AI论文速读 | Kronos: 金融市场语言基础模型
大规模多市场预训练语料库 数据来源:Kronos的预训练数据集包括来自45个全球交易所的超过120亿条K线记录,涵盖了股票、期货、外汇和加密货币等多种资产类别。这些数据的时间跨度为2010年1月至2024年3月,确保了数据的多样性和广泛性。 数据预处理:为了处理原始K线数据的不规则性和非平稳性,论文采用了对数收益率标准化(Log-Return Normalization)方法,
论文标题:Kronos: A Foundation Model for the Language of Financial Markets
作者: Yu Shi, Zongliang Fu, Shuo Chen, Bohan Zhao, Wei Xu, Changshui Zhang(张长水), Jian Li(李建)
机构:清华大学交叉信息学院(IIIS),清华大学自动化系
论文链接:https://arxiv.org/abs/2508.02739
Cool Paper:https://papers.cool/arxiv/2508.02739
代码:https://github.com/shiyu-coder/Kronos
TL;DR:针对通用时间序列模型在金融K线低信噪比、非平稳性上性能差的问题,论文提出Kronos:用BSQ分词将K线离散为双粒度标记,120亿K线自回归预训练,零样本价格预测RankIC+93%,波动率MAE-9%,生成保真度+22%。
关键词:金融时间序列、基础模型、分词化(tokenize)、预训练、Transformer、零样本

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
以大语言模型(LLM)为代表的大规模预训练范式的成功,启发了时间序列基础模型(TSFM)的发展。然而,它们在金融烛台(K线)数据上的应用仍然有限,其表现往往不如非预训练架构。此外,现有的时间序列基础模型往往忽视了诸如波动性预测和合成数据生成等关键下游任务。为了解决这些局限性,本文提出了Kronos,这是一个统一的、可扩展的预训练框架,专门用于金融K线建模。Kronos引入了一种专门的分词器,将连续的市场信息离散为标记序列,同时保留价格动态和交易活动模式。本文使用自回归目标在来自45个全球交易所的超过120亿条K线记录的大规模多市场语料库上对Kronos进行预训练,使其能够学习细致入微的时间和跨资产表示。Kronos在各种金融任务的零样本设置中表现出色。在基准数据集上,Kronos在价格序列预测的RankIC指标上比领先的时间序列基础模型提高了93%,比最佳的非预训练基线提高了87%。它在波动性预测中的平均绝对误差(MAE)也降低了9%,在合成K线序列的生成保真度上提高了22%。这些结果确立了Kronos作为一个强大、通用的端到端金融时间序列分析基础模型的地位。
Q: 这篇论文试图解决什么问题?
A: 这篇论文提出了一个名为 Kronos 的金融时间序列基础模型,旨在解决以下问题:
- 现有时间序列基础模型(TSFMs)在金融K线数据上的局限性:
- 金融K线数据具有独特的统计特性,如低信噪比、强非平稳性和复杂的高阶依赖关系,这些特性与通用TSFMs的归纳偏差不匹配,导致现有TSFMs在金融任务上表现不佳。
- 金融领域在主流TSFM研究中被忽视,金融序列在大多数现有TSFMs的预训练语料库中只占一小部分,且对定量金融至关重要的下游任务(如波动率估计、合成序列生成和风险管理)大多未被解决。
- 如何有效地将大规模预训练范式应用于金融K线数据:
- 作者提出了一种专门针对金融K线数据的统一、可扩展的预训练框架Kronos,通过引入专门的分词器(tokenizer)将连续的市场信息离散化为标记序列,同时保留价格动态和交易活动模式。
- 通过在超过120亿条K线记录的多市场语料库上进行自回归预训练,Kronos能够学习到细腻的时间和跨资产表示。
- 如何在多种金融任务中实现零样本(zero-shot)设置下的卓越性能:
- 在基准数据集上,Kronos在价格序列预测任务中将RankIC提升了93%,超过了领先的TSFM和最佳非预训练基线。
- 在波动率预测任务中,Kronos将MAE降低了9%,在合成K线序列生成任务中,生成保真度提高了22%。
综上所述,Kronos旨在通过专门针对金融K线数据的预训练框架,解决现有TSFMs在金融领域的不足,并在多种金融任务中实现卓越的性能,从而为金融时间序列分析提供一个强大而通用的基础模型。
Q: 有哪些相关研究?
