AI基础学习周报十三
本周聚焦扩散模型与Mamba模型的创新方法。系统研究了DiT模型的核心机制,包括图像分块嵌入策略、四种条件嵌入方案及其参数初始化策略;深入推导了扩散模型的数学原理;研读了论文CCViM,其创新性地将上下文聚类与视觉状态空间模型结合,通过局部网格聚类增强VMamba的全局建模能力。
摘要
本周聚焦扩散模型与Mamba模型的创新方法。系统研究了DiT模型的核心机制,包括图像分块嵌入策略、四种条件嵌入方案及其参数初始化策略;深入推导了扩散模型的数学原理;研读了论文CCViM,其创新性地将上下文聚类与视觉状态空间模型结合,通过局部网格聚类增强VMamba的全局建模能力。
Abstract
This week’s focus is on innovative approaches in diffusion models and Mamba models. We systematically investigated the core mechanisms of the DiT model, including its image patch embedding strategy, four conditional embedding schemes, and parameter initialization strategies. An in-depth derivation of the mathematical principles underlying diffusion models was also conducted. Additionally, we studied the paper CCViM, which innovatively integrates context clustering with vision state space models, enhancing the global modeling capability of VMamba through local grid clustering.
1、DiT(Diffusion Transformer)模型
DiT(Diffusion Transformer)模型由Meta在2022年首次提出,其主要是在ViT(Vision Transformer)架构基础上进行优化设计得到的。DiT是基于Transformer架构的扩散模型,将扩散模型中经典的U-Net架构完全替换成了Transformer架构。同时DiT是一个可扩展的架构,DiT不仅证明了Transformer思想与扩散模型结合的有效性,并且还验证了Transformer架构在扩散模型上具备较强的Scaling能力(Scalability),在稳步增大DiT模型参数量和增强训练数据质量时,DiT的生成性能稳步提升。其中最大的DiT-XL/2模型在ImageNet 256x256的类别条件生成任务上达到了2022年的SOTA(FID为2.27)性能。
