本地大模型实战指南:从零搭建到AI视觉识别,告别API依赖
·
一、搭建你的AI基座:Ollama一键安装与模型管理
1.1 下载 Ollama 并安装
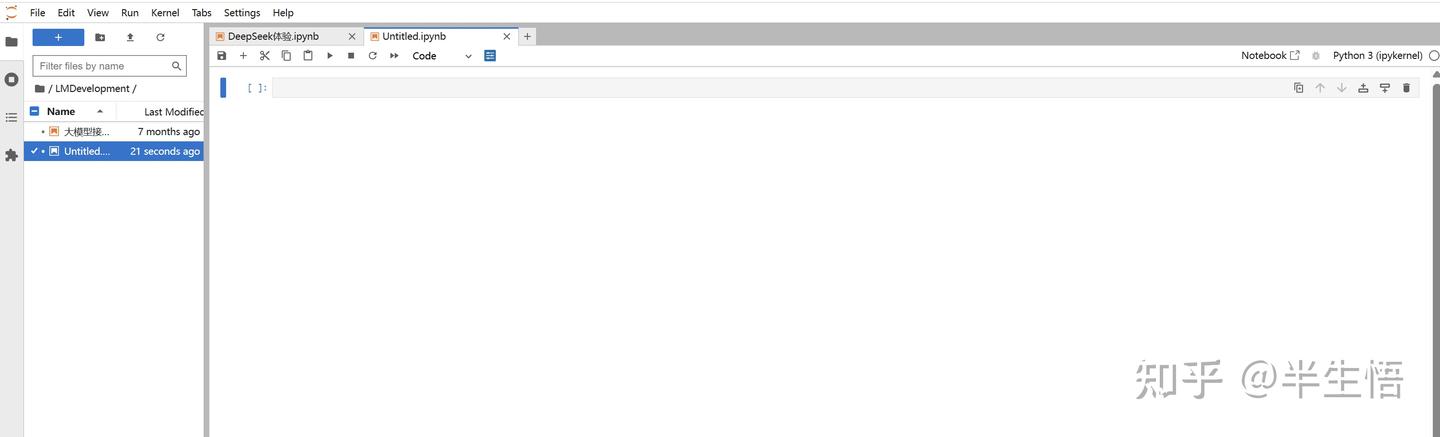
- 确保安装盘至少有40G空间,记住安装地址,后面有用
1.2 运行 Ollama
- 打开cmd
- 挑选模型
- 下载并运行模型
