputArrayOfArrays contours,
int contourIdx, const Scalar& color,
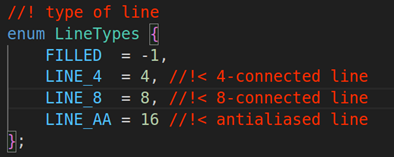
int thickness = 1, int lineType = LINE_8,
InputArray hierarchy = noArray(),
int maxLevel = INT_MAX, Point offset = Point() );
第一个参数:image输出图像,即绘制轮廓后的图像
第二个参数:contours轮廓的集合,它是由一系列的点组成
第三个参数:contourIdx、轮廓索引数组,指定要绘制哪些轮廓
第四个参数:contourColor,轮廓颜色,使用Scalar类型表示
第五个参数:thickness,轮廓线宽,默认1
第六个参数:lineType ,轮廓线类型,默认为LINE_8
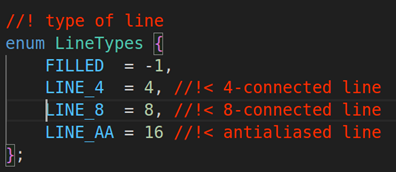
第七个参数:hierarchy ,轮廓层次结构,用于绘制轮廓的父子关系。默认为noArray()
第八个参数:maxLevel ,表示绘制轮廓的最大层级数量。若maxLevel 为0,则只绘制指定的轮廓;若maxLevel 为1,则绘制轮廓极其所有嵌套轮廓;若maxLevel 为2,则绘制轮廓、所有嵌套轮廓、所有嵌套到嵌套的轮廓。
第九个参数:轮廓点的偏移量,默认为(0,0)
-
- Canny函数的简介以及定义

Canny函数主要用在OPENCV的边缘检测计算,边缘检测是OPENCV图像中非常重要的功能,它的功能如(上图一)。它能够高效地提取图像中的边缘信息,而Canny边缘检测是OPENCV里面最优秀和最精准的边缘检测方法。Canny的工作原理可以分为以下比较重要的步骤进行处理,分别是高斯滤波(将图像转换为灰度图像,高斯滤波作用是平滑图像,让Canny检测的时候准确率更高,就是去噪,把不重要的去掉)、梯度强度和方向的计算(计算图像中每个像素的强度和方向、强度表示像素点的边缘强度、梯度表示的是边缘方向这里的梯度需要用到sobel因子)、非极大抑制(经过NMS操作后,会除去一些不是边缘的像素点)、双阈值处理(给出一个阈值,若超过这个阈值的边缘则会被保留)、边缘链接(经过双阈值处理过后,强边缘则会留下来,弱边缘则会被抑制,并会把所有的强边缘全部连接起来),步骤如下图2。

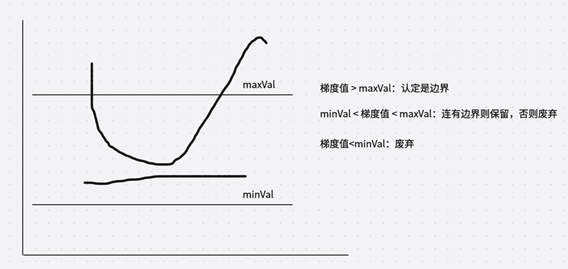
下面是双阈值的处理的图解:当梯度值大于maxVal则认为是强边界;当minVal < 梯度值 < maxVal跟边界有连接的部分则保留,否则废弃;梯度值< minVal则废弃。另外需要注意的是高阈值与低阈值的比例最好是2:1到3:1之间。
下面我们来看看Canny的函数定义:
CV_EXPORTS_W void Canny( InputArray image, OutputArray edges,
double threshold1, double threshold2,
int apertureSize = 3, bool L2gradient = false );
第一个参数:image输入的图像,这个图像一定要单通道灰度图
第二个参数:edges输出的边缘图像,这个图像也必须是单通道黑白图
第三个参数:threshold1第一个滞后性阈值,低阈值,小于低阈值则认为是弱边缘,就是需要抛弃的边缘。
第四个参数:threshold2第二个滞后性阈值,高阈值,大于高阈值被认为强边缘,需要保留的边缘
第五个参数:apertureSize指的是Sobel算子大小,这个值默认为3,代表的是3*3的矩阵大小。
第六个参数:L2gradient是计算图像梯度幅度值的情况,这个值默认为False;若选择True,则使用更精确的L2范数进行计算
1.8利用opencv查找图形轮廓并画框
imread读取图片,利用cvtcolor转换为单通道图像,canny对灰度图进行边缘检测,findcontours查找灰度图的轮廓,循环轮廓数量然后利用drawcontours画框
Opencv_findContours_Area_Demo文件夹放到share,在linux里编程
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Mat img = imread("shape.png"); //读取shape图片
Mat imgGray;
cvtColor(img, imgGray, COLOR_RGB2GRAY); //把彩色图像转换成GRAY灰度图
Mat imgCanny;
Canny(imgGray, imgCanny, 25 ,75); //Canny对图像进行边缘检测,弱阈值25,强阈值75
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(imgCanny, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_NONE); //查询轮廓,MODE是外部轮廓检测RETR_EXTERNAL,method是CHAIN_APPROX_NONE
Mat drawing = Mat::zeros(imgCanny.size(), CV_8UC3);
for (int i = 0; i < contours.size(); i++)
{
Scalar color = Scalar(255,255,0);
drawContours(drawing, contours, i, color,1,8,hierarchy ); //对图像轮廓进行画框
}
imwrite("contour.jpg", drawing);
return 0;
}编译完,拿出去,放板子。shape.png也放板子,改权限,执行。


1.9OPENCV图形计算面积、弧长API讲解
- OPENCV图形面积、弧长计算的API介绍
前两节课我们已经把图形轮廓的检测、画框等功能讲解了一遍。那今天这节课我们主要结合轮廓检测的API去计算图形的面积,这些面积可以是矩形、圆形等等。图形面积计算和弧长计算常用于车辆识别、桥梁识别等重要功能,常用的API如contourArea、arcLength、minAreaRect、boundingRect、rectangle、line等等。
1.1 contourArea的API讲解

contourArea主要的用途是计算轮廓的曲线面积,也就是去计算图像本身的面积,如上图。countArea就是计算白色区域的面积,计算的过程一般是用微积分等方式去计算。
CV_EXPORTS_W double contourArea( InputArray contour, bool oriented = false );
第一个参数:contour指的是每一个轮廓的数据,也称之为轮廓的点
第二个参数:oriented表示的是某一个方向上轮廓的面积值
返回值:计算后的轮廓面积
1.2. arcLength的API讲解
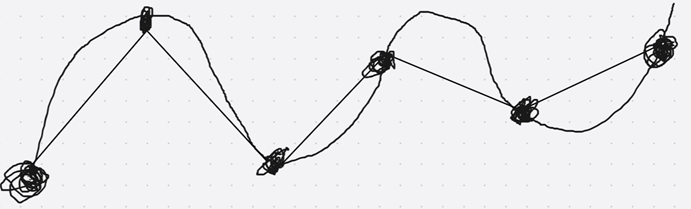
arcLength主要的用途是计算轮廓的周长,也就是图形形状本身的曲线弧度周长。如上图所述,arcLength计算的是每个点连接的长度,并计算出来。
CV_EXPORTS_W double arcLength( InputArray curve, bool closed );
第一个参数:curve轮廓曲线的2D像素点
第二个参数:closed轮廓或者曲线是否闭合标志,true表示闭合
返回值:计算后的轮廓周长
1.3. minAreaRect的API讲解
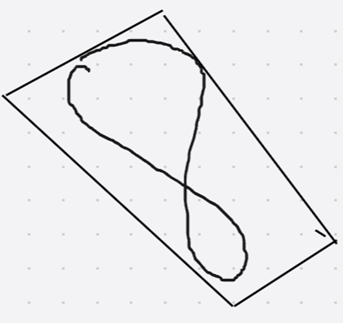
minAreaRect主要的用途是计算最小的外接矩形,最小外接矩形指的是找到一个矩形能够完全包裹所有的给定点,并且这个矩形是最小的。如上图:从上图我们可以看到8这个形状,被minAreaRect的矩形包围了。这个矩形包含了整个形状的所有点,更重要的这个矩形具有旋转功能,这个8实际上有倾斜的角度,而这个最小矩形也能够完美包含进来。
CV_EXPORTS_W RotatedRect minAreaRect( InputArray points );
第一个参数:points输入的二维点数,可以Mat类型也可以是std::vector的向量类型
返回值:RotatedRect的矩形对象, 它表示的是一个轮廓的最小外接矩形,我们来看看RotatedRect结构体成员变量
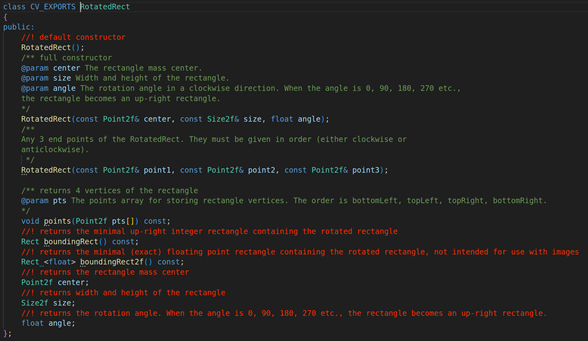
center:旋转矩形的质心
size:旋转矩形的宽度和高度
angle:顺时针的旋转角度。
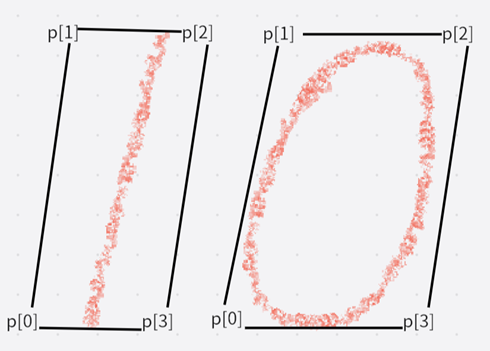
RotatedRect矩形四个点的确定
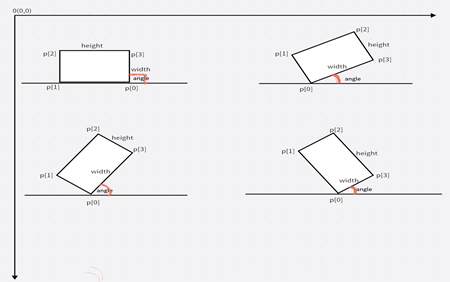
在RotatedRect中矩形四个点通常用Point2f来表示,其中p[0]点的确定是最关键的,p[0]的位置通常分为两种情况:
- 如果当前最小外接矩形没有与坐标轴平行,则Y坐标最大的为点p[0],如2,3,4三张图
- 如果当前最小矩形和坐标轴平行,则有两个Y坐标最大的点,如图1。
1.4. boundingRect的API讲解

boundingRect主要的用途是计算图形轮廓垂直边界的最小矩形,这个矩形必须要和图像是上下边界平行的。我们看上图:我们还是看8这个形状依然还是之前的位置,然后boundingRect产生的矩形对整个8进行垂直边界包围。
CV_EXPORTS_W Rect boundingRect( InputArray array );
第一个参数:array输入的灰度图像或者2D点集,数据类型为vector或者Mat矩阵数据
返回值:Rect的矩形对象,它表示的是物体轮廓的最大外接矩形。我们来看看Rect主要的成员变量
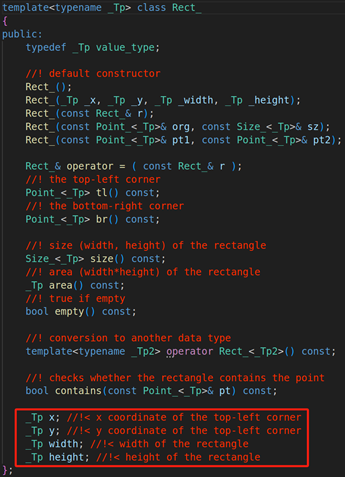
x:矩形的x坐标轴
y: 矩形的y坐标轴
width:矩形的宽度
height:矩形的高度
1.5. rectangle的API讲解
rectangle函数的作用是绘制矩形,它有两种表示形式
1.5.1. 以两个顶点的方式画矩形
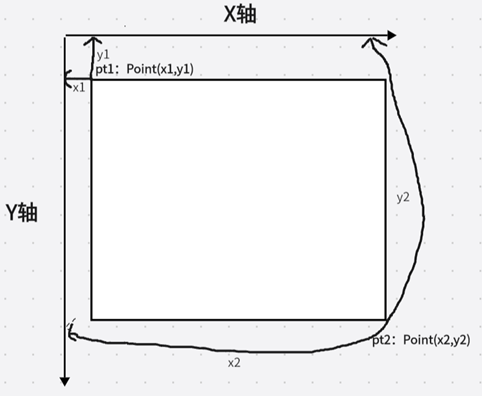
void cv::rectangle(InputOutputArray img, Point pt1, Point pt2, const Scalar & color, int thickness = 1,
int lineType = LINE_8, int shift = 0)
第一个参数:输入的矩阵图像数据
第二个参数:pt1是矩形的一个顶点,左上角的顶点
第三个参数:pt2矩形中与pt1相对的顶点,也就是两个点在对角线上,也就是右下角的顶点
第四个参数:Scalar颜色的标量
第五个参数:thickness线宽
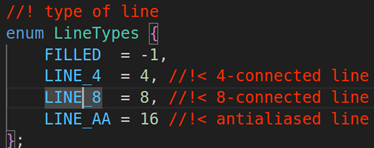
第六个参数:lineType线的类型,默认是LINE_8就行,具体的类型如下图:
第七个参数:shift坐标的小数点位,默认为0就可以
1.5.2.以Rect的方式画矩形
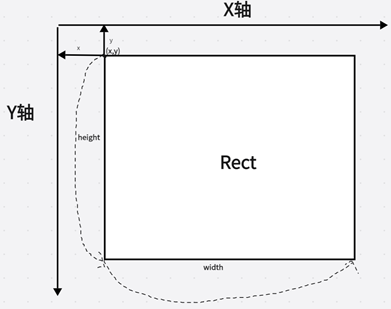
void cv::rectangle(InputOutputArray img, Rect rec, const Scalar & color, int thickness = 1,
int lineType = LINE_8, int shift = 0)
第一个参数:输入的矩阵图像数据
第二个参数:Rect的结构体,我们来看看这个Rect的重要成员变量
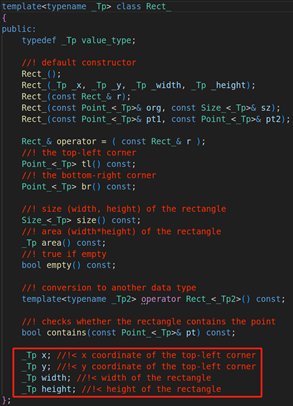
x:矩形的x坐标轴
y: 矩形的y坐标轴
width:矩形的宽度
height:矩形的高度
第三个参数:Scalar颜色的标量
第四个参数:thickness线宽,默认是1
第五个参数:lineType线的类型,默认是LINE_8就行,line的类型如下:
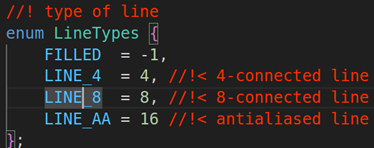
第六个参数:shift坐标点的小数点位数
1.6. line的API讲解
line函数的主要作用是通过两个点绘制直线
CV_EXPORTS_W void line(InputOutputArray img, Point pt1, Point pt2, const Scalar& color,
int thickness = 1, int lineType = LINE_8, int shift = 0);
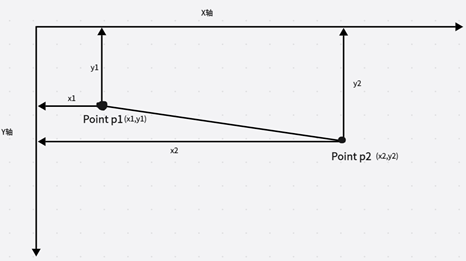
第一个参数:输入的矩阵图像数据
第二个参数:pt1是线的起始坐标,也就是图上x1坐标和y1坐标
第三个参数:pt2是线的终点坐标,也就是图上x2坐标和y2坐标
第四个参数:Scalar是颜色标量,绘制直线的颜色
第五个参数:thickness它是线的粗细程度,默认为1
第六个参数:lineType线的类型,默认是LINE_8就行,具体的类型
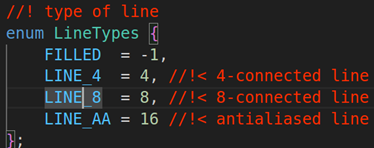
第七个参数:shift坐标点的小数点位数
1.7. threshold的API讲解
threshold主要用途是把图像进行二值化处理,二值化操作可以使图像中的数据量大大降低图像的复杂度,并且能够凸显出图像中的轮廓。
CV_EXPORTS_W double threshold( InputArray src, OutputArray dst, double thresh, double maxval, int type );
第一个参数:src源图像,可以是8位灰度图,也可以是32位的三通道图像
第二个参数:dst目标图像
第三个参数:thresh阈值
第四个参数:maxval二值图像中灰度最大值,maxval只能在THRESH_BINARY和THRESH_BINARY_INV有用,但是其他选项也需要填这个值,不能空着。
第五个参数:type阈值操作类型,具体的阈值操作如下图:
THRESH_BINARY:二值化阈值处理会将原始图像作为仅有的两个值图像,它针对的像素的处理方式是对于灰度值大于阈值thresh的像素点,将其灰度值设定为maxval最大值。而对于灰度值小于或等于阈值thresh的像素点,将其灰度值设定为0。

THRESH_BINARY_INV:反二值化阈值处理也会将原始图像作为仅有的两个值图像,但是它处理的方式和THRESH_BINARY不一样,
它的特点是:对于灰度值大于阈值的像素点,将其设置为0。而对于灰度值小于或者等于阈值的像素点,将这部分的部分设置为maxval最大像素点。

THRESH_TRUNC:截断阈值化处理会把图像中大于阈值的像素点设定为阈值,小于或者等于该阈值的像素点保持不变。比方说阈值设置成127,则说明对于像素超过127的像素点,而其像素值就被设置成127。而小于或者等于127的像素点,其数值保持不变。

THRESH_TOZERO_INV:超阈值处理会对图像中大于阈值的像素点处理为0,小于或者等于该阈值的像素点保持不变。比方说阈值的值设定为127,若当前像素点大于127则把像素点处理为0;若当前像素点小于或者等于阈值的像素点,那么该像素点保持不变

THRESH_TOZERO:低阈值处理会对图像中小于或者等于阈值的像素点处理为0,大于阈值的像素点则保持不变。比方说当前阈值设定为127,若当前像素点小于或者等于127则把像素点处理为0;若当前像素点大于127则保持像素点不变。

THRESH_OTSU:OTSU方法会遍历所有可能的阈值,从而找到一个最佳的阈值。值得注意的是,在使用OTSU方法的时候需要把阈值设定为0。这个时候,threshold会自动寻找最优的值。

1.10代码实战,利用OPENCV的API计算轮廓面积
- 计算常见的图形形状的面积DEMO
本章节主要的讲解如何通过OPENCV计算图形的面积,常见的面积包括矩形,三角形,圆形等等。那本次的代码例程,我们会结合之前学习的OPENCV轮廓检测和上一节课的面积API,来计算一个矩形的各种面积(包括轮廓面积、最小外接矩形面积、垂直边界面积)。
- 计算矩形面积的大体流程
计算矩形的面积,我们一般要分以下几个比较重要的步骤,分别是:读取图片、把图形进行灰度处理、对灰度图像进行二值处理、调用findContours去查找二值图片形状的轮廓、循环轮廓数量并且调用contourArea计算每个轮廓的曲线面积、然后再计算最小外接矩形面积(minAreaRect)、边界垂直矩形面积的计算(boundingRect)。如下图所示:

- 代码的实现DEMO
看完上面大体的流程后,我们来看下具体代码的截图
3.1. 调用OPENCV读取需要计算的图片

第一步,调用imread读取我们需要处理的图片,这里我们选择的图片是10这个图片。
3.2. 对图片进行灰度操作

读取完图片之后,使用cvtColor把三通道的彩色图像转换成单通道(COLOR_RGB2GRAY)的灰度图。
3.3. 对灰度图进行二值操作

灰度完成后,我们需要通过OPENCV的API threshold对图像进行二值操作,这样就可以得到更加精确的图像便于识别和计算。这里的阈值我们填写150,最大的阈值填写的是255,阈值处理类型填的是THRESH_BINARY_INV(背景为黑色,数字为白色,这样更利于我们计算数字的面积)。当像素值超过150之后像素全部为0,否则像素值是maxVal也就是255.

