AI大模型实战 | Dify平台MinerU插件无代码部署与知识库构建指南
Dify 是一款近年来热度极高的全能型开源无代码 AI 平台,截至 8 月底已经获得 112K Star✨。它的定位是开源的 LLM 应用开发平台。直观的界面结合了 AI 工作流、RAG 、Agent、模型管理、可观测性功能等,可以帮助用户快速从原型走向生产环境。官网: https://dify.ai/开源地址: https://github.com/langgenius/difyDify 的另一
本文详细介绍在Dify开源AI平台上部署MinerU插件的方法,解决工程建设行业文档处理痛点。通过无代码配置实现文档自动清洗、结构化转换和知识库入库,提升检索准确性和内容可维护性。提供完整部署步骤、工作流配置和常见文档处理建议,为非技术团队提供低门槛的AI知识库建设解决方案。
Dify 简介
Dify 是一款近年来热度极高的全能型开源无代码 AI 平台,截至 8 月底已经获得 112K Star✨。
它的定位是 开源的 LLM 应用开发平台。直观的界面结合了 AI 工作流、RAG 、Agent、模型管理、可观测性功能等,可以帮助用户快速从原型走向生产环境。
官网: https://dify.ai/
开源地址: https://github.com/langgenius/dify
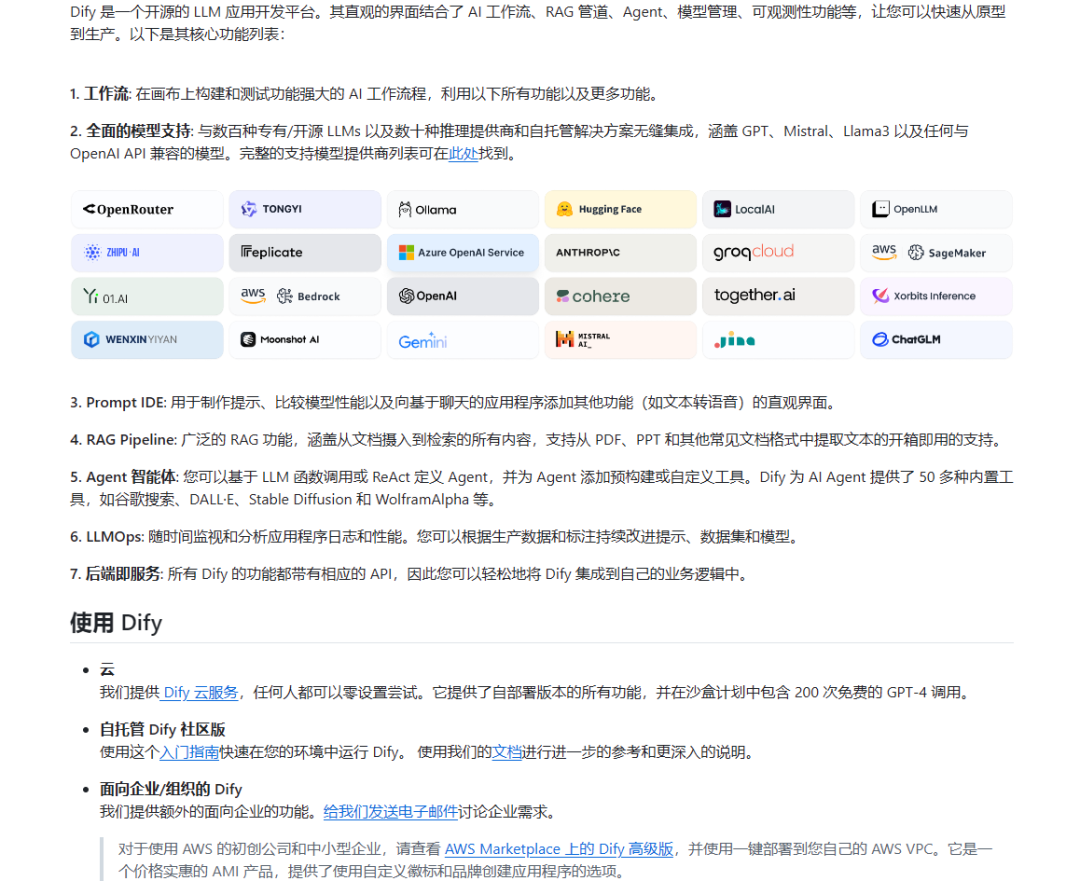
Dify 的另一大优势是插件生态非常丰富,大多数场景都能无代码满足,非常适合没有技术背景的团队快速上手。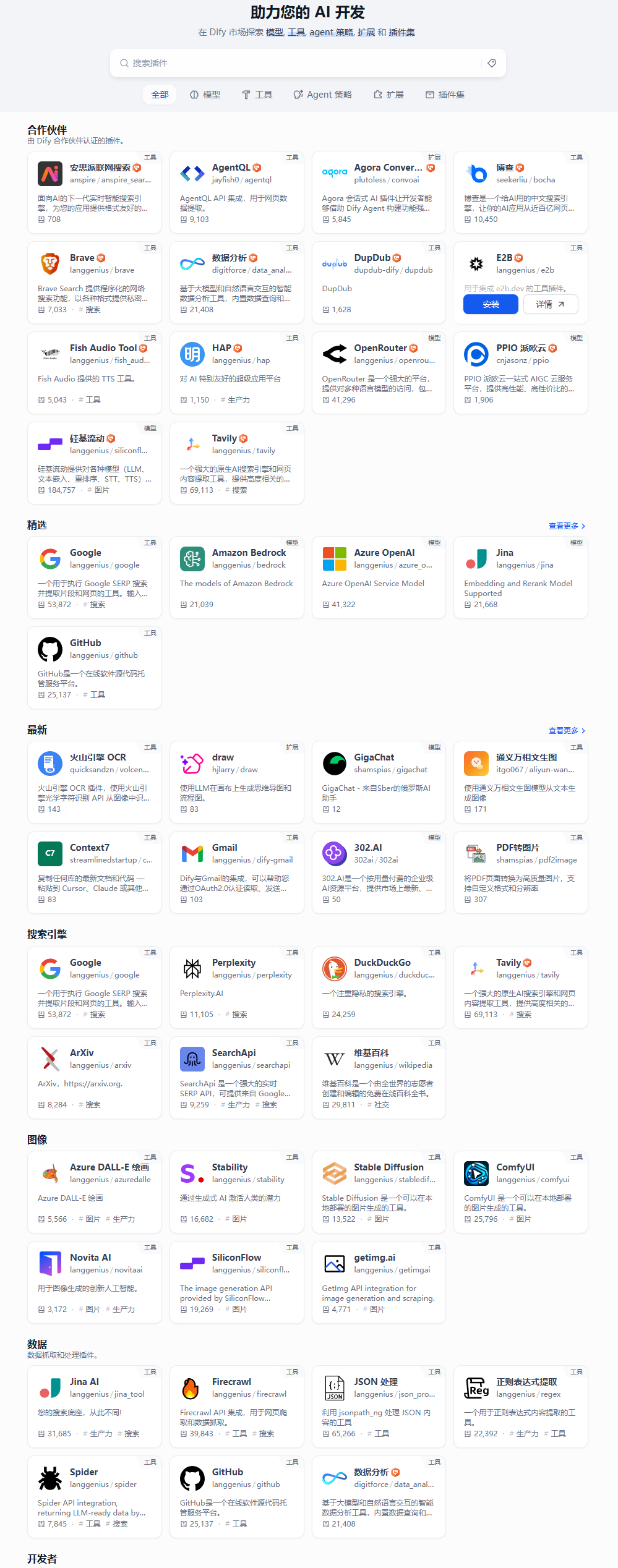
