20250913-04: Langchain概念:LangSmith 追踪(Tracing)
本文介绍了LangChain中的追踪(Tracing)功能及其在LangSmith平台上的实现。追踪是记录应用程序从输入到输出执行步骤的过程,对调试和诊断复杂问题至关重要。文章详细说明了如何配置LangSmith追踪功能,包括安装依赖项、设置API密钥、环境变量,以及通过代码示例展示如何追踪OpenAI调用和整个应用程序的执行流程。此外,还介绍了LangSmith平台的高级功能,如监控、自动化、收

20250913-04: Langchain概念:LangSmith 追踪(Tracing)
任务
- 阅读 LCEL 官方文档
- 理解
|操作符的底层是RunnableSequence
🎯 学习目标
理解 LangChain 的“运行时引擎”——所有组件如何被统一调度和编排。
🔗 核心概念
-
可运行接口(Runnable) -
LangChain 表达式语言(LCEL) -
回调(Callbacks) -
追踪(Tracing) -
流式传输(Streaming) -
异步编程(Async)
追踪(Tracing)
记录应用程序从输入到输出所采取步骤的过程。追踪对于调试和诊断复杂应用程序中的问题至关重要。
追踪本质上是您的应用程序从输入到输出所采取的一系列步骤。追踪包含称为运行的独立步骤。这些可以是模型、检索器、工具或子链的单独调用。追踪让您能够观察链和代理的内部,这对于诊断问题至关重要。
如需深入了解,请查看此 LangSmith 概念指南。
可观测性
- 设置跟踪:使用基本配置、与流行框架的集成以及高级配置选项来配置您的应用程序跟踪。
- 查看跟踪:通过 UI 和 API 访问和管理您的跟踪,包括筛选、导出、共享和比较跟踪。
- 监控:设置仪表板和警报以监控您的应用程序性能,并在出现问题时接收通知。
- 自动化:自动化:配置 规则、webhooks 和 在线评估 以自动化您的可观察性工作流程。
- 人类反馈:通过注释队列和行内注释收集和管理您应用程序输出的反馈。
- 追踪一个 RAG 应用:遵循一个教程从开始到结束追踪检索增强生成(RAG)应用。
开始使用 LangSmith
LangSmith 是一个用于构建生产级 LLM 应用程序的平台。监控和评估您的应用程序,以便您可以快速且自信地发布。
LangSmith 是框架无关的——您可以使用它,无论是否使用 LangChain 的开源框架 langchain 和 langgraph。
LangSmith 追踪快速入门
可观测性对任何软件应用都很重要,但对于LLM应用来说尤其如此。LLMs本质上是非确定性的,这意味着它们可能会产生意外的结果。这使得它们比普通应用更难调试。
这是 LangSmith 能帮到你的地方!LangSmith 让你能够看到你的应用程序在处理请求时每一步的可见性——帮助你更快地调试并增强你对应用程序的信心。从原型设计到生产,LangSmith 通过** 跟踪 ** **、 过滤 、 图表 和 警报 **来确保你的应用程序在规模上保持可靠性。
安装依赖项
pip install -U langsmith openai
创建 API 密钥
创建 API 密钥,请前往LangSmith 设置页面。然后点击 + API 密钥。
设置环境变量
如果您的 LangSmith API 密钥链接到多个工作区,请设置LANGSMITH_WORKSPACE_ID环境变量以指定要使用的工作区。
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="<your-langsmith-api-key>"
export OPENAI_API_KEY="<your-openai-api-key>"
export LANGSMITH_WORKSPACE_ID="<your-workspace-id>"
定义您的应用程序
我们将为这个教程创建一个简单的 RAG 应用程序,但如果你愿意,也可以使用你自己的代码——只需确保它有一个LLM调用!
from openai import OpenAI
openai_client = OpenAI()
# This is the retriever we will use in RAG
# This is mocked out, but it could be anything we want
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
# This is the end-to-end RAG chain.
# It does a retrieval step then calls OpenAI
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
跟踪 OpenAI 调用
首先,您可能想要追踪所有您的 OpenAI 调用。LangSmith 通过wrap_openai(Python)或wrapOpenAI(TypeScript)包装器使这变得简单。您只需修改代码,使用包装后的客户端而不是直接使用OpenAI客户端即可。
from openai import OpenAI
from langsmith.wrappers import wrap_openai
#
openai_client = wrap_openai(OpenAI())