3.4. 查找二值图像中的所有轮廓

调用findContours去查找整个二值图像的轮廓,由于我们读取的图片没有嵌套的轮廓,所以我们选择RETR_EXTERNAL的模式只查找外部轮廓,轮廓的近似方法是CV_CHAIN_APPROX_NONE来保存边界上所有连续的轮廓点。
3.5. 循环轮廓数量来计算图像轮廓的最小外接矩形的面积
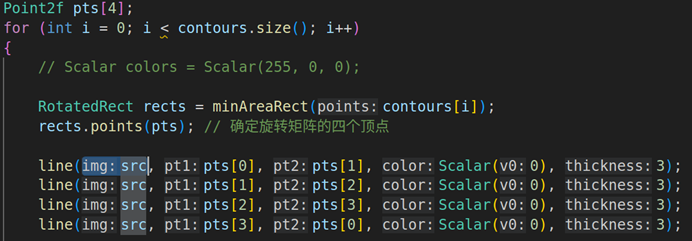
这部分代码就是通过循环轮廓数量来计算最小外接矩形,需要调用minAreaRect来查找查找出整个二值图像的最小矩形,并且用line函数画矩形(如下图1),从图1可以看到四个顶点(顶点用Point2f表示)p[0]、p[1]、p[2]、p[3]都分别以p[0]->p[1]、p[1]->p[2]、p[2]->p[3]、p[3]->p[0]的顺序连接起来变成矩形 。最小矩形面积的计算 = 最小外接矩形的长度 * 最小外接矩形的高度,代码就是int minRectArea= rects.size.width * rects.size.height。
(图1)
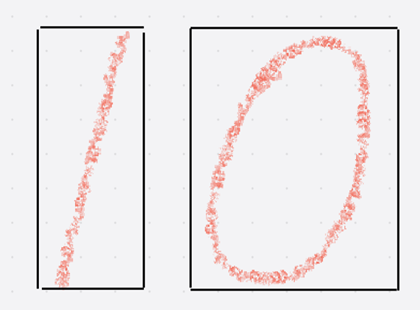
3.6. 循环轮廓数量来计算图像轮廓的最小垂直矩形面积
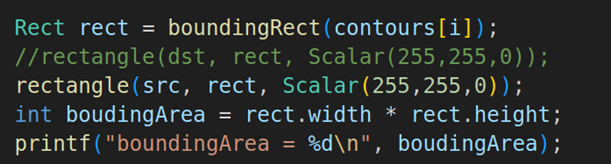
这部分代码就是通过循环轮廓数量来计算最小垂直矩形,需要调用boundingRect来查找查找出整个二值图像的最小垂直矩形,并且用rectangle把矩形框出来。最小垂直矩形面积的计算 = 最小垂直矩形的长度 * 最小垂直矩形的高度,代码就是int boundingArea= rect.width * rect.height。
3.7. 循环轮廓数量来计算图像轮廓的面积

这部分代码就是通过循环轮廓数量来计算轮廓的面积,通过contourArea来计算轮廓的面积。
输出的结果:

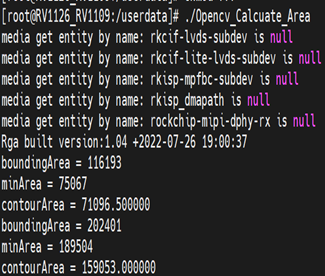
输出的结果有两个,第一个是10这个数字用最小外接矩形、最小垂直矩形并输出area.jpg,如左图。右图是输出边界垂直矩形面积(boundingArea)、最小外接矩形面积(minArea)、轮廓面积(contourArea)等信息。
Opencv_findContours_Area_Demo文件夹弄到linux里,打开编程
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Mat src = imread("ten.png");//读取ten这张图片
Mat gray, bin_img;
cvtColor(src, gray, COLOR_RGB2GRAY);//读取ten这张图片
threshold(gray, bin_img, 150, 255, THRESH_BINARY_INV);//二值化处理阈值150,最大值255,THRESH_BINARY_INV
vector<vector<Point>> contours;
findContours(bin_img, contours, RETR_EXTERNAL, CHAIN_APPROX_NONE);//查询轮廓
Point2f pts[4];
for (int i = 0; i < contours.size(); i++)
{
RotatedRect minRect = minAreaRect(contours[i]);//通过minAreaRect找到最小外接矩形
minRect.points(pts);
line(src, pts[0],pts[1],Scalar(0),3);//用line连接p[0]->p[1]
line(src, pts[1],pts[2],Scalar(0),3);//用line连接[p1]->p[2]
line(src, pts[2],pts[3],Scalar(0),3);//用line连接p[2]->p[3]
line(src, pts[3],pts[0],Scalar(0),3);//用line连接p[3]->p[0]
int minArea = minRect.size.width * minRect.size.height;
printf("minArea = %d\n", minArea);
Rect bArea = boundingRect(contours[i]);//调用boundingRect查找边界矩形
int boundingArea = bArea.width * bArea.height;//计算边界矩形面积
rectangle(src, bArea, Scalar(255,255,0));//rectangle矩形画框
printf("boundingArea = %d\n", boundingArea);
double cArea = contourArea(contours[i]);//计算轮廓面积
printf("contourArea = %lf\n", cArea);
}
imwrite("area.jpg", src);
return 0;
}
编译,导出到板子。图片ten.png也放入板子。该权限,运行


1.11OPENCV形态学基础之一膨胀
- 膨胀的原理:
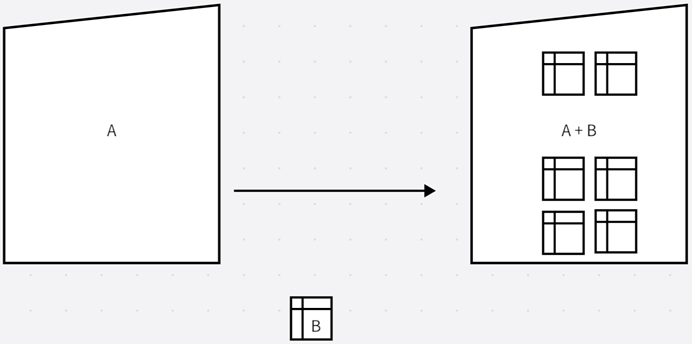
数学表达式:dst(x,y) = dilate(src(x,y)) = max(x,y)src(x+x,y+y)
膨胀是图像形态学的基本功能之一,膨胀顾名思义就是求图像的局部最大值操作,它的数学表达式是dst(x,y) = dilate(src(x,y)) = max(x,y)src(x+x,y+y)。若从数学的角度来看,无论是膨胀还是腐蚀实际上就是把图像跟核进行卷积(卷积:是通过两个函数f和g生成第三个函数的一种数学运算,它的本质就是微积分的转换,积分转换的数学公式(f * g)(t) =∫f(τ)g(t -τ)dτ ),如上图1:图像A和形状B进行卷积操作,然后形成右边的图像,右边的图像就是A+B的图像点。所谓的核就是指任意的形状或者大小,在多数情况下,核是一个小的中间带的正方形或者圆形。膨胀本质上就是把图像与核进行卷积操作,然后计算出卷积区域的最大点,并把最大的值赋值给指定的像素(如上图1)。操作完成之后,图像就会更加明亮(如下图2)。


(图2)
图2就是膨胀前和膨胀后图像的对比。从这张图我们可以看出来,右边经过dilate膨胀操作后整个图像更加的明亮和粗糙。
- 膨胀的API讲解:
2.1.dilate的API
在OPENCV中,有一个专门的API去处理图像的膨胀,这个API就是dilate
void dilate( InputArray src, OutputArray dst, InputArray kernel, Point anchor, int iterations, int borderType, const Scalar& borderValue )
第一个参数:src的类型是InputArray,它指的是输入图像,它可以是Mat类的数据。图像的通道数可以是任意数,但是图像的深度一般是CV_8U,CV_16U,CV_16S,CV_32F,CV_64F
第二个参数:dst的类型是OutputArray,它指的是目标图像,值得注意的是输出图像的尺寸、类型要和输入图像是一致的。
第三个参数:InputArray类型的kernel,膨胀操作的核。当这个值为NULL的时候,表示使用的核参考点默认是3*3。这个参数通常会配合getStructingElement参数的使用(这个参数的使用,下面我会详细说到)。
第四个参数:Point类型的anchor,描点的位置,默认是(-1,-1),表示中心位置。
第五个参数:int类型的迭代次数,默认是1
第六个参数:int类型的borderType,这个类型用于推断图像外部的边界模式,用的最多的是BORDER_DEFAULT
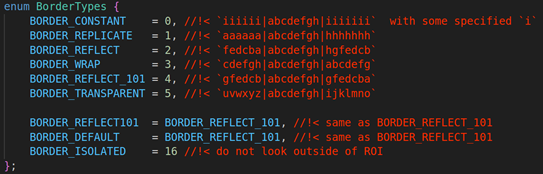
下面是常用的几种边框模式(这几种相对比较常用,其他的用的很少)
BORDER_CONSTANT:用指定的像素填充边框
BORDER_REPLICATE:用已知的边缘像素来填充边框
BORDER_WRAP:用另一边的像素来补偿填充
BORDER_DEFAULT:默认模式画边框
BORDER_TRANSPANT: 用透明的方式画框
第七个参数:const Scalar类型的borderType,一般不用填写,因为这个API已经有了默认值morphologyDefaultBorderValue()
2.2. getStructingElement的API
该函数的作用是返回一个卷积层
CV_EXPORTS_W Mat getStructuringElement(int shape, Size ksize, Point anchor = Point(-1,-1));
第一个参数:表示内核的形状,这里包括了:矩形(MORPH_RECT)、交叉形(MORPH_CROSS)、椭圆形(MORPH_ELLIPSE),常用的内核形状是矩形
第二个参数:内核的尺寸
第三个参数:锚点的位置,默认值Point(-1,-1),表示的是位于中心点
- 用OPENCV代码实现图像膨胀功能:
3.1. 用OPENCV实现膨胀功能的大体流程图
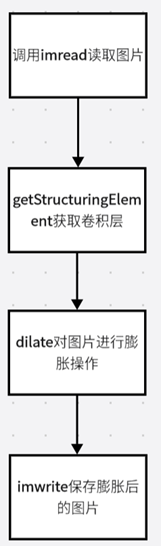
从上面的流程图我们可以看出来OPENCV实现膨胀功能需要有以下几步,分别是:imread读取图片、使用cvtColor对图片进行灰度操作、使用getStructingElement获取卷积层、使用dilate对图片进行膨胀、imwrite保存图片
3.2.代码的截图
3.2.1. 读取我们需要处理的图片
使用imread读取我们需要处理的图片
3.2.2. 获取卷积层
![]()
使用getStructuringElement获取卷积层,参数设置内核的形状是MORPH_RECT、内核的长度是Size(15,15)
3.2.3. dilate对图片进行膨胀操作![]()
获取完卷积层后,我们就对图片进行dilate膨胀,关于dilate的API上面已经详细说到了。最后用imwrite保存图片(这里就省略)
经过上述处理过后,我们来看看原图和处理后的图片效果:


左边是原图,右边是经过膨胀后的图片。我们可以看到右边经过膨胀的图片明显更加明亮和粗糙,这是因为dilate就是把原图和卷积层进行重叠,整个图像的像素都会变大。
Opencv_dlite_erode_Demo文件放到linux编程
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
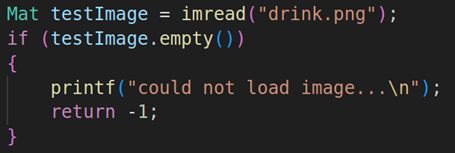
Mat testImage = imread("drink.png");
if(testImage.empty())
{
printf("could not load image.....\n");
return -1;
}
Mat vertical_structure = getStructuringElement(MORPH_RECT, Size(15,15));
erode(testImage, testImage, vertical_structure);
imwrite("erode_process.jpg", testImage);
return 0;
}
编译完导出到板子


1.12OPENCV形态学基础之二腐蚀
- 腐蚀的原理
(图1)
数学表达式:dst(x,y) = erode(src(x,y)) = min(x,y)src(x+x,y+y)
腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀的原理就是指定一个卷积内核,然后原图像和卷积内核进行局部最小值的计算,最终获取到一个局部像素点最小的图像,如上图1,数学表达式是dst(x,y) = erode(src(x,y)) = min(x,y)src(x+x,y+y)。经过erode处理后,我们来看看两个图片的区别,看下图2


(图2)
左边是原图,右边是经过腐蚀过后的图像。我们可以明显看出来,右边的图像字母部分明显比左边的原图像更加细小,但是黑暗背景部分会更加大。
- 腐蚀的API讲解
2.1. erode的函数定义
erode是OPENCV实现腐蚀效果的API
CV_EXPORTS_W void erode( InputArray src, OutputArray dst, InputArray kernel, Point anchor = Point(-1,-1), int iterations = 1, int borderType = BORDER_CONSTANT, const Scalar& borderValue = morphologyDefaultBorderValue() );
第一个参数:src的类型是InputArray,它指的是输入图像,它可以是Mat类的数据。图像的通道数可以是任意数,但是图像的深度一般是CV_8U,CV_16U,CV_16S,CV_32F,CV_64F
第二个参数:dst的类型是OutputArray,它指的是目标图像,值得注意的是输出图像的尺寸、类型要和输入图像是一致的。
第三个参数:InputArray类型的kernel,膨胀操作的核。当这个值为NULL的时候,表示使用的核参考点默认是3*3。这个参数通常会配合getStructingElement参数的使用(这个参数的使用,下面我会详细说到)。
第四个参数:Point类型的anchor,描点的位置,默认是(-1,-1),表示中心位置。
第五个参数:int类型的迭代次数,默认是1
第六个参数:int类型的borderType,这个类型用于推断图像外部的边界模式,它的默认值是BORDER_DEFAULT
第七个参数:const Scalar类型的borderType,一般不用填写,因为这个API已经有了默认值morphologyDefaultBorderValue()
2.2. getStructingElement的函数定义
getStructingElement的作用是返回一个卷积层
CV_EXPORTS_W Mat getStructuringElement(int shape, Size ksize, Point anchor = Point(-1,-1));
第一个参数:表示内核的形状,这里包括了:矩形(MORPH_RECT)、交叉形(MORPH_CROSS)、椭圆形(MORPH_ELLIPSE)
第二个参数:内核的尺寸
第三个参数:锚点的位置,默认值Point(-1,-1),表示的是位于中心点
三.OPENCV代码实现图像腐蚀功能:
3.1. 用OPENCV实现腐蚀功能的大体流程图
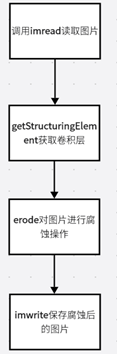
从上面的流程图我们可以看出来OPENCV实现膨胀功能需要有以下几步,分别是:imread读取图片、使用getStructingElement获取卷积层、使用erode对图片进行腐蚀、imwrite保存腐蚀后的图片
3.2. 用OPENCV实现腐蚀功能的代码截图
3.2.1. 读取我们需要处理的图片

使用imread读取我们需要处理的图片
3.2.2. 获取卷积层
![]()
使用getStructuringElement获取卷积层,参数设置内核的形状是MORPH_RECT、内核的长度是Size(15,15)
3.2.3. erode对图片进行腐蚀操作
![]()
获取完卷积层后,我们就对图片进行erode腐蚀,关于erode的API上面已经详细说到了,最后调用imwrite保存图片(这里就省略不写出来)。
经过上面处理后,我们来看看处理后的图片


左边是原图,右边是经过腐蚀后的图片。我们可以看到右边经过腐蚀的图片饮料部分图片变小了,而整个背景则加深了。
Opencv_dlite_erode_Demo文件放到linux编程,
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
Mat testImage = imread("drink.png");
if(testImage.empty())
{
printf("read testImage failed....\n");
}
Mat vertical_structure = getStructuringElement(MORPH_RECT, Size(15,15));
dilate(testImage, testImage, vertical_structure);
imwrite("dilate_process.jpg", testImage);
return 0;
}编译完,放到板子,改权限执行。


1.13OPENCV的cvtColor和putText的讲解
- cvtColor的用处和API讲解
-
- cvtColor的作用
cvtColor是OPENCV里面颜色转换的转换函数,它的功能非常强大。能够实现RGB图像转换成灰度图、灰度图转换成RGB图像、RGB转换成HSV等等。下面我们来看看
-
- cvtColor的API
CV_EXPORTS_W void cvtColor( InputArray src, OutputArray dst, int code, int dstCn = 0 );
第一个参数:输入的图像数据
第二个参数:输出的图像数据
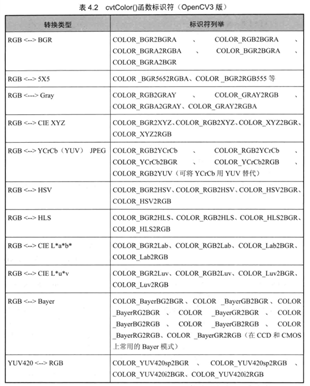
第三个参数:颜色转换的标识符,下面是转换的图表。图像转化可以分为11个大类,分别是RGB->BGR、RGB->5X5、 RGB->GRAY、RGB->CIEXYZ、RGB->YyCrcb(YUV)、RGB->HSV、RGB->HLS、RGB->CIELab、RGB->CIELuv、RGB->Bayer、YUV420->RGB。
第四个参数:目标图像通道数,默认为0
用代码实现cvtColor的颜色转换功能
这次代码主要是转换几个常见的格式,如RGB->YUV, YUV->RGB。具体的代码思路如下:
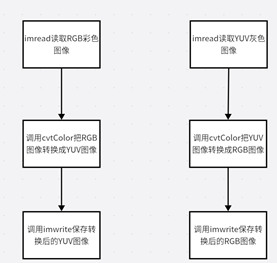
这个代码里面我们分别读取两种图片,一种是RGB图片、另外一种是YUV灰度图像、分别用cvtColor把RGB图像转换成YUV图像、把YUV灰度图像转换成RGB图像、最后用imwrite保存两种图片。下面是一些代码的实现截图:调用imread读取RGB彩色图像
读取RGB彩色通道的图像,这张图片是一张车辆的图片
把RGB图像转换为YUV图像

