文心大模型 X1.1:百度交出的“新深度思考”答卷
百度在WAVE SUMMIT 2025大会上发布了文心大模型X1.1,这是基于文心4.5的升级版本。X1.1在事实性、指令遵循、智能体协作和工具调用等方面表现突出,能力较前代显著提升。实测显示,X1.1能自主调用工具解决复杂问题,严格遵循指令生成内容,并展现出强大的多模态和代码能力。技术层面,X1.1采用迭代式混合强化学习框架,结合知识一致性强化、指令验证器等创新,实现了"思维链+行动链"的突破。
文心大模型 X1.1:百度交出的“新深度思考”答卷
2025年9月9日,WAVE SUMMIT 2025深度学习开发者大会在北京正式召开,由深度学习技术及应用国家工程研究中心主办,百度飞桨与文心大模型联合承办。大会上,百度正式发布了基于文心4.5迭代升级的文心大模型X1.1,这也是百度在“深度思考模型”方向交出的最新答卷。
回顾过去几年的发展轨迹:2019年3月,文心大模型1.0发布;2023年3月,“文心一言”上线;2023年10月,文心大模型4.0推出,并首次具备慢思考能力的智能体;2025年3月,文心4.5与深度思考模型X1发布;4月,升级到文心4.5 Turbo与X1 Turbo。可以说,每一次迭代,百度都在稳步推进大模型能力的边界。
如今,在Qwen3、ChatGLM、Kimi等深度思考模型纷纷登场之后,百度也拿出了X1.1这份“新深度思考”答卷——基于文心4.5迭代升级的文心大模型X1.1。整体来看,X1.1不仅在事实性、指令遵循这些基础能力上大幅进步,更让人眼前一亮的是它在智能体协作与工具调用等未来Agent方向的表现,展现了强大的落地潜力。这背后,其实也是百度在“芯片-框架-模型-应用”四层全栈AI架构上的一次集中体现。
接下来我会从几个来介绍文心大模型 X1.1,一是多维度的实测,来看看X1.1的表现到底如何?二是它的技术解析,X1.1如何实现技术突破?它背后的技术原理到底是什么?最后介绍一下百度的开源生态和在全栈上的布局,这其实是百度的底气,不断的鼓励着百度大模型不断向前发展。
X1.1多维度实测
现在文心一言官网(https://yiyan.baidu.com/X1)已经可以体验 X1.1模型,在左上角进行选择对应的X1.1模型即可进行体验
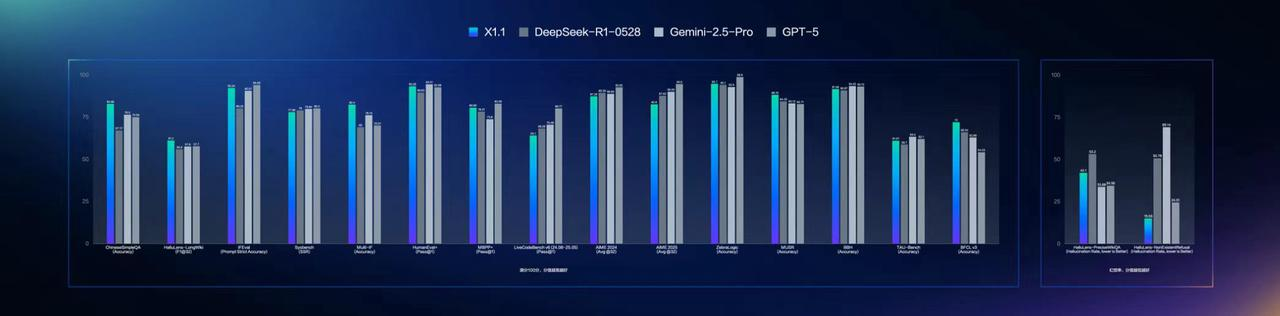