# This is the retriever we will use in RAG
# This is mocked out, but it could be anything we want
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
# This is the end-to-end RAG chain.
# It does a retrieval step then calls OpenAI
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
现在当你按照以下方式调用你的应用程序时:
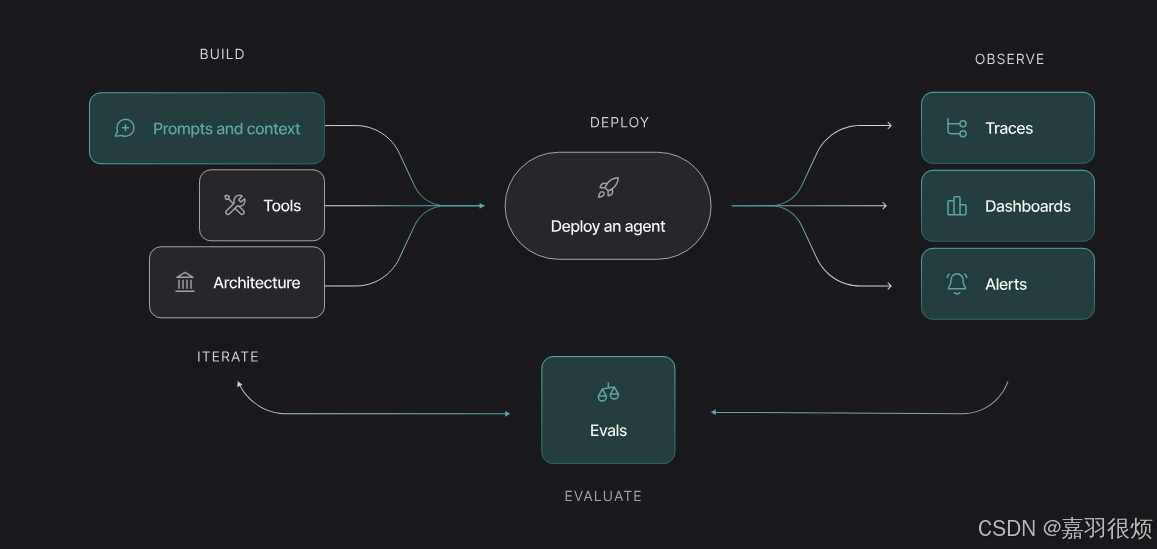
rag("where did harrison work")
这将生成 LangSmith 默认跟踪项目中仅针对 OpenAI 调用的跟踪。它看起来应该像这样。
跟踪整个应用程序
您还可以使用 traceable 装饰器(Python 或 TypeScript)来跟踪您的整个应用程序,而不仅仅是 LLM 调用。
from openai import OpenAI
from langsmith import traceable
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(OpenAI())
def retriever(query: str):
results = ["Harrison worked at Kensho"]
return results
#
@traceable
def rag(question):
docs = retriever(question)
system_message = """Answer the users question using only the provided information below:
{docs}""".format(docs="\n".join(docs))
return openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
现在如果您按照以下方式调用您的应用程序:
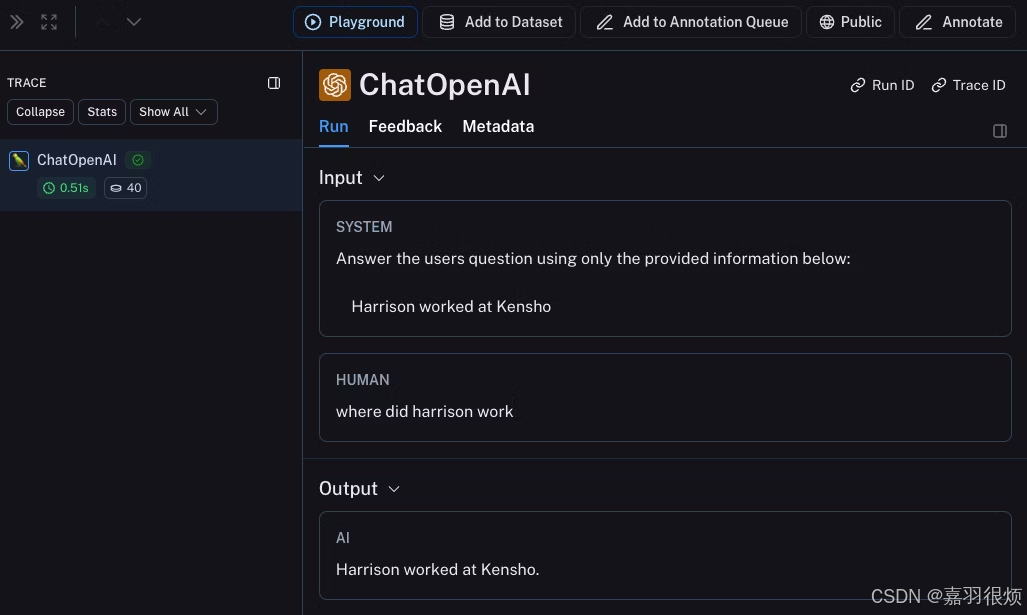
rag("where did harrison work")
这将生成整个管道的跟踪(包括作为子运行的 OpenAI 调用)- 它应该看起来像这样 这
追踪 LangChain(Python 和 JS/TS)
安装
安装核心库和 Python 和 JS 的 OpenAI 集成(以下代码片段使用 OpenAI 集成)。
pip install langchain_openai langchain_core
快速入门
配置您的环境
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY=<your-api-key>
# This example uses OpenAI, but you can use any LLM provider of choice
export OPENAI_API_KEY=<your-openai-api-key>
# For LangSmith API keys linked to multiple workspaces, set the LANGSMITH_WORKSPACE_ID environment variable to specify which workspace to use.
