Less is More : Adaptive Program Repair with Bug Localization and Preference Learning
自动程序修复(APR)是一项为错误代码自动生成补丁的任务。然而,大多数研究都侧重于生成正确的补丁,而忽略了修复代码与原始错误代码之间的一致性。如何进行自适应的bug修复,并以最小的修改生成补丁,很少有人去研究。为了弥补这一差距,我们首先引入了一个新的任务,即AdaPR(自适应程序修复。然后,我们提出了一种两阶段的方法AdaPatcher(AdaptivePatchGenerator)来增强程序修复
基本信息
2025AAAI
博客贡献人
田心
作者
Zhenlong Dai , Bingrui Chen , Zhuoluo Zhao , Xiu Tang , Sai Wu , Chang Yao , Zhipeng Gao , Jingyuan Chen
摘要
自动程序修复(APR)是一项为错误代码自动生成补丁的任务。然而,大多数研究都侧重于生成正确的补丁,而忽略了修复代码与原始错误代码之间的一致性。如何进行自适应的bug修复,并以最小的修改生成补丁,很少有人去研究。为了弥补这一差距,我们首先引入了一个新的任务,即AdaPR(自适应程序修复)。然后,我们提出了一种两阶段的方法AdaPatcher (Adaptive Patch Generator)来增强程序修复,同时保持一致性。在第一阶段,我们利用带有自调试学习功能的Bug Locator来精确定位Bug位置。在第二阶段,我们训练一个Program Modifier,以确保修改后的固定代码和修改前的bug代码的一致性。Program Modifier增强了位置感知修复学习策略,以根据已识别的错误行生成补丁,选择性参考的混合训练策略和自适应偏好学习,以优先考虑较少的更改。实验结果表明,我们的方法在很大程度上优于一组基线,验证了我们的两阶段框架对新提出的AdaPR任务的有效性。代码和数据集可在https://github.com/zhenlongDai/AdaPatcher上获得。
1 介绍
随着软件系统在日常生活中越来越普遍,软件bug也变得不可避免。这些软件漏洞可能会导致潜在的安全问题甚至经济损失。通常,开发人员需要花费大量的时间和精力来手动修复这些有bug的代码。为了减轻开发人员修复错误的负担,引入了自动程序修复(APR)来根据原始错误代码自动生成补丁。APR技术以有bug的代码和正确的规范作为输入,目的是生成满足给定规范的固定程序。
如今,大型语言模型(LLMs)在代码生成和代码理解方面表现优异,研究人员已经应用LLMs来执行APR任务,并取得了显著的成果。然而,大多数研究都集中在生成正确的补丁上,修复后的代码和有bug的代码之间的一致性往往被忽略,也无法得到保证,这极大地阻碍了LLMs在bug修复中的实际应用。
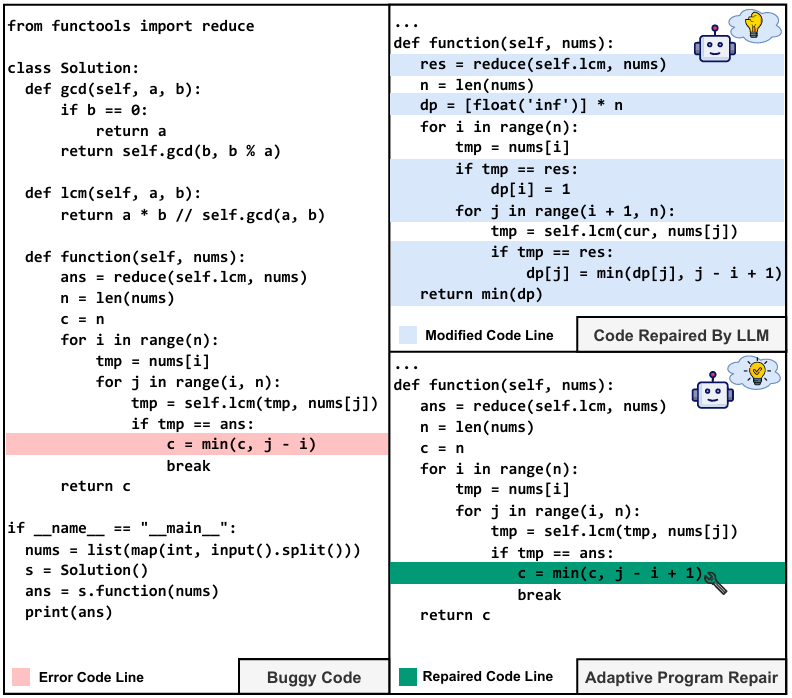
Figure 1: Example of AdaPR. The adaptive repaired code is correct and minimizes code modifications.
