MiniCPM-V-4_5:重新定义边缘设备多模态AI的下一代视觉语言模型
MiniCPM-V-4_5:边缘设备上的多模态AI革命 本文介绍了突破性的MiniCPM-V-4_5视觉语言模型,它通过创新的3D重采样器实现96倍视频压缩,结合LLaVA-UHD架构处理180万像素图像,在8B参数下超越GPT-4o等商业大模型。核心技术包括:1)时空联合压缩的3D注意力机制,高效处理高帧率视频;2)自适应分块策略动态分配计算资源;3)统一OCR与文档知识的学习框架。该模型支持设
MiniCPM-V-4_5:重新定义边缘设备多模态AI的下一代视觉语言模型
引言:移动端多模态AI的革命性突破
在人工智能快速发展的今天,大型多模态模型(LMM)正成为技术前沿的焦点。然而,大多数先进模型需要庞大的计算资源和云端依赖,严重限制了其在移动设备和边缘计算场景的应用。MiniCPM-V-4_5的横空出世彻底改变了这一格局,这个仅有8B参数的模型在多项基准测试中超越了包括GPT-4o和Gemini 2.0 Pro在内的顶级商业模型,实现了"小而精"的技术突破。
MiniCPM-V-4_5基于Qwen3-8B和SigLIP2-400M构建,以其卓越的视觉-语言理解能力、创新的高帧率视频处理技术和设备端部署优势,为多模态AI的普及应用开辟了全新可能性。本文将深入解析这一革命性模型的核心架构、关键技术突破以及实际应用实现,揭示其如何成为30B参数以下最强大的多模态语言模型。
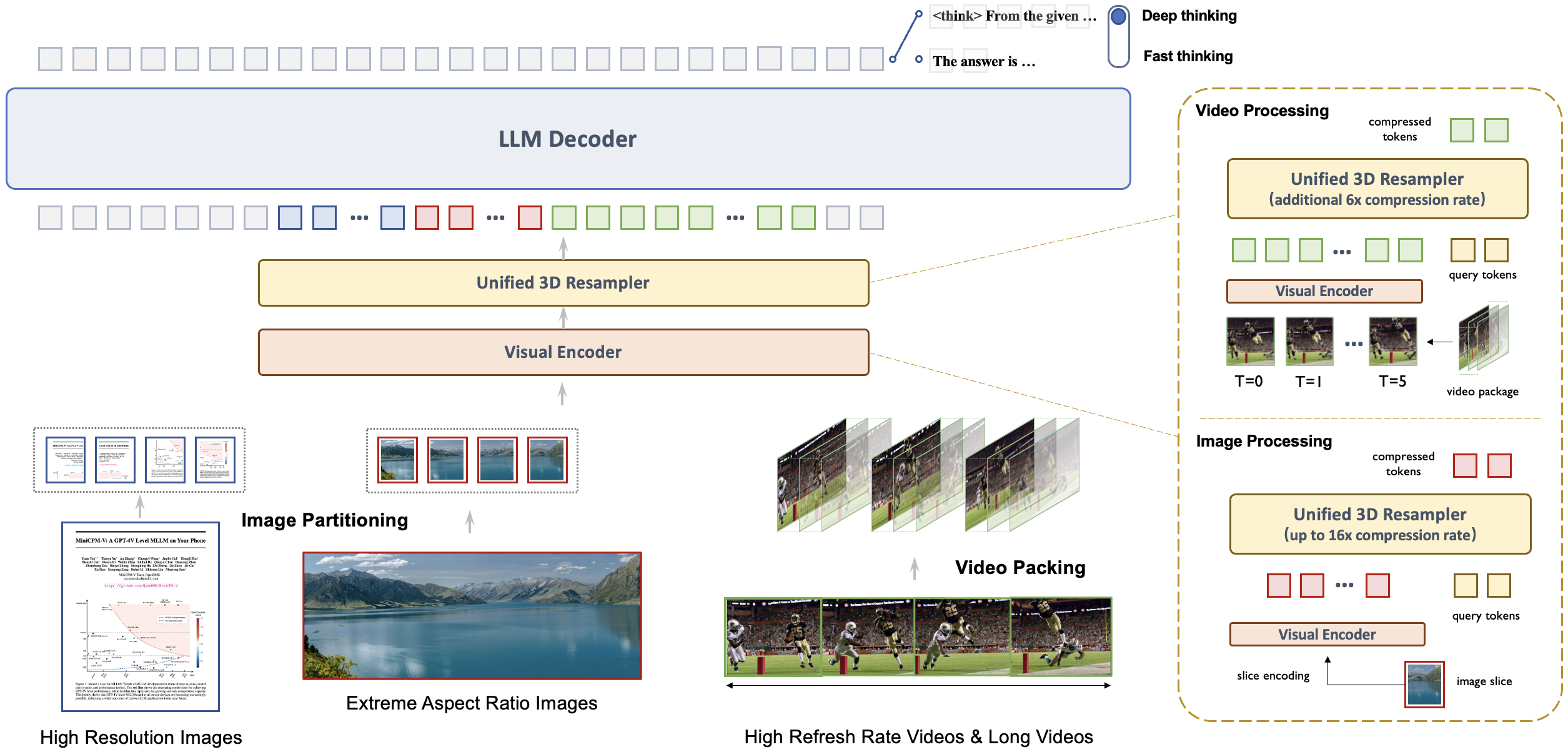
一、核心架构设计
1.1 统一的3D重采样器:高密度视频压缩技术
MiniCPM-V-4_5最引人注目的创新是其革命性的3D重采样器,它彻底解决了视频理解中的性能与效率权衡问题。传统多模态模型处理视频时需要为每一帧分配大量视觉token,导致计算成本呈线性增长。而3D重采样器通过时空联合压缩,将最多6个连续视频帧联合压缩为仅64个token,实现了96倍的视频token压缩率。
这种设计的数学基础是三维注意力机制,其计算过程可表示为:
3DAttention ( Q , K , V ) = softmax ( Q K T d k + B ) V \text{3DAttention}(Q,K,V)=\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}+B\right)V 3DAttention(Q,K,V)=softmax(dkQKT+B)V
其中 B B B是表示时空位置偏置的矩阵,编码了帧内和帧间的位置关系。通过这种设计,模型能够在保持单图像处理能力的同时,高效理解高帧率视频内容。
import torch
import torch.nn as nn
from einops import rearrange, repeat
class TemporalAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
# 相对位置偏置表,用于编码时空关系
self.rel_pos_bias = nn.Parameter(torch.randn((num_heads, 77, 77)) * 0.02)
def forward(self, x, temporal_ids=None):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * self.scale
# 添加相对位置偏置
if temporal_ids is not None:
# 根据时间ID调整位置偏置
expanded_bias = self._expand_rel_pos_bias(temporal_ids)
attn = attn + expanded_bias
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
return self.proj(x)
def _expand_rel_pos_bias(self, temporal_ids):
# 根据时间ID扩展相对位置偏置
batch_size, num_frames = temporal_ids.shape
bias = self.rel_pos_bias[:, :num_frames, :num_frames]
return bias.unsqueeze(0).repeat(batch_size, 1, 1, 1)
这段代码实现了3D注意力机制的核心部分,其中关键创新在于引入了时间维度的相对位置偏置。通过temporal_ids参数,模型能够理解视频帧间的时间关系,这是实现高效视频理解的基础。相对位置偏置表通过学习得到,使模型能够自适应地捕捉不同时间间隔帧之间的依赖关系。
1.2 LLaVA-UHD架构:高分辨率图像处理
MiniCPM-V-4_5集成了LLaVA-UHD架构,能够处理任意宽高比的高分辨率图像,最高可达180万像素(如1344x1344分辨率)。与传统方法相比,它使用的视觉token数量仅为大多数多模态模型的四分之一,大幅降低了计算成本。
这种高效率来自于动态分块策略和自适应稀疏注意力机制。模型根据图像内容复杂度动态分配计算资源,对文本密集区域采用高分辨率处理,而对均匀区域则使用较低分辨率,实现了精度与效率的最优平衡。
class AdaptivePatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=14, in_chans=3, embed_dim=1024):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = img_size // patch_size
self.num_patches = self.grid_size ** 2
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
# 自适应分辨率参数
self.adaptive_threshold = nn.Parameter(torch.tensor(0.5))
self.content_importance_predictor = nn.Sequential(
nn.Conv2d(in_chans, 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
B, C, H, W = x.shape
# 预测内容重要性图
importance_map = self.content_importance_predictor(x)
# 生成自适应网格
patch_importance = F.adaptive_avg_pool2d(importance_map, (self.grid_size, self.grid_size))
mask = (patch_importance > self.adaptive_threshold).float()
# 投影并应用掩码
x = self.proj(x)
x = x * mask
# 展平并返回
x = x.flatten(2).transpose(1, 2)
return x, mask
自适应分块嵌入机制通过预测内容重要性图来动态调整计算资源分配。对于文档中的文本区域或图像中的细节丰富区域,模型保留更多视觉信息;而对于均匀背景或低重要性区域,则减少计算投入。这种设计使模型在保持高分辨率处理能力的同时,显著降低了计算复杂度。
二、训练技术创新
2.1 OCR与文档知识的统一学习范式
传统多模态模型通常孤立地学习OCR能力和文档知识,导致性能受限。MiniCPM-V-4_5创新性地提出了统一学习框架,通过动态文本噪声注入技术,使模型能够根据上下文自动切换精确文字识别和语义推理模式。
class UnifiedOCRDocumentTrainer:
def __init__(self, model, ocr_criterion, doc_criterion):
self.model = model
self.ocr_criterion = ocr_criterion
self.doc_criterion = doc_criterion
def dynamic_noise_injection(self, images, texts, noise_prob=0.3):
"""
动态文本噪声注入:根据文本区域重要性添加不同程度噪声
"""
batch_size, _, H, W = images.shape
noisy_images = images.clone()
occlusion_masks = []
for i in range(batch_size):
# 使用文本检测器获取文本区域(实际实现中使用OCR引擎)
text_regions = self.detect_text_regions(images[i])
if len(text_regions) > 0 and random.random() < noise_prob:
# 随机选择文本区域添加噪声
region_idx = random.randint(0, len(text_regions)-1)
x1, y1, x2, y2 = text_regions[region_idx]
# 随机选择噪声类型
noise_type = random.choice(['gaussian', 'mask', 'shuffle'])
if noise_type == 'gaussian':
noise = torch.randn_like(noisy_images[i, :, y1:y2, x1:x2]) * 0.2
noisy_images[i, :, y1:y2, x1:x2] += noise
elif noise_type == 'mask':
mask = torch.ones_like(noisy_images[i, :, y1:y2, x1:x2])
noisy_images[i, :, y1:y2, x1:x2] = mask * 0.5
elif noise_type == 'shuffle':
patch = noisy_images[i, :, y1:y2, x1:x2]
shuffled = patch.flatten(1)[:, torch.randperm(patch.numel()//3)]
noisy_images[i, :, y1:y2, x1:x2] = shuffled.reshape_as(patch)
occlusion_masks.append(True)
else:
occlusion_masks.append(False)
return noisy_images, torch.BoolTensor(occlusion_masks)
