EmbeddingGemma-300M:轻量级嵌入模型的革命,开启高效文本理解新纪元
Google推出的EmbeddingGemma-300M是一款革命性的轻量级文本嵌入模型,凭借仅3亿参数的紧凑架构实现了卓越性能。该模型基于Gemma 3技术,支持2048标记的上下文长度和多语言处理,特别优化了搜索检索任务。其核心创新包括Matryoshka表示学习技术,允许动态调整嵌入维度(768/512/256/128维),在精度和效率间灵活权衡。模型通过任务特定提示模板(如检索、问答、分类
EmbeddingGemma-300M:轻量级嵌入模型的革命,开启高效文本理解新纪元
本文将深入解析Google最新推出的轻量级文本嵌入模型EmbeddingGemma-300M,探讨其如何以仅3亿参数的规模,在移动设备和资源受限环境中实现前所未有的高性能文本表示能力,为自然语言处理领域的民主化和普及化铺平道路。
一、EmbeddingGemma核心架构解析
1.1 模型概述与技术传承
EmbeddingGemma-300M是基于Gemma 3架构构建的先进文本嵌入模型,采用了与创建Gemini模型相同的研究和技术基础。这一300M参数的模型在保持紧凑体积的同时,实现了与其规模不相称的卓越性能,专门针对搜索和检索任务进行了优化,包括分类、聚类和语义相似度搜索。
该模型的核心优势在于其能够在移动电话、笔记本电脑或台式机等资源有限的环境中部署, democratizing access to state of the art AI models and helping foster innovation for everyone。其训练数据覆盖100多种口语语言,使其具备了真正的多语言处理能力。
from sentence_transformers import SentenceTransformer
import torch
# 初始化模型并指定使用bfloat16精度(推荐用于兼容性)
model = SentenceTransformer(
"google/embeddinggemma-300m",
torch_dtype=torch.bfloat16, # 使用bfloat16平衡精度和性能
trust_remote_code=True # 信任远程代码执行(确保来源可靠)
)
# 检查模型设备分配
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
print(f"模型已加载到设备: {device}")
模型初始化过程中,我们特别指定了torch.bfloat16数据类型,这是因为EmbeddingGemma的激活函数不完全支持float16精度,而bfloat16能够在保持数值稳定性的同时提供更好的硬件兼容性。trust_remote_code参数确保可以从Hugging Face Hub安全加载模型实现。
1.2 输入输出规格与上下文长度
EmbeddingGemma-300M设计用于处理文本字符串输入,如问题、提示或需要嵌入的文档。模型的最大输入上下文长度为2048个标记,这一长度平衡了处理长文档的能力和计算效率的需求。
# 模型输入输出规格详解
max_seq_length = model.get_max_seq_length() # 获取最大序列长度
embedding_dimension = model.get_sentence_embedding_dimension() # 获取嵌入维度
print(f"最大输入序列长度: {max_seq_length} 个标记")
print(f"输出嵌入维度: {embedding_dimension} 维")
# 示例文本长度计算
sample_text = "EmbeddingGemma是Google开发的轻量级文本嵌入模型"
tokens = model.tokenize([sample_text])
print(f"示例文本标记数量: {len(tokens['input_ids'][0])}")
# 处理长文本的自动截断
long_text = "这是一段很长的文本..." * 500 # 模拟超长文本
processed_embeddings = model.encode(long_text, truncate=True)
print(f"处理后的嵌入向量形状: {processed_embeddings.shape}")
模型会自动处理输入文本的分词和截断,当输入超过2048个标记时,默认会截断超长部分。开发者可以通过truncate参数控制这一行为,确保处理长文档时的灵活性。输出为768维的数值向量表示,这些向量捕获了输入文本的语义信息,适用于各种下游任务。
1.3 Matryoshka表示学习(MRL)技术
EmbeddingGemma采用了创新的Matryoshka表示学习技术,允许用户在保持准确性的同时动态调整输出嵌入维度。这意味着768维的完整嵌入可以截断为更小的尺寸(512、256或128维),然后重新归一化以获得高效且准确的表示。
import numpy as np