以图1中的实际场景为例,Alice是一名开发人员,她实现了Solution类来实现她的目标。尽管如此,她的程序未能通过测试,这表明她编写的代码中存在潜在的bug。错误信息提“AssertionError: Expected output is 4, but the received output is 3”。Alice通过向LLMs提供原始的错误代码和错误消息来修复这个错误。然而,LLMs生成的补丁覆盖了函数中的大部分代码行(用蓝色表示)。Alice很难接受这个补丁,因为生成的代码与她最初编写的代码相差太远。LLMs所做的大量修改使修复后的代码难以跟踪和理解。
为了解决这一差距,我们提出了一个新的工作,即自适应程序修复,表示为AdaPR。与APR不同,AdaPR不仅旨在为有bug的代码生成“正确”的补丁,而且旨在以最小的修改生成“一致”的补丁。更正式地说,给定有缺陷的代码和正确的规范(例如,失败的测试用例),AdaPR自适应地修复有缺陷的程序,并尽可能少地更改以满足给定的规范。例如,在图1中,Alice可以通过只更改一行代码来修复这个bug,即从c = min(c, j - i)到c = min(c, j - i + 1)。这个新生成的补丁符合她的设计意图和现有的代码结构。修复后的代码和原始错误代码之间的一致性使Alice很容易理解代码更改,并增加了她对这种修复模式的信心。因此,Alice毫无疑问地接受了这个补丁并将其合并到她的代码库中。
到目前为止,现有的研究主要集中在生成正确的补丁,没有研究如何在最小的修改下自适应修复错误代码。关于以下关键挑战,AdaPR是一项非常重要的任务:(i)在哪里修复:确定引入错误的精确位置是一项挑战。当bug发生时,程序的不同部分可能会根据bug表现出异常行为。要自适应地修复错误,AdaPR首先需要定位问题的根本原因,并精确定位需要修改的错误行。(ii)如何修复:以最小的修改生成补丁是具有挑战性的。因为LLMs通常是在通用编程语料库上训练的(例如,注释-代码对,问题-解决方案对),LLMs的主要目标是生成正确的功能代码。关于程序修复,LLMs倾向于通过从头开始重写程序来修复程序,而不考虑现有的代码结构或语义。AdaPR要求补丁既正确又一致。换句话说,生成的补丁应该尽可能少地涉及修改,同时仍然有效地解决bug。如何增量地、自适应地修复程序是这项工作中的另一个挑战。
为了应对上述挑战,我们提出了一种新的两阶段方法,称为AdaP补丁器,旨在正确和一致地修补错误程序。为了解决第一个需要修复的挑战,我们提出了一个基于差异的组件,即Bug Locator,以精确定位Bug代码中的准确Bug位置。具体来说,对于同一开发人员编写的通过的程序和失败的程序,我们首先分别记录不同变量的运行时值。接下来,我们教LLM进行自我调试学习,以识别bug位置,即引导LLM调试和分析通过的程序和失败的程序之间的差异(例如,代码删除、修改),并最终确定哪一行代码导致了测试失败。为了解决第二个如何修复挑战,我们为第二阶段设计了一个Program Modifier组件。Program Modifier通过三种技术增强,以确保修复后的程序和原始错误程序的一致性和正确性。特别是,为了避免LLMs从头开始修复程序,我们利用位置感知修复学习来基于已识别的错误行生成补丁。为了减少错误错误位置的负面影响,我们提出了一种混合训练策略,使Program Modifier能够选择性地引用错误位置,而不是盲目地修改它们。此外,为了使代码更改尽可能小,Program Modifier被训练成通过自适应偏好学习产生更少的修改。
