大模型安全应用实战:基于LangChain的Agent流量风险审计系统开发!大模型实战
本文介绍了一个基于LangChain生态的Agent和MCP开发的流量风险审计系统,由四个模块构成:AdvancedRiskTrafficAnalyzer使用正则表达式识别高风险流量;AutonomousAuditAgent通过AI分析并生成POC;curl-executor_mcp执行Curl命令模拟攻击;SSRFReceiver验证漏洞触发情况。系统实现了从静态风险识别到动态漏洞验证的完整闭环
简介
本文介绍了一个基于LangChain生态的Agent和MCP开发的流量风险审计系统,由四个模块构成:AdvancedRiskTrafficAnalyzer使用正则表达式识别高风险流量;AutonomousAuditAgent通过AI分析并生成POC;curl-executor_mcp执行Curl命令模拟攻击;SSRFReceiver验证漏洞触发情况。系统实现了从静态风险识别到动态漏洞验证的完整闭环,采用多线程、异步处理等技术,并包含安全机制如命令验证和鉴权。
目录
- 前记
- AdvancedRiskTrafficAnalyzer
- AutonomousAuditAgent
- curl-executor_mcp
- SSRFReceiver
- 后记
前记
本文探讨基于Langchain生态的Agent、MCP开发,设计一套简单的流量风险审计系统,该系统通过四个模块实现从静态风险识别到动态漏洞验证的完整闭环。
数据流动如下:
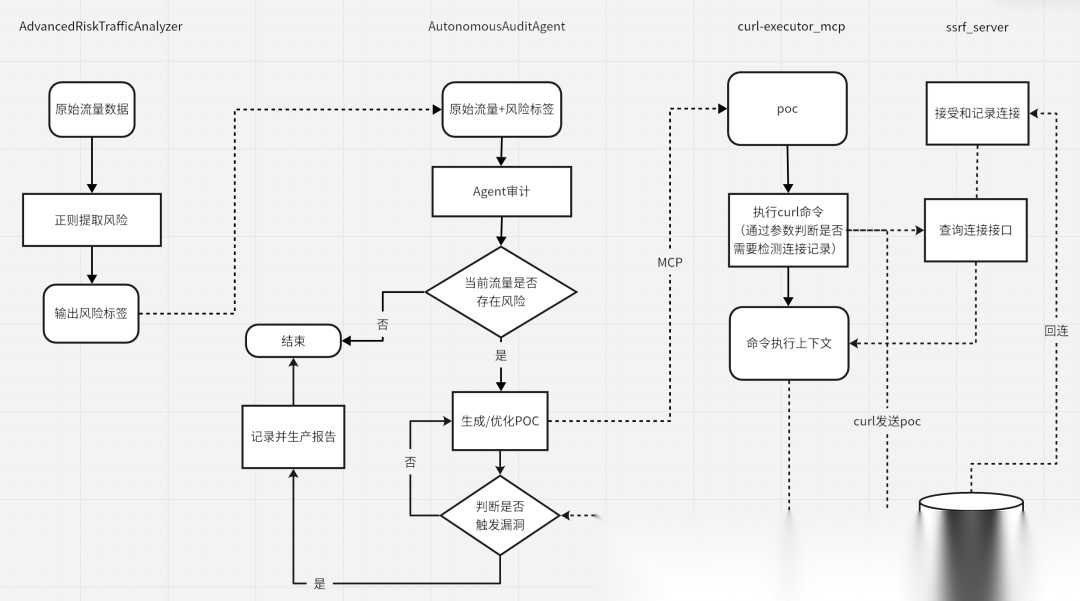
总体流程:
- 风险提取:使用正则规则扫描流量,标记高风险记录。
- Agent判断:AI Agent分析风险流量,生成POC。
- POC执行:通过MCP平台执行Curl命令模拟攻击。
- 验证成功:SSRF靶场监听并记录是否触发漏洞。
技术栈:re、concurrent.futures、LangChain、FastMCP、BaseHTTPRequestHandler、异步/并发处理(asyncio + ThreadPoolExecutor)、安全考虑(命令验证、鉴权、超时)
AdvancedRiskTrafficAnalyzer
这个模块使用Python类实现流量风险检测,主要通过正则表达式匹配常见攻击模式(如SQL注入、RCE、SSRF等)。主要通过下面三个方式计算流量风险:置信度因子、风险评分权重、风险检测规则。简单记录实现代码如下:
以SQL类风险配置为例
'SQL_INJECTION': 0.80,
'SQL_INJECTION': {'base': 15, 'multiplier': 1.2, 'max_single': 30}
(r"(?i)\binsert\s+into\s+\w+\s*\([^)]*\)\s*values", 15, "SQL操作-INSERT语句")
...