A:
时间序列基础模型(TSFMs)
- 通用时间序列基础模型:近年来,时间序列基础模型(TSFMs)的研究取得了显著进展,这些模型借鉴了自然语言处理(NLP)领域中大型语言模型(LLMs)的成功经验,旨在通过大规模预训练来学习通用的时间序列表示,从而为各种下游任务提供强大的基础支持。例如,TimeGPT-1(Garza et al., 2023)和Time-MoE(Xiaoming et al., 2025)等模型,通过在大规模时间序列数据上进行预训练,展示了在多种时间序列分析任务中的潜力。
- 金融时间序列基础模型:在金融领域,时间序列数据具有独特的统计特性和复杂的动态特性,这使得专门针对金融时间序列的基础模型研究变得尤为重要。例如,PLUTUS(Xu et al., 2024)和DELPHYNE(Ding et al., 2025)等模型,专注于利用大规模数据来挖掘金融市场中的规律性,以提高预测和分析的准确性。
时间序列分词化(Tokenization)
- 分词化方法:将连续的时间序列数据分词化为离散的标记序列,是适应基于标记的模型架构的关键步骤。早期的工作,如Chronos(Ansari et al., 2024),采用了简单的缩放和均匀量化方法。而TOTEM(Talukder et al., 2024)则利用了向量量化变分自编码器(VQ-VAE)来进行基于代码本的分词化。这些方法为时间序列的离散表示提供了初步的解决方案,但在处理复杂的时间序列数据时仍存在局限性。
- 视觉分词化方法的启发:鉴于视觉分词化领域的成熟发展,如Lookup-Free Quantization (LFQ)(Yu et al., 2023)和Binary Spherical Quantization (BSQ)(Zhao et al., 2024),这些方法通过隐式代码本实现了高保真度的重建,并在分词化过程中引入了创新的技术,如球面投影和熵正则化,以提高分词化的效果和效率。这些视觉分词化方法为时间序列分词化提供了宝贵的借鉴和启示。
