AI推理直接飙7.5倍!英伟达Rubin CPX重新定义AI赚钱效率,投1亿回报50亿
过去我们用AI,上下文稍微长点它就开始胡言乱语,不得不重开窗口。现在,AI正在朝着“智能体”的方向狂奔,它得能多步骤推理,得有持久的记忆,还得能处理超乎想象的超长上下文。你想想,让AI帮你分析一个含有几百万行代码的软件项目,或者直接生成一部完整的电影,这背后需要处理的数据量,也就是所谓的token,是天文数字。传统GPU在这种任务面前,就像让一个短跑冠军去跑马拉松,不是算力不够,就是内存带宽跟不上
9月9号,AI圈又被那个男人搅得天翻地覆了。没错,说的就是皮衣刀客,英伟达的创始人兼首席执行官黄仁勋。在AI基础设施峰会(AI Infra Summit)上,老黄面带微笑,云淡风轻地扔出一款名为Rubin CPX的新品类GPU。

过去我们用AI,上下文稍微长点它就开始胡言乱语,不得不重开窗口。现在,AI正在朝着“智能体”的方向狂奔,它得能多步骤推理,得有持久的记忆,还得能处理超乎想象的超长上下文。你想想,让AI帮你分析一个含有几百万行代码的软件项目,或者直接生成一部完整的电影,这背后需要处理的数据量,也就是所谓的token,是天文数字。传统GPU在这种任务面前,就像让一个短跑冠军去跑马拉松,不是算力不够,就是内存带宽跟不上,瓶颈多得让人头大。
而这次发布的Rubin CPX,全称Rubin上下文处理单元(Rubin Context Processing Unit),就是专为解决这个“马拉松”难题而生的。它直接把上下文窗口干到了100万token以上,更狠的是,它带来了一套全新的打法,叫做“解耦推理”(disaggregated inference)。简单说,就是把AI推理这件大事,拆成了两步,让两个“偏科生”去干,结果效率直接起飞,算力提升最高7.5倍,投资回报率(ROI)更是达到了惊人的30到50倍。
老黄在发布会上是这么说的:“Vera Rubin平台将标志着AI计算前沿的又一次飞跃——它既引入了下一代Rubin GPU,也带来了一个名为CPX的全新处理器类别。”他还补充道:“就像RTX彻底改变了图形和物理AI一样,Rubin CPX是第一款专为大规模上下文AI打造的CUDA GPU,在这种AI中,模型可以一次性在数百万token的知识上进行推理。”
这牛吹得这么大,它到底是怎么做到的?这颗“新核弹”究竟威力何在?
让专业GPU干专业的事
咱们先来聊聊AI推理的两大挑战。以前的AI推理,好比一个厨师,从洗菜、切菜到下锅爆炒,所有活儿都自己一个人干。这在处理“番茄炒蛋”这种简单任务时没问题,但现在要做的可是“佛跳墙”级别的大菜,也就是那些超长上下文任务。模型需要先花大量时间“备菜”,也就是理解海量的输入数据,这个阶段叫上下文阶段(context phase),它极其消耗计算资源,是计算密集型(compute-bound)的。菜备好了,就进入“烹饪”阶段,也就是一个token一个token地往外生成输出,这个叫生成阶段(generation phase),它对上菜速度要求极高,极其考验内存带宽,是内存带宽密集型(memory bandwidth-bound)的。
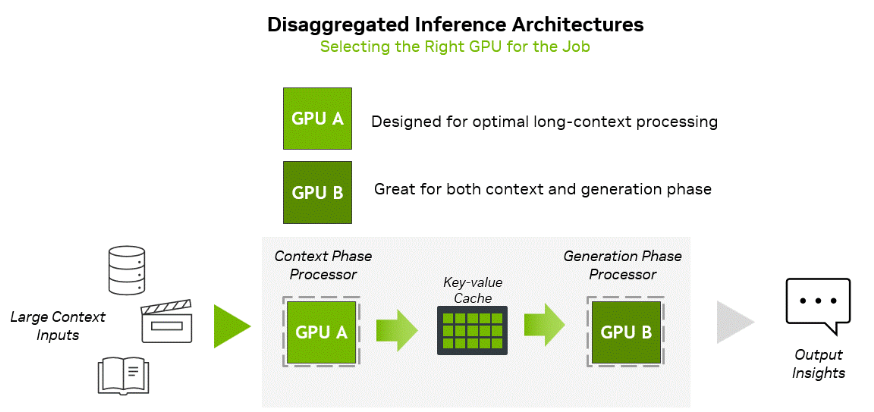
