【AI论文】集块解码(Set Block Decoding)是一种语言模型推理加速器
摘要:本研究针对大型语言模型(LLMs)生成符号图形程序(SGPs)能力不足的问题,构建了SGP-GenBench基准测试系统,并提出基于强化学习的微调方法。通过设计格式有效性奖励和跨模态对齐奖励(CLIP/DINO评分),对Qwen-2.5-7B模型进行GRPO优化,使其在组合性任务上的评分从8.8提升至60.8,显著缩小了开源模型与专有模型(如Claude3.7Sonnet)的差距。分析表明模
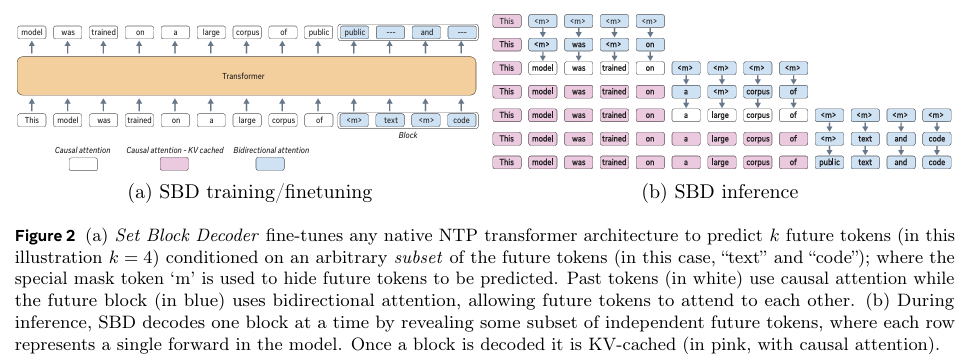
摘要:自回归式下一标记预测语言模型功能强大,但在实际部署中面临重大挑战,原因在于推理过程(尤其是解码阶段)的计算和内存成本高昂。我们提出了集块解码(Set Block Decoding,SBD),这是一种简单且灵活的范式,通过在单一架构内整合标准的下一标记预测(Next Token Prediction,NTP)和掩码标记预测(Masked Token Prediction,MATP),加速生成过程。SBD允许模型并行采样多个未来标记(这些标记不一定连续),这是其与以往加速方法的关键区别。这种灵活性使得我们可以利用离散扩散文献中的先进求解器,在保证准确率的前提下显著提升生成速度。SBD无需改变模型架构或增加额外的训练超参数,与精确的键值缓存(KV-caching)兼容,且可通过微调现有的下一标记预测模型来实现。通过对Llama-3.1 8B和Qwen-3 8B进行微调,我们证明,SBD能够将生成所需的前向传播次数减少3至5倍,同时达到与等效的下一标记预测训练相同的性能表现。Huggingface链接:Paper page,论文链接:2509.04185
研究背景和目的
研究背景:
随着自然语言处理(NLP)领域的快速发展,大型语言模型(LLMs)在多种任务中展现了卓越的能力,包括文本生成、代码生成、问答系统等。然而,尽管这些模型在处理和理解自然语言方面取得了显著进展,其在生成复杂视觉内容的符号图形程序(Symbolic Graphics Programs, SGPs)方面的能力仍然有限。SGPs通过结构化、形式化的表示方法,如SVG(Scalable Vector Graphics)代码,将自然语言描述转化为精确的视觉场景。这种能力对于跨模态理解、虚拟场景构建、教育工具开发等领域具有重要意义。
现有研究表明,尽管LLMs在代码生成任务中表现出色,但在生成与自然语言描述完全匹配的SVG代码方面仍存在挑战。这主要是因为SGPs的生成不仅要求模型理解自然语言描述中的语义信息,还需要将这些信息转化为精确的图形表示,涉及复杂的空间关系、对象属性和组合逻辑。此外,开源模型与专有模型在生成SGPs的能力上存在显著差距,这种差距往往与模型的编码能力、训练数据和优化方法密切相关。
研究目的:
本研究旨在填补这一研究空白,具体目标包括:
- 评估LLMs生成SGPs的能力:通过构建全面的基准测试SGP-GenBench,系统评估不同LLMs在生成SGPs时的性能,涵盖对象级准确性、场景级语义一致性和组合性一致性三个维度。
- 提升开源LLMs的SGP生成能力:提出一种基于强化学习的微调方法,利用可验证的奖励信号(如文本与生成图像的相似度、图像与图像的相似度)来优化模型,减少开源模型与专有模型之间的性能差距。
- 探索模型在SGP生成过程中的行为变化:通过分析强化学习过程中模型生成的SVG代码,揭示模型在提升SGP生成能力时所采用的策略,如对象分解和上下文细节的添加。
研究方法
本研究采用了一系列系统的方法来实现上述研究目的,主要包括以下几个方面:
- 基准测试构建:
- SGP-GenBench:我们构建了一个全面的基准测试SGP-GenBench,包含三个子集:
-
- 场景生成能力:基于COCO-val数据集,包含80个不同对象类别的复杂场景描述,评估模型生成复杂场景的能力。每个描述对应一个或多个SVG代码示例,用于评估生成代码的准确性和语义一致性。
- 对象生成能力:基于互联网收集的SGP-Object-val数据集,包含930个示例,主要评估模型生成单个对象的能力。每个示例包含一个自然语言描述和对应的SVG代码。
- 组合生成能力:基于SGP-CompBench数据集,评估模型在属性绑定(颜色、形状、纹理)、空间关系(2D、3D、隐式关系)和计数(3-10个对象的准确生成)方面的能力。该数据集包含一系列复杂的场景描述,要求模型能够生成包含多个对象和关系的SVG代码。