Dify快速部署
虽然市面上有很多 Dify 部署教程,看起来步骤繁琐,其实真正复杂的部分主要在于环境准备。一旦通用环境配置好,后续部署就会非常轻松。
环境配置好之后,Dify的部署只需要简单几步:
cd dify
cd docker
cp .env.example .env
docker compose up -d
MinerU插件配置
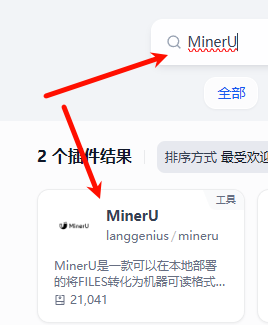
在插件市场搜索 MinerU,点击第一个结果下载安装即可。
如果使用MinerU官方API,授权地址是 https://mineru.net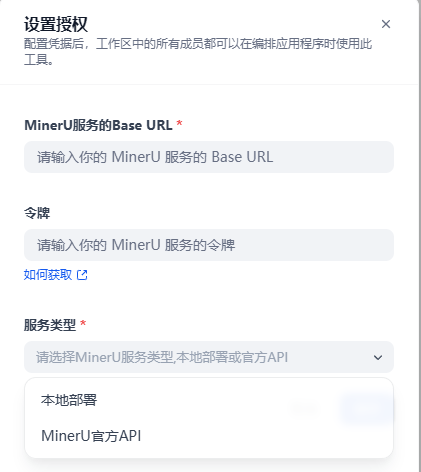
若是本地部署MinerU,则填写你的本地部署MinerU的API地址。
为了避免如下报错,需要设置 Dify 的配置文件:
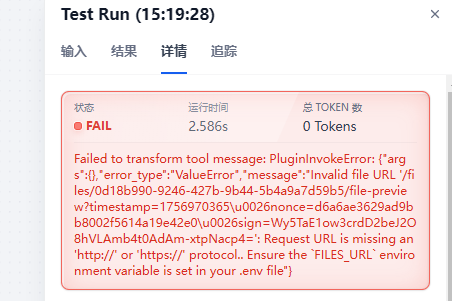
1. 找到 Dify 部署目录,打开.env文件,修改FILES_URL配置项,依据你的部署方式填写:
**Docker Compose 部署:**FILES_URL设置为 http://api:5001

**其他部署方式:**FILES_URL设置为 http://Dify宿主机IP:5001
(如 http://192.168.1.100:5001,这里的 IP 通常是运行 Dify 的机器的 IP,即前文提到的“本地IP”端口。5001是 Dify API 服务的默认端口)。