- 命令:ollama run + 模型名称:型号
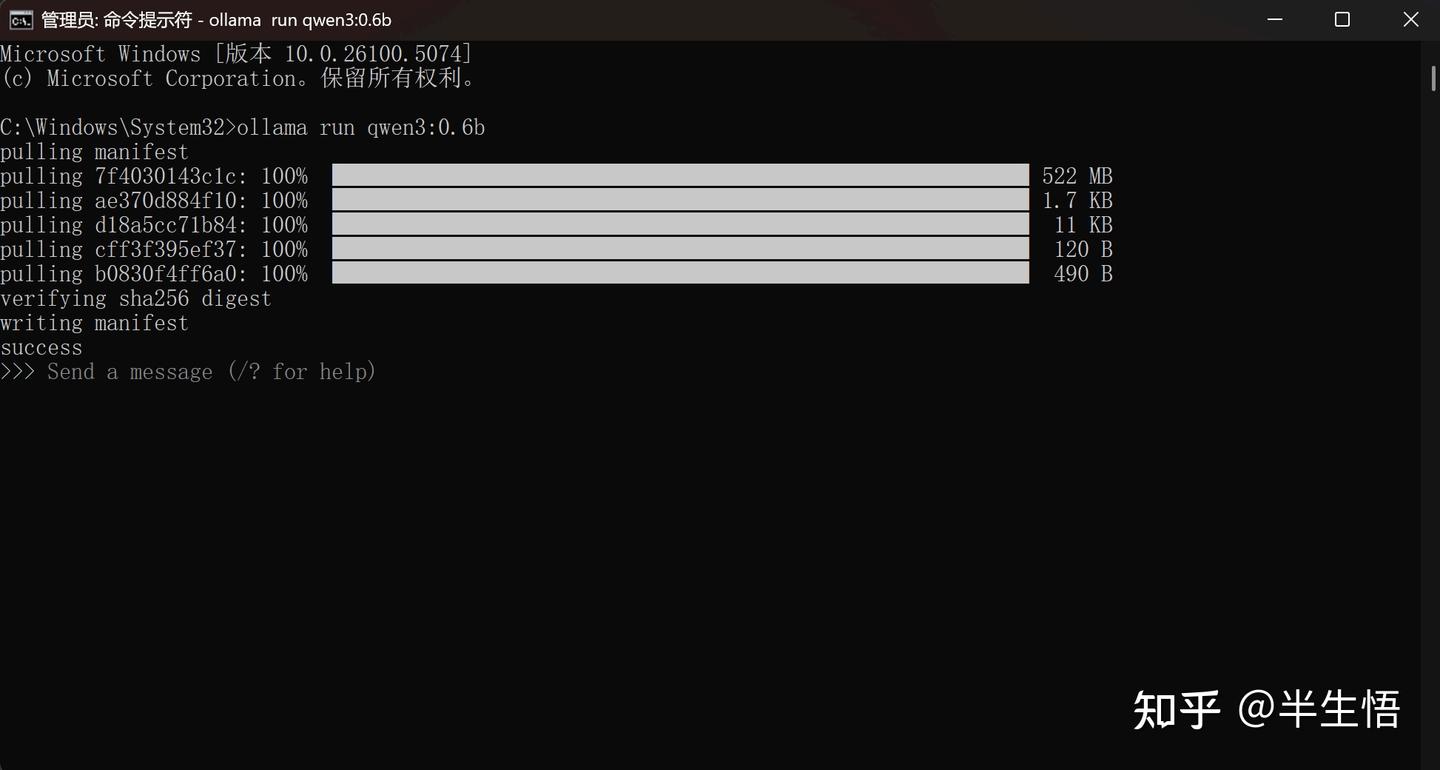
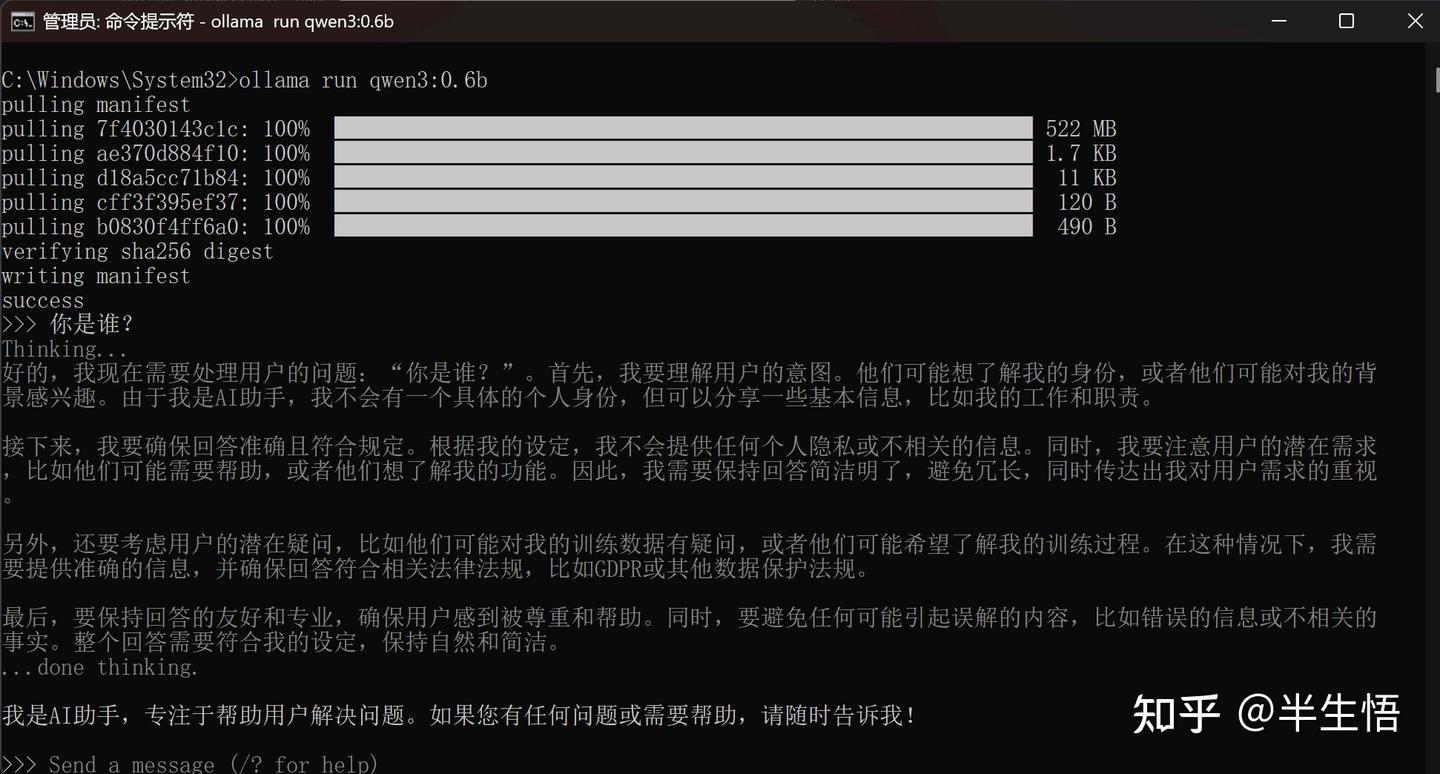
- 退出当前模型
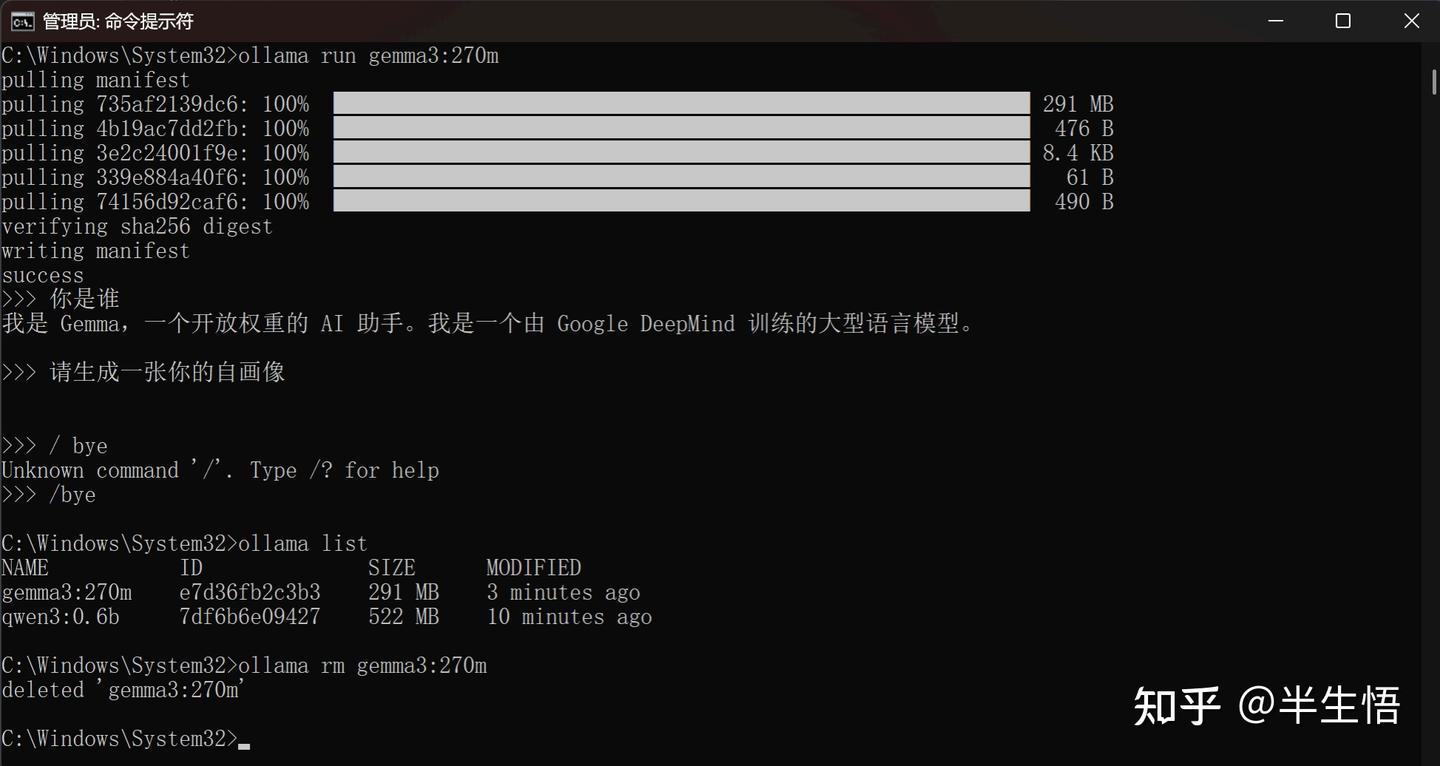
- 命令:/bye
- 查看已安装模型