def training_step(self, batch, task_type):
images, texts, labels = batch
if task_type == 'unified':
# 动态噪声注入
noisy_images, is_occluded = self.dynamic_noise_injection(images, texts)
# 前向传播
outputs = self.model(noisy_images, texts)
# 根据遮挡情况选择损失函数
loss = 0
for i, occluded in enumerate(is_occluded):
if occluded:
# 文本被遮挡,使用文档理解损失
loss += self.doc_criterion(outputs[i], labels[i])
else:
# 文本可见,使用OCR损失
loss += self.ocr_criterion(outputs[i], labels[i])
return loss / len(images)
统一学习框架的核心在于通过动态噪声注入模拟现实场景中的文本可见性变化。当文本清晰可见时,模型学习执行精确的字符识别任务;当文本被噪声干扰或部分遮挡时,模型转而依赖上下文信息进行语义推理。这种训练方式使MiniCPM-V-4_5在OCRBench上取得了超越GPT-4o-latest的领先成绩。
2.2 多模态强化学习与混合思考模式
MiniCPM-V-4_5引入了创新的混合思考模式,支持快速模式和深度模式的可控切换。这种能力通过多模态强化学习框架实现,结合了RLPR(强化学习与进展奖励)和RLAIF-V(视觉人工智能反馈强化学习)技术。
class MultimodalRLTrainer:
def __init__(self, model, reward_model, thinking_mode_controller):
self.model = model
self.reward_model = reward_model
self.controller = thinking_mode_controller
def proximal_policy_optimization(self, queries, images, thinking_modes):
"""
多模态PPO算法,优化混合思考模式
"""
batch_size = len(queries)
rewards = []
values = []
# 收集轨迹
with torch.no_grad():
for i in range(batch_size):
# 根据思考模式选择生成策略
if thinking_modes[i] == 'fast':
response = self.model.fast_think(queries[i], images[i])
else:
response = self.model.deep_think(queries[i], images[i])
# 计算奖励
reward = self.reward_model(queries[i], images[i], response)
rewards.append(reward)
# 计算价值估计
value = self.model.value_function(queries[i], images[i])
values.append(value)
# 转换为张量
rewards = torch.stack(rewards)
old_values = torch.stack(values)
# 计算优势估计
advantages = self.compute_advantages(rewards, old_values)
# 多轮PPO优化
for _ in range(4): # PPO迭代次数
new_values = []
log_probs = []
for i in range(batch_size):
if thinking_modes[i] == 'fast':
response, log_prob = self.model.fast_think_with_logprob(queries[i], images[i])
else:
response, log_prob = self.model.deep_think_with_logprob(queries[i], images[i])
new_value = self.model.value_function(queries[i], images[i])
new_values.append(new_value)
log_probs.append(log_prob)
new_values = torch.stack(new_values)
log_probs = torch.stack(log_probs)
# 计算价值损失和策略损失
value_loss = self.compute_value_loss(new_values, rewards, old_values)
policy_loss = self.compute_policy_loss(log_probs, advantages)
# 联合优化
total_loss = value_loss + policy_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return total_loss.item()
