【LLM】具有训练推理性价比的Qwen3-Next模型
基于 Qwen3-Next-80B-A3B-Base型, 同步开发并发布了Qwen3-Next-80B-A3B-Instruct与Qwen3-Next-80B-A3B-Thinking- 认为Context Length Scaling和Total Parameter Scaling是未来大模型发展的两大趋势,为了进一步提升模型在长上下文和大规模总参数下的训练和推理效率,我们设计了全新的Qwen3
note
- 基于 Qwen3-Next-80B-A3B-Base型, 同步开发并发布了Qwen3-Next-80B-A3B-Instruct与Qwen3-Next-80B-A3B-Thinking
- 认为Context Length Scaling和Total Parameter Scaling是未来大模型发展的两大趋势,为了进一步提升模型在长上下文和大规模总参数下的训练和推理效率,我们设计了全新的Qwen3-Next的模型结构。该结构相比Qwen3的MoE模型结构,进行了以下核心改进:混合注意力机制、高稀疏度 MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多 token 预测机制。
- 基于Qwen3-Next的模型结构,我们训练了Qwen3-Next-80B-A3B-Base模型,该模型拥有800亿参数仅激活30亿参数。该Base模型实现了与Qwen3-32B dense模型相近甚至略好的性能,而它的训练成本(GPU hours) 仅为Qwen3-32B的十分之一不到,在32k以上的上下文下的推理吞吐则是Qwen3-32B的十倍以上,实现了极致的训练和推理性价比。
- 解决了混合注意力机制+高稀疏度 MoE 架构在强化学习训练中长期存在的稳定性与效率难题,实现了RL训练效率与最终效果的双重提升。、
- 极致稀疏MoE: 仅激活3.7%参数。Qwen3-Next采用了高稀疏度的Mixture-of-Experts(MoE) 架构, 总参数量达80B,每次推理仅激活约3B参数。我们实验表明,在使用全局负载均衡[4]后,当激活专家固定时,持续增加专家总参数可带来训练loss的稳定下降。相比Qwen3-MoE的128个总专家和8个路由专家,Qwen3-Next我们扩展到了512总专家,10路由专家与1共享专家的组合,在不牺牲效果的前提下最大化资源利用率。
- 训练方法:混合注意力 + MoE + MTP 等机制。使用适合长上下文的策略,比如引入部分线性/sparse attention 层,以及 positional encoding 的处理方式以支持 extrapolation(即模型遇到比训练中更长的输入也能较好表现)
文章目录
一、模型架构
- 为了进一步提升模型在长上下文和大规模总参数下的训练和推理效率,我们设计了全新的Qwen3-Next的模型结构。该结构相比Qwen3的MoE模型结构,进行了以下核心改进:混合注意力机制、高稀疏度 MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多 token 预测机制。