就拿生成一小时视频来举例,AI模型得先把这一小时的视频内容,编码成大约100万个token。在第一阶段,传统GPU光是“备菜”就得累个半死,因为算力不够,导致延迟很高;到了第二阶段,又因为“上菜通道”太窄,也就是内存带宽不够,没法高效地把生成的内容端出来。
英伟达的“解耦推理”架构,就是把厨房升级了,请了两位大厨。一位是Rubin CPX,这位是“备菜大师”,力大无穷,专门负责处理上下文阶段,管你输入数据有多少,它都能用超高算力给你安排得明明白白。另一位是标准的Rubin GPU,这位是“烹饪兼上菜大师”,它配备了超高速的高带宽内存(HBM4),专门负责在生成阶段高效地往外“biu biu biu”地输出结果。
这么一分工,两位大厨各司其职,在自己最擅长的领域火力全开,资源浪费?不存在的。而为了让两位大厨配合得天衣无缝,英伟达还派了个“后厨总管”——Dynamo平台,它负责协调关键的KV缓存、任务路由和内存管理,保证两个阶段丝滑衔接,无缝切换。
这位“备菜大师”Rubin CPX,本身也是个狠角色。它采用了单芯片(monolithic die)设计,基于最新的Rubin架构,身上全是黑科技。它拥有高达30 petaFLOPS的NVFP4算力,也就是每秒能进行30千万亿次浮点运算,专门为低精度推理做了优化。内存用的是128GB的GDDR7显存,在成本和带宽之间找到了一个绝佳的平衡点,完美满足上下文阶段的大数据吞吐需求。更绝的是,它还内置了硬件级的视频解码器和编码器,可以直接处理长视频流,省去了很多预处理的麻烦。在核心的注意力机制计算上,它的速度比上一代旗舰GB300 NVL72快了整整3倍。
堆料堆出新境界,这参数简直不讲理
当然,一个CPX再厉害也只是一个人在战斗,英伟达的传统艺能是“组团开黑”。Rubin CPX是NVIDIA Vera Rubin NVL144 CPX平台的核心战力。这个平台,说白了就是一个塞满了顶级硬件的机架,堪称单机架里的AI超级计算机。它的配置单拉出来,能吓人一跳:里面塞了144颗“备菜大师”Rubin CPX,还有144颗“烹饪大师”Rubin GPU,由36颗Vera CPU负责调度。内存直接给到100TB,总带宽高达每秒1.7 PB,也就是1.7千万亿字节。在NVFP4精度下,这个大家伙的总算力达到了恐怖的8 exaFLOPS,也就是每秒80亿亿次浮点运算。

这是什么概念?这个单机架的性能,是我们当前看到的旗舰产品GB300 NVL72的7.5倍。就算跟同样不带CPX的Vera Rubin NVL144版本(3.6 exaFLOPS)相比,也强了2.2倍。为了让这些性能猛兽能够集群化,形成更庞大的战斗群,英伟达还提供了两种顶级网络方案:一个是超低延迟、高吞吐的Quantum-X800 InfiniBand网络;另一个是专门为以太网AI负载优化的Spectrum-X方案,搭配Spectrum-XGS交换机和ConnectX-9 SuperNICs网卡,保证数据传输畅通无阻。
为了让大家更直观地感受到两位“大厨”的分工有多明确,下面这个表格对比了它们的核心参数,数据都来自英伟达官方和硬件圈知名媒体Tom's Hardware的报道,保真。

看明白了吧?Rubin CPX用相对亲民的GDDR7显存,换来了极致的计算密度,专心搞定最难啃的上下文理解。而标准Rubin GPU则凭借极其奢华的HBM4超大带宽,心无旁骛地专注于快速生成内容。这种“术业有专攻”的设计,正是解耦推理架构的精髓所在,也是它强大效率的根源。
百万token上下文,到底能改变什么?