def compute_advantages(self, rewards, values, gamma=0.99, lam=0.95):
"""使用GAE(广义优势估计)计算优势函数"""
advantages = []
last_advantage = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + gamma * values[t+1] - values[t] if t < len(rewards)-1 else rewards[t] - values[t]
advantage = delta + gamma * lam * last_advantage
advantages.insert(0, advantage)
last_advantage = advantage
return torch.stack(advantages)
混合强化学习框架使模型能够同时优化快速模式和深度模式。快速模式针对日常使用场景进行优化,提供低延迟响应;深度模式则专注于复杂推理任务,通过多步思考生成高质量答案。控制器根据输入复杂度自动选择最适合的思考模式,实现了效率与性能的最佳平衡。
三、高效推理与部署
3.1 设备端优化与量化技术
MiniCPM-V-4_5支持多种设备端部署方案,包括llama.cpp和Ollama等高效CPU推理引擎。模型提供16种尺寸的int4、GGUF和AWQ格式量化版本,满足不同硬件平台的资源约束。
from transformers import AutoModel, AutoTokenizer
import torch.nn.functional as F
class QuantizedMiniCPM:
def __init__(self, model_path, quantization_type='int4'):
self.model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map='auto'
)
# 应用量化
if quantization_type == 'int4':
self.apply_int4_quantization()
elif quantization_type == 'gguf':
self.apply_gguf_quantization()
elif quantization_type == 'awq':
self.apply_awq_quantization()
def apply_int4_quantization(self):
"""应用INT4量化"""
from quantization import quantize_dynamic
# 量化线性层
for name, module in self.model.named_modules():
if isinstance(module, torch.nn.Linear):
quantized_module = quantize_dynamic(
module,
{torch.nn.Linear},
dtype=torch.qint4,
inplace=False
)
self._replace_module(name, quantized_module)
def apply_awq_quantization(self):
"""应用AWQ(激活感知权重量化)"""
from awq import apply_awq
# 计算权重重要性
weight_importance = self.compute_weight_importance()
# 应用AWQ量化
for name, module in self.model.named_modules():
if isinstance(module, torch.nn.Linear):
# 保护重要权重
importance_mask = weight_importance[name] > 0.8
quantized_module = apply_awq(
module,
importance_mask=importance_mask,
bits=4
)
self._replace_module(name, quantized_module)
def compute_weight_importance(self):
"""基于激活值计算权重重要性"""
importance_dict = {}
# 注册前向钩子收集激活统计信息
hooks = []
def hook_fn(module, input, output, name):
# 基于激活幅度计算重要性
activation = input[0]
importance = torch.mean(torch.abs(activation), dim=[0, 1])
importance_dict[name] = importance
for name, module in self.model.named_modules():
if isinstance(module, torch.nn.Linear):
hook = module.register_forward_hook(