export LANGSMITH_WORKSPACE_ID=<your-workspace-id>
记录跟踪
无需额外代码即可将跟踪记录到 LangSmith。只需像平时一样运行您的 LangChain 代码即可。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant. Please respond to the user's request only based on the given context."),
("user", "Question: {question}\nContext: {context}")
])
model = ChatOpenAI(model="gpt-4o-mini")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
question = "Can you summarize this morning's meetings?"
context = "During this morning's meeting, we solved all world conflict."
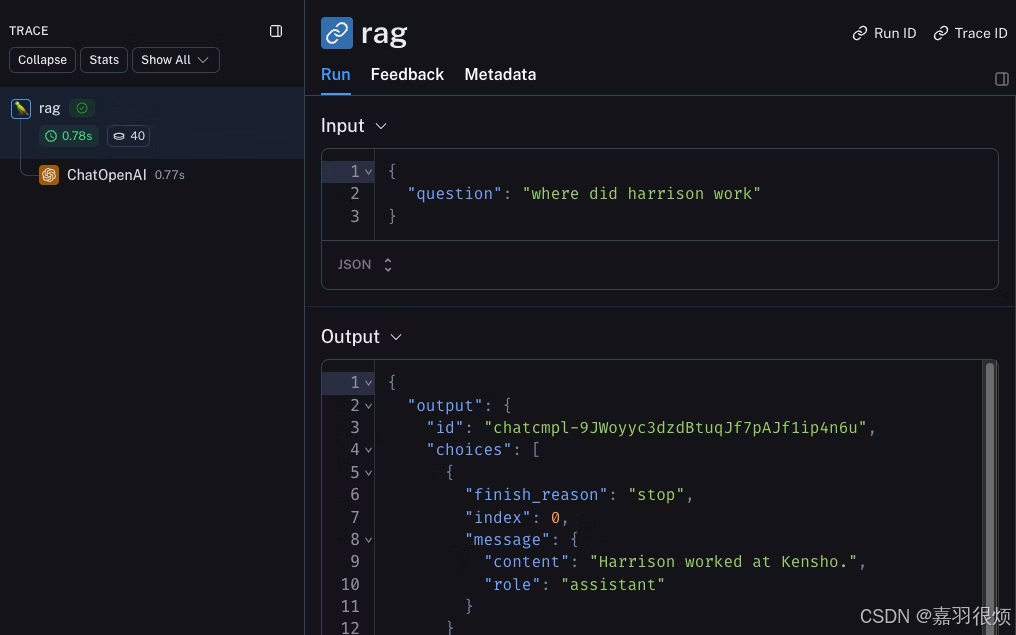
chain.invoke({"question": question, "context": context})
查看您的跟踪
默认情况下,跟踪信息将被记录到名为 default 的项目中。使用上述代码记录的跟踪示例已公开发布,并可在此 查看。
选择追踪
上一节介绍了如何通过设置单个环境变量来跟踪应用程序中 LangChain 可运行对象的全部调用。虽然这是一种方便的入门方式,但你可能只想跟踪特定的调用或应用程序的某些部分。
Python 中有两种方法来做这件事:通过手动传递一个 LangChainTracer (参考文档)实例作为回调,或者使用 tracing_context 上下文管理器 (参考文档)。