- 基于Qwen3-Next的模型结构,我们训练了Qwen3-Next-80B-A3B-Base模型,该模型拥有800亿参数仅激活30亿参数。该Base模型实现了与Qwen3-32B dense模型相近甚至略好的性能,而它的训练成本(GPU hours) 仅为Qwen3-32B的十分之一不到,在32k以上的上下文下的推理吞吐则是Qwen3-32B的十倍以上,实现了极致的训练和推理性价比。
- 解决了混合注意力机制+高稀疏度 MoE 架构在强化学习训练中长期存在的稳定性与效率难题,实现了RL训练效率与最终效果的双重提升。

相关技术亮点:
| 技术 | 用来解决什么问题 / 为什么要用 | 怎么做的 /特点 |
|---|---|---|
| 混合注意力机制(Hybrid Attention) / Gated DeltaNet + Gated Attention | 标准全注意力(full softmax attention)在长上下文时开销非常大;线性注意力/稀疏注意力虽然效率高,但 recall(召回能力、对远距离依赖/细节捕捉)可能会弱。 | 在很多层里用 Gated DeltaNet(或类似线性注意力变体),在部分层里保留标准注意力;加入 gate (门控) 的机制来调节哪些信息/距离/维度被重点关注,这样兼顾性能与效率。 (Qbitai) |
| 超稀疏 MoE(Mixture‑of‑Experts)结构 | 希望模型参数量大以增强能力,但在每次推理时只用到少部分专家,节省计算/内存资源。 | 总参数比较大(例如 80B),但每次推理/激活(active)只有少量专家被调用(激活参数例如约 3B),稀疏性非常高。路由器设计、专家数量设计、初始化等都做针对性优化。 (Qbitai) |
| Multi‑Token Prediction (MTP)(多 token 预测) | 自回归模型每次只生成一个 token → 推理速度瓶颈;长文本输入/大输出时效率低。 | 在训练时加入能够一次预测多个 token 的任务/机制,这样在推理阶段可以并行预测多个 token,从而加速生成。还配合 Speculative Decoding(猜测式解码/先预测多个 token 再校验)来提升效率。 (Qbitai) |
| 训练稳定性增强 | 大模型 + 高稀疏 + 长上下文等设计很容易引起训练不稳定,比如梯度爆炸/权重发散/loss spikes/注意力分布异常等。 | 采取了诸如 Zero‑Centered RMSNorm(规范化层/归一化但中心设为零的 RMSNorm),并对 Norm 类的权重施加 weight decay,以防范这些权重无界增长。对 MoE 路由器初始化做归一化,以保证早期各专家被公平选择,减少偏差。还有注意力输出的 gate 控制,防止特定 token(比如首 token 或某些位置)得到过多 attention “偏见/偏重” 的问题。 (Qbitai) |
1、混合架构:GatedDeltaNet+GatedAttention