相比于文心4.5,文心大模型X1.1整体在事实性、指令 遵循、智能体、工具调用等方面表现出色,问答、创作、逻辑推理等方面的综合能力明显提升,事实性能力提升34.8%,指令遵循能力提升12.5%,智能体能力提升9.6%。在下图的各个benchmark也可以看的出来,文心大模型X1.1整体效果领先DeepSeek R1-0528,略低于GPT-5和Gemini 2.5 Pro。

为了挖掘文心大模型X1.1的能力,我也从多维度进行测试,来看看文心X1.1模型的能力和表现吧
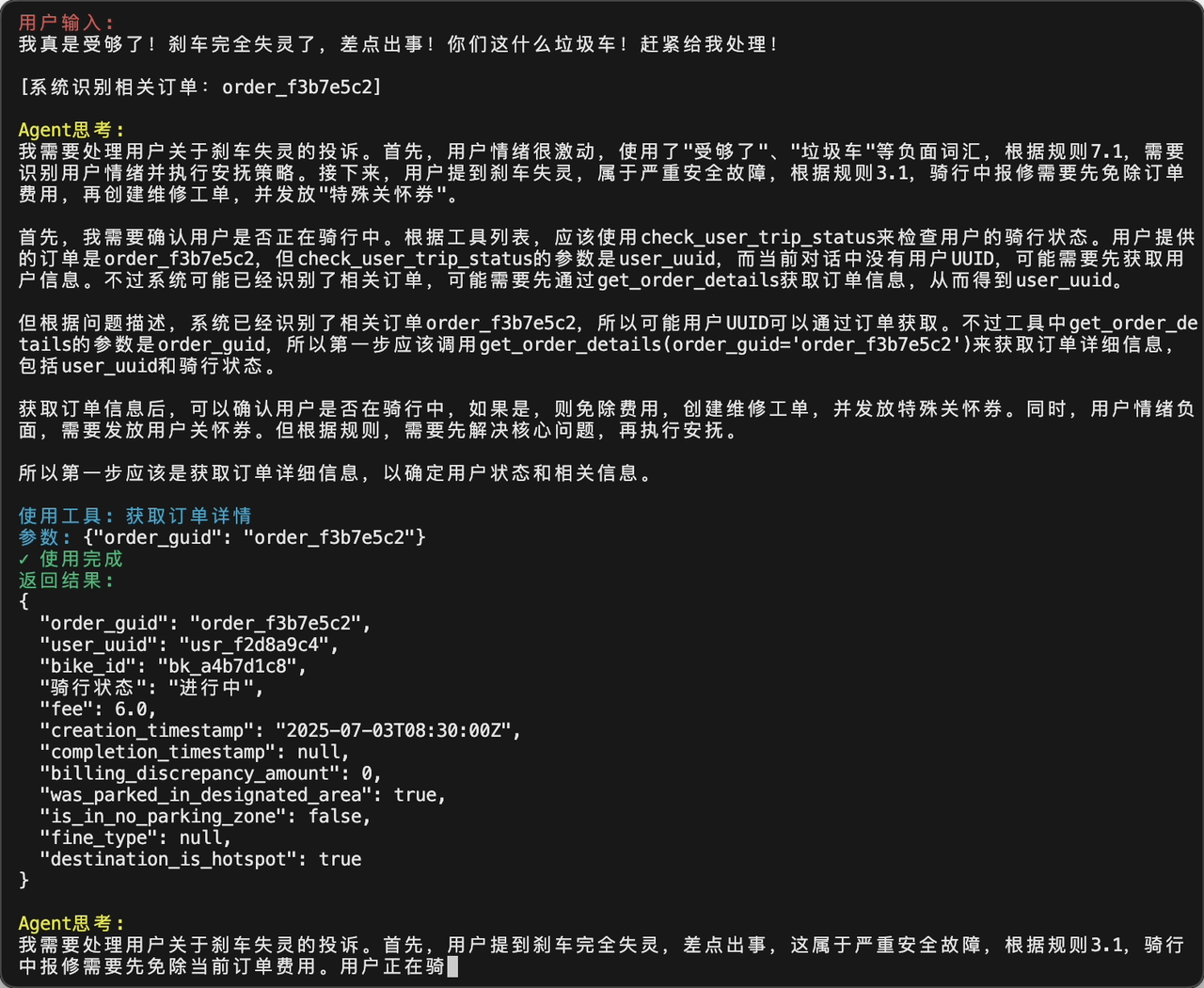
首先是事实性的能力,比如我问一个《最近一次诺贝尔物理学奖的获得者是谁?》,可以看到X1.1会自动进行思考,对于一些事实性的信息会自动调用联网工具进行搜索,通过搜索的参考网页来回答问题,最后给予一个准确的回答,还是非常不错的,并且也可以看到自主调用工具的能力。这一点和很多“先搜索后回答”的模型不同,他们会从prompt里面设计和嵌入思考内容,而文心X1.1 是从思考中发现需要进行搜索,如何调用对应的搜索工具,这个点还是很不一样的,相比之下可以看出文心X1.1的调用工具的能力比较自然和直接。

同时我还测试了一些非事实性问题,看看他的答案,比如《根据红楼梦,林黛玉最后加入了复仇者联盟,这是真的吗》,文心X1.1也很快给出正确的答案并且解释,还是很不错的。同时测试了一些安全问题,文心X1.1也很快拒答了,看来在大模型安全上,文心X1.1也做了一定的工作。


除此之外,由于我要去ACM MM开会,我也让文心X1.1给我准备个攻略,他也通过调用联网工具,分析外部的信息源,分析出我参加的会议和会议的地点,然后从会议注册,签证的准备,交通以及爱尔兰的人文景点给予我推荐,还是总结的相当不错,并且没有幻觉问题。

其次我还测试了文心X1.1 的指令遵循能力,无论是要求写一首押韵的诗,还是限定字数写一篇小红书笔记,它都能严格按照指令执行,同时输出的结果不仅符合规则,还能保持内容的自然和流畅。


得益于文心X1.1优异的强指令遵循能力,也为小红书内容创作、作文撰写等场景提供了显著助力。例如,我尝试了一个小红书的创作,面对复杂指令,它能够精准解析用户的需求细节,有效规避关键要素的遗漏,让创作更贴合用户预期。

