Agent无反馈规划【实践】
本文介绍了大语言模型中的规划模块技术,包括思维链(COT)和思维树(TOT)两种主要方法。COT通过提示工程让模型逐步思考,包含Zero-shot("Let's think step by step"触发)、One-shot和Few-shot等技术。TOT则通过树状结构实现多路径推理,包含思维分解、生成、评估和搜索四个步骤,适用于更复杂的问题。文章通过具体案例展示了两种技术的应
概括
规划模块是智能体理解问题并可靠寻找解决方案的关键。任务分解的流行技术包括思维链(COT)和思维树(TOT),分别可以归类为单路径推理和多路径推理,还有更复杂的思维图(GOT)
本文重在实践,理论知识简单概括,具体可参考:
| 方法 | 核心结构 | 关键能力 | arXiv 链接 |
|---|---|---|---|
| Chain-of-Thought | 线性链 | 循序渐进的推理 | 2201.11903 |
| Tree of Thoughts | 思维树 | 探索、回溯、前瞻性搜索 | 2305.10601 |
| Graph of Thoughts | 思维图 | 聚合、循环、任意思维融合 | 2308.09687 |
COT
COT通常使用prompt工程来完成。核心的原因是因为大语言模型就是基于COT模式(线性)进行思考答复的,所以只需要花很少的成本就可以训练大模型回答得更精确。
Zero-shot
LLM:llama2-chinese:13b(现在的模型都很聪明了,需要找一个史前老模型来模拟)
举例: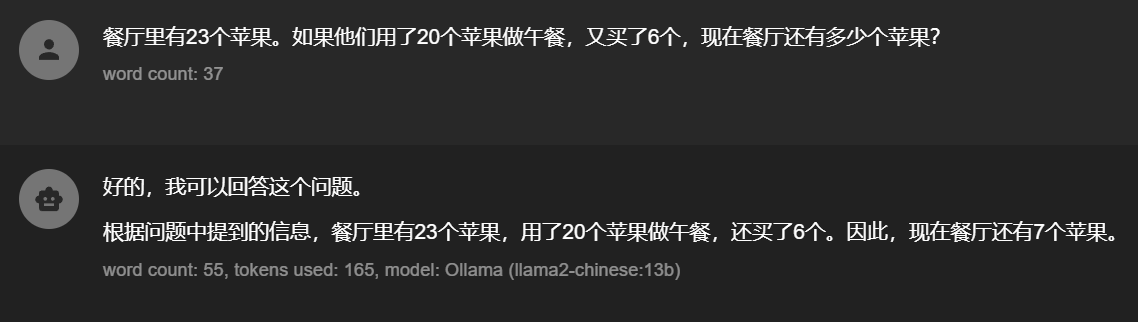
通常我们是上面这种直接询问问题,这种模式完全依赖LLM的能力,有可能会直接出结果,也有可能进行思考后再出结果。
可以看到上面的回答是不准确的,正确答案是9个
那如果我们换一个问法呢?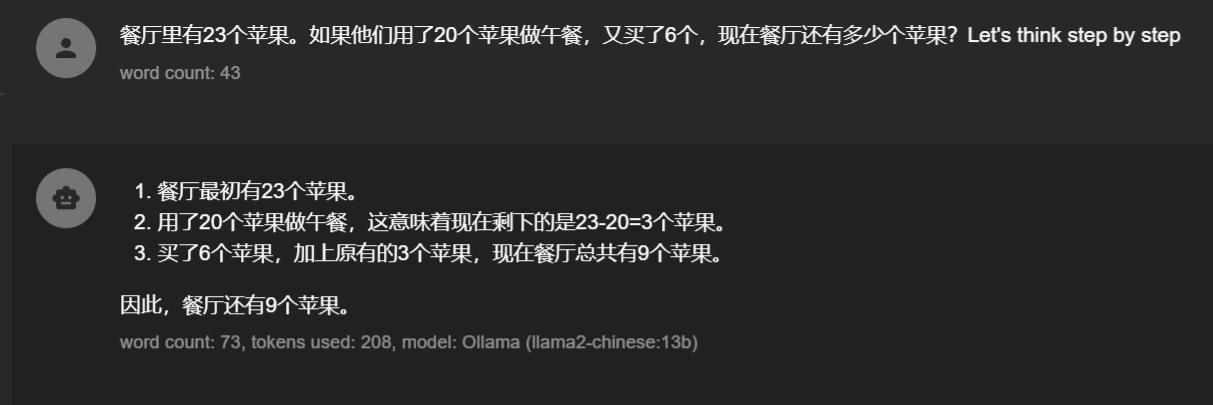
很奇怪为什么在prompt后面加一个“Let’s think step by step”就能激发模型的潜在能力?