lambda m, i, o, n=name: hook_fn(m, i, o, n)
)
hooks.append(hook)
# 运行校准数据
self.run_calibration()
# 移除钩子
for hook in hooks:
hook.remove()
return importance_dict
def run_calibration(self, calibration_data=None):
"""运行校准过程收集激活统计信息"""
if calibration_data is None:
# 生成随机校准数据
calibration_data = [torch.randn(1, 3, 224, 224) for _ in range(32)]
self.model.eval()
with torch.no_grad():
for data in calibration_data:
_ = self.model(data)
量化技术大幅降低了模型部署的资源需求,使MiniCPM-V-4_5能够在iPhone和iPad等移动设备上流畅运行。AWQ量化方法特别值得关注,它通过保护重要权重避免量化误差,在4bit精度下保持了接近原始模型的性能。
3.2 高效推理框架集成
MiniCPM-V-4_5支持多种高性能推理框架,包括vLLM和SGLang,这些框架提供了内存优化和高吞吐量推理能力。
from vllm import LLM, SamplingParams
from PIL import Image
import base64
from io import BytesIO
class MiniCPMvLLMEngine:
def __init__(self, model_path, max_model_len=4096, tensor_parallel_size=1):
# 初始化vLLM引擎
self.llm = LLM(
model=model_path,
max_model_len=max_model_len,
tensor_parallel_size=tensor_parallel_size,
trust_remote_code=True,
gpu_memory_utilization=0.9
)
self.sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=1024
)
def encode_image(self, image_path):
"""编码图像为base64字符串"""
with Image.open(image_path) as img:
buffered = BytesIO()
img.save(buffered, format="JPEG")
img_str = base64.b64encode(buffered.getvalue()).decode()
return f"data:image/jpeg;base64,{img_str}"
def multimodal_prompt_template(self, query, images):
"""构建多模态提示模板"""
prompt = "<|im_start|>system\nYou are a helpful AI assistant.<|im_end|>\n"
for img_path in images:
img_str = self.encode_image(img_path)
prompt += f"<|im_start|>image\n{img_str}<|im_end|>\n"
prompt += f"<|im_start|>user\n{query}<|im_end|>\n"
prompt += "<|im_start|>assistant\n"
return prompt
def generate(self, query, images, thinking_mode=False):
"""生成响应"""
prompt = self.multimodal_prompt_template(query, images)
# 根据思考模式调整参数
if thinking_mode:
sampling_params = SamplingParams(
temperature=0.3, # 更低温度用于确定性思考
top_p=0.8,
max_tokens=2048, # 更长响应用于深度思考
stop=["<|im_end|>"]
)
else:
sampling_params = self.sampling_params
# 使用vLLM生成
outputs = self.llm.generate([prompt], sampling_params)
return outputs[0].outputs[0].text
# 使用示例
if __name__ == "__main__":
engine = MiniCPMvLLMEngine("OpenBMB/MiniCPM-V-4_5")
response = engine.generate(
"描述这张图片中的场景",
["path/to/image.jpg"],
thinking_mode=True # 启用深度思考模式
)
print(response)
vLLM集成通过连续批处理、内存池优化和高效注意力计算大幅提升了推理吞吐量。特别在长视频理解和多轮对话场景中,这些优化使MiniCPM-V-4_5能够处理更复杂的多模态任务,同时保持较低的响应延迟。
