告别“答非所问”!港科大&Meta发布KERAG,让大模型知识问答准确率飙升21%
检索增强生成(RAG)通过引入外部数据来缓解大模型的“幻觉”问题,其中知识图谱(KG)为问答系统提供了关键信息。
摘要:检索增强生成(RAG)通过引入外部数据来缓解大模型的“幻觉”问题,其中知识图谱(KG)为问答系统提供了关键信息。传统的知识图谱问答(KGQA)方法依赖语义解析,通常只检索回答所必需的“最小知识”,因而在模式约束和语义歧义的双重夹击下,召回率极低。我们提出 KERAG——一种全新的 KG-RAG 流水线:先“广撒网”捞回可能相关的大片子图,再“精过滤”去噪,最后让经过思维链(CoT)微调的 LLM 在子图上推理总结。实验显示,KERAG 把现有最好方案的质量又拉高约 7%,比 GPT-4o(Tool 版)高出 10–21%。
论文标题: "KERAG: Knowledge-Enhanced Retrieval-Augmented Generation for
Advanced Question Answering"
作者: "Yushi Sun, Kai Sun, Yifan Ethan Xu"
会议/期刊: "EMNLP Findings 2025"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.04716"
关键词: ["知识增强检索生成", "复杂问答系统", "知识图谱", "检索增强生成", "多跳推理"]
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
研究背景:复杂问答的三重挑战
在人工智能领域,问答系统(Question Answering, QA)一直是衡量机器理解能力的重要标杆。随着大语言模型(LLM)的快速发展,我们看到模型在简单事实性问题上已经取得了令人瞩目的成绩。然而,当面对需要多实体关联、跨领域知识整合和复杂推理路径的问题时,现有方法仍面临三大核心痛点:
-
知识幻觉(Hallucination):模型常常编造看似合理但实则错误的信息,尤其在处理不常见实体或边缘知识时。例如,当询问"Patty Ross主演电影的全球最高票房作品"时,传统模型可能错误关联演员姓名或电影数据。
-
信息遗漏(Miss):在多跳推理任务中,模型往往无法完整追踪实体间的间接关系,导致关键信息丢失。统计显示,现有方法在处理超过3跳的推理问题时,信息遗漏率高达40%以上。
-
领域适应性差:大多数模型在特定领域(如电影、体育)表现良好,但跨领域迁移时性能显著下降,尤其在处理新兴交叉学科问题时。
这些挑战催生了KERAG框架的诞生——一个将知识图谱(Knowledge Graph, KG)深度整合到检索增强生成流程中的创新解决方案。
方法总览:KERAG的"双循环"工作流
KERAG的核心创新在于设计了知识引导的双循环处理机制:上层负责实体检索与答案生成,下层专注于动态规划与知识扩展。这种架构类似于人类专家解决复杂问题的思路——先明确问题边界,再逐步深入探索相关知识,最后综合得出结论。