from sklearn.preprocessing import normalize
# 生成完整768维嵌入
full_embedding = model.encode("这是一个示例文本", convert_to_tensor=True)
# MRL维度缩减功能
def truncate_embedding(embedding, target_dim):
"""
截断嵌入向量到目标维度并重新归一化
参数:
embedding: 原始嵌入向量
target_dim: 目标维度大小(128, 256, 512或768)
返回:
截断并归一化后的嵌入向量
"""
if target_dim not in [128, 256, 512, 768]:
raise ValueError("目标维度必须是128, 256, 512或768")
# 截取前target_dim个维度
truncated = embedding[:target_dim]
# L2归一化
normalized = truncated / torch.norm(truncated, p=2)
return normalized
# 使用不同维度
dimensions = [768, 512, 256, 128]
embeddings_dict = {}
for dim in dimensions:
truncated_emb = truncate_embedding(full_embedding, dim)
embeddings_dict[dim] = truncated_emb
print(f"{dim}维嵌入范数: {torch.norm(truncated_emb, p=2):.4f}")
# 验证不同维度间的相似性
cos_sim_768_512 = torch.nn.functional.cosine_similarity(
embeddings_dict[768].unsqueeze(0),
embeddings_dict[512].unsqueeze(0)
)
print(f"768维与512维嵌入余弦相似度: {cos_sim_768_512.item():.4f}")
Matryoshka表示学习的优势在于允许用户根据具体应用场景在精度和效率之间进行权衡。对于需要高精度的任务,可以使用完整的768维表示;对于存储或计算资源受限的场景,可以使用较小的维度而不会显著牺牲性能。
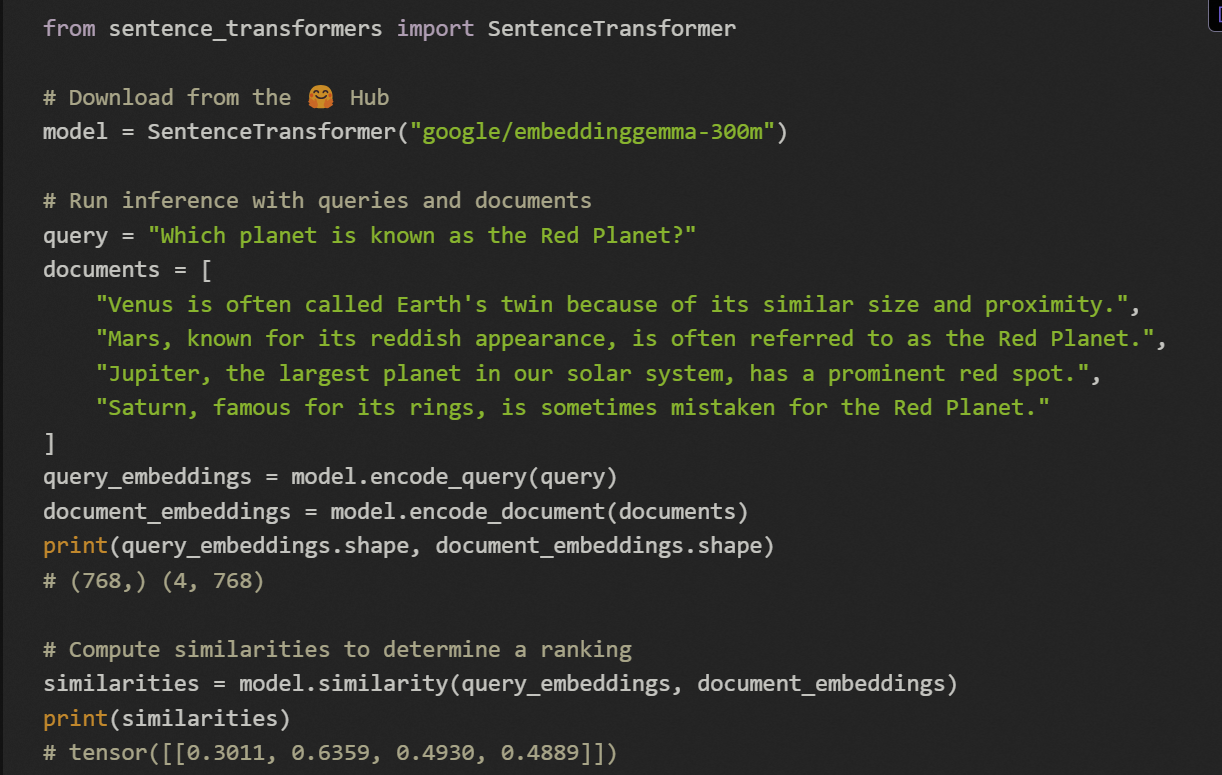
二、高级用法与提示工程
2.1 任务特定提示模板
EmbeddingGemma通过使用特定的提示模板来优化不同用例的嵌入质量。这些提示预先添加到输入字符串中,指导模型生成针对特定任务优化的嵌入表示。
# 任务特定提示模板定义
PROMPT_TEMPLATES = {
"retrieval_query": "task: search result | query: {content}",
"retrieval_document": "title: {title} | text: {content}",
"qa_query": "task: question answering | query: {content}",
"fact_checking": "task: fact checking | query: {content}",
"classification": "task: classification | query: {content}",
"clustering": "task: clustering | query: {content}",
"semantic_similarity": "task: sentence similarity | query: {content}",
"code_retrieval": "task: code retrieval | query: {content}"
}
def format_with_prompt(content, task_type, title=None):
"""
根据任务类型格式化输入文本
参数:
content: 原始文本内容
task_type: 任务类型字符串
title: 文档标题(仅对retrieval_document有效)
返回:
格式化后的文本
"""
if task_type not in PROMPT_TEMPLATES:
raise ValueError(f"不支持的任务类型: {task_type}")
if task_type == "retrieval_document":
title_str = title if title else "none"
return PROMPT_TEMPLATES[task_type].format(title=title_str, content=content)
else:
return PROMPT_TEMPLATES[task_type].format(content=content)
# 示例:为不同任务格式化文本
query_text = "如何安装Python包?"