LangChainTracer
在 JS/TS 中,您可以将一个LangChainTracer(参考文档)实例作为回调传递。
# You can opt-in to specific invocations..
import langsmith as ls
with ls.tracing_context(enabled=True):
chain.invoke({"question": "Am I using a callback?", "context": "I'm using a callback"})
# This will NOT be traced (assuming LANGSMITH_TRACING is not set)
chain.invoke({"question": "Am I being traced?", "context": "I'm not being traced"})
# This would not be traced, even if LANGSMITH_TRACING=true
with ls.tracing_context(enabled=False):
chain.invoke({"question": "Am I being traced?", "context": "I'm not being traced"})
记录到特定项目
静态地
如《跟踪概念指南》中所述,LangSmith 使用项目概念来分组跟踪。如果未指定,跟踪器项目将设置为默认值。您可以通过设置 LANGSMITH_PROJECT 环境变量来为整个应用程序运行配置自定义项目名称。这应该在执行应用程序之前完成。
export LANGSMITH_PROJECT=my-project
动态
这主要基于上一节,并允许您为特定的LangChainTracer实例设置项目名称,或将项目名称作为 Python 中tracing_context上下文管理器的参数。
# You can set the project name using the project_name parameter.
import langsmith as ls
with ls.tracing_context(project_name="My Project", enabled=True):
chain.invoke({"question": "Am I using a context manager?", "context": "I'm using a context manager"})
添加元数据和标签到跟踪
您可以通过在RunnableConfig中提供它们来使用任意元数据和标签来注释您的跟踪,这有助于将附加信息与跟踪相关联,例如执行它的环境或启动它的用户。有关如何通过元数据和标签查询跟踪和运行的说明,请参阅本指南。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI."),
("user", "{input}")
])
# The tag "model-tag" and metadata {"model-key": "model-value"} will be attached to the ChatOpenAI run only
chat_model = ChatOpenAI().with_config({"tags": ["model-tag"], "metadata": {"model-key": "model-value"}})
output_parser = StrOutputParser()
# Tags and metadata can be configured with RunnableConfig
chain = (prompt | chat_model | output_parser).with_config({"tags": ["config-tag"], "metadata": {"config-key": "config-value"}})
# Tags and metadata can also be passed at runtime
chain.invoke({"input": "What is the meaning of life?"}, {"tags": ["invoke-tag"], "metadata": {"invoke-key": "invoke-value"}})
自定义运行名称
您可以在调用或流式传输 LangChain 代码时,通过在配置中提供来自定义给定运行的名称。此名称用于在 LangSmith 中识别运行,可用于过滤和分组运行。此名称还用作 LangSmith UI 中运行的标题。这可以通过在构造RunnableConfig对象时设置run_name或通过在 JS/TS 调用参数中传递run_name来实现。
# When tracing within LangChain, run names default to the class name of the traced object (e.g., 'ChatOpenAI').
configured_chain = chain.with_config({"run_name": "MyCustomChain"})
configured_chain.invoke({"input": "What is the meaning of life?"})
# You can also configure the run name at invocation time, like below
chain.invoke({"input": "What is the meaning of life?"}, {"run_name": "MyCustomChain"})
自定义运行 ID
您可以通过在配置中提供 ID 来在调用或流式传输 LangChain 代码时自定义给定运行的 ID。此 ID 用于在 LangSmith 中唯一标识运行,并可用于查询特定运行。该 ID 可用于在不同系统之间链接运行或实现自定义跟踪逻辑。这可以通过在构造RunnableConfig对象时设置run_id或在调用参数中传递run_id来实现。
import uuid
my_uuid = uuid.uuid4()
# You can configure the run ID at invocation time:
chain.invoke({"input": "What is the meaning of life?"}, {"run_id": my_uuid})
请注意,如果您在跟踪的根目录(即顶级运行)处执行此操作,则该运行 ID 将被用作跟踪 ID(即trace_id)。
访问 LangChain 调用的运行(跨度)ID
当你调用 LangChain 对象时,你可以手动指定调用的运行 ID。这个运行 ID 可以用于在 LangSmith 中查询运行。
在 JS/TS 中,您可以使用一个RunCollectorCallbackHandler实例来访问运行 ID。
确保在退出前提交所有跟踪信息
在 LangChain Python 中,LangSmith 的追踪是在后台线程中完成的,以避免阻塞您的生产应用程序。
这意味着您的进程可能在所有跟踪成功发布到 LangSmith 之前就结束了。这在无服务器环境中尤为常见,一旦您的链或代理完成,您的虚拟机可能会立即终止。
您可以通过将环境变量 LANGCHAIN_CALLBACKS_BACKGROUND 设置为 “false” 来使回调同步。
对于两种语言,LangChain 都提供了在退出应用程序之前等待跟踪提交的方法。以下是一个示例:
from langchain_openai import ChatOpenAI
from langchain_core.tracers.langchain import wait_for_all_tracers
llm = ChatOpenAI()
try:
llm.invoke("Hello, World!")