combined_content = f"{decoded_url}{decoded_body}{user_agent}{headers}"
多层URL解码机制
def_decode_url(self, url: str) -> str:
"""多层URL解码"""
try:
decoded = url
for _ in range(5):
new_decoded = urllib.parse.unquote(decoded, errors='ignore')
if new_decoded == decoded:
break
decoded = new_decoded
return decoded
except Exception:
return url
通过ThreadPoolExecutor多线程执行
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_batch = {
executor.submit(process_batch, batch): i
for i, batch in enumerate(batches)
}
for future in as_completed(future_to_batch): #字典在 Python 中是可迭代的,默认迭代其键
batch_results = future.result()
results.extend(batch_results)
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AutonomousAuditAgent
这个模块构建AI Agent,使用LangChain和LangGraph自主决策:分析风险流量、生成POC、执行验证(最多3次poc优化尝试),输出严格JSON格式,简单记录实现代码如下:
Agent初始化
self.llm = ChatOpenAI(openai_api_base=...,openai_api_key=...,model=..., max_tokens=10240, temperature=0.3)
mcp_servers = {
"curl_executor": {
"url": "",
"transport": "streamable_http",
"headers": {"Authorization": MCP_TOKEN}
},
"login_service": {
"url": "",
"transport": "streamable_http",
"headers": {"Authorization": API_KEY}
}
}
self.mcp_client = MultiServerMCPClient(mcp_servers)
tools = await asyncio.wait_for(self.mcp_client.get_tools(),timeout=30.0)
tools=tools+[localtool]
self.prompt = ChatPromptTemplate.from_messages([("system",
"""
...
- SSRF漏洞验证: 必须使用http://.../[marker],并检查SSRF标记
- RCE类漏洞验证:必须通过使其执行curl http://.../[marker]命令,并检查SSRF标记
- SQL类漏洞验证:必须执行SQL语句查询数据库版本或者查询其他无害信息
...
"""),
("human", "{input}"),
("placeholder","{agent_scratchpad}")])
agent = create_openai_tools_agent(self.llm, tools, self.prompt)
self.agent_executor = AgentExecutor(agent=agent, tools=tools, max_iterations=10,handle_parsing_errors=True,verbose=True)
result = await asyncio.wait_for(self.agent_executor.ainvoke({"input": audit_request}),timeout=240.0)
output = result.get("output", "").strip()
多线程
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_row = {}
for index, row in merged_df.iterrows():
future = executor.submit(platform.audit_record_sync, row, index)
future_to_row[future] = (index, row)
for future in as_completed(future_to_row):
result = future.result(timeout=300)
audit_results.append(result)
create_openai_tools_agent/create_react_agent
| 特性 | create_openai_tools_agent | create_react_agent |
|---|---|---|
| 底层机制 | OpenAI 函数调用(JSON 输出) | ReAct 框架(Thought-Action-Observation 循环) |
| 模型依赖 | 需支持函数调用的 OpenAI 模型(如 GPT-3.5/4) | 任意支持文本输出的 LLM |
| 推理过程 | 隐式推理,模型内部决定工具调用 | 显式推理,输出详细的思考步骤 |
| 效率 | 更高(更少 token,单次调用为主) | 较低(多轮迭代,更多 token) |
| 灵活性 | 适合简单、结构化任务 | 适合复杂、多步推理任务 |
| 定制化 | 定制化较弱(依赖模型函数调用逻辑) | 高度可定制(通过提示模板控制推理和工具使用) |
| 输出格式 | 结构化 JSON(工具调用)、json.loads加载 | 文本(包含 Thought/Action/Observation) |