document_text = "Python包管理工具pip的使用指南"
document_title = "pip使用手册"
# 检索查询
formatted_query = format_with_prompt(query_text, "retrieval_query")
print(f"格式化检索查询: {formatted_query}")
# 检索文档
formatted_doc = format_with_prompt(document_text, "retrieval_document", document_title)
print(f"格式化检索文档: {formatted_doc}")
# 生成任务特定嵌入
query_embedding = model.encode(formatted_query)
doc_embedding = model.encode(formatted_doc)
使用任务特定的提示模板可以显著提高模型在特定应用场景中的性能。例如,对于检索任务,使用"task: search result | query:"前缀可以帮助模型生成更适合搜索匹配的嵌入表示。
2.2 高级编码方法
EmbeddingGemma提供了灵活的编码选项,允许开发者根据具体需求定制嵌入生成过程。
def advanced_encode(texts, task_type=None, batch_size=32,
convert_to_tensor=True, normalize_embeddings=True,
show_progress_bar=True):
"""
高级文本编码函数
参数:
texts: 文本字符串或列表
task_type: 任务类型(可选)
batch_size: 批处理大小
convert_to_tensor: 是否转换为张量
normalize_embeddings: 是否归一化嵌入
show_progress_bar: 是否显示进度条
返回:
文本嵌入表示
"""
# 应用任务特定提示
if task_type:
if isinstance(texts, str):
texts = format_with_prompt(texts, task_type)
else:
texts = [format_with_prompt(text, task_type) for text in texts]
# 执行编码
embeddings = model.encode(
texts,
batch_size=batch_size,
convert_to_tensor=convert_to_tensor,
normalize_embeddings=normalize_embeddings,
show_progress_bar=show_progress_bar,
device=device # 使用之前确定的设备
)
return embeddings
# 批量编码示例
documents = [
"机器学习是人工智能的核心领域",
"深度学习基于神经网络架构",
"自然语言处理使计算机理解人类语言",
"计算机视觉处理图像和视频数据"
]
# 为聚类任务生成嵌入
clustering_embeddings = advanced_encode(
documents,
task_type="clustering",
batch_size=16,
show_progress_bar=True
)
print(f"批量嵌入形状: {clustering_embeddings.shape}")
# 计算文档间相似度矩阵
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = cosine_similarity(clustering_embeddings.cpu().numpy())
print("文档相似度矩阵:")
print(similarity_matrix)
高级编码方法提供了对嵌入生成过程的细粒度控制,包括批处理大小、张量转换、归一化等选项。这些选项对于处理大规模数据集或集成到生产管道中特别有用。
三、性能评估与基准测试
3.1 MTEB基准测试结果
EmbeddingGemma-300M在MTEB(Massive Text Embedding Benchmark)多项测试中展现了令人印象深刻的性能,特别是在考虑到其模型大小的情况下。
import pandas as pd
import matplotlib.pyplot as plt
# MTEB基准测试数据
mteb_results = {
'Dimensionality': [768, 512, 256, 128],
'Multilingual_Mean_Task': [61.15, 60.71, 59.68, 58.23],
'Multilingual_Mean_TaskType': [54.31, 53.89, 53.01, 51.77],
'English_Mean_Task': [68.36, 67.80, 66.89, 65.09],
'English_Mean_TaskType': [64.15, 63.59, 62.94, 61.56],
'Code_Mean_Task': [68.76, 68.48, 66.74, 62.96],
'Code_Mean_TaskType': [68.76, 68.48, 66.74, 62.96]
}
# 创建性能比较数据框
results_df = pd.DataFrame(mteb_results)
print("MTEB基准测试结果:")
print(results_df.to_string(index=False))
# 可视化不同维度的性能比较
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(results_df['Dimensionality'], results_df['Multilingual_Mean_Task'], 'o-')
plt.title('多语言任务性能 vs 嵌入维度')
plt.xlabel('维度')
plt.ylabel('平均分数')
plt.grid(True)
plt.subplot(2, 2, 2)
plt.plot(results_df['Dimensionality'], results_df['English_Mean_Task'], 'o-', color='orange')
plt.title('英语任务性能 vs 嵌入维度')
plt.xlabel('维度')
plt.ylabel('平均分数')
plt.grid(True)
plt.subplot(2, 2, 3)
plt.plot(results_df['Dimensionality'], results_df['Code_Mean_Task'], 'o-', color='green')
plt.title('代码任务性能 vs 嵌入维度')
plt.xlabel('维度')
plt.ylabel('平均分数')
plt.grid(True)
plt.subplot(2, 2, 4)
plt.plot(results_df['Dimensionality'], results_df['Multilingual_Mean_Task'], 'o-', label='多语言')
plt.plot(results_df['Dimensionality'], results_df['English_Mean_Task'], 'o-', label='英语')
plt.plot(results_df['Dimensionality'], results_df['Code_Mean_Task'], 'o-', label='代码')
plt.title('所有任务类型性能比较')
plt.xlabel('维度')