综上,本文贡献:
1)自适应程序修复:我们首先提出了一个新的任务,即AdaPR,以最小的修改来修复有bug的代码。这个新提出的任务旨在产生既正确又一致的代码补丁,这在现实世界的软件开发中更实用。
2)构建数据集:我们构建了一个数据集,其中包含超过50K的bug代码,测试用例,固定代码⟩数据样本,据我们所知,它是该任务的第一个大型数据集。
3)实验和评估:提出了一种新的AdaPatcher模型来执行AdaPR任务。AdaPatcher基于LLMs,并引入了一些定制的改进,以有效地处理修复的位置以及如何解决挑战。实验结果显示了我们的模型在一组基线上的有效性,显示了它在增强自动化程序修复的同时减少修改的潜力。
2 相关工作
大型语言模型(LLM)的进展已推动其被系统性地引入自动化程序修复领域(Sobania et al. 2023;Xia, Wei, and Zhang 2023;Jiang et al. 2023;Paul et al. 2023)。研究表明,通过引入反馈机制对面向代码的 LLM 进行增强具有显著潜力(Miceli-Barone et al. 2023),尤其是借助编译器等外部工具所输出的追踪信息或测试诊断结果(Bouzenia et al. 2023;Xia and Zhang 2022)。在此基础上,链式思维(CoT)推理循环(Yao et al. 2022)已被用于依据调试器的交互式反馈预测修复动作。NExT(Ni et al. 2024)则进一步聚焦于调优 LLM,使其能够基于既有的执行信息开展推理。此外,LLM 还可为错误生成自然语言解释(Chen et al. 2023;Zhang et al. 2022),从而提供另一种有效的反馈形式。自我改进方法通过链式思维推理对 LLM 自身生成的反馈进行迭代式精炼,以持续优化代码输出(Madaan et al. 2024;Zhang et al. 2023)。CoFFEE(Moon et al. 2023)利用 LLM 为错误生成自然语言解释。
现有自动化程序修复研究主要聚焦于修复精度的提升,而本文工作则致力于在最小化代码变动的约束下增强程序修复能力。
3 方法论
在本节中,我们将介绍一种新的两阶段框架AdaP附加器,旨在增强程序修复,同时保持一致性。第一阶段使用Bug Locator来识别Bug的根本原因,并以Code Diff的形式精确定位有Bug的代码行。第二阶段利用Program Modifier自适应地提出修复针对已识别的有bug的代码行。这种方法优先考虑需要最小更改的补丁,从而保持代码库的清洁度和可维护性。
任务定义
给定一个特定的编程任务,一个有bug的代码
和一个正确的规范
,目标是生成一个有bug的代码的修复后的代码,记为
,它满足规范
。修复后的代码
应该与周围的代码保持一致性,并且需要对原始代码
进行最小的修改。
第一阶段:Bug Locator