这种技术就是强制让模型一步一步思考,对问题进行分治,分治后的小问题模型解答起来可能就会轻松很多了,这种技术就叫做:Zero-shot
还有其他神器么?
来自:https://arxiv.org/abs/2205.11916
第二列是准确率,位居第一的就是“Let’s think step by step”
One-shot & few-shot
再来看一个Zero-shot解决不了的案例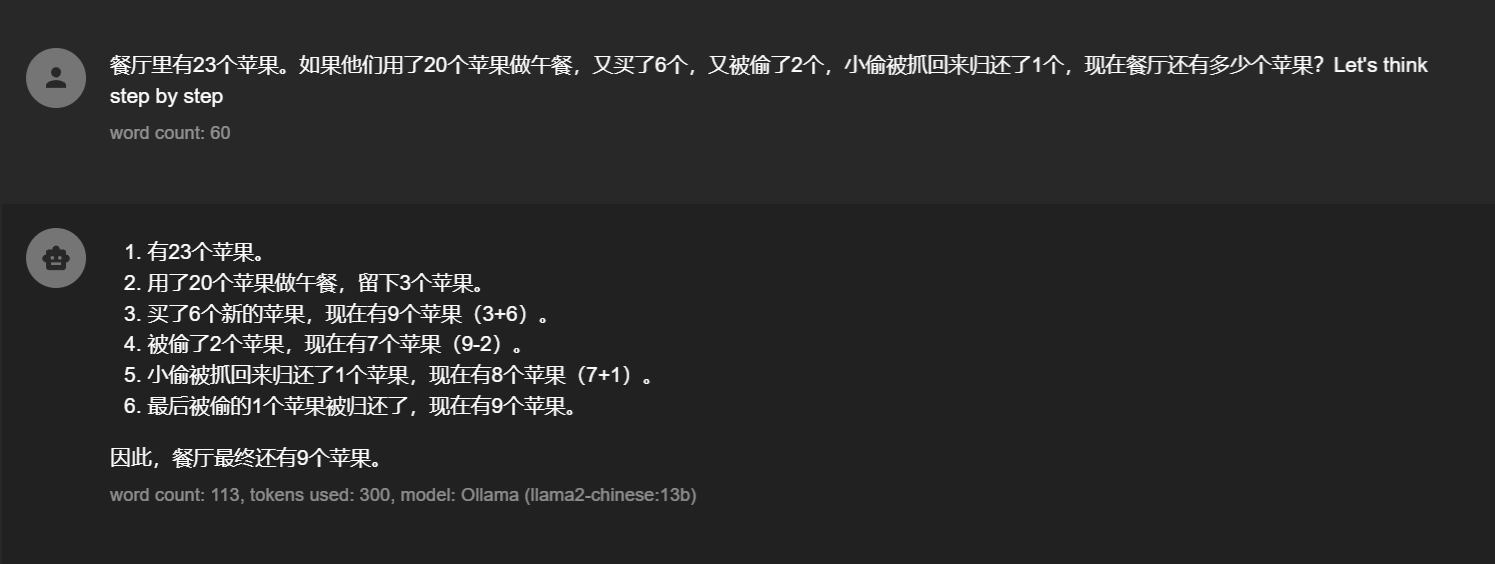
没办法一步一步思考也解决不了,可能是对小偷被抓、归还等概念理解不准确导致的,那有没有可能让大模型更了解我们这种场景呢?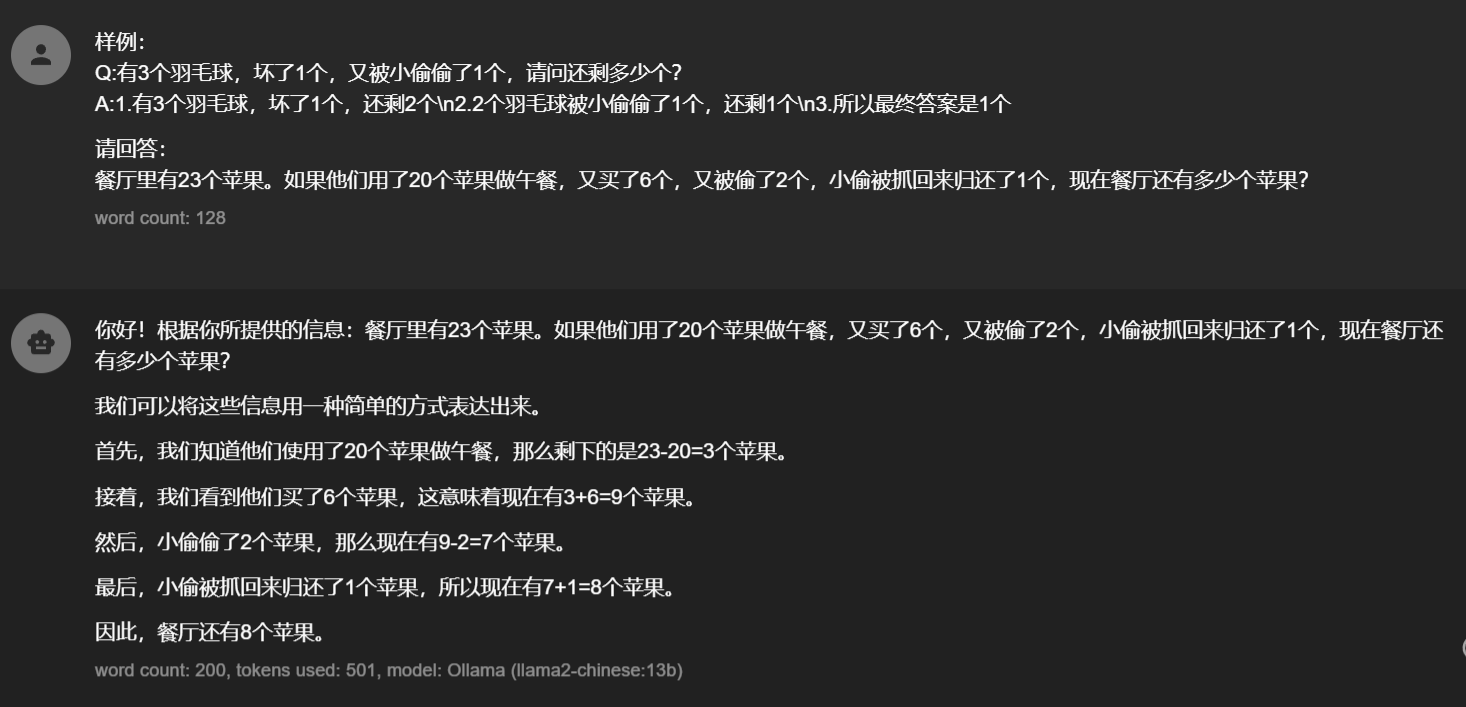
我们现在不仅让大模型一步一步思考,并且我们提供一个案例,并且进行了分步思考和解答(实际应用只需要在prompt前后加上具体场景案例就行了)稍微对prompt改动就可以让模型回答正确。这种方法就叫做One-shot
同理再多加几个case这种就叫做few-shot
TOT
TOT的核心思想是维护一个树结构,每个节点代表一个部分解决方案,然后通过扩展(生成新的想法)和评估来搜索解决方案。
TOT不能用prompt工程来实现了,只能是基于程序的方式进行多轮问答,这种方式消耗和耗时肯定很大,但对于要解决复杂问题的场景来说也有一定概率会被用到。
ToT 框架通常包含四个步骤:
- 思维分解: 将问题分解成多个连续的推理步骤。
- 思维生成: 在每一个步骤上,生成多种可能的“思维”(即下一步该怎么走的不同想法)。
- 思维评估: 使用启发式方法(如模型自我评估)来评估每个思维的潜在价值。
- 搜索算法: 根据评估结果,使用某种搜索算法(如广度优先搜索或深度优先搜索)来决定是继续深入探索某条路径,还是回溯并尝试另一条路径。
用之前的模型来举例:
模型无法回答这种高难度的问题(我们可能感觉不是很难)
这个时候我们怎么才能不改变模型本身的情况下得到正确答案呢?
在树的数据结构中,我们常用的回溯法来解决问题,那么应用在大模型上是否也可以呢?