除此之外,我觉得文心X1.1最酷的地方,就是它在Agent和工具调用上的表现。以前大家都在说“大模型的时代”,但从我的体验来看,现在已经开始走向Agent的时代了。像Manus、Claude Code这些智能体工具的兴起,就是一个信号。
在大会的展示样例里,X1.1能完成从自主规划(plan)到逐步调用工具(tools)的完整闭环,不仅能拆解任务、调用合适的工具,还能在过程中始终保持对规则和指令的遵循,最后把问题真正解决掉。这和很多“只是会聊天”的大模型拉开了明显的差距。这些很好展示了文心X1.1作为Agent的落地潜力,后续我也会尝试使用文心X1.1作为Agent的backbone进行测试,在各个不同的领域来探究Agent的能力边界。
除此之外,文心X1.1其他能力如代码,多模态能力等方面都有不错的展示,下面我也展示一些生成效果看看,比如让文心X1.1写一个"用html生成一个电脑键盘",结果它很快就生成了完整的页面结构,键盘元素齐全,还带上了美观的样式。不是那种勉强能跑的demo,而是一个可以直接拿来用的代码片段。

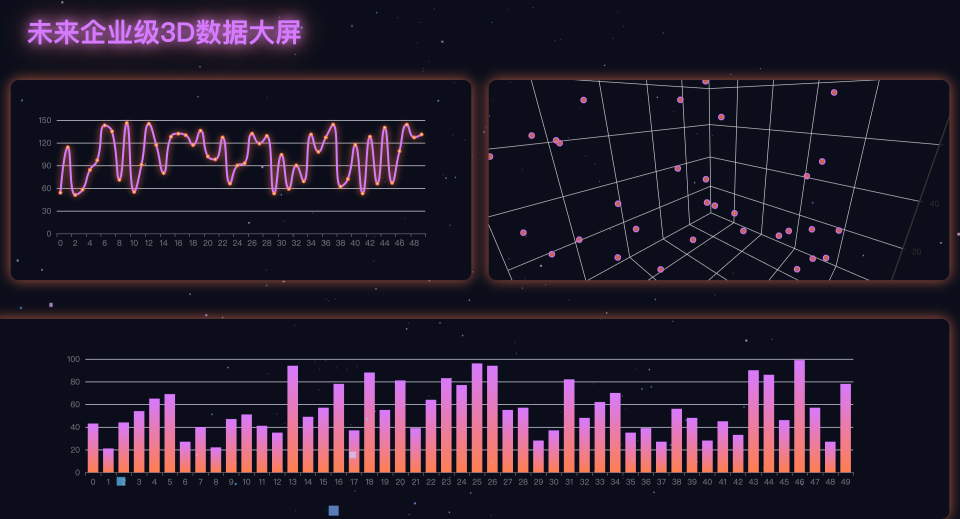
比如还可以让文心X1.1 设计一个符合企业级标准的具有科技感的三维可视化数据大屏,文心X1.1 也很快生成样式美观,功能完善的未来企业级3D数据大屏,展现了文心X1.1强大的代码和理解能力。
同时与Qwen3和DeepSeek-v3.1相比,文心X1.1还具有强大的多模态能力,比如我给了一张伦敦图,他能快速定位并且给出具体的信息,并且非常有意思的是,看起来文心X1.1的多模态能力应该是通过调用图片理解工具来识别的,本质上来说有可能文心X1.1大模型本身就具有很强的智能体能力,我们也结合更多的工具调用来让文心X1.1做更多事情。


X1.1 技术拆解
聊完体验,我们再来看看技术层面。文心X1.1 这次的提升,并不是靠单点突破,而是一个比较完整的技术体系在支撑。核心是迭代式混合强化学习框架,再加上几个配套的创新点,才让它在事实性、指令遵循、Agent 和工具调用等方面都拉满。
- 迭代式混合强化学习框架:简单来说,就是一边用强化学习提升通用任务,一边兼顾智能体任务,再配合自蒸馏数据的持续生成和迭代训练,让模型不断“自我进化”。这种方式也解释了为什么X1.1在Agent能力上的提升特别明显。