LLMs表现出了较强的代码理解能力,然而,他们经常难以准确识别和描述代码错误,特别是在精确定位错误行方面。为了应对这一挑战,我们提出了一种基于差异的方法来简化和澄清LLMs的错误位置。如图2所示,bug位置在语义和结构上都与相应的bug行对齐,使用“-”符号前缀表示需要删除或更正。Code Diff的形式通过提供需要更改的结构化和明确的指示,简化并清楚地确定bug位置。这使得Bug Locator更容易将注意力集中在代码的相关错误部分上。
此外,由于LLMs通常缺乏对运行时程序执行的理解,因此识别和定位运行时错误是一项挑战。为了解决这个问题,我们提出了一种新的自调试学习方法来增强Bug Locator识别和定位运行时错误的能力。
Code Diff的设计:给定一个有bug的代码和更正后的代码
,使用Git通过比较
和
生成一个diff文件,diff文件中用' - '符号标记的行被识别为有bug的行
。diff文件
是通过在
中有bug的行前加上' - '符号来创建的:
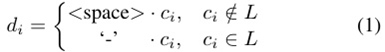
其中是
文件的第i行,
和
都包含
行。符号'·'表示字符串连接,<space>表示空白字符。
Self-Debug Learning(自调试学习):某些bug只会在运行时出现,因此需要了解程序的执行情况。LLMs经常受限于这些bug,因为他们接受的是静态文本形式的代码训练。从rubber duck debugging中汲取灵感,我们引入自调试学习来增强Bug Locator识别和定位运行时错误的能力。
具体来说,给定一个有bug的代码和一个来自正确规范
的相应失败的测试用例
,用
执行代码以捕获实际输出的代码程序的I/O数据,表示为
,包括输入和预期/实际输出。此外,使用Python ' traceback '模块,如图2所示,我们捕获每条执行行的变量状态,并记录执行顺序(用蓝色标记),以创建程序跟踪信息
。
为了方便LLM理解程序跟踪信息,被格式化为紧凑的内联代码注释(用绿色标记),不会破坏代码结构:
1)注释只显示每行执行后发生变化的变量,标记每个执行步骤;
2)循环跟踪信息使用省略号进行压缩,以便进行大的迭代计数。如图2所示,在结构上与基于差异的文件d保持一致,为Bug Locator提供了一致的格式,以识别和定位错误。然后,自调试提示符被构造为:
自我调试学习的目标是通过使用提示最小化Code Diff文件的负对数可能性:
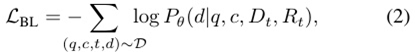
其中所有修复实例形成数据集
,以及
表示LLM的词汇表上的概率分布。
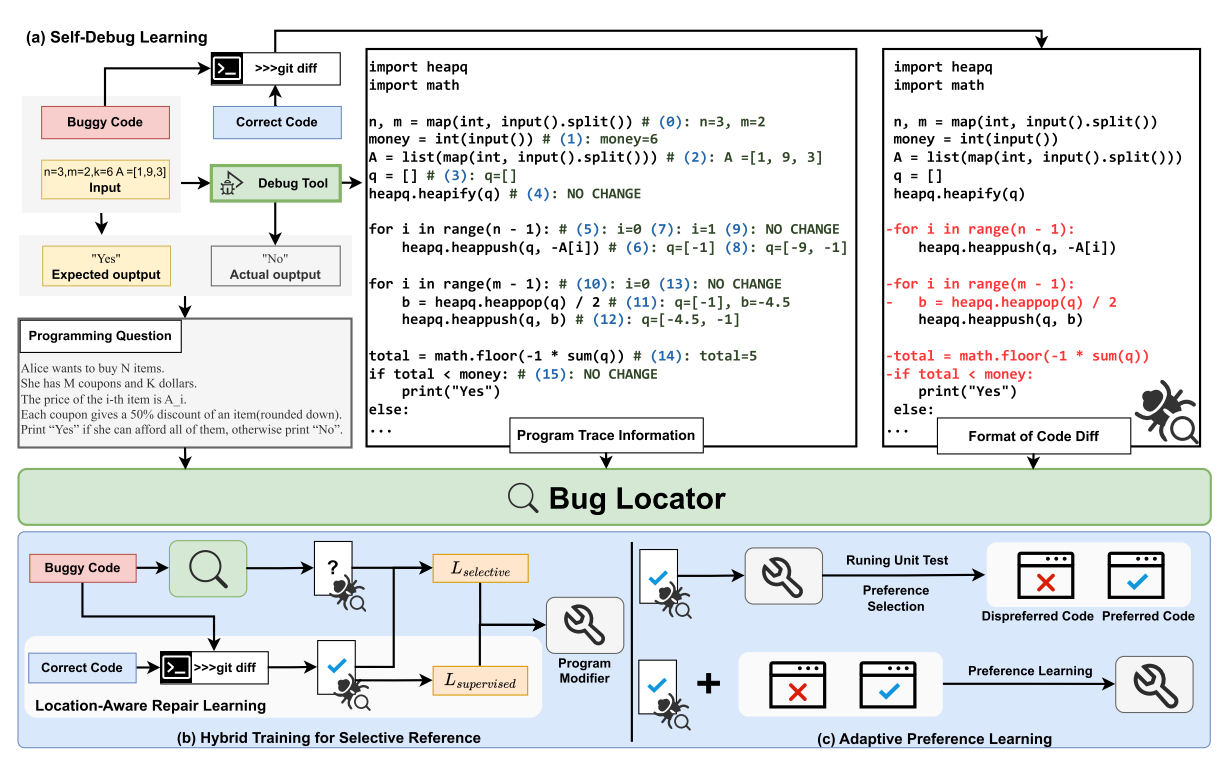
Figure 2: Overview of AdaPatcher. (a) Illustration of the Self-Debug Learning process. (b) Illustration of the Hybrid Train-ing for Selective Reference process. (c) Illustration of the Adaptive Preference Learning process.