DiT的本质:Diffusion Transformer是一种新型的扩散模型,结合了去噪扩散概率模型(DDPM)和Transformer架构。
1.1 输入图像的Patch化
DiT和ViT一样,首先采用Patch Embedding策略将输入图像Patch化,主要作用是将VAE编码后的二维特征转化为一维序列,从而得到一系列的图像tokens,具体如下图所示:
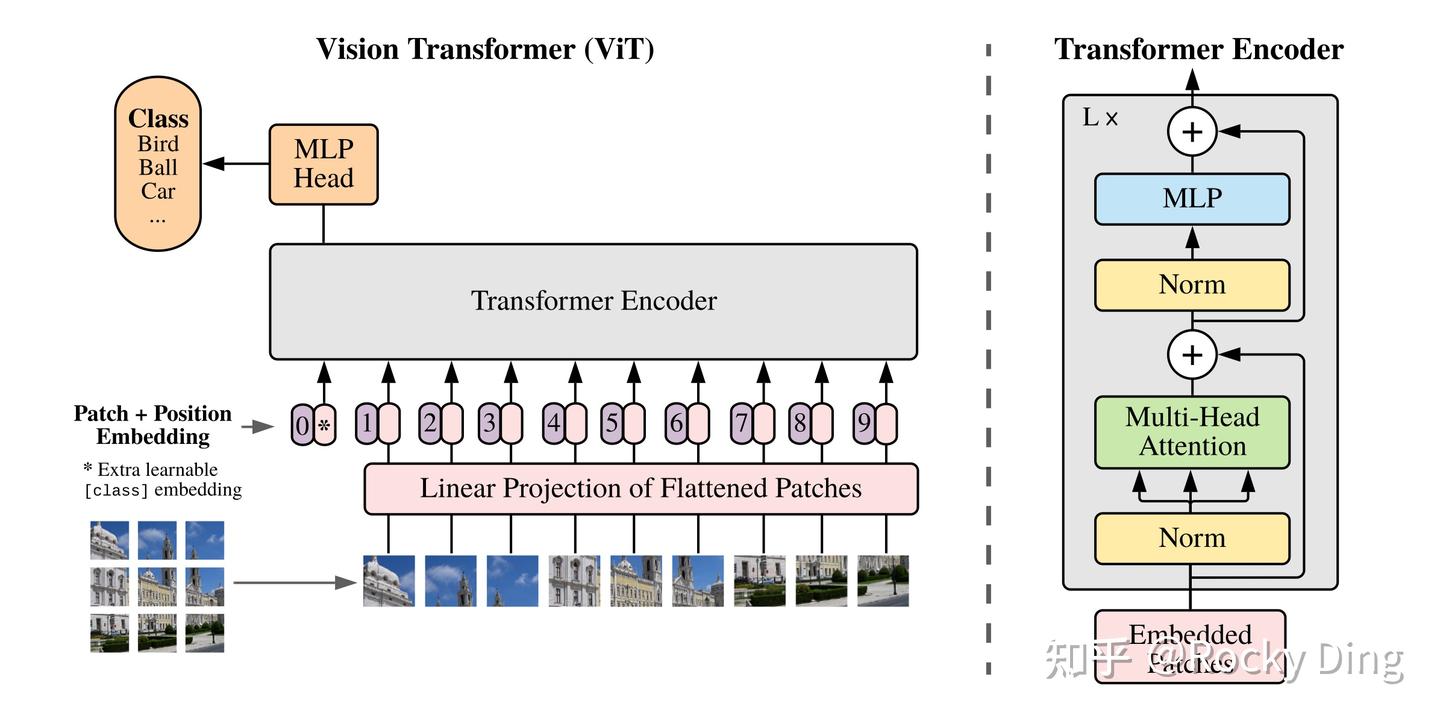
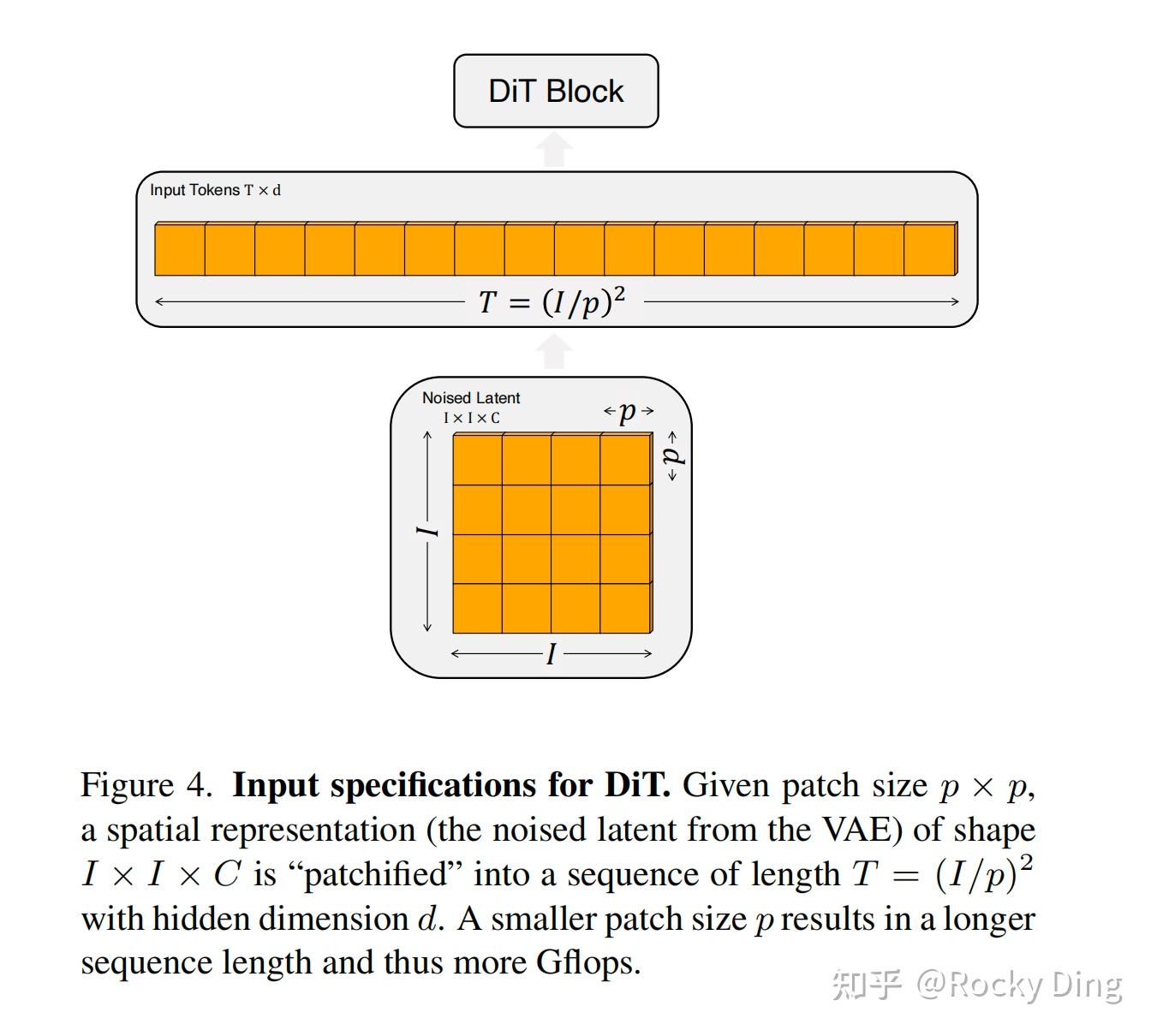
同时,DiT在这个图像Patch化的过程中,设计了patch size这个超参数,它直接决定了图像tokens的大小和数量,从而影响DiT模型的整体计算量。DiT论文中共设置了三种patch size,分别是p=2,4,8。同时和其他Transformer模型一样,在得到图像tokens后,还要加上Positional Embeddings进行位置编码,DiT中采用经典的非学习sin&cosine位置编码技术。具体流程如下图所示:
1.2 DiT Block模块