2. 确认 Dify API 服务的5001端口已对外暴露(可检查docker-compose.yaml文件的端口映射)。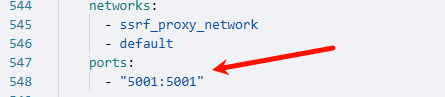
3. 保存.env文件。
4. 重启 Dify 服务以使配置生效。
Dify知识库工作流接入MinerU
基础工作流
调用 MinerU 插件的最直接方式就是作为文件处理工具。以一篇PDF为例,
MinerU 能较好保留 结构层级 与 图片内容,避免传统解析错位与图片丢失。
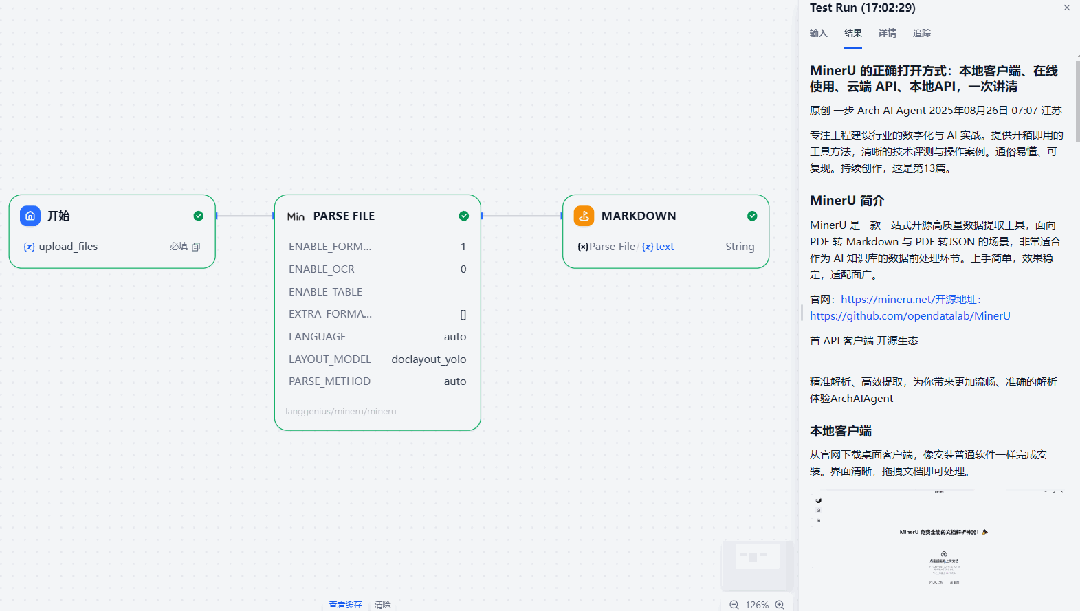
不过如果只是这样使用,还不够优雅。
更推荐把 MinerU 作为 前置步骤 融入业务流。上传文件后先进行 结构化清洗,再进入 切分与召回。这样召回结果更稳定,知识条目更可维护。
文档转换工作流
如果希望处理结果直接保存为 .md 文件,可以安装 Markdown 转换器 插件。这样转换后的文件会自动带有本地图床地址,能够直接作为知识库的结构化内容。
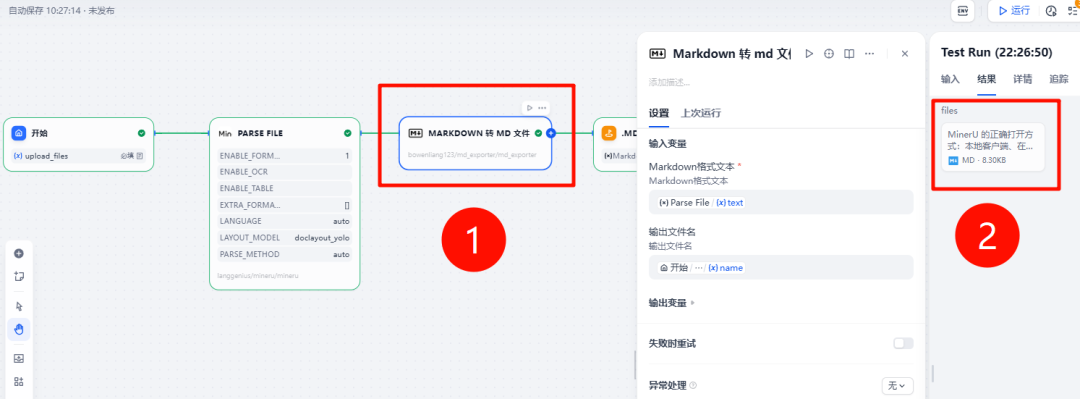
我们看一下转换好后的.md文件,可以看到图片被自动转换成了本地图床地址,这份.md文件已经直接可以用作知识库内容了。
转换后自动入库
进一步解放双手的做法,是在 MinerU 转换之后,再接入 knowledge 插件,把转换后的文件自动写入知识库。
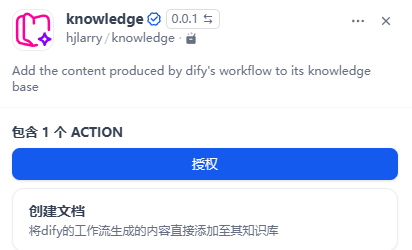
