【Agent】Agent相关
个人学习记录
文章目录
前言
个人学习记录。
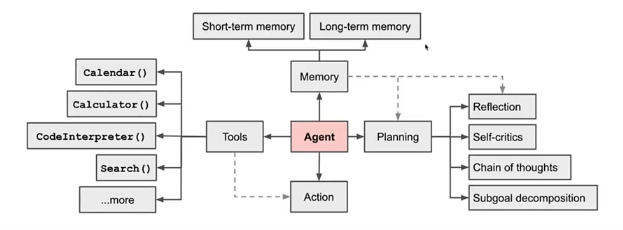
Agent的理解
大模型和特色的代码块组成,通过特色代码块进行对应的特定功能实现如Excel的读取,将处理结果给大模型进行分析和汇总,最后完成功能。
主流Agent Prompt模板
| 模板 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| ReACT | ReACT 模板较为简单,先设定 Question,再以 Thought、Action、Action Input、Observation 执行多轮,最后输出 Final Answer | prompt 简单 | 1. API 参数只能有一个2. 没有设定反思等行为,对于错误的思考不能及时纠正 |
| ModelScope | 更为直接的生成回复,调用只需要加入和字段,并在其中填入 command_name&args | 简单直接 | 没有设定反思等行为,对于错误的思考不能及时纠正 |
| AutoGPT | prompt 较为复杂,分为生成工具调用和生成最终答案两套 prompt;生成工具调用 prompt 详细设立了 Constraints(例如不需要用户协助)、Resources(例如网络链接)、Best Practices(例如每个 API 都需要花费,尽量少的调用),最终严格以 json 格式输出 | prompt 限制多,会较好地进行自我反思、任务规划等 | prompt 较长,花费较大 |
| ToolLAMA | 模仿 AutoGPT 和 ReACT,输出以 Thought、Action、Action Input 格式而非 json 格式,增加了 “give_up”,Restart 字段,支持全部推理重来,重来的 prompt 会把历史失败的记录加进去调模型用了 16w Rapid API | prompt 限制多,会较好地进行自我反思、任务规划等,并支持全部推倒重来 | 1. prompt 较长,花费较大2. 全部推倒重来花费更大 |
Agent训练的前人之鉴
当前如果模型返回形式与所需要返回的形式不一致且模型不能按照Prompt格式输出结果,则需要进行训练,需要对全参数进行训练。
训练框架:HuggingFace Trainer + DeepSpeed Zero3
配置说明:max_len: 4096 + Flash Attention + bf16(batchsize=1、AdamW 优化器)
| 模型 | 训练最低配置 | 训练数据规模(token 建) | 建议训练 epoch 数 | 平均训练时长 | 训练成本(估算) |
|---|---|---|---|---|---|
| 7B(全参数) | 4 卡 A100(4 * 80G) | 470M | 5 | 25h * 5 = 125h | 34.742 * 4 * 125 = 17371.0 元 |
| 14B(全参数) | 8 卡 A100(8 * 80G) | 470M | 4 | 24h * 4 = 96h | 34.742 * 8 * 96 = 26681.9 元 |
| 72B(全参数) | 32 卡 A100(32 * 80G) | 470M | 2 | 40h * 2 = 80h | 34.742 * 32 * 80 = 88939.5 元 |
微调和全参调
微调
- 任务与预训练领域相关但需适配:当任务与预训练模型的领域有一定相关性,但需要在特定领域或任务上进行优化时,适合使用微调。例如,将通用的语言模型应用于医疗、法律等特定领域的问答系统,此时可以通过微调,利用少量的领域数据来调整模型,使其更好地适应特定领域的术语和任务需求。
- 数据量有限:微调通常不需要大量的数据,当只有少量的标注数据时,微调可以在预训练模型的基础上,利用这些有限的数据进行优化,从而提高模型在特定任务上的性能。
- 计算资源有限:微调只需要更新少量的参数或者额外的参数,相比于全参调,其计算和存储成本较低,因此在计算资源有限的情况下,如使用单块显卡或者显存较小的设备时,微调是更合适的选择。
全参调
- 任务与预训练差异极大:当任务与预训练模型的领域差异非常大,涉及大量新词汇、结构和逻辑模式时,全参调是更好的选择。例如,从通用语言处理任务迁移到医疗诊断报告生成、法律条文推理、数学证明生成等高度专业化的任务,全参调可以深度重塑模型的参数,以适应新任务的需求。
- 需要彻底改变模型行为或风格:如果需要彻底改变模型的行为或风格,如将文章润色成非常独特的个人风格,如鲁迅式冷峻、王小波式荒诞等,且训练数据足够多(超过 2000 对),全参调能够更好地重塑语言模式,而不仅仅是在原有风格上进行微调。
- 追求最高性能:在学术研究或竞赛等场景中,当对模型的性能指标有极高的要求,需要达到最优结果时,全参调是首选。在有足够的数据和计算资源支持的情况下,全参调可以通过对所有参数的调整,充分挖掘模型的潜力,以获得最佳的性能表现。
- 长序列建模或上下文扩展:当需要对模型进行长序列建模或扩展上下文长度时,如将模型原生支持的 4K tokens 扩展到 32K 或 128K,可能需要重训 RoPE(旋转位置编码)或修改位置嵌入,这种结构性改动通常需要全参调才能稳定收敛。
- 多任务联合训练:在同时进行多个任务的联合训练时,如摘要、翻译、风格迁移、问答等不同任务,全参调可以让模型的各层进行协同优化,避免出现像 LoRA 等方法可能出现的 “任务干扰” 或 “容量不足” 的问题。
Agent Tuning
Agent Tuning的目的
通过 Prompt Engineering 可以实现 Agent,那为什么还要训练 Agent 模型呢?