DiT在完成输入图像的预处理后,就要将Latent特征输入到Backbone网络中进行特征的提取了,DiT设计了和ViT模型类似的Backbone主干网络,全部由Transformer Blocks构成。但与ViT不同的是,DiT作为扩散模型还需要在Backbone主干网络中嵌入额外的条件信息(不同模态的条件信息等),这里的条件信息就包括了Timesteps以及类别标签等。
总的来说,DiT中的Backbone网络主要进行了两个工作,一个是常规的图像特征提取,另外一个是对图像特征和额外的多模态条件特征进行融合处理。
一般来说,无论是Timesteps还是类别标签,这些额外信息都可以采用一个Embedding来进行编码,从而注入DiT中。DiT论文中为了增强特征融合的能力,一共设计了四种方案来实现两个额外Embeddings的嵌入,具体如下图所示:
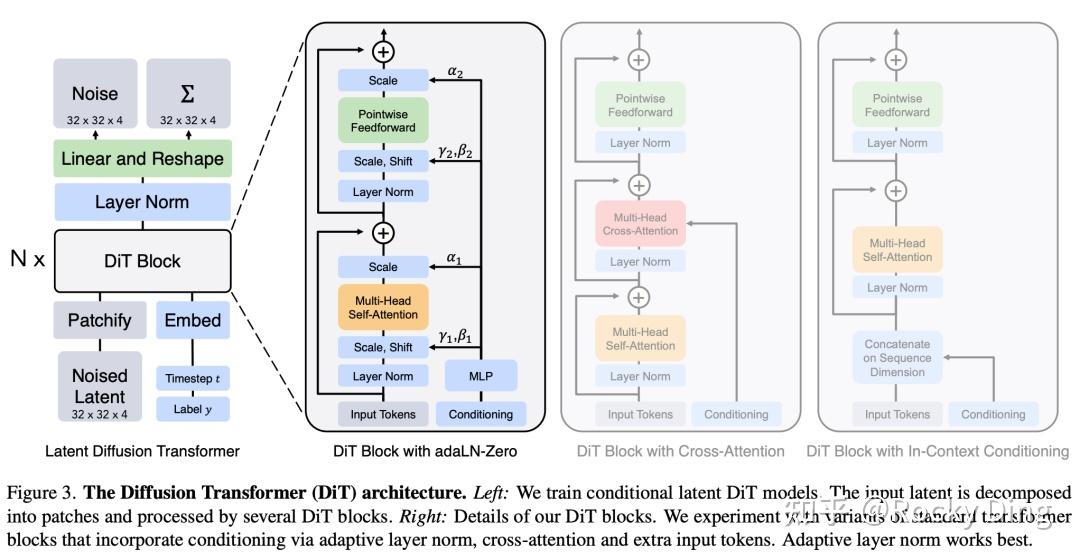
具体包括In-Context Conditioning(上下文条件)、Cross-Attention Block、Adaptive Layer Normalization (AdaLN) Block以及AdaLN-Zero block四种方案,下面对这四个方案进行详细的讲解。
【In-Context Conditioning(上下文条件)】