调用cvtColor把三通道的RGB图像转换为YUV的灰度图像,这里使用的是COLOR_RGB2YUV。
调用imread读取YUV灰度图像
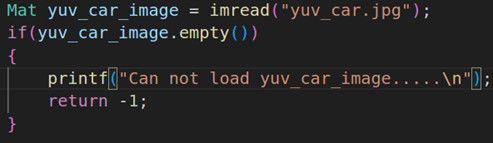
读取YUV的灰度图像,这张图片是一张灰度的汽车图像
把YUV图像转换为RGB图像
![]()
调用cvtColor把单通道的图像转换成RGB图像,调用的选项使用的是COLOR_YUV2RGB
把处理过后的两种图像保存
使用imwrite保存两种图像
imwrite("yuv_process_car_image.jpg",yuv_process_car_image);
imwrite("rgb_process_car_image.jpg",rgb_process_car_image);
最终的效果:

左边是处理后的YUV图像,右边是RGB图像
putText的用处和API讲解
putText的用法和作用
putText是OPENCV中常见的功能,他主要的功能是在Mat矩阵里面显示显示文字,像下图
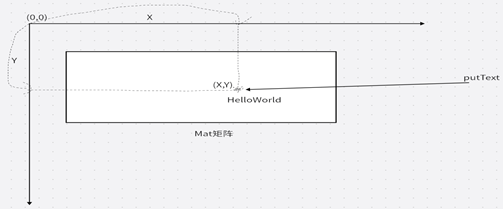
从上图可以看出来putText是通过坐标(X,Y)在矩阵显示文字
putText的API
CV_EXPORTS_W void putText( InputOutputArray img, const String& text, Point org,
int fontFace, double fontScale, Scalar color,
int thickness = 1, int lineType = LINE_8,
bool bottomLeftOrigin = false );
第一个参数:img需要传入的图像数据
第二个参数:text需要显示的文字
第三个参数:org文字在图像数据中的坐标位置
第四个参数:fontFace字体类型,常用的字体类型如下:FONT_HERSHEY_SIMPLEX, FONT_HERSHEY_PLAIN, FONT_HERSHEY_DUPLEX,FONT_HERSHEY_COMPLEX,FONT_HERSHEY_TRIPLEX,FONT_HERSHEY_COMPLEX_SMALL,FONT_HERSHEY_SCRIPT_SIMPLEX, orFONT_HERSHEY_SCRIPT_COMPLEX,以上所有类型都可以配合 FONT_HERSHEY_ITALIC使用,产生斜体效果
第五个参数:fontScale字体的大小
第六个参数:color是颜色标量,字体的显示颜色
第七个参数:thickness是字体的粗细程度,默认为1
第八个参数:lineType线性,默认是LINE_8,具体的几个如下:
第九个参数:bottomLeftOrigin图像数据原点在左下角, Otherwise(默认false)图像数据中原点的左上角。默认bottomLeftOrigin = false
2.3. 用代码实现putText的功能
本章节代码主要是实现单张图片显示文字
2.3.1.读取车辆图片
使用imread读取需要处理的图片
2.3.2.调用putText的API进行文字显示

上面是代码是利用putText对Mat矩阵进行文字显示,显示的字符是HelloWorld,这里的位置我们选择是Point(0,400)这个位置,字体选择FONT_HERSHEY_PLAIN,字体大小是4.0,颜色为红色(Scalar(0,0,255)), 绘制线的粗细程度是4,然后线的类型是LINE_8.
2.3.3.最后用imwrite来保存图片,最终的显示效果是

Opencv_putText_demo在linux打开编程
#include <opencv2/core.hpp>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main()
{
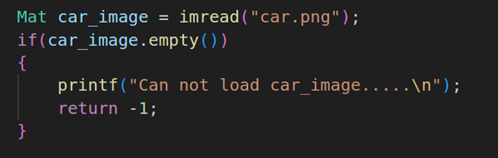
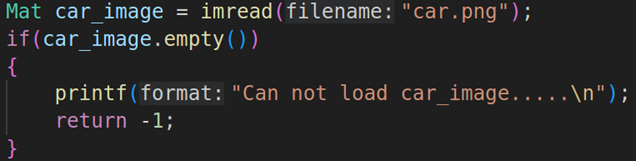
Mat car_image = imread("car.png");
if(car_image.empty())
{
printf("Can not load car_image.....\n");
return -1;
}
string str = "HelloWorld";//
Point bg;
bg.x = 0;//坐标的x轴是0
bg.y = 400;//坐标的y轴是400
int fontFace = cv::FONT_HERSHEY_PLAIN;//PLAIN的格式
double fontScale = 4.0;
int thickness = 4;
//thickness粗细程度是4
putText(car_image,str,bg,fontFace,fontScale, Scalar(0,0,255),thickness, LINE_8);
imwrite("putText.jpg", car_image);
return 0;
}编译完放到板子,该权限,执行


1.14RV1126+OPENCV在视频中添加LOGO图像
- RV1126+OPENCV在视频中添加LOGO图像大体流程图:
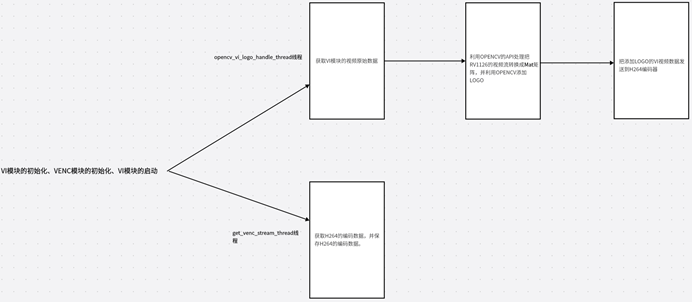
本章节属于实战课程,主要是利用RV1126的视频流结合OPENCV的API在视频流里面添加LOGO图像,换言之就是在RV1126的视频流里面叠加图片。大体流程我们来看上图,要完成这个功能我们需要创建两个线程(实际上还有初始化过程,这里先忽略了),第一个线程是opencv_vi_logo_handle_thread它主要是获取VI原始数据并有OPENCV转换成Mat矩阵然后添加LOGO图像,并把VI数据发送到VENC编码器。
第二个线程是get_venc_stream_thread它主要是获取H264的VENC码流数据,并且保存到H264文件。
- 具体代码实现:
上图我们已经说了大概的流程图,这部分我们重点讲解代码的实现
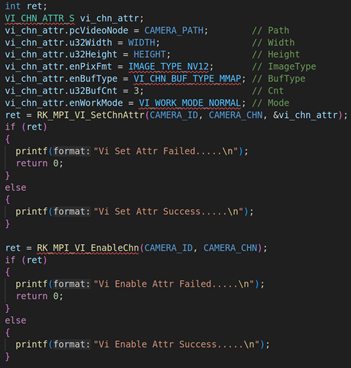
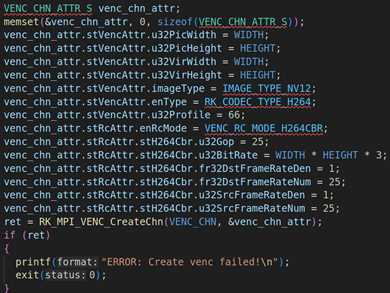
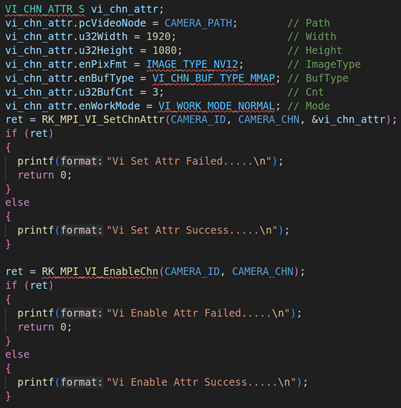
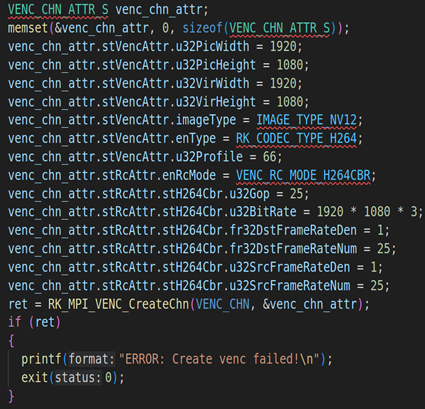
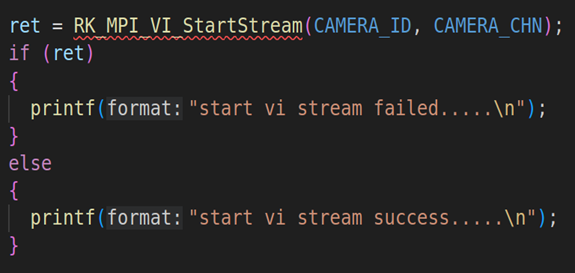
2.1. RV1126模块初始化并启动VI工作
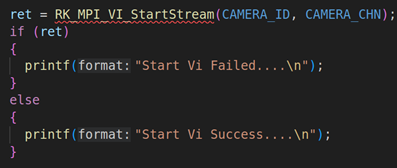
上面代码是RV1126模块的初始化,包括VI模块的初始化(RK_MPI_VI_SetChnAttr)、使能VI模块(RK_MPI_VI_EnableChn)、VENC模块的初始化(RK_MPI_VENC_CreateChn)、启动VI工作(RK_MPI_VI_StartStream)。关于这方面的参数设置,我们就不详细说了,因为这方面的内容之前的课程已经详细说过。
2.2. opencv_vi_handle_thread线程的讲解
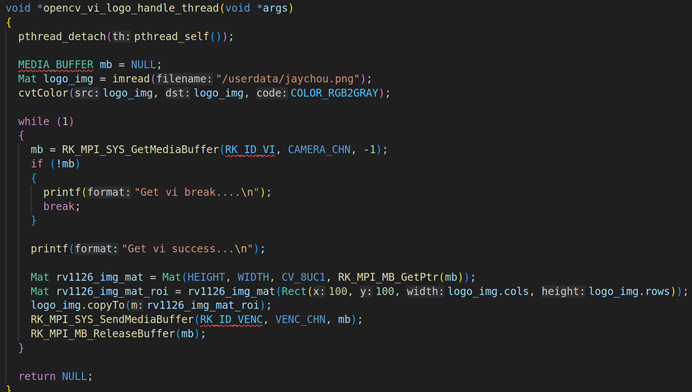
上面是opencv_vi_logo_handle_thread的具体实现。首先我们要通过imread读取图片,然后把图片cvtColor转换成灰度图片(由于VI模块的图像格式是NV12,所以我们的图片必须要以灰度图的方式进行添加)。
然后调用RK_MPI_SYS_GetMediaBuffer获取每一帧的VI视频原始数据,然后使用OPENCV的API把每一个视频数据转换成Mat矩阵,具体的操作是:Mat rv1126_img_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb)),这是一个Mat构造器,第一个参数是HEIGHT:1080,第二个参数WIDTH:1920,第三个参数:图像格式CV_8UC1,第四个参数:具体的图像数据RK_MPI_MB_GetPtr(mb)。通过Mat的构造器,就可以把RV1126的VI视频数据转换成Mat,转换成Mat之后,我们就需要对Mat进行图层叠加操作。
Mat叠加操作,需要分两步,第一步:先创建一个感兴趣区域,Mat rv1126_img_mat_roi = rv1126_img_mat(Rect(100, 100, logo_img.cols, logo_img.rows)),这里的感兴趣区域以矩形为背景Rect(100,100,logo_img.cols,logo_img.rows),x:100,y: 100,width: logo_img.cols,height:logo_img.rows。第二步:利用copyTo函数把读取的图片拷贝到感兴趣区域rv1126_img_mat_roi , 具体代码是logo_img.copyTo(rv1126_img_mat_roi)。
进行上述所有的操作后,就需要把RV1126叠加过后的视频VI数据发送到H264的VENC编码器,调用的API是RK_MPI_SYS_SendMediaBuffer。
2.3. get_venc_stream_thread线程的讲解
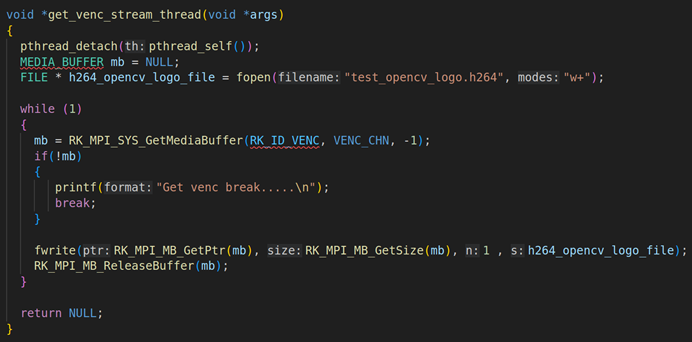
上面是get_venc_stream_thread的具体实现,在这个线程里面要通过RK_MPI_SYS_GetMediaBuffer获取每一帧H264的编码数据,然后用fwrite写入。
2.4. 输出结果:
经过上面的编码后,我们来看看输出的H264文件。可以看到这个H264文件,嵌入了周董的JPG图片。这个效果就实现了用OPENCV图片叠加的功能对RV1126的视频流进行图片LOGO的添加
video_opencv_logo_project文件夹弄到linux,编程
// Copyright 2020 Fuzhou Rockchip Electronics Co., Ltd. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <assert.h>
#include <bits/types/FILE.h>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/imgproc.hpp>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
//opencv的Logo处理VI线程
void *opencv_vi_logo_handle_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
Mat logo_img = imread("/userdata/jaychou.png");//读取LOGO图片编码Mat矩阵
cvtColor(logo_img, logo_img, COLOR_RGB2GRAY); //cvtColor把彩色图像转换成灰度图
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);//获取VI模块的数据
if (!mb)
{
printf("Get vi break....\n");
break;
}
printf("Get vi success...\n");
Mat rv1126_img_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb));//把VI数据转换成Mat矩阵
Mat rv1126_img_mat_roi = rv1126_img_mat(Rect(100, 100, logo_img.cols, logo_img.rows));//在Mat矩阵里面获取感兴趣区域
logo_img.copyTo(rv1126_img_mat_roi);//把Logo的矩阵拷贝到可感兴趣区域
RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);//把处理后的VI数据传输给VENC编码器
RK_MPI_MB_ReleaseBuffer(mb);//释放资源
}
return NULL;
}
void *get_venc_stream_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
FILE * h264_opencv_logo_file = fopen("test_opencv_logo.h264", "w+"); //
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1);//获取VENC编码器数据
if(!mb)
{
printf("Get venc break.....\n");
break;
}
fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1 , h264_opencv_logo_file);//保存数据
RK_MPI_MB_ReleaseBuffer(mb);//释放资源
}
return NULL;
}
int main()
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = WIDTH; // Width
vi_chn_attr.u32Height = HEIGHT; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
VENC_CHN_ATTR_S venc_chn_attr;
memset(&venc_chn_attr, 0, sizeof(VENC_CHN_ATTR_S));
venc_chn_attr.stVencAttr.u32PicWidth = WIDTH;
venc_chn_attr.stVencAttr.u32PicHeight = HEIGHT;
venc_chn_attr.stVencAttr.u32VirWidth = WIDTH;
venc_chn_attr.stVencAttr.u32VirHeight = HEIGHT;
venc_chn_attr.stVencAttr.imageType = IMAGE_TYPE_NV12;
venc_chn_attr.stVencAttr.enType = RK_CODEC_TYPE_H264;
venc_chn_attr.stVencAttr.u32Profile = 66;
venc_chn_attr.stRcAttr.enRcMode = VENC_RC_MODE_H264CBR;
venc_chn_attr.stRcAttr.stH264Cbr.u32Gop = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32BitRate = WIDTH * HEIGHT * 3;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateNum = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateNum = 25;
ret = RK_MPI_VENC_CreateChn(VENC_CHN, &venc_chn_attr);
if (ret)
{
printf("ERROR: Create venc failed!\n");
exit(0);
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("start vi failed....\n");
}
else
{
printf("start vi success....\n");
}
pthread_t pid1, pid2;
pthread_create(&pid1, NULL, opencv_vi_logo_handle_thread, NULL);
pthread_create(&pid2, NULL, get_venc_stream_thread, NULL);
while (1)
{
sleep(2);
}
RK_MPI_VENC_DestroyChn(VENC_CHN);
RK_MPI_VI_DisableChn(CAMERA_ID, CAMERA_CHN);
return 0;
}
编译放到板子运行

1.15RV1126+OPENCV对视频流进行视频膨胀操作
一.RV1126+OPENCV对视频流进行视频膨胀操作的大体流程图
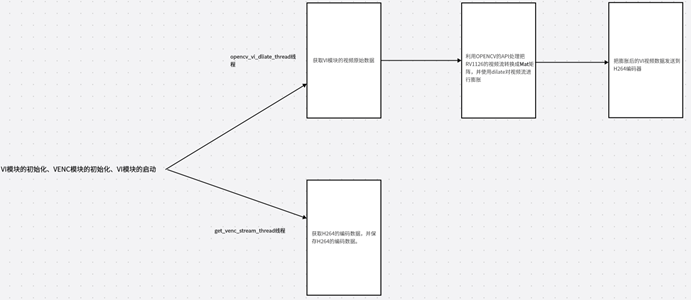
本章节属于实战课程,主要是利用RV1126的视频流结合OPENCV的API对视频流进行膨胀,然后对其进行编码保存。要完成这个功能我们首先要初始化VI、VENC的模块,并且使能,然后需要创建两个线程。第一个线程是opencv_vi_dliate_thread,它的主要功能是获取VI原始数据并用OPENCV转换成Mat矩阵然后用dilate对其VI数据进行膨胀,然后把VI数据发送到VENC编码器
第二个线程是GET_VENC_STREAM_THREAD它主要是获取H264的VENC码流数据,并且保存到H264文件。
二.具体代码实现:
2.1. RV1126模块初始化并启动VI工作
上面代码是RV1126模块的初始化,包括VI模块的初始化(RK_MPI_VI_SetChnAttr)、使能VI模块(RK_MPI_VI_EnableChn)、VENC模块的初始化(RK_MPI_VENC_CreateChn)、启动VI工作(RK_MPI_VI_StartStream)。关于这方面的参数设置,我们就不详细说了,因为这方面的内容之前的课程已经详细说过。
2.2. opencv_dliate_vi_thread线程的讲解
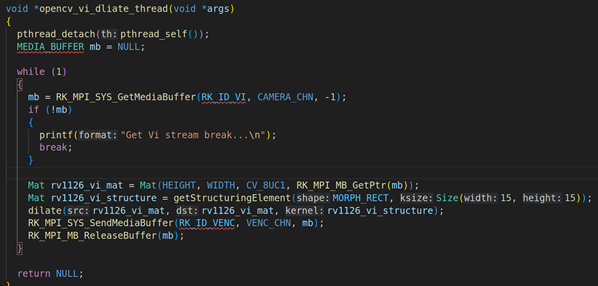
上面是opencv_dliate_vi_thread线程的具体实现,首先我们要通过RK_MPI_SYS_GetMediaBuffer获取每一帧的VI视频原始数据,然后把每一帧的原始数据通过OPENCV转换成Mat矩阵。Mat矩阵的转换用构造器就可以,Mat rv1126_vi_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb)),第一个参数是HEIGHT:1080,第二个参数WIDTH:1920,第三个参数:图像格式CV_8UC1,第四个参数:具体的图像数据RK_MPI_MB_GetPtr(mb)。然后调用dilate的对其Mat矩阵进行膨胀,这里的膨胀参数我们设置成矩形和Size(15,15)(具体的如下:Mat rv1126_vi_structure = getStructuringElement(MORPH_RECT, Size(15, 15));)。
2.3. get_venc_stream_thread线程的讲解