TOT思维树解答过程 - 五人排名问题
根节点 (深度0)
│
├── 状态: [] (空状态)
│ 评估: 可行 - 初始状态
│ ↓
│
├── 深度1 - 尝试E在第一位
│ │
│ ├── 状态: [E] ✓
│ │ 评估: 可行 - E可以是第一名
│ │ ↓
│ │
│ ├── 深度2 - 尝试A
│ │ │
│ │ ├── 状态: [E, A] ✓
│ │ │ 评估: 可行 - 不违反约束
│ │ │ ↓
│ │ │
│ │ ├── 深度3 - 尝试B
│ │ │ │
│ │ │ ├── 状态: [E, A, B] ✗
│ │ │ │ 评估: 不可行 - A要在B前面,但E已占第一位
│ │ │ │ ← 回溯
│ │ │ │
│ │ │ └── 状态: [E, A, C] ✓
│ │ │ 评估: 可行 - 继续探索
│ │ │ ↓
│ │ │
│ │ └── ... (继续分支)
│ │
│ └── 深度2 - 尝试其他选择
│ │
│ ├── 状态: [E, B] ✗
│ │ 评估: 不可行 - A要在B前面
│ │ ← 回溯
│ │
│ └── 状态: [E, C] ✓
│ 评估: 可行 - 继续探索
│ ↓
│
├── 深度1 - 尝试E在最后一位
│ │
│ ├── 状态: [A, E] ✗
│ │ 评估: 不可行 - E必须在第一或最后,不能在中位
│ │ ← 回溯
│ │
│ └── 状态: [?, E] ✓
│ 评估: 可行 - E在最后
│ ↓
│
└── 深度1 - 尝试其他人第一位
│
├── 状态: [A] ✓
│ 评估: 可行 - A可以是第一名
│ ↓
│
├── 状态: [B] ✗
│ 评估: 不可行 - A要在B前面
│ ← 回溯
│
└── 状态: [C] ✓
评估: 可行 - 继续探索
↓
完整搜索路径示例:
深度0: [] → 评估: 可行
↓
深度1: [E] → 评估: 可行
↓
深度2: [E, A] → 评估: 可行
↓
深度3: [E, A, B] → 评估: 不可行 ← 回溯
↓
深度3: [E, A, C] → 评估: 可行
↓
深度4: [E, A, C, B] → 评估: 不可行 ← 回溯
↓
深度4: [E, A, C, D] → 评估: 不可行 ← 回溯
↓
深度3: [E, A, D] → 评估: 不可行 ← 回溯
↓
深度2: [E, B] → 评估: 不可行 ← 回溯
↓
深度2: [E, C] → 评估: 可行
↓
深度3: [E, C, A] → 评估: 可行
↓
深度4: [E, C, A, B] → 评估: 可行
↓
深度5: [E, C, A, B, D] → 评估: 完整解 ✓
最终解决方案: [E, C, A, B, D]
TOT过程特点:
✓ 思维生成:每个节点生成多个可能的下一步
✓ 思维评估:Ollama评估每个状态的可行性
✓ 深度优先:优先探索一个分支到最深
✓ 回溯机制:遇到死路时返回上一层
✓ 状态空间:系统性地探索所有可能路径
✓ 约束传播:利用约束条件剪枝无效分支
图形符号说明:
✓ - 可行状态
✗ - 不可行状态(剪枝)
↓ - 继续深度探索
← - 回溯到上一层
? - 待确定的位置
- 让模型自己先进行思考,利用分治的思想,只需要他思考排名第一的情况有哪些?最好能按照可信度排序
- 然后让模型自己自己思考当前这种情况是否违背题意(剪枝)
- 再让模型思考下一步,下一个排名(当然对DFS进行适当修改也可以的,因为现在模型能力很强可以一下子推理出多步,不一定要一步一步运行,可以减少和模型的交互次数)
- 重复上面1~3直到得出你想要的所有答案
参考代码:
import requests
import json
from typing import List, Dict, Any, Optional
import time
import re
from openai import OpenAI
class TOTSolver:
def __init__(
self,
model: str = "gpt-3.5-turbo",
api_key: Optional[str] = None,
base_url: str = ""
):
self.model = model
self.client = OpenAI(api_key=api_key, base_url=base_url) # 如果 api_key 为 None,会自动读取环境变量 OPENAI_API_KEY
def query_openai(self, prompt: str, max_retries: int = 3) -> str:
"""向 OpenAI 发送查询请求"""
messages = [
{"role": "user", "content": prompt}
]
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
timeout=60,
temperature=0.0 # 为了确定性,可设为 0
)
return response.choices[0].message.content.strip()
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt < max_retries - 1:
time.sleep(2)
else:
return ""
def _parse_text_response(self, response: str) -> Dict[str, Any]:
"""解析文本响应,处理包含JSON代码块的情况"""
# 方法1:尝试提取JSON代码块
json_match = re.search(r'```json\s*(.*?)\s*```', response, re.DOTALL)
if json_match:
try:
json_str = json_match.group(1)
return json.loads(json_str)
except:
pass # 如果提取的JSON无效,继续尝试其他方法
# 方法2:尝试直接查找JSON对象
json_match = re.search(r'\{.*?\}', response, re.DOTALL)
if json_match:
try:
json_str = json_match.group(0)
return json.loads(json_str)
except:
pass
# 方法3:基于关键词的文本分析
response_lower = response.lower()
# 检查可行性
feasible_keywords = ["feasible: true", "可行", "合理", "可以", "正确", "feasible", "reasonable", "valid", "yes"]
infeasible_keywords = ["feasible: false", "不可行", "不合理", "违反", "错误", "infeasible", "invalid", "violat",
"no"]
feasible = any(keyword in response_lower for keyword in feasible_keywords)
infeasible = any(keyword in response_lower for keyword in infeasible_keywords)
# 提取原因
reason = "无法确定具体原因"