如上图中所示,将两个Embeddings看成两个tokens通过Concat的方式合并到Input tokens中,这种处理方式有点类似ViT中的cls token,实现简单同时也不引入额外的计算量。
【Cross-Attention Block】
如上图所示,在Transformer Block中插入一个Cross-Attention机制,将条件Embeddings作为Cross-Attention机制的key和value。这种方式是Stable Diffusion系列模型中常用的特征注入方式,它需要额外引入15%的Gflops。
【Adaptive Layer Normalization (AdaLN) Block】
首先了解一下Adaptive Layer Normalization(AdaLN)的基础概念和核心原理。
**Adaptive Layer Normalization(AdaLN)是在Layer Normalization(LN)的基础上进行了优化,用来增强AI模型在处理不同输入条件时的适应能力。**下面再通俗易懂地讲解AdaLN的核心原理:
AdaLN的核心原理
Layer Normalization
首先在理解AdaLN之前,我们先简单回顾一下Layer Normalization,LN的处理步骤主要分成三步:
- **计算输入权重的均值和标准差:**计算模型每一层输入权重的均值和标准差。
- **对输入权重进行标准化:**使用计算得到的均值和标准差将输入权重标准化,使其均值为0,标准差为1。
- 对输入权重进行仿射变换:使用可学习的缩放参数和偏移参数,对标准化后的输入权重进行线性变换,使模型能够拟合任意的分布。
其中:
- 代表输入权重。
- 和分别是输入权重的均值和标准差。
- 和是可学习的参数,用于输入权重的缩放和偏移。
- 是一个小常数,防止除零造成的NAN问题。
讲到这里,我们就了解LN的核心原理了,接下来我们再看看AdaLN是如何在此基础上进行优化的。
AdaLN的核心思想
AdaLN的核心思想是根据输入的不同条件信息,自适应地调整LN的 缩放参数和 **偏移参数。**AdaLN的核心步骤包括:
**1. 提取条件信息:**从输入的条件(如Text Embeddings、类别标签等)中提取信息,一般来说会专门使用一个神经网络模块(比如全连接层等)来处理输入条件,并生成与输入数据相对应的缩放和偏移参数。
在DiT的官方实现中,使用了一个全连接层+SiLU激活函数来实现这样一个输入条件的特征提取网络:
# 输入条件的特征提取网络
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
# c代表输入的条件信息
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
同时,DiT在每个残差模块之后还使用了一个回归缩放参数来对权重进行缩放调整,这个 参数也是由上述条件特征提取网络提取的。