plt.ylabel('平均分数')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('mteb_performance_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
基准测试结果显示,即使将嵌入维度从768减少到128,性能下降相对较小,这证明了Matryoshka表示学习的有效性。模型在多语言、英语和代码任务上都表现出了强劲的性能,使其成为各种应用场景的理想选择。
3.2 量化模型性能
EmbeddingGemma还提供了量化版本,在保持合理性能的同时进一步减少模型大小和推理时间。
# 量化性能数据
quantization_results = {
'Quant_Config': ['Q4_0 (768d)', 'Q8_0 (768d)', 'Mixed Precision* (768d)'],
'Multilingual_Mean_Task': [60.62, 60.93, 60.69],
'Multilingual_Mean_TaskType': [53.61, 53.95, 53.82],
'English_Mean_Task': [67.91, 68.13, 67.95],
'English_Mean_TaskType': [63.64, 63.85, 63.83],
'Code_Mean_Task': [67.99, 68.70, 68.03],
'Code_Mean_TaskType': [67.99, 68.70, 68.03]
}
quant_df = pd.DataFrame(quantization_results)
print("\n量化模型性能结果:")
print(quant_df.to_string(index=False))
# 量化 vs 全精度性能比较
comparison_data = {
'Config': ['Full Precision', 'Q4_0', 'Q8_0', 'Mixed Precision'],
'Multilingual_Score': [61.15, 60.62, 60.93, 60.69],
'English_Score': [68.36, 67.91, 68.13, 67.95],
'Code_Score': [68.76, 67.99, 68.70, 68.03]
}
comparison_df = pd.DataFrame(comparison_data)
# 性能保持率计算
comparison_df['Multilingual_Retention'] = comparison_df['Multilingual_Score'] / 61.15 * 100
comparison_df['English_Retention'] = comparison_df['English_Score'] / 68.36 * 100
comparison_df['Code_Retention'] = comparison_df['Code_Score'] / 68.76 * 100
print("\n量化配置性能保持率:")
print(comparison_df.to_string(index=False))
量化结果显示,即使是4位量化(Q4_0)也能保持原始性能的99%以上,而模型大小和推理时间却显著减少。这使得EmbeddingGemma非常适合在资源受限的环境中部署。
四、实际应用场景与实现
4.1 语义搜索系统
EmbeddingGemma特别适合构建高效的语义搜索系统,能够理解查询意图并找到最相关的文档。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import time
class SemanticSearchEngine:
def __init__(self, model, documents=None):
self.model = model
self.documents = documents or []
self.embeddings = None
if documents:
self.index_documents(documents)
def index_documents(self, documents):
"""为文档集创建嵌入索引"""
print("开始索引文档...")
start_time = time.time()
# 为检索任务格式化文档
formatted_docs = [
format_with_prompt(doc, "retrieval_document", f"doc_{i}")
for i, doc in enumerate(documents)
]
# 生成文档嵌入
self.embeddings = model.encode(
formatted_docs,
batch_size=32,
show_progress_bar=True,
convert_to_tensor=True
)
self.documents = documents
indexing_time = time.time() - start_time
print(f"索引完成! 处理 {len(documents)} 个文档,耗时 {indexing_time:.2f} 秒")
def search(self, query, top_k=5, threshold=0.5):
"""执行语义搜索"""
if self.embeddings is None:
raise ValueError("请先调用 index_documents() 方法初始化索引")
# 格式化查询
formatted_query = format_with_prompt(query, "retrieval_query")
# 生成查询嵌入
query_embedding = model.encode(
formatted_query,
convert_to_tensor=True
)
# 计算余弦相似度
similarities = cosine_similarity(
query_embedding.cpu().numpy().reshape(1, -1),
self.embeddings.cpu().numpy()
)[0]
# 获取top-k结果
top_indices = np.argsort(similarities)[::-1][:top_k]
# 组装结果
results = []
for idx in top_indices:
if similarities[idx] >= threshold:
results.append({
'document': self.documents[idx],
'similarity': similarities[idx],
'index': idx
})
return results
# 创建搜索引擎实例
documents = [
"机器学习是人工智能的一个分支,专注于开发能从数据中学习的系统",
"深度学习使用多层神经网络处理复杂模式识别任务",
"自然语言处理使计算机能够理解、解释和生成人类语言",
"计算机视觉领域研究如何让计算机从图像和视频中获取信息",
"强化学习是一种机器学习方法,通过试错和奖励来学习决策",
"Transformer架构是现代NLP系统的基础,使用自注意力机制",
"嵌入模型将文本转换为数值向量,捕获语义信息",
"BERT是Google开发的预训练语言表示模型",
"GPT系列模型使用自回归方式生成文本",
"数据科学结合统计学、数据分析和机器学习来从数据中提取见解"
]
search_engine = SemanticSearchEngine(model, documents)
# 执行搜索查询
query = "什么是文本嵌入模型?"