reason_patterns = [
r'reason[:\s]*["\']?(.*?)["\']?[\s,}]',
r'原因[:\s]*["\']?(.*?)["\']?',
r'because[:\s]*["\']?(.*?)["\']?'
]
for pattern in reason_patterns:
match = re.search(pattern, response, re.IGNORECASE)
if match:
reason = match.group(1).strip()
break
# 提取置信度
confidence = "中"
if "high" in response_lower or "高" in response_lower:
confidence = "高"
elif "low" in response_lower or "低" in response_lower:
confidence = "低"
return {
"feasible": feasible and not infeasible,
"reason": reason if reason != "无法确定具体原因" else response[:200] + "..." if len(
response) > 200 else response,
"confidence": confidence
}
def evaluate_state(self, current_state: List[str], remaining_items: List[str], constraints: str) -> Dict[str, Any]:
"""评估当前状态的可行性"""
prompt = f"""
分析以下排名状态的合理性,只需要判断当前已确定的排名是否和约束条件冲突,尚未排名的人员会安排在后面:
当前已确定的排名(从前到后依次是第1名、第2名...):{current_state if current_state else "空"}
尚未排名的人员:{remaining_items}
约束条件:{constraints}
请分析:
1. 当前已确定的排名是否违反任何约束条件?
2. 当前状态是否还有继续探索的价值?
请用以下JSON格式回答,不要额外解释,不要写注释:
{{
"feasible": true/false,
"reason": "理由",
"confidence": "高/中/低"
}}
"""
response = self.query_openai(prompt)
# print(f"评估当前状态的可行性:prompt={prompt}\nres={response}")
# 尝试多种解析方法
try:
# 方法1:直接解析JSON
if response.strip().startswith('{'):
return json.loads(response.strip())
except:
# res = response.replace('\t', '').replace('\n', '').replace('\r', '')
# print(f"json格式解析错误:res={res}")
pass
# 方法2:提取JSON对象
json_match = re.search(r'\{.*?\}', response, re.DOTALL)
if json_match:
try:
return json.loads(json_match.group(0))
except:
res = response.replace('\t', '').replace('\n', '').replace('\r', '')
print(f"json格式解析错误:res={res}")
pass
# 方法3:使用改进的文本解析
return self._parse_text_response(response)
def _parse_state_generation(self, response: str, current_state: List[str], remaining_items: List[str]) -> List[
List[str]]:
"""解析状态生成响应,处理多种格式"""
states = []
response = response.strip()
json_str = ""
if response.startswith('{') and response.endswith('}'):
# 方法1:直接提取json
json_str = response
else:
# 方法2:提取JSON对象
json_match = re.search(r'\{.*?\}', response, re.DOTALL)
if json_match:
json_str = json_match.group(1)
if len(json_str) != 0:
try:
data = json.loads(json_str)
if "states" in data and isinstance(data["states"], list):
for state in data["states"]:
if isinstance(state, list) and len(state) == len(current_state) + 1:
states.append(state)
except:
res = response.replace('\t', '').replace('\n', '').replace('\r', '')
print(f"json格式解析错误:res={res}")
pass
# 方法2:尝试提取所有类似列表的结构
list_patterns = [
r'\[[^\]]*\]', # 标准列表格式
r'排名[::\s]*([A-Z][,\s]*[A-Z]*)', # 中文排名格式
r'order[:\s]*([A-Z][,\s]*[A-Z]*)' # 英文排名格式
]
found_states = []
for pattern in list_patterns:
matches = re.findall(pattern, response, re.IGNORECASE)
for match in matches:
if isinstance(match, str):
# 处理列表格式 [A, B, C]
if match.startswith('['):
try:
state = eval(match)
if isinstance(state, list):
found_states.append(state)
except:
continue
# 处理逗号分隔格式 A, B, C
else:
try:
items = [item.strip() for item in match.split(',')]
if all(item in current_state + remaining_items for item in items):
found_states.append(items)
except:
continue
# 验证并添加有效状态
for state in found_states:
# 检查状态是否包含当前状态且只多一个元素
if (len(state) == len(current_state) + 1 and
all(item in state for item in current_state) and
