PPIO上线Qwen3-Next,专为极长上下文和超大规模参数性能优化
并且,经过长期实践,PPIO 已经实现大模型推理的 10 倍+ 降本,实现推理效率与资源使用的动态平衡。Qwen3-Next 系列采用了“混合注意力机制”——引入业内前沿的“线性注意力机制”,与经典的“全注意力机制”混搭使用,该架构专为极长上下文和超大规模参数性能而优化。基于这一架构,Qwen 训练并开源了 Qwen3-Next-80B-A3B——总参数 800 亿,但仅 30 亿处于激活状态,实

今天,阿里通义千问发布了下一代基础模型 Qwen3-Next,该模型已经首发上线 PPIO!
Qwen3-Next 系列采用了“混合注意力机制”——引入业内前沿的“线性注意力机制”,与经典的“全注意力机制”混搭使用,该架构专为极长上下文和超大规模参数性能而优化。
现在,PPIO 上线了 Qwen3-Next-80B-A3B-Instruct 和 Qwen3-Next-80B-A3B-Thinking 两款模型,前者为非思考模型,后者为思考模型,上下文长度为 64K。
价格方面,Qwen3-Next-80B-A3B-Instruct 每百万输入 tokens 1 元、每百万输出 tokens 10 元;Qwen3-Next-80B-A3B-Thinking 每百万输入 tokens 1 元,每百万输出 tokens 4 元。
前往 PPIO 官网或点击文末阅读原文即可体验,新用户填写邀请码【LYYQD1】注册可得 15 元代金券。
快速入口:
https://ppio.com/llm/qwen-qwen3-next-80b-a3b-instruct
https://ppio.com/llm/qwen-qwen3-next-80b-a3b-thinking
# 01
Qwen3-Next 的架构创新
Qwen3-Next 系列代表了 Qwen 系列下一代的基础模型,专为极长上下文和超大规模参数性能而优化。
这一系列引入了一套架构创新,旨在最大化性能的同时最小化计算成本:
-
混合注意力(Hybrid Attention):用 Gated DeltaNet 与 Gated Attention 组合替代标准注意力,实现高效上下文建模。
-
高稀疏度 MoE:在 MoE 层中实现 1:50 的极低激活比,大幅减少每个 token 的 FLOPs,同时保留模型容量。
-
多 Token 预测(MTP):提升预训练模型性能,加快推理速度。
-
训练稳定性友好设计:包括零中心和带权衰减的 LayerNorm、Gated Attention,以及其他稳定性增强手段。
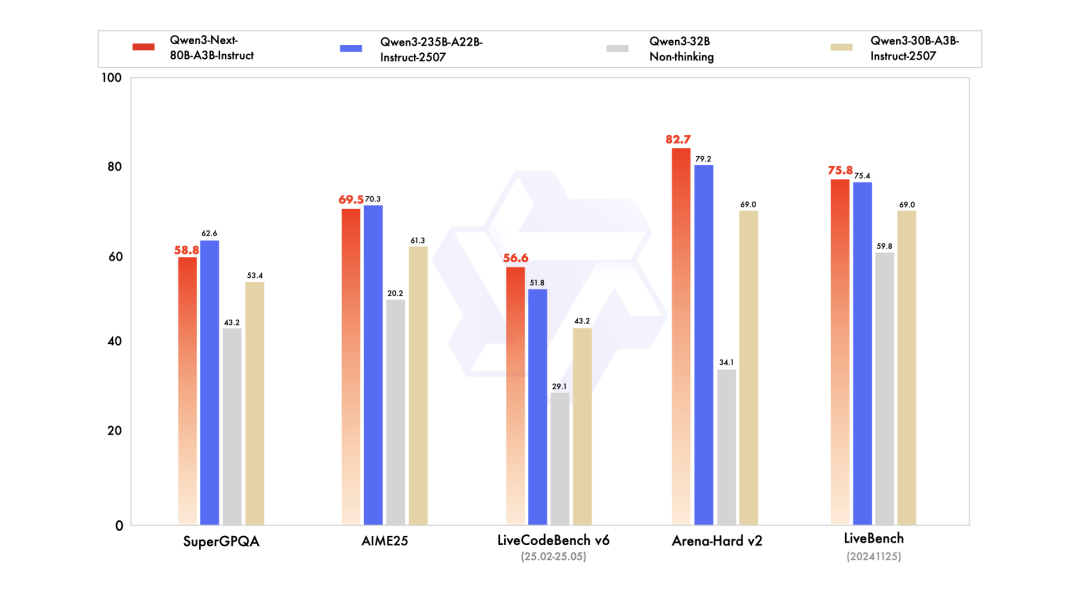
基于这一架构,Qwen 训练并开源了 Qwen3-Next-80B-A3B——总参数 800 亿,但仅 30 亿处于激活状态,实现了极端稀疏性与高效率。
尽管极度高效,Qwen3-Next 在下游任务上的表现仍优于 Qwen3-32B —— 同时训练成本却不到十分之一。
此外,在处理超过 32K tokens 的长上下文时,它的推理吞吐量比 Qwen3-32B 高出 10 倍以上。
# 02
如何在 PPIO 使用?
我们将 PPIO Qwen3-Next 的模型 API 接入 Cherry Studio 进行体验。
提示词 1:
请用三种不同的身份回答同一个问题:
-
身份1:物理学博士
-
身份2:中学老师
-
身份3:科幻小说作家
问题:量子计算与经典计算的根本差异是什么?
该问题测试 MoE 路由是否能覆盖不同领域的知识,Qwen3-Next-80B-A3B-Instruct 的回答如下:

提示词2:
某工厂有三个机器:A、B、C。
-
A 生产 40 个零件,每个零件有 20% 概率次品。
-
B 生产 60 个零件,每个零件有 10% 概率次品。
-
C 生产 100 个零件,每个零件有 5% 概率次品。
问题:如果我从总产出里随机抽一个零件,结果是次品,那么它来自机器 A 的概率是多少?请详细推理。
该问题测试模型的推理能力是否因为 MoE 的稀疏化受影响,Qwen3-Next-80B-A3B-Thinking 的回答如下:

现在,你可以到 PPIO 官网在线体验 Qwen3-Next ,或者将模型 API 接入 Cherry Studio、ChatBox 或者你自己的 AI项目中。
查看详细接入教程:
https://ppio.com/docs/model/overview

PPIO 致力于为企业及开发者提供高性能的模型 API 服务,目前已上线 DeepSeek R1/V3、Qwen3、Kimi K2 等系列模型,仅需一行代码即可调用。并且,经过长期实践,PPIO 已经实现大模型推理的 10 倍+ 降本,实现推理效率与资源使用的动态平衡。
最后送一份福利:PPIO 整理了 20 余篇 Agent 相关的白皮书 & Blog,无论你作为开发者参考业内最前沿的 Agent 开发经验,还是作为 AI 爱好者学习最前沿的 Agent 趋势,都可以扫码下载。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)