金融时间序列的特性
- 复杂动态特性:金融时间序列数据具有低信噪比、强非平稳性和复杂的高阶依赖关系等独特统计特性。这些特性使得金融时间序列的建模和预测面临巨大挑战。例如,Zhang and Hua (2025) 和 Baidya and Lee (2024) 等研究深入探讨了这些特性对时间序列建模的影响,并提出了相应的解决方案。
- 数据丰富性和高频观测:金融市场数据的丰富性和高频观测特性,为时间序列分析提供了大量的样本和丰富的信息。然而,这也增加了数据处理和模型训练的复杂性。如何有效地利用这些数据,同时克服其带来的挑战,是金融时间序列分析中的一个重要研究方向。
金融时间序列的应用
- 预测任务:金融时间序列预测是金融市场分析中的核心任务之一,包括价格预测、收益率预测和波动率预测等。这些任务对于投资决策、风险管理等具有重要的实际意义。例如,Liu et al. (2023) 提出的iTransformer模型,通过引入倒置变换器架构,显著提高了时间序列预测的性能。
- 合成数据生成:合成数据生成在金融市场模拟、模型训练和风险评估等方面具有广泛的应用。例如,DiffusionTS(Yuan and Qiao, 2024)、TimeVAE(Desai et al., 2021)和TimeGAN(Yoon et al., 2019)等模型,通过不同的生成机制,为金融时间序列的合成数据生成提供了有效的解决方案。
时间序列预训练方法
- 预训练目标和架构:不同的预训练目标和架构对模型的性能和泛化能力有着重要影响。例如,Lag-Llama(Rasul et al., 2023)采用了解码器架构,并引入了概率预测目标,以更好地捕捉时间序列的不确定性。而MOMENT(Goswami et al., 2024)则采用了编码器架构,并通过多任务学习来提高模型的泛化能力。