线性注意力打破了标准注意力的二次复杂度,在处理长上下文时有着更高的效率。我们发现,单纯使用线性注意力或标准注意力均存在局限:前者在长序列建模上效率高但召回能力弱,后者计算开销大、推理不友好。通过系统实验,我们发现Gated DeltaNet 1相比常用的滑动窗口注意力(Sliding Window Attention)和 Mamba2有更强的上下文学习(in-context learning)能力, 并在3:1的混合比例(即75%层使用 Gated DeltaNet,25%层保留标准注意力)下能一致超过超越单一架构,实现性能与效率的双重优化。
在保留的标准注意力中,我们进一步引入多项增强设计:(1)沿用我们先前工作[2]中的输出门控机制,缓解注意力中的低秩问题。(2)将单个注意力头维度从128扩展至256。(3)仅对注意力头前25%的位置维度添加旋转位置编码,提高长度外推效果。
2、极致稀疏MoE: 仅激活3.7%参数
Qwen3-Next采用了高稀疏度的Mixture-of-Experts(MoE) 架构, 总参数量达80B,每次推理仅激活约3B参数。我们实验表明,在使用全局负载均衡[4]后,当激活专家固定时,持续增加专家总参数可带来训练loss的稳定下降。相比Qwen3-MoE的128个总专家和8个路由专家,Qwen3-Next我们扩展到了512总专家,10路由专家与1共享专家的组合,在不牺牲效果的前提下最大化资源利用率。
3、训练稳定性友好设计
我们发现,注意力输出门控机制能消除注意力池[5]与极大激活[6]等现象,保证模型各部分的数值稳定。
在Qwen3中我们采用了QK-Norm,我们发现部分层的 norm weight值会出现异常高的现象。为了缓解这一现象,进一步提高模型的稳定性,我们在Qwen3-Next中采用了Zero-Centered RMSNorm[7],并在此基础上, 对norm weight 施加weight decay, 以避免权重无界增长。
我们还在初始化时归一化了 MoE router的参数[8],确保每个expert在训练早期都能被无偏地选中,减小初始化对实验结果的扰动。
这些稳定友好设计既使得我们小规模实验结果更为可靠,也帮助最终scaling up实验稳定进行。
QK‑Norm背景介绍:
(1)QK‑Norm:QK‑Norm 是在 Transformer 架构里,对 Query(Q) 和 Key(K) 向量进行正规化(normalization)的一种技术。也就是说,在注意力 (attention) 的点积(dot‑product)发生之前或在这个过程当中,对 Q 和 K 向量先做标准化处理,以控制它们的范数(norm)不至于变得过大,从而避免训练不稳定或得到过极端的注意力分布。
(2)在 transformer 的 self-attention 中,有一个公式类似: Attention ( Q , K , V ) = softmax ( Q K T d ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d}}\right) V Attention(Q,K,V)=softmax(dQKT)V
