AI编程:重塑软件开发范式的实践与探索
本文系统探讨了AI在编程领域的三大核心应用:自动化代码生成、低代码/无代码开发和算法优化。通过技术分析、代码实例和流程图解,展示了AI如何通过自然语言处理生成完整代码、简化应用开发流程,以及优化算法性能。文章指出,AI辅助编程并非替代开发者,而是将其从重复性工作中解放,专注于更高价值的创造性和架构设计任务。同时,文章也分析了当前面临的代码质量、技术债等挑战,并展望了AI结对编程、自我调试修复等未来
摘要
本文深入探讨了AI编程领域的三大核心支柱:自动化代码生成、低代码/无代码开发以及算法优化实践。通过详细的技术分析、代码实例、流程图解和Prompt示例,全面阐述了AI如何变革传统的软件开发流程,提升开发效率,降低技术门槛,并优化系统性能。文章旨在为开发者、技术决策者和爱好者提供一份全面的AI编程实践指南。
1. 引言:AI与软件开发的融合新时代
软件开发行业正经历一场由人工智能驱动的范式转移。传统的编码方式——开发者手动编写每一行代码——正在被一种更加智能、高效和可访问的新模式所补充甚至替代。这场变革的核心在于三大趋势:
-
自动化代码生成:利用AI模型(如大型语言模型LLMs)根据自然语言描述或部分代码片段,自动生成完整、可运行的程序代码。
-
低代码/无代码开发:通过图形化界面、拖拽组件和模型驱动逻辑,让非专业开发者也能构建应用程序,而AI在其中扮演了智能辅助和自动化的角色。
-
算法优化实践:AI不仅用于生成代码,还用于优化代码本身,从自动性能分析和调优,到设计更高效的算法和数据结构。
这并非要取代开发者,而是将开发者从重复性、机械性的劳动中解放出来,使其能更专注于架构设计、创造性解决问题和核心业务逻辑等更高价值的工作。下面,我们将深入这三大领域,并通过丰富的实例展示其强大能力。
2. 自动化代码生成
自动化代码生成是AI编程中最引人注目的领域。它主要依赖于在大量代码库上训练的大型语言模型(如OpenAI的Codex、GitHub Copilot、Amazon CodeWhisperer等)。这些模型能够理解开发者的意图,并生成相应的代码建议。
2.1 核心技术与原理
这类模型通常是基于Transformer架构的深度学习模型。它们通过分析海量的公开代码库(如GitHub上的项目)学习编程语言的语法、常见模式、API使用方式乃至最佳实践。其工作流程可以概括为以下步骤:
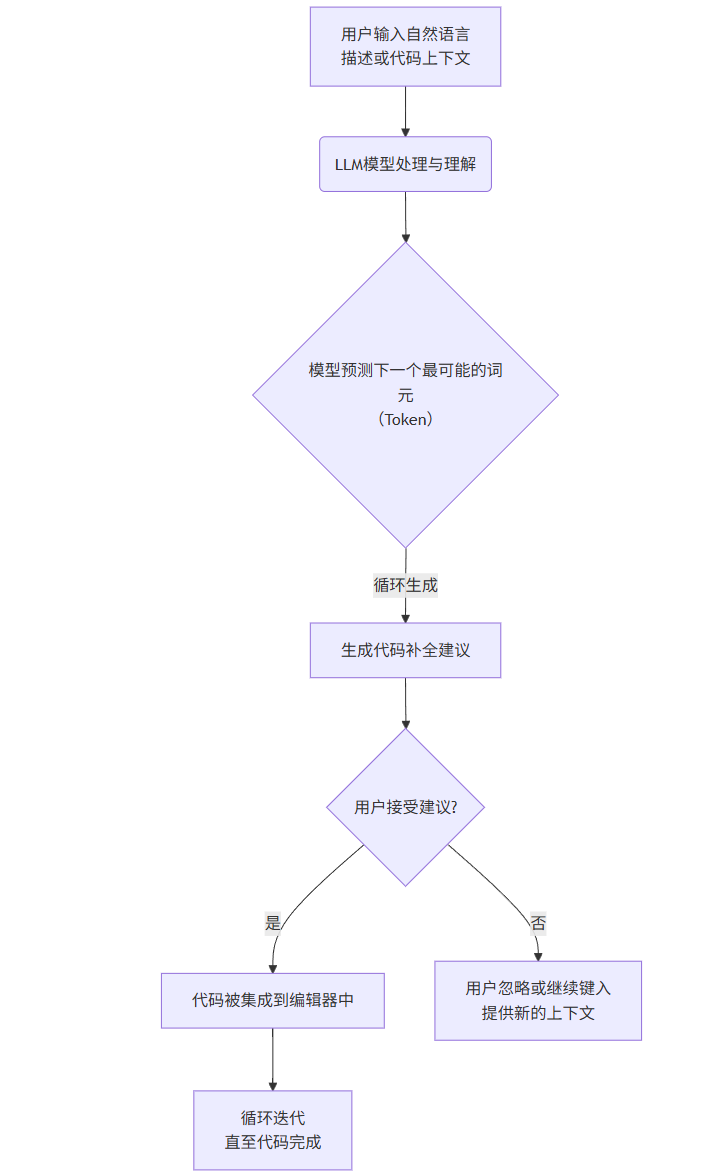
flowchart TD
A[用户输入自然语言<br>描述或代码上下文] --> B(LLM模型处理与理解)
B --> C{模型预测下一个最可能的词元<br>(Token)}
C -- 循环生成 --> D[生成代码补全建议]
D --> E{用户接受建议?}
E -- 是 --> F[代码被集成到编辑器中]
E -- 否 --> G[用户忽略或继续键入<br>提供新的上下文]
F --> H[循环迭代<br>直至代码完成]
2.2 实践示例:使用OpenAI API生成Python代码