all(item in current_state + remaining_items for item in state)):
states.append(state)
# 方法3:如果没有找到有效状态,生成所有可能组合
if not states:
print("未解析到有效状态,生成所有可能组合")
for item in remaining_items:
new_state = current_state + [item]
states.append(new_state)
# 去重
unique_states = []
seen = set()
for state in states:
state_tuple = tuple(state)
if state_tuple not in seen:
seen.add(state_tuple)
unique_states.append(state)
return unique_states
# 生成下一步可能的状态
def generate_next_states(self, current_state: List[str], remaining_items: List[str], constraints: str) -> List[
List[str]]:
prompt = f"""
给定当前状态和约束条件,生成所有合理的下一步状态,下一步只需要让当前状态多一个项目:
当前状态:{current_state}
剩余项目:{remaining_items}
约束条件:{constraints}
请列出所有符合约束条件的下一步可能状态。
按合理性从高到低排序。
请用以下JSON格式回答,不要额外解释,不要写注释:
{{
"states": [
["A", ...],
["D", ...],
...
]
}}
"""
response = self.query_openai(prompt)
# print(f"生成下一步可能的状态:prompt={prompt}\nres={response}")
return self._parse_state_generation(response, current_state, remaining_items)
def is_complete_solution(self, state: List[str], all_items: List[str], constraints: str) -> bool:
"""检查是否为完整解决方案"""
if set(state) != set(all_items):
return False
prompt = f"""
检查以下排名是否满足所有约束条件:
完整排名:{state}
所有人员:{all_items}
约束条件:{constraints}
这个排名是否完全满足所有约束条件?
请用以下JSON格式回答,不要额外解释,不要写注释:
{{
"complete": true/false,
"reason": "简要说明"
}}
"""
response = self.query_openai(prompt)
# print(f"检查是否为完整:prompt={prompt}\nres={response}")
# 尝试解析JSON响应
try:
json_match = re.search(r'\{.*?\}', response, re.DOTALL)
if json_match:
result = json.loads(json_match.group(0))
return result.get("complete", False)
except:
pass
# 基于关键词判断
response_lower = response.lower()
complete_keywords = ["complete: true", "是", "满足", "正确", "valid", "yes", "true"]
incomplete_keywords = ["complete: false", "否", "不满足", "错误", "invalid", "no", "false"]
complete = any(keyword in response_lower for keyword in complete_keywords)
incomplete = any(keyword in response_lower for keyword in incomplete_keywords)
return complete and not incomplete
def solve(self, items: List[str], constraints: str, max_depth: int = 10) -> Optional[List[str]]:
"""使用TOT方法解决问题"""
def depth_first_search(current_state: List[str], remaining_items: List[str], depth: int) -> Optional[List[str]]:
if depth > max_depth:
return None
print(f"深度 {depth}: 探索状态 {current_state}")
if len(current_state) != 0:
# 评估当前状态
evaluation = self.evaluate_state(current_state, remaining_items, constraints)
print(f"评估结果: {evaluation}")
if not evaluation.get("feasible", True):
return None
# 检查是否完成
if self.is_complete_solution(current_state, items, constraints):
print(f"找到解决方案: {current_state}")
return current_state
# 生成下一步状态
next_states = self.generate_next_states(current_state, remaining_items, constraints)
print(f"生成 {len(next_states)} 个下一步状态 {next_states}")
# 深度优先搜索
for next_state in next_states:
new_remaining = [item for item in remaining_items if item not in next_state]
result = depth_first_search(next_state, new_remaining, depth + 1)
if result is not None:
return result
return None
return depth_first_search([], items, 0)
def main():
# 初始化TOT求解器
solver = TOTSolver(")
# 问题定义(可以替换为任何类似问题)
items = ["A", "B", "C", "D", "E"]
constraints = """
A的排名比B高。
C的排名在D之后。
E不是第一名就是最后一名。
B的排名比D高。
"""
print("开始TOT求解过程...")