上面是get_venc_stream_thread的具体实现,在这个线程里面要通过RK_MPI_SYS_GetMediaBuffer获取每一帧H264的编码数据,然后用fwrite写入。
经过上面的编码后,我们来看看输出的H264文件。这个视频流更加的明亮,整个视频流的细节都变大了,包括手的部分、窗的部分等等。
video_erode_dilate_project文件弄到linux编程
// Copyright 2020 Fuzhou Rockchip Electronics Co., Ltd. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <assert.h>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/imgproc.hpp>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
void *opencv_vi_dliate_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);//获取VI数据
if (!mb)
{
printf("Get Vi stream break...\n");
break;
}
Mat rv1126_vi_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb)); //把VI数据转换成OPENCV的Mat矩阵
Mat rv1126_vi_structure = getStructuringElement(MORPH_RECT, Size(15, 15));//获取内核,内核的形状是矩形,长度大小是15 * 15
dilate(rv1126_vi_mat, rv1126_vi_mat, rv1126_vi_structure);//对Mat矩阵进行dilate膨胀
RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);//把膨胀后的数据传输到VENC编码器
RK_MPI_MB_ReleaseBuffer(mb);//释放资源
}
return NULL;
}
void *get_venc_stream_thread(void * args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
FILE *opencv_dliate_file = fopen("test_opencv_dliate.h264", "w+");
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1);
if (!mb)
{
printf("Get Venc stream break...\n");
break;
}
printf("Get Dlite_Venc Stream Success...\n");
fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1, opencv_dliate_file);
RK_MPI_MB_ReleaseBuffer(mb);
}
return NULL;
}
int main()
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = 1920; // Width
vi_chn_attr.u32Height = 1080; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
VENC_CHN_ATTR_S venc_chn_attr;
memset(&venc_chn_attr, 0, sizeof(VENC_CHN_ATTR_S));
venc_chn_attr.stVencAttr.u32PicWidth = 1920;
venc_chn_attr.stVencAttr.u32PicHeight = 1080;
venc_chn_attr.stVencAttr.u32VirWidth = 1920;
venc_chn_attr.stVencAttr.u32VirHeight = 1080;
venc_chn_attr.stVencAttr.imageType = IMAGE_TYPE_NV12;
venc_chn_attr.stVencAttr.enType = RK_CODEC_TYPE_H264;
venc_chn_attr.stVencAttr.u32Profile = 66;
venc_chn_attr.stRcAttr.enRcMode = VENC_RC_MODE_H264CBR;
venc_chn_attr.stRcAttr.stH264Cbr.u32Gop = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32BitRate = 1920 * 1080 * 3;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateNum = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateNum = 25;
ret = RK_MPI_VENC_CreateChn(VENC_CHN, &venc_chn_attr);
if (ret)
{
printf("ERROR: Create venc failed!\n");
exit(0);
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("start vi stream failed.....\n");
}
else
{
printf("start vi stream success.....\n");
}
pthread_t pid;
pthread_create(&pid, NULL, opencv_vi_dliate_thread, NULL);//膨胀处理线程
pthread_create(&pid, NULL, get_venc_stream_thread, NULL);//获取VENC线程
while (1)
{
sleep(2);
}
RK_MPI_VENC_DestroyChn(VENC_CHN);
RK_MPI_VI_DisableChn(CAMERA_ID, CAMERA_CHN);
return 0;
}
编译放到板子运行

1.16RV1126+OPENCV对视频流进行视频腐蚀操作
一.RV1126+OPENCV对视频流进行视频腐蚀操作的大体流程图
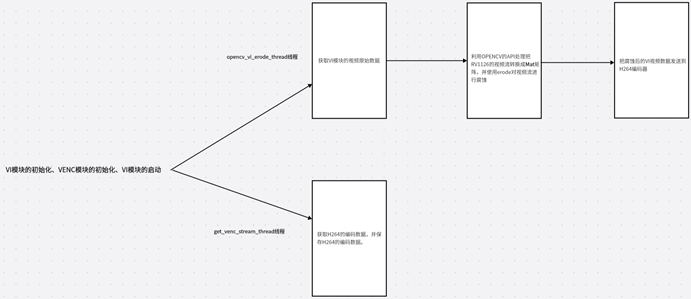
本章节属于实战课程,主要是利用RV1126的视频流结合OPENCV的API对视频流进行腐蚀,然后对其进行编码保存。要完成这个功能我们首先要初始化VI、VENC的模块,并且使能,然后需要创建两个线程。第一个线程是opencv_vi_erode_thread,它的主要功能是获取VI原始数据并用OPENCV转换成Mat矩阵然后用erode对其VI数据进行腐蚀,然后把VI数据发送到VENC编码器。
第二个线程是GET_VENC_STREAM_THREAD它主要是获取H264的VENC码流数据,并且保存到H264文件。
二.具体代码实现:
2.1. RV1126模块初始化并启动VI工作
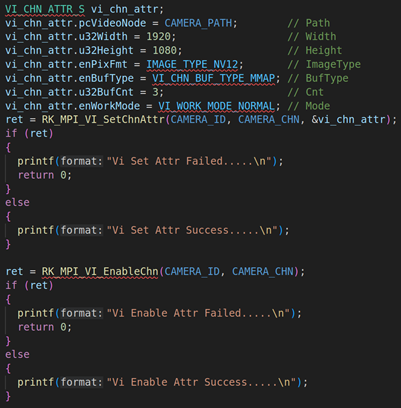
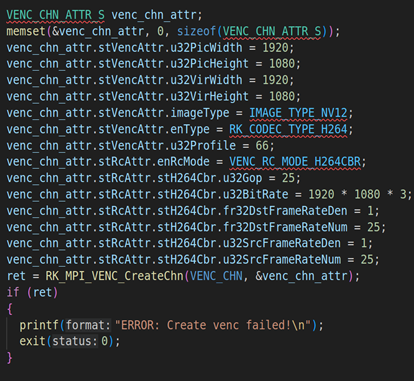
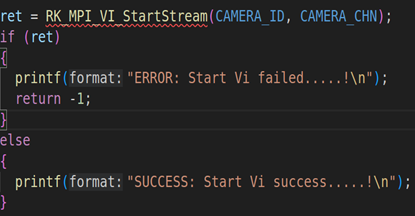
上面代码是RV1126模块的初始化,包括VI模块的初始化(RK_MPI_VI_SetChnAttr)、使能VI模块(RK_MPI_VI_EnableChn)、VENC模块的初始化(RK_MPI_VENC_CreateChn)、启动VI工作(RK_MPI_VI_StartStream)。关于这方面的参数设置,我们就不详细说了,因为这方面的内容之前的课程已经详细说过。
2.2. opencv_erode_vi_thread线程的讲解:
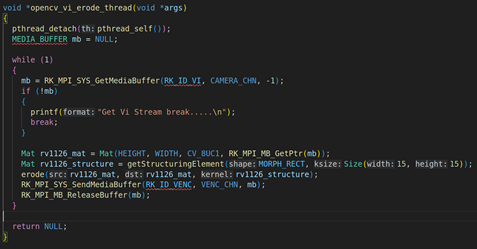
上面是opencv_erode_vi_thread线程的具体实现,首先我们要通过RK_MPI_SYS_GetMediaBuffer获取每一帧的VI视频原始数据,然后把每一帧的原始数据通过OPENCV转换成Mat矩阵。Mat矩阵的转换用构造器就可以,Mat rv1126_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb));,第一个参数是HEIGHT:1080,第二个参数WIDTH:1920,第三个参数:图像格式CV_8UC1,第四个参数:具体的图像数据RK_MPI_MB_GetPtr(mb)。然后调用erode的对其Mat矩阵进行腐蚀,这里的膨胀参数我们设置成矩形和Size(15,15),具体的( Mat rv1126_structure = getStructuringElement(MORPH_RECT, Size(15, 15)))。
2.3. get_venc_stream_thread线程的讲解
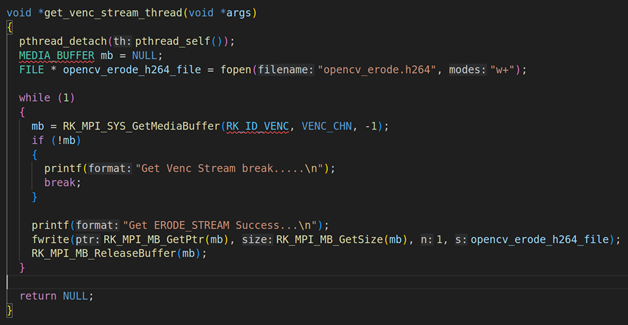
上面是get_venc_stream_thread的具体实现,在这个线程里面要通过RK_MPI_SYS_GetMediaBuffer获取每一帧H264的编码数据,然后用fwrite写入。
经过上面的编码后,我们来看看输出的H264文件。这个视频流明显更加暗淡,并且细节都变小了,包括手的部分、窗的部分等等。

video_erode_dilate_project文件弄到linux编程
// Copyright 2020 Fuzhou Rockchip Electronics Co., Ltd. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <assert.h>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/imgproc.hpp>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
void *opencv_vi_erode_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);//获取VI数据
if (!mb)
{
printf("Get Vi Stream break.....\n");
break;
}
Mat rv1126_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb));//把VI数据转换成OPENCV的Mat矩阵
Mat rv1126_structure = getStructuringElement(MORPH_RECT, Size(15, 15));//获取内核,内核的形状是矩形,长度大小是15 * 15
erode(rv1126_mat, rv1126_mat, rv1126_structure);//对Mat矩阵进行erode腐蚀
RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);//把腐蚀后的数据传输到VENC编码器
RK_MPI_MB_ReleaseBuffer(mb);//释放资源
}
return NULL;
}
void *get_venc_stream_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
FILE * opencv_erode_h264_file = fopen("opencv_erode.h264", "w+");
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1);
if (!mb)
{
printf("Get Venc Stream break.....\n");
break;
}
printf("Get ERODE_STREAM Success...\n");
fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1, opencv_erode_h264_file);
RK_MPI_MB_ReleaseBuffer(mb);
}
return NULL;
}
int main()
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = 1920; // Width
vi_chn_attr.u32Height = 1080; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
VENC_CHN_ATTR_S venc_chn_attr;
memset(&venc_chn_attr, 0, sizeof(VENC_CHN_ATTR_S));
venc_chn_attr.stVencAttr.u32PicWidth = 1920;
venc_chn_attr.stVencAttr.u32PicHeight = 1080;
venc_chn_attr.stVencAttr.u32VirWidth = 1920;
venc_chn_attr.stVencAttr.u32VirHeight = 1080;
venc_chn_attr.stVencAttr.imageType = IMAGE_TYPE_NV12;
venc_chn_attr.stVencAttr.enType = RK_CODEC_TYPE_H264;
venc_chn_attr.stVencAttr.u32Profile = 66;
venc_chn_attr.stRcAttr.enRcMode = VENC_RC_MODE_H264CBR;
venc_chn_attr.stRcAttr.stH264Cbr.u32Gop = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32BitRate = 1920 * 1080 * 3;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateNum = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateNum = 25;
ret = RK_MPI_VENC_CreateChn(VENC_CHN, &venc_chn_attr);
if (ret)
{
printf("ERROR: Create venc failed!\n");
exit(0);
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("ERROR: Start Vi failed.....!\n");
return -1;
}
else
{
printf("SUCCESS: Start Vi success.....!\n");
}
pthread_t pid;
pthread_create(&pid, NULL, opencv_vi_erode_thread, NULL);//腐蚀处理线程
pthread_create(&pid, NULL, get_venc_stream_thread, NULL);//获取VENC线程
while (1)
{
sleep(2);
}
RK_MPI_VENC_DestroyChn(VENC_CHN);
RK_MPI_VI_DisableChn(CAMERA_ID, CAMERA_CHN);
return 0;
}
编译放到板子运行

1.17RV1126+OPENCV在视频中添加时间戳
- RV1126+OPENCV在视频中添加时间戳大体流程图
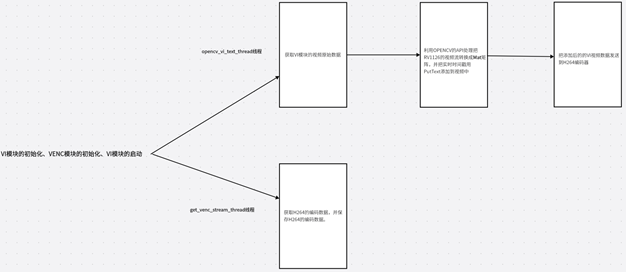
本章节属于实战课程,主要是利用RV1126的视频流结合OPENCV的API对视频流进行字符串叠加,字符串的内容是实时时间戳,然后把VI发送到H264编码器里面,最后把编码数据保存起来。要完成这个功能我们首先要初始化VI、VENC的模块,并且使能,然后需要创建两个线程。
第一个线程是opencv_vi_text_thread线程,这个线程主要的功能是获取VI原始数据,然后格式化字符串并且转换成string,并用OPENCV的API把每一帧转换成Mat,转换完之后用putText把字符串写到矩阵里面,最后把处理后的VI视频数据发送到VENC编码器里面。
第二个线程是get_venc_stream_thread它主要是获取H264的VENC码流数据,并且保存到H264文件。
- RV1126+OPENCV在视频中添加实时时间戳代码实现
代码的实现如下,我们来看看具体的代码截图:
2.1. RV1126模块初始化并启动VI工作
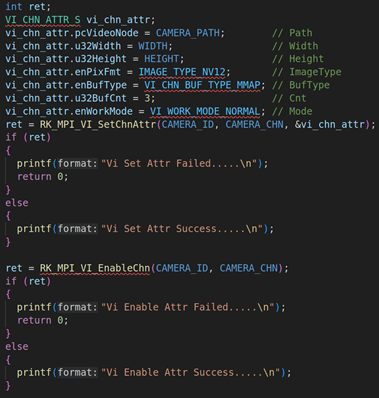
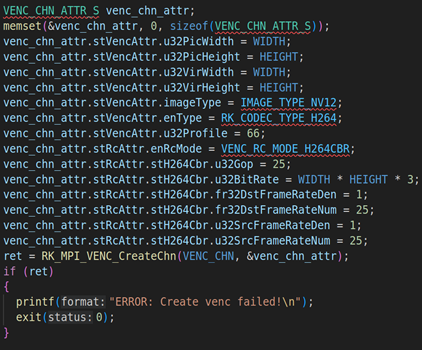
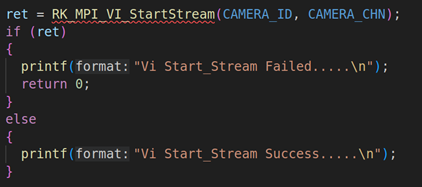
上面代码是RV1126模块的初始化,包括VI模块的初始化(RK_MPI_VI_SetChnAttr)、使能VI模块(RK_MPI_VI_EnableChn)、VENC模块的初始化(RK_MPI_VENC_CreateChn)、启动VI工作(RK_MPI_VI_StartStream)。关于这方面的参数设置,我们就不详细说了,因为这方面的内容之前的课程已经详细说过。
2.2. opencv_vi_text_thread线程的讲解
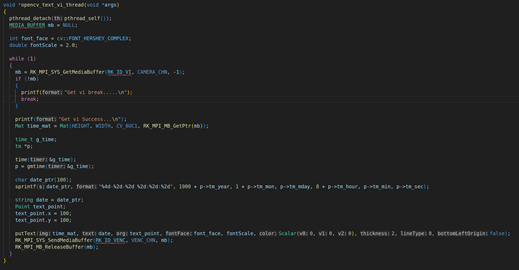
上面是opencv_vi_text_thread线程的主要内容,首先我们要通过RK_MPI_SYS_GetMediaBuffer获取每一帧的VI视频原始数据。
然后使用time的时间函数获取系统时间,并用gmtime把当前时间转换成格林威治时间函数,并且调用sprintf格式化系统时间的字符串打印:打印需要遵循这种格式(”%4d-%2d-%2d %2d:%2d:%2d”, 1900 + p->tm_year(这里的年份需要加上1900,这是由于当前系统时间的年份都是从1900开始算起,所以真实年份都需要加上1900), 1+p->tm_mon(gmtime返回的月份是从0开始,换言之就是第一个月对应的索引值是0而不是1,所以我们要得到真正的月份都需要加1),p->tm_mday(日的输出,正常输出就行),8 + p->tm_hour(由于格林威治获取的小时和北京时间有8个小时的时差,因此我们要获取当前的本地时间需要+8小时才能够得到真实的小时),p->tm_min(分钟的输出,正常输出),p->tm_sec(输出秒数)。
利用OPENCV的Mat构造器把每一帧RV1126的VI视频原始数据转换成矩阵,Mat tmp_img = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb));第一个参数是HEIGHT:1080,第二个参数WIDTH:1920,第三个参数:图像格式CV_8UC1,第四个参数:具体的图像数据RK_MPI_MB_GetPtr(mb),然后再调用putText把时间戳的字符串,叠加到OPENCV的矩阵上面,具体的实现cv::putText(tmp_img, date_text, origin, font_face, font_scale, cv::Scalar(0, 0, 0), thickness, 8, 0);
做完上述步骤后,把每一帧经过处理后的VI原始数据发送到H264的VENC编码器,调用的API是RK_MPI_SYS_SendMediaBuffer。具体的实现是RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);。
2.3. get_venc_stream_thread线程的讲解
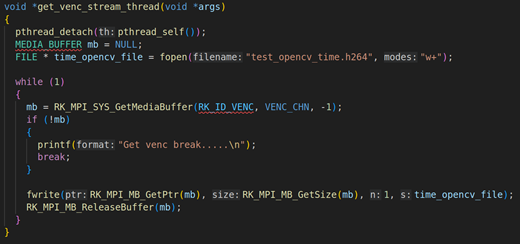
上面是get_venc_stream_thread的具体实现,在这个线程里面要通过RK_MPI_SYS_GetMediaBuffer获取每一帧H264的编码数据,然后用fwrite写入,具体的实现如mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, 0, -1);。
我们来看看,最后的输出效果

