ForgeLens: Data-Efficient Forgery Focus for Generalizable Forgery Image Detection(ForgeLens:面向可泛化伪造图像
AI生成内容技术的迅猛发展,尤其是图像合成领域中GANs和扩散模型的广泛应用,使得虚假图像的生成变得极为逼真且难以与真实图像区分,这不仅模糊了真实与虚假视觉的界限,更对社会安全造成了重大威胁。(先说了一下背景,什么什么深度伪造技术发展迅速,难以区分,介绍背景)这张图比较了三种图像伪造检测方法:专业化检测方法在已知数据集上准确率高,但泛化能力和数据效率低;冻结网络方法泛化能力强,但检测准确率低;而F
1.摘要
生成模型的流行引发了对图像真实性的担忧,亟需泛化能力强、数据效率高的检测器。我们设计了ForgeLens,它是一种数据高效、特征引导的伪造检测框架。通过权重共享引导模块(WSGM)和伪造感知特征集成器(FAFormer),ForgeLens引导网络专注于伪造特征提取,整合多阶段特征,大幅提高泛化能力,可以以少量数据集达到极高的泛化性。在19个生成模型的实验中,ForgeLens仅用1%训练数据,使Avg.Acc提升13.61%,Avg.AP提升8.69%,达到顶尖性能。(作者用了百分之一的训练数据就在wang数据集熵到达了95的测试准确率。)
2.介绍
AI生成内容技术的迅猛发展,尤其是图像合成领域中GANs和扩散模型的广泛应用,使得虚假图像的生成变得极为逼真且难以与真实图像区分,这不仅模糊了真实与虚假视觉的界限,更对社会安全造成了重大威胁。(先说了一下背景,什么什么深度伪造技术发展迅速,难以区分,介绍背景)
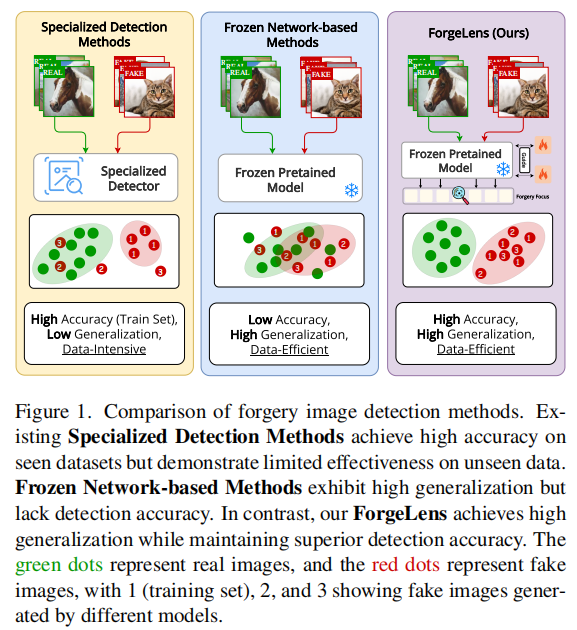
这张图比较了三种图像伪造检测方法:专业化检测方法在已知数据集上准确率高,但泛化能力和数据效率低;冻结网络方法泛化能力强,但检测准确率低;而ForgeLens方法则在保持高泛化能力的同时,实现了高检测准确率和数据效率。(主要引出数据效率)
传统手工特征提取的图像伪造检测方法性能有限,而基于深度学习的专门检测方法虽能有效识别已知生成模型的合成图像,但因不同模型生成的伪影独特,常过度拟合训练集,导致泛化能力差、对新模型生成图像检测效果不佳,且需大量数据训练。
