【AI论文】EchoX:面向语音到语音大语言模型(Speech-to-Speech LLMs),通过回声训练缓解声学-语义鸿沟
摘要:本研究针对语音大语言模型(SLLMs)存在的声学-语义鸿沟问题,提出EchoX新型训练框架。该模型通过三阶段训练策略(语音-文本转换、文本-编码训练、回声训练),结合动态语音目标生成机制,有效融合声学与语义特征。实验表明,仅用6000小时训练数据的EchoX在多个知识问答基准测试中表现优异,3B和8B版本平均准确率分别达37.1%和46.3%。研究同时验证了单元语言压缩和流式生成机制的有效性
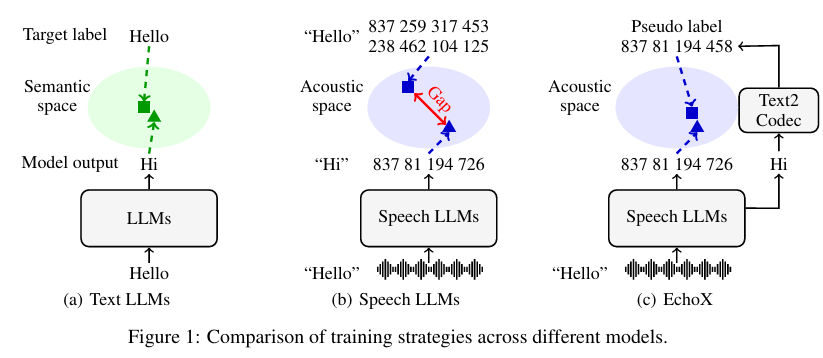
摘要:语音到语音大语言模型(Speech-to-speech Large Language Models,SLLMs)正受到越来越多的关注。这类模型由基于文本的大语言模型(Large Language Models,LLMs)衍生而来,但往往在知识和推理能力上有所退化。我们推测,这一局限源于当前SLLMs的训练范式未能弥合特征表示空间中的声学-语义鸿沟。为解决这一问题,我们提出了EchoX,该模型利用语义表示并动态生成语音训练目标。这种方法融合了声学与语义学习,使EchoX能够作为语音大语言模型保留强大的推理能力。实验结果表明,使用约六千小时训练数据的EchoX在多个基于知识的问答基准测试中取得了优异表现。该项目可在Github获取。Huggingface链接:Paper page,论文链接:2509.09174。
研究背景和目的
研究背景:
随着人工智能技术的快速发展,语音到语音的大型语言模型(Speech-to-Speech Large Language Models, SLLMs)逐渐成为研究热点。这些模型旨在将语音识别、自然语言理解和语音生成整合到一个统一的框架中,从而实现更加自然和高效的人机交互。然而,现有的SLLMs大多源于基于文本的大型语言模型(LLMs),在知识表示和推理能力上存在显著退化。这种退化主要归因于当前SLLMs的训练范式未能有效弥合语音特征表示空间中的声学-语义间隙(Acoustic-Semantic Gap)。
声学-语义间隙指的是语音信号中的声学特征与文本信号中的语义特征之间的不匹配。在传统的SLLMs训练中,语音通常被离散化为语音标记(speech tokens),模型通过预测这些标记来生成响应。然而,这种方法偏向于发音层面的准确性,而非语义层面的正确性,导致模型在生成语义正确但发音略有不同的响应时受到严重惩罚。这种偏差限制了SLLMs在复杂语音交互任务中的表现,尤其是在需要深度理解和推理的场景中。
研究目的:
本研究旨在提出一种新的训练框架——EchoX,以解决现有SLLMs中的声学-语义间隙问题,从而提升模型在语音交互任务中的知识表示和推理能力。具体目标包括:
- 弥合声学-语义间隙:通过引入动态语音训练目标生成机制,使模型在训练过程中同时考虑声学和语义特征,从而生成更加准确和自然的语音响应。
- 提升推理能力:通过保留LLMs的强大推理能力,使SLLMs在语音交互任务中能够进行深度理解和推理,提高任务解决的准确性和效率。
- 验证有效性:通过在多个基于知识的问答基准测试上评估EchoX的性能,验证其在解决声学-语义间隙问题上的有效性,并展示其在有限训练数据下的先进性能。
研究方法
1. 整体设计:
EchoX采用三阶段训练框架来弥合声学-语义间隙:
- 阶段一:语音到文本训练(Speech-to-Text Training):将文本型LLM转换为语音到文本的对话LLM,使模型能够感知语音并生成文本响应。这一阶段采用Soundwave模型,通过对齐适配器和压缩适配器高效实现语音理解。
- 阶段二:文本到编码训练(Text-to-Codec Training):训练一个文本到编码的模块,将文本转换为语音标记。这一阶段采用典型的仅解码器架构,通过交叉熵损失进行优化,确保文本表示空间与语音到文本LLM的一致性。
- 阶段三:Echo训练(Echo Training):将前两个阶段的模块结合起来,对整个语音到语音LLM进行微调。这一阶段引入Echo解码器,利用预训练的文本到编码模块解码语音到文本LLM的输出,生成语音训练目标,从而消除语音标记与语义特征之间的不匹配。
2. 语音标记构建:
为了解决长语音序列的挑战,EchoX采用单元语言(Unit Language)作为语音标记。单元语言通过将原始波形输入预训练的HuBERT模型,转换为连续的隐藏表示,并通过k均值聚类将其离散化为单元ID序列。这种方法显著压缩了音频序列的长度,同时确保了文本到语音合成的质量。