| 调试透明性 | 较低(推理过程不透明) | 较高(显式记录推理步骤) |
curl-executor_mcp
MCP平台执行Curl命令,支持SSRF检查。使用FastMCP框架,提供工具接口。简单记录实现代码如下:
鉴权
defauth():
request: Request = get_http_request()
token = request.headers.get("Authorization", "Unknown")
if token != mcp_token:
raise HTTPException(status_code=401, detail="Unauthorized")
执行命令
safe_command = f"{command} --max-time {timeout} --connect-timeout 15 --compressed --show-error"
if self.validate_curl_command(command):
result = subprocess.run(safe_command, shell=True, capture_output=True, text=True, timeout=timeout + 5)
return {
'success': result.returncode == 0,
'execution_id': execution_id,
'command': command,
'safe_command': safe_command,
'stdout': result.stdout,
'stderr': result.stderr,
'return_code': result.returncode,
'execution_time': execution_time,
'timestamp': datetime.now().isoformat()
}
mcp框架
from fastmcp import FastMCP
sandbox = CurlSandbox()
# MCP工具函数
@mcp.tool()
defexecute_curl_command(command: str, check_ssrf: bool = False, ssrf_marker: str = "") -> Dict[str, Any]:
"""
执行curl命令并可选检查SSRF触发
Args:
command: curl命令字符串
check_ssrf: 是否检查SSRF触发
ssrf_marker: SSRF标记(如果为空则自动提取)
Returns:
执行结果字典
"""
auth()
ifnot command ornot isinstance(command, str):
return {'success': False, 'error': '无效的curl命令'}
result = sandbox.execute_curl(command)
if check_ssrf:
ifnot ssrf_marker:
ssrf_marker = sandbox.extract_ssrf_marker(command)
if ssrf_marker:
ssrf_result = sandbox.ssrf_checker.check_ssrf_triggered(ssrf_marker)
result['ssrf_check'] = ssrf_result
if __name__ == "__main__":
try:
mcp.run(transport="http", host="0.0.0.0", port=8000, path="/curlmcp")
except KeyboardInterrupt:
logger.info("服务停止")
except Exception as e:
logger.error(f"服务异常: {str(e)}")
raise
SSRFReceiver
实现一个简化的SSRF(服务器端请求伪造)测试接收平台,实现如下功能
- 监听和记录HTTP请求(包括GET、POST等方法),用于接收SSRF测试的连接。
- 提供查询API,用于查看连接记录和统计信息。
- 支持自动清理旧数据(每24小时一次)。
- 提供简单的Web界面展示API文档。
主要是使用BaseHTTPRequestHandler
作用:BaseHTTPRequestHandler 是一个抽象基类,用于处理单个 HTTP 请求。开发者通过继承该类并重写其方法来定义自定义的请求处理逻辑。
工作机制:
- 每次客户端发起 HTTP 请求(如 GET、POST 等),HTTPServer 会创建一个 BaseHTTPRequestHandler 实例来处理该请求。
- 它解析请求(方法、路径、头、数据等),并提供方法供开发者自定义响应。
典型用法:
- 继承 BaseHTTPRequestHandler,重写
do_<METHOD>方法(如 do_GET、do_POST)来处理特定 HTTP 方法的请求。 - 使用提供的属性(如 self.path、self.headers)访问请求信息。
- 通过 self.wfile 发送响应内容,通过 self.send_response 和 self.send_header 设置响应状态和头。
重写的方法:
- do_GET、do_POST、do_PUT、do_DELETE、do_OPTIONS、do_HEAD:统一调用自定义的 _handle_request 处理各种 HTTP 方法。
- log_message:pass禁用默认日志,使用 logging 模块记录。
使用的属性:
- self.client_address:获取客户端 IP 和端口。
- self.path:解析请求路径。
- self.headers:获取请求头。
- self.rfile:读取请求体。
request_body = self.rfile.read(content_length).decode('utf-8', errors='ignore') - self.wfile:发送响应内容。
self.wfile.write(json.dumps(response_data, indent=2, ensure_ascii=False).encode('utf-8')) - self.server.server_port:获取服务器端口。