上面这张图就是在RV1126的视频数据里面添加时间字符串,并把字符串放在画面中间。
这里要注意的一点,需要用date去修改板子日期,因为板子默认是1970的时间,如:
date -s "2024-1-27 12:15:35"
video_opencv_text_project放在在linux里编程
// Copyright 2020 Fuzhou Rockchip Electronics Co., Ltd. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
#include <assert.h>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgproc/imgproc_c.h>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
//VI数据和时间戳添加处理线程
void *opencv_text_vi_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
int font_face = cv::FONT_HERSHEY_COMPLEX;
double fontScale = 2.0;
while (1)
{
//获取VI模块的数据
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);//把VI数据转换成Mat矩阵
if (!mb)
{
printf("Get vi break.....\n");
break;
}
printf("Get vi Success...\n");
Mat time_mat = Mat(HEIGHT, WIDTH, CV_8UC1, RK_MPI_MB_GetPtr(mb));//把VI数据转换成Mat矩阵
time_t g_time;
tm *p;
time(&g_time);//获取系统时间
p = gmtime(&g_time);//把系统时间转换成格林威治时间,并标准化
char date_ptr[100];
sprintf(date_ptr, "%4d-%2d-%2d %2d:%2d:%2d", 1900 + p->tm_year, 1 + p->tm_mon, p->tm_mday, 8 + p->tm_hour, p->tm_min, p->tm_sec);//把标准化的数据转换成字符串,包括年(1900 + tm_year)月(tm_mon+1)日(tm_day)时(tm_hour + 8)分(tm_min)秒(tm_src)
string date = date_ptr;
Point text_point;
text_point.x = 100;
text_point.y = 100;
putText(time_mat, date, text_point, font_face, fontScale, Scalar(0, 0, 0), 2, 8, false);//把字符串显示到Mat矩阵
RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);//把处理后的VI数据传输给VENC编码器
RK_MPI_MB_ReleaseBuffer(mb);//释放资源
}
}
//
void *get_venc_stream_thread(void *args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
FILE * time_opencv_file = fopen("test_opencv_time.h264", "w+");
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1);//获取VENC编码器数据
if (!mb)
{
printf("Get venc break.....\n");
break;
}
fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1, time_opencv_file);//保存数据
RK_MPI_MB_ReleaseBuffer(mb);//释放资源
}
}
int main()
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = WIDTH; // Width
vi_chn_attr.u32Height = HEIGHT; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
VENC_CHN_ATTR_S venc_chn_attr;
memset(&venc_chn_attr, 0, sizeof(VENC_CHN_ATTR_S));
venc_chn_attr.stVencAttr.u32PicWidth = WIDTH;
venc_chn_attr.stVencAttr.u32PicHeight = HEIGHT;
venc_chn_attr.stVencAttr.u32VirWidth = WIDTH;
venc_chn_attr.stVencAttr.u32VirHeight = HEIGHT;
venc_chn_attr.stVencAttr.imageType = IMAGE_TYPE_NV12;
venc_chn_attr.stVencAttr.enType = RK_CODEC_TYPE_H264;
venc_chn_attr.stVencAttr.u32Profile = 66;
venc_chn_attr.stRcAttr.enRcMode = VENC_RC_MODE_H264CBR;
venc_chn_attr.stRcAttr.stH264Cbr.u32Gop = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32BitRate = WIDTH * HEIGHT * 3;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateNum = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateNum = 25;
ret = RK_MPI_VENC_CreateChn(VENC_CHN, &venc_chn_attr);
if (ret)
{
printf("ERROR: Create venc failed!\n");
exit(0);
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("start vi failed....\n");
}
else
{
printf("start vi success....\n");
}
pthread_t pid1, pid2;
pthread_create(&pid1, NULL, opencv_text_vi_thread, NULL);
pthread_create(&pid2, NULL, get_venc_stream_thread, NULL);
while (1)
{
sleep(2);
}
RK_MPI_VENC_DestroyChn(VENC_CHN);
RK_MPI_VI_DisableChn(CAMERA_ID, CAMERA_CHN);
return 0;
}
编译完放到板子运行

2.ROCKX
2.1Rockx-SDK的简介
- ROCKX-SDK是什么
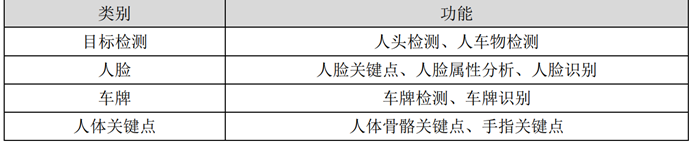
Rockx-sdk是基于rk系列(包括: RV1126/RV1109、RK3399/RK3568)的一套AI组件。开发者可以使用ROCKX的AI组件快速搭建AI的应用,这些应用可以是车牌识别、人脸识别、目标识别,人体骨骼识别等等,具体的如上图。我们本章节的内容主要是讲解rockx的人脸识别、人脸检测模块。
二.ROCKX-SDK版本
![]()
上面目录有很多个版本的ROCKX-SDK, 这个SDK主要是包含不同类型的识别模型 , 我们来一一来进行解释:
2.1. rockx-data:
rockx-data是通用的版本,就是所有的芯片都可以用到这个模型类型
![]()
2.1.1. carplate_align.data:车牌对齐模型,主要是用在车牌图像的矫正
2.1.2. carplate_detection.data:车牌检测模型,主要是用于图像中的车牌图像的检测
2.1.3. carplate_recognition.data:车牌识别模型,主要是用于图像中的车牌图像的识别
2.1.4. face_attribute.data:人脸属性模型,主要是用于人脸属性的输出
2.1.5. face_detection.data:人脸检测模型,主要是用于人脸的检测
2.1.6. face_landmark5.data:人脸关键点检测,landmark5指的是5点面部标识,包括:额头、两边的面颊、鼻尖、下巴
2.1.7. face_landmarks68.data:人脸关键点检测,landmark68指的是68点面部标识,包括:眉毛、眼睛、鼻子、嘴巴一共51个关键点,轮廓关键点17个
2.1.8. face_liveness_2d.data:人脸活体检测模型,主要是检测人脸是否是活人
2.1.9. face_recognition.data:人脸识别模型,主要是判断两个人脸的特征值是否是同一个人
2.1.10.head_detection.data:头部检测模型,主要是判断人的头部
2.1.11.object_detection.data:物体检测模型,判断当前图像的物体是什么,object_detection的底层是用rknn进行人工智能的训练
2.1.12.pose_body.data:人体姿态检测模型,人体姿态指的是将图片中已检测到的人体关键点正确连接起来,并正确估计人体的姿态。人体的姿态一般如:肩、颈、腰、膝盖等
2.1.13.pose_finger.data:人体手指检测模型,主要是检测手指的关键点。
2.1.14.pose_hand.data:人体手势识别。
2.2.rockx-data-rv1109:
![]()
rockx-data-rv1109是rv1126/rv1109芯片适配的AI模型
2.2.1.body_detection.data:人体检测模型,主要是判断目前物体是否是人
2.2.2.body_mask:口罩检测模型,判断目前人是否带口罩
2.2.3. carplate_align.data:车牌对齐模型,主要是用在车牌图像的矫正
2.2.4. carplate_detection.data:车牌检测模型,主要是用于图像中的车牌图像的检测
2.2.5. carplate_recognition.data:车牌识别模型,主要是用于图像中的车牌图像的识别
2.2.6. face_attribute.data:人脸属性模型,主要是用于人脸属性的输出
2.2.7.face_detection_v2.data:人脸检测模型V2,V2指的是Version2。它主要运用在人脸的检测
2.2.8.face_detection_v2_horizontal.data:人脸水平位置检测V2,V2指的是Version2。它主要运用在人脸的水平位置检测,就是图像位置只能是水平位置。
2.2.9.face_detection_v3.data:人脸检测模型V3,V3指的是Version3。它主要运用在人脸检测,Version3的人脸检测精确度比Version3更加精确。
2.2.10.face_detection_v3_fast.data:人脸检测模型V3,V3指的是Version3。它主要运用在人脸检测,Version3的人脸检测精确度比Version3更加精确,fast指的是精简版意思它的人脸检测的模型比较少。
2.2.11. face_detection_v3_large.data:人脸检测模型V3,V3指的是Version3。它主要运用在人脸检测,Version3的人脸检测精确度比Version3更加精确,large指的是加强版它提供的人脸检测模型比v3和v3_fast都要全面。
2.2.11. face_landmark5.data:人脸关键点检测,landmark5指的是5点面部标识,包括:额头、两边的面颊、鼻尖、下巴
2.2.12. face_landmarks68.data:人脸关键点检测,landmark68指的是68点面部标识,包括:眉毛、眼睛、鼻子、嘴巴一共51个关键点,轮廓关键点17个
2.2.13. face_mask_classify.data:口罩分类检测,检测当前口罩是什么类型
2.2.14. face_masks_detection.data:检测当前人是否戴口罩
2.2.15. face_recognition.data:人脸识别模型,主要是判断两个人脸的特征值是否是同一个人
2.2.16. head_detection.data:头部检测模型,主要是判断人的头部
2.2.17. head_detection_v2_640X480.data:头部检测模型,它只能检测640 * 480的视频图像
2.2.18. object_detection.data:物体检测模型,判断当前图像的物体是什么,object_detection的底层是用rknn进行人工智能的训练
2.2.19. person_detection_v2.data:人体检测模型,判断当前的视频或者图像有无行人,V2指的是Version2版本。
2.2.19. person_detection_v3.data:人体检测模型,判断当前的视频或者图像有无行人,V3指的是Version3版本。V3的行人检测精确度要比Version2要高不少
2.2.19. pose_body.data:人体姿态检测模型,人体姿态指的是将图片中已检测到的人体关键点正确连接起来,并正确估计人体的姿态。人体的姿态一般如:肩、颈、腰、膝盖等
2.2.20. pose_body_v2.data:人体姿态检测模型,人体姿态指的是将图片中已检测到的人体关键点正确连接起来,并正确估计人体的姿态,人体的姿态一般如:肩、颈、腰、膝盖等。V2指的是Version2,它的精确度要比pose_body.data要高。
2.2.21.pose_finger.data:人体手指检测模型,主要是检测手指的关键点。
2.2.22.pose_hand.data:人体手势识别。
2.3.rockx-rk1806-Linux:
![]()
这里主要是放rk1806的动态库和头文件include
2.3.1. lib文件夹:
![]()
librknn_api.so:rknn的动态库
librockx.so:rockx的动态库
注意:在开发中,通常需要把librknn_api.so和librockx.so放在同一个目录下,rockx的功能才会正常
2.3.2.include文件夹
![]()
rockx.h:rockx的创建和销毁的API函数的头文件
rockx_type.h:rockx类型的头文件定义,包括像素类型、数据类型等
2.3.2.1. modules文件夹
![]()
carplate.h:车牌识别的头文件
face.h:人脸识别检测相关的头文件
object_detection.h:物体检测的头文件
object_track.h:物体追踪的头文件
pose.h:姿态相关的头文件
2.3.2.2. utils文件夹![]()
rockx_config_util.h:rockx配置相关的头文件
rockx_image_util.h:rockx跟图像处理相关的头文件
rockx_tensor_util.h:rockx跟tensor相关的头文件
2.4.rockx-rk1808-Linux:
![]()
这里主要是放rk1808的动态库和头文件include
2.4.1.lib64文件夹
![]()
librknn_api.so:rknn的动态库
librockx.so:rockx的动态库
注意:在开发中,通常需要把librknn_api.so和librockx.so放在同一个目录下,rockx的功能才会正常
2.4.2.include文件夹
![]()
rockx.h:rockx的创建和销毁的API函数的头文件
rockx_type.h:rockx类型的头文件定义,包括像素类型、数据类型等
2.4.2.1. modules文件夹
![]()
carplate.h:车牌识别的头文件
face.h:人脸识别检测相关的头文件
object_detection.h:物体检测的头文件
object_track.h:物体追踪的头文件
pose.h:姿态相关的头文件
2.4.2.2. utils文件夹![]()
rockx_config_util.h:rockx配置相关的头文件
rockx_image_util.h:rockx跟图像处理相关的头文件
rockx_tensor_util.h:rockx跟tensor相关的头文件
2.5.rockx-rk3399pro-Android:
![]()
这里主要是放rk3399的Android动态库和头文件,要注意的是Android版本的动态库分两个,一个是arm64-v8a,另外一个是arm64-v7a。
2.5.1. arm64-v8a目录
![]()
arm64-v8a:第八代64位ARM处理器,这个文件夹里面主要是放了librknn_api.so和librockx.so两个动态库。
2.5.2. arm64-v7a目录
arm64-v8a:第七代ARM处理器,这个文件夹里面主要是放了librknn_api.so和librockx.so两个动态库。
2.5.3.include目录
![]()
2.5.3.1. include文件夹
![]()
rockx.h:rockx的创建和销毁的API函数的头文件
rockx_type.h:rockx类型的头文件定义,包括像素类型、数据类型等
2.5.3.2. modules文件夹
![]()
carplate.h:车牌识别的头文件
face.h:人脸识别检测相关的头文件
object_detection.h:物体检测的头文件
object_track.h:物体追踪的头文件
pose.h:姿态相关的头文件
2.5.3.3. utils文件夹![]()
rockx_config_util.h:rockx配置相关的头文件
rockx_image_util.h:rockx跟图像处理相关的头文件
rockx_tensor_util.h:rockx跟tensor相关的头文件
2.6.rockx-rk3399pro-Linux:
![]()
这里主要是放rk3399的Linux动态库和头文件。
2.6.1.lib64文件夹
![]()
librknn_api.so:rknn的动态库
librockx.so:rockx的动态库
注意:在开发中,通常需要把librknn_api.so和librockx.so放在同一个目录下,rockx的功能才会正常
2.6.2.include文件夹
![]()
rockx.h:rockx的创建和销毁的API函数的头文件
rockx_type.h:rockx类型的头文件定义,包括像素类型、数据类型等
2.6.2.1.modules文件夹
![]()
carplate.h:车牌识别的头文件
face.h:人脸识别检测相关的头文件
object_detection.h:物体检测的头文件
object_track.h:物体追踪的头文件
pose.h:姿态相关的头文件
2.7. rockx-rv1109-Linux:
![]()
这里主要是放rv1126/rv1109的Linux动态库和头文件。
2.7.1. lib文件夹
![]()
librknn_api.so:rknn的动态库
librockx.so:rockx的动态库
注意:在开发中,通常需要把librknn_api.so和librockx.so放在同一个目录下,rockx的功能才会正常
2.7.2. include文件夹
![]()
rockx.h:rockx的创建和销毁的API函数的头文件
rockx_type.h:rockx类型的头文件定义,包括像素类型、数据类型等
2.7.2.1.modules文件夹
![]()
bodymask.h:身体遮挡的头文件
carplate.h:车牌识别的头文件
face.h:人脸识别检测相关的头文件
object_detection.h:物体检测的头文件
object_track.h:物体追踪的头文件
pose.h:姿态相关的头文件
2.7.2.2. utils文件夹![]()
rockx_config_util.h:rockx配置相关的头文件
rockx_image_util.h:rockx跟图像处理相关的头文件
rockx_tensor_util.h:rockx跟tensor相关的头文件
2.8.rockx-x86-64-Linux:
这里主要是包含x86-64的瑞芯微动态库和include头文件
![]()
2.8.1. lib64文件夹
![]()
librknn_api.so:rknn的动态库
librockx.so:rockx的动态库
npu_transfer_proxy:npu是人工智能加速的模块
注意:在开发中,通常需要把librknn_api.so和librockx.so放在同一个目录下,rockx的功能才会正常
2.8.2. include文件夹
![]()
rockx.h:rockx的创建和销毁的API函数的头文件
rockx_type.h:rockx类型的头文件定义,包括像素类型、数据类型等
2.8.2.1.modules文件夹
![]()
carplate.h:车牌识别的头文件
face.h:人脸识别检测相关的头文件
object_detection.h:物体检测的头文件
object_track.h:物体追踪的头文件
pose.h:姿态相关的头文件
2.8.2.2. utils文件夹
![]()
rockx_config_util.h:rockx配置相关的头文件
rockx_image_util.h:rockx跟图像处理相关的头文件
rockx_tensor_util.h:rockx跟tensor相关的头文件
三.把rockx_data的文件夹放到板子的/userdata/里面
![]()
上图是要把rockx_data的文件夹放到/usesrdata/里面,这个rockx_data是我经过裁剪后的data模型数据,直接用就可以。
2.2 rockx常用的API讲解
- rockx人脸检测使用的API
rockx框架提供了一系列的人脸识别、检测的API,开发者使用它的API能够快速开发出人脸相关的功能。我们来看看在人脸检测中需要用到的API。
-
- rockx_create函数的定义
rockx_ret_t rockx_create(rockx_handle_t *handle, rockx_module_t m, void *config, size_t config_size);
函数解释:rockx_create创建rockx的句柄rockx_handle_t。rockx_handle_t也是管理整个rockx人脸检测、人脸识别的最重要结构体
第一个参数:rockx_handle_t的结构体指针
第二个参数:rockx_module_t的结构体,rockx_module_t是一个枚举类型,设置当前rockx的处理类型。具体的如下:
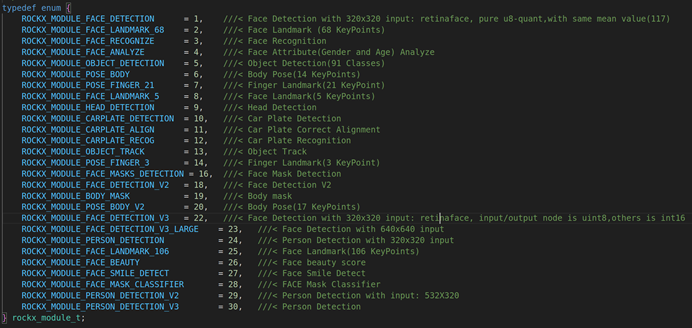
ROCKX_MODULE_FACE_DETECTION:人脸检测模块
ROCKX_MODULE_FACE_LANDMARK_68:人脸68个特征点检测
ROCKX_MODULE_FACE_RECOGNIZE:人脸识别模块
ROCKX_MODULE_FACE_ANALYZE: 人脸分析模块
ROCKX_MODULE_OBJECT_DETECTION:目标检测模块
ROCKX_MODULE_POSE_BODY: 人体姿态检测模块,14个关键点
ROCKX_MODULE_POSE_FINGER_21:手指检测模块,21个关键点
ROCKX_MODULE_FACE_LANDMARK_5:人脸5个特征点检测
ROCKX_MODULE_HEAD_DETECTION: 人体头部检测模块
ROCKX_MODULE_CARPLATE_DETECTION: 车牌检测模块
ROCKX_MODULE_CARPLATE_ALIGN:车牌对齐模块
ROCKX_MODULE_CARPLATE_RECOG:车牌识别模块
ROCKX_MODULE_OBJECT_TRACK:物体追踪模块
ROCKX_MODULE_POSE_FINGER_3:手指检测模块, 支持3个关键点
ROCKX_MODULE_FACE_MASKS_DETECTION:人脸口罩检测,检测这个人是否戴口罩
ROCKX_MODULE_FACE_DETECTION_V2:人脸检测模块,Version2版本
ROCKX_MODULE_BODY_MASK:人体身体遮挡检测,主要是检测当前人体是否有遮挡物
ROCKX_MODULE_POSE_BODY_V2:人体姿态检测,V2是Version2,最多能够检测17个关键点
ROCKX_MODULE_FACE_DETECTION_V3:人脸检测模块,V3是Version3,它只能检测320 * 320的人脸
ROCKX_MODULE_FACE_DETECTION_V3_LARGE:人脸检测模块加强版,V3是Version3,Large能够检测640 * 640的人脸
ROCKX_MODULE_PERSON_DETECTION:行人检测模块,主要是检测当前图像中是否有行人
ROCKX_MODULE_FACE_LANDMARK_106:人脸关键点检测模型,总共能检测出106个关键点
ROCKX_MODULE_FACE_BEAUTY:人脸漂亮指数检测模型,主要是检测人的漂亮指数是多少
ROCKX_MODULE_FACE_SMILE_DETECT:人脸微笑检测模型,检测当前人是否微笑
ROCKX_MODULE_FACE_MASK_CLASSIFIER:人脸口罩分类检测模型,主要是检测当前口罩的类型是什么
ROCKX_MODULE_PERSON_DETECTION_V2:行人检测模型,V2是Version2,它只能检测532 * 320的行人图像
ROCKX_MODULE_PERSON_DETECTION_V3:行人检测模型,V3是Version3,它可以检测多尺寸的行人图像
第三个参数:rockx_config_t结构体指针,主要是配置rockx的基本参数,它的创建是用rockx_add_config来创建
第四个参数:config_size,默认是0就可以
-
- rockx_add_config函数的定义
rockx_ret_t rockx_add_config(rockx_config_t *config, const char *key, const char *value);
函数解释:添加rockx的config配置
第一个参数:rockx_config_t结构体指针,rockx_config_t的创建是用rockx_create_config来分配,如:rockx_config_t *config = rockx_create_config();
第二个参数:config的key, 最常见的KEY是ROCKX_CONFIG_DATA_PATH(ROCKX的配置路径)
第三个参数:config的value, 跟Key一一对应, 比方说Key是ROCKX_CONFIG_DATA_PATH, 那它的value就是对应的rockx的具体路径,如:/userdata/rockx_data/。
示例:
rockx_config_t *config = rockx_create_config();
rockx_add_config(config, ROCKX_CONFIG_DATA_PATH, "/userdata/rockx_data/");
-
- rockx_face_detect函数的定义
函数解释:这个API主要是对人脸进行检测,得到人脸检测的位置信息
rockx_ret_t rockx_face_detect(rockx_handle_t handle, rockx_image_t *in_img, rockx_object_array_t *face_array, rockx_async_callback *callback);
第一个参数:rockx_handle_t的结构体
第二个参数:rockx_image_t的结构体指针,这个是输入的图像,需要检测的图像,也可以是每一帧视频流。
第三个参数:rockx_object_array_t的结构体指针,主要是输出检测结果,这个检测结果的结构体如下:

