OpenMMLab AI实战四——MMPreTrain
将图像切分乘干16x16的小块(即无重叠,固定大小),所有块排列成“词向量”,先经过线性层映射,一张[H,W,C]维度的图片变为[L,C](图片token化),再经过Transformer Encoder的计算产生相应的特征向量。输入数据维度3x4,将Q与K相乘得到Q对应的一系列K,然后再将K与V相乘,得到K对应的V(如何理解QKV?基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出
一、MMPreTrain算法库
MMClassification与MMSelfSup合并,同时增加多模态相关算法
代码库:MMPreTrain
文档:MMPreTrain文档
可完成图形分类、图像描述、视觉问答、视觉定位以及检索
MMPreTrain的代码目录结构
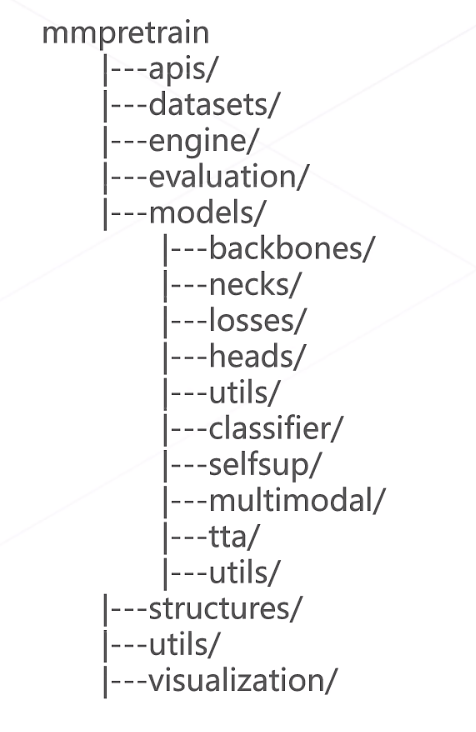
apis:顶层API接口,支持各类推理任务
datasets:支持各类数据集、数据变换等
engine:支持各类钩子,优化器等训练相关组件
evaluation:各类评测相关函数和指标计算
models:各类算法模型的定义
-
backbones:一般为图像的特征提取器,各类主干网络的定义
-
necks:承接backbone和head之间的其他计算(例如高维特征解码,多尺度特征融合等)
-
heads:相关loss计算和推理结果的预测
-
classifier,selfup,multimodel则为模型高阶抽象定义(什么是高阶抽象定义?)
structures:DataSample数据结构的定义(统一数据流)
utils:相关工具