- 预训练数据的选择和处理:预训练数据的质量和多样性对模型的性能至关重要。在金融领域,由于数据的复杂性和非平稳性,如何选择和处理预训练数据,以确保模型能够学习到有效的表示,是一个重要的研究问题。例如,Woo et al. (2024) 提出的Moirai模型,通过在大规模时间序列数据上进行预训练,展示了在多种下游任务中的优异性能。
时间序列模型的评估和比较
- 评估指标:在时间序列分析中,常用的评估指标包括均方误差(MSE)、平均绝对误差(MAE)、信息系数(IC)和秩信息系数(RankIC)等。这些指标从不同的角度反映了模型的预测性能和泛化能力。
- 模型比较:通过与现有的时间序列模型进行比较,可以更好地评估新模型的性能和优势。例如,Das et al. (2024) 提出的Units模型,通过与多种现有的时间序列模型进行比较,展示了其在预测任务中的优越性能。
Q: 论文如何解决这个问题?
A: 论文通过以下方法解决现有时间序列基础模型(TSFMs)在金融K线数据上的局限性问题:
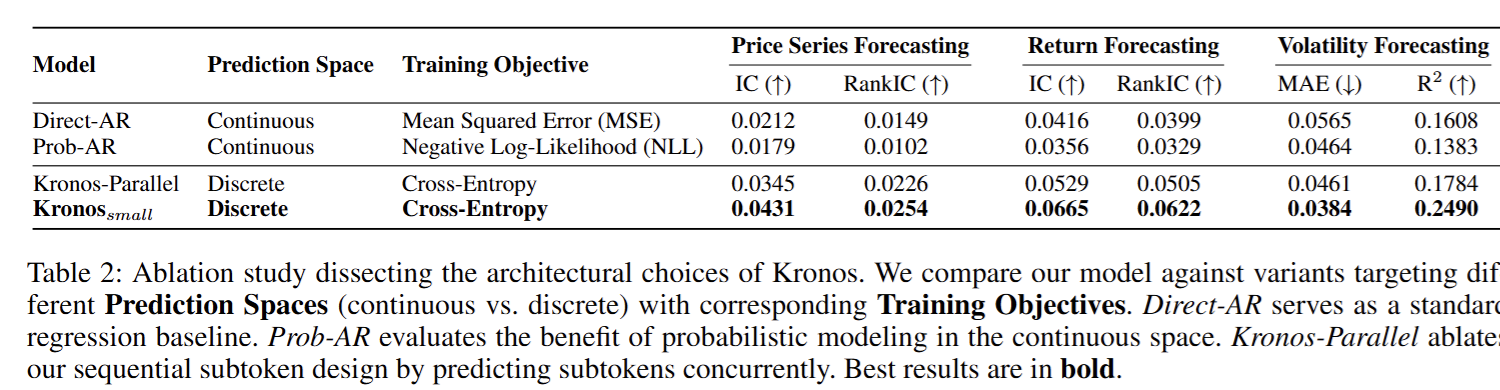
提出Kronos模型
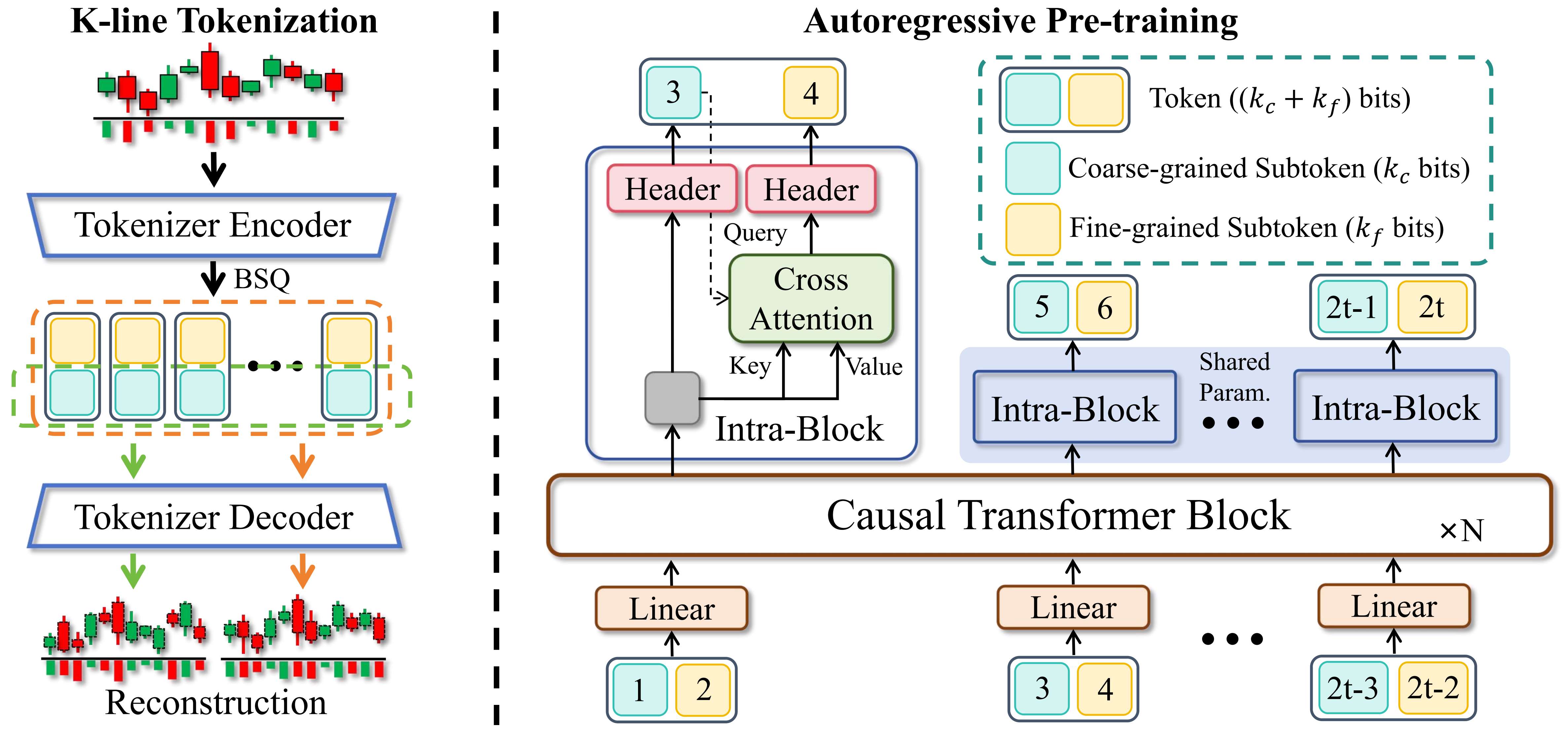
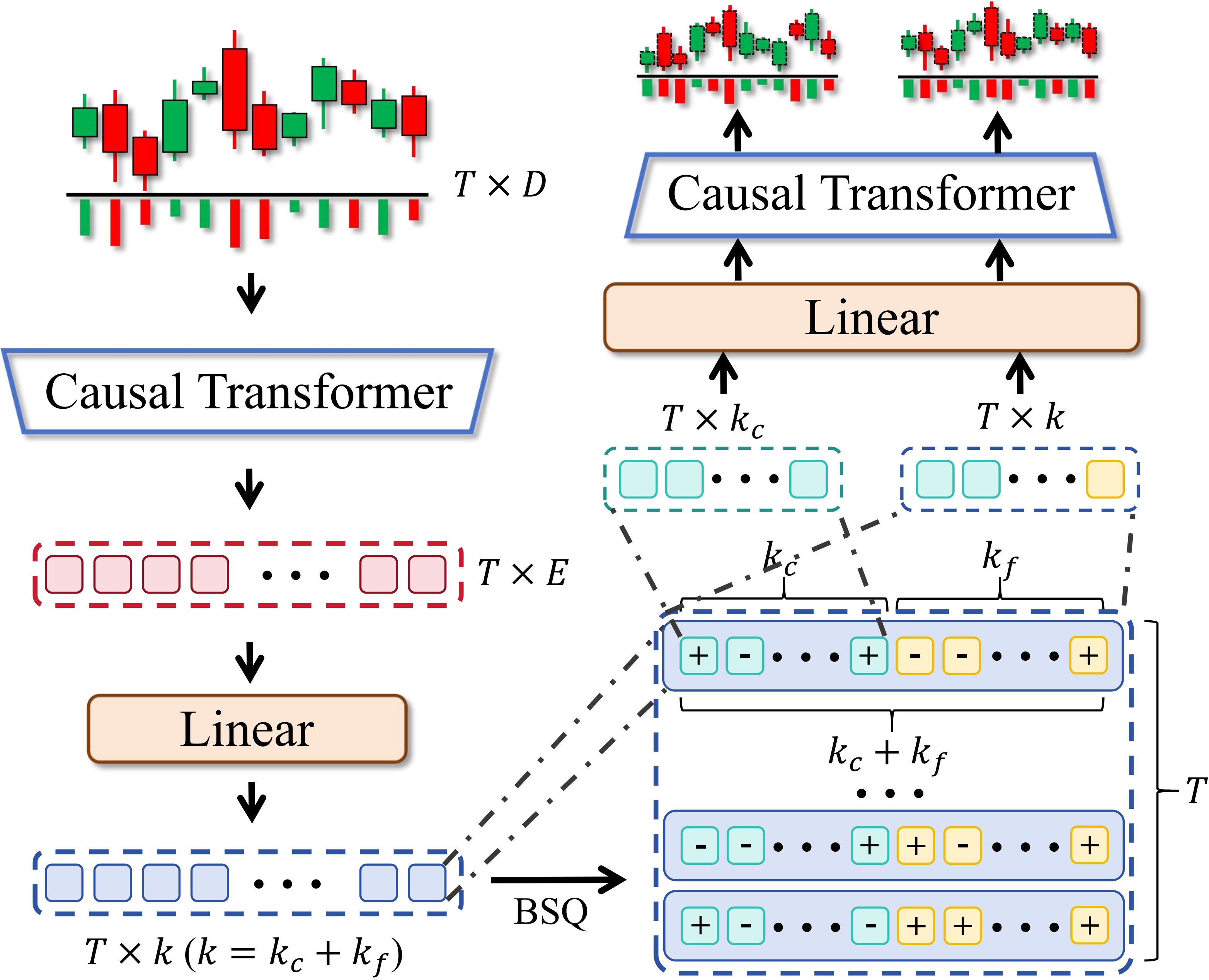
- 专门的分词器(Tokenizer):Kronos引入了一个专门的分词器,将连续的金融K线数据离散化为标记序列。这个分词器使用了**二进制球面量化(BSQ)**技术,将每个K线记录(包括开盘价、最高价、最低价、收盘价、交易量和成交额等六个维度)量化为一个离散的标记。每个标记由一个粗粒度子标记和一个细粒度子标记组成,这种设计使得模型能够捕捉到不同层次的市场动态。