count:检测的人脸数量
rockx_object_t:检测的具体信息,具体的成员变量如下:
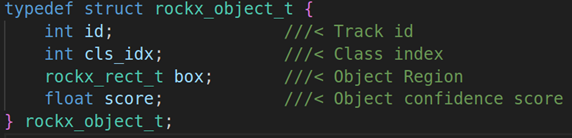
id:object的id号
cls_idx:object的index索引
box:rockx的区域信息,rockx_rect_t结构体。
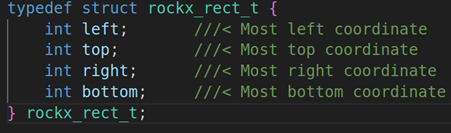
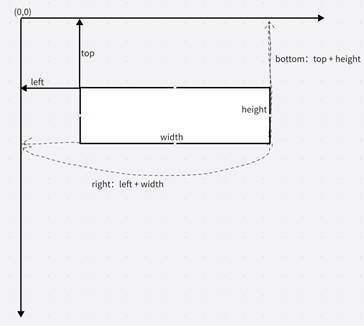
left:区域左边缘的x坐标,其实就是x轴数据
top: 区域顶的y坐标,其实就是Y轴数据
right:区域右边缘的x坐标,其实就是left + width
bottom:区域底的Y坐标,其实就是 top + height
score:object物体信任分数
第四个参数:config_size,默认是0就可以
-
- rockx_face_recognize函数的定义
函数定义:这个API主要是对人脸进行识别,并提取人脸数据
rockx_ret_t rockx_face_recognize(rockx_handle_t handle, rockx_image_t *in_img, rockx_face_feature_t *out_feature);
第一个参数:rockx_handle_t的结构体
第二个参数:rockx_image_t的结构体指针,这个是输入的图像,需要检测的图像,也可以是每一帧视频流。
第三个参数:rockx_face_feature_t的结构体指针,rockx_face_feature_t结构体主要是存储人脸的特征值和长度,我们来看看这个结构体的组成

version:人脸识别版本
len:人脸识别的长度(size)
feature[512]:人脸识别的数据,512的float数组,这个值是存储一个二进制数据
-
- rockx_face_feature_similarity函数的定义
函数的定义:这个API主要是对比两个人脸,并计算两个人脸的对比数值
rockx_ret_t rockx_face_feature_similarity(rockx_face_feature_t *in_feature1, rockx_face_feature_t *in_feature2, float *out_similarity);
第一个参数:in_feature1,需要对比的人脸特征值1
第一个参数:in_feature2,需要对比的人脸特征值2
第三个参数:in_feature1和in_feature2对比的相似度值,一般小于1.0可以判断为同一个人
-
- rockx_face_align函数的定义
函数的定义:这个API主要是对目前检测的人脸进行对齐,这个对齐一般是用face_landmark检测人脸关键点进行对齐
rockx_ret_t rockx_face_align(rockx_handle_t handle, rockx_image_t *in_img, rockx_rect_t *in_box, rockx_face_landmark_t *in_landmark, rockx_image_t *out_img);
第一个参数:rockx_handle_t的结构体
第二个参数:in_img输入的图像
第三个参数:in_box是人脸检测的区域,用矩形来表示,我们来看看rockx_rect_t的结构体成员变量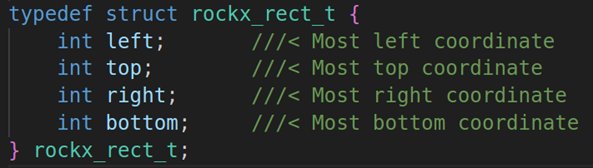
left:表示矩形左边缘的X坐标。
top:表示矩形顶部的y坐标
right:表示矩形右边缘的x坐标
bottom:表示矩形底部的y坐标。
第四个参数:rockx_face_landmark_t 的结构体指针,主要是检测人脸关键点,我们来看看这个结构体的成员变量
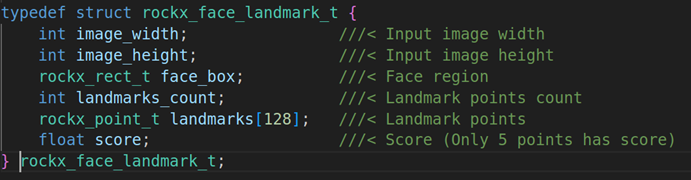
image_width:图像的长度
image_height:图像的高度
face_box:人脸的检测区域,用矩形表示
landmarks_count:关键点个数
landmarks[128]:具体的人脸关键点,rockx_point_t来表示,它本质上就是x,y的点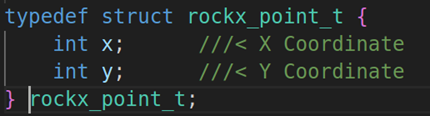
score:每个关键点的分数
第五个参数:out_img输出的图像,经过人脸对齐后的图像
-
- rockx_face_filter函数的定义
函数的定义:这个API主要是过滤人脸,过滤图像中不符合人脸的图像
rockx_ret_t rockx_face_filter(rockx_handle_t handle, rockx_image_t *in_img, rockx_rect_t *in_box, int *is_false_face);
第一个参数:rockx_handle_t的结构体
第二个参数:in_img是输入的图像
第三个参数:in_box人脸检测区域,是一个矩形
第四个参数:is_falas_face判断当前检测的图像是否是人脸,是人脸就等于true,否则false
-
- rockx_face_masks_detect函数的定义
函数解释:这个API主要是检测当前人脸是否有戴口罩
rockx_ret_t rockx_face_masks_detect(rockx_handle_t handle, rockx_image_t *in_img, rockx_face_mask_array_t *face_mask_array,
rockx_async_callback *callback);
第一个参数:rockx_handle_t的结构体
第二个参数:in_img是输入的图像
第三个参数:face_mask_array存放口罩的数据,我们来看看这个结构体的数据
第一个参数:count,口罩的数量
第二个参数:rockx_face_mask_t,具体的口罩参数,如下图
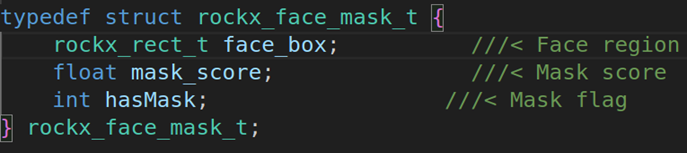
第一个参数:face_box是口罩的区域,用矩形表示
第二个参数:mask_score,口罩的分数
第三个参数:hasMask,是否有戴口罩
2.3rockx读取单张图片并检测图片内人脸的矩形
- rockx人脸检画框测大体流程:
本次代码主要实现如何通过rockx的框架进行人脸的检测,并把人脸画出来。具体的流程如下:
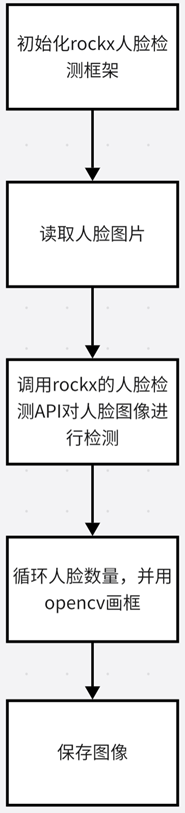
总共分成四步,第一步是初始化rockx人脸检测框架、第二步是读取人脸图片、第三步是调用rockx的人脸检测API对其进行人脸检测、第四步循环人脸数量并使用Opencv进行画框、第五步保存图像.
-
- 初始化rockx人脸检测框架
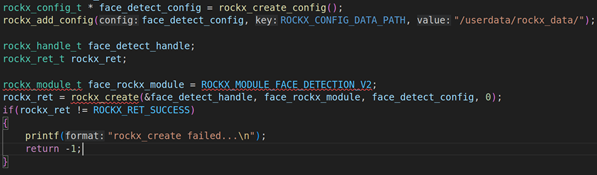
上图是初始化步骤,首先要使用rockx_create_config分配rockx_config_t结构体,并使用rockx_add_config把对应的rockx路径配置进去,在我们的板子里面在/userdata/rockx_data里面,并使用rockx_create创建rockx_handle_t句柄。
-
- 读取人脸图片

读取对应的人脸图片,在rockx里面用rockx_image_read来读取对应的人脸图片。并把人脸的特征数据传入到rockx_image_t结构体里面。
-
- 调用rockx的人脸检测API对其进行人脸检测

调用rockx_face_detect对图片进行人脸检测,这里的输入的是input_image,这个是由rockx_image_read读取的图片数据,输出的数据是rockx_object_array_t,后面的数据则都是通过rockx_object_array_t来处理。
-
- 循环人脸数量并使用Opencv进行画框

循环人脸数量,人脸数量是face_array.count。然后获取人脸的坐标属性,这里的坐标属性就是left、top、w、h,并用OPENCV把input_image转换成Mat矩阵( Mat tmp_img = Mat(input_image.height, input_image.width, CV_8UC3, input_image.data)),转换完成之后再使用rectangle把坐标转换成矩形。
-
- 保存人脸检测的图片

最后用imwrite保存人脸检测后的图片,并使用rockx_destroy销毁rockx_handle_t。
最后的效果:

可以看到周董的脸上就已经出现矩形检测的框框。
rockx_face_detection弄到linux编译
****************************************************************************
*
* Copyright (c) 2017 - 2019 by Rockchip Corp. All rights reserved.
*
* The material in this file is confidential and contains trade secrets
* of Rockchip Corporation. This is proprietary information owned by
* Rockchip Corporation. No part of this work may be disclosed,
* reproduced, copied, transmitted, or used in any way for any purpose,
* without the express written permission of Rockchip Corporation.
*
*****************************************************************************/
#include <stdio.h>
#include <memory.h>
#include <sys/time.h>
#include "rknn_rockx_include/rockx_type.h"
#include "rknn_rockx_include/utils/rockx_config_util.h"
#include "rknn_rockx_include/utils/rockx_image_util.h"
#include "rockx.h"
#include <opencv2/opencv.hpp>
#include <opencv2/imgcodecs.hpp>
using namespace cv;
int main(int argc, char **argv)
{
const char * img_path = argv[1];
rockx_config_t * face_detect_config = rockx_create_config();
rockx_add_config(face_detect_config, ROCKX_CONFIG_DATA_PATH, "/userdata/rockx_data/");
rockx_handle_t face_detect_handle;
rockx_ret_t rockx_ret;
rockx_module_t face_rockx_module = ROCKX_MODULE_FACE_DETECTION_V2;
rockx_ret = rockx_create(&face_detect_handle, face_rockx_module, face_detect_config, 0);
if(rockx_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_create failed...\n");
return -1;
}
rockx_image_t face_rockx_image;
rockx_image_read(img_path, &face_rockx_image, 1);
rockx_object_array_t face_array;
rockx_ret = rockx_face_detect(face_detect_handle, &face_rockx_image, &face_array, nullptr);
if(rockx_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_face_detect failed...\n");
return -1;
}
Mat rockx_face_mat = Mat(face_rockx_image.height, face_rockx_image.width, CV_8UC3, face_rockx_image.data);
for (int i = 0; i < face_array.count; i++)
{
int left = face_array.object[i].box.left;
int top = face_array.object[i].box.top;
int w = face_array.object[i].box.right - face_array.object[i].box.left;
int h = face_array.object[i].box.bottom - face_array.object[i].box.top;
Rect boudingRect(left, top, w, h);
rectangle(rockx_face_mat, boudingRect, Scalar(255,255,0),1);
}
imwrite("output_face_det.jpg", rockx_face_mat);
rockx_destroy(face_detect_handle);
return 0;
}
段错误原因:给的图片有问题,导致创建mat矩阵的时候出错。


2.4ROCKX+RV1126视频流检测人脸
- Rockx+Rv1126视频流检测人脸的大体流程图
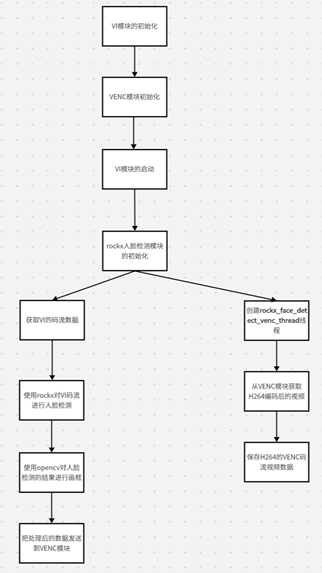
上图是rockx+rv1126的大体流程,首先要初始化模块包括VI模块、VENC模块、并启动VI模块采集视频流、rockx模块的初始化。初始化模块后,就要分两个线程处理了。
主线程是负责rockx对VI视频流的处理,并用OPENCV对人脸进行画框,最后把处理后的VI数据传输到VENC模块里面。
第二个线程rockx_face_detect_venc_thread,从VENC模块获取到H264的编码码流数据,并把VENC码流数据保存。
二.Rockx+Rv1126视频流检测人脸的代码截图
2.1. RV1126模块初始化并启动VI工作
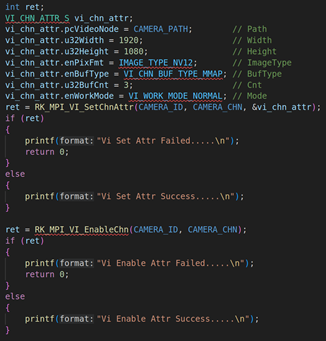
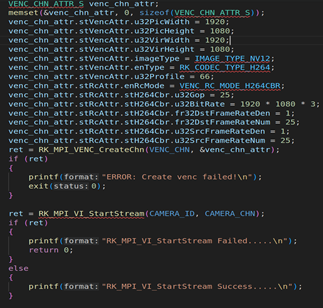
上图是RV1126模块的初始化,包括VI模块、VENC模块的初始化,初始化上述模块后,则调用RK_MPI_VI_StartStream启动VI开始采集摄像头的视频流。关于VI模块、VENC模块的初始化参数这里就不阐述了,因为之前的课程里面已经讲了很多次。
2.2. rockx人脸检测模块的初始化
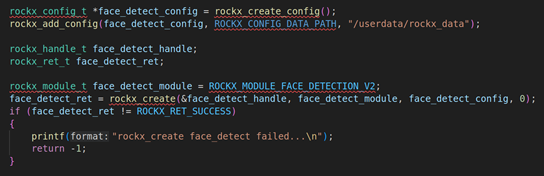
这段代码是初始化rockx的模块,首先要使用rockx_create_config分配rockx_config_t结构体,并使用rockx_add_config把对应的rockx路径配置进去,在我们的板子里面在/userdata/rockx_data里面,并使用rockx_create创建rockx_handle_t句柄,rockx_create的传参第一个参数rockx_handle_t结构体指针、 第二个参数rockx_module_t是ROCKX_MODULE_FACE_DETECTION_V2,ROCKX_MODULE_FACE_DETECTION_V2是人脸检测的Version2模块、第三个参数是rockx_config_t结构体指针、第四个参数默认是0。
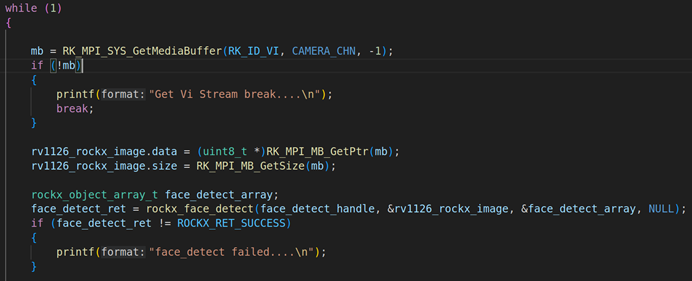
2.3. 使用rockx对VI模块的数据进行人脸检测处理