冻结网络方法利用预训练网络提取通用特征,虽能提高泛化能力,但因通用特征含大量无关信息,使分类器难以区分真假,导致检测精度受限。
为验证之前陈述,对经典ResNet50模型(代表完全训练的专用方法)及冻结的CLIP-ViT提取的图像特征进行可视化(图2)。ResNet50在已见ProGAN数据上能清晰区分真实与伪造图像特征,但在未见数据上区分度降低。冻结的CLIP-ViT提取的特征通用且未针对伪造检测优化,在ProGAN和StyleGAN数据上按图像类别而非真实或伪造分组,表明其区分能力有限。
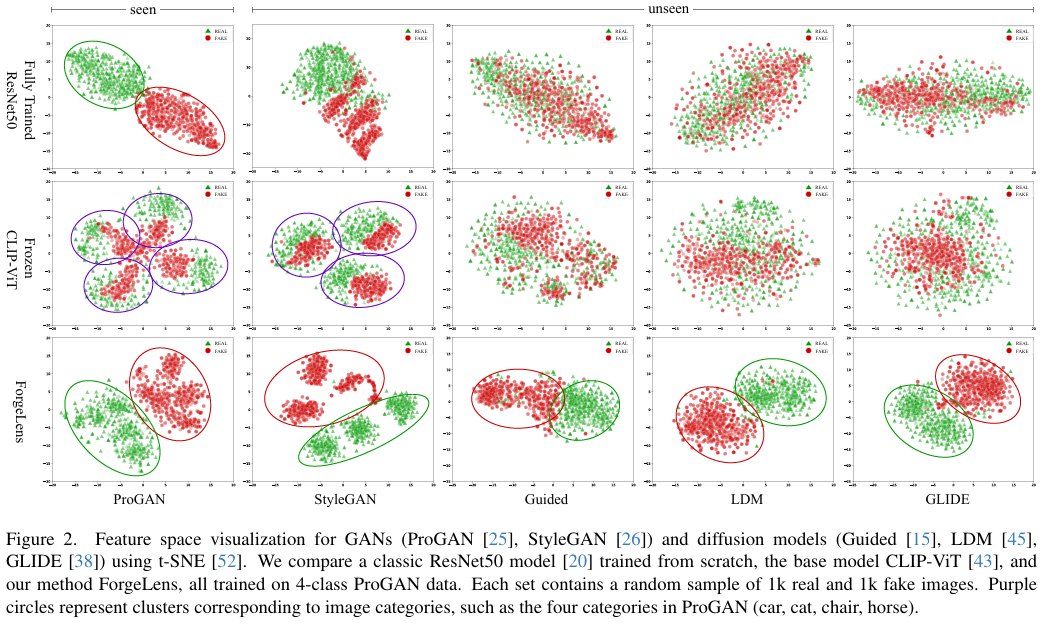
这张图展示了使用t-SNE对GANs(ProGAN、StyleGAN)和扩散模型(Guided、LDM、GLIDE)的特征空间进行可视化。比较了全量训练的ResNet50、冻结的CLIP-ViT和ForgeLens三种方法,它们都在4类ProGAN数据上训练。每个子图包含1k真实图像和1k伪造图像的随机样本。紫色圆圈表示图像类别的聚类,如ProGAN中的四类(汽车、猫、椅子、马)。

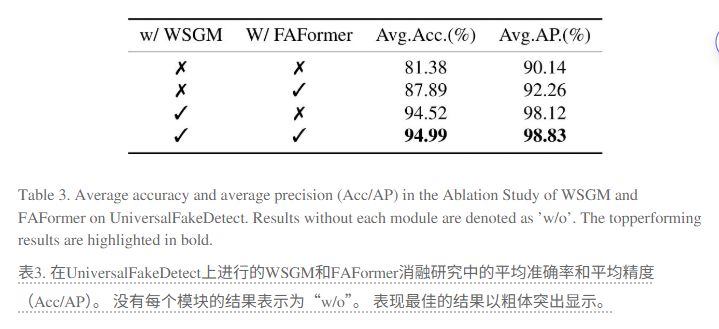
ForgeLens是一款高效的伪造图像检测器,具备强泛化能力和低数据需求。它通过权重共享引导模块(WSGM)引导预训练的CLIP-ViT关注伪造特征,并利用伪造感知特征集成器(FAFormer)提炼多阶段特征中的伪造信息,抑制通用图像特征中的无关信息,从而获得高度判别性的特征表示。实验表明,ForgeLens仅需1%的训练数据,就能在包含多种生成模型图像的数据集上实现94.99%的高平均检测准确率,展现了强大的泛化能力和数据效率。
(为了实现这一点,我们提出了 ForgeLens(图 1,右),这是一个特征引导的框架,它使用轻量级的、可训练的权重共享引导模块(WSGM)来引导冻结的、预训练的 CLIP-ViT 专注于伪造特定的特征。此外,还设计了一个伪造感知特征集成器 FAFormer,用于提炼跨多阶段特征的伪造信息,使模型能够保持大规模预训练权重的高泛化能力,同时有效地专注于伪造检测。通过这种方法,我们的方法抑制了原始 CLIP-ViT 提取的通用图像特征中与伪造无关的信息,从而获得高度判别性的特征表示)