- 命令:ollama list
- 卸载模型
- 命令:ollama rm gemma3:270m
二、让Python与大模型对话:SDK集成与智能交互实现
2.1 准备工作
- 启动 Ollama
- 模型运行中的任意一条命令都可以启动
- 安装好指定模型
- 安装 Ollama 的SDK
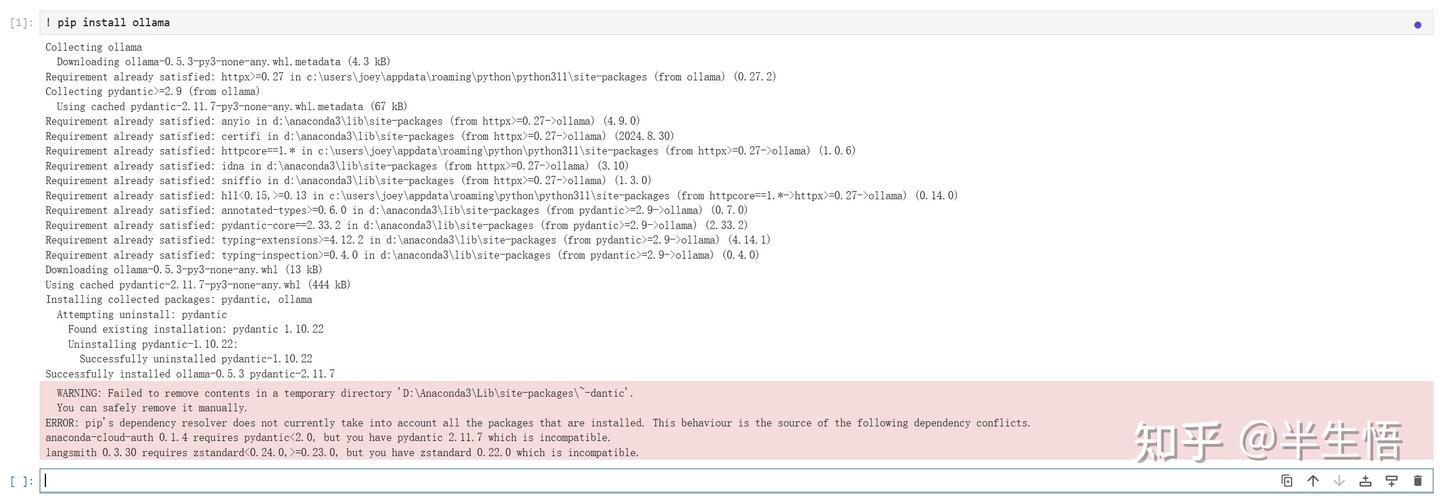