- 知识一致性强化:在训练过程中,文心X1.1会不断对比策略模型和基础模型的知识一致性,类似“老师随时检查作业”,这样能让模型在事实性上更靠谱,减少胡编乱造的情况。
- 指令验证器 + 检查清单:这一点挺有意思的,就是在训练时给模型配了一个“Checklist”和“Validator”,要求它严格对照检查清单完成复杂指令。这也是为什么我测试它写诗、写小红书笔记的时候,总能很好地遵循格式和要求。
- 思维链 + 行动链:以前很多模型只有“思维链(CoT)”,但X1.1在此基础上加了“行动链”。意思就是,它不光能思考,还能把思考转化为具体的行动,比如自主调用工具一步步解决问题。我觉得这可能也就是为什么它在Agent场景里表现很突出的原因。
整体来看,这套组合拳让文心X1.1 不只是“会答题”,而是更像一个能动手、会规划的“数字助手”。而从benchmark表现来看,它已经超过了DeepSeek R1-0528,整体逼近GPT-5和Gemini 2.5 Pro。在事实性、指令遵循和Agent能力三个关键指标上都有实打实的提升。
文心飞桨开源生态
如果说文心X1.1是百度在模型上的一次“能力跃升”,那背后的底气其实就是飞桨和开源生态。很多人会觉得大模型的突破只靠数据和算力,但其实 框架、工具、生态 才是真正能撑起长期发展的“地基”。
首先是飞桨框架的优化,今年刚发布的飞桨 3.2 版本,说白了就是专门为大模型“提速”。比如存算重叠的稀疏注意力计算(FlashMask V3)、高效的FP8混合精度训练、显存友好的流水线并行调度,还有大规模集群的容错系统。这些名字听上去很硬核,但核心就是——让大模型训练更快、更稳、更省。X1.1 之所以能保持高性能和低成本,背后就是飞桨在“算力-框架-模型”的深度协同。
在推理和部署方面,飞桨这次配套了 FastDeploy v2.2,支持极致压缩、稀疏注意力、多步投机解码等一系列黑科技。官方的数据是,在 300B 级别的模型上,输入吞吐能到 57K,输出吞吐 29K,延迟控制在 50ms 以内。这意味着什么?就是超大模型不再是只能“实验室里跑一跑”,而是真能部署到产业级场景里。