我们的主要贡献包括:
ForgeLens是特征引导的CLIP-ViT框架,专为伪造图像检测设计,既具备强大泛化能力,又保持高检测精度。
我们引入轻量级的WSGM和FAFormer,让冻结的预训练CLIP-ViT专注于伪造图像特征,解决了其通用特征中无关信息过多的问题。
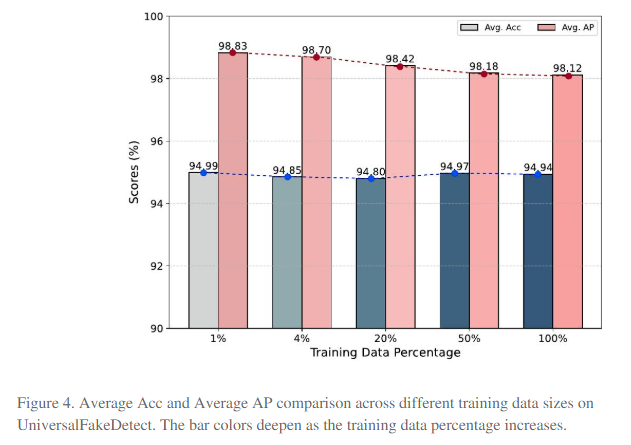
ForgeLens在UniversalFakeDetect数据集上性能超越现有方法,且以极少训练数据保持卓越表现,展现了强大的数据效率。(仅用了1%的数据达到了95的准确率)
3.相关工作
3.1专用伪造图像检测方法
传统伪造图像检测方法(如GLFF、FreqNet、NAFID等)依赖神经网络和复杂模块提取伪影,但泛化能力有限,难以处理未见模型,且需大量数据从头训练。相比之下,ForgeLens通过轻量级设计,在极少数据下实现对未知模型的高效泛化。(现有的伪造图像检测方法都需要消耗大量的训练集,如果训练集过少,他们的准确率就会存在不足的情况)
3.2基于预处理的检测方法
现有伪造图像检测方法通过数据增强或图像预处理来提升对未见模型的泛化能力,但这些方法易丢失原始RGB图像信息,增加检测流程复杂性。相比之下,我们的端到端框架直接以原始图像为输入,无需额外处理,有效实现了更好的泛化效果。(目前有很多人他们不拿原始RGB作为输入,而是从图像增强的角度来去对RGB进行增强,然后再把增强后的图像交给神经网络去进行学习,(我们也是怎么干的),但是这样会在很大程度熵丢失RGB信息)
3.3基于冻结预训练模型的方法、
某研究路线用冻结预训练图像编码器(如CLIP-ViT)提取通用图像特征,再用线性分类器做伪造检测,这能防过拟合,提高对未见模型图像的泛化力。FatFormer 用伪造感知适配器聚合频率特征,C2PCLIP 通过类别通用提示注入类别概念,但它们都受限于通用特征中的无关信息。我们提出仅用图像编码器的框架,让冻结图像编码器聚焦伪造特征、抑制无关信息,提升泛化能力和检测精度。(也有很多人使用冻结的CLIP来去进行深度伪造检测,但是他们冻结的CLIP会在很大程度上让模型学习到很多没用的信息,而我们的提的的网络可以抑制无关信息,让模型关注特定伪影)。