以下是一个使用OpenAI的GPT模型生成数据可视化代码的示例。我们通过精心设计的Prompt来引导模型生成我们想要的代码。
Prompt示例:
python
""" 你是一位专业的Python数据分析师。请使用pandas和matplotlib库编写代码。 任务:读取一个名为'sales_data.csv'的CSV文件,该文件包含'Date'(日期)、'Product'(产品)和'Sales'(销售额)三列。 1. 将'Date'列转换为datetime类型。 2. 计算每个产品的总销售额。 3. 绘制一个饼图来展示不同产品的销售额占比,并为图表添加适当的标题和图例。 请确保代码完整、可直接运行。 """
生成的Python代码可能如下:
python
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取数据并转换日期类型
df = pd.read_csv('sales_data.csv')
df['Date'] = pd.to_datetime(df['Date'])
# 2. 按产品分组计算总销售额
sales_by_product = df.groupby('Product')['Sales'].sum()
# 3. 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(sales_by_product.values, labels=sales_by_product.index, autopct='%1.1f%%', startangle=140)
plt.title('Sales Distribution by Product')
plt.axis('equal') # 确保饼图是圆的
plt.legend(sales_by_product.index, title="Products", loc="center left", bbox_to_anchor=(1, 0, 0.5, 1))
plt.tight_layout()
plt.show()
代码解释与AI的作用:
-
库导入:AI根据常见的数据分析任务,准确地导入了
pandas和matplotlib.pyplot。 -
数据加载与处理:它理解了需要读取CSV文件并转换日期格式。
-
核心逻辑:通过
groupby操作进行数据聚合,这正是计算每个产品总销售额的正确方法。 -
可视化:生成了绘制饼图的所有必要参数,包括设置百分比格式、起始角度、标题和图例,甚至考虑了布局和图形比例。
这个例子展示了AI如何将高阶任务描述转化为功能完整、结构良好的代码,极大地提升了开发效率。
2.3 高级应用:代码翻译与重构
AI代码生成不仅限于从头创建,还能用于代码翻译(将一种语言的代码转换为另一种语言)和代码重构(改进现有代码的结构和质量)。
Prompt示例(代码翻译):
text
将以下Python函数转换为JavaScript函数。
Python:
def greet(name):
return f"Hello, {name}! How are you today?"