说了这么多技术,可能有人会问,这百万token上下文到底能给我们的生活带来什么实际变化?问得好,这变化可太大了。
软件开发领域,AI编程助手,比如大家熟悉的GitHub Copilot,以前只能帮你写写单个文件里的小代码片段,对整个项目的宏观结构基本是“睁眼瞎”。但有了Rubin CPX的超长上下文能力,AI模型可以直接把整个代码库、所有相关文档、甚至多年的修改历史记录一口气全读进去,形成一个“上帝视角”,从而进行项目级的代码分析和生成。
AI编程公司Cursor的首席执行官Michael Truell就对此兴奋不已:“借助NVIDIA Rubin CPX,Cursor将能够提供闪电般的代码生成和开发者洞察,从而改变软件创建的方式。这将释放新的生产力水平,并使用户能够实现曾经遥不可及的想法。”
视频生成领域,AI生成视频正在从几秒钟的“GIF动图”向着长篇电影进化。就像前面说的,生成1小时的高清视频,需要处理大约100万个token,传统GPU在理解视频内容这个阶段就要花掉太长时间,根本没法做到实时创作。
Rubin CPX的出现彻底改变了游戏规则。它集成的硬件视频编解码器,可以直接处理视频流,大大缩短了预处理时间。Runway公司的首席执行官Cristóbal Valenzuela对此评价道:“视频生成正迅速向更长的上下文和更灵活、由智能体驱动的创作工作流发展。我们认为Rubin CPX是性能上的一次重大飞跃,它支持这些要求苛刻的工作负载,以构建更通用、更智能的创作工具。这意味着创作者——从独立艺术家到大型工作室——都可以在他们的工作中获得前所未有的速度、真实感和控制力。”
真正的AI智能体要想实现自主决策,就必须拥有长期记忆和强大的推理能力。专注于AI软件工程自动化的Magic公司,其首席执行官Eric Steinberger是这么描述未来的:“通过一亿token的上下文窗口,我们的模型可以在没有微调的情况下,看到整个代码库、多年的交互历史、文档和库。这使得用户可以在测试时通过对话和访问他们的环境来指导智能体,让我们更接近自主的智能体体验。使用像NVIDIA Rubin CPX这样的GPU,极大地加速了我们的计算工作负载。”
真金白银的回报,才是硬道理
聊了这么多性能和应用,商业价值如何?英伟达官方给出了一个非常惊人的测算:基于Rubin CPX的Vera Rubin NVL144 CPX平台,能够实现“30到50倍的投资回报率”。这意味着,客户每投入1亿美元的资本支出,最高可以获得50亿美元的token收入。
这个数字听起来有点像天方夜谭,但背后是有逻辑支撑的。单机架8 exaFLOPS的恐怖算力,是上一代的7.5倍,这意味着单位算力的成本被大幅摊薄了。解耦架构让硬件资源的使用效率达到了最大化,推理吞吐量直接提升好几倍。英伟达提供了一整套软件生态,包括我们前面提到的Dynamo平台,还有NIM微服务、Nemotron多模态模型等等,这些软件工具进一步优化了部署和运维的效率,让客户能更快地把算力转化成收入。
老黄在发布会上对此总结道:“Rubin CPX让长上下文处理的性能和token收入达到了前所未有的高度——远超当今系统的设计极限。这彻底改变了AI编程助手,从简单的代码生成工具,转变为能理解并优化大型软件项目的复杂系统。”
当然,强大的硬件离不开繁荣的软件生态。
Rubin CPX背后站着的是整个英伟达AI帝国。有负责推理编排的NVIDIA Dynamo平台,它已经在MLPerf性能测试中创造了纪录。有企业级的NVIDIA NIM微服务,为企业提供顶级的AI推理能力。还有拥有600万开发者和近6000个应用的CUDA-X库,保证了Rubin CPX一出世就有海量的应用可以跑。更有为企业量身打造的AI Enterprise软件平台,支持从云端、数据中心到工作站的全场景部署。
Rubin CPX,通过解耦架构和为特定任务优化的设计,它精准地解决了长上下文推理的核心痛点,为软件工程、视频创作和AI智能体这些最前沿的应用铺平了前进的道路。
Vera Rubin NVL144 CPX平台更是用它那堪称变态的性能参数,重新定义了AI基础设施的天花板。
正如黄仁勋所说:“Rubin CPX是大规模上下文AI的RTX时刻。”
从这一刻起,AI或许将真正摆脱“工具”的束缚,开始成为一个具备长久记忆、深度推理和非凡创造力的智能伙伴。
参考资料:
https://nvidianews.nvidia.com/news/nvidia-unveils-rubin-cpx-a-new-class-of-gpu-designed-for-massive-context-inference
https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads
https://www.tomshardware.com/tech-industry/semiconductors/nvidia-rubin-cpx-forms-one-half-of-new-disaggregated-ai-inference-architecture-approach-splits-work-between-compute-and-bandwidth-optimized-chips-for-best-performance
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)