第二阶段:Program Modifier
用少量修改修复代码需要了解有bug代码的修改过程。然而,LLMs通常在这个过程中挣扎,因为他们可能没有知识来做出明智的决定,即为了有效地修复代码而进行哪些更改。为了应对这一挑战,我们引入了位置感知修复学习,它指导Program Modifier专注于在第一阶段确定的错误区域。认识到错误Bug Locator产生错误错误位置的可能性,我们提出了选择性参考混合训练,以防止Program Modifier进行不必要的修改,从而提高修复精度。此外,为了进一步减少修改的程度,我们通过自适应偏好学习训练Program Modifier与较少更改的偏好保持一致。
Location-Aware Repair Learning(位置感知修复学习)。为了明确地捕获修改过程,我们提出了位置感知修复学习,它训练Program Modifier通过关注已识别的错误区域来进行精确的修复。给定错误位置和正确的代码,我们指导Program Modifier在不改变不相关代码的情况下进行更正。
具体来说,使用监督学习训练Program Modifier,以预测正确的代码y,如下所示:

其中是LLM词汇表上的概率分布。

Hybrid Training for Selective Reference(选择性参考混合训练)。Bug Locator可能生成错误位置,潜在地导致Program Modifier在修复错误时失败。为了解决这个问题,我们提出了一种选择性参考的混合训练策略,该策略进一步训练Program Modifier根据可能不正确的错误位置修复代码。该训练策略增强了Program Modifier对Bug Locator提供的错误位置的选择性参考,而不是盲目地修改它们。
具体来说,将数据集D拆分为D1和D2,数据体积满足,其中
为比率参数。每个实例
都由Bug Locator
处理以生成新的标签
![]() :
:
![]()
然后我们构造一个新的数据集D2′:
![]()
Program Modifier的选择性引用损失函数为:
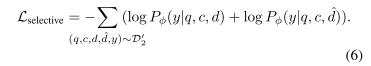
我们使用监督学习数据和选择性学习数据联合训练Program Modifier,保持其修复能力,增强其选择性参考能力:
![]()
其中L(·)表示在训练过程中应用于各自数据集的损失函数。
Adaptive Preference Learning(适应性偏好学习)。即使在修复相同的bug时,不同的方法也会导致不同程度的代码更改。为了在修复过程中优先考虑更少的修改,我们从直接偏好优化(DPO) 中获得灵感,该优化指导LLMs匹配特定的偏好。在DPO的基础上,我们提出了一种自适应偏好学习机制,指导LLMs进一步减少代码修改的程度。给定两个修改程度不同的代码,我们利用偏好学习来指导Program Modifier对较少修改的偏好进行学习,如图2所示。
具体来说,我们获得偏好对(,
),表示首选(即修改较少的正确版本)和不首选(即修改较多的不正确版本)由Program Modifier
在运行单元测试后生成的代码。偏好集
由偏好对
组成。基于偏好集
,我们应用DPO-Positive学习来增强Program Modifier,迭代其训练以获得优先考虑需要较少修改的修复的
。形式上,Program Modifier
的训练目标定义为:
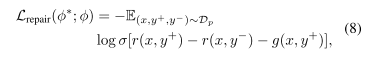
其中表示逻辑函数,
简化为
,
是生成的代码上的奖励函数,由
和
隐式定义,并带有一个超参数
来控制与
的偏差:

表示log-sigmoid内的惩罚项,以鼓励保持首选代码的高对数可能性:
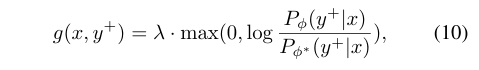
其中为超参数。经过训练后,Program Modifier被优化,以增加生成首选代码的概率,从而以更少的更改实现有效的修复。
4 实验
实验设置
数据集。我们为我们的AdaPR任务构建了第一个数据集,命名为ACPR(准确性-一致性程序修复),旨在从准确性(即正确修复错误)和一致性(即最小化修改)两方面评估生成的补丁。具体来说,我们的数据集收集自CodeNet,其中包含来自不同用户的编程问题提交。对于给定的有bug的程序,我们将其与随机选择的失败测试用例(测试用例包括测试输入和预期输出)以及来自同一用户针对相同编程问题提交的通过的程序配对,从而生成⟨有bug的代码,失败的测试用例,通过的代码⟩三重组样本。整个数据集包含52,168个三元组数据样本。然后,我们将数据集按8:1:1的比例分成训练/验证/测试集,确保任何特定的编程问题只出现在其中一个集中,以避免数据泄漏问题。为了防止来自同一编程问题的代码数据过拟合,并确保评估的公平性,我们通过将训练/验证/测试集中每个问题的最大配对数限制在150/10/20来平衡数据集。数据集的总体统计信息如表1所示。

Table 1: Dataset Statistics.