finally:
wait_for_all_tracers()
跟踪而不设置环境变量
如其他指南中所述,以下环境变量允许您配置启用跟踪、API 端点、API 密钥和跟踪项目:
然而,在某些环境中,无法设置环境变量。在这种情况下,您可以以编程方式设置跟踪配置。
这主要基于之前的部分。
import langsmith as ls
# You can create a client instance with an api key and api url
client = ls.Client(
api_key="YOUR_API_KEY", # This can be retrieved from a secrets manager
api_url="https://api.smith.langchain.com", # Update appropriately for self-hosted installations or the EU region
)
# You can pass the client and project_name to the tracing_context
with ls.tracing_context(client=client, project_name="test-no-env", enabled=True):
chain.invoke({"question": "Am I using a callback?", "context": "I'm using a callback"})
分布式追踪与 LangChain(Python)
LangSmith 支持 LangChain Python 的分布式追踪。这允许您将不同服务和应用程序的运行(跨度)链接起来。其原理与 LangSmith SDK 的分布式追踪指南类似。
import langsmith
from langchain_core.runnables import chain
from langsmith.run_helpers import get_current_run_tree
# -- This code should be in a separate file or service --
@chain
def child_chain(inputs):
return inputs["test"] + 1
def child_wrapper(x, headers):
with langsmith.tracing_context(parent=headers):
child_chain.invoke({"test": x})
# -- This code should be in a separate file or service --
@chain
def parent_chain(inputs):
rt = get_current_run_tree()
headers = rt.to_headers()
# ... make a request to another service with the headers
# The headers should be passed to the other service, eventually to the child_wrapper function
#
parent_chain.invoke({"test": 1})
复习知识点
核心概念:追踪 (Tracing)
- 一句话定义:追踪是记录 LLM 应用程序从输入到输出所采取的一系列步骤(称为“运行”或“跨度”)的过程,用于调试和诊断复杂问题。
- 追踪的组成:一个追踪包含多个独立的运行 (Runs) ,每个运行代表模型、检索器、工具或子链的一次调用。
- 核心价值:追踪让您能够观察链和代理的内部执行过程,这对于诊断非确定性 LLM 行为产生的问题至关重要。
核心平台:LangSmith
- 一句话定义:LangSmith 是一个用于构建生产级 LLM 应用程序的平台,提供监控、评估和可观测性功能。
- 关键特性:框架无关,即使不使用 LangChain 开源框架,也可以使用 LangSmith。
- 核心功能:通过跟踪、过滤、图表和警报来确保应用程序在规模上的可靠性。
重要说明与配置
- 启用全局追踪:通过设置环境变量
LANGSMITH_TRACING=true来启用追踪,所有 LangChain 可运行对象的调用将被自动记录。 - 必备配置:必须设置
LANGSMITH_API_KEY和OPENAI_API_KEY等环境变量才能将数据发送到 LangSmith 平台。 - 选择式追踪:并非必须全局开启追踪,可以使用
tracing_context(enabled=True/False)上下文管理器或传递LangChainTracer回调来精确控制哪些调用被追踪。 - 项目分组:追踪默认记录到
default项目,可通过设置LANGSMITH_PROJECT环境变量或使用tracing_context(project_name="...")来指定自定义项目名称,用于对追踪进行分组。 - 自定义元数据:可以通过
RunnableConfig为追踪添加标签 (tags) 和元数据 (metadata) ,便于后续的查询、过滤和分析。 - 自定义运行名称:通过在配置中设置
run_name可以覆盖 LangSmith UI 中显示的运行标题,默认为被追踪对象的类名。 - 自定义运行 ID:可以通过配置自定义
run_id,此 ID 在根运行时将同时作为追踪 ID (trace_id) ,用于跨系统链接运行或实现自定义逻辑。
高级主题与警告
- 异步提交机制:追踪在后台线程中异步完成,以避免阻塞主应用程序。
- 关键警告:在无服务器等环境中,进程可能在追踪数据发送前终止,必须调用
wait_for_all_tracers() 来确保所有追踪信息在退出前被提交。 - 编程式配置:在无法设置环境变量的场景中,可以通过代码实例化
langsmith.Client 并传入 api_key 等参数来配置追踪。 - 分布式追踪:支持通过
get_current_run_tree().to_headers()获取当前上下文并注入到跨服务请求的 header 中,从而将不同服务或应用程序的跨度链接成一个完整的分布式追踪。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)