3. 流式生成:
考虑到语音序列显著长于文本序列,EchoX采用流式生成机制来降低合成难度并提高实时响应能力。通过设计触发特征,计算当前语义表示与历史语义表示之间的余弦相似度,仅在相似度超过阈值且为局部极值时执行写操作,从而确保每个片段的语义完整性。
研究结果
1. 知识问答基准测试性能:
在Llama Questions、Web Questions和TriviaQA等基于知识的问答基准测试上,EchoX展示了先进的性能。具体来说,EchoX-3B模型在Web Questions上的准确率为31.6%,在TriviaQA上的准确率为25.8%,平均准确率为37.1%;EchoX-8B模型在这些基准测试上的性能进一步提升,平均准确率达到46.3%。与现有模型相比,EchoX在有限训练数据下实现了与基于数百万小时数据训练的模型相当的性能。
2. 语音到文本与语音到语音任务性能:
在语音到文本任务中,EchoX-3B模型在Llama Questions、Web Questions和TriviaQA上的平均准确率为50.0%,显著优于其他基线模型;EchoX-8B模型的平均准确率进一步提升至56.2%。在语音到语音任务中,尽管基于交错生成策略的模型表现出一定优势,但EchoX通过文本到编码的方法仍高效实现了可比性能,进一步验证了Echo训练策略的有效性。
3. 单元语言与流式生成效果:
使用单元语言作为语音标记显著压缩了音频序列长度,同时保持了较高的合成质量。实验结果表明,单元语言在压缩比和识别准确率上均优于传统单元方法。流式生成机制有效降低了长序列生成的难度,提高了实时响应能力,且未引入显著的性能下降。
研究局限
1. 数据依赖性:
尽管EchoX在有限训练数据下实现了先进性能,但其表现仍受限于训练数据的规模和多样性。在极端数据稀缺情况下,模型的泛化能力可能受到限制。未来研究需要探索更高效的数据利用策略,以进一步提升模型在低资源场景下的性能。
2. 探索效率:
在Echo训练过程中,模型的探索效率仍有限。尽管采用了多种探索增强策略,但在某些复杂任务中,模型可能仍难以发现最优解。未来研究需要设计更智能的探索策略,以提高模型在复杂环境中的探索能力和收敛速度。
3. 奖励设计:
本研究采用简单的二元奖励函数,仅根据任务完成情况分配奖励。虽然这种方法在实验中表现良好,但在某些复杂任务中,可能需要更精细的奖励设计以引导模型学习更优的行为策略。未来研究可以探索结合过程奖励和结果奖励的混合奖励设计,以进一步提升模型的性能。
未来研究方向
1. 改进初始模型能力:
未来研究可以探索更有效的预训练策略,以提升基线模型的初始任务能力。例如,可以采用自监督学习、对比学习等方法,提升模型在少量数据下的学习能力。同时,多任务学习框架也可以用于同时训练模型处理多个相关任务,以提升模型的初始泛化能力。
2. 优化探索策略:
设计自适应的探索策略,根据模型的当前能力和任务复杂度动态调整探索强度。例如,可以在训练初期采用较高的探索温度,随着模型能力的提升逐渐降低探索温度。同时,引入基于好奇心的探索机制,鼓励模型探索未知状态和动作空间,以提升探索效率和多样性。
3. 精细奖励设计:
结合过程奖励和结果奖励,设计更精细的奖励函数。例如,可以为关键子任务分配过程奖励,同时保留结果奖励以引导模型完成整体任务。此外,探索基于人类反馈的奖励设计,利用人类评估者的知识引导模型学习更优的行为策略,也是未来研究的重要方向。
4. 扩展应用场景:
将EchoX框架应用于更多真实世界任务中,如家庭服务机器人、工业自动化等。通过收集真实世界数据,进一步验证和优化模型的性能。同时,探索EchoX在跨模态任务中的应用,如结合视觉、语言和触觉等多模态输入,完成更复杂的操作任务,以提升模型在复杂环境中的适应能力和鲁棒性。
5. 伦理和安全性研究:
加强对模型安全性和鲁棒性的研究,确保模型在复杂环境中的可靠运行。例如,可以探索如何在训练过程中引入安全性约束,避免模型学习到危险或不合规的行为。同时,随着VLA模型在真实世界中的广泛应用,其可能带来的伦理问题也日益凸显。未来研究应加强对这些问题的关注,制定相应的伦理准则和监管措施,确保技术的健康、可持续发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献129条内容
已为社区贡献129条内容

所有评论(0)