简单记录实现代码如下:
定时清理
defstart_cleanup_thread(self):
"""启动定时清理线程"""
defcleanup_worker():
whileTrue:
try:
# 检查是否需要清理(24小时间隔)
if datetime.now() - self.last_cleanup > timedelta(hours=24):
self.cleanup_old_data()
time.sleep(3600) # 每小时检查一次
except Exception as e:
logging.error(f"清理线程错误: {e}")
time.sleep(3600)
cleanup_thread = threading.Thread(target=cleanup_worker)
cleanup_thread.daemon = True
cleanup_thread.start()
logging.info("定时清理线程已启动")
接受连接
classHTTPRequestHandler(BaseHTTPRequestHandler):
"""HTTP请求处理器 - 用于接收SSRF测试"""
def__init__(self, *args, logger=None, **kwargs):
self.logger = logger
super().__init__(*args, **kwargs)
defdo_GET(self):
self._handle_request('GET')
defdo_POST(self):
self._handle_request('POST')
defdo_PUT(self):
self._handle_request('PUT')
defdo_DELETE(self):
self._handle_request('DELETE')
defdo_OPTIONS(self):
self._handle_request('OPTIONS')
defdo_HEAD(self):
self._handle_request('HEAD')
def_handle_request(self, method):
"""处理HTTP请求"""
client_ip = self.client_address[0]
client_port = self.client_address[1]
server_port = self.server.server_port
# 获取URL路径
parsed_path = urllib.parse.urlparse(self.path)
path = parsed_path.path
# 获取请求数据
content_length = int(self.headers.get('Content-Length', 0))
request_body = self.rfile.read(content_length).decode('utf-8', errors='ignore')
# 构建请求信息
request_info = {
'method': method,
'path': path,
'query': urllib.parse.parse_qs(parsed_path.query),
'body': request_body[:1000] if request_body else''# 限制body长度
}
# 记录连接
if self.logger:
self.logger.log_connection(
source_ip=client_ip,
source_port=client_port,
target_port=server_port,
path=path,
request_data=json.dumps(request_info),
headers=self.headers,
user_agent=self.headers.get('User-Agent')
)
# 发送响应
self.send_response(200)
self.send_header('Content-type', 'application/json; charset=utf-8')
self.send_header('Access-Control-Allow-Origin', '*')
self.end_headers()
response_data = {
'status': 'success',
'message': 'SSRF received',
'timestamp': datetime.now().isoformat(),
'client_info': {
'ip': client_ip,
'port': client_port,
'user_agent': self.headers.get('User-Agent')
},
'request_info': {
'method': method,
'path': path,
'server_port': server_port
}
}
self.wfile.write(json.dumps(response_data, indent=2, ensure_ascii=False).encode('utf-8'))
deflog_message(self, format, *args):
"""重写日志方法"""
pass
查询连接
classQueryAPIHandler(BaseHTTPRequestHandler):
"""查询API处理器"""
def__init__(self, *args, logger=None, auth_token=None, **kwargs):
self.logger = logger
self.auth_token = auth_token or"ssrf-auth"
super().__init__(*args, **kwargs)
def_check_auth(self):
"""检查鉴权"""
auth_header = self.headers.get('Auth') or self.headers.get('Authorization')
...