请写出功能完全相同的JavaScript代码。
AI生成的JavaScript代码:
javascript
function greet(name) {
return `Hello, ${name}! How are you today?`;
}
Prompt示例(代码重构):
text
重构以下Python代码,使其更Pythonic(更符合Python风格指南)。
def calculate_average(numbers):
sum = 0
count = 0
for num in numbers:
sum = sum + num
count = count + 1
average = sum / count
return average
AI重构后的代码:
python
def calculate_average(numbers):
"""计算数字列表的平均值。"""
if not numbers: # 处理空列表情况
return 0
return sum(numbers) / len(numbers)
AI识别出了原始代码中低效的部分(手动求和和计数),并用内置函数sum()和len()替代,同时增加了文档字符串和边界条件检查,使代码更健壮、更简洁。
3. 低代码/无代码开发
低代码/无代码平台通过可视化工具和预构建模块,抽象化了传统的编码过程。AI的融入为这些平台带来了“智能”,使其从简单的表单生成器进化成为能够理解业务逻辑和自动生成工作流的强大工具。
3.1 AI在低代码/无代码平台中的角色
-
智能表单和UI生成:根据描述(如“创建一个员工入职表单”)或样本数据,自动生成带有相应字段(姓名、职位、部门等)的用户界面。
-
工作流自动化与建议:分析业务流程,推荐最佳的工作流步骤和集成点。例如,连接“表单提交”事件到“发送邮件”和“更新数据库”操作。
-
自然语言到逻辑转换:允许用户用自然语言描述业务规则(如“如果订单金额超过100美元,则自动免运费”),平台自动将其转换为可执行的条件逻辑语句。
-
数据模型设计:根据用户对实体和关系的描述,自动生成数据库 schema。
3.2 实践示例:构建一个简单的客户反馈仪表板
假设我们使用一个虚构的名为“SmartBuilder”的AI增强型低代码平台。
步骤 1: 用自然语言创建应用
-
我们在平台中输入:“我需要一个应用来展示客户反馈。它应该有一个列表显示所有反馈,一个图表显示满意度评分(1-5分)的分布,并且我能点击列表项查看详细信息。”
步骤 2: AI生成数据模型和UI
-
平台AI会解析指令,并建议创建以下数据实体:
-
Feedback: 包含字段customer_name(文本),feedback_text(长文本),rating(数字),date_submitted(日期时间).
-
-
同时,它自动生成一个主从视图(Master-Detail)的UI布局:
-
主视图:一个表格,列出所有反馈的摘要信息。
-
详情视图:显示所选反馈的完整内容。
-
一个自动绑定了
rating字段的柱状图。
-
步骤 3: 微调与部署
-
开发者可以在可视化编辑器中拖拽调整组件布局、修改颜色主题。
-
AI可以提供实时建议,如“将
rating字段的显示控件从数字输入框改为评分星级组件可能更合适”。 -
点击“发布”,应用即可上线。
整个过程无需编写任何传统代码,但AI在后台生成了所有的代码(可能是HTML, CSS, JavaScript, SQL),而用户只需关注业务逻辑本身。
3.3 可视化流程图:AI增强的低代码应用开发流程
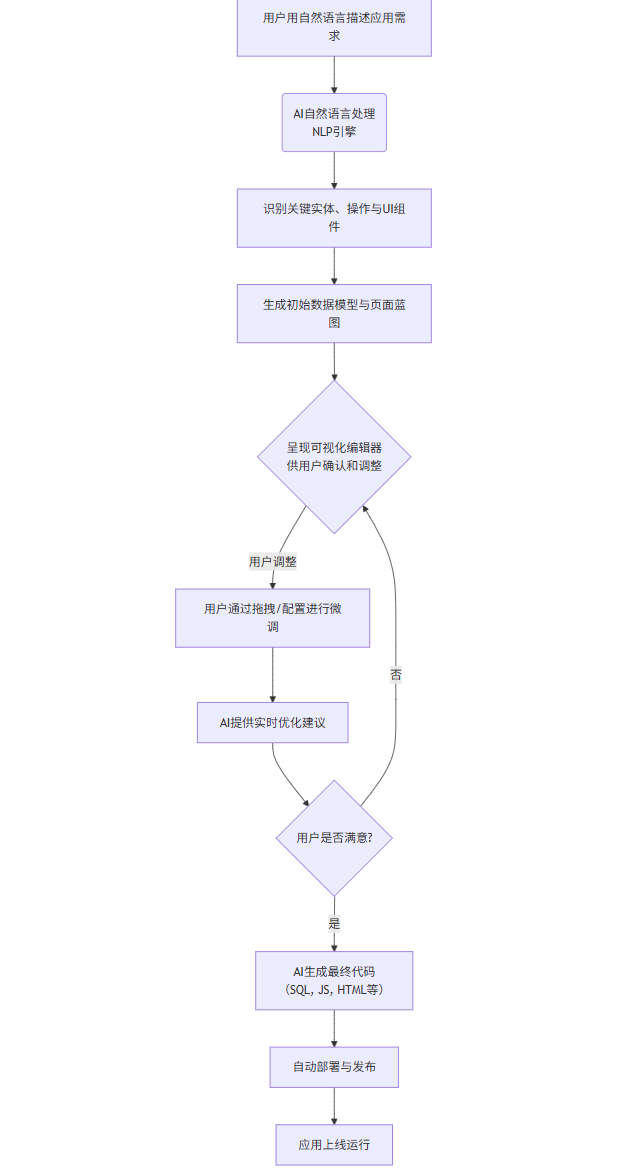
flowchart TD
A[用户用自然语言描述应用需求] --> B(AI自然语言处理<br>NLP引擎)
B --> C[识别关键实体、操作与UI组件]
C --> D[生成初始数据模型与页面蓝图]
D --> E{呈现可视化编辑器<br>供用户确认和调整}
E -- 用户调整 --> F[用户通过拖拽/配置进行微调]
F --> G[AI提供实时优化建议]
G --> H{用户是否满意?}
H -- 否 --> E
H -- 是 --> I[AI生成最终代码<br>(SQL, JS, HTML等)]
I --> J[自动部署与发布]
J --> K[应用上线运行]
这个流程图展示了AI如何作为核心驱动,将模糊的自然语言需求一步步转化为一个可运行的应用,极大地降低了开发门槛。
4. 算法优化实践
AI在算法优化领域的应用是双向的:一方面,我们使用AI来优化传统算法;另一方面,我们也在设计新的、更高效的AI算法本身。