4.方法
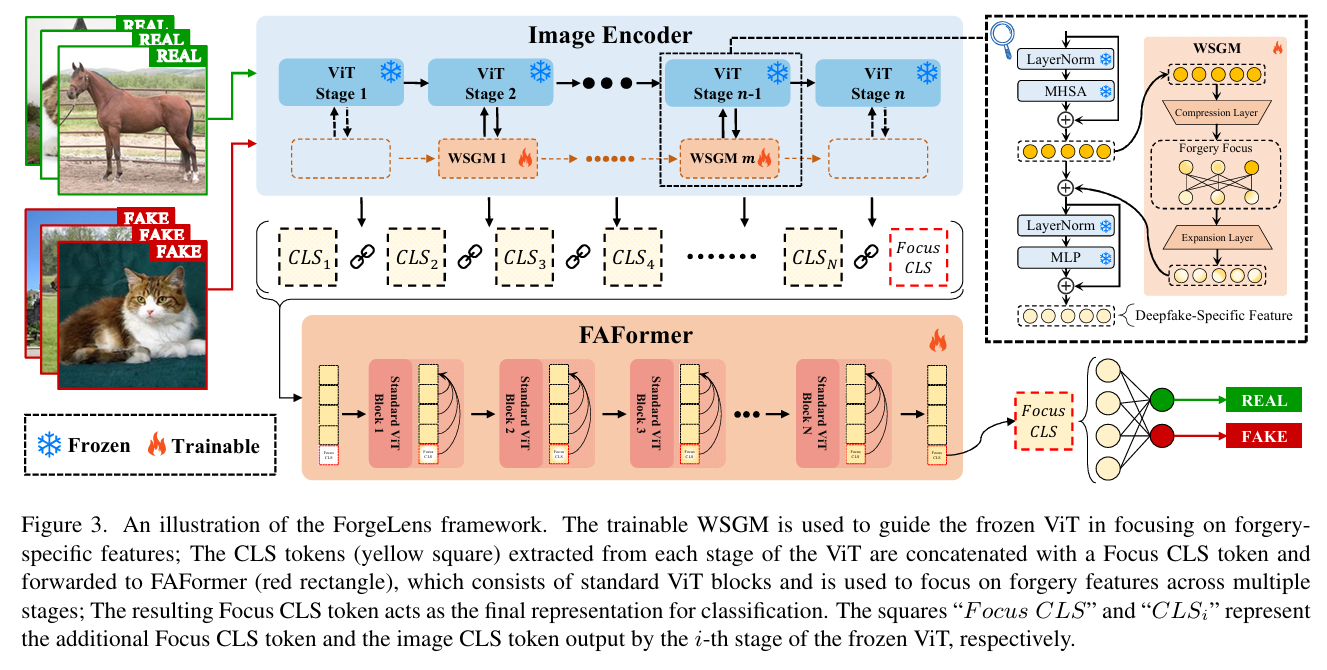




4.1图像编码器
我先仔细琢磨了这段话,它主要是讲CLIP-ViT怎么处理RGB图像的。核心就是图像先被分割成好多小块,也就是patch,然后这些patch被转化到一个特征空间里,形成一个序列。在这个序列前面再加上一个CLS token,接着通过多个Vision Transformer块来处理这个序列,自注意力机制会让表示更精准。最后,输出的CLS token就作为图像的表示了。整个过程,就是从图像到特征表示的转换。我得把这些关键点都提炼出来,同时把一些次要的细节,比如具体的数学符号、维度这些稍微简化一下,让人一眼就能看明白CLIP-ViT的处理流程。
4.2权重共享引导模块
为解决冻结预训练CLIP-ViT提取的通用图像特征中包含过多与伪造无关信息的问题,提出轻量级、可训练的权重共享引导模块(WSGM),以最少额外参数引导编码器提取伪造特定特征。WSGM跨多个ViT块运行,在MHSA输出特征馈送到MLP前进行处理,优化全局特征、强调伪造信息,使MLP接收适合伪造检测的特征,增强冻结编码器对伪造特征的关注。WSGM采用瓶颈结构,含压缩层、扩展层、ReLU激活及额外线性层,减少可训练参数的同时引导ViT块聚焦伪造特征,有效提升伪造检测精度。
4.3FAFormer
在引导提取伪造特征后,我们提出FAFormer,一种伪造感知特征集成器,用于细化多阶段的伪造信息,包括低级和高级图像特征。基于经典Transformer利用CLS token捕获输入序列综合表示的发现,我们连接冻结ViT模型各阶段的CLS token,并引入新的Focus CLS token作为全局表示,提炼所有阶段的信息。FAFormer遵循标准ViT块架构,使用自注意力机制整合冻结CLIP-ViT提取的多阶段特征,结合低级细节与高级语义,增强伪造线索的表示,助力伪造检测。
4.实验
4.1数据集
作者使用了wang数据集使用1%、4%、20%、50% 和 100% 数据的子集。
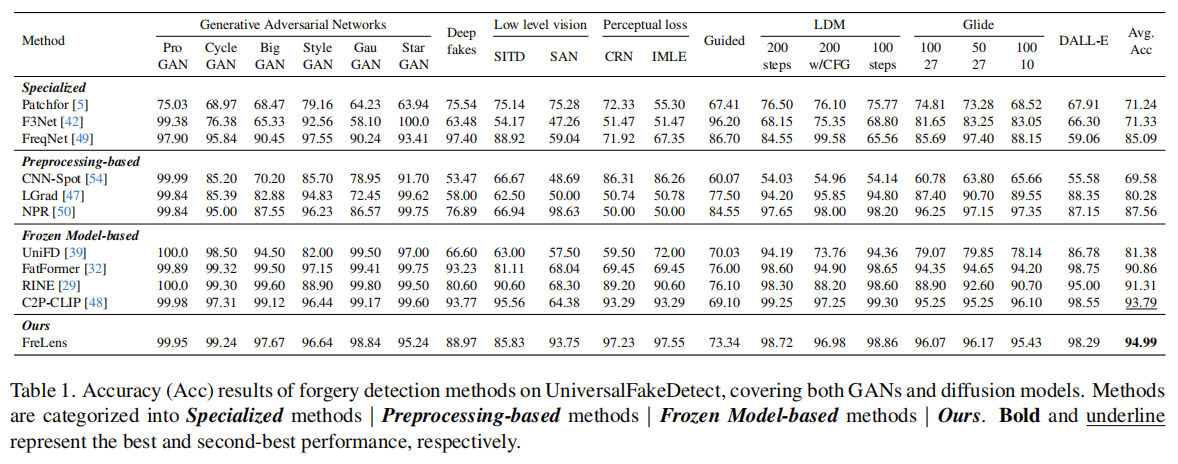