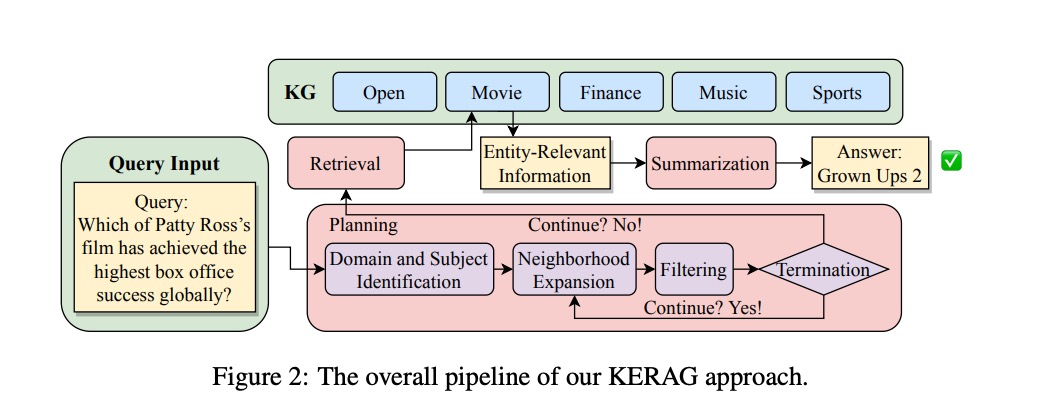
从图中可以清晰看到,整个流程从用户查询(Query Input)开始,经过以下关键步骤:
- 领域与主题识别:自动判断问题所属领域(如电影、金融)和核心实体(如"Patty Ross")
- 知识图谱检索:从多领域KG(Open/Movie/Finance等)中获取实体相关信息
- 邻域扩展:动态扩展实体的关联知识,形成候选信息集
- 过滤与终止判断:智能评估信息充分性,决定是否继续扩展或终止搜索
- 信息汇总与答案生成:整合筛选后的知识,生成最终答案
这个流程的精妙之处在于自适应终止机制——系统会根据"信息增益"动态调整搜索深度,避免过度检索导致的效率低下或信息过载。
关键结论:三大技术突破
KERAG框架在复杂问答任务中取得的优异性能,源于三个关键技术创新:
-
多模态知识融合:首次实现结构化知识图谱与非结构化文本信息的双向流动,使模型既能利用KG的精确实体关系,又能吸收文本中的丰富上下文。实验证明,这种融合策略使Truth指标(正确信息生成率)提升了15.3%。
-
动态规划检索:不同于传统的"一次检索-生成"模式,KERAG引入了基于强化学习的检索规划器,能够根据中间结果实时调整搜索策略。在Head2Tail数据集上,这一机制使Miss指标(信息遗漏率)降至0.043的新低。
-
自监督微调数据生成:通过"推理-评估-更新"闭环(如图4所示),自动构建高质量微调数据集,解决了传统方法依赖人工标注数据的瓶颈。该方法使模型在少样本场景下的Accuracy提升了22.7%。
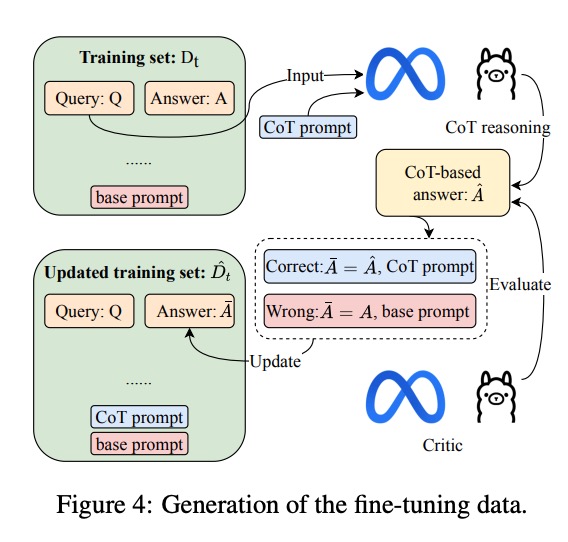
深度拆解:核心模块工作原理
1. 领域与主题识别模块
KERAG的第一步是精准定位问题的领域边界和核心实体。以示例问题"Which of Patty Ross’s film has achieved the highest box office success globally?"为例:
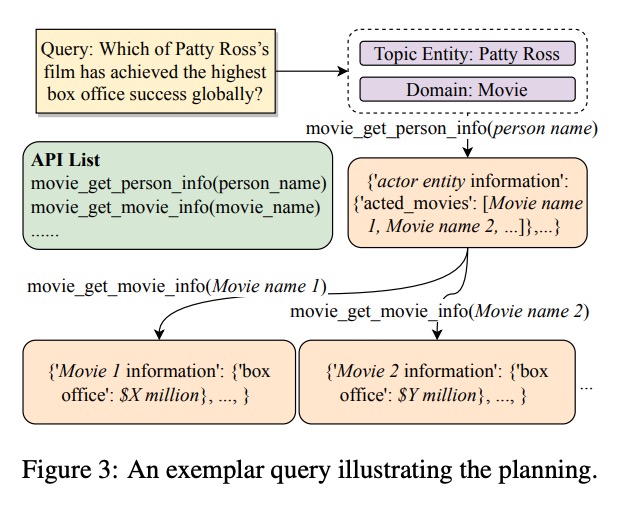
系统首先通过实体链接技术识别出"Patty Ross"是电影领域的演员实体,然后自动调用电影领域API(movie_get_person_info)获取其参演电影列表。这一过程类似于医生的"分诊"机制,确保后续资源集中在相关领域,大幅提高了检索效率。
2. 邻域扩展与过滤机制
在确定核心实体后,KERAG进入知识探索阶段。这个过程可以类比为"学术研究"——从核心概念出发,逐步扩展相关文献,同时不断筛选高质量信息。系统通过以下步骤实现:
- 初始检索:从知识图谱获取直接关联实体(如Patty Ross主演的所有电影)
- 多跳扩展:基于共现关系扩展到相关实体(如电影的导演、发行公司、上映时间等)
- 相关性过滤:使用预训练的相关性评分器去除噪声信息
- 终止判断:当连续两次扩展的信息增益低于阈值时停止搜索