4.1 AI用于性能分析与调优
AI工具可以分析程序的运行时性能(Profiling),识别热点(消耗资源最多的代码部分),并提出甚至自动实施优化建议。
示例:使用AI分析排序算法
假设我们有一个自定义的排序函数,但性能不佳。AI性能分析工具可以:
-
运行分析:在测试数据上运行该函数,并收集CPU时间、内存分配等指标。
-
识别瓶颈:发现内层循环中的比较操作是主要性能瓶颈。
-
提供建议:“您的自定义排序算法时间复杂度为O(n²)。对于大型数据集,建议替换为标准库中的
Timsort算法(list.sort()),其平均时间复杂度为O(n log n)。” 或者,如果必须使用自定义算法,AI可能会建议使用更高效的数据结构来减少比较次数。
4.2 超参数优化
在机器学习领域,模型的性能极度依赖于超参数(如学习率、神经网络层数、每层神经元数量等)。手动调试这些参数非常耗时。
AI优化技术(例如):
-
网格搜索:自动遍历所有预定义的参数组合。
-
随机搜索:从参数空间中随机采样进行尝试。
-
贝叶斯优化:一种更智能的方法,它基于之前的评估结果,建立概率模型,来预测下一步最有可能产生最佳结果的参数组合。
代码示例:使用Scikit-learn的BayesSearchCV进行超参数优化
python
from skopt import BayesSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义分类器和方法参数
rf = RandomForestClassifier()
# 定义超参数搜索空间
search_spaces = {
'n_estimators': (10, 200), # 整数范围
'max_depth': (1, 50), # 整数范围
'min_samples_split': (2, 10), # 整数范围
'criterion': ['gini', 'entropy'] # 分类列表
}
# 使用贝叶斯优化进行超参数调优
opt = BayesSearchCV(
estimator=rf,
search_spaces=search_spaces,
n_iter=50, # 迭代50次
cv=5, # 5折交叉验证
n_jobs=-1, # 使用所有CPU核心
random_state=42
)
# 执行搜索
opt.fit(X_train, y_train)
# 输出最佳参数和得分
print("Best parameters found: ", opt.best_params_)
print("Best cross-validation score: ", opt.best_score_)
# 在测试集上评估最佳模型
best_model = opt.best_estimator_
test_score = best_model.score(X_test, y_test)
print(f"Test set score with best parameters: {test_score:.4f}")
在这个例子中,AI(贝叶斯优化算法)自动为我们探索了随机森林算法的超参数空间,找到了性能最佳的一组配置,省去了大量手动实验的时间。
4.3 算法选择与设计
AI可以帮助研究者为特定问题设计全新的、更高效的算法。例如,DeepMind的AlphaDev甚至通过强化学习发现了更快的排序算法,改进了几十年未被触动的基础库例程。它通过将排序操作视为一个单人在“组装游戏”中,AI通过选择并组合低级CPU指令(如cmov,blend等)来生成一个既正确又更快的算法。
5. 综合案例:端到端的AI辅助开发流程
让我们设想一个完整的场景,将自动化代码生成、低代码和算法优化结合起来,开发一个“智能邮件分类系统”。
项目目标:自动对流入的客户邮件进行分类(如:咨询、投诉、订单相关、垃圾邮件)。
5.1 阶段一:需求分析与数据准备(低代码/无代码)
-
我们使用一个低代码平台来构建一个简单的数据标注界面。
-
Prompt:“创建一个允许用户查看未分类邮件并将其拖拽到‘咨询’、‘投诉’、‘订单’、‘垃圾’四个标签下的界面。”
-
平台AI生成此数据标注应用,并自动创建好背后的数据库来存储邮件和标签。
-
非技术背景的团队成员可以立即开始使用这个应用来标注数据,为训练AI模型做准备。
5.2 阶段二:模型开发与训练(自动化代码生成)
-
数据准备好后,我们需要编写机器学习模型代码。
-
Prompt:“使用Python和scikit-learn编写一个文本分类模型。数据是CSV格式,两列:
text(邮件内容)和label(类别)。需要进行文本向量化(TF-IDF),然后训练一个逻辑回归模型,并输出分类报告。” -
AI生成类似以下的代码框架:
python
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 加载已标注的数据
df = pd.read_csv('labeled_emails.csv')
# 划分特征和标签
X = df['text']
y = df['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 文本向量化
vectorizer = TfidfVectorizer(stop_words='english', max_features=1000)
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# 训练模型
model = LogisticRegression()
model.fit(X_train_vec, y_train)
# 预测并评估
y_pred = model.predict(X_test_vec)
print(classification_report(y_test, y_pred))
# 【后续】保存模型和向量化器以供部署使用
5.3 阶段三:性能优化(算法优化实践)
-
我们发现模型在“投诉”类上的召回率(Recall)不高,需要优化。
-
方法1(超参数优化):使用上一节提到的贝叶斯优化来调整逻辑回归的
C参数和TF-IDF的max_features参数。 -
方法2(算法选择):让AI建议并尝试其他算法。
-
Prompt:“针对文本分类问题,除了逻辑回归,还有哪些模型通常表现更好?请给出使用Naive Bayes和SVM的代码示例进行比较。”
-
AI会生成使用
MultinomialNB和SVC的代码,并进行比较。我们可能会发现SVM+RBF核在这个数据集上效果更好。
-
5.4 阶段四:部署与集成(低代码/自动化)
-
模型训练好后,需要集成到现有的邮件系统中。
-
我们使用低代码平台的工作流功能:
-
触发条件:当新邮件到达时。
-
执行动作:调用我们训练好的模型API(例如,通过一个部署好的HTTP端点)进行分类。
-
后续操作:根据分类结果(如“投诉”),自动打上标签并转发给客户服务团队进行处理。
-
-
这个集成流程可以通过在低代码平台上拖拽“触发器”和“动作”模块来完成,无需编写复杂的集成代码。
通过这个案例,我们可以看到三种技术如何无缝协作,高效地完成一个复杂的软件项目。
6. 挑战与未来展望
尽管AI编程前景广阔,但仍面临诸多挑战:
-
代码质量与可靠性:AI生成的代码可能存在细微的错误、安全漏洞或性能问题,需要严格的人工审查和测试。
-
理解与可控性:有时AI像一个“黑盒”,开发者难以理解其生成代码的逻辑,在调试和定制化时会遇到困难。
-
依赖性与技术债:过度依赖AI可能导致开发团队基础技能退化,并可能引入难以维护的“AI技术债”。
-
版权与伦理问题:训练代码模型的数据来源的合法性,以及生成代码的版权归属,都是待解决的法律问题。
未来展望:
-
AI结对程序员:AI将从代码补全工具进化成为真正的“结对程序员”,能理解整个项目的上下文,进行架构讨论和设计决策。
-
自我调试与修复:AI将能够自动识别、解释并修复自己或他人代码中的bug。
-
需求工程:AI甚至可以从模糊的自然语言需求文档中,直接生成原型代码或可执行的需求规格说明。
-
全民开发:低代码/无代码平台与AI的结合将真正实现“全民开发”,让领域专家无需依赖专业程序员就能构建复杂的应用。
7. 结论
AI编程正在从根本上重塑我们创建软件的方式。自动化代码生成、低代码/无代码开发和算法优化实践这三大支柱,共同构建了一个新的软件开发范式,其核心是人机协作。
开发者不再是纯粹的编码者,而是逐渐转变为目标的定义者、架构的设计者、提示的工程师和AI输出的审核者。AI负责处理重复性高、模式固定的工作,而人类则专注于需要创造力、批判性思维和深层领域知识的任务。
拥抱AI编程并非意味着放弃编程技能,而是意味着学习如何更有效地与AI工具协作,如何设计更好的Prompt,如何评估和指导AI的输出,以及如何将AI生成的结果整合到更大、更复杂的系统中。未来属于那些能够善用AI放大自身能力的开发者。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献122条内容
已为社区贡献122条内容

所有评论(0)