其中 d d d 是 head 的维度。问题在于:
- 如果 Q 或 K 的向量范数过大(norm 很大),那么 Q K T Q K^T QKT 的结果中每一个 logit(softmax 之前的输入)可能非常大。
- Softmax 对 logarithm 输入非常敏感:大的正数使 softmax 输出趋近 one-hot(一个 token 或一个 key占比几乎全注意力),注意力分布崩塌(attention entropy collapse)。这样训练就容易失稳。
- 特别是在包含多种模态(multimodal,比如图像、文本、音频等混合输入)或者不同 token 类型、不同 embedding 范围的情况下,不同模态或类型的 Q 或 K 的 variance(方差)/scale 差别可能很大,导致某些模态的 Q-K 掩盖其他模态。
-使用较大 learning rate 时,这种不稳定更容易导致训练过程发散。
因此,对 Q 和 K 做规范化(normalization)可以控制它们的范数/分布,使得 dot-product 输入的 scale 更可控,从而提升训练稳定性。
4、Multi-Token Prediction
Qwen3-Next 引入原生 Multi-Token Prediction 机制[3][9],既得到了 Speculative Decoding 接受率较高的 MTP 模块,又提升了主干本身的综合性能。
Qwen3-Next 还特别优化了 MTP 多步推理性能,通过训练推理一致的多步训练,进一步提高了实用场景下的 Speculative Decoding 接受率。
二、模型训练
1、预训练
训练效率及推理效率:
Qwen3-Next 采用的是 Qwen3 36T 预训练语料的一个均匀采样子集,仅包含 15T tokens。其训练所消耗的 GPU Hours 不到 Qwen3-30A-3B 的 80%;而与 Qwen3-32B 相比,仅需 9.3% 的 GPU 计算资源,即可实现更优的模型性能,展现出极高的训练效率与性价比。
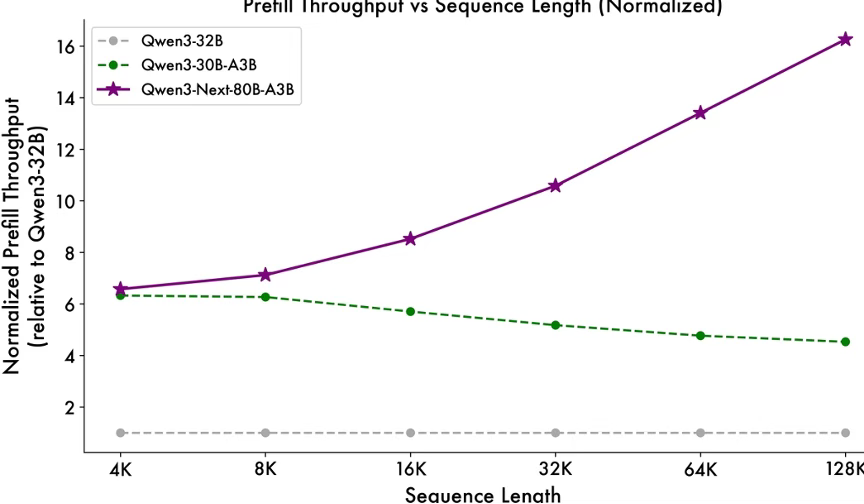
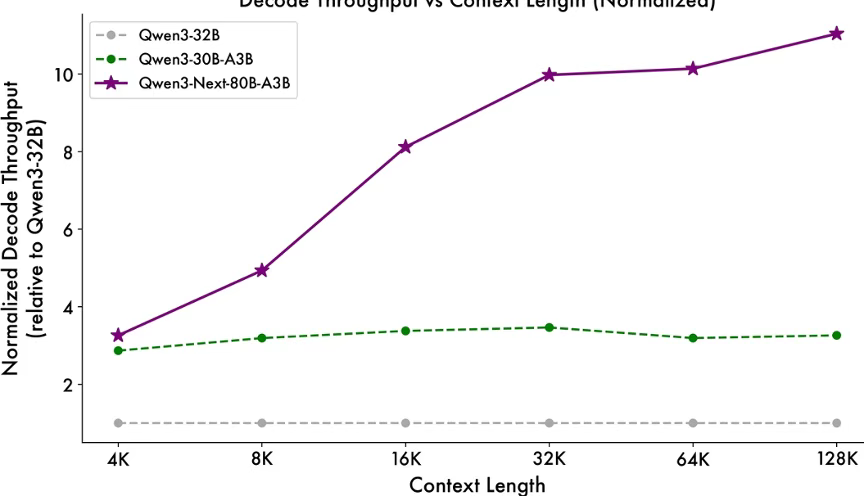
得益于创新的混合模型架构,Qwen3-Next 在推理效率方面表现出显著优势。与 Qwen3-32B 相比,Qwen3-Next-80B-A3B 在预填充(prefill)阶段展现出卓越的吞吐能力:在 4k tokens 的上下文长度下,吞吐量接近前者的七倍;当上下文长度超过 32k 时,吞吐提升更是达到十倍以上。
在解码(decode)阶段,该模型同样表现优异——在 4k 上下文下实现近四倍的吞吐提升,而在超过 32k 的长上下文场景中,仍能保持十倍以上的吞吐优势。
2、后训练
instruct模型效果(如下图):Qwen3-Next-80B-A3B-Instruct 显著优于 Qwen3-30B-A3B-Instruct-2507 和 Qwen3-32B-Non-thinking,并取得了几乎与 Qwen3-235B-A22B-Instruct-2507 相近的结果。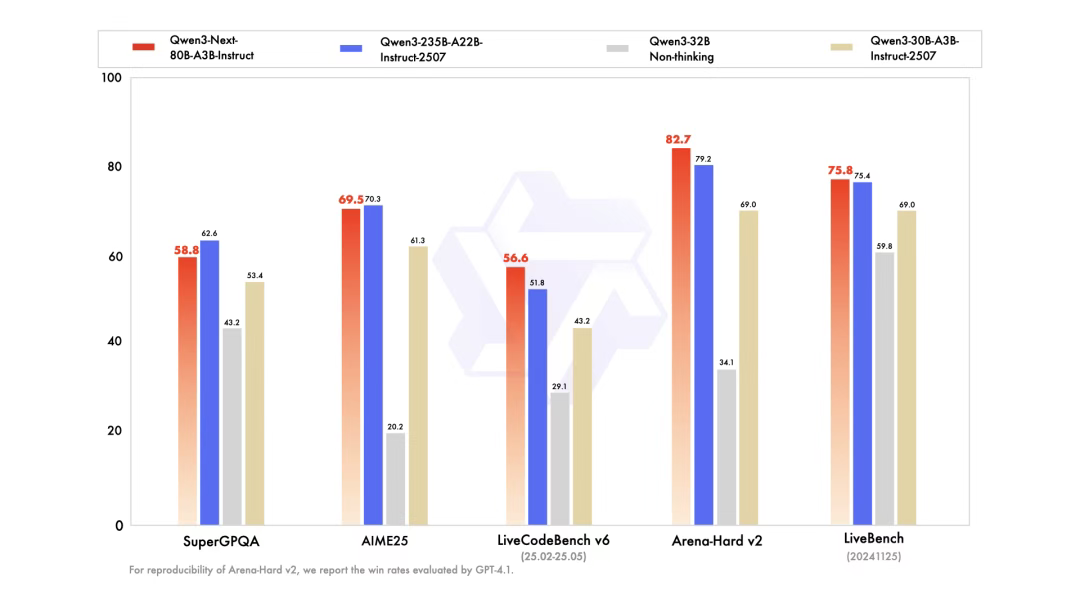