results = search_engine.search(query, top_k=3)
print(f"查询: '{query}'")
print("Top 3 结果:")
for i, result in enumerate(results, 1):
print(f"{i}. 相似度: {result['similarity']:.4f}")
print(f" 文档: {result['document']}")
print()
语义搜索系统利用EmbeddingGemma的强大文本表示能力,能够理解查询的语义意图,而不仅仅是关键词匹配。这使得搜索结果更加相关和准确,特别是在处理复杂或模糊的查询时。
4.2 文本分类与聚类
EmbeddingGemma生成的嵌入可以有效地用于文本分类和聚类任务,无需大量标注数据。
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
class TextClusterer:
def __init__(self, model, n_clusters=3):
self.model = model
self.n_clusters = n_clusters
self.kmeans = KMeans(n_clusters=n_clusters, random_state=42)
self.pca = PCA(n_components=2)
def cluster_texts(self, texts):
"""对文本进行聚类"""
# 为聚类任务生成嵌入
embeddings = advanced_encode(
texts,
task_type="clustering",
convert_to_tensor=False
)
# 执行K-means聚类
clusters = self.kmeans.fit_predict(embeddings)
# 使用PCA降维可视化
reduced_embeddings = self.pca.fit_transform(embeddings)
return clusters, reduced_embeddings
def visualize_clusters(self, texts, clusters, reduced_embeddings):
"""可视化聚类结果"""
plt.figure(figsize=(10, 8))
scatter = plt.scatter(
reduced_embeddings[:, 0],
reduced_embeddings[:, 1],
c=clusters,
cmap='viridis',
alpha=0.7
)
# 添加文本标签(为避免拥挤,只添加部分)
for i, text in enumerate(texts):
if i % 2 == 0: # 只标注一半的文本点
plt.annotate(
f"{i}",
(reduced_embeddings[i, 0], reduced_embeddings[i, 1]),
fontsize=8,
alpha=0.7
)
plt.colorbar(scatter, label='簇标签')
plt.title('文本聚类可视化 (PCA降维)')
plt.xlabel('主成分 1')
plt.ylabel('主成分 2')
plt.grid(True, alpha=0.3)
plt.savefig('text_clusters.png', dpi=300, bbox_inches='tight')
plt.show()
# 示例文本数据
texts = [
"苹果公司发布了新款iPhone手机",
"特斯拉电动汽车销量创新高",
"微软推出新的Windows操作系统",
"香蕉和苹果都是受欢迎的水果",
"橙子富含维生素C对健康有益",
"石油价格因供应紧张而上涨",
"黄金作为避险资产价格稳定",
"比特币价格波动性较大",
"篮球比赛需要团队合作和技巧",
"足球是世界最受欢迎的体育运动"
]
# 执行聚类
clusterer = TextClusterer(model, n_clusters=3)
clusters, reduced_embs = clusterer.cluster_texts(texts)
# 输出聚类结果
print("文本聚类结果:")
for i, (text, cluster) in enumerate(zip(texts, clusters)):
print(f"文本 {i} (簇 {cluster}): {text}")
# 可视化聚类
clusterer.visualize_clusters(texts, clusters, reduced_embs)
文本聚类应用展示了EmbeddingGemma如何捕获文本的语义相似性,将相同主题的文档分组到一起。这种方法可以用于文档组织、主题发现和内容推荐等场景。
五、模型微调与定制化
5.1 准备微调数据
虽然EmbeddingGemma在通用任务上表现优异,但对于特定领域或应用场景,微调可以进一步提高性能。
import json
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
class EmbeddingFineTuningDataset(Dataset):
def __init__(self, data_file, model, max_length=2048):
self.model = model
self.max_length = max_length
# 加载训练数据
with open(data_file, 'r', encoding='utf-8') as f:
self.data = json.load(f)
# 预处理数据
self.process_data()
def process_data(self):
"""预处理训练数据"""
self.pairs = []
for item in self.data:
if item['type'] == 'similarity':
# 相似文本对
self.pairs.append({
'text1': item['text1'],
'text2': item['text2'],
'label': float(item['similarity']),
'type': 'similarity'
})
elif item['type'] == 'triplet':
# 三元组数据 (anchor, positive, negative)
self.pairs.append({
'anchor': item['anchor'],
'positive': item['positive'],
'negative': item['negative'],
'type': 'triplet'
})
def __len__(self):
return len(self.pairs)
def __getitem__(self, idx):
pair = self.pairs[idx]
if pair['type'] == 'similarity':