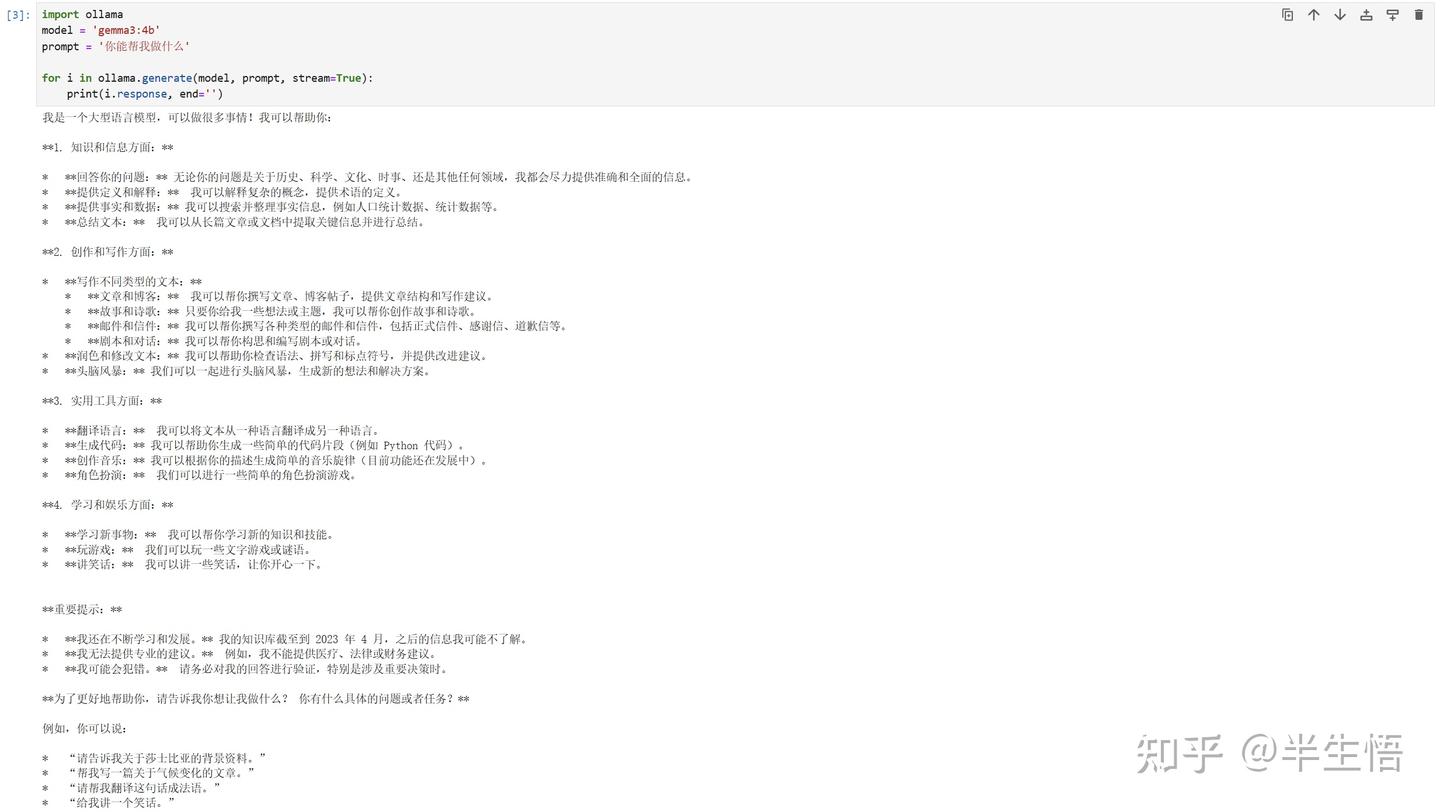
2.2 调用 Ollama
- 导入 Ollama
- 代码:import ollama
- 设置模型
- 代码:model = 'gemma3:4b'
- 设置提示词
- 代码:prompt = '你能帮我做什么'
- 设置流失对话输出