Qwen3-Next-80B-A3B-Instruct 在RULER上所有长度的表现明显优于层数相同、注意力层数更多的 Qwen3-30B-A3B-Instruct-2507,甚至在 256k 范围内都超过了层数更多的 Qwen3-235B-A22B-Instruct-2507,这展示了 Gated DeltaNet 与 Gated Attention 混合模型在长文本情景下的优越性。
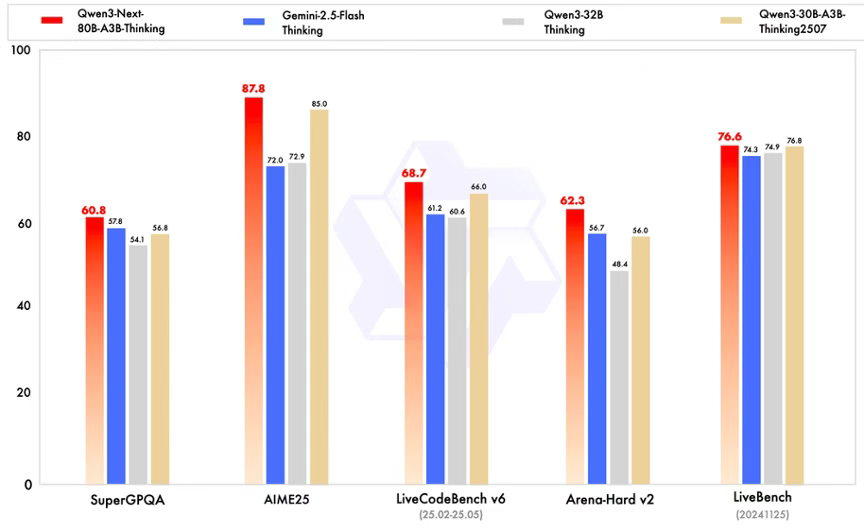
Qwen3-Next-80B-A3B-Thinking 优于预训练成本更高的 Qwen3-30B-A3B-Thinking-2507 和 Qwen3-32B-thinking,超过了闭源的模型 Gemini-2.5-Flash-Thinking,并在部分指标上接近了我们的最新的旗舰模型 Qwen3-235B-A22B-Thinking-2507。
三、模型效果
解决了混合注意力机制+高稀疏度 MoE 架构在强化学习训练中长期存在的稳定性与效率难题,实现了RL训练效率与最终效果的双重提升。
Qwen3-Next-80B-A3B-Instruct与旗舰模型 Qwen3-235B-A22B-Instruct-2507表现相当,同时在256K超长上下文处理任务中展现出显著优势。Qwen3-Next-80B-A3B-Thinking在复杂推理任务上表现卓越,不仅优于预训练成本更高的Qwen3-30B-A3B-Thinking-2507与Qwen3-32B-Thinking,更在多项基准测试中超越闭源模型Gemini-2.5-Flash-Thinking,部分关键指标已逼近我们Qwen3-235B-A22B-Thinking-2507。
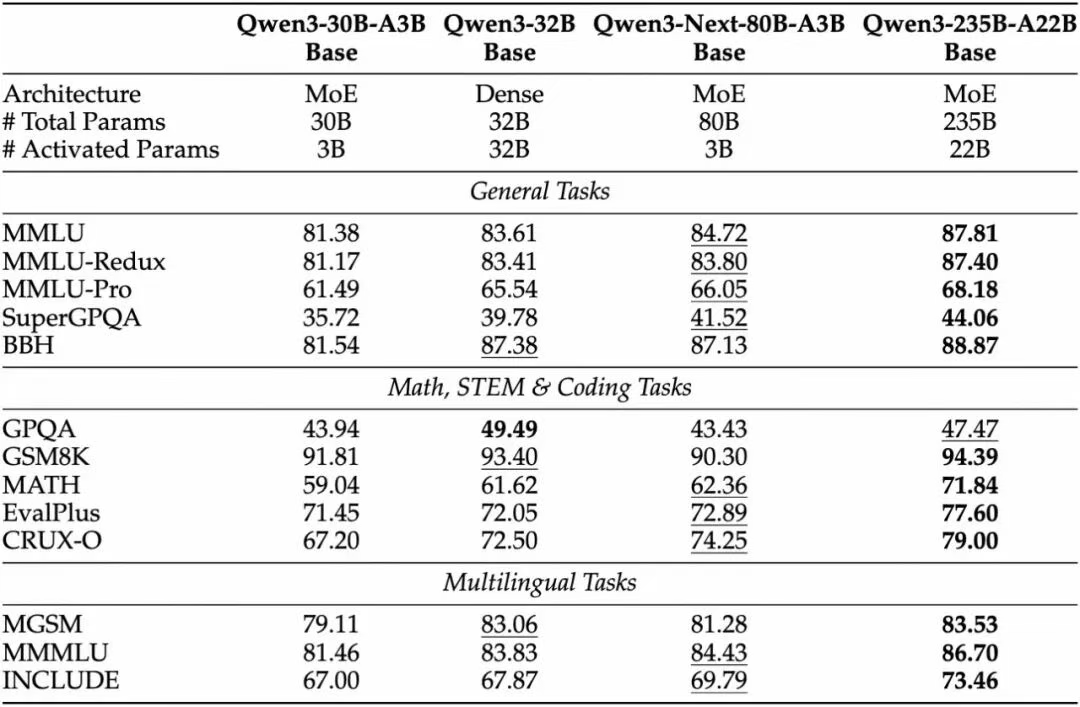
Qwen3-Next-80B-A3B-Base 仅使用十分之一的 Non-Embedding 激活参数,在大多数基准测试中便已超越 Qwen3-32B-Base,且显著优于 Qwen3-30B-A3B,展现出卓越的模型效率与性能优势。
Reference
1 Gated Delta Networks: Improving Mamba2 with Delta Rule
[2] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
[3] DeepSeek-V3 Technical Report
[4] Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
[5] Qwen3-Next:迈向更极致的训练推理性价比
[6] 聊一下Qwen3-Next-80B-A3B实测感受!附测试用例!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)