(图2.3.1)
(图2.3.2)
这部分代码是整个DEMO的核心,也是ROCKX检测VI视频数据的核心。图2.3.1是初始化rockx_image_t结构体,初始化需要传三个值分别是width = WIDTH(1920)、height = HEIGHT(1080)、pixel_format=ROCKX_PIXEL_FORMAT_YUV420SP_NV12。这三个值都需要和VI模块的配置是一样的。
初始化rockx_image_t后,则需要通过RK_MPI_SYS_GetMediaBuffer获取每一帧VI模块的数据,并把每一帧VI模块的缓冲区和长度传输给rockx_image_t。具体的代码是rv1126_rockx_image.data = (uint8_t *)RK_MPI_MB_GetPtr(mb)(把每一帧VI缓冲区数据赋值到rockx_image_t的data)、rv1126_rockx_image.size = RK_MPI_MB_GetSize(mb)(把每一帧VI大小赋值到rockx_image_t的size)
赋值到rockx_image_t后,则调用rockx_face_detect对每一帧的rockx_image_t图像进行人脸检测,并把人脸检测的结果输出到rockx_object_array_t。rockx_object_array_t的内容主要存储的是人脸检测数量和人脸检测区域信息(如:left、top、right、bottom的坐标信息)
2.4. 使用opencv对人脸检测的结果进行画框
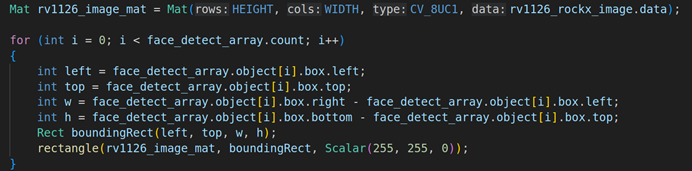
检测完每一帧人脸数据后就需要对每个人脸区域进行画框了,这里画框是用opencv进行处理。首先要先创建OPENCV的Mat矩阵,Mat rv1126_image_mat = Mat(HEIGHT, WIDTH, CV_8UC1, rv1126_rockx_image.data)。创建完Mat之后,则需要根据rockx_object_array_t的坐标信息进行画框,先循环遍历人脸的数量(rockx_object_array_t.count),然后获取每一帧人脸的坐标信息,主要是left、top、right、bottom, 最后使用OPENCV的rectangle函数把坐标信息描绘出一个矩形表现出来。
2.5. 把处理后的数据发送到VENC模块
![]()
把上述的数据处理完成之后则把每一帧数据传输给VENC模块,这里使用的API是RK_MPI_SYS_SendMediaBuffer。此时此刻VENC模块就有VENC码流数据了
2.6. 创建rockx_face_detect_venc _thread线程保存每一帧H264的编码码流数据
![]()
(图2.6.1)
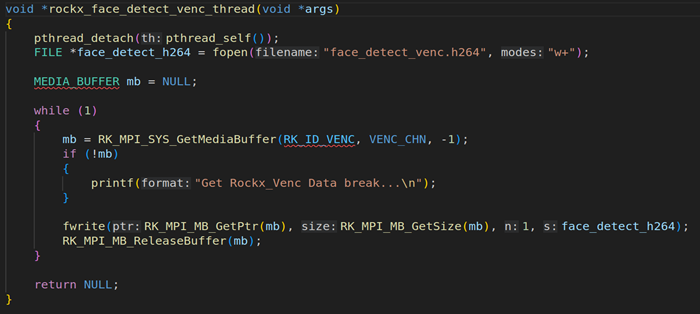
(图2.6.2)
通过pthread_create创建venc码流线程,这个线程的名字是rockx_face_detect_venc thread,如图(2.6.1)。在这个线程里面,通过RK_MPI_SYS_GetMediaBuffer获取每一帧通过rockx人脸检测处理后的VENC码流数据,并用fwrite保存起来(fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1, face_detect_h264)),如图2.6.2。
最终输出的结果:
最终输出的结果是在视频中检测出对应的人脸并用opencv画矩形出来。
rockx_face_camera_vi文件夹放入linux编程,编译后拿到板子运行
/****************************************************************************
*
* Copyright (c) 2017 - 2019 by Rockchip Corp. All rights reserved.
*
* The material in this file is confidential and contains trade secrets
* of Rockchip Corporation. This is proprietary information owned by
* Rockchip Corporation. No part of this work may be disclosed,
* reproduced, copied, transmitted, or used in any way for any purpose,
* without the express written permission of Rockchip Corporation.
*
*****************************************************************************/
#include <assert.h>
#include <cstddef>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgproc/imgproc_c.h>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include "rknn_rockx_include/rockx_type.h"
#include "rockx.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
using namespace cv;
void *rockx_face_detect_venc_thread(void *args)
{
pthread_detach(pthread_self());
FILE *face_detect_h264 = fopen("face_detect_venc.h264", "w+");
MEDIA_BUFFER mb = NULL;
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1);
if (!mb)
{
printf("Get Rockx_Venc Data break...\n");
}
fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1, face_detect_h264);
RK_MPI_MB_ReleaseBuffer(mb);
}
return NULL;
}
int main(int argc, char **argv)
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = 1920; // Width
vi_chn_attr.u32Height = 1080; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
VENC_CHN_ATTR_S venc_chn_attr;
memset(&venc_chn_attr, 0, sizeof(VENC_CHN_ATTR_S));
venc_chn_attr.stVencAttr.u32PicWidth = 1920;
venc_chn_attr.stVencAttr.u32PicHeight = 1080;
venc_chn_attr.stVencAttr.u32VirWidth = 1920;
venc_chn_attr.stVencAttr.u32VirHeight = 1080;
venc_chn_attr.stVencAttr.imageType = IMAGE_TYPE_NV12;
venc_chn_attr.stVencAttr.enType = RK_CODEC_TYPE_H264;
venc_chn_attr.stVencAttr.u32Profile = 66;
venc_chn_attr.stRcAttr.enRcMode = VENC_RC_MODE_H264CBR;
venc_chn_attr.stRcAttr.stH264Cbr.u32Gop = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32BitRate = 1920 * 1080 * 3;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateNum = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateNum = 25;
ret = RK_MPI_VENC_CreateChn(VENC_CHN, &venc_chn_attr);
if (ret)
{
printf("ERROR: Create venc failed!\n");
exit(0);
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("RK_MPI_VI_StartStream Failed.....\n");
return 0;
}
else
{
printf("RK_MPI_VI_StartStream Success.....\n");
}
pthread_t pid;
pthread_create(&pid, NULL, rockx_face_detect_venc_thread, NULL);
rockx_config_t *face_detect_config = rockx_create_config();
rockx_add_config(face_detect_config, ROCKX_CONFIG_DATA_PATH, "/userdata/rockx_data");
rockx_handle_t face_detect_handle;
rockx_ret_t face_detect_ret;
rockx_module_t face_detect_module = ROCKX_MODULE_FACE_DETECTION_V2;
face_detect_ret = rockx_create(&face_detect_handle, face_detect_module, face_detect_config, 0);
if (face_detect_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_create face_detect failed...\n");
return -1;
}
rockx_image_t rv1126_rockx_image;
rv1126_rockx_image.width = WIDTH;
rv1126_rockx_image.height = HEIGHT;
rv1126_rockx_image.pixel_format = ROCKX_PIXEL_FORMAT_YUV420SP_NV12;
MEDIA_BUFFER mb;
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);
if (!mb)
{
printf("Get Vi Stream break....\n");
break;
}
rv1126_rockx_image.data = (uint8_t *)RK_MPI_MB_GetPtr(mb);
rv1126_rockx_image.size = RK_MPI_MB_GetSize(mb);
Mat rv1126_image_mat = Mat(HEIGHT, WIDTH, CV_8UC1, rv1126_rockx_image.data);
rockx_object_array_t face_detect_array;
face_detect_ret = rockx_face_detect(face_detect_handle, &rv1126_rockx_image, &face_detect_array, NULL);
if (face_detect_ret != ROCKX_RET_SUCCESS)
{
printf("face_detect failed....\n");
}
for (int i = 0; i < face_detect_array.count; i++)
{
int left = face_detect_array.object[i].box.left;
int top = face_detect_array.object[i].box.top;
int w = face_detect_array.object[i].box.right - face_detect_array.object[i].box.left;
int h = face_detect_array.object[i].box.bottom - face_detect_array.object[i].box.top;
Rect boundingRect(left, top, w, h);
rectangle(rv1126_image_mat, boundingRect, Scalar(255, 255, 0));
}
RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);
RK_MPI_MB_ReleaseBuffer(mb);
}
RK_MPI_VENC_DestroyChn(VENC_CHN);
RK_MPI_VI_DisableChn(CAMERA_ID, CAMERA_CHN);
return 0;
}
运行报错。
模型问题,rockx_data里的模型不对。
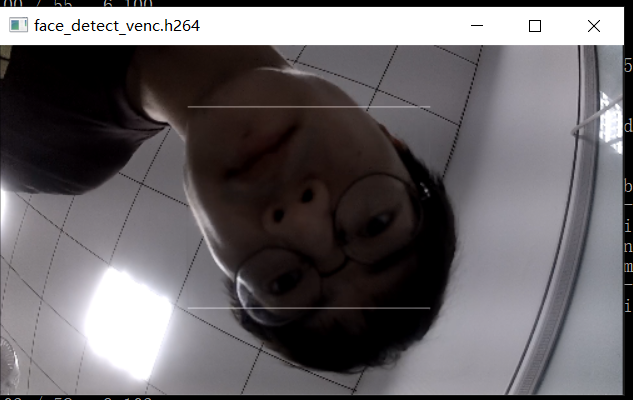
2.5ROCKX+RV1126检测人脸并进行拍照
- Rockx+Rv1126检测人脸并进行拍照大体框图
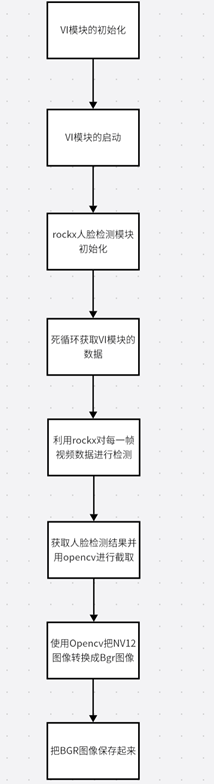
上图是rockx+rv1126人脸检测拍照的大体流程,这个功能只需要用一个主线程就可以完成,首先要初始化VI模块、ROCKX模块并启动VI模块采集摄像头数据。
初始化完成之后,则开始获取每一帧的VI码流数据,并且用rockx框架对每一帧视频数据进行人脸检测,若检测出人脸则用Opencv对人脸图像进行截取,并用opencv的API把NV12图像转换为BGR图像,最后把转换后的BGR图像保存起来。
二.Rockx+Rv1126检测人脸并进行拍照的代码截图
2.1. RV1126模块初始化并启动VI工作
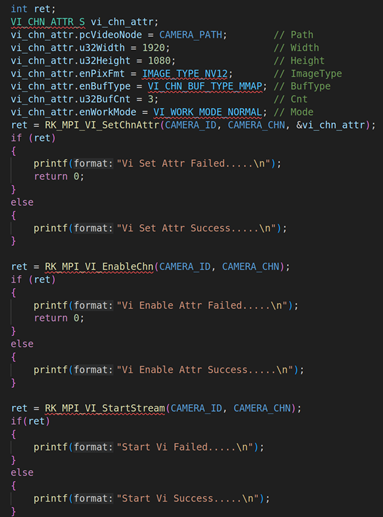
上图是RV1126模块的初始化,拍照功能只需要初始化VI模块,并调用RK_MPI_VI_StartStream启动VI开始采集摄像头的视频流。关于VI模块的初始化不介绍了,因为之前的课程里面已经讲了很多次。
2.2. rockx人脸检测模块的初始化
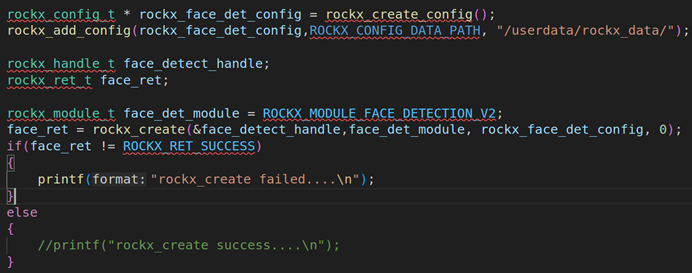
这段代码是初始化rockx的模块,首先要使用rockx_create_config分配rockx_config_t结构体,并使用rockx_add_config把对应的rockx路径配置进去,在我们的板子里面在/userdata/rockx_data里面,并使用rockx_create创建rockx_handle_t句柄,rockx_create的传参第一个参数rockx_handle_t结构体指针、 第二个参数rockx_module_t是ROCKX_MODULE_FACE_DETECTION_V2,ROCKX_MODULE_FACE_DETECTION_V2是人脸检测的Version2模块、第三个参数是rockx_config_t结构体指针、第四个参数默认是0。
2.3. 使用rockx对VI模块的数据进行人脸检测处理

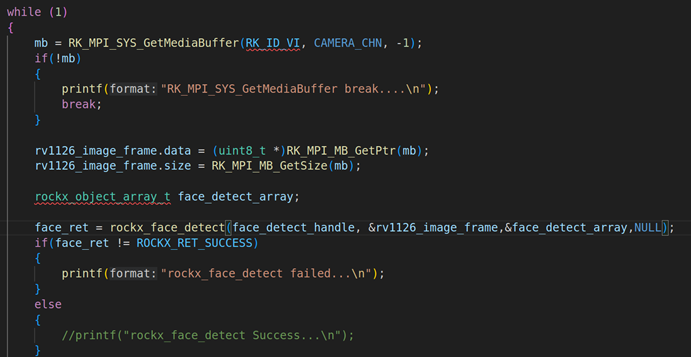
这部分代码是整个DEMO的核心,也是ROCKX检测VI视频数据的核心。图2.3.1是初始化rockx_image_t结构体,初始化需要传三个值分别是width = WIDTH(1920)、height = HEIGHT(1080)、pixel_format=ROCKX_PIXEL_FORMAT_YUV420SP_NV12。这三个值都需要和VI模块的配置是一样的。
初始化rockx_image_t后,则需要通过RK_MPI_SYS_GetMediaBuffer获取每一帧VI模块的数据,并把每一帧VI模块的缓冲区和长度传输给rockx_image_t。具体的代码是rv1126_rockx_image.data = (uint8_t *)RK_MPI_MB_GetPtr(mb)(把每一帧VI缓冲区数据赋值到rockx_image_t的data)、rv1126_rockx_image.size = RK_MPI_MB_GetSize(mb)(把每一帧VI大小赋值到rockx_image_t的size)
赋值到rockx_image_t后,则调用rockx_face_detect对每一帧的rockx_image_t图像进行人脸检测,并把人脸检测的结果输出到rockx_object_array_t。rockx_object_array_t的内容主要存储的是人脸检测数量和人脸检测区域信息(如:left、top、right、bottom的坐标信息)
2.4. 使用OPENCV对人脸检测的图像进行截取
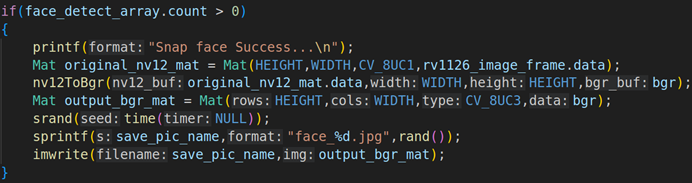

检测人脸后并判断人脸数量是否大于0,若大于0则说明有人脸。然后就用opencv对人脸检测后的图像进行截取,这里使用的是Mat矩阵直接截取(具体的是Mat original_nv12_mat = Mat(HEIGHT,WIDTH,CV_8UC1,rv1126_image_frame.data)),截取之后则需要把NV12的图像转换为BGR图像。具体的实现在图2,这里的核心在于如何使用opencv的cvtColor把NV12矩阵转换为BGR矩阵。
NV12的Mat矩阵的rows长度是height + height /2等于height * 3 /2,cols的长度是width,通道数是单通道(CV_8UC1)。BGR的Mat矩阵rows是height、 cols是width,通道数是三通道(CV_8UC3),然后调用cvtColor把NV12的Mat矩阵转换为BGR的Mat。
2.5. 保存转换后的bgr图像

上图就是保存图片bgr图片的代码,保存的时候需要用随机数来命名,具体的实现就是srand(time(NULL)),并且把保存的图片名称定义为face_%d.jpg也就是face_rand().jpg的图片(如:face_306072035.jpg、face_306072040.jpg等),最后用imwrite来保存截取后的图片
最后运行的效果:
上图是通过人脸检测并且保存的图片。
rockx_face_opencv_snap文件弄到linux编程
/****************************************************************************
*
* Copyright (c) 2017 - 2019 by Rockchip Corp. All rights reserved.
*
* The material in this file is confidential and contains trade secrets
* of Rockchip Corporation. This is proprietary information owned by
* Rockchip Corporation. No part of this work may be disclosed,
* reproduced, copied, transmitted, or used in any way for any purpose,
* without the express written permission of Rockchip Corporation.
*
*****************************************************************************/
#include <assert.h>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/core/hal/interface.h>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgproc/imgproc_c.h>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include "rockx.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
using namespace cv;
void nv12ToBgr(uint8_t * nv12_buf, int width, int height, uint8_t * bgr_buf)
{
Mat nv12_mat(height + height/2, width, CV_8UC1, nv12_buf);
Mat bgr_mat(height, width, CV_8UC3, bgr_buf);
cvtColor(nv12_mat,bgr_mat,COLOR_YUV2BGR_NV12);
}
int main(int argc, char **argv)
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = 1920; // Width
vi_chn_attr.u32Height = 1080; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if(ret)
{
printf("Start Vi Failed.....\n");
}
else
{
printf("Start Vi Success.....\n");
}
rockx_config_t * rockx_face_det_config = rockx_create_config();
rockx_add_config(rockx_face_det_config,ROCKX_CONFIG_DATA_PATH, "/userdata/rockx_data/");
rockx_handle_t face_detect_handle;
rockx_ret_t face_ret;
rockx_module_t face_det_module = ROCKX_MODULE_FACE_DETECTION_V2;
face_ret = rockx_create(&face_detect_handle,face_det_module, rockx_face_det_config, 0);
if(face_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_create failed....\n");
}
else
{
//printf("rockx_create success....\n");
}
rockx_image_t rv1126_image_frame;
rv1126_image_frame.width = WIDTH;
rv1126_image_frame.height = HEIGHT;
rv1126_image_frame.pixel_format = ROCKX_PIXEL_FORMAT_YUV420SP_NV12;
MEDIA_BUFFER mb;
uint8_t *bgr = new uint8_t[WIDTH * HEIGHT *3];
char save_pic_name[50];
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);
if(!mb)
{
printf("RK_MPI_SYS_GetMediaBuffer break....\n");
break;
}
rv1126_image_frame.data = (uint8_t *)RK_MPI_MB_GetPtr(mb);
rv1126_image_frame.size = RK_MPI_MB_GetSize(mb);
rockx_object_array_t face_detect_array;
face_ret = rockx_face_detect(face_detect_handle, &rv1126_image_frame,&face_detect_array,NULL);
if(face_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_face_detect failed...\n");
}
else
{
//printf("rockx_face_detect Success...\n");
}
if(face_detect_array.count > 0)
{
printf("Snap face Success...\n");
Mat original_nv12_mat = Mat(HEIGHT,WIDTH,CV_8UC1,rv1126_image_frame.data);
nv12ToBgr(original_nv12_mat.data,WIDTH,HEIGHT,bgr);
Mat output_bgr_mat = Mat(HEIGHT,WIDTH,CV_8UC3,bgr);
srand(time(NULL));
sprintf(save_pic_name,"face_%d.jpg",rand());
imwrite(save_pic_name,output_bgr_mat);
}
RK_MPI_MB_ReleaseBuffer(mb);
}
return 0;
}