评估指标。为了彻底评估一个关于AdaPR任务的模型的性能,我们采用了以下评估指标:
(1)代码准确率(Acc):它表示编程问题的所有测试用例成功通过的代码的百分比。
(2)代码改进率(Improve):这个指标衡量的是每段有bug代码的平均改进率。它计算有bug的代码被修改后通过的额外测试用例的比例。第i个固定代码改良率的计算公式如下:
![]()
其中χ(·)是一个指标函数,如果括号内的条件为真,则返回1,否则返回0。如果代码修改后所有之前通过的测试用例仍然通过,则A为真,否则为假。N表示修复后额外通过的用例数量,m表示之前失败的测试用例数量。如果代码通过了bug代码通过的所有测试用例,则第i个修复代码的值为,否则为0。
(3)失败修复率(FR):它统计生成的代码在之前通过的情况下,不通过的比例,计算方法如下:
![]()
其中|D|为代码片段数,χ(·)为指标函数。如果第i段代码导致之前通过的情况失败,为真,否则为假。
(4)代码一致性率(Code Consistency Rate):计算修改后保留的代码行数的比例。其定义如下:
![]()
其中k表示代码修改的行数,r表示修改后代码中保留的代码行数
Baselines。为了评估我们的模型在AdaPR任务上的有效性,我们基于流行的LLMs构建了AdaP附加器,包括闭源和开源模型。对于闭源基线,一个高性能模型gpt - 4o和Claude-Sonnet-3.5被考虑。对于开源基线,我们使用CodeLlama-Instruct-7B,这是一种流行的代码相关任务基础模型。我们分别使用gpt - 4o和CodeLlama进行第一阶段(即bug定位)和第二阶段(即程序修复),分别表示为、
和
,
。所有基线都采用端到端框架来执行程序修复任务。此外,我们将基线与三种广泛使用的基于LLMs的优化方法相结合:
(1)Chain-of-Thought(CoT): CoT提示引出复杂的多步推理,以增强模型对程序修复任务的认知能力。
(2) Few-Shot Learning: 利用LLMs的上下文学习能力,将输入输出对作为额外的上下文来实现高性能。
(3)Fine-Tuning:LoRA将可训练的秩分解矩阵注入LLMs中,基于监督标签更新程序修复任务的权重。
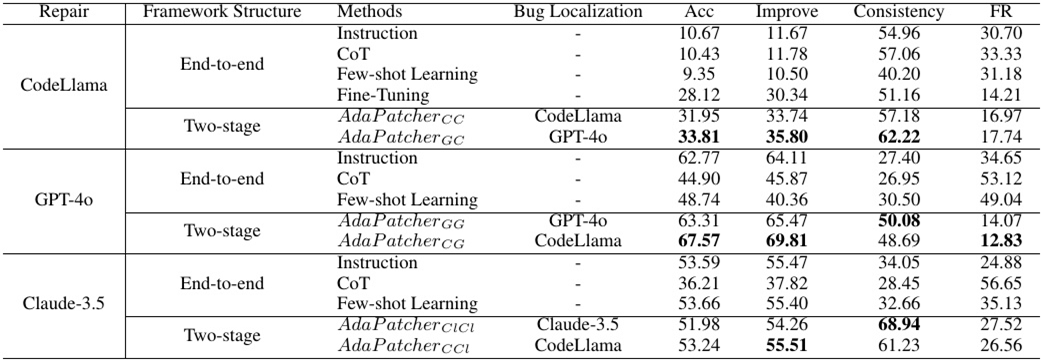
Table 2: Evaluation results on the ACPR dataset. All results in the table are reported in percentage (%).