2. 生成自适应的缩放和偏移参数
3. 应用自适应参数
AdaLN处理流程图
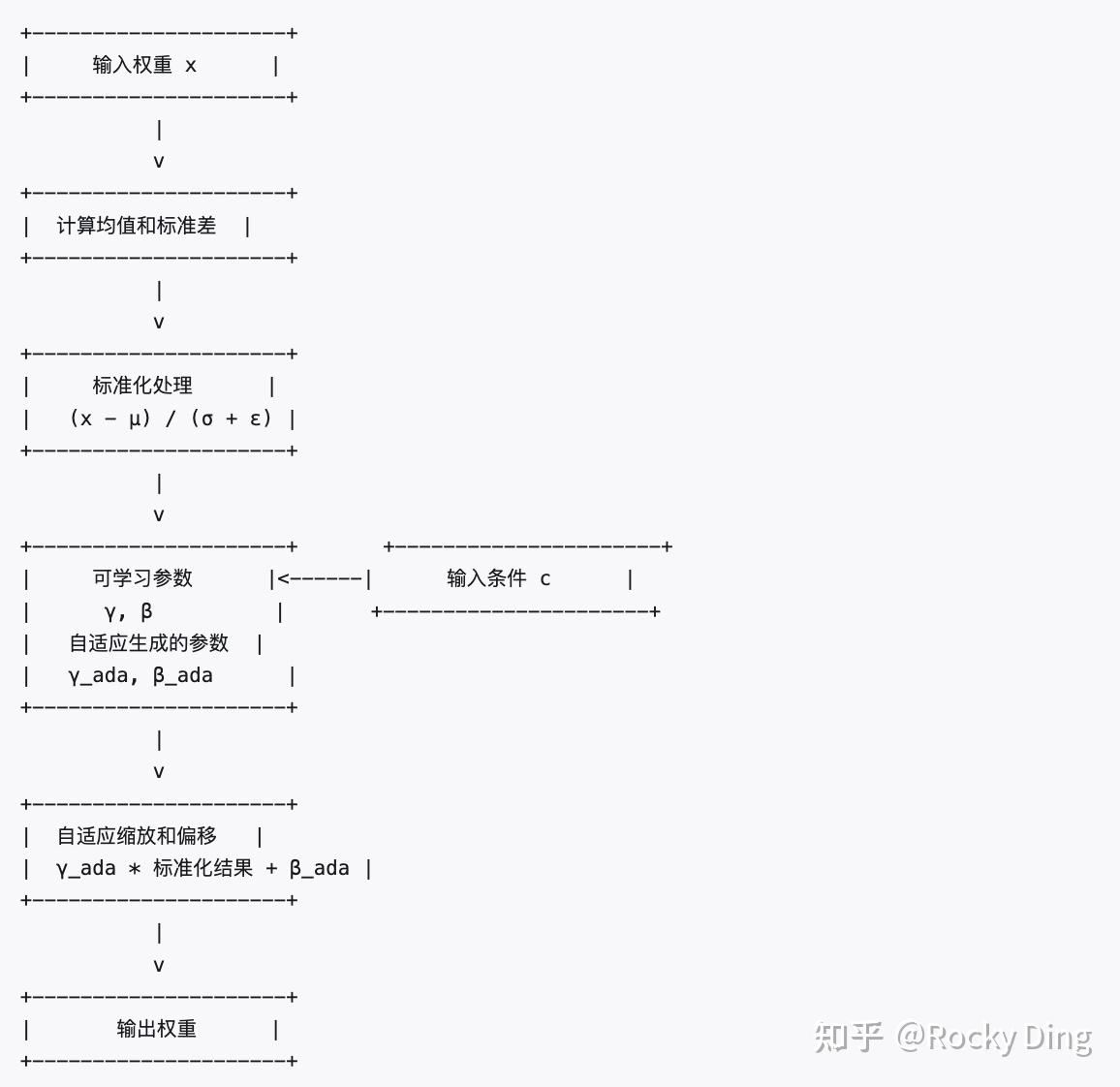
当在DiT中采用AdaLN Block模块时,其核心思想是通过DiT模型在训练中自适应学习那两个参数。将Time Embedding和Class Embedding两个额外条件信息相加,并作为AdaLN Block模块的输入,进而来拟合那两个参数,这种方式也不增加计算量。
【AdaLN-Zero block】
iT中具体的初始化设置如下所示:
- 对DiT Block中的AdaLN和Linear层均采用参数0初始化。
- 对于其它网络层参数,使用正态分布初始化和xavier初始化。
2、扩散模型数学原理学习
扩散模型的数学原理部分推导还是比较繁琐的,经过查阅各种笔记资料,也是自己照着算了一下,整理了思路。笔记如下:
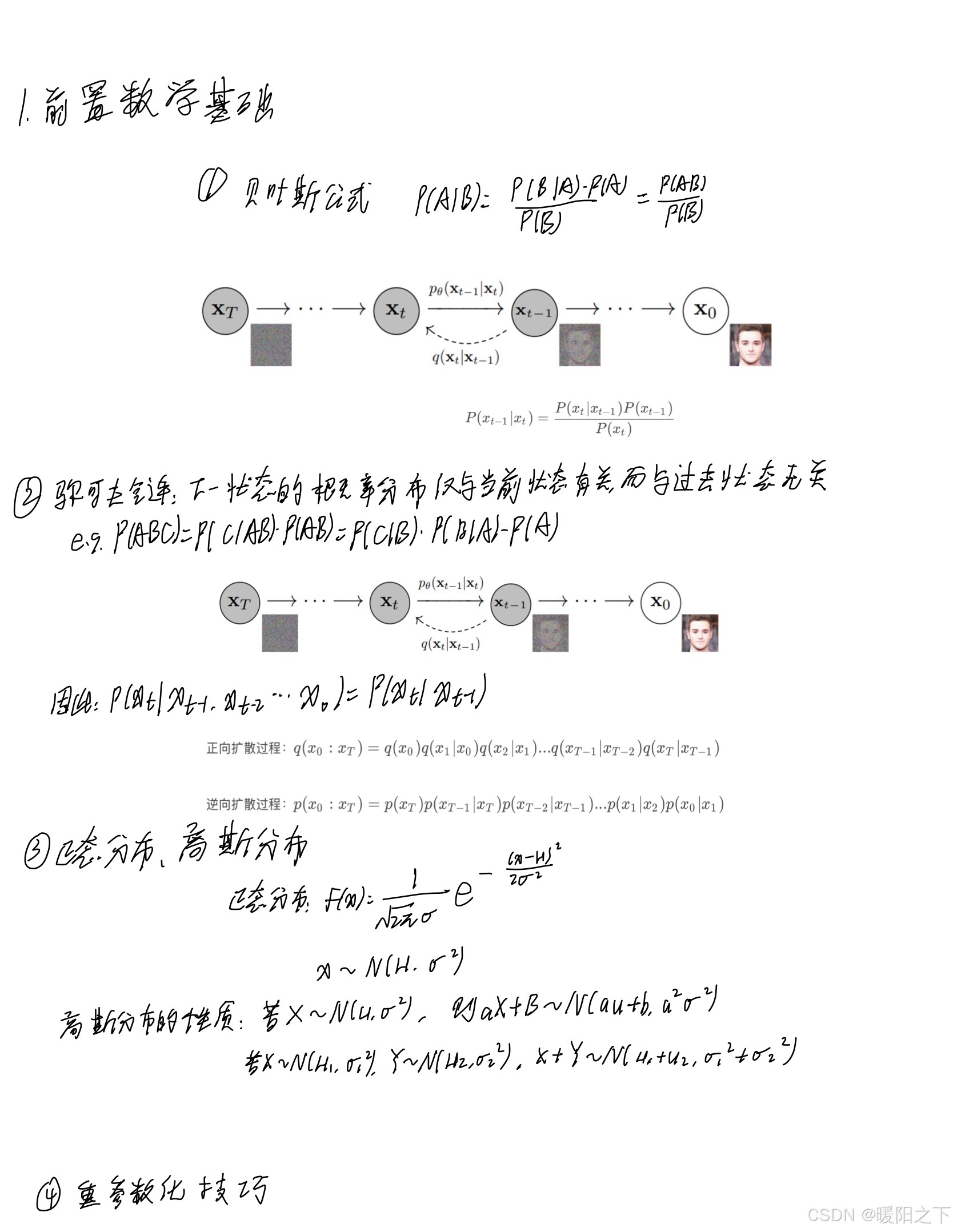
首先可以复习一下概率论的相关数学知识,后面会用到




3、读《Merging Context Clustering with Visual State Space Models for Medical Image Segmentation》