visualization:可视化的支持
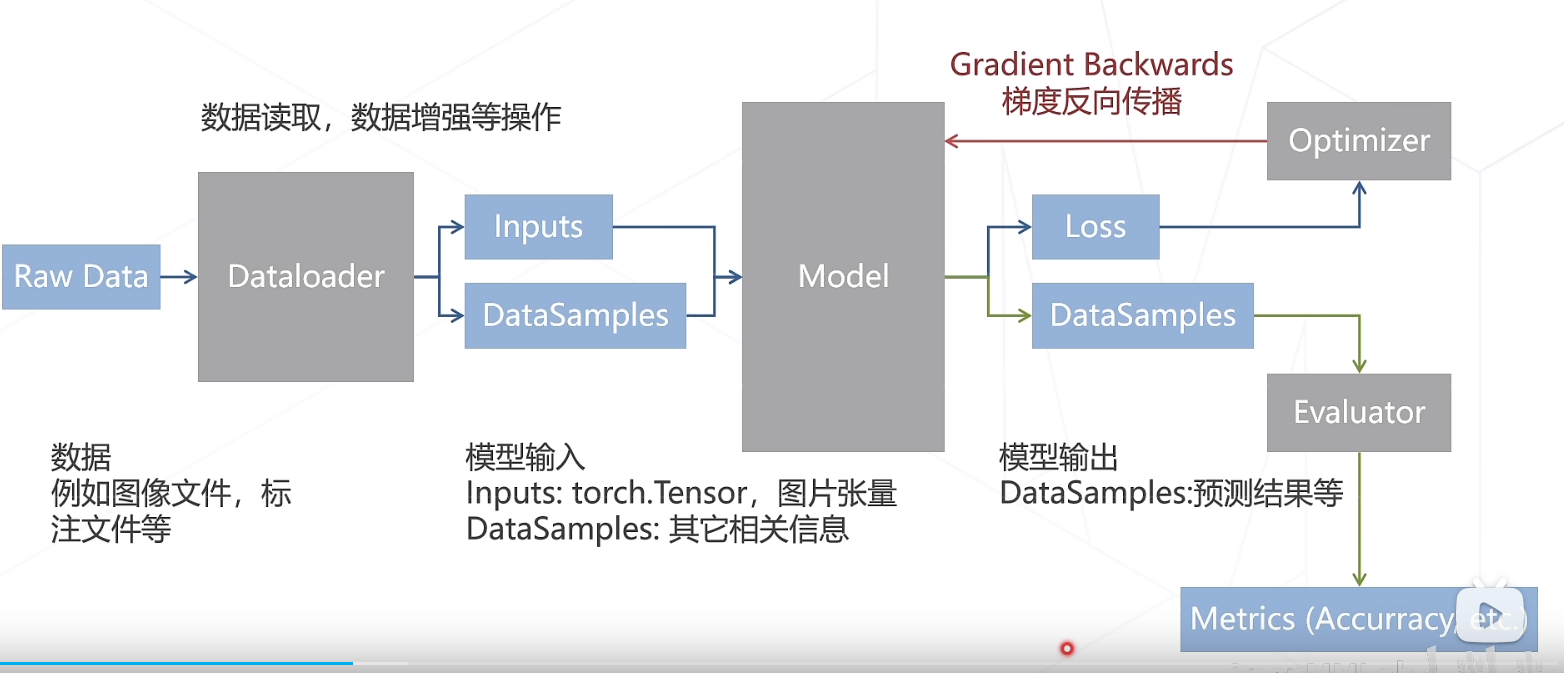
MMPreTrain的数据流如图所示
二、经典骨干网络
经典深度神经网络:AlexNet (2012)、VGG (2014)、GoogLeNet (2014)(简单堆叠层数)
-
问题点:当卷积退化为恒等映射的时候,深层网络和浅层网络相同;然而当深层网络在训练过程中很难找到更优的模型使得新增加的卷积层拟合一个近似恒等映射,从而导致精度的下降
-
解决方法:残差建模,让新增加的层拟合浅层网络与深层网络之间的差异,更加容易学习梯度,可直接回传到浅层网络,从而监督浅层网络学习
-
优点:没有引入额外参数,让参数更加有效地贡献到最终的模型中
相关阅读:
主要思路:
-
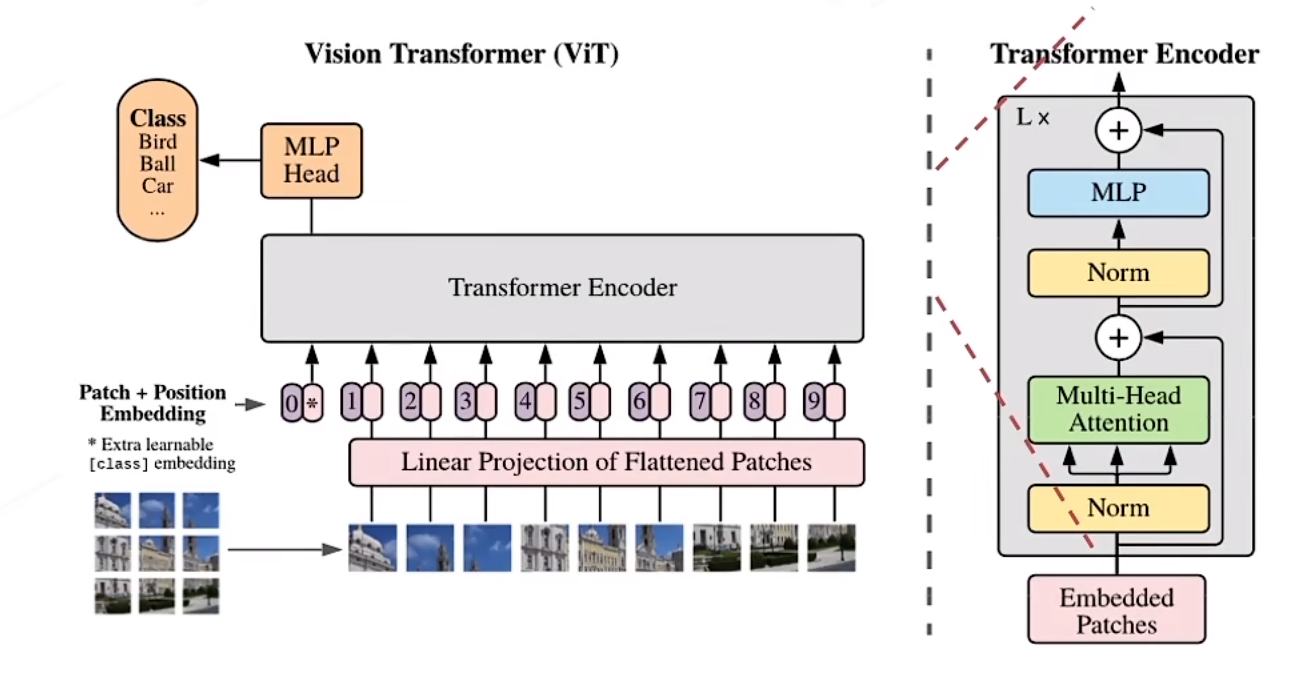