因为可以这么做的前提是:模型足够 “聪明”,靠着 “说明书” 就能执行,Prompt Engineering 实际上是把 “说明书” 写得更加清晰易懂。
- 实践证明,除了 GPT-4 level 的大模型,其他大模型(包括 GPT-3.5)无法很好遵从 prompt 要求完成复杂的 Agent 任务;
- 在很多实际应用场景,无法使用最强的大模型 API,需要私有化部署小模型,需要控制推理成本;
- 通过训练,一个小参数量的大模型(13B、7B 等)也能达到较好的能力,更加实用。
训练 Agent 模型,可以看做是 “案例学习”,在 “说明书” 的基础上,再通过真实的案例来 “强化培训”。
Agent Tuning训练数据构建的步骤
- 根据实际业务收集大量 query,要尽可能覆盖各种场景;
- 将每一个 query 与 prompt 模板结合,加上 memory,构成 agent prompt,也就是训练数据中的输入部分;
- 为每一个 agent prompt 构建对应的标准答案,也就是训练数据中的输出部分,这项工作可以借助 GPT-4 level 的大模型来降本提效;
- 如果第三步是用大模型来生成答案,则最好通过人工修正或筛选高质量的 Output,数据质量越高,最终 Agent Tuning 得到的模型效果越好。
还须避免灾难性遗忘,即防止训练后模型的通用能力剧烈下降,因此要在训练数据中加上通用 SFT 数据,配比(经验值):Agent 5: 通用 1
Fine Tuning
大模型 Fine Tuning 本质上是在给定输入 Input 的条件下,调整模型的参数,使得大模型生成的输出内容 Output’ 和训练数据中的标准回答 Output 尽可能接近。Fine Tuning 也被称作 Supervised Fine Tuning,简称 SFT,有监督微调,训练数据中的 Output 就是用来 “监督” 模型参数调整的。
Agent Tuning 是一种特殊的 fine-tuning,有时也被称作 Tool SFT,特殊之处在于:
- Agent Tuning 的 Prompt 更复杂,约束条件更多;
- 通常 Agent 工作过程是多步的,因此训练数据也需要是多步骤的,多步之间前后有关联。
模型训练
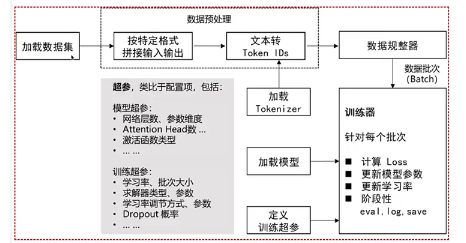
Agent 模型通常需要全参数训练,LoRA 效果不好。
高阶经验(大家了解即可):
- 应用加速训练、节省显存的方法,例如:混合精度、分布式训练(Deepspeed Zero3)、梯度检查点(Gradient Checkpointing)、梯度累积(Gradient Accumulation)、Flash Attention 等;
- 推理用 vllm 等框架加速。
效果评估
- 自动评估
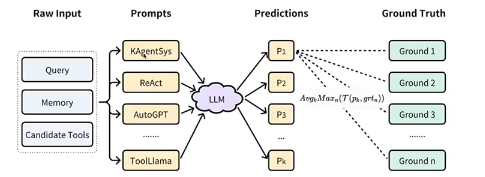
自动评估的主要目的是在模型训练过程中监控模型的效果,评估指标的对比意义大于绝对值意义。
1、 采用 Agent - 4 + 人工的方式构建自动评估的 benchmark(一般从训练数据中随机分出一部分即可);
2、将 GPT - 4 输出结果与 benchmark 中的参考答案进行对比,计算得到分数。 - 人工评估
Agent泛化性提升
基座大模型本身的理解能力和 Agent Tuning 训练数据的多样性共同决定了 Agent 的泛化能力。在指定了基座模型的情况下,我们可以做的是提升训练数据的多样性。
我们可以将训练数据 Input 部分拆解为 3 个变量:Query、Tools、Agent Prompt 模板,最终的数据就是这 3 个变量的组合。
- Query:
覆盖全部场景:对于内部业务工具构造特定 query,尽可能覆盖所有可能的业务场景,避免有遗漏;
困难负样本:构造正样本(需要用到工具的 query) + 困难负样本(看似和工具有关,但实际上不调用),其中大部分是正样本,但不能全是正样本
示例:上海明天天气怎么样?(正样本)| 北京今天下雨吗?(正样本)| 今天天气真好(困难负样本)
经验值:正样本和困难负样本比例 4:1,仅供参考。
样本复杂度多样:简单样本和复杂样本都需要构造,简单样本为一步即可完成的任务,复杂样本为涉及多步推理、多种工具的任务;(实践中评测时发现,仅减少 550 复杂 query,测试集中的事实准确率下降 6 个百分点)
示例:这周末适合去北京郊区露营吗?如果适合,请推荐几个地方?| 刘德华的女儿几岁了?(涉及到多步工具调用)
经验值:简单样本与复杂样本比例 6:1,仅供参考。
Agent Prompt模板多样性提升
