如何在Welight 中使用Ollama 本地模型
摘要: Welight 2.4.0版本将新增Ollama本地AI模型支持,用户可灵活选择不同模型并保障隐私。使用步骤包括下载Ollama、获取模型、启动服务(如ollama serve)。集成后,通过AI配置页面启用本地模型即可。开发者欢迎用户加入QQ群(474919458)反馈问题或建议。
·
基于用户的反馈建议和这段时间用户整体的使用情况,还是决定在 Welight中新增ollama 本地 AI 模型的支持。尽管本地模型的智能程度以及整体的使用体验都存在褒贬不一的讨论,但是它的优势在于用户可以根据自己设备的实际情况和需求选中不同程度的本地模型,不同模型的体验是不一样的,由于Ollama是完全基于本地模型的,因此也保护了用户隐私。
安装和配置Ollama
- 下载 Ollama,下载地址https://ollama.com/download
- 下载模型,可以根据自己的需求下载想要的模型
# ollama pull 模型名称,比如
ollama pull llama3.2
- 启动模型,启动方式不一,可以直接启动下载下来的执行文件,也可以通过下面的命令在终端启动。
ollama serve
- 常用命令
# 查看模型详细
ollama show llama3.2
# 查看已下载的模型列表
ollama list
# 停止当前模型
ollama stop llama3.2
这一步完成之后就可以继续往后阅读了。
集成版本
Ollama本地模型的集成将会在 Welight2.4.0版本中完成。因此,在使用之前,务必前往官网下载更新最新版本。
在最新版本的 Welight中,通过 AI 配置页面你可以看到默认的 AI 模型新增了 Ollama本地模型。
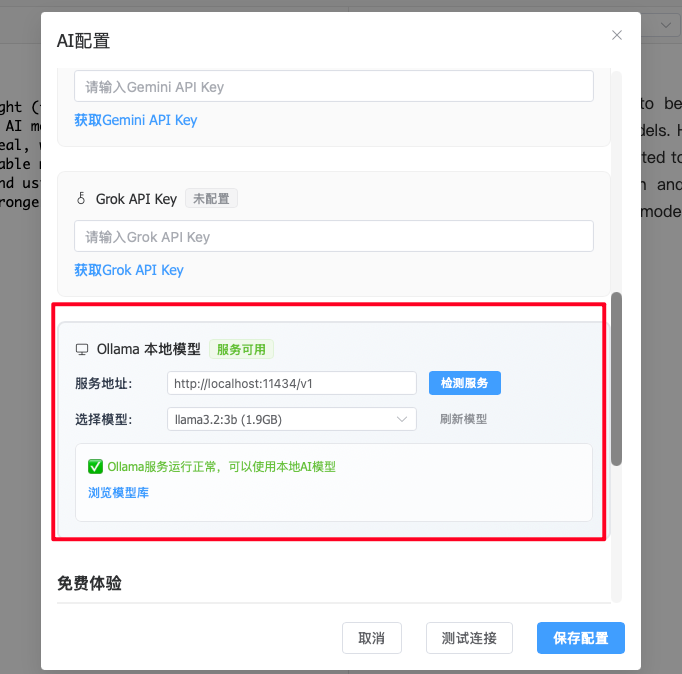
如果你看到的界面和我上面的截图差不多(可能存在模型上的差别)并且 测试连接 也通过,那么恭喜你,你的本地模型已就绪,可以正常使用所有AI功能。
交流反馈
- Welight完全是个人独立开发,精力有限,可能更新没有那么频繁,测试也不够完善,如果遇到问题或者有什么功能上的建议或者意见,欢迎加入交流群进行反馈。
- QQ交流群:474919458


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)