defdo_GET(self):
parsed_path = urllib.parse.urlparse(self.path)
path = parsed_path.path
query_params = urllib.parse.parse_qs(parsed_path.query)
try:
if path == '/':
self.send_response(200)
self.send_header('Content-type', 'text/html; charset=utf-8')
self.send_header('Access-Control-Allow-Origin', '*')
self.end_headers()
self._handle_index()
elif path.startswith('/api/'):
is_auth, auth_message = self._check_auth()
ifnot is_auth:
logging.warning(f"鉴权失败: {self.client_address[0]} - {auth_message}")
self._send_auth_error()
return
self.send_response(200)
self.send_header('Content-type', 'application/json; charset=utf-8')
self.send_header('Access-Control-Allow-Origin', '*')
self.send_header('Access-Control-Allow-Methods', 'GET, POST, OPTIONS')
self.send_header('Access-Control-Allow-Headers', 'Content-Type, Auth, Authorization')
self.end_headers()
if path == '/api/query':
self._handle_path_query(query_params)
elif path == '/api/all':
self._handle_all_query(query_params)
elif path == '/api/stats':
self._handle_stats_query()
else:
self._send_error(404, "API endpoint not found")
else:
self.send_response(404)
self.send_header('Content-type', 'application/json; charset=utf-8')
self.send_header('Access-Control-Allow-Origin', '*')
self.end_headers()
self._send_error(404, "Endpoint not found")
if path == '/api/query':
self._handle_path_query(query_params)
后记
以下表格总结了风险流量审计平台中所有导入的Python库及其用到的具体函数/方法,包含每个库的模块、作用、使用的函数及其功能描述。表格旨在为开发、复习和分享提供清晰参考。
| 库名称 | 模块/子模块 | 作用 | 使用的函数/方法 | 功能描述 |
|---|---|---|---|---|
| os | os.path | 提供操作系统接口,用于文件路径操作 | os.path.join | 拼接文件路径,确保跨平台兼容(如生成CSV输出路径) |
| os | os.path | 提供操作系统接口,用于文件路径操作 | os.path.exists | 检查文件是否存在(如检查patterns_file是否有效) |
| datetime | datetime | 处理日期和时间,用于时间戳和清理 | datetime.now | 获取当前时间,用于记录连接时间戳或清理旧数据 |
| datetime | datetime | 处理日期和时间,用于时间戳和清理 | datetime.fromisoformat | 解析ISO格式时间字符串(如SSRFReceiver中处理时间查询) |
| datetime | timedelta | 表示时间间隔,用于定时任务 | timedelta | 创建时间差(如SSRFReceiver中设置24小时清理间隔) |
| re | re | 正则表达式处理,用于风险流量模式匹配 | re.compile | 编译正则表达式,提高匹配效率(如SQL注入模式) |
| re | re | 正则表达式处理,用于风险流量模式匹配 | re.findall | 查找所有匹配的模式(如检测攻击特征) |
| re | re | 正则表达式处理,用于风险流量模式匹配 | re.search | 查找首个匹配模式(如提取SSRF标记) |
| concurrent.futures | ThreadPoolExecutor | 提供线程池,支持并行处理 | ThreadPoolExecutor | 创建线程池(如批量处理流量或并行审计) |
| concurrent.futures | concurrent.futures | 提供线程池,支持并行处理 | as_completed | 按完成顺序获取线程结果(如处理批次结果) |
| asyncio | asyncio | 异步编程,支持Agent异步执行 | asyncio.wait_for | 设置异步任务超时(如Agent审计单条记录) |
| asyncio | asyncio | 异步编程,支持Agent异步执行 | asyncio.ensure_future | 调度异步任务(如并行审计) |
| subprocess | subprocess | 执行外部命令,用于Curl沙箱 | subprocess.run | 运行Curl命令,捕获输出和错误(如execute_curl) |