- 自回归预训练(Autoregressive Pre-training):Kronos使用一个解码器-only的Transformer架构进行自回归预训练。预训练的目标是预测下一个时间步的标记序列,通过最大化观测序列的对数似然来训练模型。这种预训练方式使得模型能够学习到金融时间序列的复杂动态特性,并且能够生成高质量的合成数据。
大规模预训练
- 大规模多市场语料库:Kronos在超过120亿条K线记录的多市场语料库上进行预训练,这些数据涵盖了来自45个全球交易所的多种资产类别和7种时间粒度。这种大规模的预训练语料库使得模型能够学习到丰富的市场动态和跨资产的表示,从而提高了模型的泛化能力和预测性能。
- 数据清洗和预处理:为了确保预训练数据的质量,作者开发了一个专门的数据清洗和预处理流程。这个流程包括处理缺失值、过滤低质量数据段(如异常价格波动、长时间无交易活动等),从而保证了输入数据的高质量和可靠性。
模型的可扩展性和灵活性
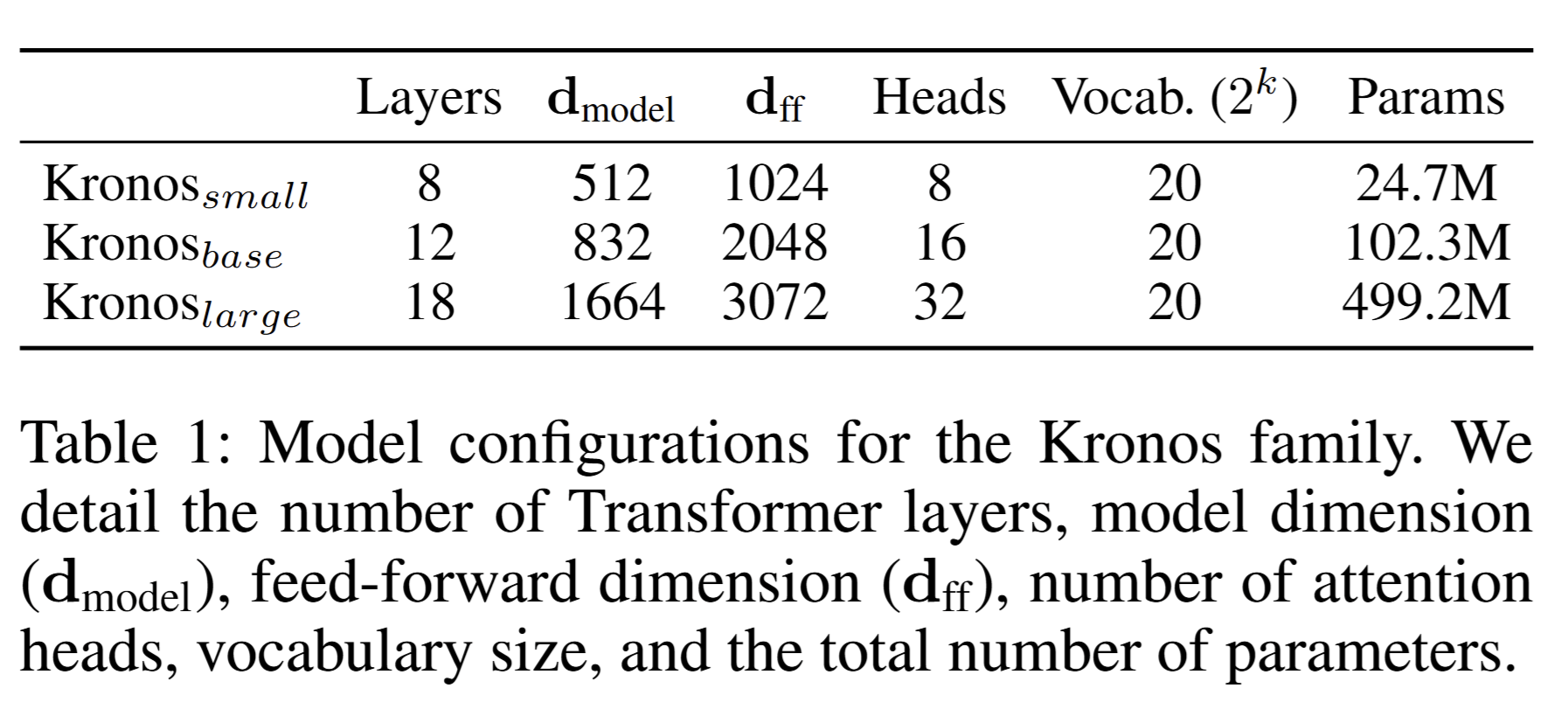
- 不同容量的模型变体:为了满足不同的应用场景和资源限制,作者训练了不同容量的Kronos模型变体,包括Kronos-small、Kronos-base和Kronos-large。这些模型在性能和计算成本之间提供了良好的权衡,使得Kronos能够适应不同的实际应用需求。
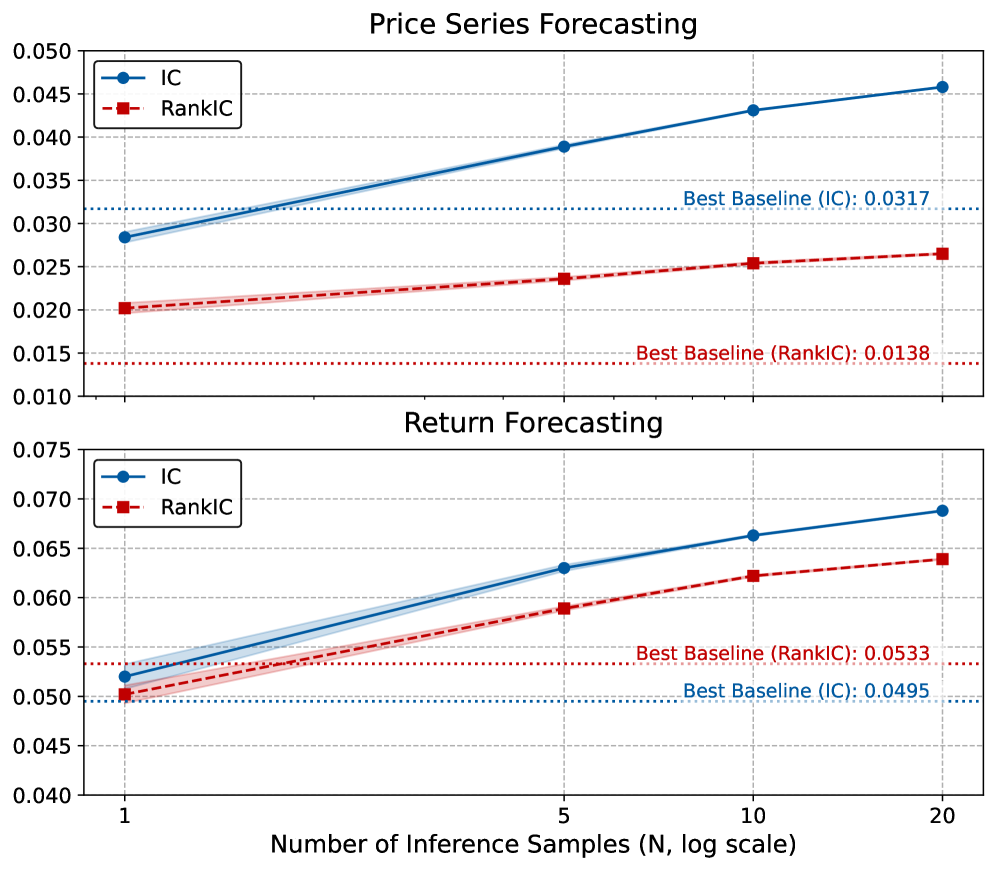
- 推理时的随机采样:Kronos在推理时可以通过随机采样生成多个不同的未来轨迹,并通过对这些轨迹进行平均来提高预测的准确性。这种随机采样策略不仅增加了预测的多样性,还通过减少随机性提高了预测的稳定性和准确性。
通过上述方法,Kronos模型有效地解决了现有TSFMs在金融K线数据上的局限性问题,为金融时间序列分析提供了一个强大而通用的基础模型。
Q: 论文做了哪些实验?