通过 Prompt Engineering 来设计一个基于 GPT-4 的 Agent,用于生成多样性的 Agent Prompt 模板,我们称之为:Meta-Agent(元 - Agent)。
Meta-Agent Prompt:用于调用 GPT-4 生成 Agent Prompt 模板的 Prompt,我们称之为 Meta-Agent Prompt。
我们可以手动写一个固定的 Meta-Agent Prompt 作为 GPT-4 的输入,利用大模型内容生成的多样性来生成不同的模板,但实际上多样性效果有限,更好的方式是用不同的种子 query 做引导,提升多样性。
- 根据实际业务收集大量 query,要尽可能覆盖各种场景;
- 选取相似的数条 query 组成多个集合,如果数量不足,这一步也可以借助 GPT-4 来对 query 做扩展;
- 设计一个 Meta-Agent Prompt 模板,将不同的 query 集合插入设计好的模板中组合成不同的 Meta-Agent Prompt;
- 调用 GPT-4 生成不同的 Agent Prompt 模板。
训练数据构建关键经验
1、数据质量:
- 准确性:确保数据的标注正确且准确。错误标注会导致模型学到错误的模式。
- 一致性:数据应该保持一致,避免同样的输入在不同记录中对应相互冲突的答案。
2、数据量:
- 数量:足够大的数据量有助于模型捕捉复杂的模式。数据量不足可能导致模型过拟合。
- 多样性:数据应包含尽可能多的不同情况,避免模型对某些特定模式的偏好。
3、数据平衡:确保各种类型的数据量相对平衡。例如对于分类问题,类别不平衡会导致模型偏向多数类。
4、数据增强:
- 数据扩充:对于图像、文本等数据,通过旋转、翻转、添加噪声等方法扩充数据量。
- 合成数据:在数据量不足时,考虑生成合成数据。
5、数据清洗:
- 去重:删除重复的数据记录,避免模型学习到重复信息。
- 提质:对于含有瑕疵的数据,合理补充修正或直接删除。
6、隐私和合规性:
- 隐私保护:确保数据的收集和使用符合隐私保护法规。
- 数据匿名化:对敏感数据进行匿名化处理,保护个人隐私。
7、数据分割:
- 训练集、验证集、测试集:将数据合理分割为训练集、验证集和测试集,确保模型的泛化能力。
- 避免数据泄露:确保训练数据中不包含测试数据的信息,避免模型在测试时表现出非真实的高精度。
8、持续更新:
- 数据更新:随着时间推移,定期更新训练数据,保持模型的准确性和可靠性。
- 模型监控:监控模型性能,及时发现和解决数据相关的问题。
几个Agent Tuning开源项目介绍
ToolBench (ToolLLaMA)
- 发布机构:面壁智能
- 4.8k stars
- https://github.com/OpenBMB/ToolBench
提供数据集、相应的训练和评估脚本,以及在 ToolBench 上经过微调的强大模型 ToolLLaMA。
数据:ToolBench,包含 469585 条数据(工具数量:3451;API 数量:16464);
模型:ToolLLaMA-2-7b-v2、ToolLLaMA-7b-v1、ToolLLaMA-7b-LoRA-v1
AgentTuning
- 发布机构:智谱华章
- 1.4k stars
- https://github.com/THUDM/AgentTuning
利用多个 Agent 任务交互轨迹对 LLM 进行指令调整的方法。评估结果表明,AgentTuning 让 LLM 在未见过的 Agent 任务中也展现出强大的泛化能力,同时通用语言能力也基本保持不变。
数据:AgentInstruct,包含 1866 个高质量交互、6 个多样化的真实场景任务;
模型:AgentLM 由 Llama2-chat 开源模型系列在 AgentInstruct, ShareGPT 混合数据集上微调得到,有 7B、13B、70B 三个模型。
KwaiAgents
- 发布机构:快手
- 1.1k stars
- https://github.com/KwaiKEG/KwaiAgents
快手联合哈尔滨工业大学研发,使 7B/13B 的 “小” 大模型也能达到超越 GPT-3.5 的效果。
数据:KAgentInstruct,超过 20w(部分人工编辑)的 Agent 相关的指令微调数据;KAgentBench:超过 3k 条经人工编辑的自动化评测 Agent 能力数据;
模型:采用 Meta-Agent 方法训练,包括 Qwen-7B-MAT、Qwen-14B-MAT、Qwen-7B-MAT-cpp、Qwen1.5-14B-MAT、Baichuan2-13B-MAT。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)