配置要点:
1. 在插件内填写知识库 API 地址和密钥;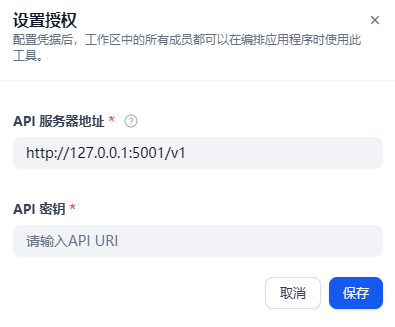
API服务器地址和API密钥是指知识库的API服务器地址和密钥,在如下位置找到。
2. 获取目标知识库的数据集 ID;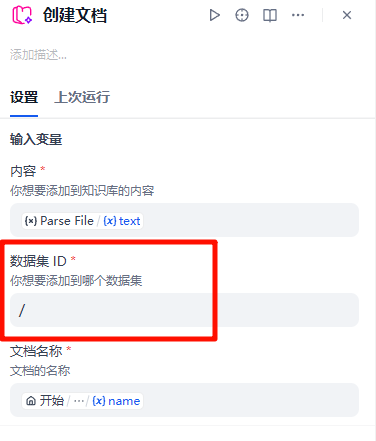
打开需要插件写入文件的知识库,在地址栏获取。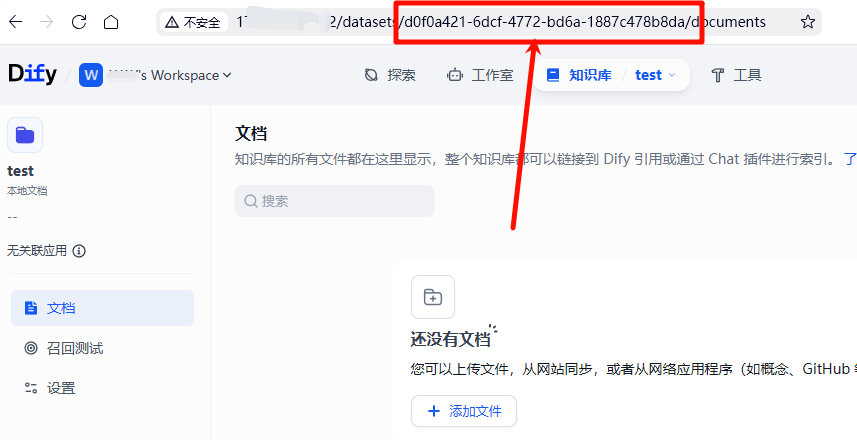
设置完成后,即可在工作流中实现“接收文件 → 自动处理 → 自动入库”的全流程。最终的工作流既简单,又能大大提高文档管理效率。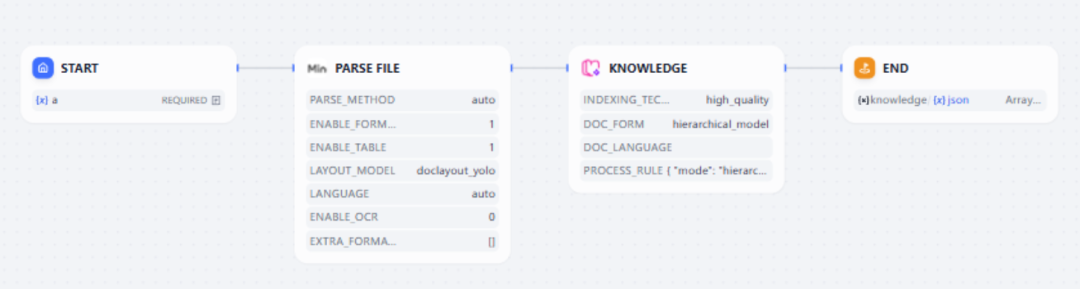
为什么一定要前处理
痛点一 结构丢失
原始 PDF 与复杂 Word 文档常见 标题层级错乱、列表断裂、表格行列对不齐。这会直接影响切分效果与向量召回质量。
痛点二 图片与图表缺失
直接导入时图片容易丢失或只保留占位,知识库回答会出现描述缺图的情况,影响可用性。
痛点三 噪声片段干扰
页眉页脚、水印、页码、目录、脚注等若未清洗,会造成冗余片段,稀释语义密度,拉低命中率。
痛点四 可维护性差
未经标准化的内容难以批量更新与回滚,后续维护成本陡增。
前处理的价值在于 结构化、去噪、内容可读可写。经过 MinerU 清洗后,再进入切分与召回,整体质量会更稳定。
常见文档的处理建议
行业报告 PDF
目标 保留章节结构与图表说明;