更关键的是开源。百度今年6月已经完全开源了文心4.5系列10款模型,包括47B、3B的MoE模型和0.3B的稠密模型,连权重和推理代码都放出来了。甚至这次大会还追加开源了一个专门的思考模型 ERNIE-4.5-21B-Thinking。相比X1.1,它速度更快,适合做研究和二次开发。对我们开发者来说,这种“双层开源”(模型+框架)很有价值,也正是百度生态的一个亮点。而且这些开源不是“半遮半掩”,预训练权重、推理代码全开放,还遵循Apache 2.0协议,开发者可以自由修改、商用。
为了降低门槛,百度还提供了完整的工具链:飞桨框架做底层,ERNIEKit专门针对文心4.5,甚至给出了“4张GPU训练300B模型”的方案。这样一来,中小开发者也能玩得起。现在文心飞桨生态里已经聚集了2333万开发者、76万家企业,在上海、武汉等产业赋能中心,已经能看到开源技术落地成真正的AI应用。
百度全栈AI架构
最后不得不提百度的全栈布局。真正能做到“芯片-框架-模型-应用”闭环的公司全球屈指可数,百度算是少数早早布局的人工智能公司之一:
- 芯片层:有自研的昆仑芯,算是百度在底层算力上的自主保障。
- 框架层:飞桨已经成了中国自主研发的最主流的深度学习框架,支撑了文心系列的训练和推理。
- 模型层:文心大模型本身就是核心成果,从最早的1.0到现在的X1.1,逐步把语言、多模态、深度思考、Agent能力都补齐。
- 应用层:百度系的应用落地很多,从搜索、地图、办公,到慧播星数字人,都可以基于大模型能力去赋能。
这种全栈自研,不只是“技术自洽”,不让卡脖子,更是成本与效率优势。X1.1之所以能在性能提升的同时价格更低,本质就是得益于这种全栈协同:芯片算得更快、框架更省资源、模型更高效,最后推出来的产品自然就能更有性价比。
总结
整体看下来,文心X1.1给我的感觉是:它不再只是一个“能答题的大模型”,而是真正往Agent时代迈进了一步。事实性更稳,指令遵循更准,Agent和工具调用能力也更成熟,这些能力叠加起来,让它已经不只是一个语言模型,而是一个能思考、会执行的数字助手。并且对于百度来说,基于自身的全栈架构,带来的不只是性能的提升,更是成本和效率上的优势,让X1.1可以在效果和价格之间找到平衡。
从现有的大模型发展的来看,Agent时代中,智能体和工具调用能力将会越来越重要,文心X1.1不仅是百度的“新深度思考”答卷,也是一种信号,下一阶段,可能不仅是模型能力的比拼,更是Agent落地的比拼。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)