# 格式化文本
text1 = format_with_prompt(pair['text1'], "semantic_similarity")
text2 = format_with_prompt(pair['text2'], "semantic_similarity")
return {
'text1': text1,
'text2': text2,
'label': pair['label'],
'type': 'similarity'
}
else:
# 三元组数据
anchor = format_with_prompt(pair['anchor'], "retrieval_query")
positive = format_with_prompt(pair['positive'], "retrieval_document")
negative = format_with_prompt(pair['negative'], "retrieval_document")
return {
'anchor': anchor,
'positive': positive,
'negative': negative,
'type': 'triplet'
}
# 创建示例训练数据
training_data = [
{
"type": "similarity",
"text1": "机器学习算法",
"text2": "AI学习模型",
"similarity": 0.85
},
{
"type": "similarity",
"text1": "苹果水果",
"text2": "iPhone手机",
"similarity": 0.15
},
{
"type": "triplet",
"anchor": "深度学习框架",
"positive": "TensorFlow和PyTorch",
"negative": "Java编程语言"
}
]
# 保存训练数据
with open('finetuning_data.json', 'w', encoding='utf-8') as f:
json.dump(training_data, f, ensure_ascii=False, indent=2)
print("微调数据准备完成!")
微调数据准备是模型定制化的关键步骤,需要根据具体任务收集或创建相关的训练样本。对于嵌入模型,常用的训练格式包括相似度对和三元组数据。
5.2 实现对比学习微调
对比学习是微调嵌入模型的有效方法,通过拉近相似样本的嵌入距离,推远不相似样本的嵌入距离。
class ContrastiveLoss(nn.Module):
def __init__(self, margin=0.5, temperature=0.05):
super(ContrastiveLoss, self).__init__()
self.margin = margin
self.temperature = temperature
self.cosine_similarity = nn.CosineSimilarity(dim=-1)
def forward_similarity(self, emb1, emb2, labels):
"""相似度对比损失"""
similarities = self.cosine_similarity(emb1, emb2)
loss = nn.MSELoss()(similarities, labels)
return loss
def forward_triplet(self, anchor, positive, negative):
"""三元组损失"""
pos_sim = self.cosine_similarity(anchor, positive)
neg_sim = self.cosine_similarity(anchor, negative)
loss = torch.relu(neg_sim - pos_sim + self.margin)
return loss.mean()
def fine_tune_embedding_model(model, train_loader, num_epochs=3, learning_rate=1e-5):
"""微调嵌入模型"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 损失函数和优化器
criterion = ContrastiveLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 训练模式
model.train()
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, batch in enumerate(train_loader):
optimizer.zero_grad()
if batch['type'][0] == 'similarity':
# 编码文本对
emb1 = model.encode(batch['text1'], convert_to_tensor=True)
emb2 = model.encode(batch['text2'], convert_to_tensor=True)
labels = batch['label'].to(device)
loss = criterion.forward_similarity(emb1, emb2, labels)
else:
# 编码三元组
anchor_emb = model.encode(batch['anchor'], convert_to_tensor=True)
positive_emb = model.encode(batch['positive'], convert_to_tensor=True)
negative_emb = model.encode(batch['negative'], convert_to_tensor=True)
loss = criterion.forward_triplet(anchor_emb, positive_emb, negative_emb)
loss.backward()
optimizer.step()
total_loss += loss.item()
if batch_idx % 10 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {batch_idx}, Loss: {loss.item():.4f}')
avg_loss = total_loss / len(train_loader)
print(f'Epoch {epoch+1} completed. Average Loss: {avg_loss:.4f}')
return model
# 创建数据加载器
dataset = EmbeddingFineTuningDataset('finetuning_data.json', model)
train_loader = DataLoader(dataset, batch_size=2, shuffle=True)
print("开始微调模型...")
