【Prompt学习技能树地图】大模型如何“理解”?
LLM是数据驱动的概率模型,其强大能力与固有局限皆源于此。严谨的应用范式理解其本质:认清其是“概率预测”而非“思考”。精通其调控:熟练运用参数引导其行为。系统化治理其局限:通过RAGAgent等架构,将LLM与外部知识、符号系统、工具环境相结合,构建可靠、安全、可控的智能系统。未来的发展已从追求“更大模型”转向构建“更智能系统”,即如何将LLM作为强大的核心组件,与其他模块化技术有效集成,迈向能感
阶段:入门 模块:认知层
具体内容:
1.理解LLM原理:知其然(文本生成)并知其所以然(概率预测、基于训练数据的统计模型)。
2.核心概念:了解Token、Temperature、Top-P、频率惩罚等参数的基本影响。
3.局限性认知:理解模型的幻觉、知识截止日期和偏见问题。
一、LLM工作原理:从“文本生成”表象到“概率预测”本质
1. 表象层 (Phenomenon Level) - “文本生成”
用户观察到的是LLM接收一段提示(Prompt),并返回一段流畅、连贯、且合乎语境的文本。这表现为对话、创作、翻译、代码生成等高级能力。其行为极具迷惑性,仿佛一个理解语言、进行思考的智能体。
2. 本质层 (Mechanism Level) - “概率预测”
LLM的本质是一个基于上下文的条件概率生成模型。其唯一的核心工作是:在给定的上文(上下文)条件下,预测下一个最可能出现的词元(Token)。
- 数学表达:其核心是计算一个条件概率分布 $ P(\text{token}{n} | \text{context}{<n}) $。
- 生成过程:这是一个自回归(Autoregressive) 过程。模型从提示词开始,逐Token地计算概率分布,通过某种策略(如采样)选择一个Token作为输出,将其追加到上下文中,并重复此过程,直至生成完整序列。
- 能力源泉:这种预测能力并非来自“理解”,而是源于对海量训练数据(互联网文本)中词序、句法和语义关联的统计模式的极致拟合。模型是这些统计规律的压缩表示。
3. 核心类比:终极版智能输入法
LLM的核心原理与智能输入法的联想词推荐完全一致,但存在规模鸿沟:
- 基础原理:输入“今天”,输入法推荐“天气”,即计算 $ P(\text{下一个词} | \text{“今天”}) $。
- 规模跃迁:
- 数据:从用户输入习惯 → 整个互联网语料。
- 上下文:从前几个词 → 数万Token的长程上下文。
- 模型:从简单统计模型 → 千亿参数的Transformer神经网络。
因此,LLM是一个拥有海量知识、无限耐心并能考量极长上下文的终极版智能输入法。其高级能力皆从“预测下一个词”这一基础任务中涌现。
二、实现概率预测的三大技术支柱
1. Tokenization:语言的“原子化”
- 专业阐述:Token是模型处理文本的基本单位。通过分词器(Tokenizer),文本被切割为子词(Subword)(如:“unfortunately” → “un”, “##for”, “##tun”, “##ate”, “##ly”)。这能高效处理未登录词(OOV),平衡词汇表大小与序列长度。
- 类比:乐高积木。Token就像一块块标准积木。文本生成就是用这些积木搭建模型。模型的学习就是学习积木之间的拼接规律。
2. 上下文(Context):模型的理解框架
- 专业阐述:上下文指模型在生成时所能参考的全部历史信息(即当前生成位置之前的所有Token序列)。它是模型进行概率预测的唯一依据。上下文的质量和长度直接决定输出的准确性。
- 类比:即兴戏剧的已上演剧情。每位新演员(下一个Token)的台词和动作,必须基于之前所有的剧情(上下文)来即兴发挥,以保证戏剧的连贯性。
3. Transformer架构:动态上下文建模引擎
- 专业阐述:Transformer是LLM的基石架构。其核心自注意力机制(Self-Attention) 允许序列中的任何位置直接与所有其他位置交互,动态计算相关性权重,从而为每个Token生成一个融合了全局上下文信息的深度表征。