将图像切分乘干16x16的小块(即无重叠,固定大小),所有块排列成“词向量”,先经过线性层映射,一张[H,W,C]维度的图片变为[L,C](图片token化),再经过Transformer Encoder的计算产生相应的特征向量
-
图块之外加入额外的token,用于query其他patch的特征并给出最后分类
-
注意力模块基于全局感受野,复杂度为尺寸的4次方
结构图如图所示
简要计算步骤如图所示
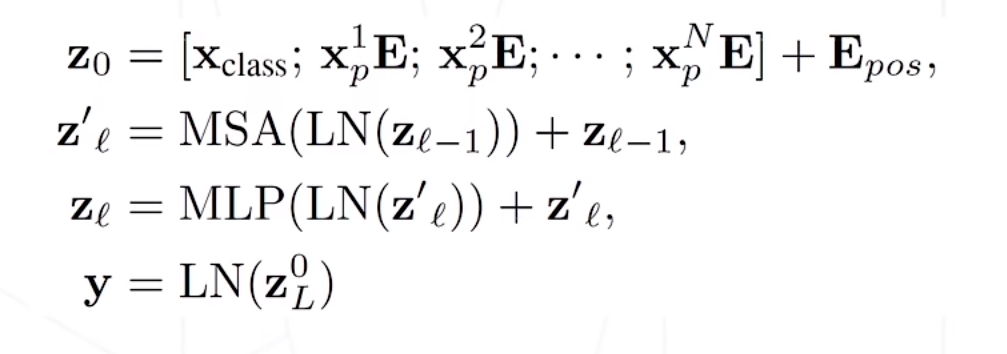
自注意力机制计算图
一维注意力机制计算图
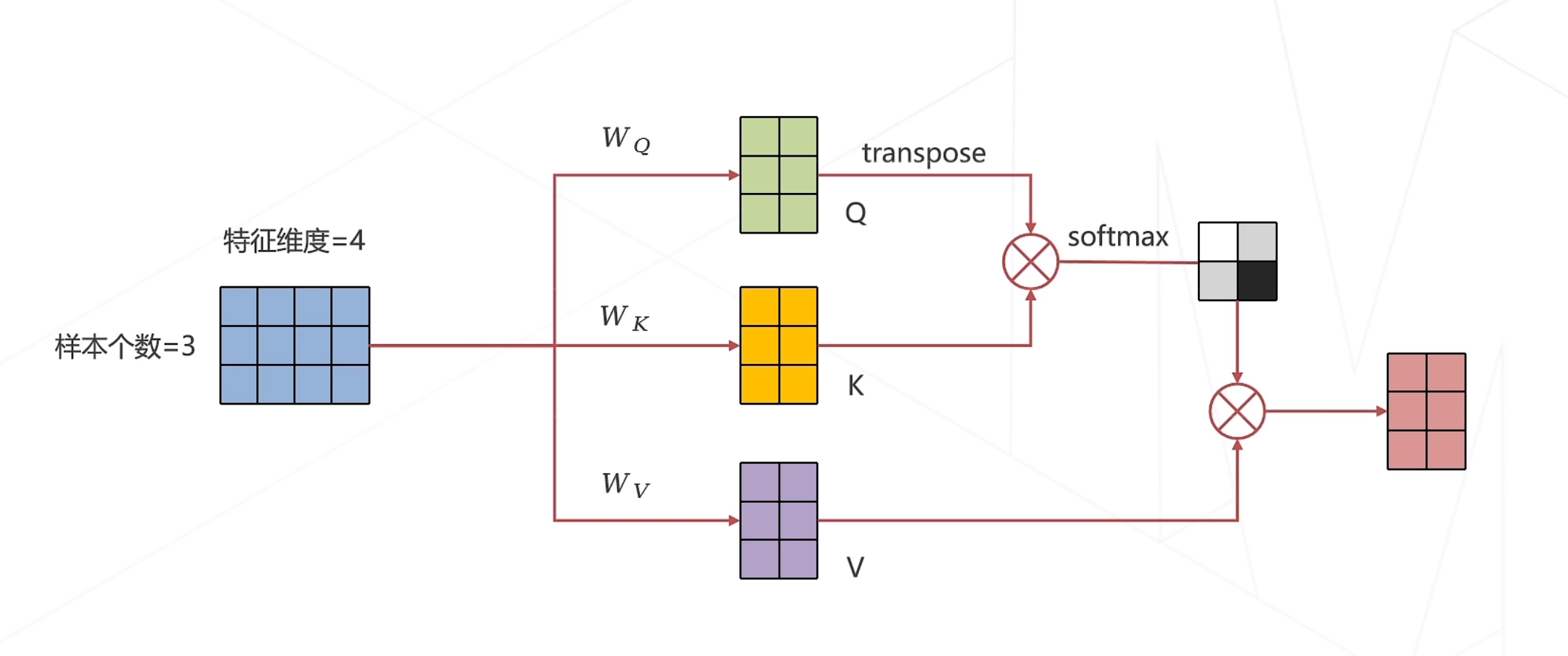
输入数据维度3x4,将Q与K相乘得到Q对应的一系列K,然后再将K与V相乘,得到K对应的V(如何理解QKV?)