实验结果
有效性评估。在这个研究问题中,我们想要评估我们的方法在AdaPR任务上的有效性。表2显示了我们的方法在测试集上的实验结果和基线。很明显:
(1)我们的方法(例如,,
)在程序修复精度上优于其他基线(例如,CoT,Few-Shot Learning和Fine-Tuning),在准确性上也产生类似的结果,同时显着提高一致性。优越的性能是由于我们的Bug Locator在第一阶段精确识别Bug位置的能力。在第一阶段,AdaPatcher通过利用代码diff样本中的自调试学习来精确定位错误行,增强了我们的方法有效处理修复挑战的能力。
(2)关于程序修复一致性,我们的方法相对于其他基线的优势是显而易见的。例如,基线(即CodeLlama微调)达到的最佳一致性分数为51.16%,我们的达到了62.22%的一致性比率,显著优于其他基线模型。我们将这种提高的一致性归功于Program Modifier在第二阶段的有效性。在第二阶段,我们设计了三个关键技术(即位置感知修复学习,选择性参考和适应性偏好的混合训练),以确保固定代码和有bug的代码之间的一致性。
总的来说,与端到端程序修复框架相比,我们的两阶段框架显示出稳定和实质性的改进,验证了我们的两阶段方法对AdaPR任务的有效性。
(3)此外,AdaPatcher在第二阶段(即程序修复)使用gpt - 4o时获得了更好的程序修复精度,在同一阶段使用CodeLlama时获得了更好的程序修复一致性。这可能是因为gpt - 4o在精度方面优于CodeLlama,因为它的模型参数要大得多。同时,CodeLlama在微调后识别bug位置方面也有自己的优势。因此,当我们选择CodeLlama作为第一阶段,gpt - 4o作为第二阶段时,可以获得最优的性能。
消融实验。我们进行了一项消融研究,通过系统地从我们的方法中移除每个组件来评估不同技术的贡献。特别是,对于,我们分别删除了关键组件(即,Self-Debug Learning, Hybrid Train-ing, and Preference Learning)。对于
,我们删除了唯一的组件(即Self-Debug Learning),因为gpt - 4o是闭源的。实验结果如表3所示,我们可以看到:
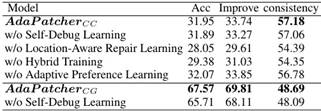
Table 3: Ablation study.
(1)去除Self-Debug Learning, Location-Aware Learning, 或者 Hybrid Training,导致准确性和一致性的性能下降,这表明了这些组件的重要性和有效性。
(2)虽然Preference Learning会导致代码准确性的轻微下降,但它进一步增强了一致性,表明该组件可以有效地减少代码修复过程中的修改。
为什么我们的方法有效/失败。我们人工检查了我们的方法有效和失败的测试用例。图3展示了通过我们的方法和gpt - 4o修复的错误代码。我们的Bug定位器首先精确地识别出有Bug的代码行,然后我们的Program Modifier通过稍微改变这行Bug来修复这个Bug。虽然gpt - 40正确地修复了这个错误,但gpt - 40修改了原始函数的大部分代码行,改变了原始代码的代码结构、逻辑和语义。两阶段框架(Bug定位器 + Program Modifier)的有效性确保了我们生成的代码补丁的正确性和一致性。我们还检查了许多AdaPatcher无法处理的情况。我们总结了两种常见的失败情况。
一种常见的失败情况是失败的测试用例没有提供足够的信息来精确地识别bug位置。
另一种糟糕的情况是,有bug的代码过于复杂或微妙,以至于AdaPatcher无法学习。例如,复杂的bug可能需要开发人员跨不同子模块进行代码更改。

Figure 3: The example of adaptive program repair.