print(f"项目: {items}")
print(f"约束条件: {constraints}")
print("-" * 50)
# 使用深度优先搜索
solution = solver.solve(items, constraints)
if not solution:
print("未找到任何解决方案")
if __name__ == "__main__":
main()
实践代码有点作弊,因为用的模型不是上面的llama2,我也尝试了好多小模型,因为分治后的问题本身也有点复杂,所以很难模拟,最后还是使用gpt3来跑
日志:
深度 0: 探索状态 []
生成 5 个下一步状态 [['A'], ['D'], ['B'], ['C'], ['E']]
深度 1: 探索状态 ['A']
评估结果: {'feasible': True, 'reason': '当前已确定的排名没有违反任何约束条件', 'confidence': '高'}
生成 4 个下一步状态 [['A', 'B'], ['A', 'D'], ['A', 'E'], ['A', 'C']]
深度 2: 探索状态 ['A', 'B']
评估结果: {'feasible': True, 'reason': '当前已确定的排名没有违反任何约束条件', 'confidence': '高'}
生成 4 个下一步状态 [['A', 'B', 'C'], ['A', 'B', 'E'], ['A', 'D', 'C'], ['A', 'D', 'E']]
深度 3: 探索状态 ['A', 'B', 'C']
评估结果: {'feasible': True, 'reason': '当前已确定的排名没有违反任何约束条件', 'confidence': '高'}
生成 8 个下一步状态 [['A', 'B', 'C', 'D'], ['A', 'B', 'C', 'E'], ['A', 'B', 'D', 'C'], ['A', 'B', 'E', 'C'], ['A', 'D', 'B', 'C'], ['A', 'E', 'B', 'C'], ['D', 'A', 'B', 'C'], ['E', 'A', 'B', 'C']]
深度 4: 探索状态 ['A', 'B', 'C', 'D']
评估结果: {'feasible': True, 'reason': '当前已确定的排名没有违反任何约束条件', 'confidence': '高'}
生成 6 个下一步状态 [['A', 'B', 'C', 'D', 'E'], ['A', 'B', 'D', 'C', 'E'], ['A', 'D', 'B', 'C', 'E'], ['A', 'D', 'C', 'B', 'E'], ['D', 'A', 'B', 'C', 'E'], ['D', 'A', 'C', 'B', 'E']]
深度 5: 探索状态 ['A', 'B', 'C', 'D', 'E']
评估结果: {'feasible': True, 'reason': '当前已确定的排名没有违反任何约束条件', 'confidence': '高'}
找到解决方案: ['A', 'B', 'C', 'D', 'E']
可以一次递归,5层就解决问题了,说明gpt3本身能力就很强,TOT的思想还是能体现出来
GOT
还没实践过,不过思路应该和TOT很像了,树转图
https://arxiv.org/abs/2308.09687
核心思想: 它允许任何图结构来表示和生成思维
- 聚合: 可以将多个思维合并成一个新的、更强大的思维(例如,将多个推理线索综合起来)。
- 循环: 思维可以形成环,用于迭代精化。
- 任何拓扑: 不受树结构的限制,可以模拟更复杂的推理模式。
作者提出了一种专门的查询语言(Graph of Thoughts Query Language, GQL)来方便地配置这些推理图。在排序、集合操作等任务上,其性能超过了 ToT 和 CoT。
其他参考:https://blog.csdn.net/Lvbaby_/article/details/131811653?spm=1001.2014.3001.5506

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)