为评估我们方法的有效性和泛化能力,我们采用广泛使用的 UniversalFakeDetect 数据集。具体来说,UniversalFakeDetect 测试集包含 19 个子集,涵盖多种生成模型,包括 ProGAN、StyleGAN、BigGAN、CycleGAN、StarGAN、GauGAN、Deepfake、CRN、IMLE、SAN、SITD、引导扩散模型、LDM、Glide、DALLE。详细信息见附录 A.2。
4.2基线
为全面评估我们的方法,我们将其与多种伪造检测方法比较,涵盖专门检测、预处理和冻结模型三类。专门检测方法有Patchfor、F3Net、FreqNet;预处理类有CNN-Spot、LGrad、NPR;冻结模型类有UniFD、FatFormer、RINE、C2PCLIP。
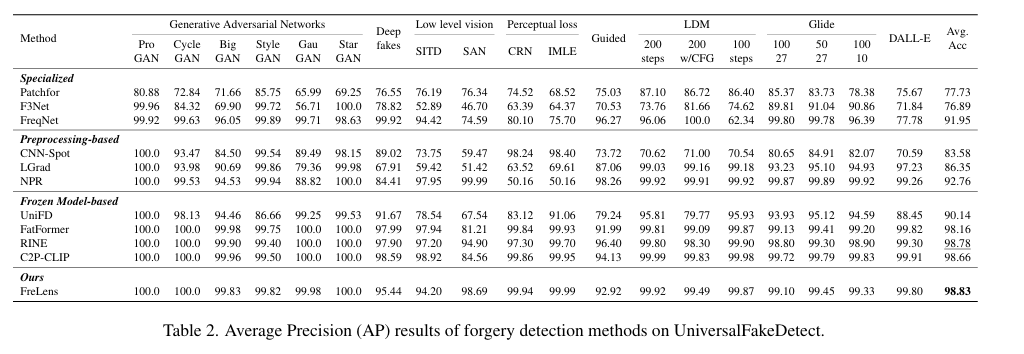
4.3评价指标
ACC AP
4.4实施细节
我们采用两阶段训练策略确保稳定性。第一阶段冻结 CLIP-ViT 主干,仅训练 WSGM;第二阶段保持先前网络冻结,集成 FAFormer 后独立训练。输入图像随机裁剪至 224×224 分辨率,训练时应用水平翻转,无额外增强,测试仅中心裁剪。使用 Adam 优化器,beta 参数 (0.9, 0.999),采用二元交叉熵损失。实验在 PyTorch 框架的 Nvidia GeForce RTX 3090 GPU 上进行。更多细节见附录 D。
5.结果分析

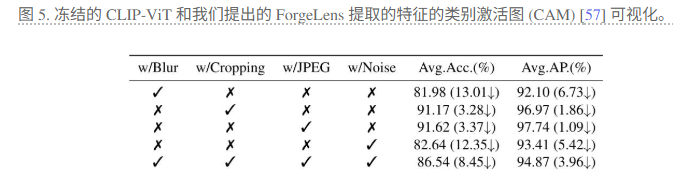
在这项工作中,我们介绍了 ForgeLens,一个数据高效且特征引导的框架,用于可泛化的伪造检测。通过集成轻量级的权重共享引导模块 (WSGM) 以引导伪造焦点,并集成 FAFormer 以在多个阶段提炼伪造感知特征,ForgeLens 有效地解决了先前基于冻结网络的方法的局限性,减少了与伪造无关的信息,同时提高了特征的区分度。在 19 个生成模型(包括 GAN 和扩散模型)上的大量实验表明,ForgeLens 实现了最先进的性能,同时仅需要最少的训练数据。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)