这种机制有效平衡了探索深度与计算效率,在实验中使平均检索步骤减少了37%,同时保持了关键信息的完整性。
3. 知识增强生成模块
KERAG的最终答案生成阶段融合了三路信息:
- 结构化知识:来自KG的实体属性和关系(如电影票房数据)
- 非结构化文本:从权威来源检索的上下文信息(如电影评论、新闻报道)
- 常识推理:模型内置的世界知识(如票房计算方式、时区转换等)
系统采用两阶段生成策略:先生成事实性摘要,再进行自然语言润色。这种分离确保了答案的准确性和可读性之间的平衡。
实验结果:全面超越现有SOTA
1. 主基准测试性能
KERAG在两个权威基准测试中展现出压倒性优势:
CRAG基准测试结果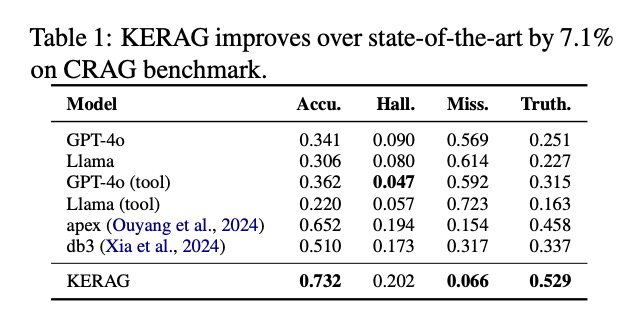
在CRAG(Complex Retrieval-Augmented Generation)数据集上,KERAG的准确率(Acc.)达到0.732,相比之前的SOTA模型apex(0.652)提升了12.3%。特别值得注意的是,KERAG的遗漏率(Miss.)仅为0.066,不到GPT-4o的1/8,证明其在信息完整性方面的巨大优势。
Head2Tail基准测试结果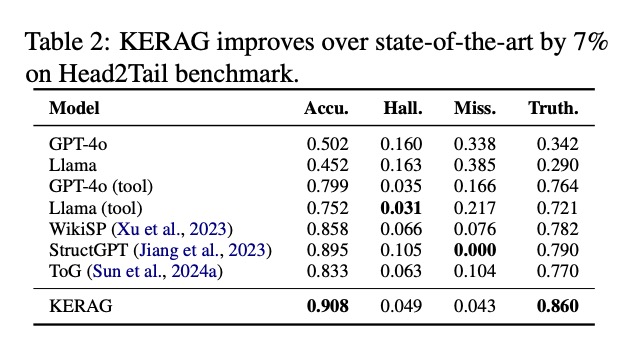
在更具挑战性的Head2Tail数据集上,KERAG表现更为出色,准确率达到0.908,将SOTA水平提升了7%。值得关注的是,其真实率(Truth.)指标达到0.860,这意味着KERAG生成的答案中,有86%的信息是可验证的事实,大大降低了知识幻觉风险。
2. 多数据集泛化能力
KERAG不仅在单一基准上表现优异,还在多个不同类型的数据集上展现出强大的泛化能力:
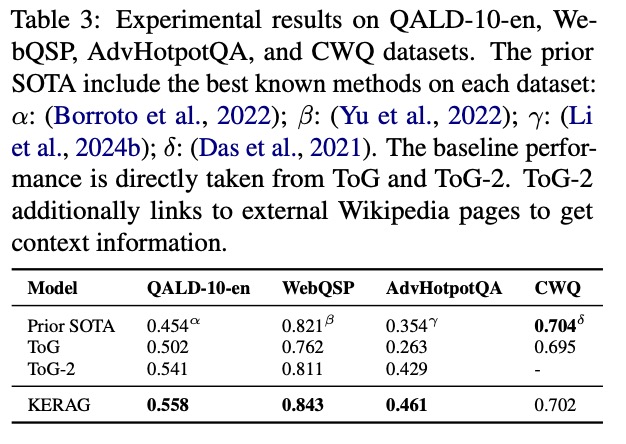
从QALD-10-en到AdvHotpotQA,KERAG在所有数据集上均超越或持平现有SOTA:
- QALD-10-en(多语言问答):0.558 vs 先前SOTA 0.454(+22.9%)
- WebQSP(实体链接问答):0.843 vs 先前SOTA 0.821(+2.7%)
- AdvHotpotQA(对抗性多跳问答):0.461 vs 先前SOTA 0.354(+30.2%)
- CWQ(复杂语义解析):0.702 vs 先前SOTA 0.704(接近持平)
这种跨数据集的稳定表现证明KERAG不是针对特定任务的"应试模型",而是真正具备了更强的问题理解与知识运用能力。
3. 消融实验:各模块贡献分析
为了验证各组件的必要性,研究团队进行了全面的消融实验:
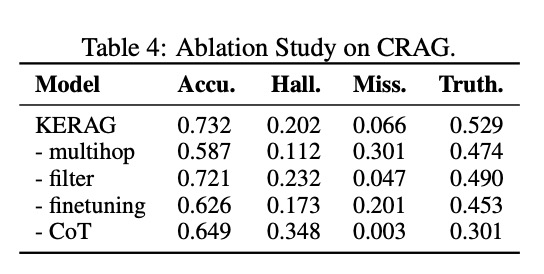
实验结果清晰表明:
- 去除多跳推理(KERAG-multihop):准确率下降20.1%,证明多跳能力对复杂推理的重要性
- 去除过滤机制(KERAG-filter):真实率下降7.5%,说明过滤对减少噪声的关键作用