- 强化学习微调方法:
- 奖励设计:我们设计了一个包含格式有效性奖励和跨模态奖励的强化学习框架。格式有效性奖励确保生成的SVG代码是可渲染的,即代码结构正确且能够生成有效的图形。跨模态奖励则通过文本编码器(如CLIP、SigLIP)和视觉编码器(如DINO)来评估生成图像与输入文本描述以及参考图像之间的相似度。
- 训练过程:采用GRPO(Generalized Reinforcement Learning with Proximal Policy Optimization)算法,对Qwen-2.5-7B模型进行微调。在训练过程中,模型根据奖励信号逐步调整其生成策略,以生成更符合自然语言描述的SVG代码。
- 实验与分析:
- 基准测试评估:在SGP-GenBench上对多个开源和专有LLMs进行评估,比较它们在生成SGPs时的性能。评估指标包括CLIP-Score、DINO-Score、VQA-Score等,用于衡量生成图像与输入文本描述以及参考图像之间的相似度。
- 训练动态分析:通过分析训练过程中模型生成的SVG代码,揭示模型在提升SGP生成能力时所采用的具体策略。例如,模型是否学会了将复杂对象分解为更简单的可控元素,或者是否添加了与提示相关的上下文细节。
- 消融实验:通过去除奖励函数中的不同组件(如文本-图像对齐奖励、图像-图像对齐奖励),评估各组件对模型性能的影响。这有助于理解不同奖励信号在模型优化过程中的作用。
研究结果
- 基准测试结果:
- 模型排名与整体能力:基准测试结果显示,模型在SGP-GenBench上的排名与其整体能力(尤其是代码生成能力)高度相关。例如,Claude3.7 Sonnet Thinking在所有任务上均表现出色,而开源模型如DeepSeek-R1和Qwen-2.5-7B则相对较弱。这表明,专有模型在编码能力和复杂场景理解方面具有显著优势。
- 专有模型的优势:专有模型在组合性任务(如属性绑定和计数)上表现尤为突出,这得益于它们强大的编码能力和对复杂场景的理解能力。例如,Claude3.7 Sonnet Thinking在组合性评分上达到了82.4,远高于其他开源模型。
- 开源模型的进步:通过强化学习微调,我们的Qwen-2.5-7B模型在组合性评分上从8.8提升至60.8,超过了所有其他开源模型,并在某些指标上接近或超过了专有模型。这表明,强化学习微调是提升开源模型SGP生成能力的有效途径。
- 强化学习微调的效果:
- 性能提升:强化学习微调显著提升了模型生成SGPs的质量和语义一致性。例如,在COCO-val场景生成任务上,微调后的模型在CLIP-Score、DINO-Score和VQA-Score等指标上均有显著提升。这表明,模型通过强化学习逐渐学会了生成更符合自然语言描述的SVG代码。
- 行为变化:分析训练过程中模型生成的SVG代码发现,模型逐渐学会了将复杂对象分解为更简单的可控元素,并添加了与提示相关的上下文细节。例如,在生成包含多个对象的场景时,模型会先生成每个对象的独立SVG代码,然后将它们组合在一起,并添加必要的空间关系和属性绑定。
- 奖励函数的影响:
- 文本-图像对齐奖励:使用SigLIP作为文本编码器时,模型在语义对齐方面表现更佳。这得益于SigLIP在对比学习任务中的优异表现,使其能够更好地捕捉自然语言描述中的语义信息。
- 图像-图像对齐奖励:添加图像-图像对齐奖励进一步提高了模型生成图像的视觉质量。通过比较生成图像与参考图像的相似度,模型能够生成更接近真实场景的SVG代码。
研究局限
尽管本研究在提升LLMs生成SGPs的能力方面取得了显著进展,但仍存在一些局限性:
- 数据集的局限性:
- 数据覆盖度:尽管SGP-GenBench涵盖了多个维度的评估任务,但其数据集仍可能无法完全代表所有可能的自然语言描述和视觉场景。未来工作需要进一步扩展数据集,以提高评估的全面性和准确性。例如,可以收集更多样化的自然语言描述和对应的视觉场景,或者构建更大规模、更具挑战性的基准测试数据集。
- 文本与图像的对应关系:在构建数据集时,我们假设每个自然语言描述都对应一个唯一的视觉场景。然而,在实际应用中,这种对应关系可能更加复杂和模糊。例如,同一个自然语言描述可能对应多个不同的视觉场景,或者一个视觉场景可能由多个自然语言描述共同构成。未来工作需要探索如何处理这种不确定性,以提高模型生成SGPs

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)