- 类比:交响乐总谱分析。一位作曲家分析总谱时,不会孤立看待某个音符,而是同时审视所有乐器的旋律(全局上下文),理解它们如何相互呼应、对抗与融合,从而形成对乐曲的完整理解。Transformer就在并行地进行这种复杂的“总谱分析”。
三、调控上下文利用的关键参数
这些参数是用户指导模型如何利用当前上下文来选择下一个Token的精密旋钮。
| 参数 | 专业机理(对上下文利用的影响) | 基于“导演”类比的理解 | 实践应用 |
|---|---|---|---|
| Temperature | 调节概率分布的平滑度。低T锐化分布(保守);高T平滑分布(创造性)。 | “导演的严格度” • 低T:要求演员严格按剧本(上下文)最合理走向表演。 • 高T:允许演员在不离谱的前提下即兴发挥。 |
• 低T (0.1-0.5):代码、事实问答。 • 高T (0.7-1.0+):创意写作。 |
| Top-p (核采样) | 从概率累积超过阈值p的动态候选集中采样。 | “选角范围限制” 导演只从“最适合的演员清单”(候选集)中挑人, p值控制清单大小。 |
优先调整Top-p。p=0.9是常用起始点。 |
| Frequency Penalty | 降低已生成上下文中已出现Token的概率,防重复。 | “防剧透机制” 导演:“这台词用过了,换一句。” |
生成长文本时设置(如0.5-1.5)。 |
| Presence Penalty | 对已生成上下文中出现的概念施加固定惩罚,鼓励新主题。 | “防剧情停滞” 导演:“这个话题聊完了,该转场了。” |
推动对话或叙事转向新方向。 |
四、LLM的三大核心局限性及最前沿应对策略
1. 幻觉(Hallucination)
- 根源:模型被优化为生成统计上合理的文本,而非事实正确的文本。它缺乏事实核查的内在机制。
- 前沿策略 - 检索增强生成(RAG):
- 原理:在生成前,先从外部知识库(如数据库、文档)检索相关证据,将其作为增强上下文与用户查询一并提供给LLM,让其“开卷考试”。
- 类比:专家咨询会议。LLM是专家,检索器是秘书。秘书会前从图书馆(知识库)找来最新资料(外部上下文),专家结合资料和自己的学识进行综合解答,而非仅凭记忆。
2. 知识截止(Knowledge Cutoff)
- 根源:模型参数静态化,无法感知训练截止日期后的新知识。
- 前沿策略:
- RAG(同上):通过更新外部知识库来绕过该问题,无需重新训练模型。
- 持续学习(Continual Learning):研究如何用新数据高效更新模型参数而不灾难性遗忘旧知识,是重大研究挑战。
3. 逻辑与推理瓶颈
- 根源:Transformer架构擅长模式匹配与关联,但在需要严格、多步、符号化推理的任务上存在固有瓶颈。
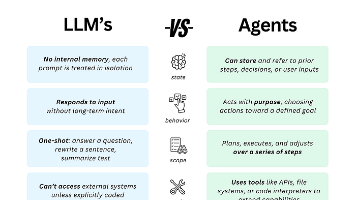
- 前沿策略 - 智能体(Agent)与工具调用(Tool Use):
- 原理:将LLM视为一个核心“大脑”(规划与决策器),赋予其调用外部工具(如计算器、代码解释器、搜索引擎、API)的能力。模型自主规划步骤,利用工具弥补自身在计算、检索、逻辑等方面的不足。
- 类比:一位精通语言但数学不好的经理。他不会自己算账,但懂得命令(调用) 计算器(工具)进行计算,然后基于结果继续他的工作。LLM Agent正在成为构建复杂AI应用的新范式。
总结与展望
LLM是数据驱动的概率模型,其强大能力与固有局限皆源于此。严谨的应用范式是:
- 理解其本质:认清其是“概率预测”而非“思考”。
- 精通其调控:熟练运用参数引导其行为。
- 系统化治理其局限:通过RAG、Agent等架构,将LLM与外部知识、符号系统、工具环境相结合,构建可靠、安全、可控的智能系统。
未来的发展已从追求“更大模型”转向构建“更智能系统”,即如何将LLM作为强大的核心组件,与其他模块化技术有效集成,迈向能感知、规划、行动并持续学习的具身智能体(Embodied Agent)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)