2.6ROCKX+RV1126实现1->N人脸识别功能
一.Rockx+Rv1126实现1->N人脸识别功能大体流程
一个闸机,提前读取人脸数据,保存在数据库里,一张数据库里的图片对应多张人脸时,只有一张人脸可以对上,1>n是指n张脸出现时,只有一张可以对上。
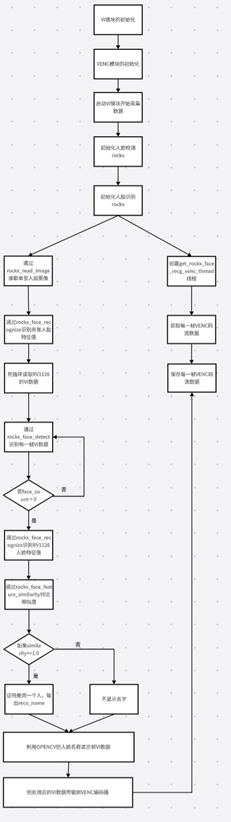
上图是实现1->N人脸识别流程,首先要初始化RV1126模块初始化,包括VI模块、VENC模块、人脸检测rockx模块、人脸识别rockx模块,初始化模块之后,就要分两个线程做处理。
主流程是先读取单张图片的图像并提取人脸特征值,然后死循环获取VI的码流数据,然后用rockx的人脸检测模块RV1126的VI数据是否有人脸,如果有人脸则调用rockx的人脸识别模块识别出RV1126视频流的人脸数据并且提取出来人脸特征值。然后对比两个人脸的阈值,如果<=1.0,则认定单张人脸图片和RV1126检测的人脸是同一个,输出人名数据,否则就不是同一个人,并把数据通过Opencv显示到VI数据,最后把识别后的VI数据传输到VENC编码器里面
get_rockx_face_recg_venc_thread线程主要是获取每一帧的VENC码流数据,并且保存起来。
- Rockx+Rv1126实现1->N人脸识别功能代码截图
2.1. RV1126模块的初始化并启动VI工作
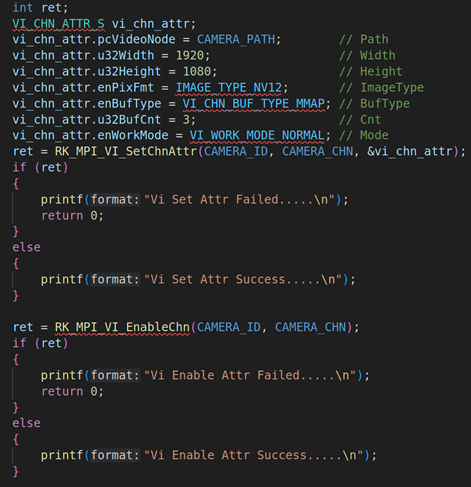
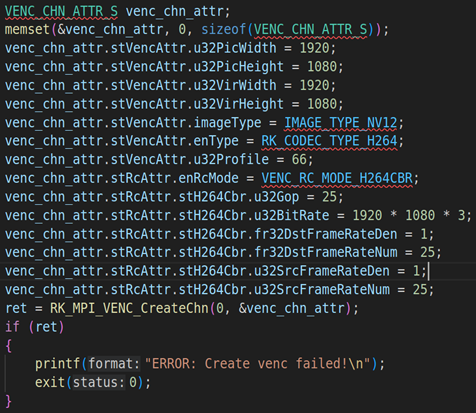
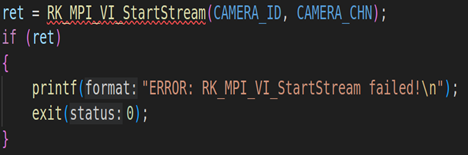
上图是RV1126模块的初始化,这里需要初始化RV1126的VI模块、VENC模块、并调用RK_MPI_VI_StartStream启动VI模块采集摄像头数据。具体的API不讲解了,因为之前已经讲了很多次。
2.1. 初始化人脸检测和人脸识别的rockx模块
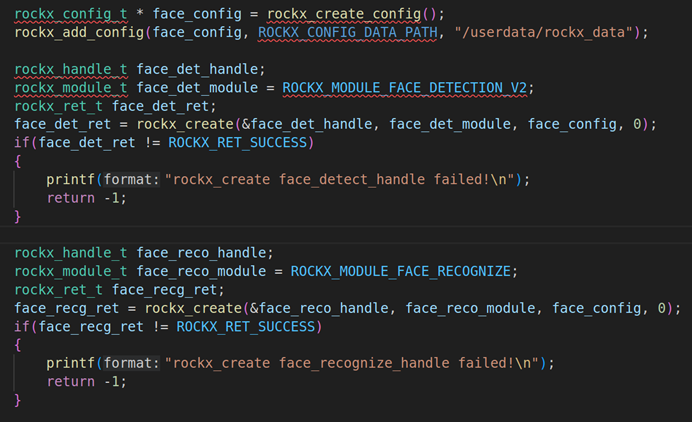
上图是rockx模块的初始化,这里我们要初始化两个rockx模块,分别是人脸检测rockx模块和人脸识别rockx模块。首先要使用rockx_create_config分配rockx_config_t结构体,并使用rockx_add_config把对应的rockx路径配置进去,在我们的板子里面在/userdata/rockx_data里面。
使用rockx_create创建人脸检测rockx_handle_t句柄。rockx_create的传参第一个参数rockx_handle_t结构体指针、 第二个参数rockx_module_t是ROCKX_MODULE_FACE_DETECTION_V2,ROCKX_MODULE_FACE_DETECTION_V2是人脸检测的Version2模块、第三个参数是rockx_config_t结构体指针、第四个参数默认是0。
使用rockx_create创建人脸识别rockx_handle_t句柄。rockx_create的传参第一个参数rockx_handle_t结构体指针、 第二个参数rockx_module_t是ROCKX_MODULE_FACE_RECOGNIZE,ROCKX_MODULE_FACE_RECOGNIZE是人脸识别模块、第三个参数是rockx_config_t结构体指针、第四个参数默认是0。
2.2. 读取单张人脸的图像并提取特征值

用rockx_image_read读取单张人脸图像,face_02.jpg这张图片是我上节课拍照的图片,并且用rockx_face_recognize提取单张图片的人脸特征值,第一个参数传值:人脸识别的句柄(face_reco_handle),第二个参数传值:单张人脸的rockx_image_t数据地址(&single_face_image),第三个参数传值:获取单张人脸的人脸特征(&single_face_feature)。
2.3. 获取每一帧VI视频数据并提取VI数据的人脸特征值

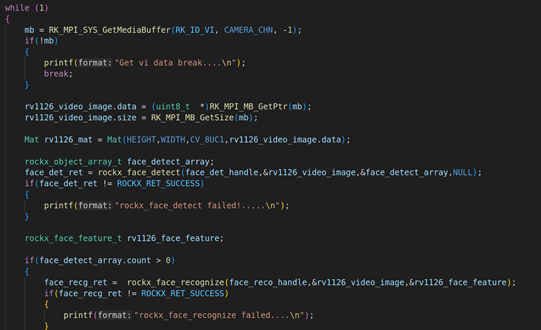
首先初始化rockx_image_t结构体,包括
width(WIDTH=1920),height(HEIGHT=1080),pixel_format(ROCKX_PIXEL_FORMAT_YUV420SP_NV12)。使用RK_MPI_SYS_GetMediaBuffer获取每一帧VI数据,并且把每一帧VI数据赋值到rockx_image_t,这里关键要赋值的是data(data =(uint8_t *)RK_MPI_MB_GetPtr(mb) )和size(size = RK_MPI_MB_GetSize(mb))。
赋值后,就调用rockx_face_detect对每一帧的视频数据进行人脸检测,如果rockx_object_array_t的count大于0(face_detect_array.count),则说明检测到人脸。若检测到人脸则调用rockx_face_recognize提取VI摄像头的人脸特征值,第一个参数传值:人脸识别的句柄(face_reco_handle),第二个参数传值:rv1126的图像数据地址(&rv1126_video_image),第三个参数传值:获取rv1126视频流的人脸特征(&rv1126_face_feature)
2.4. 对比单张图片的人脸特征值和VI数据的人脸特征值
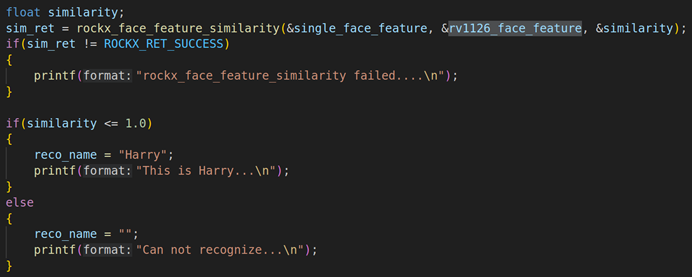
提取完单张图片特征值和RV1126视频流的人脸特征值后就要对比两个特征值的相似度了,在rockx框架提供了rockx_face_feature_similarity去对比两个脸特征值。第一个参数传值:单张人脸的特征结构体指针(&single_face_feature), 第二个参数:rv1126视频流人脸特征结构体指针(&rv1126_face_feature),第三个参数:两个人脸对比输出的相似度阈值similarity(&similarity)。
如果输出的人脸相似度值<=1.0(1.0是rockx比较经典的人脸识别阈值, 值越小相似度越高),则说明单张人脸和视频流的人脸是同一个人,然后把”Harry”输出到string , 否则就不输出。
2.5. 把识别的人脸名称输出到opencv的Text
![]()
![]()
上述步骤已经得到了对比的人脸名称,这一步则需要把人脸的名称输出到OPENCV里面,并显示到视频上。首先要创建OPENCV的矩阵Mat rv1126_mat = Mat(HEIGHT,WIDTH,CV_8UC1,rv1126_video_image.data),第一个参数:HEIGHT(1080),第二个参数HEIGHT(1920),第三个参数:CV_8UC1(单通道), 第四个参数:rv1126_video_image.data(每一帧的rv1126的VI数据).
创建完矩阵后,则需要调用OPENCV的putText把人脸名称输出到Mat矩阵里面。具体的如下:putText(rv1126_mat,reco_name,text_point,FONT_HERSHEY_COMPLEX,1.0,Scalar(255,0,255),1),第一个参数:rv1126_mat(Mat矩阵数据),第二个参数:reco_name(人脸名称的string字符串),第三个参数:text_point(坐标信息,x轴=300,y轴-300),第四个参数:FONT_HERSHEY_COMPLEX(字体类型),第五个参数:1.0(字体大小是1.0),第六个参数:Scalar(255,0,255)(颜色标量),第七个参数:1(粗细程度是1)
2.6. 把处理后的数据传输到VENC编码器
![]()
上述识别工作完成之后,就需要把VI数据传输到VENC编码器里面。这里直接调用RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb)去发送。
2.7.开启get_rockx_face_recg_venc_thread线程获取每一帧VENC数据并且保存到H264

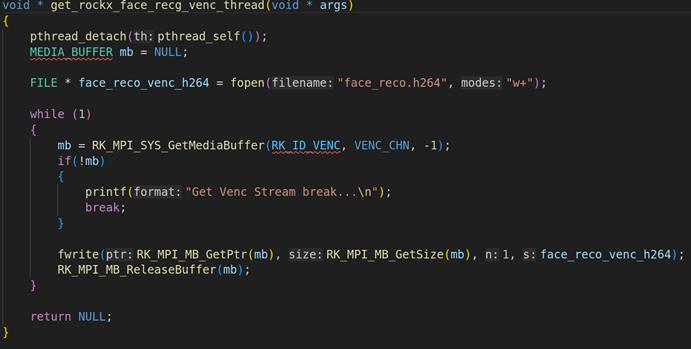
上图是创建一个get_rockx_face_recg_venc_thread线程,在这个线程里面通过RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1)获取每一帧VENC码流,并且用fwrite写到face_reco.h264文件里面。
最终的运行效果:
上图就是程序运行的效果,在这个H264里面,可以识别到我的人脸名称,并且显示出来。
rockx_face_recognize_demo文件
/****************************************************************************
*
* Copyright (c) 2017 - 2019 by Rockchip Corp. All rights reserved.
*
* The material in this file is confidential and contains trade secrets
* of Rockchip Corporation. This is proprietary information owned by
* Rockchip Corporation. No part of this work may be disclosed,
* reproduced, copied, transmitted, or used in any way for any purpose,
* without the express written permission of Rockchip Corporation.
*
*****************************************************************************/
#include <assert.h>
#include <fcntl.h>
#include <getopt.h>
#include <opencv2/core/hal/interface.h>
#include <opencv2/imgproc.hpp>
#include <opencv2/imgproc/imgproc_c.h>
#include <pthread.h>
#include <signal.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
#include <string>
// #include "common/sample_common.h"
#include "rkmedia_api.h"
#include "rockx.h"
#include <opencv2/core.hpp>
// #include <opencv2/imgoroc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/opencv.hpp>
#define CAMERA_PATH "rkispp_scale0"
#define CAMERA_ID 0
#define CAMERA_CHN 0
#define VENC_CHN 0
#define WIDTH 1920
#define HEIGHT 1080
using namespace std;
using namespace cv;
string reco_name;
void * get_rockx_face_recg_venc_thread(void * args)
{
pthread_detach(pthread_self());
MEDIA_BUFFER mb = NULL;
FILE * face_reco_venc_h264 = fopen("face_reco.h264", "w+");
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VENC, VENC_CHN, -1);
if(!mb)
{
printf("Get Venc Stream break...\n");
break;
}
fwrite(RK_MPI_MB_GetPtr(mb), RK_MPI_MB_GetSize(mb), 1, face_reco_venc_h264);
RK_MPI_MB_ReleaseBuffer(mb);
}
return NULL;
}
int main(int argc, char **argv)
{
int ret;
VI_CHN_ATTR_S vi_chn_attr;
vi_chn_attr.pcVideoNode = CAMERA_PATH; // Path
vi_chn_attr.u32Width = 1920; // Width
vi_chn_attr.u32Height = 1080; // Height
vi_chn_attr.enPixFmt = IMAGE_TYPE_NV12; // ImageType
vi_chn_attr.enBufType = VI_CHN_BUF_TYPE_MMAP; // BufType
vi_chn_attr.u32BufCnt = 3; // Cnt
vi_chn_attr.enWorkMode = VI_WORK_MODE_NORMAL; // Mode
ret = RK_MPI_VI_SetChnAttr(CAMERA_ID, CAMERA_CHN, &vi_chn_attr);
if (ret)
{
printf("Vi Set Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Set Attr Success.....\n");
}
ret = RK_MPI_VI_EnableChn(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("Vi Enable Attr Failed.....\n");
return 0;
}
else
{
printf("Vi Enable Attr Success.....\n");
}
VENC_CHN_ATTR_S venc_chn_attr;
memset(&venc_chn_attr, 0, sizeof(VENC_CHN_ATTR_S));
venc_chn_attr.stVencAttr.u32PicWidth = 1920;
venc_chn_attr.stVencAttr.u32PicHeight = 1080;
venc_chn_attr.stVencAttr.u32VirWidth = 1920;
venc_chn_attr.stVencAttr.u32VirHeight = 1080;
venc_chn_attr.stVencAttr.imageType = IMAGE_TYPE_NV12;
venc_chn_attr.stVencAttr.enType = RK_CODEC_TYPE_H264;
venc_chn_attr.stVencAttr.u32Profile = 66;
venc_chn_attr.stRcAttr.enRcMode = VENC_RC_MODE_H264CBR;
venc_chn_attr.stRcAttr.stH264Cbr.u32Gop = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32BitRate = 1920 * 1080 * 3;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.fr32DstFrameRateNum = 25;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateDen = 1;
venc_chn_attr.stRcAttr.stH264Cbr.u32SrcFrameRateNum = 25;
ret = RK_MPI_VENC_CreateChn(0, &venc_chn_attr);
if (ret)
{
printf("ERROR: Create venc failed!\n");
exit(0);
}
ret = RK_MPI_VI_StartStream(CAMERA_ID, CAMERA_CHN);
if (ret)
{
printf("ERROR: RK_MPI_VI_StartStream failed!\n");
exit(0);
}
rockx_config_t * face_config = rockx_create_config();
rockx_add_config(face_config, ROCKX_CONFIG_DATA_PATH, "/userdata/rockx_data");
rockx_handle_t face_det_handle;
rockx_module_t face_det_module = ROCKX_MODULE_FACE_DETECTION_V2;
rockx_ret_t face_det_ret;
face_det_ret = rockx_create(&face_det_handle, face_det_module, face_config, 0);
if(face_det_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_create face_detect_handle failed!\n");
return -1;
}
rockx_handle_t face_reco_handle;
rockx_module_t face_reco_module = ROCKX_MODULE_FACE_RECOGNIZE;
rockx_ret_t face_recg_ret;
face_recg_ret = rockx_create(&face_reco_handle, face_reco_module, face_config, 0);
if(face_recg_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_create face_recognize_handle failed!\n");
return -1;
}
char * image_path = "face_02.jpg";
rockx_image_t single_face_image;
rockx_image_read(image_path, &single_face_image, 1);
rockx_face_feature_t single_face_feature;
rockx_face_recognize(face_reco_handle, &single_face_image,&single_face_feature);
pthread_t pid;
pthread_create(&pid, NULL, get_rockx_face_recg_venc_thread, NULL);
MEDIA_BUFFER mb = NULL;
rockx_image_t rv1126_video_image;
rv1126_video_image.width = WIDTH;
rv1126_video_image.height = HEIGHT;
rv1126_video_image.pixel_format = ROCKX_PIXEL_FORMAT_YUV420SP_NV12;
rockx_ret_t sim_ret;
Point text_point;
text_point.x = 300;
text_point.y = 300;
while (1)
{
mb = RK_MPI_SYS_GetMediaBuffer(RK_ID_VI, CAMERA_CHN, -1);
if(!mb)
{
printf("Get vi data break....\n");
break;
}
rv1126_video_image.data = (uint8_t *)RK_MPI_MB_GetPtr(mb);
rv1126_video_image.size = RK_MPI_MB_GetSize(mb);
Mat rv1126_mat = Mat(HEIGHT,WIDTH,CV_8UC1,rv1126_video_image.data);
rockx_object_array_t face_detect_array;
face_det_ret = rockx_face_detect(face_det_handle,&rv1126_video_image,&face_detect_array,NULL);
if(face_det_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_face_detect failed!.....\n");
}
rockx_face_feature_t rv1126_face_feature;
if(face_detect_array.count > 0)
{
face_recg_ret = rockx_face_recognize(face_reco_handle,&rv1126_video_image,&rv1126_face_feature);
if(face_recg_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_face_recognize failed....\n");
}
float similarity;
sim_ret = rockx_face_feature_similarity(&single_face_feature, &rv1126_face_feature, &similarity);
if(sim_ret != ROCKX_RET_SUCCESS)
{
printf("rockx_face_feature_similarity failed....\n");
}
if(similarity <= 1.0)
{
reco_name = "Harry";
printf("This is Harry...\n");
}
else
{
reco_name = "";
printf("Can not recognize...\n");
}
putText(rv1126_mat,reco_name,text_point,FONT_HERSHEY_COMPLEX,1.0,Scalar(255,0,255),1);
}
RK_MPI_SYS_SendMediaBuffer(RK_ID_VENC, VENC_CHN, mb);
RK_MPI_MB_ReleaseBuffer(mb);
}
RK_MPI_VI_DisableChn(CAMERA_ID,CAMERA_CHN);
RK_MPI_VENC_DestroyChn(VENC_CHN);
return 0;
}
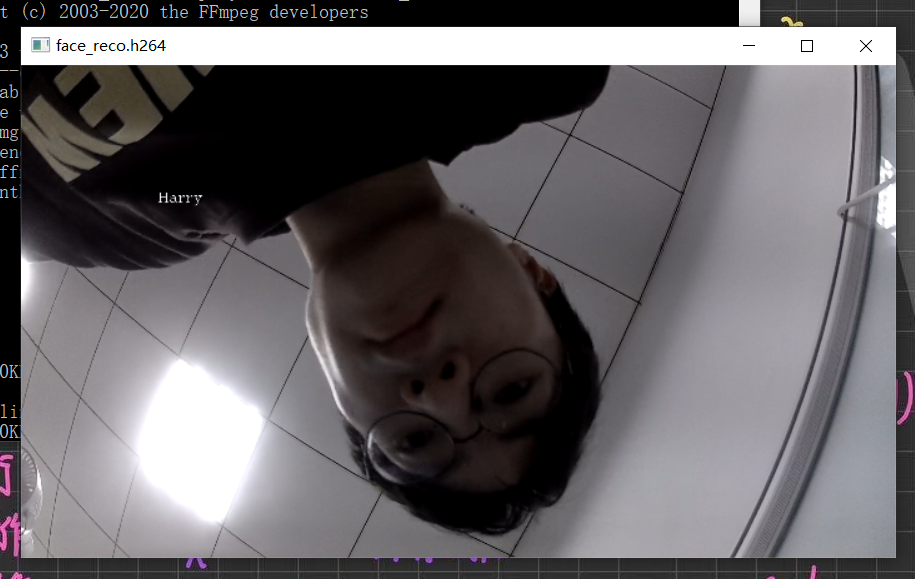

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)