多头注意力机制
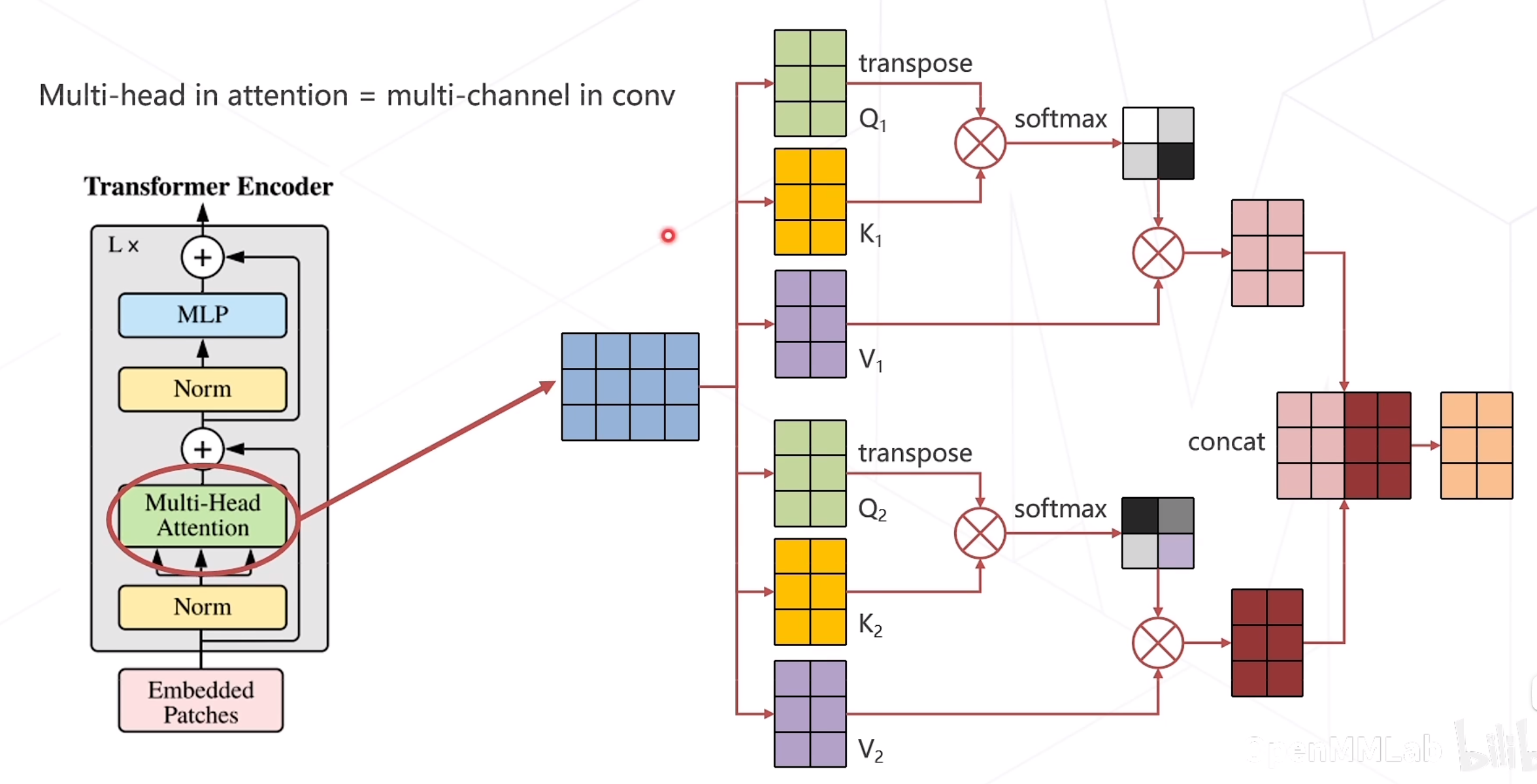
优点:不同头的注意力对不同的特征进行提取
三、自监督学习
A Simple Framework for Contrastive Learning of Visual Representations(2020)(对比学习)
基本假设:如果模型能够很好地提取图片内容的本质,那么无论图片经过什么样的数据增强操作,则提取出的特征都应极为相似
Masked Autoencoders Are Scalable Vision Learners(2022)(掩码学习)
基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容
四、多模态算法
Contrastive Language-Image Pre-Training(2021)
Flamingo: a Visual Language Model for Few-Shot Learning(2022)
Language Is Not All You Need: Aligning Perception with Language Models(2023)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)