Bug Localization的人工研究。第一阶段的bug定位对于指导后续的程序修复过程有着重要的作用。因此,在本节中,我们进行了一项人工研究,以手动评估第一阶段的表现。我们将gpt - 4o和使用我们的框架训练的CodeLlama的bug定位能力与人类定位进行了比较。具体来说,900个样本被提供给2个经验丰富的评估者,每个评估者被要求独立确定bug的位置,当他们有分歧时,第一作者会参与引导讨论。
接下来,我们将模型预测的bug位置与人工识别的bug位置进行了以下几个方面的比较:
(1)准确定位(accuracy Localization, AL)是指模型预测的bug位置与人工识别的bug位置精确匹配。
(2)局部定位(Partial Localization, PL)是指只有部分模型预测的位置与人工识别的位置匹配。
(3)错误定位(EL)表明模型生成的位置与人工识别的位置完全不匹配。
(4) No Localization (NL)表示模型没有识别出任何bug。
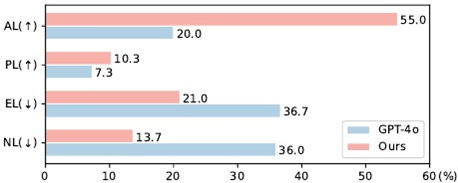
Figure 4: The statistical result of the human study.
图4示出了人工研究结果。使用我们的框架训练的CodeLlama在错误定位方面比gpt - 4o表现更好,AL和PL的示例分别增加了35.0%和3.0%,而EL和NL的示例分别减少了15.7%和22.3%。结果表明,即使是gpt - 4o也不能有效地识别出错误代码的错误位置,验证了该任务的挑战性。我们的Bug Locator使小型LLM(即CodeLlama)能够获得比gpt - 4o优越得多的性能,通过Code Diff样本验证了我们self-debug learning的有效性。
Hybrid Training分析。为了验证选择性参考混合训练的有效性,在本节中,我们与其他常用训练方法进行了对比分析。我们进一步设计了我们的实验,将训练过程中的弱监督数据和监督数据结合起来。如表4所示,实验结果表明:
(1)我们的混合训练在程序修复正确性的各种指标上优于其他训练方法。
(2)比较相比,我们的方法的正确性有了显著提高,证明了混合训练在避免盲目修改方面的有效性。
(3)与监督训练和弱监督训练比较,实验结果表明,无论训练数据量多少,混合训练都是有效的。

Table 4: Evaluation results of different training methods.
5 未来的工作
首先,研究基于Python,这是开发人员使用的最流行的编程语言之一。然而,AdaPatcher是独立于语言的,我们相信我们的方法可以很容易地适应其他编程语言,如c++或Java。其次,当我们的模型通过使用自适应偏好学习来应用时,生成代码的正确性会受到影响。探索在减少修改的情况下生成修复代码的有效方法,同时进一步提高其正确性,是未来工作的一个有趣的研究课题。
6 结论
这项研究的目的是修复代码,同时需要最小的修改。为了完成这项新颖的任务,提出了一种方法AdaPatcher,它利用Self-Debug Learning(自调试学习)来训练Bug Locator,从而准确地识别Bug并通过Bug位置修复代码。对于Program Modifier,通过Location-Aware Repair Learning(位置感知修复学习)来训练program Modifier。然后提出了Hybrid Training for Selective Reference(选择性参考混合训练),有效避免盲目修改不正确的bug位置。此外,使用Adaptive Preference Learning(适应性偏好学习)来学习较少的修改。实验结果表明,AdaPatcher对于这项任务是有效的。
启发
1)把“尽量少改动”定为与“改对”同等重要的目标。
2)混合训练防止“见错就改”
BibTeX
@misc{dai2025moreadaptiveprogramrepair,
title={Less is More: Adaptive Program Repair with Bug Localization and Preference Learning},
author={Zhenlong Dai and Bingrui Chen and Zhuoluo Zhao and Xiu Tang and Sai Wu and Chang Yao and Zhipeng Gao and Jingyuan Chen},
year={2025},
eprint={2503.06510},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2503.06510},
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)