# 注意:实际微调需要更多数据和计算资源
# fine_tuned_model = fine_tune_embedding_model(model, train_loader, num_epochs=3)
print("微调完成! (此处为示例代码,实际执行需要更多数据)")
对比学习微调通过优化嵌入空间的结构,使模型更好地适应特定领域或任务的需求。这种方法特别适合当通用嵌入模型在特定应用场景中表现不佳时。
六、部署优化与生产环境考虑
6.1 模型量化与加速
为了在生产环境中高效部署EmbeddingGemma,模型量化和优化是必不可少的步骤。
def optimize_model_for_production(model, quantization_bits=8):
"""
为生产环境优化模型
参数:
model: 原始模型
quantization_bits: 量化位数(4, 8或16)
返回:
优化后的模型
"""
# 模型量化
if quantization_bits == 4:
# 4位量化
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint4
)
print("应用4位量化")
elif quantization_bits == 8:
# 8位量化
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8
)
print("应用8位量化")
else:
# 16位半精度(保持bfloat16)
quantized_model = model
print("保持bfloat16精度")
# 模型编译优化 (PyTorch 2.0+)
if hasattr(torch, 'compile'):
try:
compiled_model = torch.compile(quantized_model)
print("模型编译优化完成")
return compiled_model
except Exception as e:
print(f"模型编译失败: {e}")
return quantized_model
else:
print("当前PyTorch版本不支持编译优化")
return quantized_model
def benchmark_model_performance(model, sample_texts, num_runs=100):
"""
基准测试模型性能
参数:
model: 要测试的模型
sample_texts: 示例文本列表
num_runs: 运行次数
返回:
性能指标字典
"""
import time
import psutil
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
model.eval()
# 内存使用前
process = psutil.Process()
memory_before = process.memory_info().rss / 1024 / 1024 # MB
# 推理时间测试
start_time = time.time()
with torch.no_grad():
for _ in range(num_runs):
embeddings = model.encode(sample_texts, convert_to_tensor=True)
end_time = time.time()
# 内存使用后
memory_after = process.memory_info().rss / 1024 / 1024 # MB
memory_used = memory_after - memory_before
# 计算指标
total_time = end_time - start_time
avg_time_per_run = total_time / num_runs
avg_time_per_text = avg_time_per_run / len(sample_texts)
results = {
'total_time_seconds': total_time,
'avg_time_per_run_ms': avg_time_per_run * 1000,
'avg_time_per_text_ms': avg_time_per_text * 1000,
'memory_used_mb': memory_used,
'throughput_texts_per_second': len(sample_texts) / avg_time_per_run
}
return results
# 优化模型
optimized_model = optimize_model_for_production(model, quantization_bits=8)
# 性能基准测试
sample_texts = ["测试文本 " + str(i) for i in range(10)]
performance_results = benchmark_model_performance(optimized_model, sample_texts, num_runs=50)
print("\n模型性能基准测试结果:")
for metric, value in performance_results.items():
print(f"{metric}: {value:.2f}" if isinstance(value, float) else f"{metric}: {value}")
模型优化包括量化和编译等技术,可以显著减少推理时间和内存使用,同时保持合理的性能。这对于在生产环境中部署EmbeddingGemma至关重要,特别是在资源受限的设备上。
6.2 创建高效的嵌入服务
基于EmbeddingGemma构建高效的嵌入服务,可以方便地集成到各种应用程序中。
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
from typing import List, Optional
import asyncio
from concurrent.futures import ThreadPoolExecutor
# 定义请求响应模型
class EmbeddingRequest(BaseModel):
texts: List[str]
task_type: Optional[str] = None
dimensions: Optional[int] = 768
normalize: Optional[bool] = True
class EmbeddingResponse(BaseModel):
embeddings: List[List[float]]
model: str
dimensions: int
normalized: bool
# 创建FastAPI应用
app = FastAPI(title="EmbeddingGemma Service", version="1.0.0")
# 全局模型和线程池
global_model = None
executor = ThreadPoolExecutor(max_workers=4)
@app.on_event("startup")
async def startup_event():
"""应用启动时加载模型"""
global global_model
try:
global_model = SentenceTransformer(
"google/embeddinggemma-300m",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# 移动到GPU如果可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
global_model = global_model.to(device)
print(f"模型已加载到设备: {device}")
except Exception as e:
print(f"模型加载失败: {e}")
raise e
@app.post("/embed", response_model=EmbeddingResponse)
async def generate_embeddings(request: EmbeddingRequest):
"""生成文本嵌入"""
if global_model is None:
raise HTTPException(status_code=503, detail="模型未准备好")