- 代码:for i in ollama.generate(model, prompt, stream=True): print(i.response, end='')
三、解锁视觉AI能力:多模态模型的图像理解实战
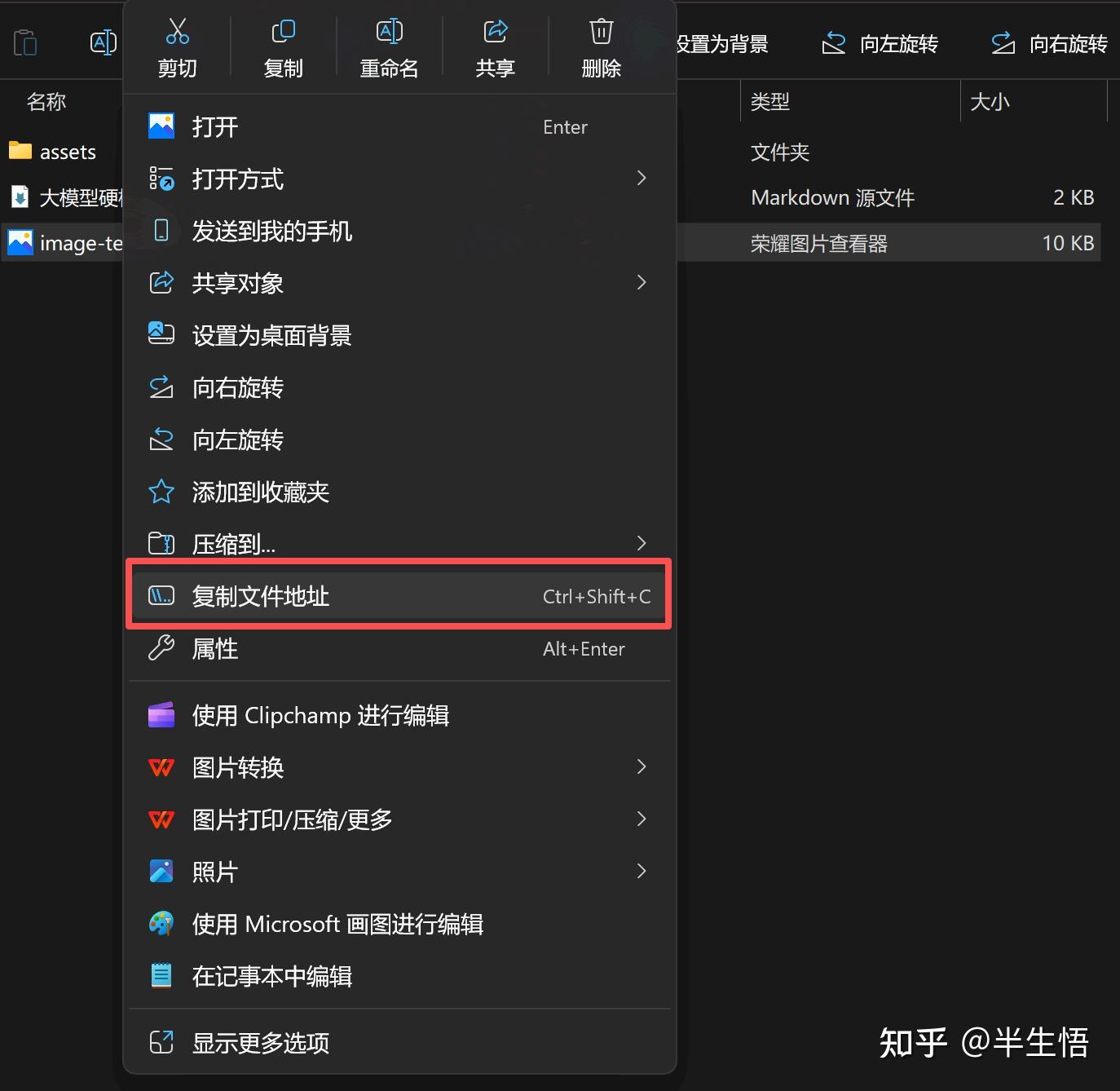
3.1 获取图片地址
- 选中图片并点击右键
3.2 调用视觉理解模型
- 视觉理解模型调用模板
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'What is in this image?', # 提示词
'images': ['image.jpg'] # 在这里粘贴图片地址
}]
)
print(response)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)