A: 论文设计了一系列实验来全面评估Kronos模型在金融时间序列分析中的性能。以下是实验的详细内容:
实验设置
为了确保实验的严谨性,论文对每个任务都进行了详细的设置,包括数据集的选择、模型的配置和评估指标的定义。以下是实验设置的一些关键点:
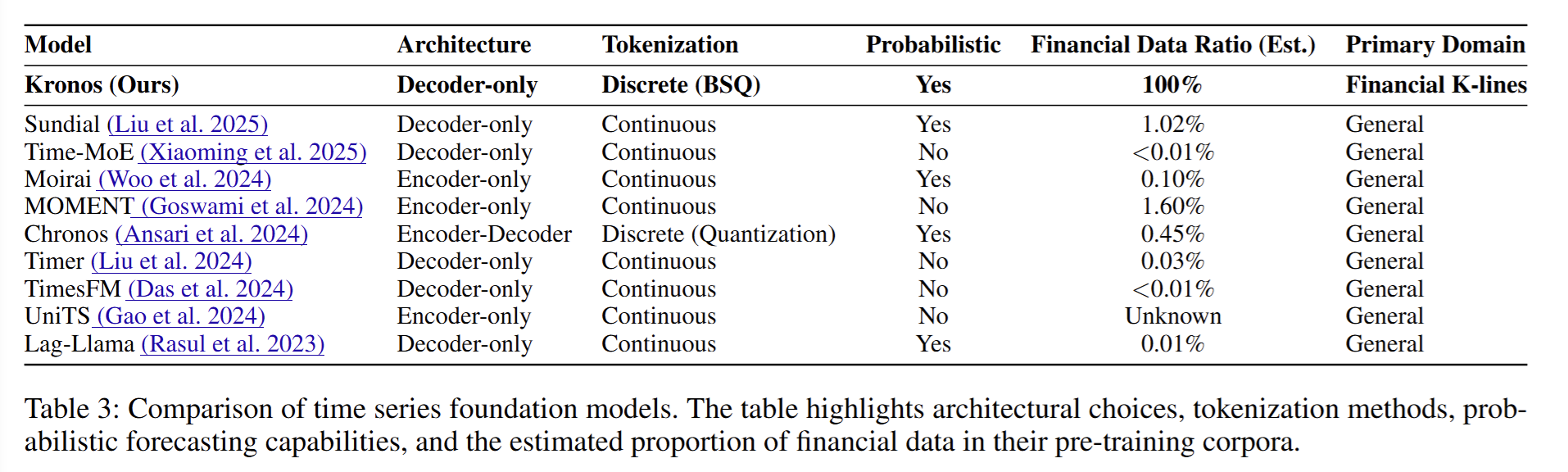
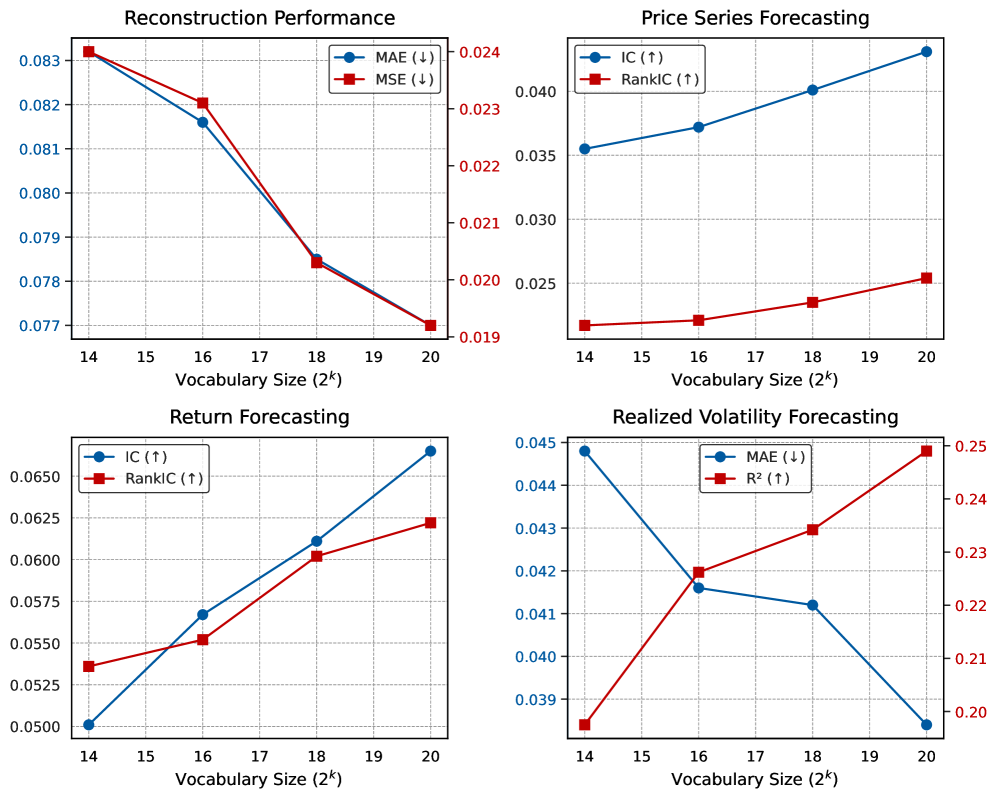
- 数据集:实验使用了超过120亿条K线记录的多市场语料库,涵盖了来自45个全球交易所的多种资产类别和7种时间粒度。数据集的详细统计信息见表13。
- 模型配置:Kronos模型有三个变体,分别是Kronos-small、Kronos-base和Kronos-large,它们在参数数量、模型维度和注意力头数等方面有所不同。详细的模型配置见表1。
- 基线模型:为了进行比较,论文选择了25种现有的时间序列模型作为基线,包括非预训练的全样本模型、零样本时间序列模型、计量经济学波动率模型和生成性时间序列模型。这些模型涵盖了不同的研究领域和方法。
实验任务
论文选择了5个具有代表性的金融任务来评估Kronos模型的性能,这些任务涵盖了预测和生成两个方面:
- 价格序列预测(Price Series Forecasting):
- 目标:预测未来的价格序列。
- 评估指标:信息系数(IC)和秩信息系数(RankIC)。
- 数据集:包括股票、加密货币和外汇市场的多种时间频率数据。
- 收益率预测(Return Forecasting):
- 目标:预测资产的收益率。
- 评估指标:IC和RankIC。
- 数据集:与价格序列预测相同,涵盖多种资产和时间频率。
- 波动率预测(Realized Volatility Forecasting):