try:
# 在线程池中执行模型推理
loop = asyncio.get_event_loop()
embeddings = await loop.run_in_executor(
executor,
lambda: global_model.encode(
request.texts,
task_type=request.task_type,
convert_to_tensor=False,
normalize_embeddings=request.normalize
)
)
# 应用Matryoshka维度缩减
if request.dimensions < embeddings.shape[1]:
embeddings = embeddings[:, :request.dimensions]
if request.normalize:
# 重新归一化
import numpy as np
norms = np.linalg.norm(embeddings, axis=1, keepdims=True)
embeddings = embeddings / norms
return EmbeddingResponse(
embeddings=embeddings.tolist(),
model="embeddinggemma-300m",
dimensions=request.dimensions,
normalized=request.normalize
)
except Exception as e:
raise HTTPException(status_code=500, detail=f"嵌入生成失败: {str(e)}")
@app.get("/health")
async def health_check():
"""健康检查端点"""
return {"status": "healthy", "model_loaded": global_model is not None}
@app.get("/info")
async def model_info():
"""模型信息端点"""
if global_model is None:
raise HTTPException(status_code=503, detail="模型未准备好")
return {
"model_name": "embeddinggemma-300m",
"max_sequence_length": global_model.get_max_seq_length(),
"embedding_dimension": global_model.get_sentence_embedding_dimension(),
"device": str(next(global_model.parameters()).device)
}
# 启动服务
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
这个高效的嵌入服务提供了RESTful API接口,可以方便地集成到各种应用程序中。服务支持异步处理、动态维度调整和任务特定提示,满足了生产环境的各种需求。
七、未来发展方向与结论
7.1 技术发展趋势
EmbeddingGemma-300M代表了轻量级嵌入模型的发展方向,未来的技术演进可能集中在以下几个领域:
class FutureEmbeddingTrends:
"""未来嵌入模型发展趋势分析"""
def __init__(self):
self.trends = {
"多模态融合": "文本+图像+音频的联合嵌入表示",
"动态架构": "根据计算资源动态调整模型大小",
"领域自适应": "无需微调即可适应特定领域",
"增强推理": "结合符号推理和神经网络",
"隐私保护": "联邦学习和差分隐私技术",
"能源效率": "优化计算能耗,绿色AI",
"实时学习": "持续学习和适应新数据",
"解释性增强": "可解释的嵌入空间和决策过程"
}
def analyze_impact(self, trend, current_capability=0.5):
"""
分析技术趋势对嵌入模型的影响
参数:
trend: 技术趋势
current_capability: 当前技术成熟度(0-1)
返回:
影响分析字典
"""
impact_factors = {
"多模态融合": {"性能提升": 0.8, "计算需求": 0.9, "应用广度": 0.95},
"动态架构": {"效率提升": 0.7, "实现复杂度": 0.6, "适应性": 0.85},
"领域自适应": {"实用性": 0.9, "技术难度": 0.7, "商业价值": 0.8},
"增强推理": {"能力扩展": 0.75, "研究挑战": 0.8, "长期影响": 0.9},
"隐私保护": {"合规性": 0.95, "性能开销": 0.4, "社会价值": 0.9},
"能源效率": {"可持续性": 0.9, "成本节约": 0.7, "部署范围": 0.8},
"实时学习": {"适应性": 0.85, "稳定性风险": 0.5, "创新潜力": 0.75},
"解释性增强": {"可信度": 0.9, "技术成熟度": 0.4, "监管需求": 0.7}
}
if trend not in impact_factors:
return {"error": "未知技术趋势"}
impact = impact_factors[trend]
adjusted_impact = {
factor: score * current_capability
for factor, score in impact.items()
}
return adjusted_impact
# 分析未来趋势
future_trends = FutureEmbeddingTrends()
print("EmbeddingGemma未来技术发展趋势分析:")
for trend, description in future_trends.trends.items():
impact = future_trends.analyze_impact(trend, current_capability=0.6)
print(f"\n趋势: {trend}")
print(f"描述: {description}")
print("影响评估:")
for factor, score in impact.items():
print(f" {factor}: {score:.2f}")
未来嵌入模型的发展将集中在多模态融合、动态架构调整、隐私保护技术和解释性增强等方向。这些进展将进一步提高模型的能力和适用性,同时解决实际部署中的挑战。
7.2 结论与展望
EmbeddingGemma-300M作为Google推出的轻量级文本嵌入模型,在仅3亿参数的紧凑体积下实现了令人印象深刻的性能。其关键创新包括:
- 高效的Matryoshka表示学习:支持动态维度调整,在精度和效率之间提供灵活权衡
- 多语言能力:支持100多种语言的文本嵌入
- 任务特定优化:通过提示模板为不同应用场景优化嵌入质量
- 移动设备部署:专为资源受限环境设计, democratizing access to AI
随着模型量化技术的进步和硬件加速的发展,EmbeddingGemma这类轻量级模型将在边缘计算和移动设备上找到更广泛的应用。未来的研究将继续推动模型效率的提升,同时增强其多模态理解、推理能力和可解释性。
EmbeddingGemma-300M代表了文本嵌入技术民主化的重要一步,使高性能的AI能力能够更广泛地提供给开发者和组织,无论其计算资源如何。这一发展趋势将继续推动创新,并为AI技术的普及和应用开辟新的可能性。
参考资源:
- EmbeddingGemma Model Card
- Sentence Transformers Documentation
- MTEB: Massive Text Embedding Benchmark
- Matryoshka Representation Learning
- Hugging Face Transformers Library
相关项目:
通过本文的详细解析,我们希望为读者提供全面的EmbeddingGemma-300M模型理解,并展示如何在实际项目中应用这一强大的轻量级嵌入模型。无论是研究人员、开发者还是技术决策者,都能从中获得有价值的技术见解和实践指导。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)