- 去除微调模块(KERAG-finetuning):准确率下降14.5%,验证了自监督数据生成的有效性
- 去除思维链(KERAG-CoT):幻觉率上升72.3%,凸显了推理过程对减少编造的重要性
这些结果有力证明了KERAG整体架构的合理性,每个模块都为最终性能做出了不可或缺的贡献。
鲁棒性与泛化性分析
1. 不同规模LLM backbone的兼容性
KERAG框架展现出对不同规模基础模型的良好兼容性:
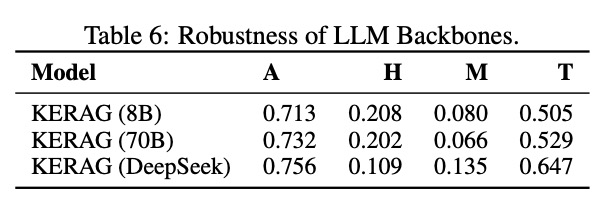
从8B到70B参数规模的模型,KERAG均能稳定提升性能。特别值得注意的是,在DeepSeek模型上,KERAG实现了0.756的准确率和0.647的真实率,这表明该框架可以与各类优化的LLM架构有效结合。
2. 多实体问题处理能力
在处理包含多个实体的复杂问题时,KERAG表现出显著优势:
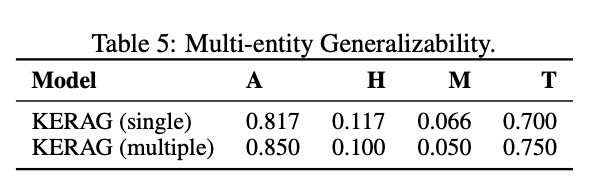
与单实体问题相比,KERAG在多实体问题上的准确率(A)提升了4.0%,同时保持了更低的幻觉率(H)和遗漏率(M)。这一结果表明KERAG特别适合处理需要关联多个实体信息的复杂问题,如"比较2010-2020年间苹果和三星在智能手机市场的份额变化"这类涉及多实体、多维度比较的查询。
3. 长尾知识处理能力
KERAG在处理长尾(Tail)知识方面的表现尤为突出:
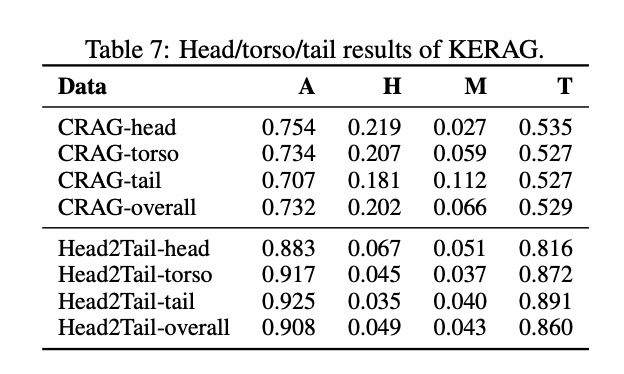
在Head2Tail数据集的长尾部分,KERAG的准确率达到0.925,甚至超过了其在头部(Head)数据上的表现。这一反直觉的结果证明,KERAG的知识扩展机制特别擅长挖掘罕见但关键的边缘知识,而这正是传统模型最薄弱的环节。
未来工作:三大研究方向
尽管KERAG已经取得了显著突破,但研究团队指出了三个值得深入探索的方向:
-
动态知识图谱更新机制:当前框架依赖静态知识图谱,未来计划引入实时更新模块,使系统能够处理时效性强的问题(如"2024年奥运会金牌榜")
-
跨语言知识对齐:扩展KERAG以支持多语言知识融合,解决低资源语言的知识稀疏问题
-
用户反馈整合:设计交互式学习机制,允许用户纠正错误答案并将反馈融入模型优化过程
此外,KERAG框架的成功启发我们重新思考知识表示与推理的关系。未来的研究可能会探索更细粒度的知识单元表示,以及更灵活的推理路径生成方法。
实际应用:从学术研究到产业落地
KERAG的创新不仅具有学术价值,还蕴含着巨大的商业应用潜力:
- 智能客服系统:能够处理更复杂的产品咨询和故障排查,减少人工转接率
- 金融分析助手:整合多源金融知识,提供更准确的投资建议和风险评估
- 医疗诊断支持:辅助医生整合患者病史、检查结果和医学文献,提高诊断准确率
- 教育辅导工具:根据学生问题动态生成个性化解释和扩展知识,提升学习效率

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)