论文地址:https://arxiv.org/pdf/2501.01618
在该论文中提出,VMamba每个patch之间存在交互,但是它的内部patch是缺少一个交互的,所以作者提出在每个patch之间,加入上下文聚类操作,进一步提取局部的特征。这种局部和Mamba的全局操作,构成了本文提出的CCViM模型。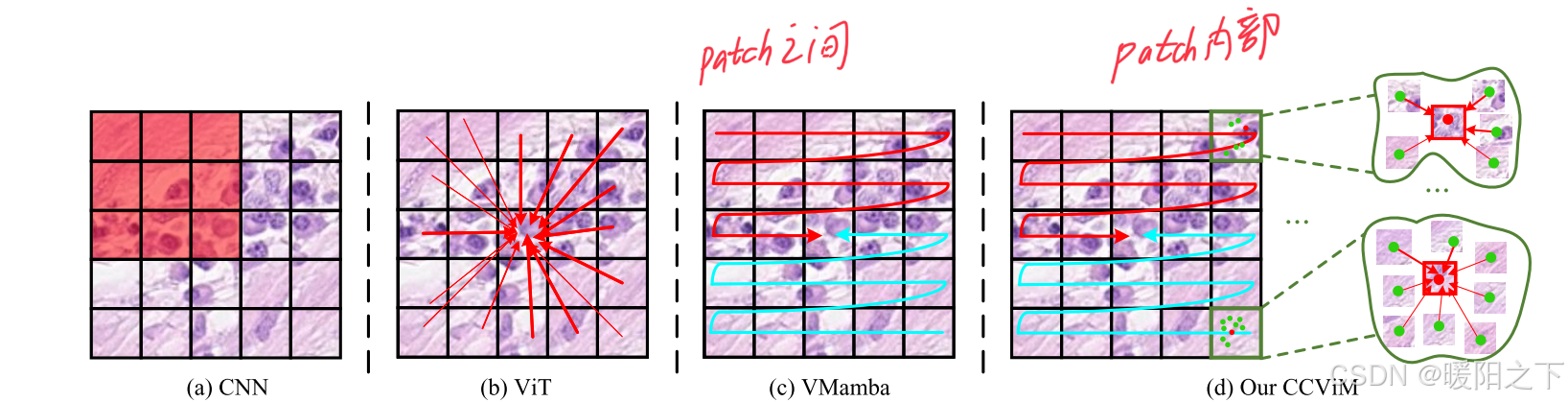
模型结构:
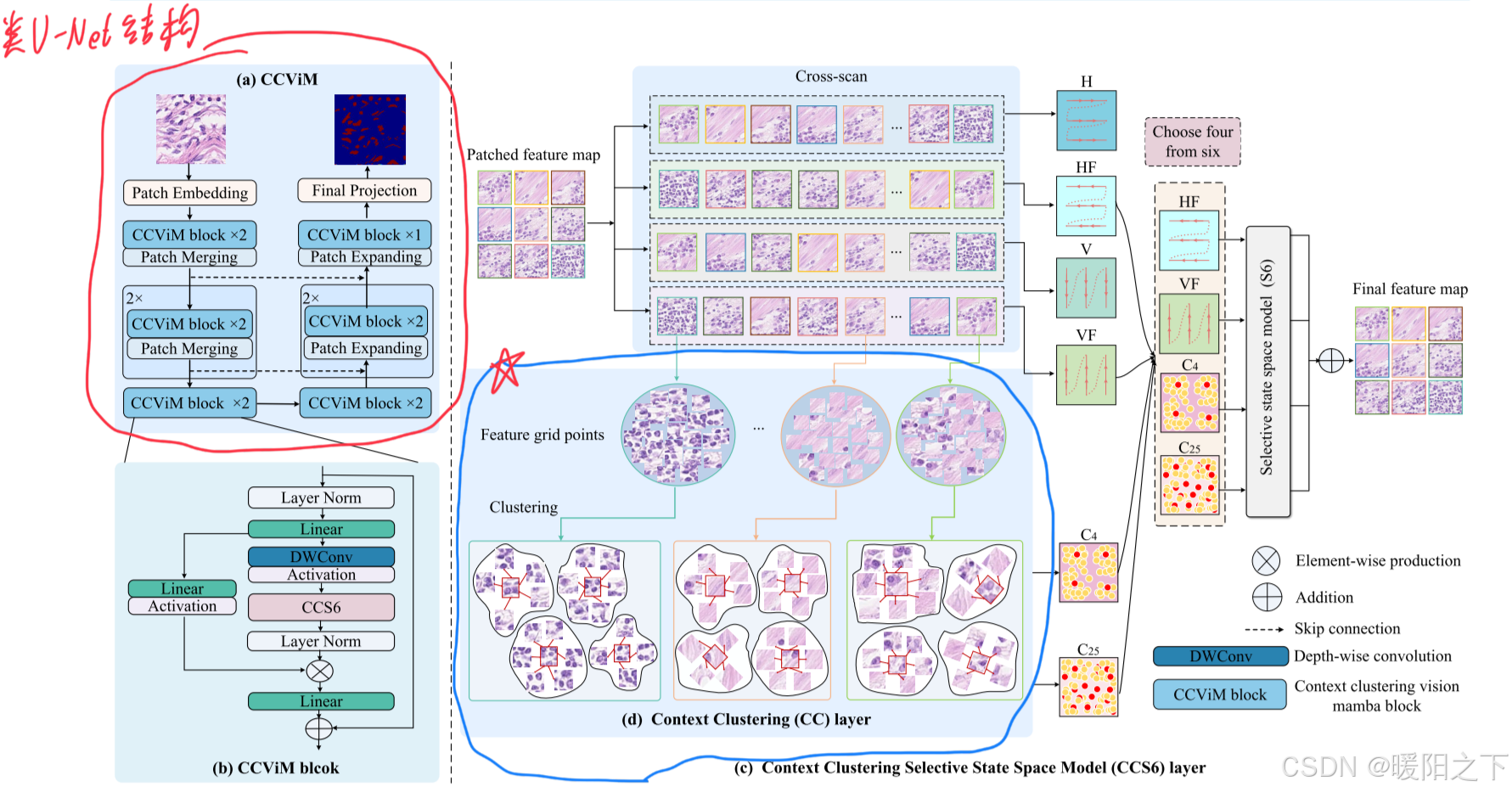
本文中最关键的部分就是画圈打五角星的地方:将一个patch继续划分,分成一些网格的点,然后进行聚类的操作,来完成一个局部的特征交互。
最关键的部分来了,这个局部的特征交互是ICLR 2023年的一篇文章提出来的。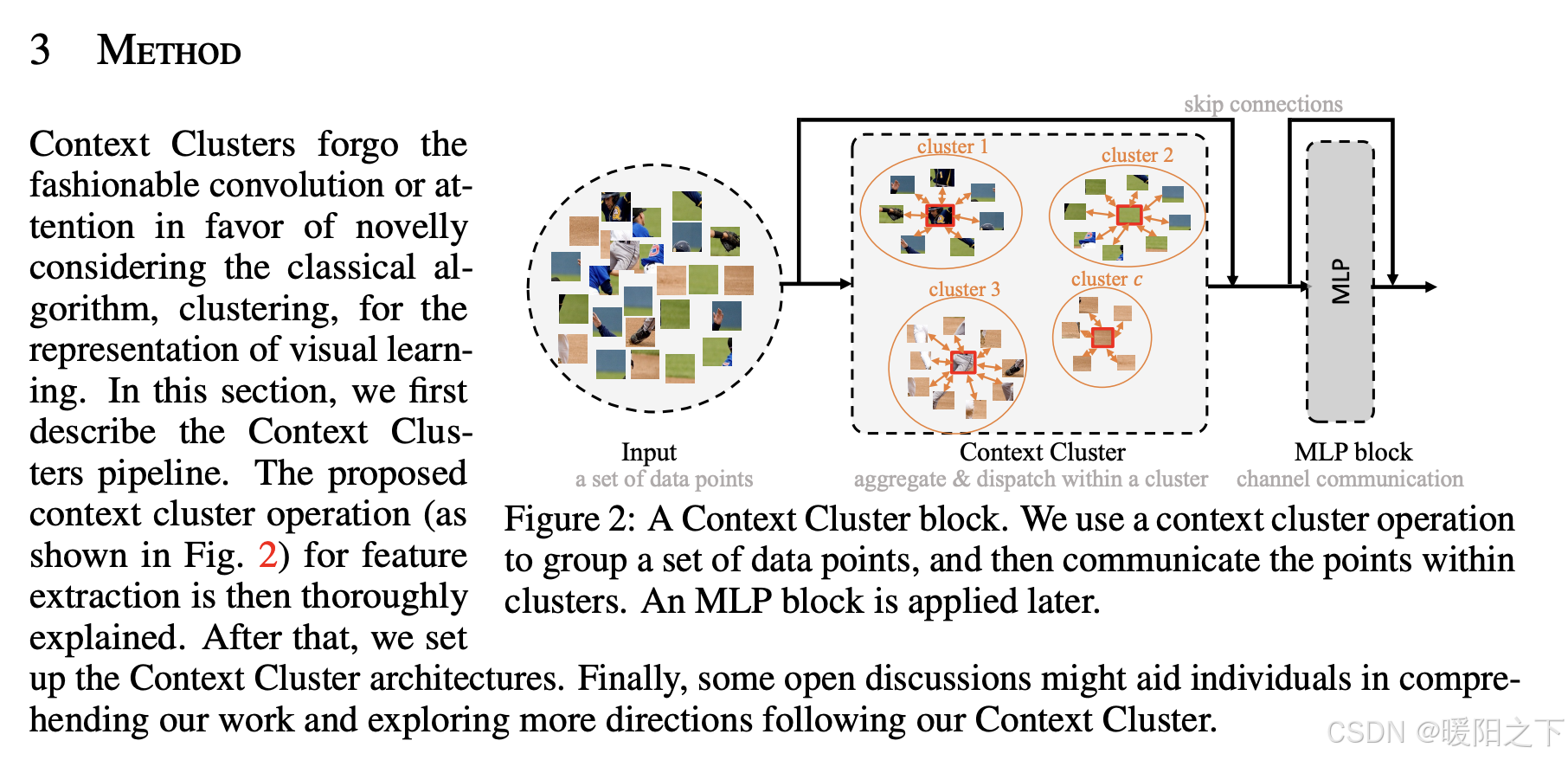
论文名称:Image as Set of Points
论文地址:https://arxiv.org/abs/2303.01494
总结
本周主要学习了AIGC领域比较经典的扩散模型,特别对于扩散模型较为难理解的数学原理进行了手推。最后阅读了一篇论文,其中最关键的部分在于它能够将别人论文中的一个idea,运用在自己的问题当中,这是一个比较值得学习的点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)