- 目标:使用高频价格数据估计已实现波动率。
- 评估指标:平均绝对误差(MAE)和决定系数(R²)。
- 数据集:高频价格数据,涵盖多种资产。
- 合成K线序列生成(Synthetic K-line Generation):
- 目标:生成高质量的合成K线序列。
- 评估指标
- :从多样性、保真度和有用性三个角度评估生成数据的质量。
- 多样性:通过t-SNE嵌入和核密度估计(KDE)比较原始数据和合成数据的分布。
- 保真度:使用判别分数(Discriminative Score)评估合成数据与真实数据的相似度。
- 有用性:通过在合成数据上训练预测模型,并在真实数据上测试其性能(Train-on-Synthetic, Test-on-Real, TSTR)。 - 数据集:包括股票、加密货币和外汇市场的多种时间频率数据。
- 投资模拟(Investment Simulation):
- 目标:在真实市场环境中验证模型的预测信号的有效性。
- 评估指标:年化超额回报(AER)和信息比率(IR)。
- 数据集:中国A股市场数据,使用模型的预测信号构建投资组合,并进行回测。
实验结果
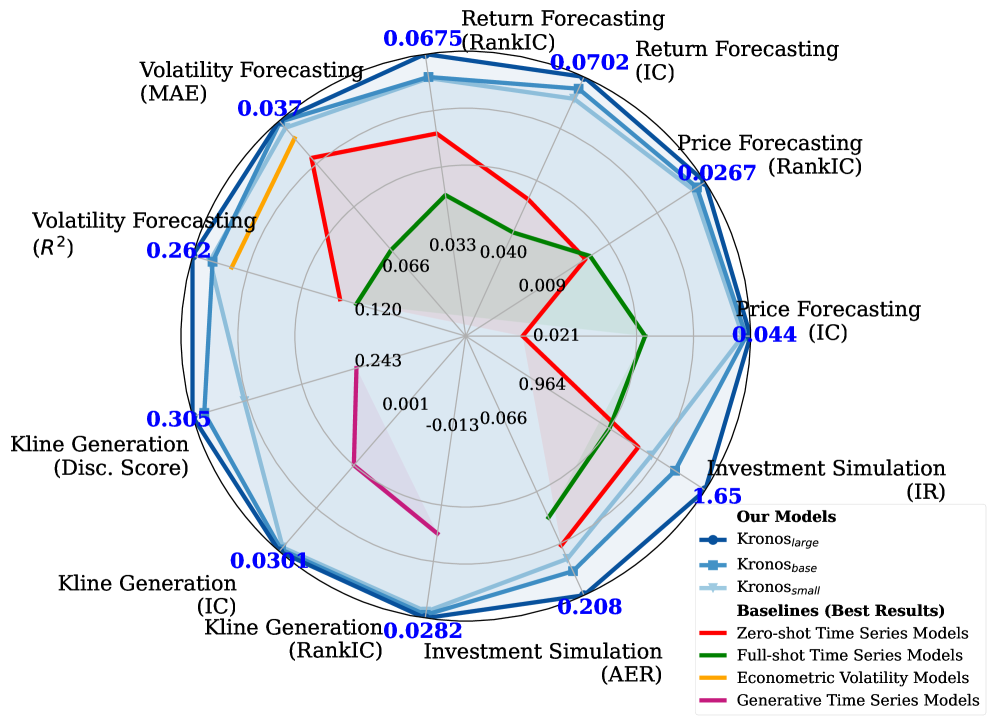
实验结果表明,Kronos模型在所有任务上均取得了显著优于现有TSFMs和非预训练模型的性能。以下是实验结果的详细内容:
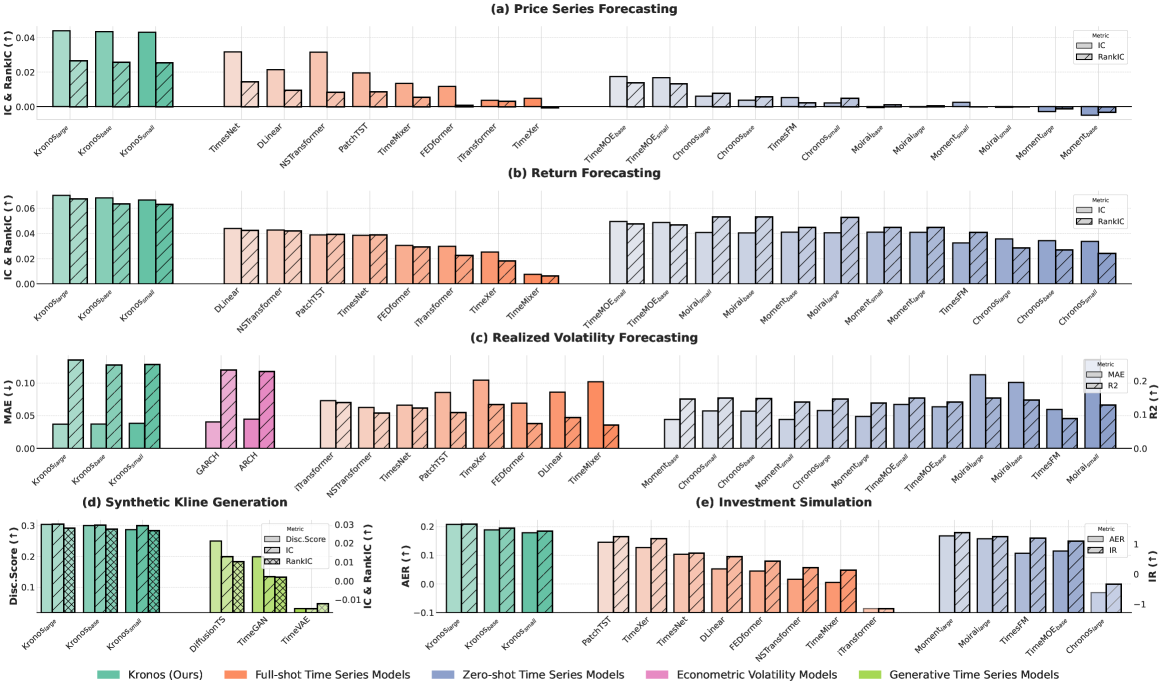
- 价格序列预测:
- Kronos在价格序列预测任务上取得了显著的性能提升,RankIC比领先的TSFM高出93%,比最佳非预训练基线高出87%。随着模型容量的增加,性能进一步提升。
- 收益率预测:
- 在收益率预测任务上,Kronos同样表现出色,IC和RankIC指标均优于所有基线模型。这表明Kronos能够准确地预测资产的收益率。
- 波动率预测:
- 在波动率预测任务上,Kronos将MAE降低了9%,R²提高了22%。这表明Kronos能够有效地捕捉到市场波动的动态特性。
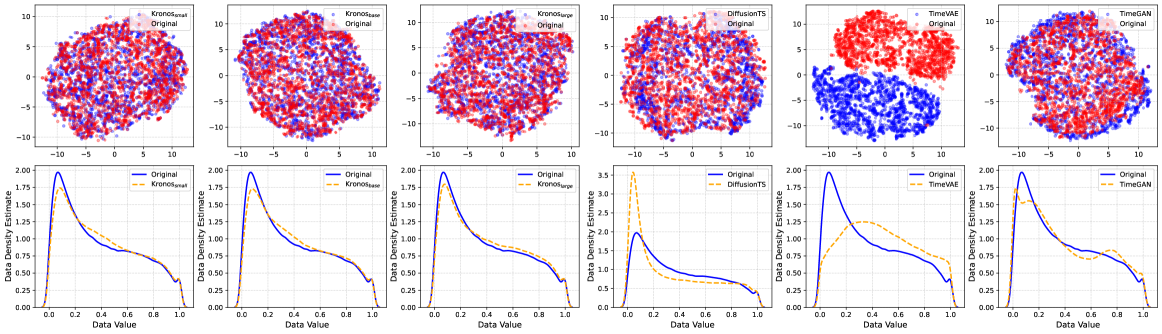
- 合成K线序列生成:
- 在合成K线序列生成任务上,Kronos在多样性、保真度和有用性三个方面均表现出色。生成数据的t-SNE嵌入和KDE分布与原始数据高度重叠,判别分数接近0.5,表明合成数据与真实数据难以区分。此外,使用合成数据训练的预测模型在真实数据上的测试性能也优于其他基线模型。
- 投资模拟:
- 在投资模拟任务上,Kronos在年化超额回报(AER)和信息比率(IR)两个指标上均取得了最高的性能,表明Kronos的预测信号能够有效地转化为实际投资收益。
结论
ttps://files.mdnice.com/user/56459/8d429f7c-886c-4363-8025-3144602baaef.png)
[外链图片转存中…(img-cdyNXOw3-1757745216877)]
[外链图片转存中…(img-FYW9b0en-1757745216877)]
结论
通过这些实验,论文证明了Kronos模型在金融时间序列分析中的强大性能和广泛适用性。Kronos不仅在预测任务上取得了显著的性能提升,还在生成任务上展示了高质量的合成数据生成能力。这些结果表明,Kronos模型为金融时间序列分析提供了一个强大而通用的基础模型。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)