| requests | requests | HTTP请求,用于SSRF检查和API调用 | requests.get | 发送GET请求(如查询SSRF触发状态) |
| urllib.parse | urllib.parse | URL解析和解码 | urllib.parse.unquote | 解码URL编码字符串(如_decode_url) |
| urllib.parse | urllib.parse | URL解析和解码 | urllib.parse.parse_qs | 解析URL查询参数(如SSRFReceiver处理API查询) |
| json | json | JSON数据处理,用于结果存储和解析 | json.loads | 解析JSON字符串(如提取Agent输出) |
| json | json | JSON数据处理,用于结果存储和解析 | json.dump | 将数据写入JSON文件(如SSRFReceiver保存连接记录) |
| time | time | 时间操作,用于清理线程睡眠 | time.sleep | 暂停执行(如SSRFReceiver清理线程等待1小时) |
| threading | threading | 线程管理,用于SSRFReceiver并发安全 | threading.Lock | 创建锁,确保连接记录线程安全 |
| threading | threading | 线程管理,用于SSRFReceiver并发安全 | threading.Thread | 创建守护线程(如定时清理旧数据) |
| http.server | http.server | 构建HTTP服务器,用于SSRF接收 | HTTPServer | 创建HTTP服务器,监听SSRF请求 |
| http.server | http.server | 构建HTTP服务器,用于SSRF接收 | BaseHTTPRequestHandler | 基类,用于自定义SSRF查询处理 |
| csv | csv | 处理CSV文件,用于流量输入/输出 | csv.DictReader | 读取CSV为字典列表(如read_traffic_from_csv_optimized) |
| csv | csv | 处理CSV文件,用于流量输入/输出 | csv.DictWriter | 写入字典列表到CSV(如export_results_to_csv_enhanced) |
| pandas | pandas | 数据处理,用于合并和分析数据 | pandas.DataFrame | 创建数据框(如autonomous_parallel_audit处理merged_df) |
| pandas | pandas.DataFrame | 数据处理,用于合并和分析数据 | DataFrame.iterrows | 迭代数据框行(如并行审计记录) |
| base64 | base64 | Base64编码解码,用于流量内容处理 | base64.b64decode | 解码Base64字符串(如_decode_content) |
| binascii | binascii | 十六进制解码,用于流量内容处理 | binascii.unhexlify | 解码Hex字符串(如_decode_content) |
| langchain | langchain.chat_models | LLM集成,用于Agent初始化 | BaseChatOpenAI | 初始化OpenAI模型(如gpt-4.1-mini) |
| langchain | langchain.prompts | 提示模板,用于Agent指令 | ChatPromptTemplate.from_messages | 定义Agent提示(如指定JSON输出格式) |
| langchain | langchain.agents | Agent框架,支持ReAct循环 | create_openai_tools_agent | 创建工具调用Agent |
| langchain | langchain.agents | Agent框架,支持ReAct循环 | AgentExecutor | 执行Agent任务,限制迭代次数 |
| fastmcp | fastmcp | MCP框架,提供工具接口 | @mcp.tool | 装饰器,定义MCP工具(如execute_curl_command) |
| dels | LLM集成,用于Agent初始化 | BaseChatOpenAI | 初始化OpenAI模型(如gpt-4.1-mini) | |
| langchain | langchain.prompts | 提示模板,用于Agent指令 | ChatPromptTemplate.from_messages | 定义Agent提示(如指定JSON输出格式) |
| langchain | langchain.agents | Agent框架,支持ReAct循环 | create_openai_tools_agent | 创建工具调用Agent |
| langchain | langchain.agents | Agent框架,支持ReAct循环 | AgentExecutor | 执行Agent任务,限制迭代次数 |
| fastmcp | fastmcp | MCP框架,提供工具接口 | @mcp.tool | 装饰器,定义MCP工具(如execute_curl_command) |
| fastmcp | fastmcp | MCP框架,提供工具接口 | MultiServerMCPClient | 初始化MCP客户端,连接多个服务 |
AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献339条内容
已为社区贡献339条内容

所有评论(0)