做法 上传 PDF 以 MinerU 清洗,以 Markdown 转换器生成 .md ,校对标题层级与图片渲染,由 knowledge 插件写入数据集;
验证 以章节标题作为查询词核对召回片段,连续抽样检查图片是否可预览;
设计说明书 Word
目标 保留目录层级与参数表;
做法 将 .docx 上传 以 MinerU 清洗并剥离页眉页脚,将表格转为 Markdown 表格或嵌入图片,统一单位与关键名词书写;
验证 以参数名与数值组合进行查询,对比召回片段与原文是否一致;
合同与扫描件
目标 提升可检索性并保留关键条款;
做法 对扫描件使用 MinerU 的 OCR 能力,进行去噪与版面重建 生成 .md,并对关键条款添加锚点或标签;
验证 使用条款编号与关键词抽查回答,关注错别字与数字识别准确率;
总结一下
当 Dify 遇上 MinerU,原始文档先经过 MinerU 的清洗与格式化,再进入 Dify 的工作流,不仅能提升召回的准确性,还能保证知识内容的结构完整。
更进一步,通过 Markdown 转换器和 knowledge 插件,整个链路可以实现自动化闭环:
文件输入 → 数据前处理 → 转换为结构化内容 → 自动写入知识库。
这套组合让知识库建设真正变得可控、可靠,也减少了人工重复操作的成本。
对没有技术背景的团队而言,更是低门槛、可复现的实践路径。
如果你的团队正被文档格式混乱、图片缺失与噪声干扰困扰,不妨按本文的步骤搭建这条流水线。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献160条内容
已为社区贡献160条内容

所有评论(0)