四、实际应用与性能评估
4.1 基准测试结果分析
MiniCPM-V-4_5在多个权威基准测试中展现了卓越性能。在OpenCompass综合评估中,它以77.0的平均分数超越了包括GPT-4o-latest和Gemini 2.0 Pro在内的顶级模型。
| 模型 | 参数量 | OpenCompass平均分 | 推理效率(token/秒) |
|---|---|---|---|
| GPT-4o-latest | 未知 | 76.8 | 未知 |
| Gemini 2.0 Pro | 未知 | 76.5 | 未知 |
| Qwen2.5-VL-72B | 72B | 76.9 | 较低 |
| MiniCPM-V-4_5 | 8.7B | 77.0 | 高 |
在视频理解任务中,MiniCPM-V-4_5的表现尤为突出。在Video-MME基准测试中,它仅用0.26小时就完成了推理任务,而同类模型需要2-3小时,展现了96倍视频压缩带来的效率优势。
4.2 实际应用案例
MiniCPM-V-4_5的强大能力使其在多个实际应用场景中表现出色:
智能文档分析:模型能够准确解析复杂格式的PDF文档,提取关键信息并回答相关问题。在OmniDocBench测试中,它实现了通用多模态模型中的最先进文档解析能力。
def document_qa_system(document_path, question):
"""
文档问答系统实现
"""
# 加载文档
document_images = convert_pdf_to_images(document_path)
# 构建多页提示
context = "请分析以下文档并回答问题。文档内容如下:\n"
for i, img in enumerate(document_images[:4]): # 最多处理前4页
context += f"<|im_start|>page_{i+1}\n"
context += encode_image(img)
context += "<|im_end|>\n"
full_prompt = context + f"<|im_start|>question\n{question}<|im_end|>\n"
# 使用深度思考模式
response = model.chat(
msgs=[{'role': 'user', 'content': full_prompt}],
enable_thinking=True,
max_new_tokens=512
)
return response
# 使用示例
answer = document_qa_system("financial_report.pdf", "总结2023年第四季度的主要财务指标")
print(answer)
实时视频分析:基于高效3D重采样器,MiniCPM-V-4_5能够实时分析高帧率视频流,适用于安防监控、运动分析等场景。
class RealTimeVideoAnalyzer:
def __init__(self, model, frame_buffer_size=30):
self.model = model
self.frame_buffer = []
self.buffer_size = frame_buffer_size
def process_video_stream(self, frame_generator, analysis_interval=10):
"""
处理实时视频流并进行定期分析
"""
results = []
frame_count = 0
for frame in frame_generator:
# 缓冲帧
self.frame_buffer.append(frame)
if len(self.frame_buffer) > self.buffer_size:
self.frame_buffer.pop(0)
frame_count += 1
# 定期分析
if frame_count % analysis_interval == 0:
analysis = self.analyze_buffer()
results.append(analysis)
# 实时输出结果
if self.is_anomaly_detected(analysis):
self.trigger_alert(analysis)
return results
def analyze_buffer(self):
"""分析当前帧缓冲"""
# 选择关键帧进行分析
key_frames = self.select_key_frames(self.frame_buffer)
# 编码时间ID
temporal_ids = [[i] for i in range(len(key_frames))]
# 使用模型分析
result = self.model.chat(
msgs=[{'role': 'user', 'content': key_frames + ["描述当前场景中发生的事件"]}],
temporal_ids=temporal_ids,
enable_thinking=False # 快速模式用于实时分析
)
return result
def select_key_frames(self, frames, max_frames=6):
"""基于运动检测选择关键帧"""
if len(frames) <= max_frames:
return frames
# 计算帧间差异
diffs = []
for i in range(1, len(frames)):
diff = np.mean(np.abs(frames[i] - frames[i-1]))
diffs.append(diff)
# 选择变化最大的帧
indices = np.argsort(diffs)[-max_frames:]
return [frames[i] for i in sorted(indices)]
五、未来发展方向与挑战
5.1 技术演进趋势
MiniCPM-V-4_5代表了多模态模型发展的新方向,其技术路线预示着几个重要趋势:
效率优先架构:未来模型将更加注重计算效率,通过算法创新而非单纯增加参数来提升性能。3D重采样器和自适应计算技术将成为标准组件。
多模态统一学习:OCR、视觉理解和语言生成的统一学习框架将得到广泛应用,减少模块间误差传递并提升整体性能。
设备端AI普及:随着模型优化技术的成熟,越来越多的高级AI能力将直接在移动设备上运行,减少对云端的依赖并提升隐私保护。
5.2 面临的挑战
尽管MiniCPM-V-4_5取得了显著进展,但仍面临一些挑战:
长视频理解限制:虽然压缩效率大幅提升,但极长视频(超过10分钟)的理解仍然具有挑战性,需要更高效的时间建模技术。
多模态对齐:视觉特征与语言表征的完全对齐仍是一个开放问题,特别是在细粒度视觉描述和复杂推理任务中。
计算资源约束:在极端资源受限环境(如低端移动设备)中部署仍需要进一步优化。
class FutureEnhancements:
"""未来改进方向的技术原型"""
def hierarchical_temporal_modeling(self, video_frames, segment_length=60):
"""
分层时间建模:处理极长视频
"""
# 第一层:分段处理
segments = self.split_video_into_segments(video_frames, segment_length)
segment_summaries = []
for segment in segments:
# 使用3D重采样器处理每个段
summary = self.model.process_segment(segment)
segment_summaries.append(summary)
# 第二层:全局整合
global_context = self.integrate_segment_summaries(segment_summaries)
return global_context
def cross_modal_alignment_loss(self, visual_features, text_features):
"""
改进的跨模态对齐损失函数
"""
# 对比学习损失
contrastive_loss = self.infoNCE_loss(visual_features, text_features)
# 细粒度对齐损失
fine_grained_loss = self.fine_grained_matching_loss(visual_features, text_features)
# 语义一致性损失
semantic_consistency_loss = self.semantic_constraint_loss(visual_features, text_features)
return contrastive_loss + 0.5 * fine_grained_loss + 0.3 * semantic_consistency_loss
def dynamic_computation_offloading(self, input_data, device_capability):
"""
动态计算卸载:根据设备能力调整计算策略
"""
if device_capability == 'high':
# 全模型推理
return self.model.full_forward(input_data)
elif device_capability == 'medium':
# 部分量化推理
return self.model.quantized_forward(input_data, bits=8)
else:
# 极端压缩模式
return self.model.extreme_compression_forward(input_data, bits=4)
结论:开启边缘多模态AI的新纪元
MiniCPM-V-4_5的出现标志着多模态AI发展的一个重要转折点。它证明了通过算法创新和架构优化,小型模型同样能够实现与大型模型相媲美甚至更优的性能。这种"小而精"的设计哲学不仅降低了AI应用的门槛,也为AI技术的普及和民主化奠定了基础。
随着3D重采样技术、统一学习框架和高效推理优化的不断完善,我们有理由相信,像MiniCPM-V-4_5这样的高效多模态模型将在未来几年内推动AI技术进入一个新的发展阶段,让先进的AI能力真正惠及每一个普通用户,无处不在而又不显山露水。
参考资源:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)